
Research on Closed-Loop Control of Screen-Based Guidance Operations in High-Speed Railway Passenger Stations Based on Visual Detection Model



Abstract
1. Introduction
- To address the issue of detecting text information within the target area, an automated closed-loop control method is proposed that integrates the YOLOv5 model with the PaddleOCR model.
- For the purposes of more accurately simulating the detection of guide screens, a comprehensive dataset comprising images of guide screens from high-speed rail stations has been assembled and developed.
- A method of integrating the triple attention mechanism with the feature pyramid network to improve the accuracy and speed of detection is proposed.
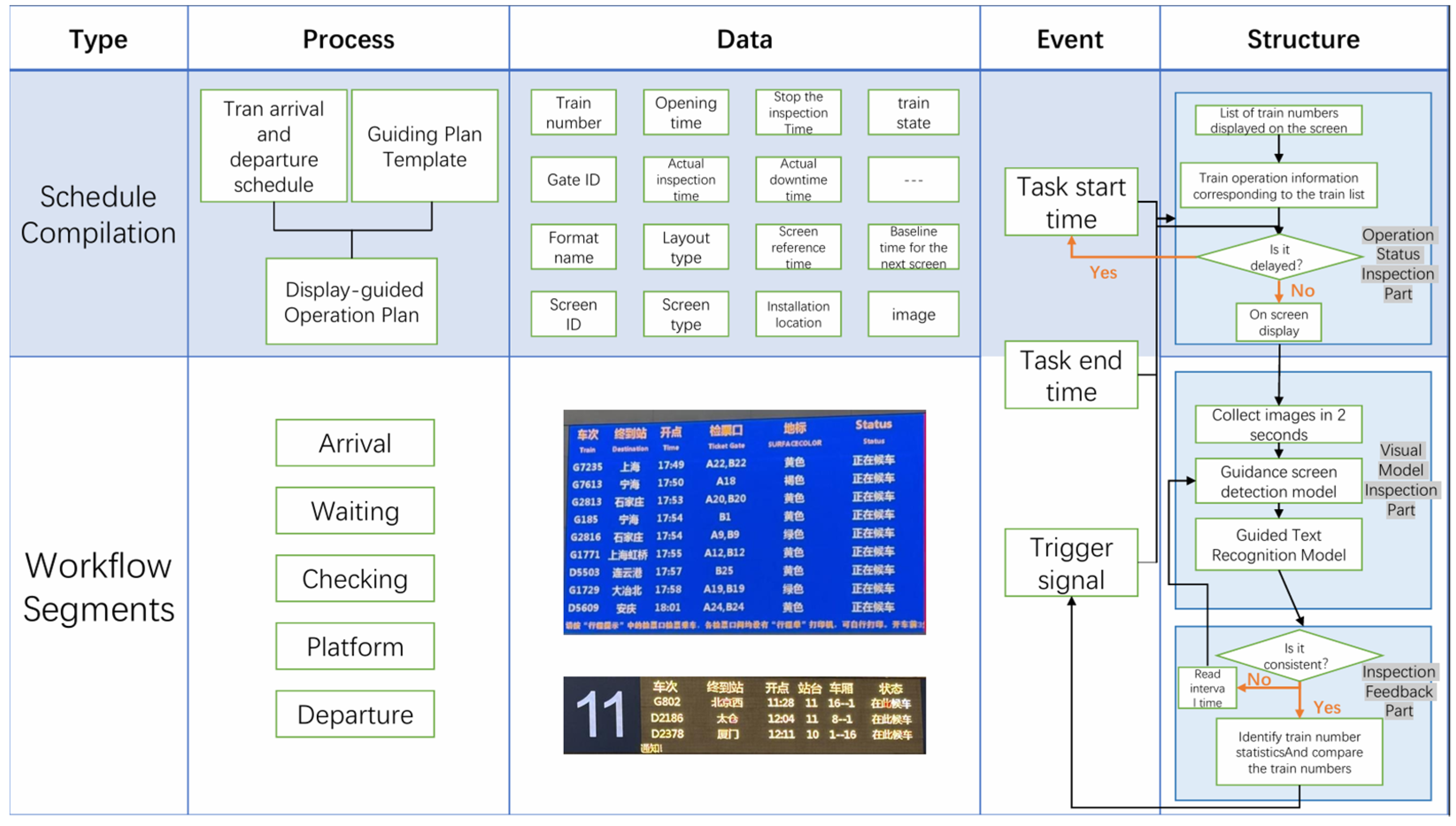
2. Design of Machine Vision-Guided Operation Closed-Loop Control Framework
2.1. Framework Design
2.2. Machine Vision Models
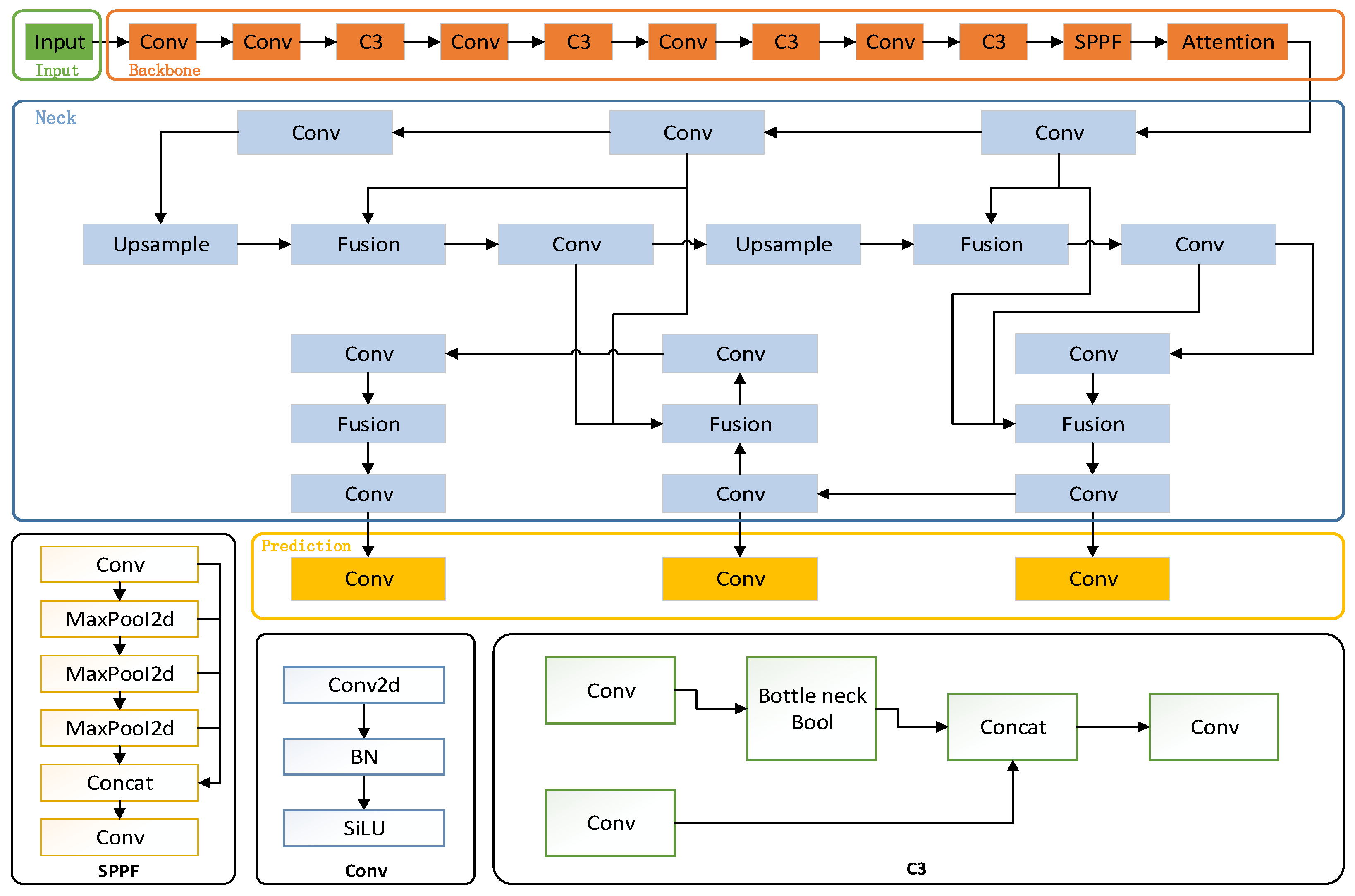
2.2.1. Based on the Improved YOLOv5 Guide Screen Detection Model
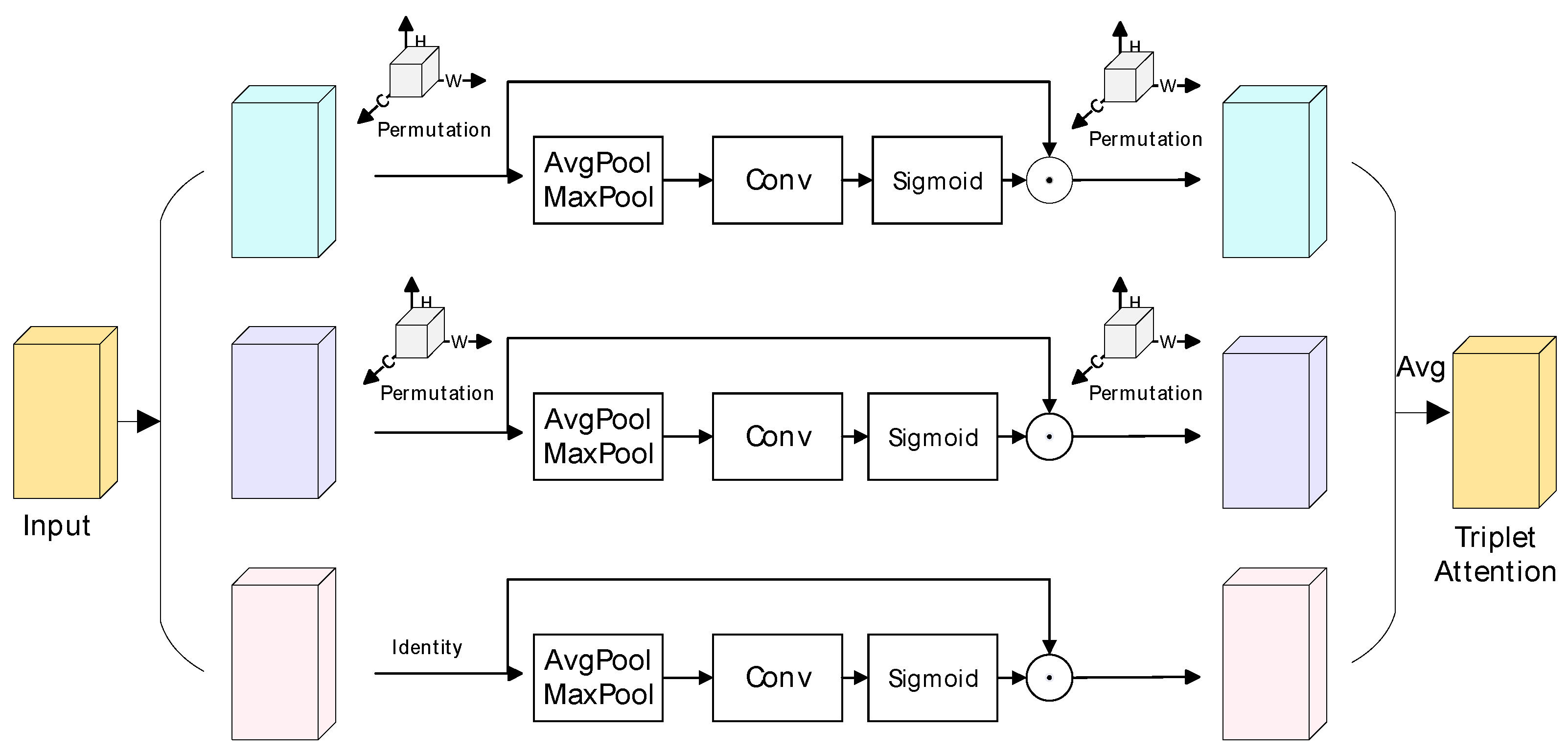
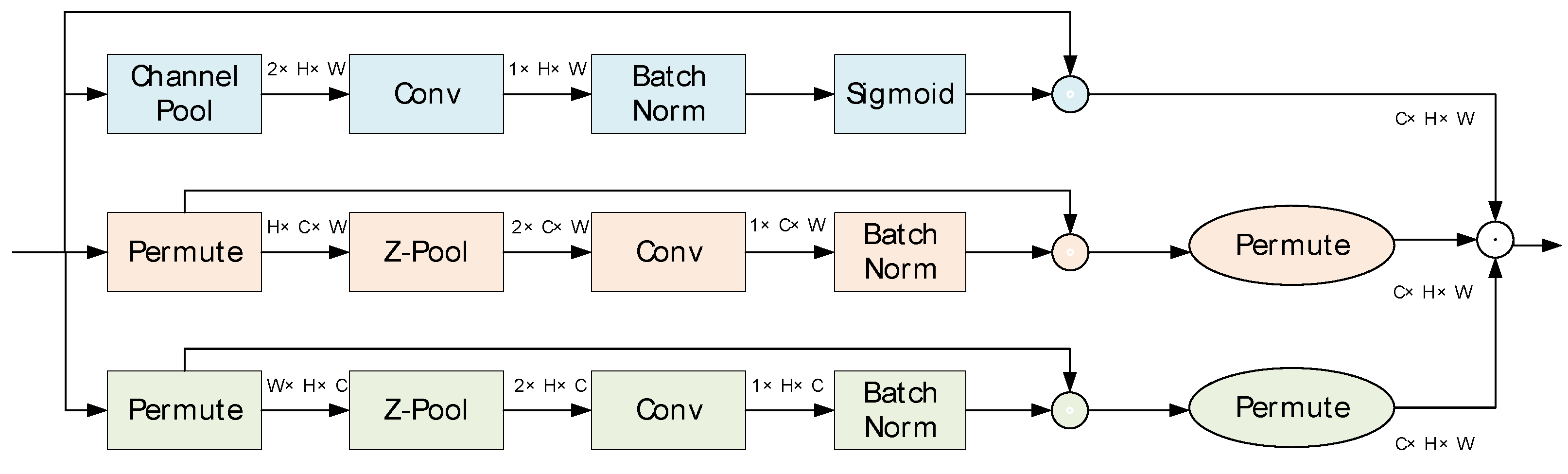
- Triplet Attention Mechanism
- 2.
- Characteristic Pyramid Network
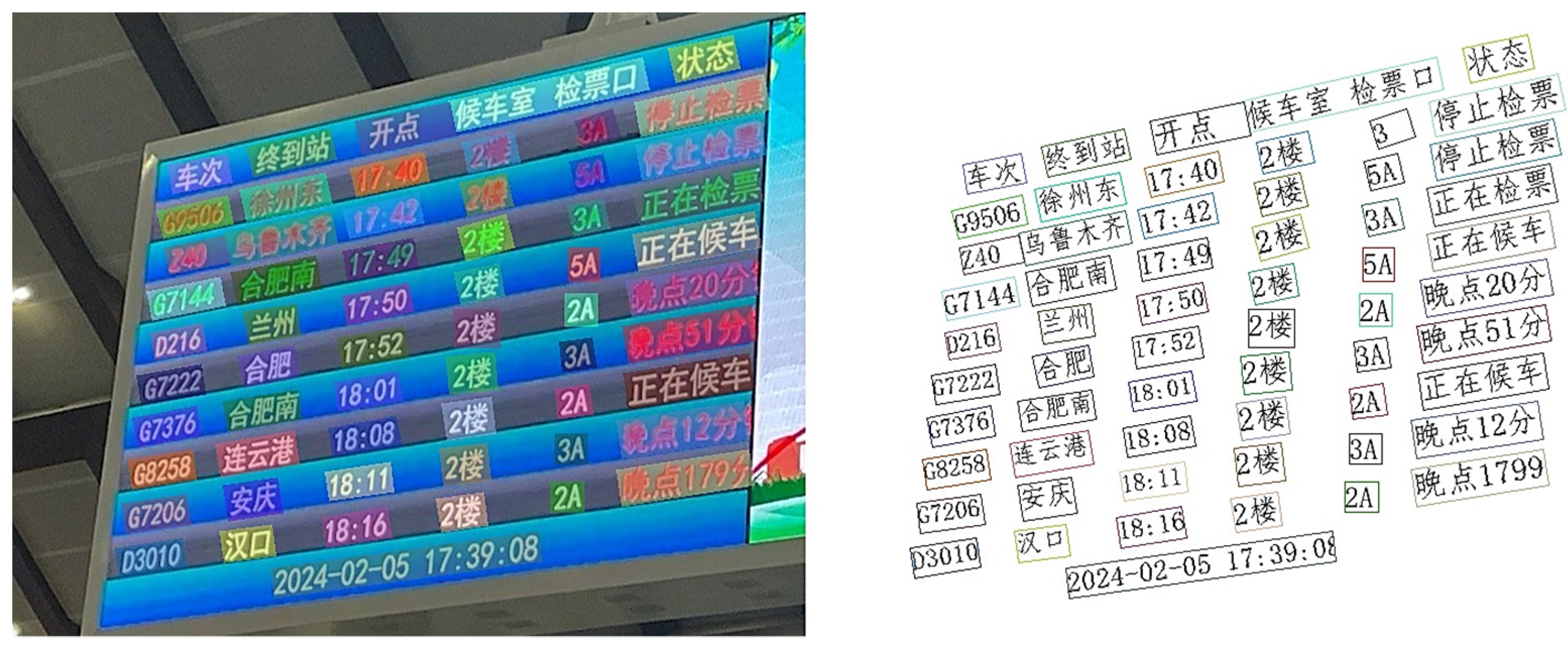
2.2.2. PaddleOCR-Based Text Recognition Model
3. Experimental Results
3.1. Dataset
3.2. Experimental Setting
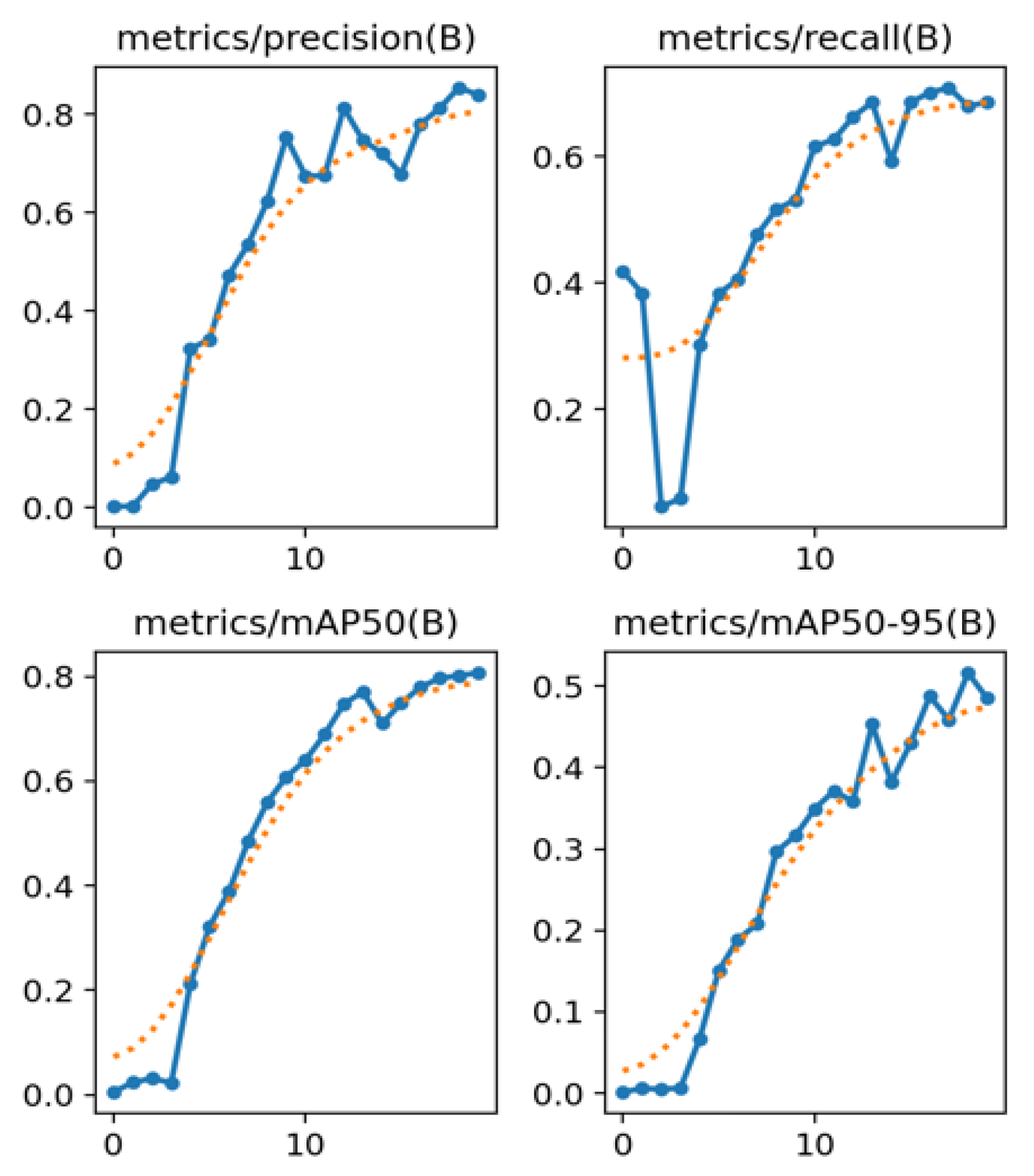
3.3. Evaluation Indicators
- (1)
- Precision indicates the proportion of positive samples detected that are truly positive, i.e., the accuracy of the detection frame. Precision rate is defined as follows:where TP (True Positive) denotes the number of positive samples predicted as positive and FP (False Positive) denotes the number of negative samples predicted as positive.
- (2)
- Recall indicates how many of the actual positive samples are detected, i.e., sensitivity. Recall is defined as follows:where TP (True Positive) denotes the number of positive class samples correctly identified by the model and FN (False Negative) denotes the number of positive class samples incorrectly identified as negative by the model.
- (3)
- Comprehensive Evaluation Indicator F-Measure (F1 Score) is used to weigh precision and recall. F-Measure is defined as follows:In target detection tasks, which are often used to evaluate model performance, especially when dealing with unbalanced datasets, it is important to consider precision and recall together.
- (4)
- mAP50(B) is a metric used to comprehensively evaluate the performance of a target detection model at an IoU threshold of 0.5.
- (5)
- mAP50-95 is a metric used to assess model performance, which represents the average of the model’s Average Precision across all categories as the IoU (intersection and concurrency ratio) threshold is varied from 0.5 to 0.95.
