3.3. Deep Reinforcement Learning Models
In this study, the intersection signal control problem is formulated as a Markov Decision Process (MDP) [
42], where the key components—state space, action space, and reward function—are defined to guide the reinforcement learning process. Reinforcement learning is typically modeled using an MDP, which consists of the following elements:
A set of states, expressed as ;
A set of actions, expressed as ;
The conversion probability , which indicates the probability that the agent will transition from state to after taking action ;
The reward function
, which specifies the reward for taking action
in the
state. T the goal of reinforcement learning methods is to maximize the cumulative reward, i.e., Equation (1):
The discount factor , which reduces the value of future rewards.
The goal of the agent is to determine the optimal strategy to maximize the expected return, which can be determined using the following Equation (2):
The status, actions, and rewards of this article are set as follows.
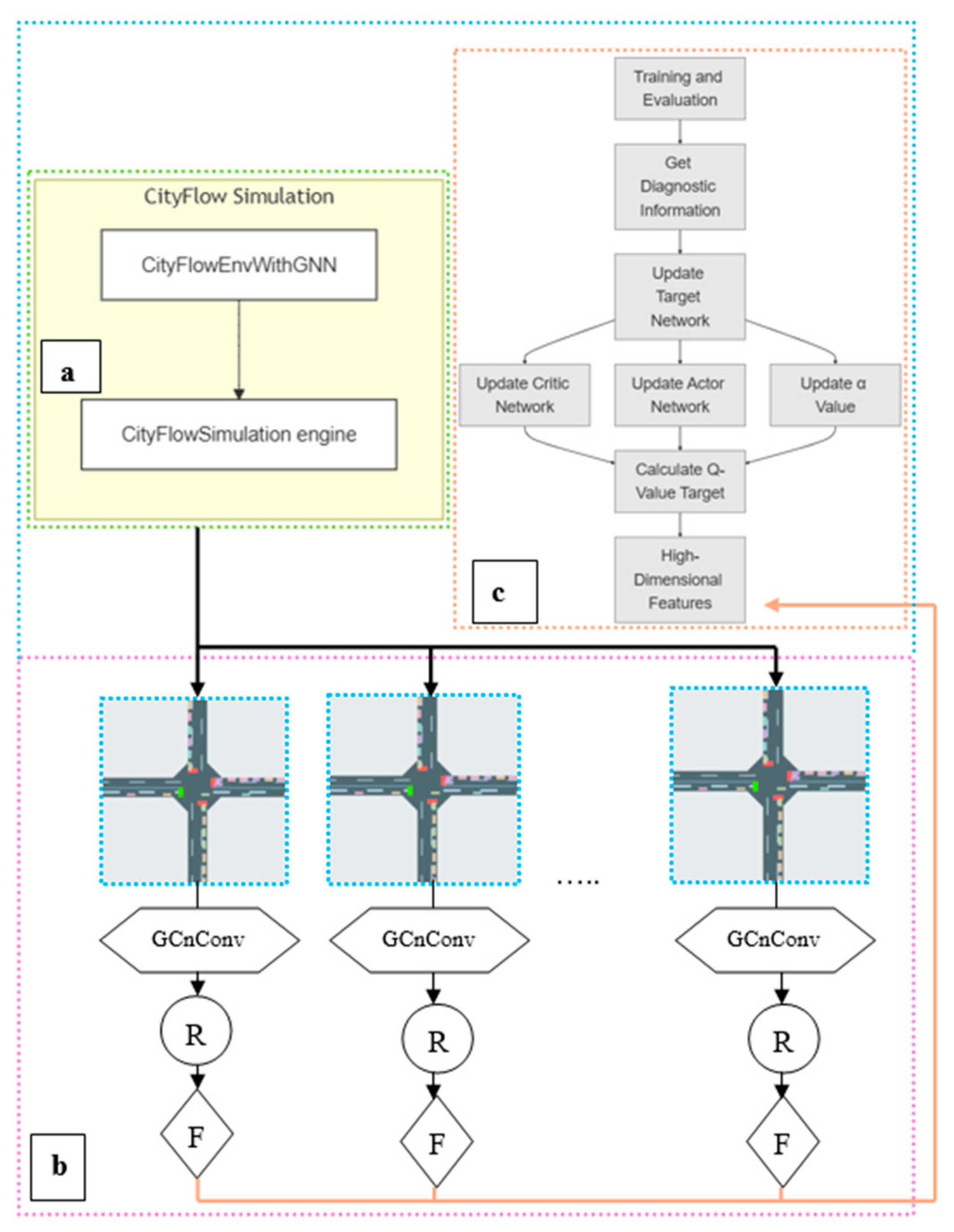
In our model, the state at each time step is defined as a combination of the queue length and vehicle speed at each intersection, along with those at neighboring intersections. These two metrics are crucial for assessing traffic congestion and flow. Queue length represents the number of vehicles in each lane and serves as a direct indicator of congestion. Speed reflects the average speed of vehicles in each lane and indicates the smoothness of traffic flow. To obtain this state information, vehicle counts and average speeds are first extracted from the traffic simulation environment. These features are then integrated with the graphical data obtained through the Graph Neural Network (GNN), forming a comprehensive state representation. This representation not only captures the traffic state of individual intersections; it also incorporates the conditions at surrounding intersections, enabling the optimization of the entire traffic network.
