


Exploring Hardware Fault Impacts on Different Real Number Representations of the Structural Resilience of TCUs in GPUs †

 , , and
, , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We report the results of an extensive reliability assessment of permanent faults affecting the structures of an accelerator (TCUs) for AI workloads (e.g., GEMM) by considering two number format width configurations (i.e., 16- and 32-bit data) and two real number formats (i.e., FP and posit).
- We introduce PyOpenTCU [45], an open-source architectural model of TCUs in GPUs that integrates a custom reliability evaluation framework, which allows the evaluation of hardware defects located in the internal hardware structures of TCUs (i.e., DPUs and near-registers).
- We show that TCUs are highly sensitive to permanent hardware defects. However, we demonstrate that only around 5% to 10% of all analyzed and observed errors affect significantly the final result.
- We prove that the posit number format is less error-sensitive to permanent faults in comparison to the floating-point one by up to three orders of magnitude for 16 bits and up to twenty orders of magnitude in the 32-bit case.
2. Background
2.1. Organization of Graphics Processing Units (GPUs)
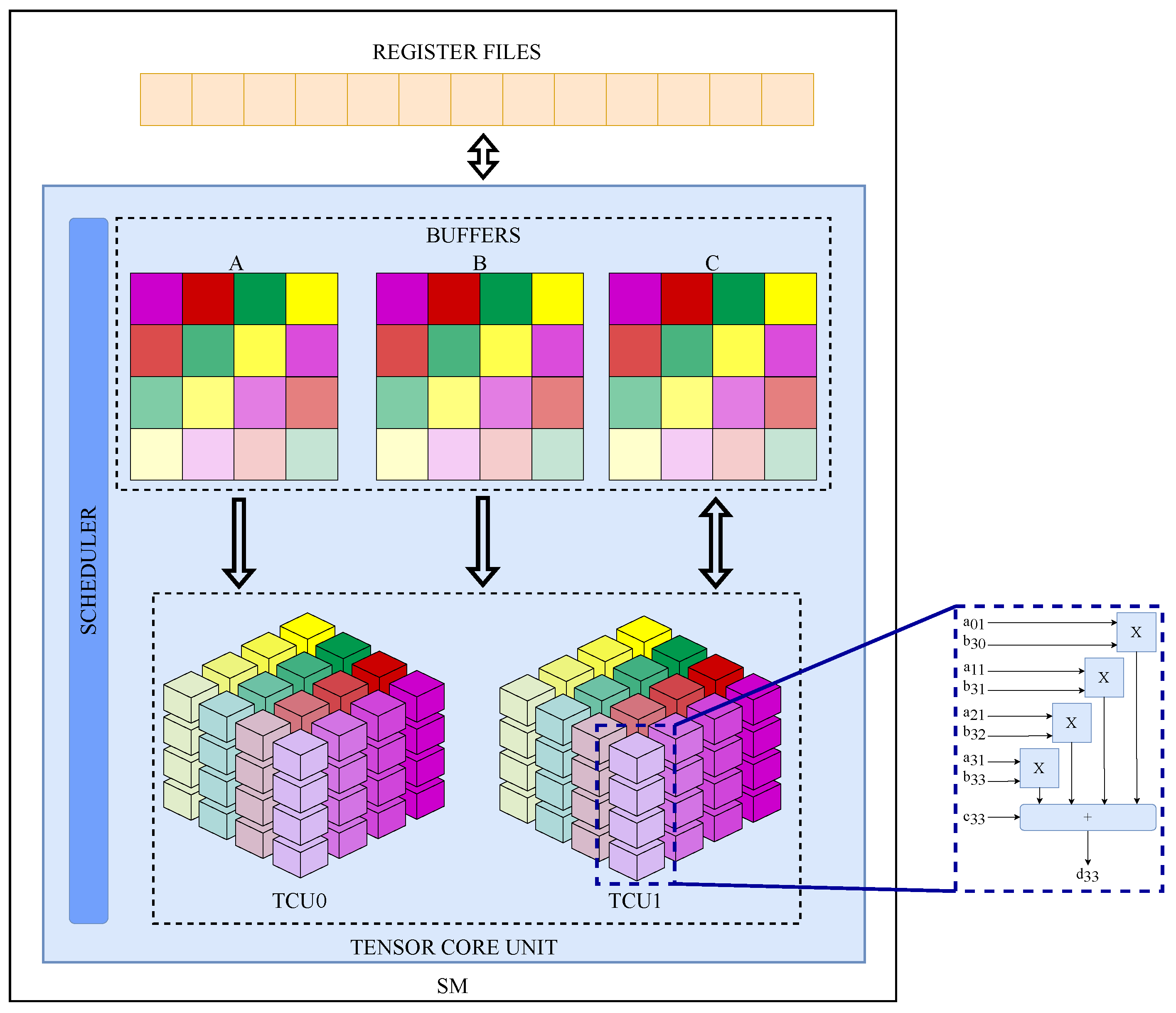
2.2. TCUs’ Organization and Operation in GPUs
2.3. Number Formats for Real Numbers
2.3.1. Floating-Point (FP) Format
2.3.2. Posit Format
3. Evaluation of Real Number Representations in TCUs
3.1. Functional Characterization of TCUs
3.2. Fault Evaluation and Error Propagation
3.3. Error Impact Assessment
- Masked: The fault does not produce any effect;
