1. Introduction
Amid the continuous growth of global power demand and the increasing complexity of grid loads, ensuring stable operation and precise monitoring of transmission lines has become a pivotal task in power system management [
1]. Arc sag, a crucial parameter for transmission lines, significantly influences the safety and operational efficiency of power grids and is integral to system fault prediction and prevention [
2]. However, arc sag is impacted by various factors such as ambient temperature, load fluctuations, wind speed, humidity, and line aging, all of which contribute to its significant nonlinear and non-smooth characteristics. These complexities pose challenges for traditional linear prediction models, making them less effective in addressing such dynamic changes. Consequently, developing intelligent algorithms that can precisely capture the intricate timing characteristics and deliver high-precision predictions has become a crucial research direction for enhancing the intelligence of power systems.
In recent years, the development and innovative application of technology have led to the proposal of various advanced methods for arc sag monitoring of transmission lines. For instance, Wang D et al. [
3] proposed a method for monitoring arc sag in iced transmission lines using stereo vision technology, which enables accurate 3D reconstruction and monitoring of overhead transmission lines. This technique is crucial for maintaining grid security under freezing conditions. Similarly, Song J et al. [
4] introduced a method for arc sag measurement based on unmanned aerial vehicle (UAV) aerial photography and deep learning techniques. The study proposed an automatic isolation bar segmentation algorithm, CM–Mask–RCNN, which integrates a CAB attention mechanism and MHSA self-attention mechanism to automatically extract isolation bars and compute their center coordinates. By combining conventional algorithms, such as beam method leveling, spatial pre-convergence, and spatial curve fitting, this method provides cost-effective arc droop measurements. Wydra M et al. [
5] proposed a vision-based system utilizing LoRa communication for monitoring slack and temperature in overhead transmission lines. This method captures images from cameras mounted on poles and processes them to obtain slack and temperature data, thus preventing disconnections during installation or maintenance. Long X et al. [
6] applied Bayesian optimization (BO) and XGBoost models to predict the jump height of transmission lines after de-icing. By performing numerical studies under various structural, icing, and wind conditions, the BO-XGBoost model outperforms other machine learning models, offering a reliable, efficient, and interpretable tool for designing safer transmission line systems in freezing conditions. Finally, Wang J et al. [
7] proposed Boosted DETR, an end-to-end sensing framework for UAV inspection of transmission lines. This framework uses a detection transformer (DETR) model and an enhanced multi-scale Retinex algorithm to optimize object detection, improving the recognition accuracy of small critical components, such as insulators and anti-vibration hammers, in complex environments. The framework aims to enhance the efficiency and accuracy of transmission line inspections while adapting to changing environmental conditions.
Deep learning techniques, particularly long short-term memory networks (LSTMs) [
8], have demonstrated robust modeling capabilities for time–series prediction tasks. For instance, Jun Liu et al. [
9] introduced an innovative LSTM model known as Global Context-Aware Attention LSTM (GCA-LSTM) for human action recognition based on skeletal sequences. Additionally, Fazle Karim et al. [
10] developed a hybrid model that combines fully convolutional neural networks (FCNs) and long short-term memory networks (LSTMs) for time–series classification tasks, known as LSTM-FCN and ALSTM-FCN. Furthermore, Weicong Kong et al. [
11] proposed an LSTM-based recurrent neural network for short-term residential load forecasting, addressing the prediction challenges for individual residential users.
LSTM has been extensively employed in various domains such as finance, weather forecasting, and speech recognition, due to its unique structure that captures both long-term and short-term data dependencies. For instance, Haojun Pan et al. [
12] developed an innovative hybrid model that integrates a long short-term memory (LSTM) network with a generalized autoregressive conditional heteroskedasticity (GARCH) model to predict stock index futures prices. Similarly, Jun Luo et al. [
13] combined an ARIMA model, the Whale Optimization Algorithm (WOA), and LSTM to enhance air pollution management by accurately forecasting air pollutant concentrations. Additionally, Ruben Zazo et al. [
14] utilized LSTM-based recurrent neural networks (RNNs) for automatic language identification, which is particularly effective in scenarios involving very short utterances, such as those under three seconds. These applications highlight the adaptability of LSTM in handling various challenges, including those in power systems. Nevertheless, the single LSTM model often struggles with capturing complex feature interactions and nonlinear variations in multidimensional data. In contexts such as arc droop prediction in transmission lines, where multiple factors influence the outcomes, a more sophisticated modeling approach is essential to address the shortcomings of conventional models in processing high-dimensional dynamic features.
Parameters in power systems often exhibit significant aggregation effects and irregular fluctuations, where subtle variations can profoundly influence prediction outcomes and system operational decisions. In response to these challenges, several advanced composite models incorporating convolutional neural networks (CNNs) and attention mechanisms have been developed. For instance, Kun Xia et al. [
15] introduced a deep learning model that combines long short-term memory (LSTM) and CNNs for human activity recognition (HAR). Similarly, Toon Bogaerts et al. [
16] designed a graph CNN-LSTM neural network for predicting both short and long-term traffic flows based on trajectory data from urban road networks. Furthermore, Ranjan Kumar Behera et al. [
17] developed a novel hybrid model that merges CNNs and LSTM networks for sentiment analysis tasks in social media. These methods have demonstrated considerable potential in extracting local features and global dependencies. However, optimizing these models to better suit the complex, multidimensional time–series data needs in power systems remains a pressing research challenge [
18].
This paper introduces an innovative composite prediction model that integrates a convolutional neural network (CNN), an attention mechanism, and the adaptive rabbit optimization algorithm (AROA). This model targets high-precision predictions of critical parameters such as arc sag in transmission lines. Initially, the CNN extracts local features from input data and identifies short-term fluctuation patterns within the time–series. Subsequently, long-term dependencies are captured by an CNN–LSTM–Attention network to develop a comprehensive feature representation. To enhance model performance further, the AROA, which simulates the foraging and avoidance behaviors of rabbits, is employed to intelligently search and optimize hyperparameters. This algorithm dynamically balances global exploration and local exploitation in the search space, effectively preventing convergence to locally optimal solutions and thus boosting the model’s prediction accuracy and generalization capability. Meanwhile, the attention mechanism focuses the model’s awareness on crucial moments within the time–series, facilitating a deeper understanding and processing of complex temporal data. Additionally, this paper outlines the following key contributions.
- (1)
Optimization of the ROA algorithm: Building on improvements to the traditional ROA algorithm, the AROA algorithm incorporates dynamic energy coefficients and a differential variance strategy. These enhancements effectively improve the algorithm’s global exploration and local exploitation capabilities, significantly increasing the model’s convergence speed and optimization efficiency.
- (2)
Proposing a novel prediction model: This paper presents the integration of the adaptive rabbit optimization algorithm (AROA) into the CNN–LSTM–Attention model for the first time, creating the AROA–CNN–LSTM–Attention (AROA-CLA) model. The AROA algorithm enhances prediction accuracy and stability by optimizing model parameters.
- (3)
Innovative introduction of a multi-correlated target variable forecasting model: This model combines data from multivariate time–series, allowing it to more effectively capture the joint variations of the target variable and its correlated factors, thereby enhancing the adaptability of arc droop forecasting in complex environments.
2. Materials and Methods
2.1. Adaptive Rabbit Optimization Algorithm
The rabbits optimization algorithm (ROA) is a novel meta-heuristic algorithm inspired by the foraging and hiding behaviors of rabbits. The algorithm simulates rabbits’ survival strategies in nature, such as detour foraging and random hiding, to locate the global optimal solution within a complex search space. ROA employs the foraging behavior of rabbits for global exploration and their hiding behavior for local exploitation, achieving a smooth transition between the two through the gradual decay of an energy factor. This design makes ROA well-balanced and adaptable, enabling it to achieve superior solutions across various optimization problems. Building on this background, ROA solves optimization problems through six core steps: population initialization, energy factor control, detour foraging, random hiding, position updating, and termination.
2.1.1. Population Initialization
In ROA, a set of individual rabbits is initially generated, where the position of each rabbit represents a candidate solution. These locations are randomly assigned within the search space to ensure a diverse initial population, thereby enhancing the potential for global exploration. First, nnn individual rabbits are generated, each with a position randomly distributed within the search space bounds [lower_bound,upper_bound]. The global best solution and fitness values are then initialized to support subsequent solution updates and comparisons [
19].