Figure 4 provides an example of this state representation. In this figure, each point represents a vehicle in the current lane, with the
x-axis showing the vehicle ID, the
y-axis indicating its position within the lane (in meters), and the
z-axis representing its speed (in meters per second). Different colors are used to denote the travel direction: red for north, blue for south, green for east, and yellow for west. The 3D scatter plot visualizes the distribution of vehicles in the lane and their speeds, showing traffic flow across different directions.
This figure illustrates how our model organizes and processes state data. By tracking vehicle locations and speeds in real time, the system can dynamically adjust traffic signals to improve flow and reduce congestion. The graphical representation also highlights the spatio-temporal relationships between intersections, which is essential for making informed decisions in adaptive traffic signal control. The final state representation example is shown in
Figure 4.
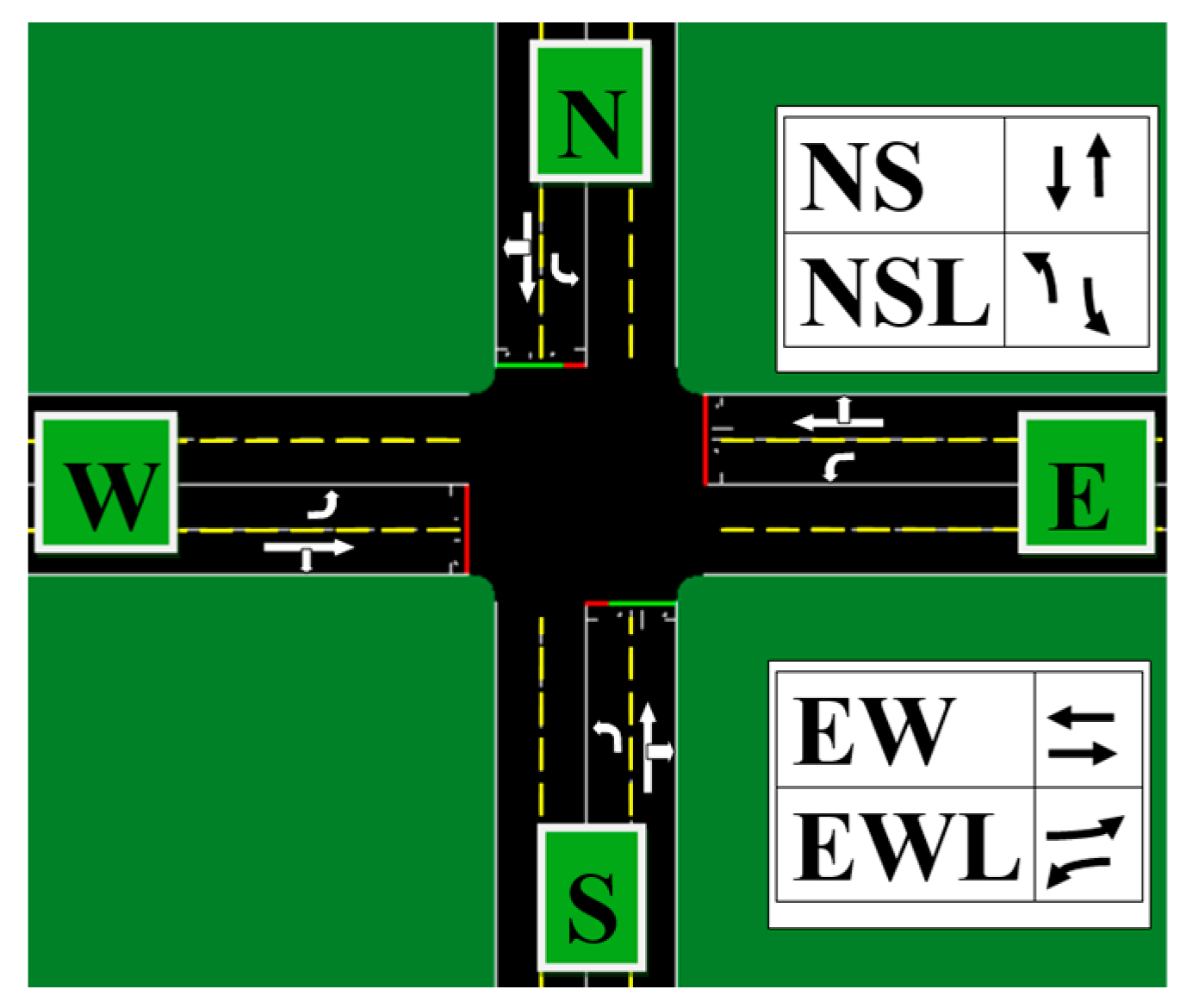
The action space in our model consists of two components: phase shifts and phase durations. Phase Shifts: Represent the change in signal phases, determining which lanes are open for passage at a given time. Phase Durations: Specify how long each phase remains active, controlling the duration of each traffic signal phase. At each time step, the environment updates the state of the traffic light based on a given phase transition and phase duration. An example of the action representation is shown in
Figure 5.