- Silent data corruption (SDC): The fault affects the results by corrupting one or more output values;
- Detected unrecoverable error (DUE): The fault prevents the correct execution of the application (i.e., the results show one or more values of inf or NaN).
4. Experimental Results
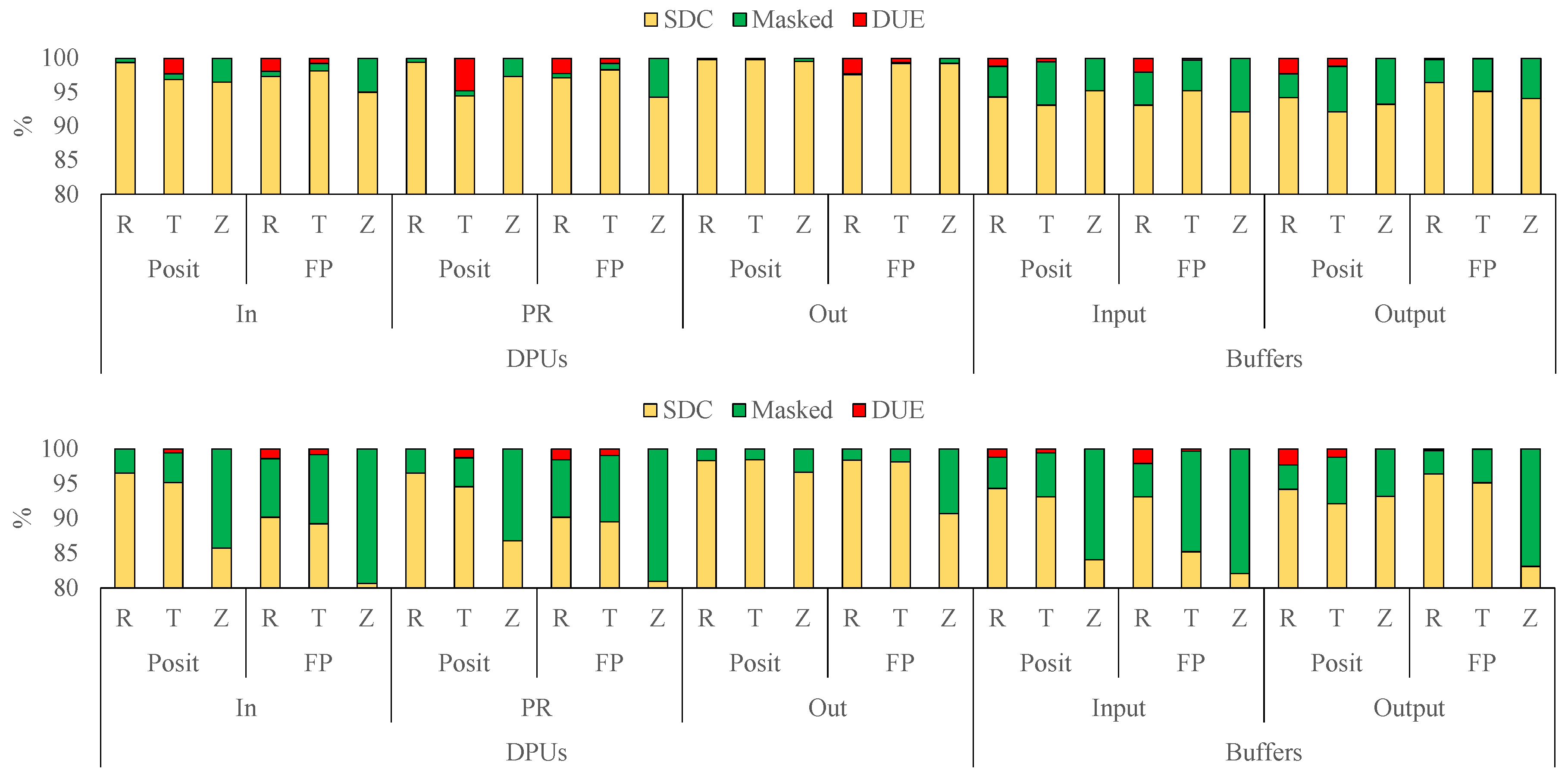
4.1. Fault Effect Assessment
4.2. Quantitative Error Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Peccerillo, B.; Mannino, M.; Mondelli, A.; Bartolini, S. A survey on hardware accelerators: Taxonomy, trends, challenges, and perspectives. J. Syst. Archit. 2022, 129, 102561. [Google Scholar] [CrossRef]
- Dally, B. Hardware for Deep Learning. In Proceedings of the 2023 IEEE Hot Chips 35 Symposium (HCS), IEEE Computer Society, Palo Alto, CA, USA, 27–29 August 2023; pp. 1–58. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. SIGARCH Comput. Archit. News 2017, 45, 1–12. [Google Scholar] [CrossRef]
- Raihan, M.A.; Goli, N.; Aamodt, T.M. Modeling Deep Learning Accelerator Enabled GPUs. In Proceedings of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Madison, WI, USA, 24–26 March 2019; pp. 79–92. [Google Scholar]
- Dally, W.J.; Keckler, S.W.; Kirk, D.B. Evolution of the Graphics Processing Unit (GPU). IEEE Micro 2021, 41, 42–51. [Google Scholar] [CrossRef]
- Lee, W.K.; Seo, H.; Zhang, Z.; Hwang, S.O. TensorCrypto: High Throughput Acceleration of Lattice-Based Cryptography Using Tensor Core on GPU. IEEE Access 2022, 10, 20616–20632. [Google Scholar] [CrossRef]
- Groth, S.; Teich, J.; Hannig, F. Efficient Application of Tensor Core Units for Convolving Images. In Proceedings of the 24th International Workshop on Software and Compilers for Embedded Systems, Eindhoven, The Netherlands, 1–2 November 2021. [Google Scholar]