2.1.2. Calculation of Energy Factor A
Energy factor A controls the search behavior of the algorithm at each iteration, simulating the rabbit’s energy consumption during foraging and hiding. As the number of iterations increases, the energy factor gradually decreases, guiding the algorithm’s transition from global exploration to local exploitation. The energy factor is calculated as follows:
is the current number of iterations. is the maximum number of iterations. is a random number used to introduce uncertainty. When A > 1, the algorithm enters global exploration (foraging in a roundabout way); when A ≤ 1, the algorithm enters local exploitation (random hiding).
2.1.3. Detour Foraging–Global Exploration
When energy factor A > 1, the algorithm simulates the detour foraging behavior of rabbits, where they forage in areas distant from their nest to avoid local minima traps. This strategy enhances the algorithm’s global search capability.
and are run operators that control the direction of the rabbit’s movement and the step size. is a run operator that controls the direction of the rabbit’s movement and the step size. is a random number that is used to increase the randomness of the exploration. is a perturbation term of the standard normal distribution that prevents from falling into the local extremes. The detour foraging strategy allows the rabbit to explore over a large area and helps to discover potential global optimal solutions in the search space.
2.1.4. Random Hiding–Local Development
When energy factor A ≤ 1, the algorithm simulates the rabbit’s random hiding behavior. In this phase, the rabbit randomly selects one of multiple hiding locations, enabling a more refined search within the local area:
In this algorithm, represents the hiding position of rabbit i in dimension j. The hiding parameter, decreases with each iteration, ensuring that the algorithm focuses on local search in the later stages. The mapping vector g specifies the dimensions in which the hiding position is updated.
2.1.5. Location Updates
Each rabbit is assigned a candidate position after performing either detour foraging or random hiding. If the fitness of the candidate position is better than that of the current solution, the rabbit’s position is updated to the candidate position; otherwise, it remains in its original location.
Here, represents the fitness function, used to evaluate the quality of each solution.
2.1.6. Termination Conditions
At the end of each iteration, the algorithm checks whether the maximum number of iterations T has been reached. If the maximum number has been reached, the algorithm stops and outputs the current global best solution; otherwise, it proceeds to the next iteration.
2.1.7. Calculation of Adaptive Energy Factor A
The rabbit optimization algorithm has been improved to become the adaptive rabbit optimization algorithm. The specific parts of the improvement are detailed in the following.
In the original algorithm, energy factor A gradually decays to balance exploration and exploitation. To enhance adaptability, the energy factor can be dynamically adjusted based on population diversity: when diversity decreases, the algorithm increases exploration to avoid premature convergence. The formula for the dynamic energy factor is as follows:
Here, represents the current iteration number, and is the maximum number of iterations. The variable is a random number introduced to add randomness, while “diversity” denotes population diversity, measuring the degree of variation within the current population. Lower diversity results in a higher energy factor, enhancing global exploration.
2.1.8. Adaptive Detour for Food—Global Exploration
Improvement: In the detour foraging phase, the step length R can be dynamically adjusted according to the iteration process and population diversity. Initially, a larger step length is used to cover a wider search space, while in the later stages, the step length is gradually reduced to allow for fine-grained local exploitation. Dynamic step size adjustment is applied to the step size factor R(t), based on population diversity, with the global best position added as an additional reference to guide individuals closer to the current optimal solution.
The constant controls the dynamics of the step size, while is a random number that adds variability to the step size. “Diversity” denotes population diversity, initially setting a larger step size to enhance global exploration and gradually decreasing it in later stages to improve the precision of local exploitation.
Each rabbit references not only the position of a randomly selected rabbit but also the current global best position,
, during detour foraging. This collaborative mechanism allows rabbits to gather in regions near the global optimal solution, thereby enhancing the algorithm’s convergence.
In this context, and represent the positions of rabbit i and a randomly selected rabbit j at the current iteration. The dynamic step factor controls the exploration direction, while denotes the global optimal position. The weight parameter α adjusts the extent to which rabbits move closer to the global optimal position.
2.1.9. Random Hiding–Localized Development
Improvement: During the generation of candidate hiding positions, a differential variation strategy is introduced. This strategy randomly selects two positions from the population and uses their differences to increase solution diversity, helping to avoid local optima. Differential variation creates new candidate solutions by calculating the difference between two randomly selected rabbits.
Here, and represent two randomly selected positions of different rabbits. The differential scaling factor controls the magnitude of the difference between these positions, thereby adjusting the update step of the solution.
2.1.10. Updating Locations
Improvement: A memory pool mechanism, M, is introduced to store the best position found in each round. When updating positions, the algorithm references the historical optimal solutions in the memory pool, helping individuals escape from local optima.
Here, represents the historically optimal position selected from the memory pool. The dynamic step factor controls the step size of the update, while is a weight parameter that regulates the influence of memory, typically set to a constant less than 1. “Diversity” denotes population diversity, which further increases the randomness of exploration.
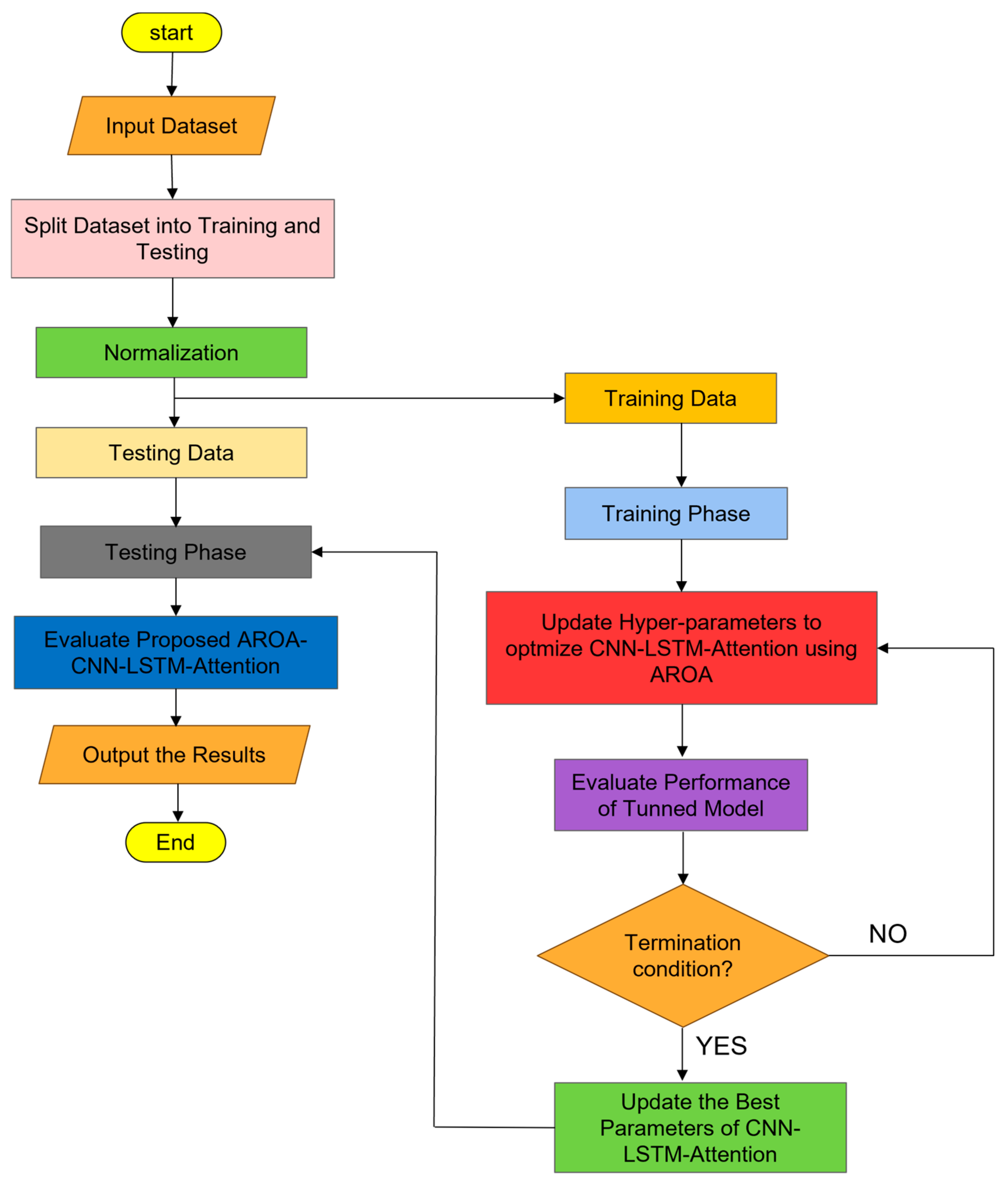
This flowchart illustrates a hybrid process that combines the adaptive rabbit optimization algorithm (AROA) with deep learning model training. On the left, the AROA begins by initializing the population and variables, balancing global exploration with local exploitation through the calculation of the dynamic energy coefficient A. When A > 1, the algorithm performs detour foraging, using adaptive step size and a global best reference mechanism to conduct an extensive search of the solution space. When A ≤ 1, it employs the differential variance strategy (DVS) to enhance local search. The algorithm then generates multiple candidate hiding locations, calculates fitness values, updates locations, and uses a memory pool mechanism to reference historical optimal solutions. This loop continues until the maximum number of iterations is reached, ultimately outputting the optimal solution.