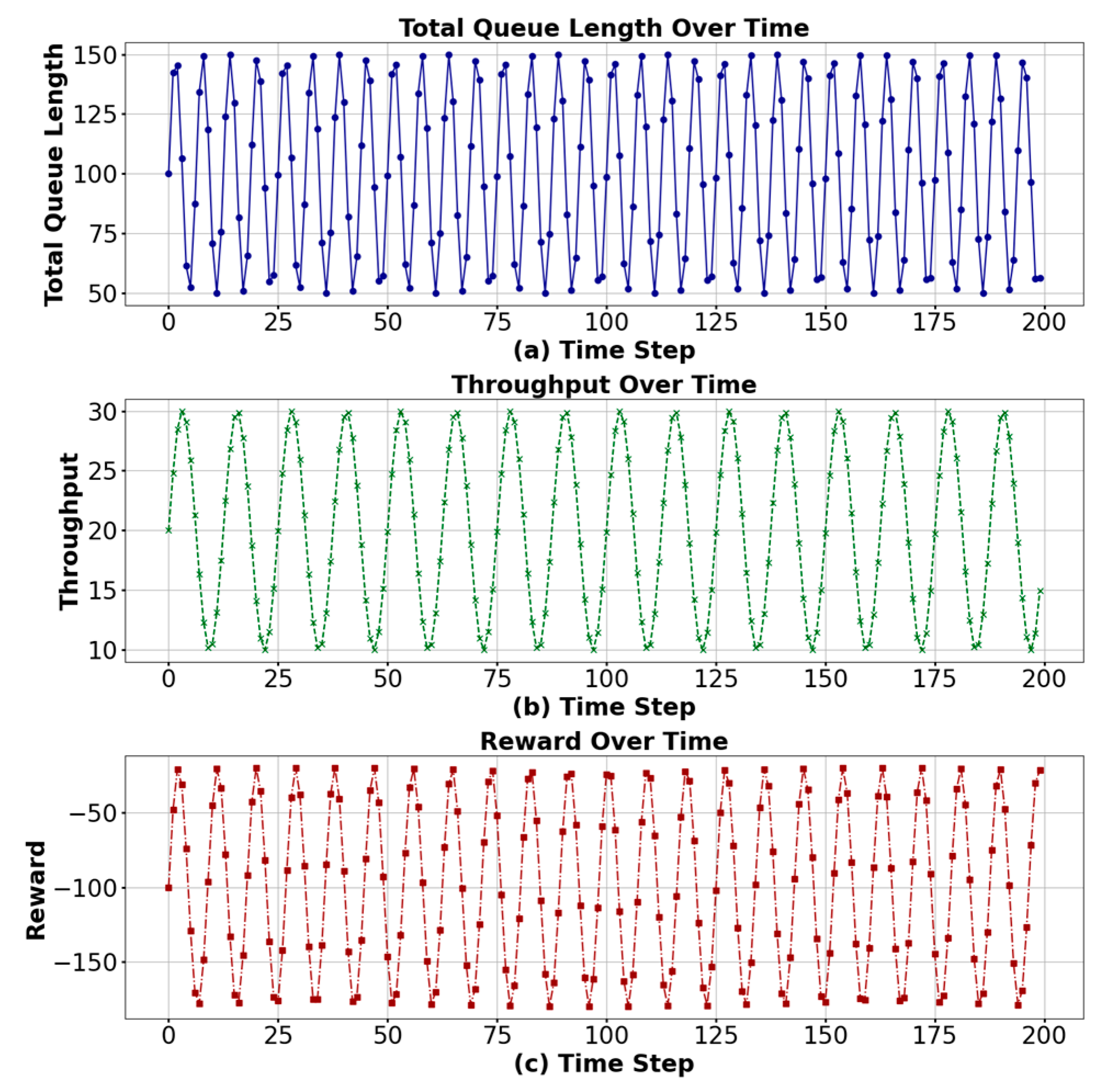
The reward function is designed to balance traffic congestion and traffic smoothness. It consists of two primary components. Negative Queue Length: A penalty that encourages the reduction of vehicles in each lane, aiming to alleviate congestion. An illustration of this penalty is shown in
Figure 6a. Throughput: A positive reward that encourages increasing the number of vehicles passing through the intersection, thus improving traffic flow. The throughput reward is shown in
Figure 6b. The combined reward is a weighted sum of these two components, with negative rewards for long queues and positive rewards for increased throughput. The overall reward function, combining both aspects, is shown in
Figure 6c. By using this reward function, the reinforcement learning agent is incentivized to optimize traffic flow by minimizing congestion while maximizing the throughput of vehicles through the intersection.
Through the above design, this study aims to use GNNs to extract high-dimensional features from complex transportation networks and combine queue length and speed information to form a comprehensive description of traffic status. At the same time, by defining a reasonable action space and reward function, our model can learn an effective traffic signal control strategy to optimize the urban traffic management system.
GNN plays a crucial role in our model. It extracts the complex relationship information between nodes through the convolution operation of the topology and node features of the transportation network. This allows our model to not only account for the local information of individual intersections, but also to capture the global dynamics of the entire transportation network. By combining queue length, velocity, phase conversion, phase duration, and reward functions based on queue length and throughput, our model is able to adaptively optimize signal control strategies in complex urban traffic environments, thereby significantly improving the efficiency of traffic flow and reducing traffic congestion.