- Oakden, T.; Kavakli, M. Graphics Processing in Virtual Production. In Proceedings of the 2022 14th International Conference on Computer and Automation Engineering (ICCAE), Brisbane, Australia, 25–27 March 2022; pp. 61–64. [Google Scholar]
- Gati, N.J.; Yang, L.T.; Feng, J.; Mo, Y.; Alazab, M. Differentially Private Tensor Train Deep Computation for Internet of Multimedia Things. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–20. [Google Scholar] [CrossRef]
- Fu, C.; Yang, Z.; Liu, X.Y.; Yang, J.; Walid, A.; Yang, L.T. Secure Tensor Decomposition for Heterogeneous Multimedia Data in Cloud Computing. IEEE Trans. Comput. Soc. Syst. 2020, 7, 247–260. [Google Scholar] [CrossRef]
- Wang, H.; Yang, W.; Hu, R.; Ouyang, R.; Li, K.; Li, K. A Novel Parallel Algorithm for Sparse Tensor Matrix Chain Multiplication via TCU-Acceleration. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 2419–2432. [Google Scholar] [CrossRef]
- Chen, H.; Ahmad, F.; Vorobyov, S.; Porikli, F. Tensor Decompositions in Wireless Communications and MIMO Radar. IEEE J. Sel. Top. Signal Process. 2021, 15, 438–453. [Google Scholar] [CrossRef]
- Xu, H.; Jiang, G.; Yu, M.; Zhu, Z.; Bai, Y.; Song, Y.; Sun, H. Tensor Product and Tensor-Singular Value Decomposition Based Multi-Exposure Fusion of Images. IEEE Trans. Multimed. 2022, 24, 3738–3753. [Google Scholar] [CrossRef]
- Cheng, M.; Jing, L.; Ng, M.K. A Weighted Tensor Factorization Method for Low-Rank Tensor Completion. In Proceedings of the 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 30–38. [Google Scholar] [CrossRef]