On the right, the flowchart depicts the training process of the deep learning model. The dataset is first divided into training and test sets, after which the model is constructed and trained. The trained model then predicts the test data, and its accuracy and error are evaluated. By incorporating the AROA optimization step, hyperparameter selection and initial model conditions are optimized, enhancing the efficiency of the training process and improving the accuracy of the deep learning model’s predictions, as shown in
Figure 1.
2.2. Sparrow Search Algorithm
The Sparrow Search Algorithm (SSA) is a swarm-intelligence-based optimization technique inspired by the foraging behavior of sparrows. SSA models the cooperative foraging and vigilance behaviors observed in sparrow groups, dividing individuals into two roles: foragers and sentinels. Foragers primarily search for the most optimal resource (representing the optimal solution), while sentinels remain vigilant to help the group avoid local optima (representing suboptimal traps). During each iteration of the algorithm, individuals continuously adjust their positions to improve the group’s overall solution. Due to its simplicity, efficiency, and adaptability, SSA is widely applied in complex function optimization, engineering design, and data mining.
2.3. Northern Goshawk Optimization
The Northern Goshawk Optimization (NGO) algorithm is an emerging swarm intelligence-based optimization technique inspired by the hunting behavior of the northern goshawk. By simulating the goshawk’s strategies—such as circling, diving, and precisely locking onto prey—NGO effectively searches for and tracks optimal solutions. Individuals in the algorithm gradually converge toward the global optimum through collaborative exploration and exploitation. With robust global search and local refinement capabilities, NGO is well-suited to solving complex nonlinear optimization problems and is widely applied in fields such as engineering optimization, pattern recognition, and machine learning. Its flexibility and efficiency make it highly effective in performance optimization.
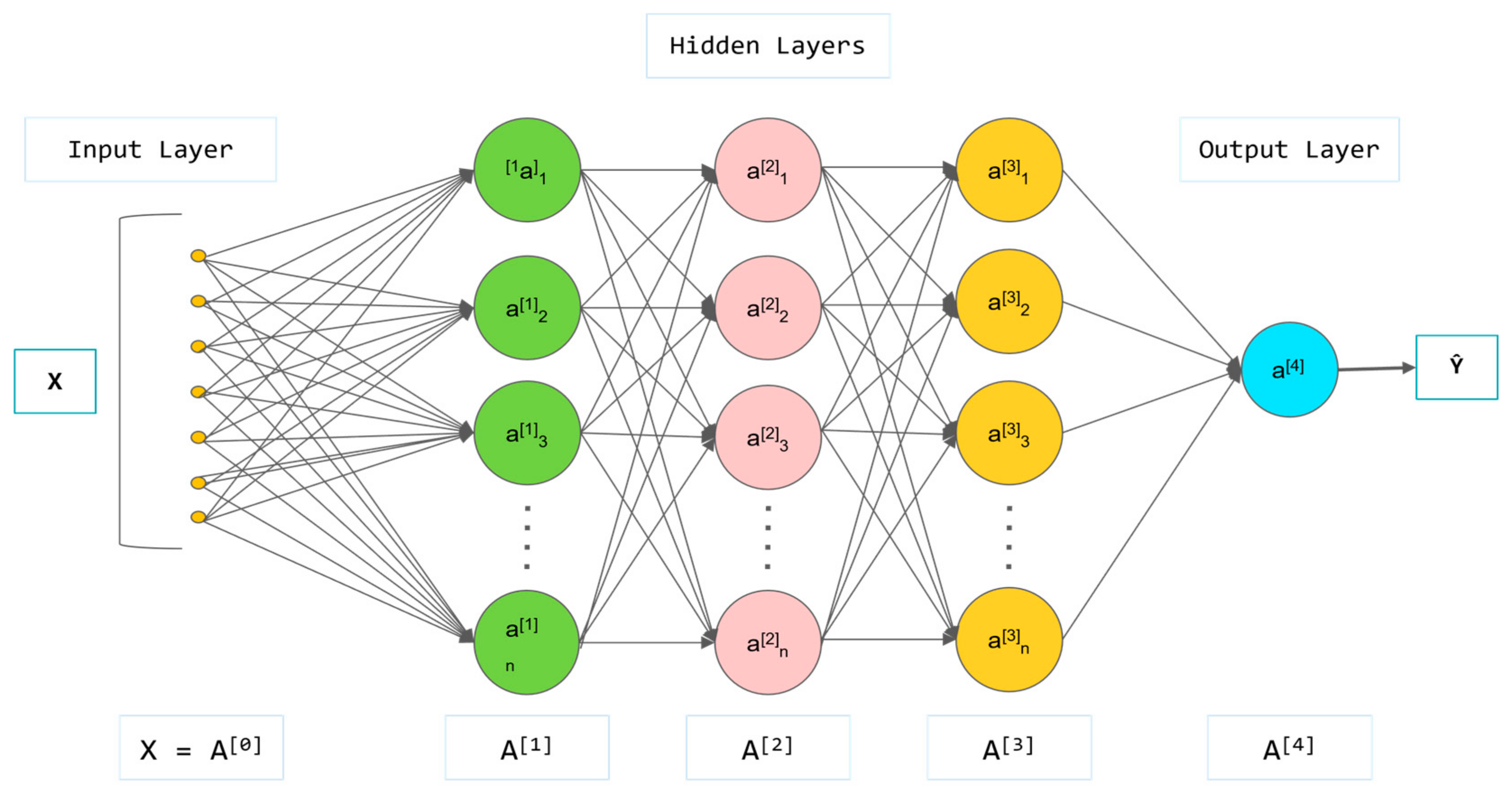
2.4. Artificial Neural Network
An artificial neural network (ANN) is a computational model inspired by the brain’s structure and functions, designed to process information by emulating biological neuron operations [
20]. ANNs comprise multiple layers of neurons; each receives inputs, processes them, and transmits the results to subsequent layers. Neurons within these layers are interconnected via weights that regulate the input signal strength. During training, the network modifies these weights to reduce the discrepancy between the predicted and actual outputs, thereby enhancing the network’s task performance.
The fundamental working principle of an artificial neural network (ANN) is based on the interaction among neurons in each layer [
21]. Initially, the input layer receives external data and forwards them to the hidden layer. Here, neurons process the data through weighted summation and activation functions to extract essential features. Subsequently, the output layer produces the network’s predicted values based on the hidden layer’s processed results. Activation functions impart nonlinear properties to the ANN, allowing it to manage complex patterns and relationships [
22].
ANNs usually consist of three main components.
Input Layer: The input layer receives data from external sources, with each neuron (input node) representing a single-dimensional feature of the data. For instance, in a dataset with multiple features, each feature corresponds to one node in the input layer.
Hidden Layer: The hidden layer, situated between the input and output layers, can consist of multiple layers. Each neuron in these hidden layers connects to all the neurons in both the preceding and subsequent layers, forming a densely connected structure. Neurons in the hidden layer amalgamate information from the previous layer through weights and bias values and undergo nonlinear transformation via an activation function.
Output Layer: The output layer outputs the final computation results, with the number of nodes depending on the type of task, as illustrated in
Figure 2.
