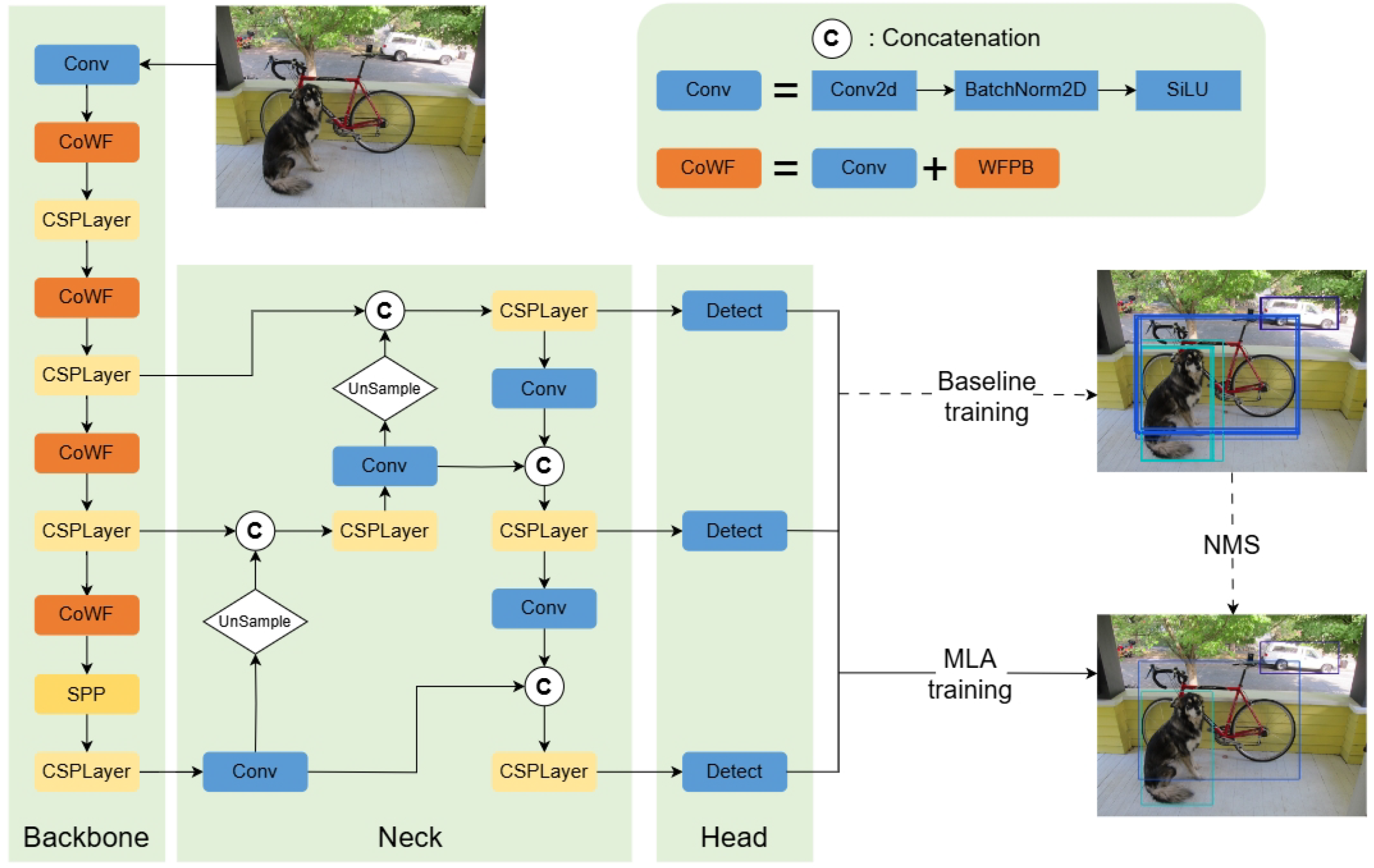
4.1. Applied Datasets
The public datasets PASCAL VOC [
34] and DUO dataset [
35] were chosen for model evaluation. The PASCAL Visual Object Classes is a world-class computer vision challenge that was proposed in 2005, which includes the task of object detection. It features a total of 20 detection categories: person, bird, cat, cow, dog, horse, sheep, aeroplane, bicycle, boat, bus, car, motorbike, train, bottle, chair, dining table, potted plant, sofa, and monitor. These categories encompass commonly seen objects in daily life, including people, animals, household items, and transportation vehicles. It provides a wealth of resources for the development of object detection. This paper uses the 2012 training and validation set, consisting of 11,540 images for training, and tests the results on the 2007 test set of 4952 images.