- Sofuoglu, S.E.; Aviyente, S. Graph Regularized Tensor Train Decomposition. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3912–3916. [Google Scholar] [CrossRef]
- Zeng, H.; Xue, J.; Luong, H.Q.; Philips, W. Multimodal Core Tensor Factorization and its Applications to Low-Rank Tensor Completion. IEEE Trans. Multimed. 2023, 25, 7010–7024. [Google Scholar] [CrossRef]
- Chen, L.; Liu, Y.; Zhu, C. Robust Tensor Principal Component Analysis in All Modes. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Chang, S.Y.; Wu, H.C.; Yan, K.; Chen, X.; Wu, Y. Novel Personalized Multimedia Recommendation Systems Using Tensor Singular-Value-Decomposition. In Proceedings of the 2023 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Beijing, China, 14–16 June 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Tan, J.; Li, Y. Multi-Purpose Oriented Single Nighttime Image Haze Removal Based on Unified Variational Retinex Model. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1643–1657. [Google Scholar] [CrossRef]
- Lee, A. Train Spotting: Startup Gets on Track with AI and NVIDIA Jetson to Ensure Safety, Cost Savings for Railways. 2022. Available online: https://resources.nvidia.com/en-us-jetson-success/rail-vision-startup-uses?lx=XRDs_y (accessed on 28 January 2024).
- ISO 26262; Road Vehicles—Functional Safety [Norm]. Available online: https://www.iso.org/standard/68387.html (accessed on 28 January 2024).
- Mariani, R. Driving toward a Safer Future: NVIDIA Achieves Safety Milestones with DRIVE Hyperion Autonomous Vehicle Platform. 2023. Available online: https://blogs.nvidia.com/blog/2023/04/20/nvidia-drive-safety-milestones/ (accessed on 28 January 2024).