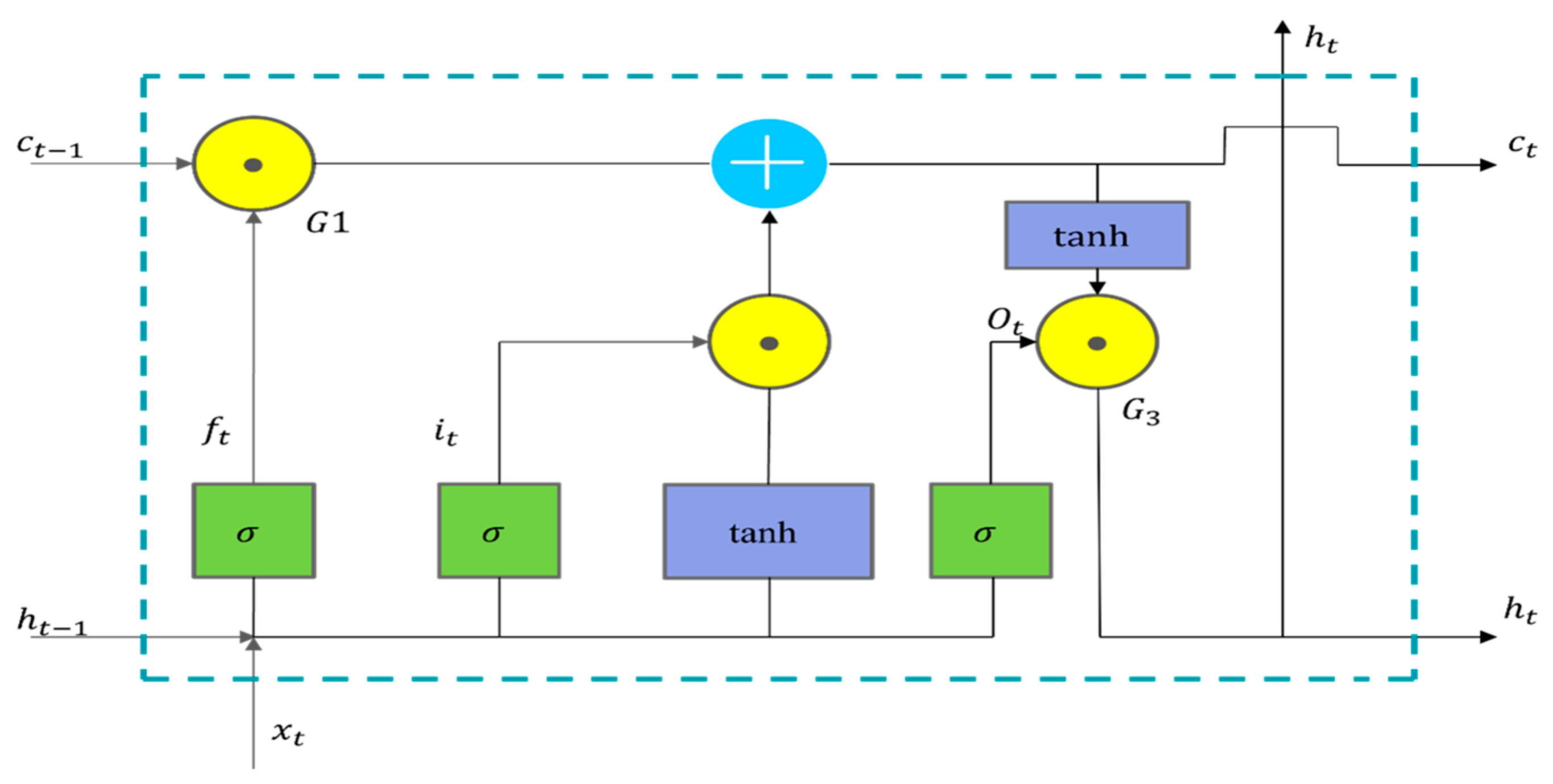
2.5. LSTM Neural Network
LSTM (long short-term memory) is a specialized type of recurrent neural network (RNN) proposed by Hochreiter and Schmidhuber in 1997 to address the issue of vanishing gradients commonly encountered by standard RNNs when processing long sequential data [
23]. The LSTM network possesses memory capabilities that enable it to retain long-term dependencies in sequence data, meaning that it is extensively utilized in fields such as time–series prediction, natural language processing (NLP), and speech recognition [
24].
LSTM network unit: The fundamental unit of an LSTM network is the memory cell, which is regulated by several gating mechanisms that control information flow. These primarily include three core gates: the input gate, the forgetting gate, and the output gate. Through these mechanisms, the LSTM can selectively retain or discard historical information, thereby mitigating the issue of vanishing gradients.
Forgetting gate: The forgetting gate determines whether to retain the memory from the previous moment. It is governed by a sigmoid function that outputs a value between 0 and 1, where 1 signifies complete retention and 0 signifies complete discard.
where
is the output of the forgetting gate,
is the hidden state at the previous moment,
is the input at the current moment,
and
are the weight and bias, and
is the Sigmoid function.
Input gate: The input gate determines whether to save new information at the current moment to the memory cell. It consists of two components: one part, using a sigmoid activation, decides which information to update; the other part, typically employing a tanh activation, generates candidate memories.
where
is the output of the input gate,
is the candidate memory value, LSTM will combine the forgetting gate and the input gate to update the memory state.
Memory state update: The memory state is updated via a forgetting gate, which determines the extent to which the previous moment’s memory should be retained, and an input gate, which assesses the impact of new information at the current moment.
where
is the memory state at the current moment and
is the memory state at the previous moment.
Output gate: The output gate determines the value of the hidden state at the current moment by integrating information from the memorized state. It then outputs the hidden state through the sigmoid and tanh functions.
where
is the output of the output gate and
is the hidden state at the current moment, which is the output of the LSTM, as shown in
Figure 3.
2.6. Attention Mechanism
The attention mechanism operates by focusing on the correlation between a query and a key, calculating their relationship to determine the most appropriate value. This process assigns attention weights to the value, generating the final output results [
25]. The mechanism’s role within the model is primarily manifested in two areas: feature weighting and performance enhancement. The attention layer can identify and assign varying weights to input features, thereby intensifying the model’s focus on critical features, which in turn enhances prediction accuracy and robustness [
26]. During the integration process, the input data are first processed through fully connected multilayers and dropout layers, and then the resultant output serves as the input to the attention layer. This layer performs a weighted summation of inputs, produces weighted features, and ultimately yields prediction results through a linear layer. Specifically, the attention mechanism improves feature selection by autonomously identifying the most crucial features for the task, enhances the model’s ability to generalize, captures long-distance dependencies in time–series or other ordered data, and, by analyzing the attention weights, allows researchers to discern which input features the model prioritizes during decision making, thus improving the model’s interpretability [
27].
Calculated intermediate representation (
):
Calculating attention scores (
):
Normalized attention score:
The attention scores are normalized by the Softmax function so that they sum to the 1. weighted sum.
Attention output is obtained by weighted summation of input features using attention weights, “*” represents the weighted product operation between matrices or vectors as shown in
Figure 4.