In contrast to VOC, the DUO dataset is an underwater object detection dataset. The DUO dataset was proposed by the Underwater Robot Professional Contest in 2021, aimed at robot picking based on underwater images. It contains about 6671 images in the training set and 1111 images in the testing set. The dataset includes four categories of underwater targets: holothurians, echinoderms, scallops, and starfish. These two datasets cover normal terrestrial scenes and underwater scenes, respectively. Achieving excellent results on both diverse datasets can better reflect the superiority of the method.
4.3. Evaluation Metrics
This paper uses mAP and Latency to measure model accuracy and speed. mAP represents the average accuracy of all classes, as described in Equation (
7). Latency refers to the time taken by the detector from receiving the image to producing the detection result. The calculation formula is as follows:
The number of correctly predicted positive samples is denoted as (True Positive), (False Positive) represents the incorrectly predicted positive samples, and (False Negative) represents the mistakenly predicted negative samples. Latency is the time required for the model’s forward propagation, plus the post-processing time, resulting in the total detection Latency. The combination of accuracy and speed can well reflect the superiority of detector performance.
4.4. Comparisons to State-of-the-Art
To prove the effectiveness and efficiency of the proposed method, several representative detectors were adopted for comparison on benchmark datasets, including Faster R-CNN [
20], Cascade R-CNN [
36], and RepPoints [
37] for two-stage detection; FCOS [
12], ATSS [
21], and GFL [
38] for one-stage detection; and YOLOv5 [
19] and YOLOv7 [
39] for real-time detection. All methods used the original settings and were trained from scratch with a resolution of 640 × 640.
Table 1 shows the experimental results of different methods on the DUO dataset. Using the COCO evaluation metrics [
40], in addition to the conventional Average Precision (AP) and AP at IoU threshold 0.5 (AP
), the evaluation metrics for the DUO dataset also included detection results for small, medium, and large objects (AP
, AP
, AP
), providing a more comprehensive comparison of the model’s performance in various aspects. It can be observed that our method significantly outperforms other benchmark networks. Compared to two-stage and one-stage networks, MA-YOLOX achieved better results with 66.0 mAP using fewer parameters; this is also attributed to YOLOX’s excellent design. However, compared to YOLOX, with an improvement of 1.7 mAP, our detector further enhanced detection performance, significantly outperforming other real-time detectors. Among the detection results for large, medium, and small objects, MA-YOLOX showed greater improvement in the more challenging medium and small targets, with a 3.3 increase for small objects and a 1.9 increase for medium objects, significantly enhancing the model’s ability to detect small objects.