For scenarios where the Markov decision process is completely known and its state–action space is limited, we can create a model of the environment in which we interact with the intelligences, called model-based reinforcement learning. However, in real-world TSC, it is challenging to fulfill these conditions, and, therefore, model-free reinforcement learning is more commonly applied in TSC [
43]. Model-free reinforcement learning can be further categorized into value-based approaches, policy-based approaches, and combinations of both (AC).
SAC [
44] is an offline policy AC algorithm based on a maximum entropy reinforcement learning framework. Contrary to other RL methods, participants in SAC attempt to maximize entropy while maximizing discounted cumulative rewards. The main idea behind SAC is to combine the off-policy updating from soft Q learning [
45] with the AC algorithm. In this way, SAC overcomes the problem of poor sampling efficiency. SAC achieves state-of-the-art performance on RL problems with continuous settings.
Regarding Soft Actor–Critic, SAC learns one policy and two Q-functions at the same time. There are two standard variants of SAC: one uses fixed entropy regularization coefficients, and the other enforces entropy constraints by varying during training. In this paper, we use the DESAC algorithm, which enforces the entropy constraint by varying the entropy regularization coefficients during training, i.e., the DESAC algorithm. The dynamic entropy constraint is a crucial component of our approach designed to balance exploration and exploitation in reinforcement learning. By dynamically adjusting policy randomness, this method enhances the model’s adaptability to different traffic environments. Specifically, in traffic signal control, dynamic entropy constraints enable the model to respond effectively to traffic fluctuations by regulating the probability of signal transitions. For instance, during periods of high traffic flow, the constraint reduces unnecessary signal changes, while in low traffic conditions, it promotes exploration to identify more efficient signal configurations. We implement this mechanism using the DESAC algorithm, which incorporates policy entropy as a guide for exploration. In train_sac, we set a target entropy value (target_entropy) and dynamically adjust the policy’s entropy during training. This dynamic adjustment ensures that the model can adapt its decision-making process to varying traffic conditions, optimizing signal control by reducing congestion during peak periods and enhancing flow during off-peak times. By combining GNN-based feature extraction with DESAC’s dynamic entropy regulation, our method achieves robust and efficient traffic signal control across diverse scenarios.
In the Entropy Regularized Reinforcement Learning (ERRL) setup, the goal is to maximize the weighted sum of the entropy of the reward and the strategy. This setup encourages exploration by increasing the entropy of the strategy so that the strategy is not overly deterministic, leading to better exploration of the state–action space.
The goal of entropy regularization can be expressed as optimizing the following objective function:
is the optimization target, the distribution of state actions caused by the strategy , is the immediate reward for taking action in state , is the entropy of the strategy in state , and is the entropy coefficient, weighing the weight of the immediate reward and the entropy of the strategy.
- 2.
Definition of entropy;
The goal of entropy regularization can be expressed as optimizing the following objective function:
- 3.
Target Q value calculation;
is rewards, is the discount factor, is the terminal sign, which indicates whether the termination state has been reached, is the Q value of the next state, when takes action , is the entropy scale, which controls the randomness of the strategy, and is the logarithmic probability of taking action in state .
- 4.
is the experience replay buffer. is the target Q-value. is the current Q value. This formula is in the form of the Mean Squared Error (MSE), which represents the loss function of the Q-valued network.
- 5.
Policy updates:
The goal of the policy update is to minimize the following loss functions:
is the logarithmic probability of taking action in state , and is the Q value of the action pair in the current state.
- 6.
Entropy coefficient updated:
The update goal of the entropy coefficient is to minimize the following loss functions:
is the target entropy (adjusted for the environment).
- 7.
The state value function:
In the DESAC algorithm, the state value function
is indirectly represented by the following relationship:
This formula is actually embodied in the policy update process. Specifically, the DESAC algorithm uses a soft Q function that combines the value of the action and the logarithmic probability of the strategy, thus being equivalent to the state value function to a certain extent.
In the strategy update, the part of the loss function of Equation (7) can be seen as a manifestation of the state value , because it adjusts to take into account both the action value and the entropy of the strategy. Specifically, Equation (7) shows that the state value function is expressed indirectly by the action value function and the entropy of the strategy (i.e., the logarithmic probability of the action). This approach allows the DESAC algorithm to effectively exploit the randomness of the strategy to explore and learn, resulting in better performance. Therefore, although the state value function is not directly defined in the DESAC algorithm, it is indirectly represented by the soft Q function in the policy update.
The state value function
considering entropy regularization is defined as
is the value in state , is the value of the action taken in state , and is the entropy term that is used to encourage the randomness of the strategy.
- 8.
Action value function.
Combined with entropy regularization, the action value function is defined as
is the immediate reward, is the discount factor, and is the next state.