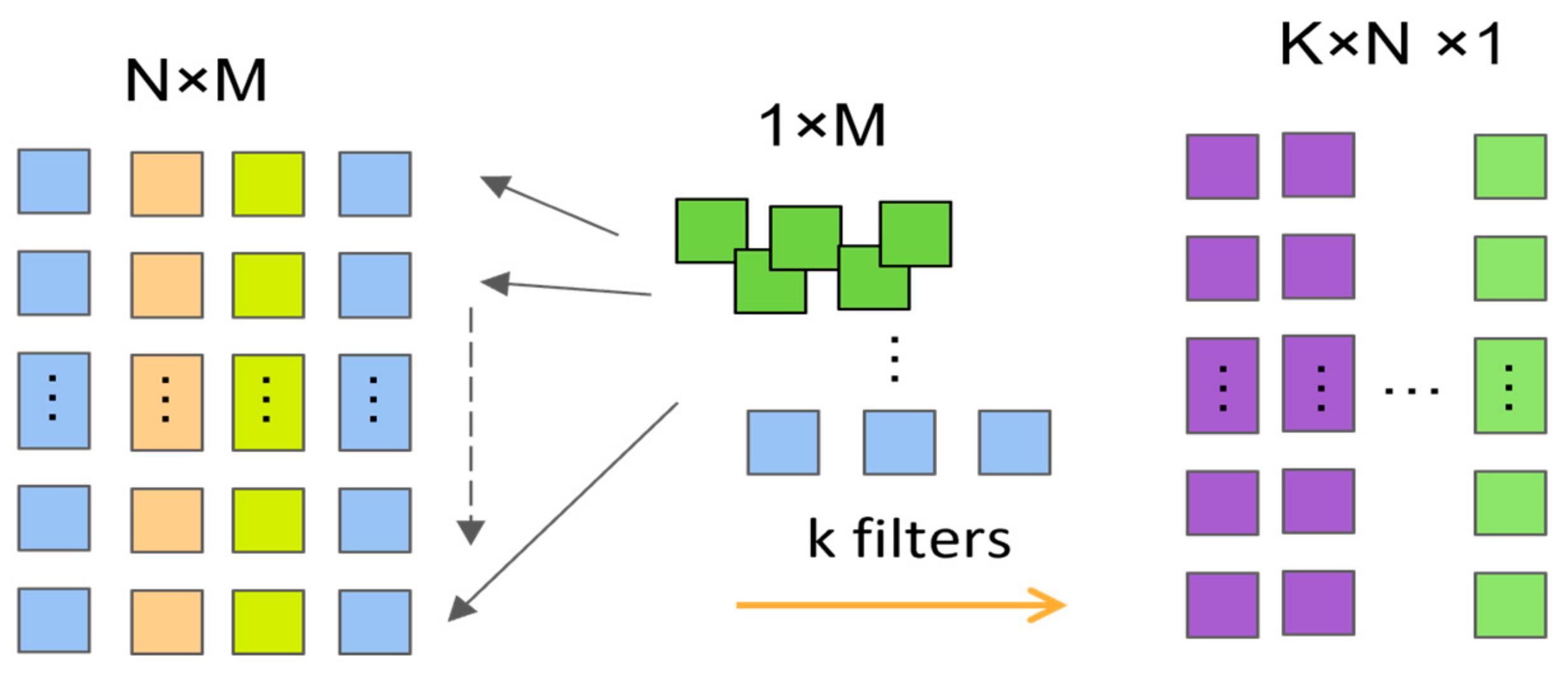
2.7. CNN
CNNs are a class of architectures prevalent in various feed-forward neural networks, primarily consisting of convolutional, pooling, and fully connected layers. These networks are especially effective for processing data with spatial structures, such as images and time–series data. CNNs efficiently process and analyze data in Euclidean space through convolutional operations, thereby demonstrating significant advantages in time–series prediction tasks [
28].
The convolutional layers of CNN effectively capture local features in time–series data, utilizing mechanisms such as weight sharing and spatial invariance to improve the efficiency and accuracy of data processing. Furthermore, the pooling layer simplifies data complexity and mitigates the risk of model overfitting by implementing dimensionality reduction operations; common methods include average pooling and maximum pooling [
29]. The fully connected layer incorporates these local features and maps them to the output space for subsequent classification or regression tasks after the convolutional and pooling layers have processed them.
In this study, we utilize a one-dimensional convolutional neural network (1D CNN) equipped with specialized convolutional kernels to predict time–series data. This network is optimized to detect short-term pattern features in time–series, streamlining the computational demands of the model by minimizing the number of required parameters through a parameter-sharing mechanism [
30]. This strategy not only boosts the model’s training efficiency but also its scalability for handling large-scale data. With this method, 1D CNNs are capable of predicting time–series data more effectively and adapting to rapidly evolving trends and patterns, as illustrated in
Figure 5.
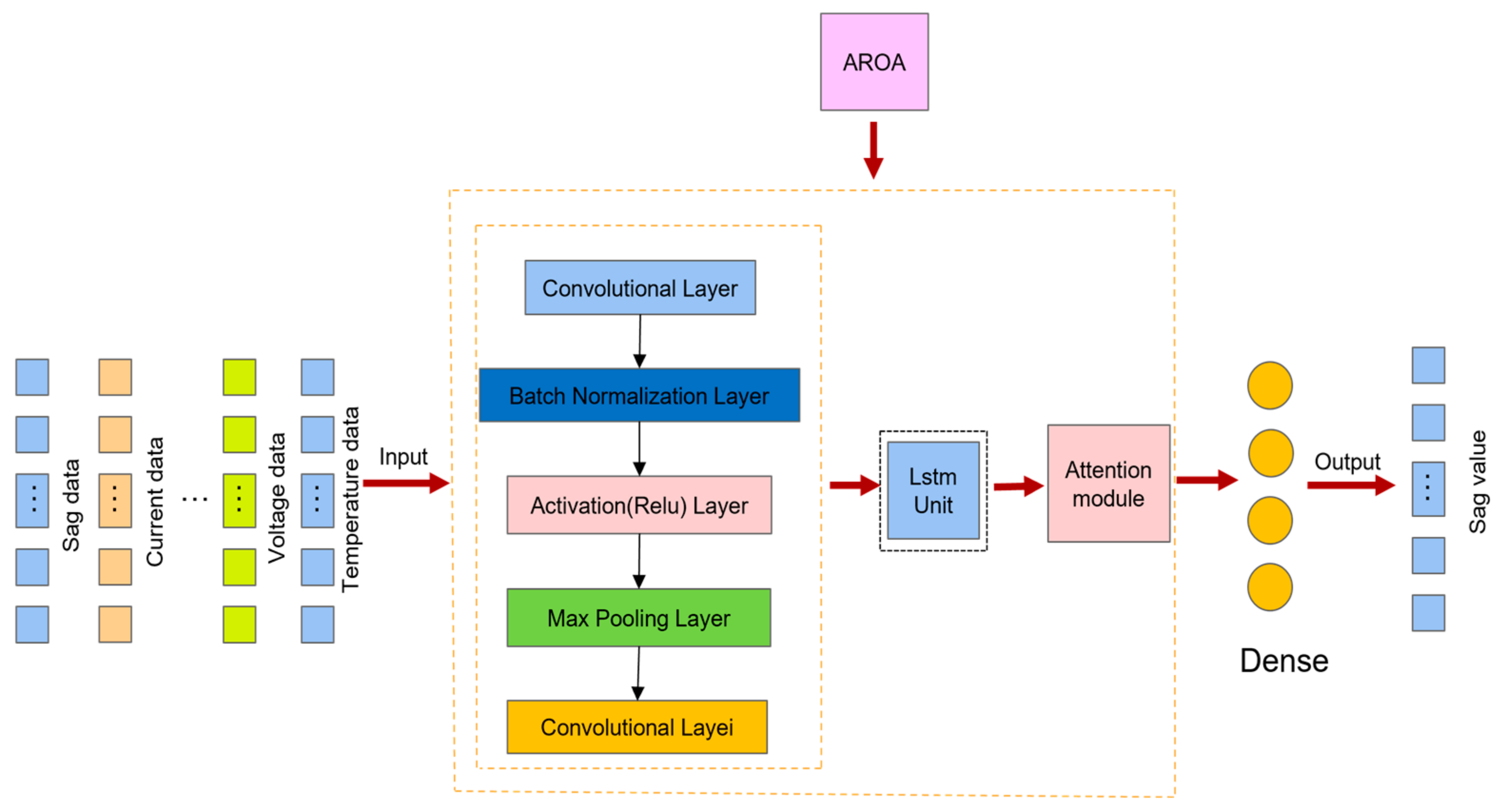
2.8. Arc Sag Prediction Model
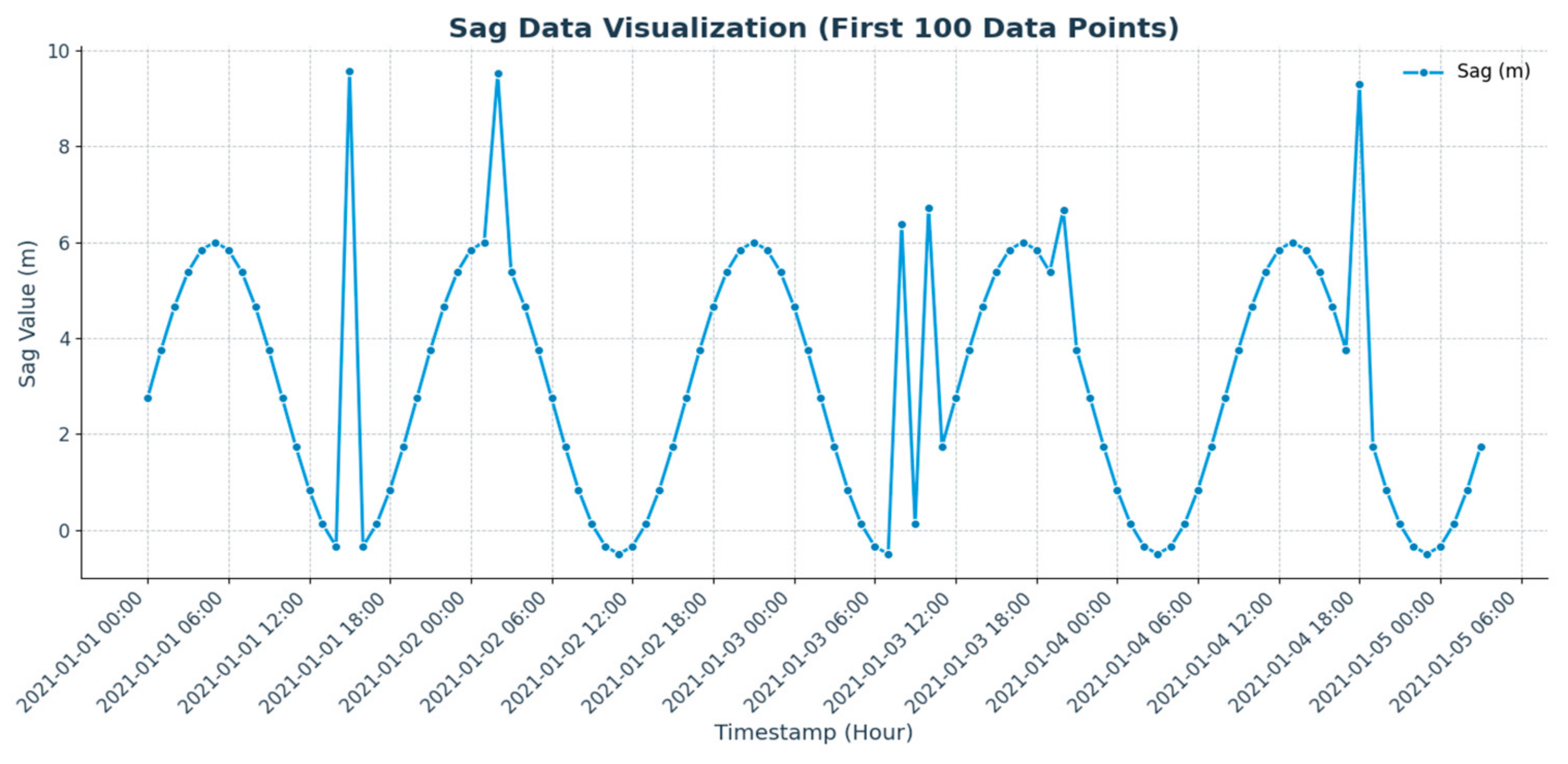
The target variable is frequently impacted by a variety of external factors in time–series forecasting. For example, current, voltage, and temperature are all factors that can affect arc sag data. The use of correlated variables as model inputs is predicated on these correlations. The single input–single output target-variable model, the multiple input–multiple output correlated-variable and target-variable model, and the multiple input–single output correlated-variable and single-target-variable model are among the numerous approaches that can be implemented when developing an input–output prediction model. This paper proposes a novel time–series forecasting method, the multi-correlated target variable forecasting model, that incorporates the benefits of these three models to fully leverage multivariate time–series data for forecasting.
The model takes as input the target variable along with its associated multidimensional time–series. In arc droop prediction, the input data include not only the historical arc droop values but also other influencing factors, such as current, voltage, and temperature. The model’s output is the predicted future value of the target variable, specifically the arc droop.
In multistep time–series forecasting, commonly employed strategies include direct multistep forecasting and recursive multistep forecasting. Direct multistep forecasting allows for the simultaneous generation of predicted values for the target variable at multiple time points. However, this method may restrict the correlation among neighboring predicted values. Consequently, we utilize a recursive multistep forecasting approach that incrementally generates predictions for the next arc–pendant step in a rolling fashion. It is important to note that this approach can lead to the accumulation of prediction errors, which may render the predictions insignificant if the error surpasses a certain threshold.