We also compared the results of various real-time detectors YOLOv5, YOLOv7, and YOLOV8 [
41] on Pascal VOC, as shown in
Table 2. VOC was derived from various images in natural scenes and included many common categories from daily life, making the results more reflective of the detector’s performance in real-world scenarios. The best result is displayed in bold in the table; the detection results still outperformed other detectors. During the evaluation of the detector, NMS was not used, demonstrating the effectiveness of the mixed label assignment. Additionally,
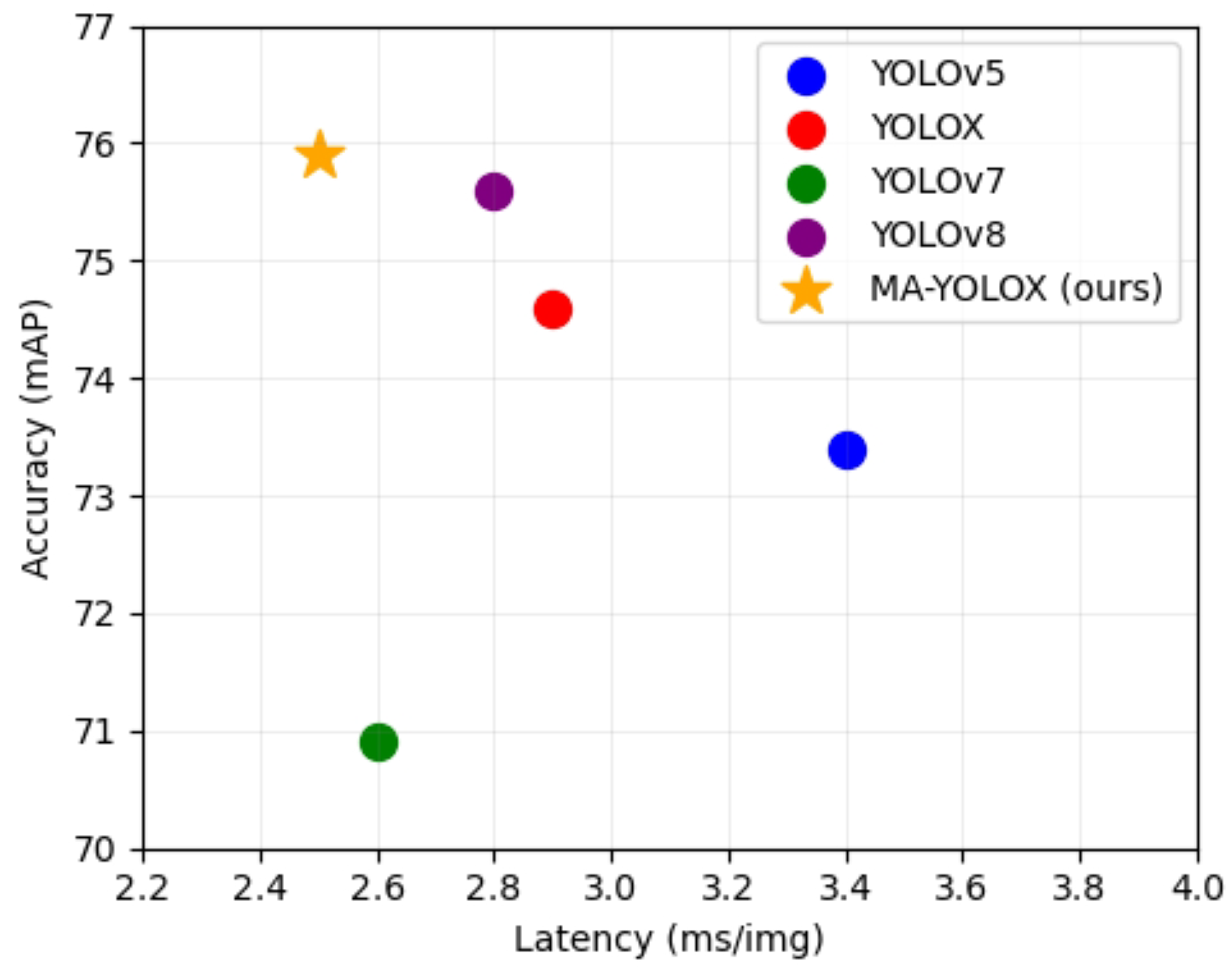
Table 2 also shows the inference speeds of various real-time detectors. To present the results more intuitively,
Figure 5 visualizes the detection results in terms of speed and accuracy. Although MA-YOLOX’s number of parameters or computational complexity was not the lowest, our method demonstrated a significant advantage in inference speed, achieving a detection speed of 2.5 ms per image. This speed improvement is attributed to the removal of NMS in the post-processing stage, which eliminates the additional computational overhead introduced by NMS. As a result, MA-YOLOX is faster than other real-time detectors. Specifically, compared to YOLOX, MA-YOLOX reduces post-processing time by 0.5 ms by removing NMS, increasing processing speed by 50%. In comparison, MA-YOLOX is also faster than the YOLOV5, YOLOV7, and YOLOV8 real-time detectors. This result further proves our core idea: removing NMS is not only theoretically feasible, but it also significantly optimizes inference speed in practical applications.
To illustrate the importance of NMS in the post-processing stage, we visualize the detection results of YOLOX with and without NMS and ours, as shown in
Figure 6. YOLOX and our detector can effectively detect objects in images; however, without NMS, YOLOX generates multiple predicted boxes for the same object, which affects detection performance. Especially in dense scenes, a large number of redundant boxes can obscure the original information in the image. For conventional detectors, NMS is particularly important. MA-YOLOX achieves the same results as Baseline that rely on NMS, even without using NMS. Extensive experiments have demonstrated the effectiveness and feasibility of the method.
