1. Introduction
With the continuous progress of industrial technology and the improvement of production requirements, the demand for products in modern society is not only limited to functionality but also puts forward higher standards in terms of quality, shape, appearance, and so on. However, during the manufacturing process, due to the influence of a variety of interfering factors, the surface of the product may produce different degrees of defects, which will not only affect the appearance of the product but also reduce the actual performance of the product. As a result, reliable and efficient surface defect detection has become crucial across multiple industrial sectors, including the textile industry, the steel industry, and semiconductor manufacturing. In each of these fields, the need for consistent and perfect product surfaces has sparked a strong interest among researchers in developing surface defect detection methods. Early surface defect detection mainly adopts manual detection, which not only can easily be affected by subjective factors of detection personnel but also has low detection efficiency and high detection and false detection rates of some types of defects, especially for some defects with small deformations and no obvious distortion. Therefore, researchers are now turning to computer vision technology, leveraging powerful algorithms and high computing capabilities to create advanced, automated surface defect detection methods.
In the early stages of computer vision, defect detection mainly relied on traditional image processing algorithms. For complex environments, these algorithms require frequent parameter tuning, especially under unstable conditions. In addition, they often struggle to handle defects with inconspicuous or irregular contrast, resulting in high false detection rates and limited adaptability. As defect detection needs change, machine learning becomes an advanced solution. This shift has seen the application of simple neural networks, such as single-layer models and multi-layer perceptron, for training and classifying defect features. However, this method requires the pre-extraction of defect areas and is often combined with traditional segmentation techniques to achieve accurate defect detection and classification. Moreover, in open or unpredictable environments, factors such as different lighting conditions, changes in camera angles, and the characteristics of the material being inspected can introduce interference that diminishes the reliability and accuracy of detection. With the emergence of the convolutional neural network (CNN), deep learning technology has shown great potential in image processing tasks, such as face recognition [
1,
2], object detection [
3,
4], and semantic segmentation [
5,
6]. Among them, semantic segmentation has emerged as a valuable approach for industrial quality control, transforming the detection task into the precise delineation of defect versus non-defect areas within an image. Classifying each pixel based on regional defects or normal semantic segmentation is critical to maintaining quality standards in complex and variable environments.
At present, the fully convolutional network (FCN) [
7] and U-Net [
8] have become foundational architectures due to their efficient model structures, which are well-suited for fast, accurate defect segmentation across various industrial applications. Among them, Shi et al. [
9] introduced an advanced segmentation method, which effectively reduces the dependence on large amounts of labeled data by introducing a variety of perturbing cross-pseudo supervision mechanisms. Furthermore, the framework integrates edge pixel-level information to capture detailed edge features that are critical for accurate defect boundary detection. Huang et al. [
10] introduced an innovative multi-scale feature integration approach designed to address the limitations of traditional models in extracting local features accurately. Additionally, the model dynamically merges underlying feature information, which strengthens its capability to detect and interpret the diverse. Xu et al. [
11] applied a simple linear iterative clustering method to capture essential features of the citrus surface across multiple levels. On this basis, they introduced a cross-fusion transformer module to better transmit and integrate feature information of different scales. Zhang et al. [
12] proposed a method to realize real-time detection of production lines by efficiently aggregating multi-scale information from original images and focusing on key feature areas. In this process, the model can dynamically capture and integrate the different scale feature information of the image and effectively improve the detection sensitivity and accuracy of the target defect. Si et al. [
13] integrated a local perception module within the encoding network, which significantly enhances the model’s capability to interpret and capture fine-grained regional details and contextual cues. Meanwhile, a spatial detail extraction module was added to fully retain the key spatial detail information. Zhang et al. [
14] introduced a context-aware convolution technique aimed at refining the network’s focus on key features, effectively minimizing interference from background noise. Additionally, during the feature fusion process, they developed a specialized module to enhance feature detail, which targets the capture of subtle, complex, and irregular structural details.
Recently, substantial research efforts have focused on analyzing surface defects, particularly in complex and challenging environments. Among them, Lu et al. [
15] proposed a sophisticated multi-scale feature enhancement fusion module aimed at improving the quality and integration of deeper feature maps within the backbone network. By enhancing the expressiveness of deeper feature representations and ensuring effective fusion, their approach achieves remarkable accuracy in surface defect detection. Li et al. [
16] introduced a novel position attention module designed to enhance the network’s ability to accurately perceive and localize defects within an image. Additionally, they developed a shape detection module incorporating feature difference loss, which plays a crucial role in refining the segmentation process to delineate the precise defect areas. Xiao et al. [
17] developed an advanced multilevel receiving field module aimed at achieving a comprehensive perception of surface defects, particularly those that are complex and exhibit significant variability. Song et al. [
18] introduced an innovative design by replacing all under-sampled layers in the encoder, with a combination of a spatial attention mechanism and a feedforward neural network. This approach enhances the network’s ability to preserve finer spatial details, which are often lost in traditional under-sampling processes. Luo et al. [
19] developed a Gaussian residual attention convolution module aimed at addressing the challenges of distinguishing similar feature defects in low-contrast environments. This approach effectively amplifies key features while suppressing irrelevant or redundant information, improving the accuracy and reliability of defect detection in visually challenging scenarios.