Figure 6 illustrates a multiple correlated target variable prediction model using a recursive multistep prediction strategy. In this model, Ri represents the multiple inputs from the correlated variables, O represents the input of the target variable, and assuming a step size of m, the target variable at the m + 1st data point can be predicted.
Initially, the parameters that necessitated optimization, including hyperparameters and network structure parameters, were identified in order to achieve optimal experimental results. A fitness function was subsequently created to evaluate the model’s performance under specific parameter configurations. Random combinations within a predetermined range were employed to establish the initial parameters. The model was trained and analyzed under a variety of parameter configurations to determine the fitness values of each potential solution.
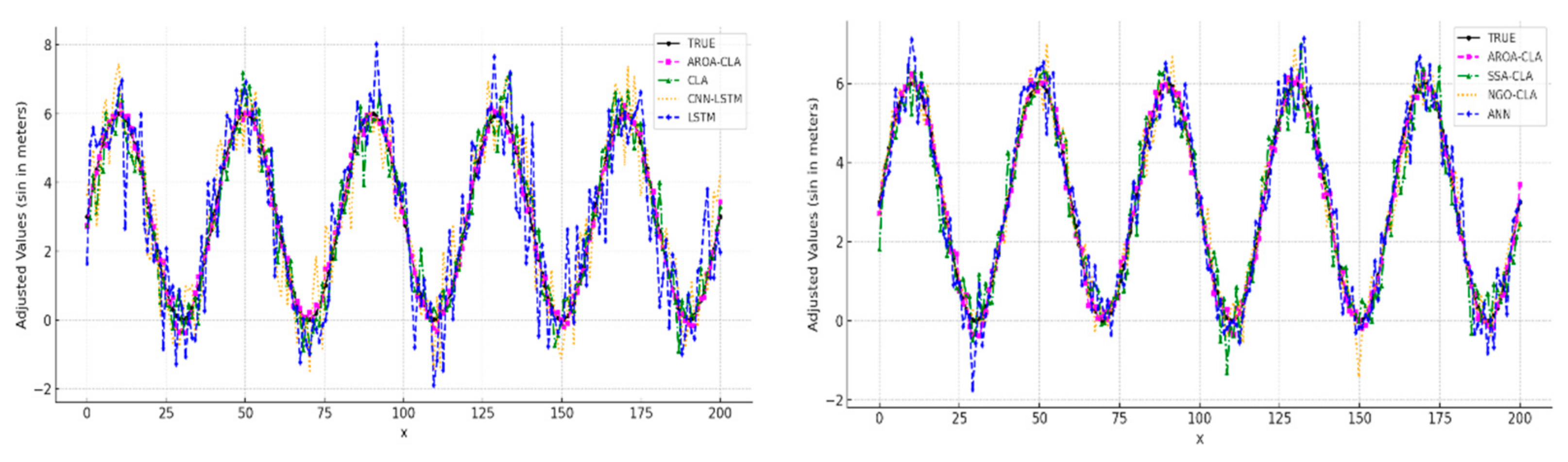
In summary, the proposed arc droop prediction model, known as the CLA model (CNN–LSTM–Attention), enables accurate forecasting of arc droop in power transmission lines under complex environmental conditions. The model begins by extracting key features from input data—such as temperature, humidity, and wind speed—using a convolutional neural network (CNN). The CNN captures local spatial information, establishing correlations between environmental factors and arc droop trends. Next, the model utilizes a long short-term memory (LSTM) network to process time–series features, effectively modeling the temporal dependencies of arc droop and incorporating historical information that influences future trends. To further enhance prediction accuracy, an attention mechanism is applied to weight the LSTM output, allowing the model to focus on key time points with greater predictive impact, thereby improving its ability to capture future arc droop trends. For hyperparameter optimization, the model incorporates the adaptive rabbit optimization algorithm (AROA), which optimizes critical hyperparameters such as convolutional kernel size, LSTM layers, neuron count per layer, and learning rate. By dynamically adjusting individual positions, the AROA balances global exploration with local exploitation, enhancing search efficiency. Its dynamic energy coefficients and differential variation strategies make AROA adaptable to complex optimization challenges, accelerating convergence speed, and improving global solution stability. The model is trained using the mean square error (MSE) as a loss function, measuring differences between predicted and actual values, and the Adam optimizer, known for stability and rapid convergence in high-dimensional spaces. To prevent overfitting, an early stopping strategy is employed, halting training if validation performance does not improve within a specified number of iterations. Model performance is evaluated using metrics such as root mean square error (RMSE) and mean absolute error (MAE), confirming its predictive accuracy and generalization capabilities. Testing results demonstrate that the model effectively forecasts arc droop trends, adapting to environmental changes and offering reliable support for real-time monitoring and early warning in power transmission. With this model, the power system can better predict and manage arc sag, enhancing transmission line safety and stability, as illustrated in
Figure 7.