4.5. Ablation Study on VOC
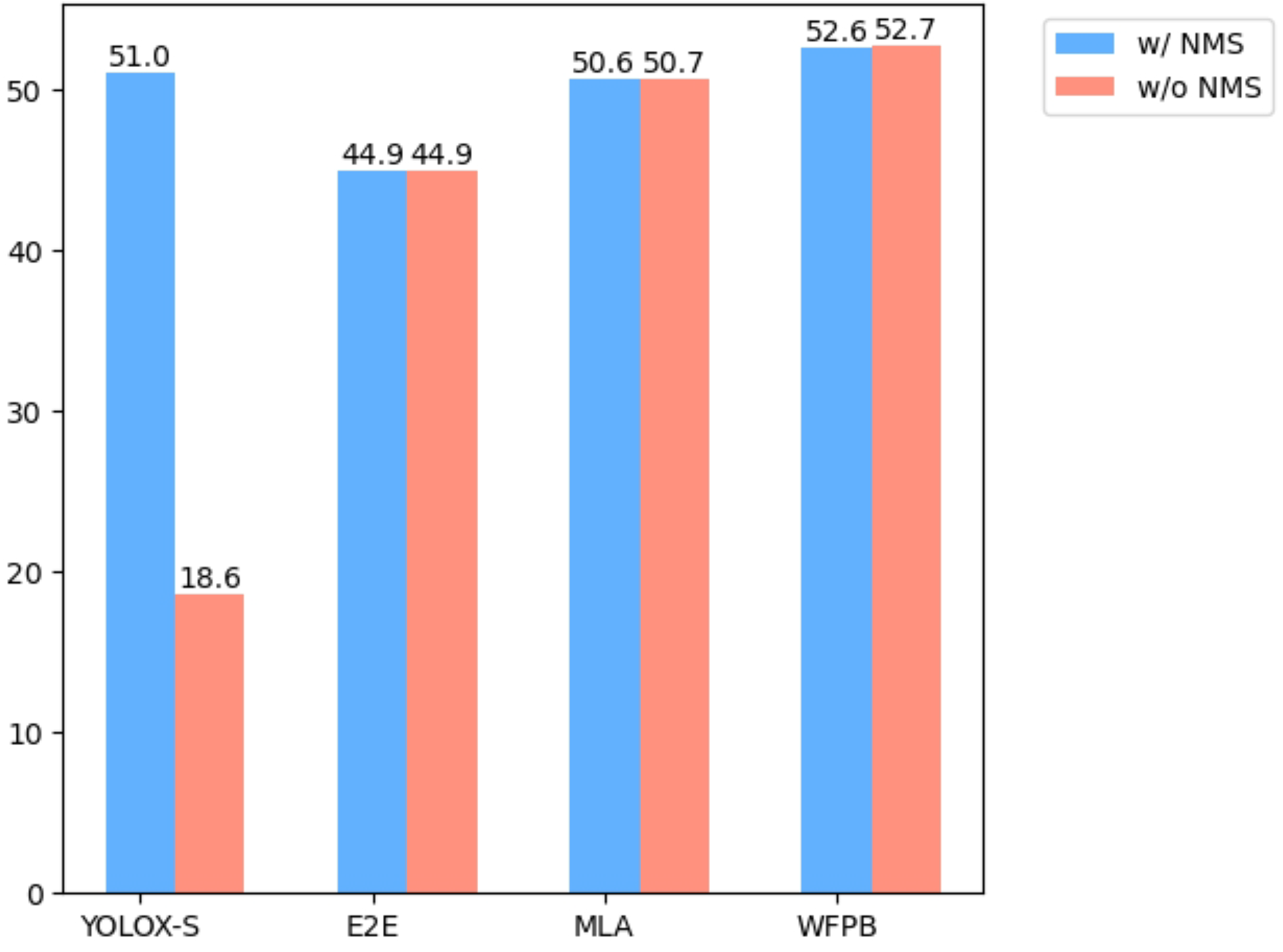
Table 3 shows the ablation results based on YOLOX-S, and
Figure 7 provides a more intuitive demonstration of the detector’s performance with and without NMS. It can be observed that the performance of conventional detectors significantly declined without NMS. Implementing end-to-end with one-to-one label assignment and the mixed label assignment allowed the model to operate without NMS in the post-processing stage, making the inference speed 0.5 ms faster than the Baseline. However, the one-to-one label assignment led to a significant decline in the model’s detection results, from 51.0 to 44.9 mAP. In contrast, the mixed label assignment improved performance by 5 AP compared to the one-to-one label assignment, reaching 50.6 mAP. Additionally, the window feature propagation block improved the performance by about 2.0 mAP based on the mixed label assignment, exceeding the Baseline. The increase in parameters and computational cost was only around 10%. Our method achieved a result of 52.6 AP and a Latency of 2.5 ms without NMS, improved the detection results by 1.6 AP, and increased the inference speed by 0.4 ms, outperforming the Baseline in both performance and speed. Moreover, without NMS, there was a slight improvement in detection results, indicating that NMS removed some more accurate predicted boxes, effectively proving the feasibility and effectiveness of this approach.