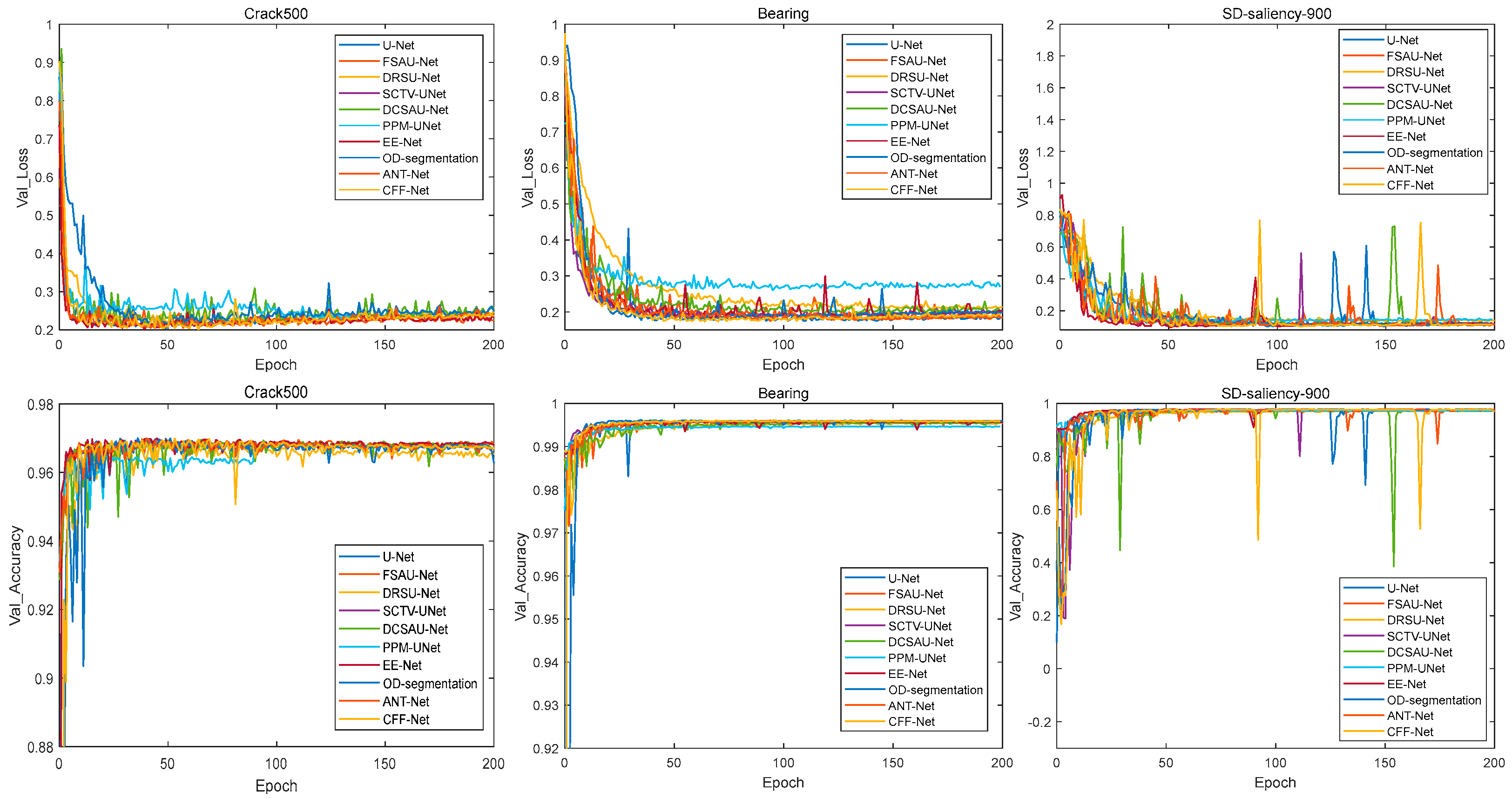
Inspired by the above methods, we propose a cross-hierarchy feature fusion network based on a composite dual-channel encoder for surface defect segmentation. Experimental results on road, bearing, and strip steel defect datasets demonstrate that the proposed CFF-Net network exhibits exceptional segmentation performance. In the Crack500 dataset, our network demonstrated a notable improvement over the U-Net baseline, with an increase of 2.06% in the Mcc, 2.14% in the Dice coefficient, and 2.57% in the Jaccard index. Similarly, in the Bearing dataset, performance gains were observed, with the Mcc improving by 2.70%, the Dice coefficient increasing by 2.74%, and the Jaccard index rising by 3.45%. In the SD-saliency-900 dataset, our network continued to showcase its effectiveness, achieving enhancements of 1.06% in the Mcc, 1.01% in the Dice coefficient, and 1.43% in the Jaccard index. These results demonstrate that the network effectively handles varying defect types and complexities within these datasets, achieving precise segmentation even in challenging scenarios with diverse textures and irregular defect boundaries. The primary contributions of our work can be summarized as follows: (1) In the encoder phase, we introduce a composite dual-channel module that combines standard convolution with dilated convolution in a dual-path parallel configuration, significantly improving the model’s feature extraction capability. (2) To bridge the encoder and decoder, we integrate a dilated residual pyramid module, leveraging convolutions with varied dilation rates to capture multi-scale contextual information. (3) At the output stage, we employ a cross-hierarchy feature fusion strategy, which merges outputs from multiple network layers or stages to obtain edge details. This approach contributes to enhanced segmentation accuracy, particularly in regions with complex boundary structures.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}