The DESAC algorithm pseudocode is shown in Algorithm 1. The G-DESAC model diagram is shown in
Figure 7.
| Algorithm 1: DESAC |
| Input: | Policy network , two Q networks , , target Q networks , , Replay buffer D, entropy coefficient α |
| Set hyperparameters: discount factor γ, target update coefficient τ, target entropy H; |
| Initialize α optimizer (for entropy-constrained SAC); |
| repeat |
| Sample an action a from the environment using and store () in D; |
| Sample a batch () from D; |
| Q-Target Calculation: Sample next action and log probability ; |
| Compute |
| ; |
| Q-Value Update: Compute current Q-values and ; |
| Compute Q loss: |
| |
| Update Q networks and using gradient descent; |
| Policy Update: For each state s in batch, sample action ; |
| Compute policy loss: |
| |
| Update policy network using gradient ascent; |
| Entropy Coefficient Update (for entropy-constrained SAC): Compute entropy loss: |
| |
| Update entropy coefficient α; |
| Soft Update of Target Q Networks: Update target Q networks: |
| |
| until; |
| Return (for debugging and monitoring); |
3.4. Deep Neural Networks
In the proposed algorithm, three main deep neural network models are involved: GNN-Feature-Extractor, Policy-Network, and Q-Network. They are used for feature extraction, policy generation, and value evaluation, respectively.
- 1.
GNN-Feature-Extractor;
Input Layer: The connection relationship A between the receiving node feature X and the edge.
The first layer of the graph convolutional layer: the input dimension input-dim is converted to the hidden layer dimension hidden-dim:
where
is the adjacency matrix,
is the input feature matrix, and
is the weight matrix of the first layer, and the activation function
applies nonlinear activation.
The second layer of the graph convolutional layer converts the hidden layer dimension hidden-dim to the output layer dimension:
where
is the weight matrix of the second layer.
Output Layer: The output graph feature represents .
GNN-Feature-Extractor is used to extract features from the graph data of the transportation network, capturing the relationship between nodes and edges through graph convolution operations. These characteristics are used as input to subsequent networks (policy networks and Q-networks).
- 2.
Policy-Network:
Input Layer: Receives the environmental state feature .
The first fully connected layer contains 128 neurons, and the activation function is
.
where
is the bias vector of the first fully connected layer.
The second fully connected layer contains 128 neurons and has an activation function of
.
where
is the bias vector of the second fully connected layer.
Output layer: The output is the size of the action space, which represents the probability distribution of each action
. This layer uses the
function to normalize the output so that the sum of the probabilities of all actions is 1.
where
is a normalization function that converts multiple values of the output into a probability distribution, and
is the bias vector of the output layer.
Policy-Network is used to generate action policies. Given the environmental state feature , the network outputs a probability distribution of each possible action , and the policy network samples action based on this distribution.
- 3.
Q-Network.
Input layer: Receives the environment state and the action feature .
The first fully connected layer contains 128 neurons with an activation function of
.
The second fully connected layer contains 128 neurons, and the activation function is
.
Output Layer: The output is a single Q value
, which represents the value of the state–action pair.
Q-Network is used to evaluate the value of state–action pairs. Given the environment state and the action , the network outputs the corresponding Q value , which is used to estimate the return of taking that action in that state. Together, these deep neural network models form the core components of the algorithm, handling tasks like feature extraction, policy generation, and value evaluation, respectively. The specific process is as follows.
Feature Extraction: Use GNN-Feature-Extractor to extract features of nodes and edges from the graph data of the transportation network. These features capture the relationships between nodes (junctions) and edges (roads) in a transportation network. The formula is as follows:
where
is the result of feature extraction, which represents the features of nodes and edges extracted from the transportation network,
represents the node information in the transportation network, and
represents the edge information in the transportation network.
Policy generation: The extracted feature
is passed to Policy-Network as input. The policy network processes the input features and outputs the probability distribution
of each possible action. According to the probability distribution, the strategy network samples and selects the optimal action
. The formula is as follows:
where
represents the output of the policy network and the probability distribution of possible actions and
represents the actions sampled according to the probability distribution
.
Valuation: The current state and selected actions are passed as input to Q-Network. The Q-network processes the input and outputs the corresponding Q value. The Q value is used to estimate the expected return for taking that action in the current state. The formula is as follows:
where
denotes the
Q value, the expected return for performing action
in state
.
Algorithm training: During the training process, the algorithm continuously uses the above network for feature extraction, policy generation, and value evaluation. Through the deep reinforcement learning method DESAC, the policy network and the Q-network are optimized so that the policy network can choose the actions that can maximize the cumulative return.