4. Conclusions
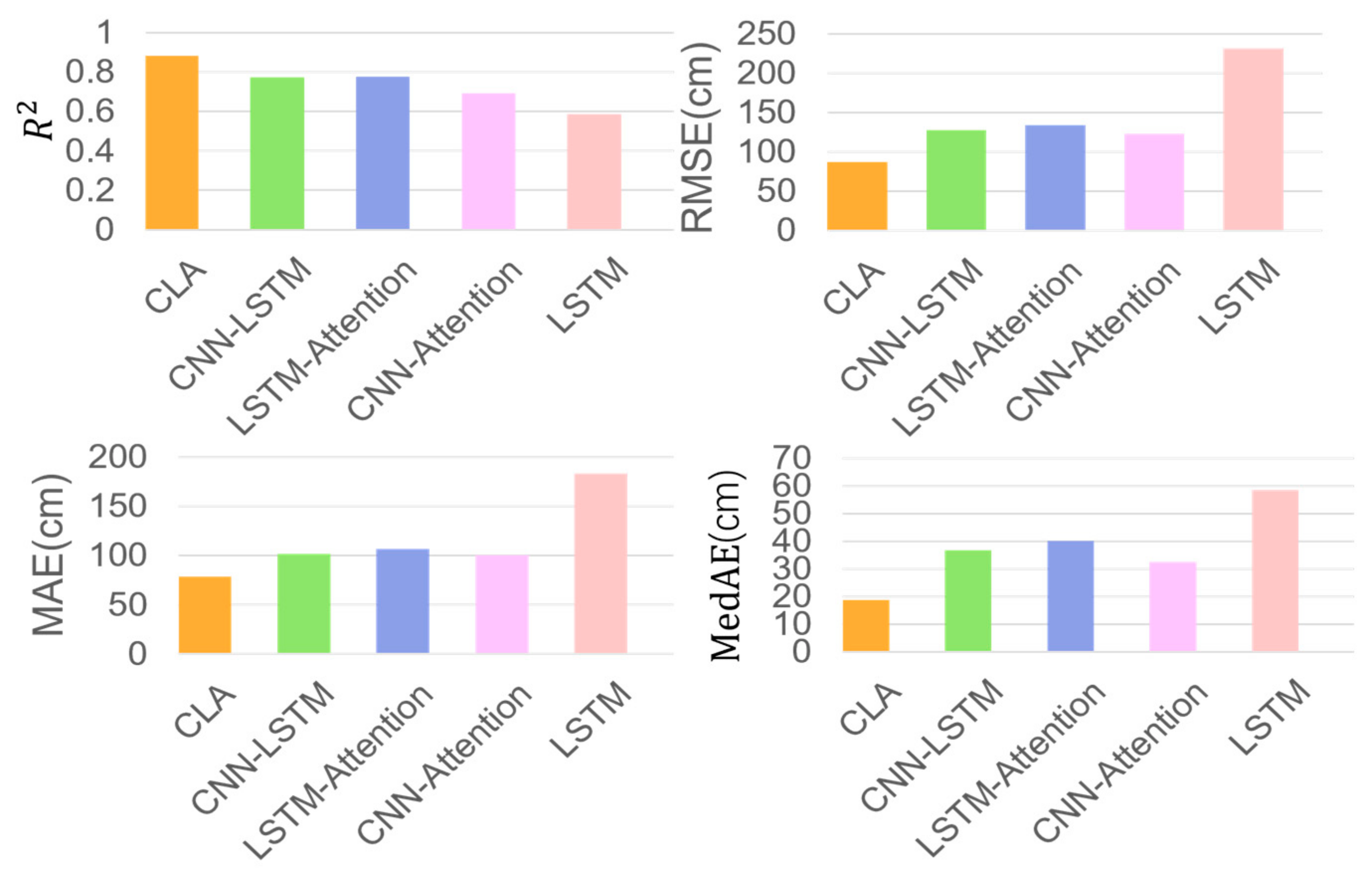
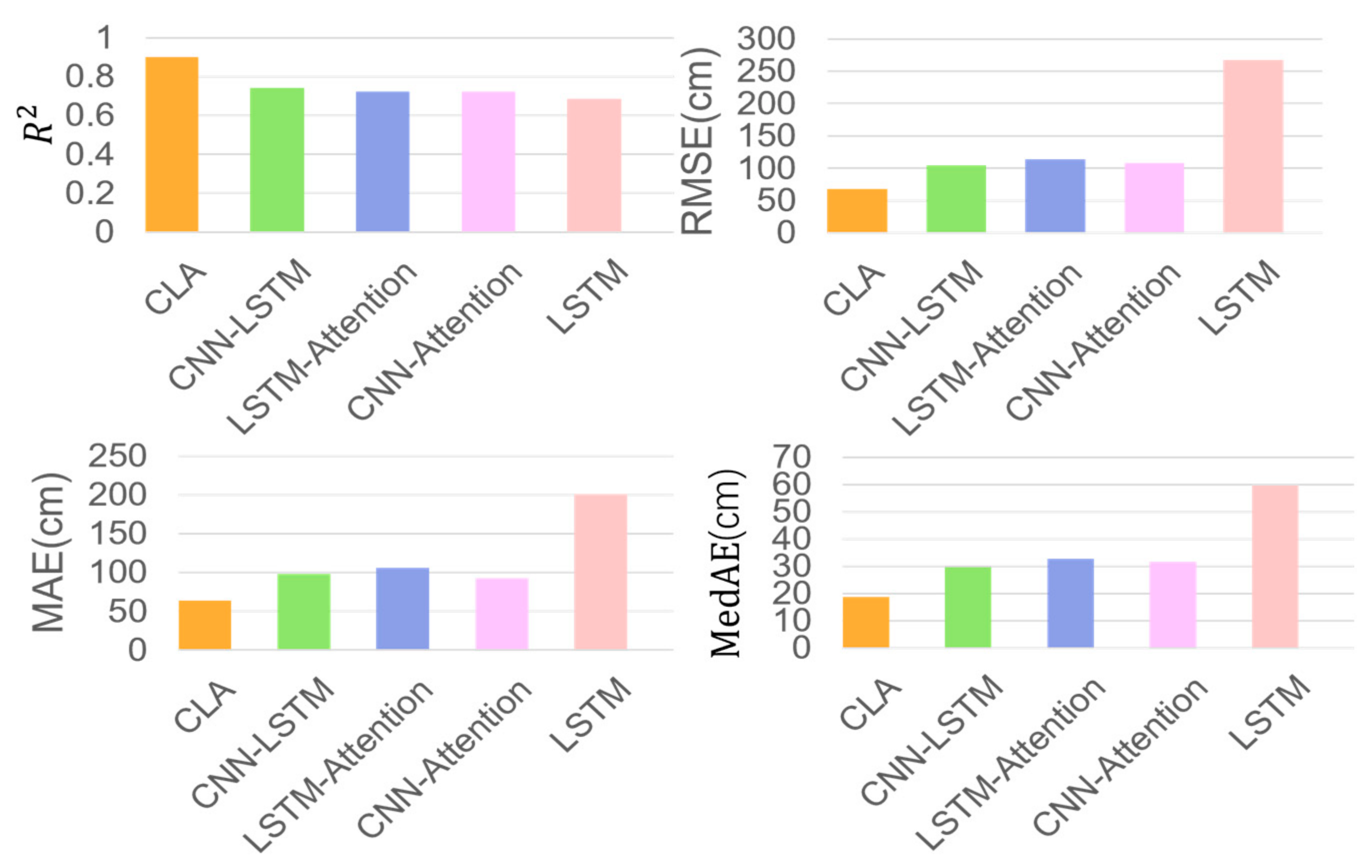
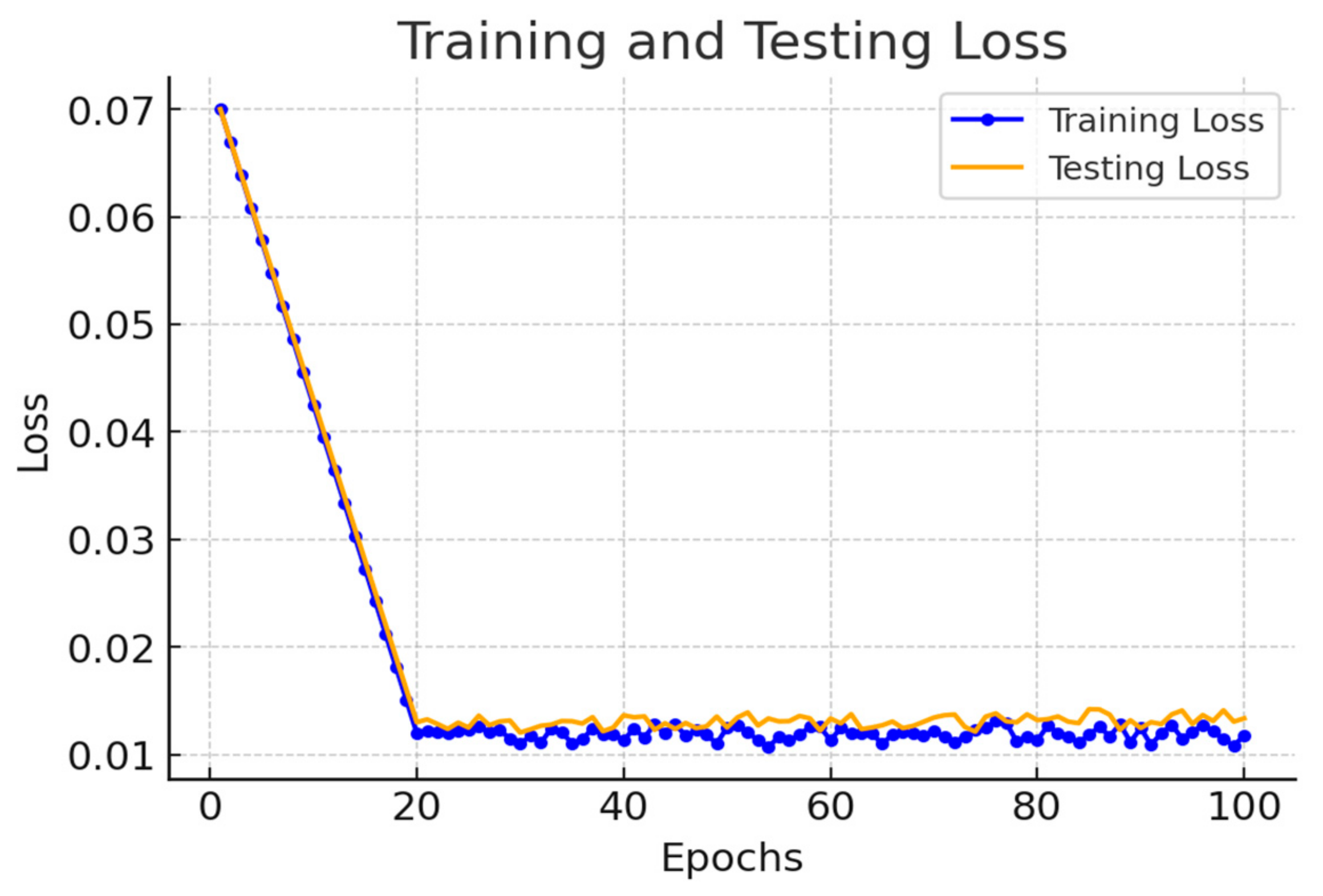
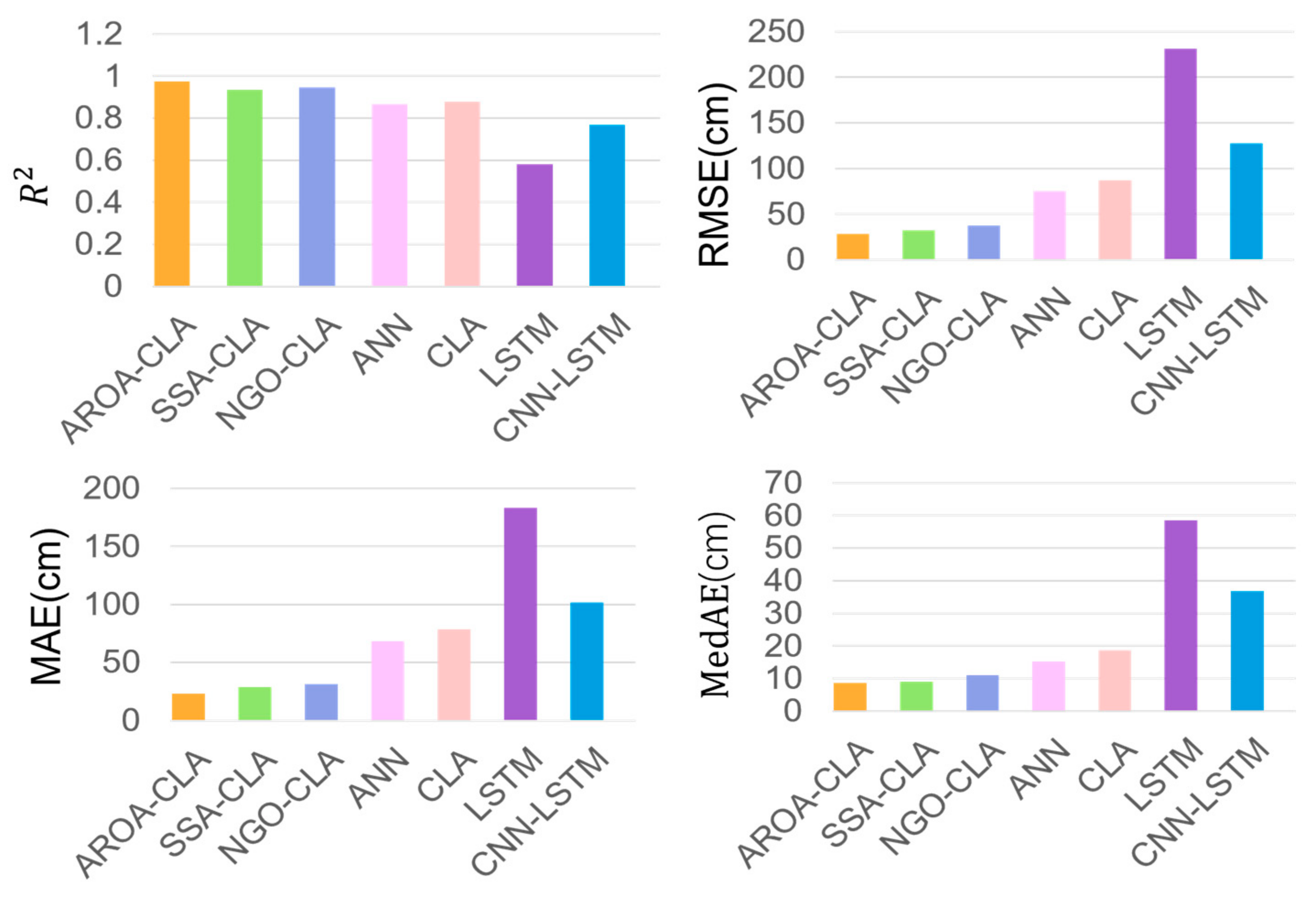
In this study, a new prediction model, AROA–CNN–LSTM–Attention (AROA-CLA), is proposed to address the challenging task of arc sag time–series prediction for transmission lines. This model integrates the Adaptive Rabbit Optimization Algorithm (AROA) into the CNN–LSTM–Attention framework, marking the first use of AROA within the CLA model for parameter optimization. This approach enhances the model’s focus on key parts of historical data and leverages advanced time–series processing capabilities to improve prediction accuracy and stability. Additionally, a multi-correlated target variable prediction model is introduced, utilizing both univariate and multivariate time–series inputs, where the target variable and associated multivariate time–series serve as model inputs. Experimental results demonstrate the model’s adaptability and stability across various time scales. The AROA algorithm performs efficiently in optimizing model parameters, reducing the loss value to below 0.01 by the sixth iteration, which significantly accelerates the model’s convergence speed. With an score of 0.974, the AROA-CLA model achieves the lowest RMSE, MAE, and MedAE compared to traditional methods and recently developed optimization models with a step size of whole, highlighting its superiority, stability, and resilience to perturbations. These results confirm the AROA-CLA model’s effectiveness and applicability in arc sag prediction. Furthermore, the AROA-CLA model not only achieves high prediction accuracy but also demonstrates consistent performance during both training and testing, reflecting its strong generalization ability and robustness. Future research could explore the potential and scalability of the AROA-CLA model in other application domains.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}