- IEEE. The International Roadmap for Devices and Systems: 2022; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2022. [Google Scholar]
- Strojwas, A.J.; Doong, K.; Ciplickas, D. Yield and Reliability Challenges at 7 nm and Below. In Proceedings of the 2019 Electron Devices Technology and Manufacturing Conference (EDTM), Singapore, 12–15 March 2019; pp. 179–181. [Google Scholar]
- Libano, F.; Rech, P.; Brunhaver, J. On the Reliability of Xilinx’s Deep Processing Unit and Systolic Arrays for Matrix Multiplication. In Proceedings of the 2020 20th European Conference on Radiation and Its Effects on Components and Systems (RADECS), Virtual, 19–23 June 2020; pp. 1–5. [Google Scholar]
- Oml, P.; Netti, A.; Peng, Y.; Baldovin, A.; Paulitsch, M.; Espinosa, G.; Parra, J.; Hinz, G.; Knoll, A. HPC Hardware Design Reliability Benchmarking With HDFIT. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 995–1006. [Google Scholar]
- Rech, R.L.; Rech, P. Reliability of Google’s Tensor Processing Units for Embedded Applications. In Proceedings of the 2022 Design, Automation & Test in Europe Conference & Exhibition (DATE), Virtual, 14–23 March 2022; pp. 376–381. [Google Scholar]
- He, Y.; Hutton, M.; Chan, S.; De Gruijl, R.; Govindaraju, R.; Patil, N.; Li, Y. Understanding and Mitigating Hardware Failures in Deep Learning Training Systems. In Proceedings of the 50th Annual International Symposium on Computer Architecture ISCA ’23, New York, NY, USA, 17–21 June 2023. [Google Scholar] [CrossRef]
- Basso, P.M.; dos Santos, F.F.; Rech, P. Impact of Tensor Cores and Mixed Precision on the Reliability of Matrix Multiplication in GPUs. IEEE Trans. Nucl. Sci. 2020, 67, 1560–1565. [Google Scholar] [CrossRef]
- Kundu, S.; Basu, K.; Sadi, M.; Titirsha, T.; Song, S.; Das, A.; Guin, U. Special Session: Reliability Analysis for AI/ML Hardware. In Proceedings of the 2021 IEEE 39th VLSI Test Symposium (VTS), San Diego, CA, USA, 25–28 April 2021; pp. 1–10. [Google Scholar]
- Ozen, E.; Orailoglu, A. Architecting Decentralization and Customizability in DNN Accelerators for Hardware Defect Adaptation. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2022, 41, 3934–3945. [Google Scholar] [CrossRef]
- Chaudhuri, A.; Talukdar, J.; Chakrabarty, K. Special Session: Fault Criticality Assessment in AI Accelerators. In Proceedings of the 2022 IEEE 40th VLSI Test Symposium (VTS), San Diego, CA, USA, 25–27 April 2022; pp. 1–4. [Google Scholar]
- Agarwal, U.K.; Chan, A.; Asgari, A.; Pattabiraman, K. Towards Reliability Assessment of Systolic Arrays against Stuck-at Faults. In Proceedings of the 2023 53rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks—Supplemental Volume (DSN-S), Porto, Portugal, 27–30 June 2023; pp. 230–236. [Google Scholar] [CrossRef]
- Tan, J.; Wang, Q.; Yan, K.; Wei, X.; Fu, X. Saca-FI: A microarchitecture-level fault injection framework for reliability analysis of systolic array based CNN accelerator. Future Gener. Comput. Syst. 2023, 147, 251–264. [Google Scholar] [CrossRef]
- Stoyanov, M.; Webster, C. Quantifying the Impact of Single Bit Flips on Floating Point Arithmetic; Technical Report; Oak Ridge National Laboratory, Department of Computer Science, North Carolina State University: Oak Ridge, TN, USA, 2013. [Google Scholar]
- Fu, H.; Mencer, O.; Luk, W. Comparing floating-point and logarithmic number representations for reconfigurable acceleration. In Proceedings of the IEEE International Conference on Field Programmable Technology, Bangkok, Thailand, 13–15 December 2006; pp. 337–340. [Google Scholar]
- Haselman, M.; Beauchamp, M.; Wood, A.; Hauck, S.; Underwood, K.; Hemmert, K.S. A comparison of floating point and logarithmic number systems for FPGAs. In Proceedings of the 13th Annual IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM’05), Napa, CA, USA, 18–20 April 2005; pp. 181–190. [Google Scholar]