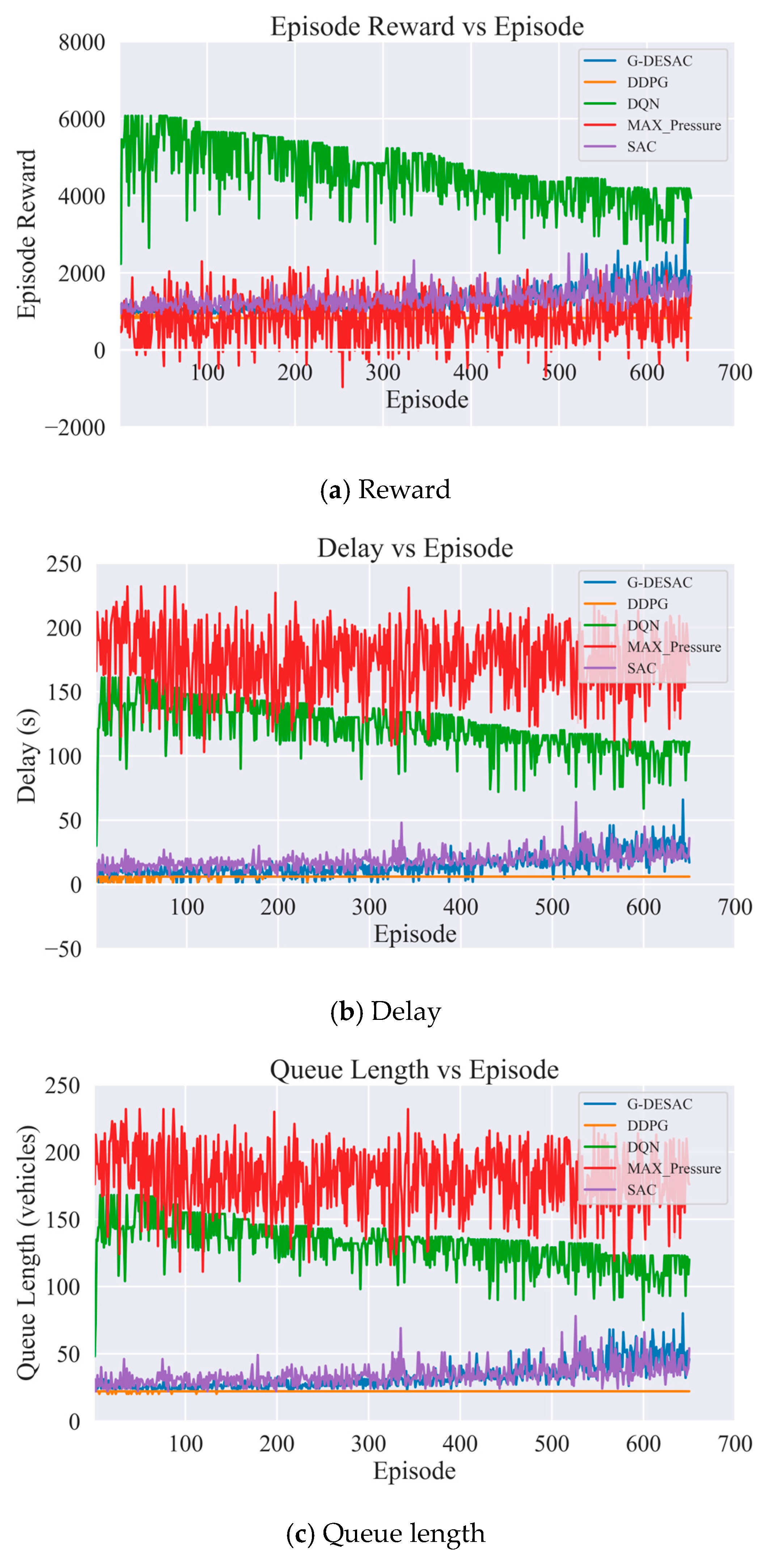
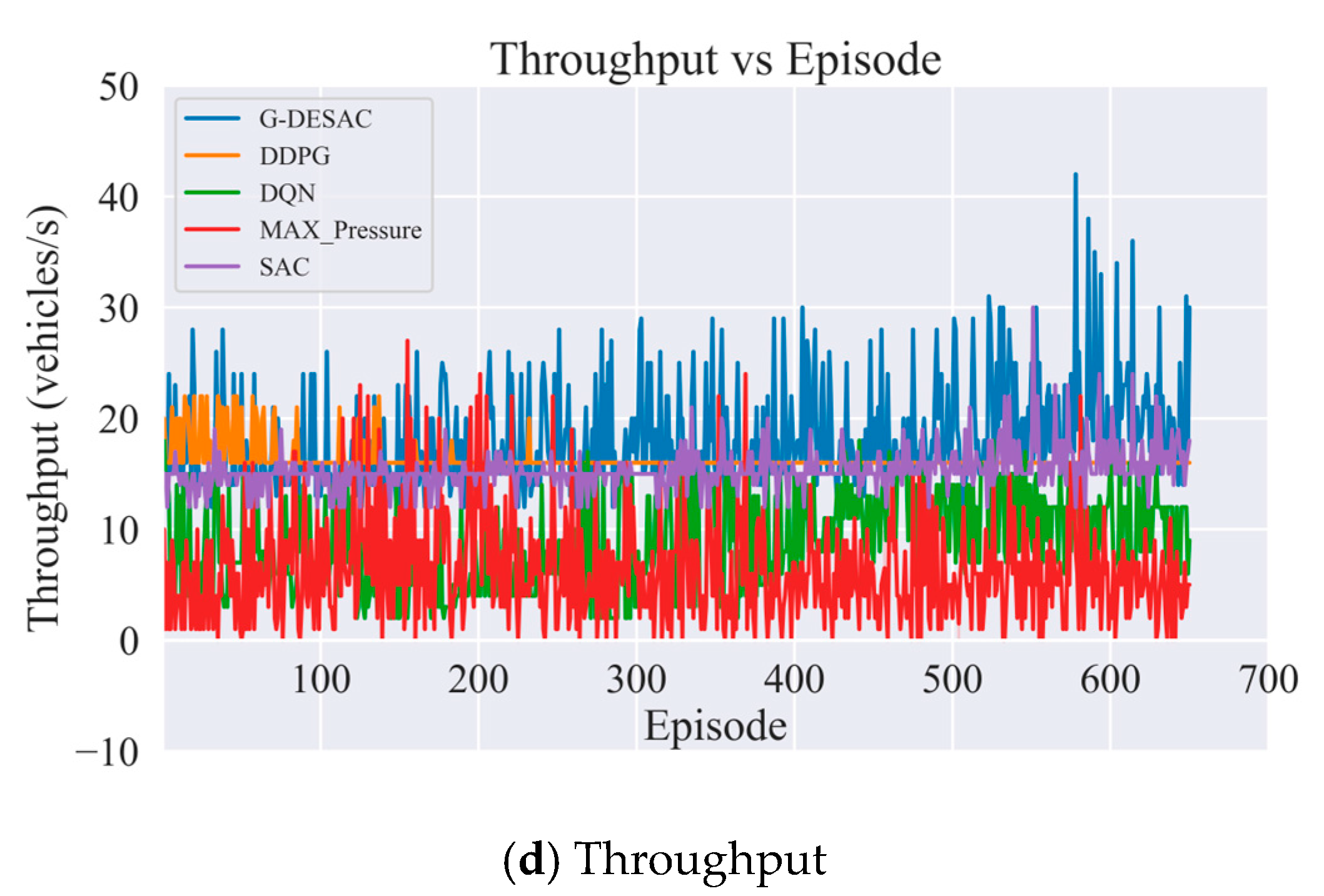