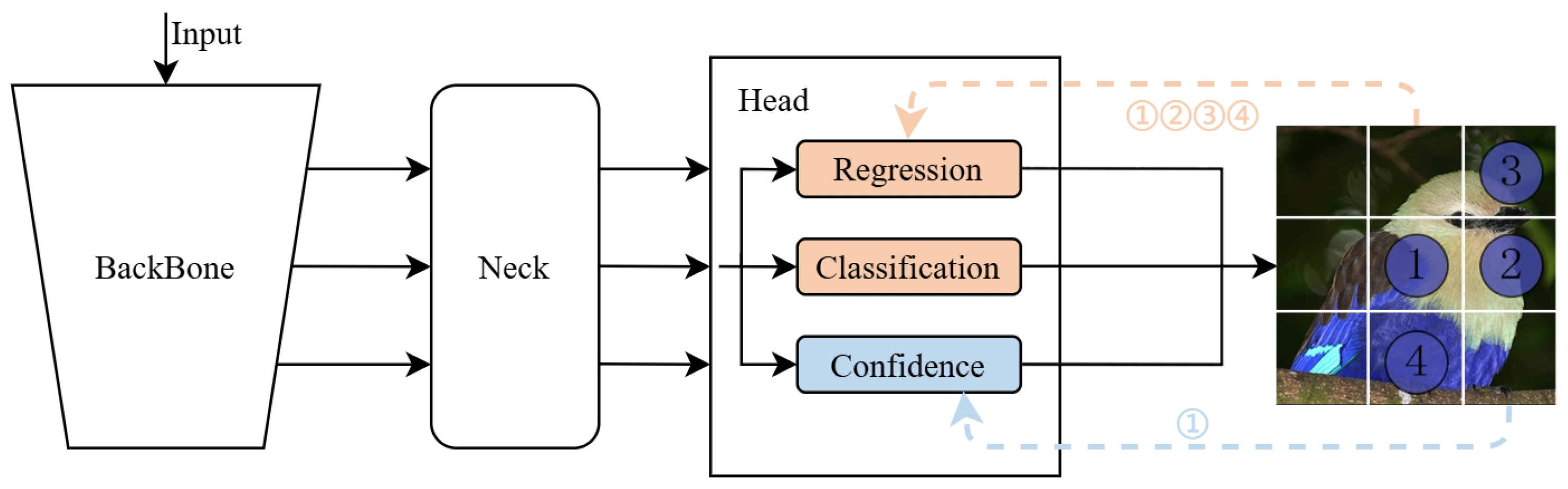
4.5.1. Analyses for Mixed Label Assignment
The training strategy for mixed label assignment involves both one-to-one and one-to-many dual-label assignment, where one key aspect is how to allocate positive and negative samples. Choosing the right positive and negative samples is crucial for model training. As shown in Equation (
1), the hyperparameter
in the matching cost controls the importance ratio between classification and regression. Different values of
lead to the model optimizing different positive samples during the training, which impacts the model’s performance.
Table 4 presents the model training results under various hyperparameters, with
= 5 achieving the best detection results. When
is either too high or too low, it has a certain effect on model training, with
= 1 reaching the worst results. This indicates that during the assignment process, more consideration should be given to the location of the predicted boxes. However, if
is too high, ignoring the importance of classification negatively affects the model’s performance.