3.4. Experiments on the GPU
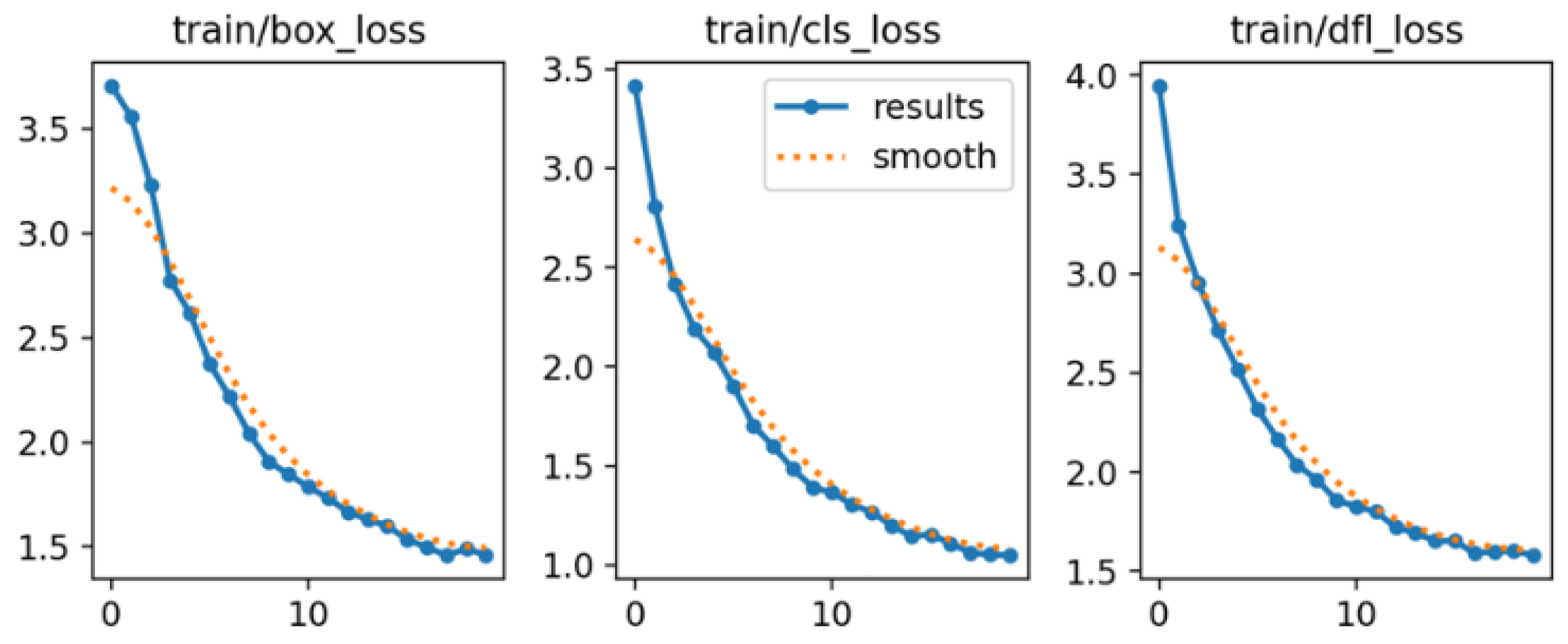
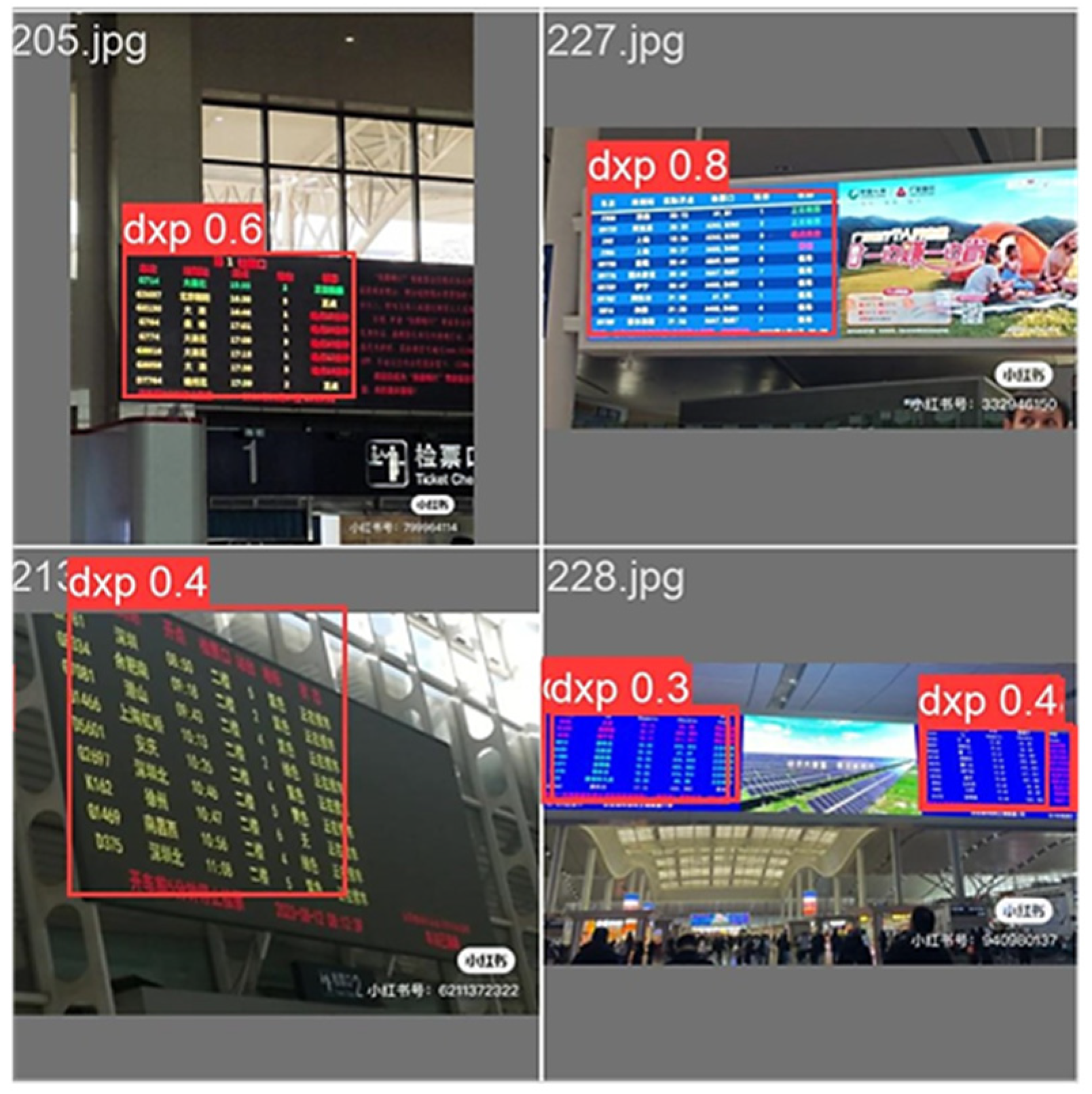
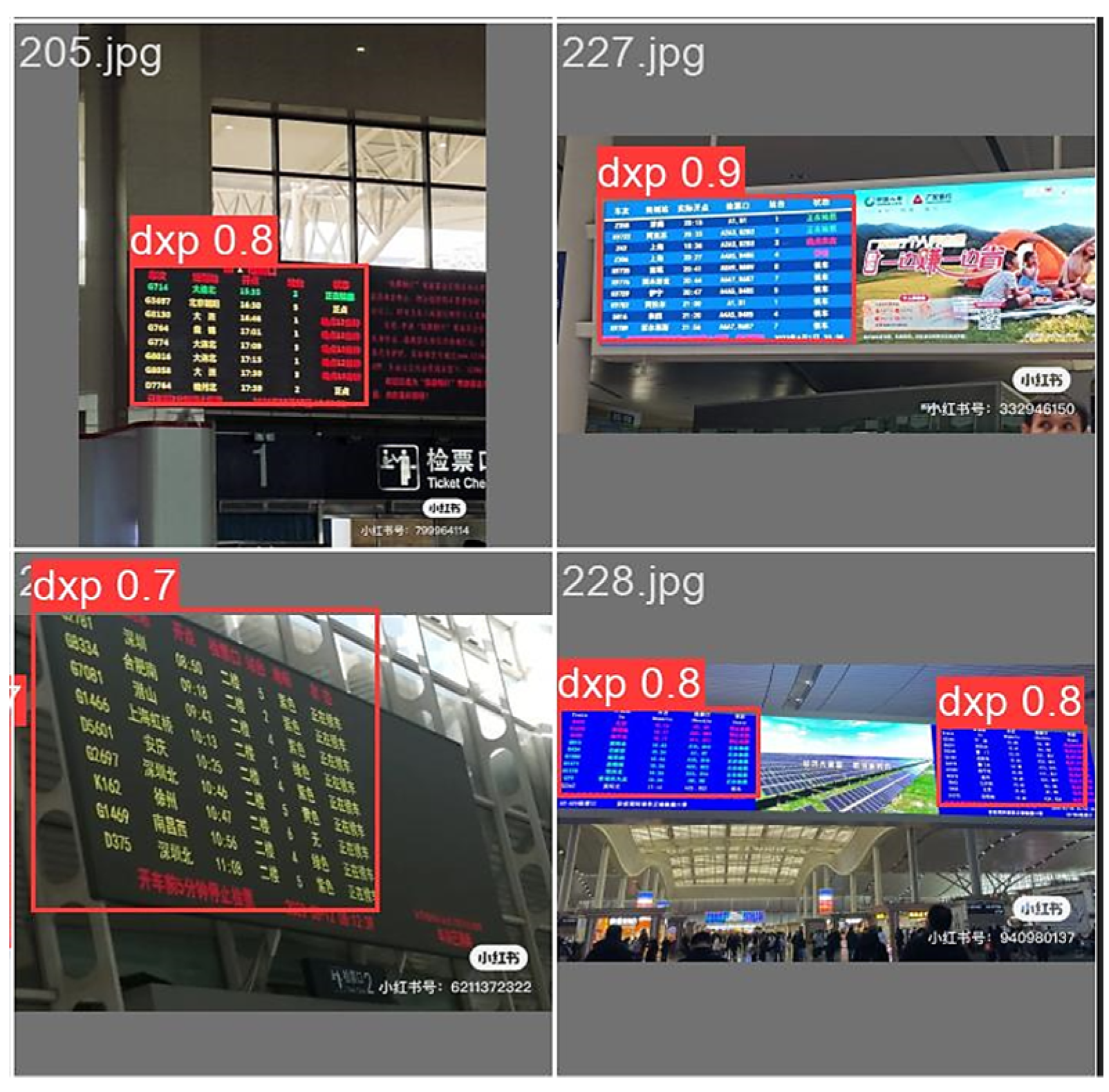
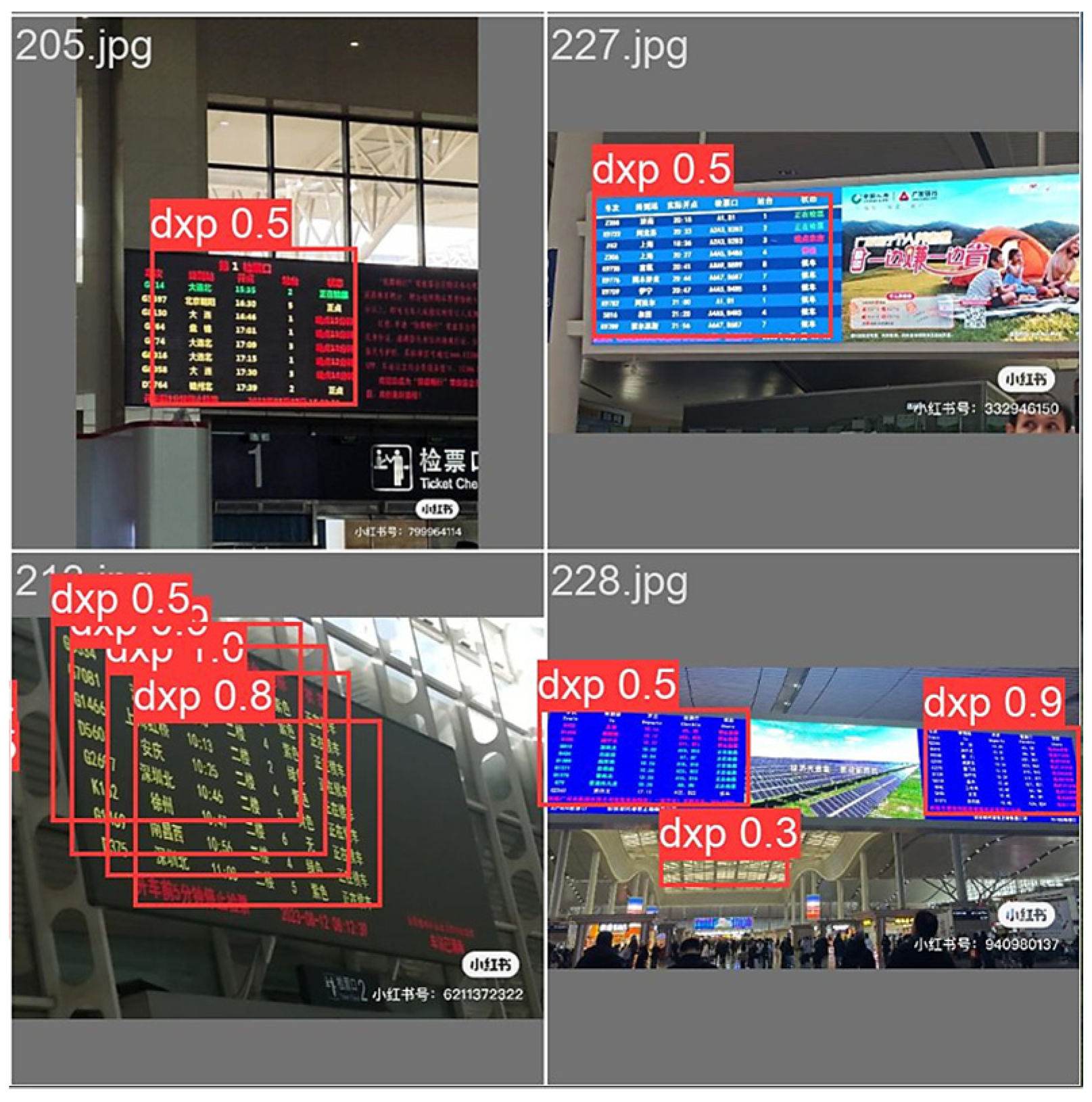
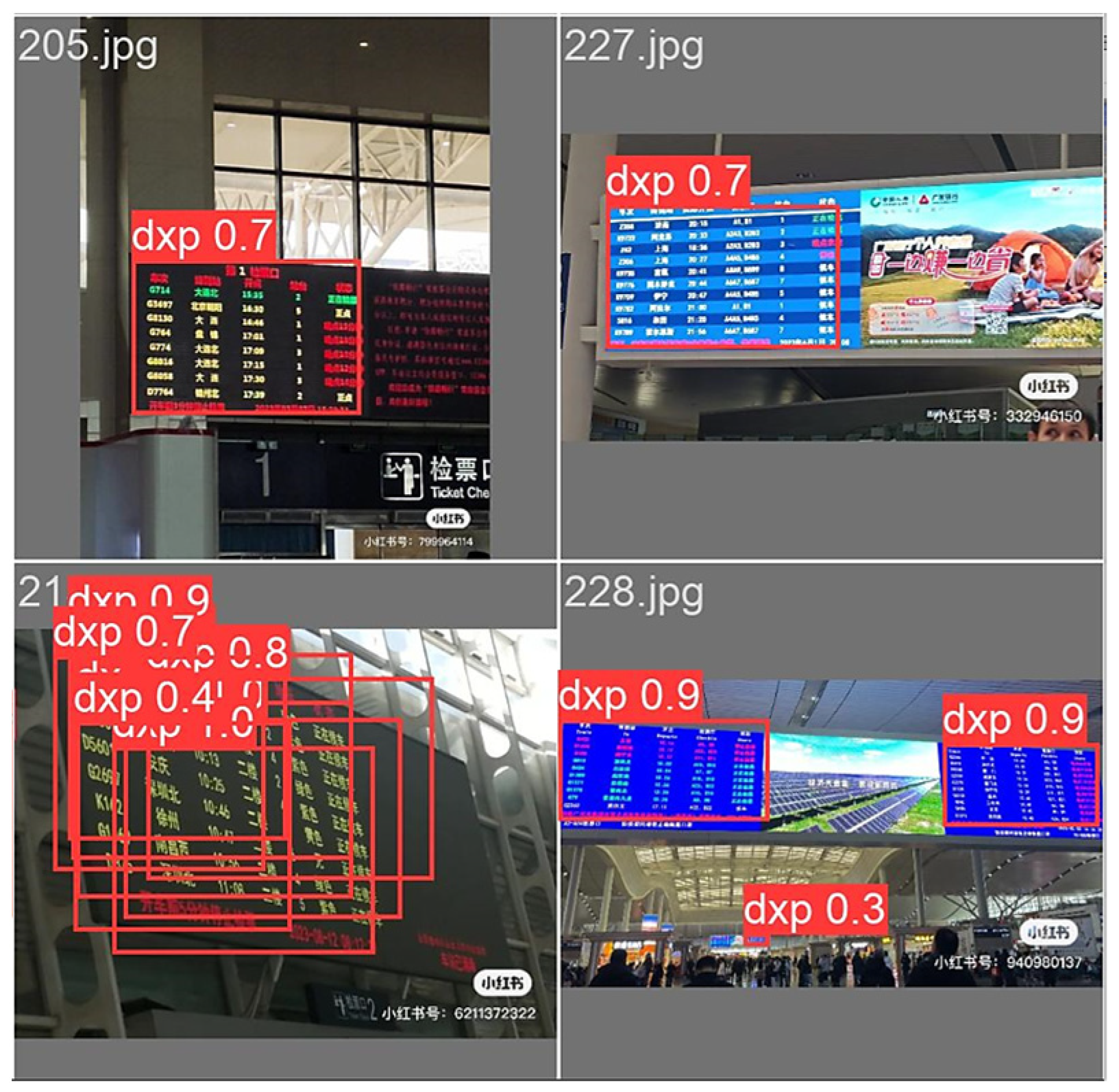
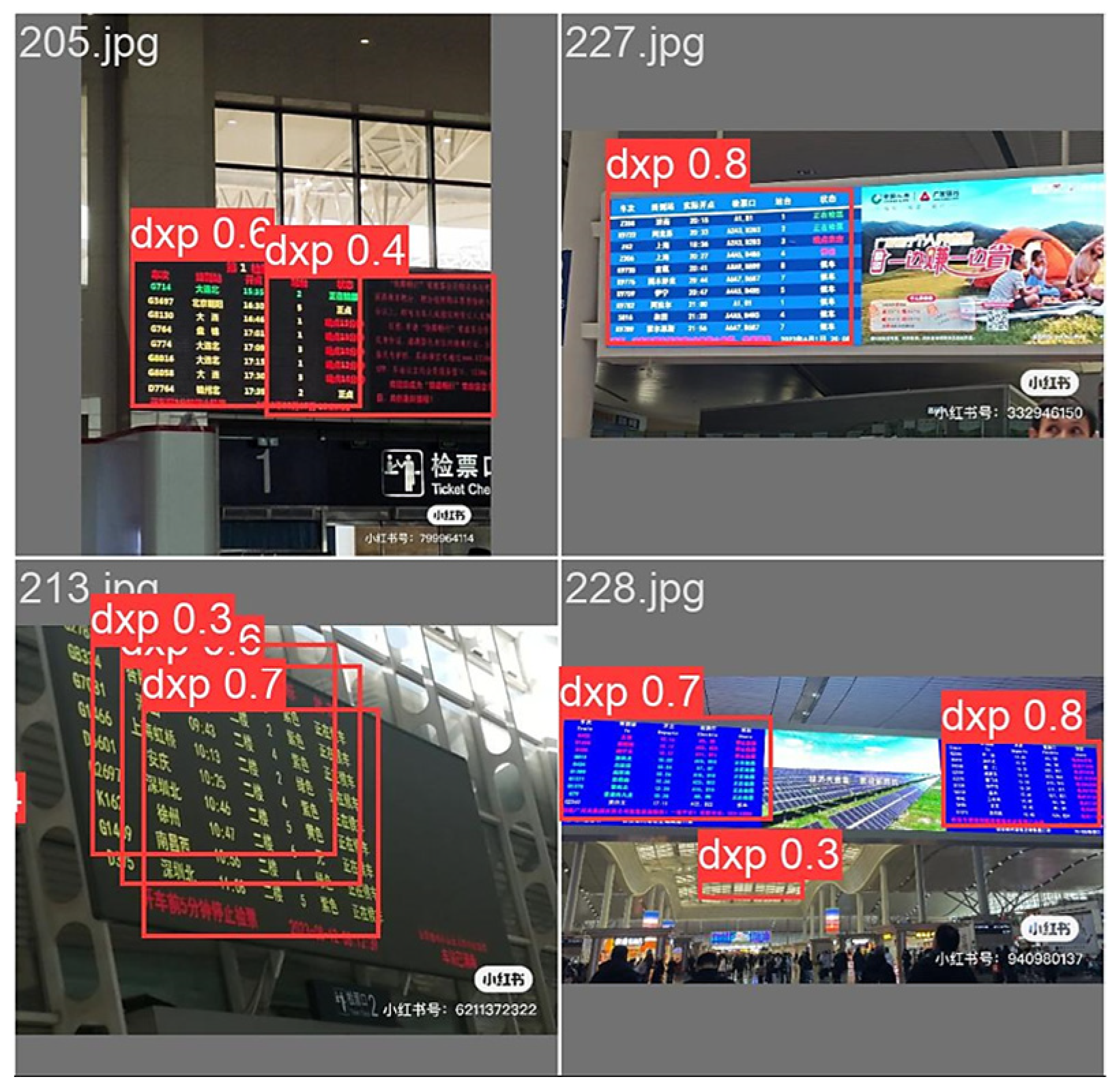
3.4.1. Ablation Experiments
3.4.2. Comparison Experiments
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef]
- Long, S.; He, X.; Yao, C. Scene text detection and recognition: The deep learning era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Zhu, J.; Li, C.; Huang, Y.; Wang, J.; Zhong, S. Research and Application of Text Information Extraction from Vehicle-mounted Remote Sensing Expressway Billboard Data. Remote Sens. Inf. 2022, 37, 126–130. [Google Scholar] [CrossRef]
- Xiao, K.; Dai, S.; He, Y.; Sun, L. Chinese Text Extraction Method from Natural Scene Images Based on Urban Surveillance. Comput. Res. Dev. 2019, 56, 1525–1533. [Google Scholar] [CrossRef]