- Chugh, M.; Parhami, B. Logarithmic arithmetic as an alternative to floating-point: A review. In Proceedings of the 2013 Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 3–6 November 2013; pp. 1139–1143. [Google Scholar]
- Barrois, B.; Sentieys, O. Customizing fixed-point and floating-point arithmetic—A case study in K-means clustering. In Proceedings of the IEEE International Workshop on Signal Processing Systems (SiPS), Lorient, France, 3–5 October 2017; pp. 1–6. [Google Scholar]
- Gohil, V.; Walia, S.; Mekie, J.; Awasthi, M. Fixed-Posit: A Floating-Point Representation for Error-Resilient Applications. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 3341–3345. [Google Scholar] [CrossRef]
- Schlueter, B.; Calhoun, J.; Poulos, A. Evaluating the Resiliency of Posits for Scientific Computing. In Proceedings of the SC ’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, Denver, CO, USA, 12–17 November 2023; pp. 477–487. [Google Scholar]
- Fatemi Langroudi, S.H.; Pandit, T.; Kudithipudi, D. Deep Learning Inference on Embedded Devices: Fixed-Point vs Posit. In Proceedings of the 1st Workshop on Energy Efficient Machine Learning and Cognitive Computing for Embedded Applications (EMC2), Williamsburg, VA, USA, 25 March 2018; pp. 19–23. [Google Scholar]
- Alouani, I.; Khalifa, A.B.; Merchant, F.; Leupers, R. An Investigation on Inherent Robustness of Posit Data Representation. In Proceedings of the 34th International Conference on VLSI Design and 20th International Conference on Embedded Systems (VLSID), Guwahati, India, 20–24 February 2021; pp. 276–281. [Google Scholar]
- Sierra, R.L.; Guerrero-Balaguera, J.D.; Condia, J.E.R.; Reorda, M.S. Analyzing the Impact of Different Real Number Formats on the Structural Reliability of TCUs in GPUs. In Proceedings of the 2023 IFIP/IEEE 31st International Conference on Very Large Scale Integration (VLSI-SoC), Dubai, United Arab Emirates, 16–18 October 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Limas Sierra, R.; Guerrero-Balaguera, J.D.; Condia, J.E.R.; Sonza Reorda, M. PyOpenTCU. 2023. Available online: https://github.com/TheColombianTeam/PyOpenTCU.git (accessed on 12 December 2023).
- Boswell, B.R.; Siu, M.Y.; Choquette, J.H.; Alben, J.M.; Oberman, S. Generalized Acceleration of Matrix Multiply Accumulate Operations. U.S. Patent 10,338,919, 2 July 2019. [Google Scholar]
- Gebhart, M.; Johnson, D.R.; Tarjan, D.; Keckler, S.W.; Dally, W.J.; Lindholm, E.; Skadron, K. Energy-efficient mechanisms for managing thread context in throughput processors. In Proceedings of the 38th Annual International Symposium on Computer Architecture (ISCA), San Jose, CA, USA, 4–8 June 2011; pp. 235–246. [Google Scholar]
- Huang, J.; Yu, C.D.; van de Geijn, R.A. Implementing Strassen’s Algorithm with CUTLASS on NVIDIA Volta GPUs. arXiv 2018, arXiv:1808.07984. [Google Scholar]
- IEEE Std 754-2019 (Revision of IEEE 754-2008); IEEE Standard for Floating-Point Arithmetic. IEEE: Piscataway, NJ, USA, 2019; pp. 1–84. [CrossRef]
- Gustafson, J.L.; Yonemoto, I. Beating Floating Point at Its Own Game: Posit Arithmetic. Supercomput. Front. Innov. Int. J. 2017, 4, 71–86. [Google Scholar]
- Lindstrom, P.; Lloyd, S.; Hittinger, J. Universal Coding of the Reals: Alternatives to IEEE Floating Point. In Proceedings of the Conference for Next Generation Arithmetic CoNGA ’18, New York, NY, USA, 15–18 July 2018. [Google Scholar] [CrossRef]
- Mallasén, D.; Barrio, A.A.D.; Prieto-Matias, M. Big-PERCIVAL: Exploring the Native Use of 64-Bit Posit Arithmetic in Scientific Computing. arXiv 2023, arXiv:2305.06946. [Google Scholar]