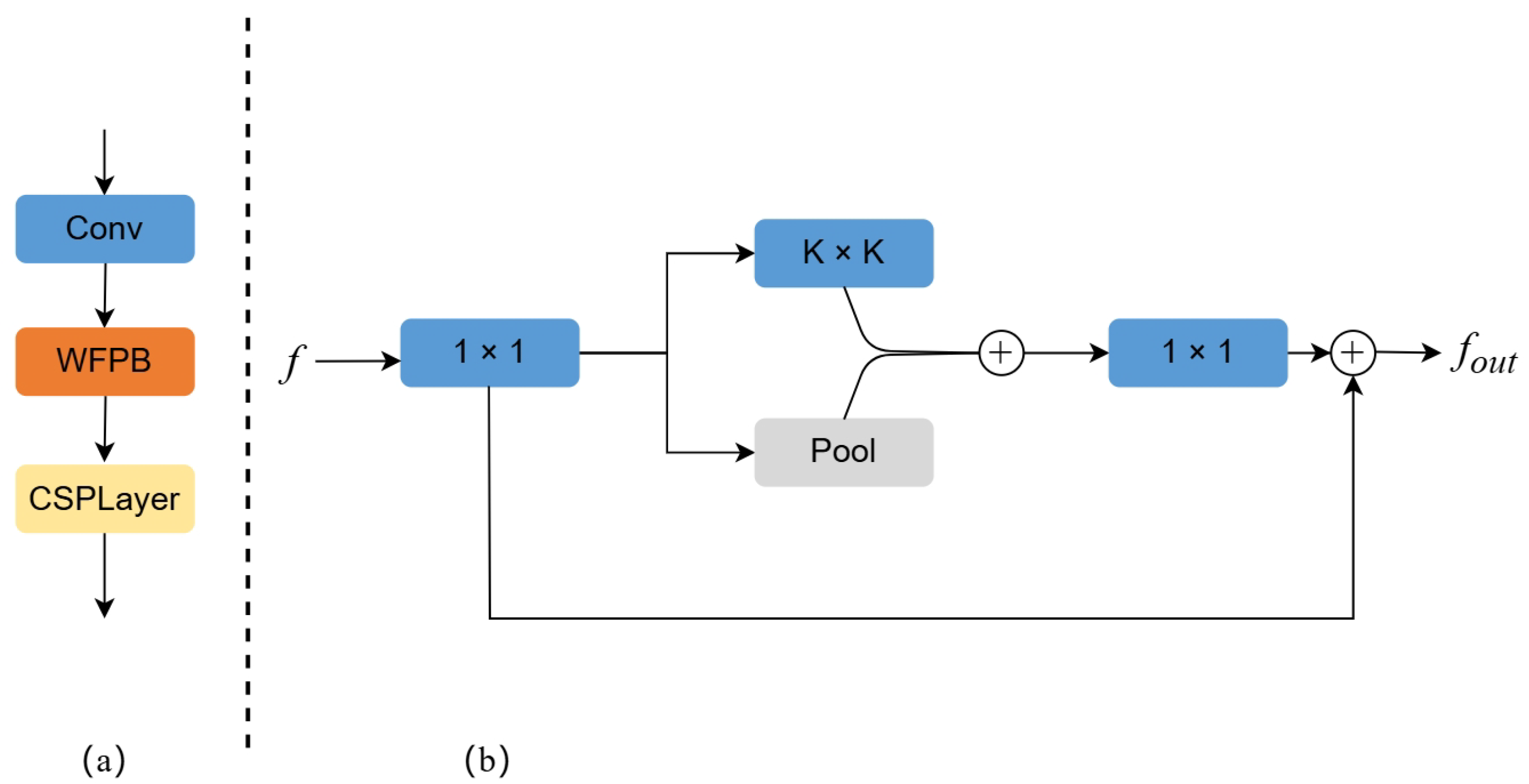
4.5.2. Analyses for Window Feature Propagation Block
The structure of the window feature propagation block is shown in
Figure 4. The parameter K determined the window size for feature propagation, and we tested the model’s performance for K = 1, 3, 5, 7, as shown in
Table 5. It can be observed that the performance for K = 3, 5, 7 was significantly better than for K = 1, demonstrating the feasibility of the window feature propagation block. However, as the window size K increased, the parameters and computational cost also increased significantly, and we found that the model performance improved slowly. This indicates that some redundant features are captured as the window expands. The best result was obtained when K = 7, but the number of parameters increased too much, leading to the final decision of setting the window size K to 3.
Additionally, to demonstrate the superiority of the window feature propagation block, we compared the detection results of WFPB with other attention modules, CBAM [
42], CA [
43], and PSA [
44], under the same conditions, as shown in
Table 6. CBAM (Convolutional Block Attention Module) and CA (Channel Attention) both implement attention mechanisms through convolution in spatial and channel dimensions. In contrast, PSA (partial self-attention) is based on self-attention, making it suitable for image Attention mechanisms. WFPB achieved 53.7, clearly outperforming the other modules.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}