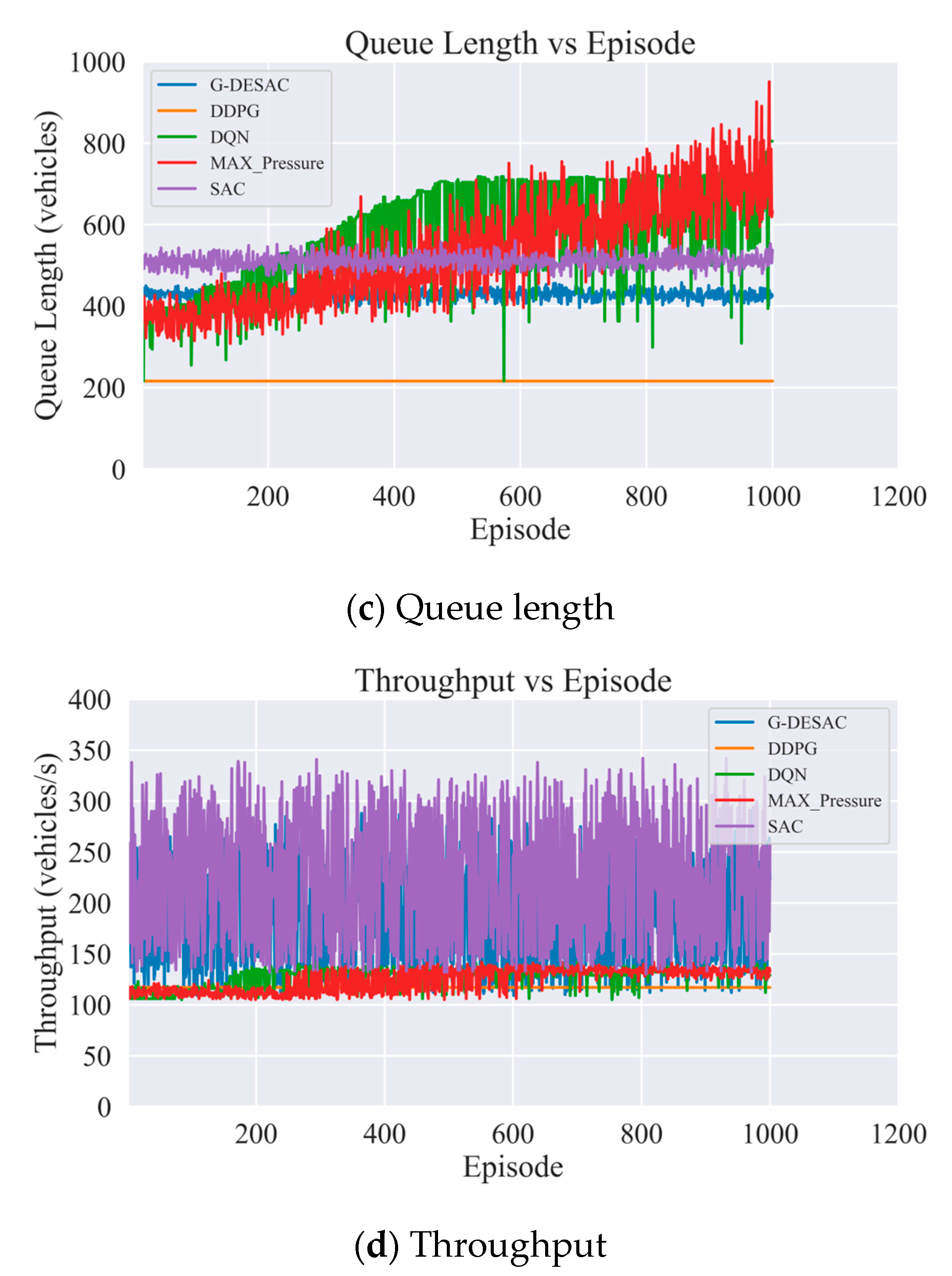
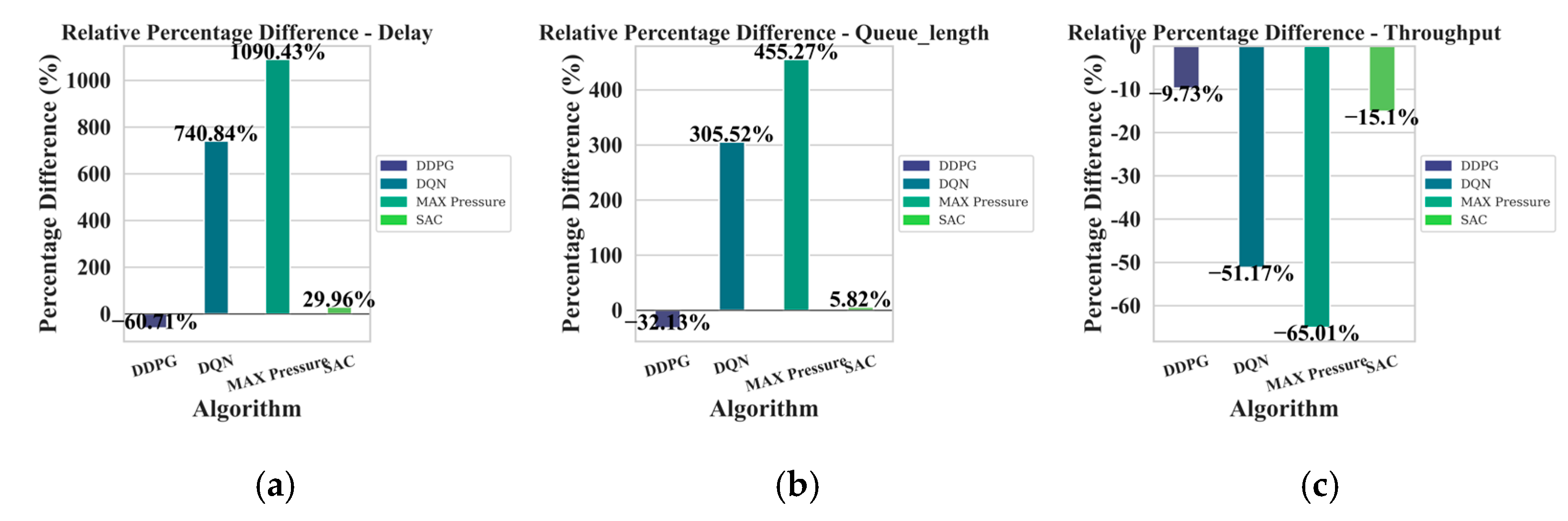