- Mishra, S.M.; Tiwari, A.; Shekhawat, H.S.; Guha, P.; Trivedi, G.; Jan, P.; Nemec, Z. Comparison of Floating-point Representations for the Efficient Implementation of Machine Learning Algorithms. In Proceedings of the 2022 32nd International Conference Radioelektronika (RADIOELEKTRONIKA), Kosice, Slovakia, 21–22 April 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Murillo, R.; Del Barrio, A.A.; Botella, G. Customized Posit Adders and Multipliers using the FloPoCo Core Generator. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Gil, P.; Blanc, S.; Serrano, J.J. Book Chap. Pin-Level Hardware Fault Injection Techniques. In Fault Injection Techniques and Tools for Embedded Systems Reliability Evaluation; Benso, A., Prinetto, P., Eds.; Springer Science & Business Media: Berlin, Germany, 2003; pp. 63–79. ISBN 978-0-306-48711-8. [Google Scholar]
- Jenn, E.; Arlat, J.; Rimén, M.; Ohlsson, J.; Karlsson, J. Fault Injection into VHDL Models: The MEFISTO Tool. In Proceedings of the Predictably Dependable Computing Systems, Austin, TX, USA, 15–17 July 1995; Randell, B., Laprie, J.C., Kopetz, H., Littlewood, B., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 329–346. [Google Scholar]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight Uncertainty in Neural Network. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Bach, F., Blei, D., Eds.; JMLR W&CP: Atlanta, GA, USA, 2015; Volume 37, pp. 1613–1622. [Google Scholar]
- Češka, M.; Matyáš, J.; Mrazek, V.; Vojnar, T. Designing Approximate Arithmetic Circuits with Combined Error Constraints. arXiv 2022, arXiv:2206.13077. [Google Scholar]
- Previlon, F.G.; Kalra, C.; Kaeli, D.R.; Rech, P. A Comprehensive Evaluation of the Effects of Input Data on the Resilience of GPU Applications. In Proceedings of the 2019 IEEE International Symposium on Defect and Fault Tolerance in VLSI and Nanotechnology Systems (DFT), Noordwijk, The Netherlands, 2–4 October 2019. [Google Scholar]
- Zhang, Z.; Wang, Z.; Gu, X.; Chakrabarty, K. Physical-Defect Modeling and Optimization for Fault-Insertion Test. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2012, 20, 723–736. [Google Scholar] [CrossRef]
- Su, F.; Liu, C.; Stratigopoulos, H.G. Testability and Dependability of AI Hardware: Survey, Trends, Challenges, and Perspectives. IEEE Des. Test 2023, 40, 8–58. [Google Scholar] [CrossRef]
- Jiang, H.; Santiago, F.J.H.; Mo, H.; Liu, L.; Han, J. Approximate Arithmetic Circuits: A Survey, Characterization, and Recent Applications. Proc. IEEE 2020, 108, 2108–2135. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Limas Sierra, R.; Guerrero-Balaguera, J.-D.; Condia, J.E.R.; Sonza Reorda, M. Exploring Hardware Fault Impacts on Different Real Number Representations of the Structural Resilience of TCUs in GPUs. Electronics 2024, 13, 578. https://doi.org/10.3390/electronics13030578
Limas Sierra R, Guerrero-Balaguera J-D, Condia JER, Sonza Reorda M. Exploring Hardware Fault Impacts on Different Real Number Representations of the Structural Resilience of TCUs in GPUs. Electronics. 2024; 13(3):578. https://doi.org/10.3390/electronics13030578
Chicago/Turabian StyleLimas Sierra, Robert, Juan-David Guerrero-Balaguera, Josie E. Rodriguez Condia, and Matteo Sonza Reorda. 2024. "Exploring Hardware Fault Impacts on Different Real Number Representations of the Structural Resilience of TCUs in GPUs" Electronics 13, no. 3: 578. https://doi.org/10.3390/electronics13030578
APA StyleLimas Sierra, R., Guerrero-Balaguera, J.-D., Condia, J. E. R., & Sonza Reorda, M. (2024). Exploring Hardware Fault Impacts on Different Real Number Representations of the Structural Resilience of TCUs in GPUs. Electronics, 13(3), 578. https://doi.org/10.3390/electronics13030578