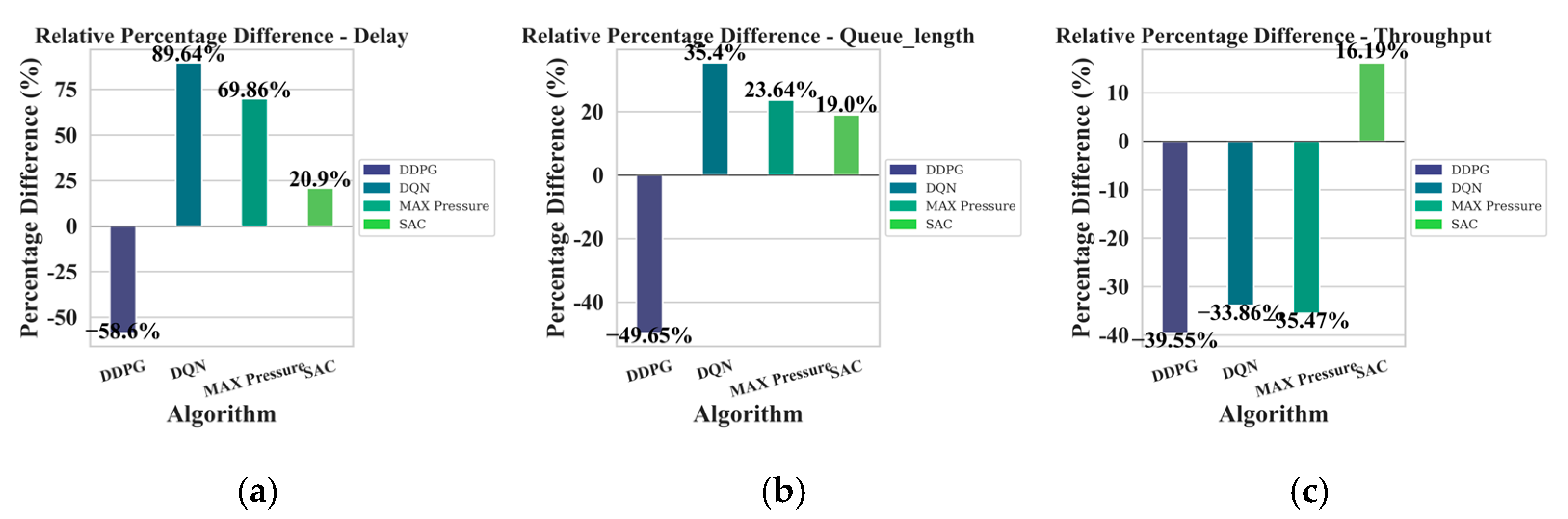

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}