- Chen, W.; Wang, L.; Tao, D. Scene Text Recognition Method Integrating Soft Attention Mask Embedding. J. Image Graph. 2024, 29, 1381–1391. [Google Scholar] [CrossRef]
- Shivakumara, P.; Phan, T.Q.; Tan, C.L. A laplacian approach to multi-oriented text detection in video. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 412–419. [Google Scholar] [CrossRef] [PubMed]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character region awareness for text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9365–9374. [Google Scholar]
- Ch’ng, C.K.; Chan, C.S. Total-Text: A Comprehensive Dataset for Scene Text Detection and Recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 935–942. [Google Scholar] [CrossRef]
- Wu, W.; Liu, H.; Li, L.; Long, Y.; Wang, X.; Wang, Z.; Li, J.; Chang, Y. Application of local fully Convolutional Neural Network combined with YOLO v5 algorithm in small target detection of remote sensing image. PLoS ONE 2021, 16, e0259283. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Ke, Z.; Yu, D.; Zhang, J.; Jia, J.; Liu, L. Vehicle license plate number recognition algorithm based on mobile edge calculation. Comput. Eng. Des. 2021, 42, 3151–3157. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905. [Google Scholar]
- Ross, T.Y.; Dollár, G.K.H.P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Home—Ultralytics YOLOv5 Docs. Available online: https://docs.ultralytics.com/zh/models/yolov5/ (accessed on 2 July 2024).
- Wang, L.; Bai, J.; Li, W.; Jiang, J. Research Progress of YOLO Series Object Detection Algorithms. Comput. Eng. Appl. 2023, 59, 15–29. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 3139–3148. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Jia, J.; Yang, H.; Lu, X.; Li, M.; Li, Y. Operator Behavior Analysis System for Operation Room Based on Deep Learning. Math. Probl. Eng. 2022, 2022 Pt 8, 6374040. [Google Scholar] [CrossRef]
- Li, R.; Li, P.; Dai, M.; Ma, X.; Li, G. Crowd Counting Estimation Model Based on Multi-View Projection Fusion of Railway Passenger Station Video. Chin. Railw. Sci. 2012, 43, 182–192. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of the Environment | Configuration Name | Releases |
|---|---|---|
| Software Development | detection modelling | development language |
| recognition model | PaddleOCR | |
| development language | Python 3.9 |
| Name of the Environment | Configuration Name | Releases |
|---|---|---|
| Hardware Development | CUDA | 12.3 |
| operating system | Windows 10 | |
| GPUs | NVIDIA GeForce MX230 | |
| CPU | Intel(R) Core (TM) i7-1065G7 | |
| memory | 8203 MB |
| Models | Attention | Fusion | Precision% | Recall/% | mAP50/% | mAP 50–95% | Speed |
|---|---|---|---|---|---|---|---|
| YOLOv5 | - | - | 84.30% | 76.10% | 84.60% | 54.40% | 0.7 ms |
| Change1 | √ | - | 86.10% | 72.10% | 81.80% | 53.40% | 0.7 ms |
| Change2 | - | √ | 85.40% | 75.50% | 86.80% | 53.80% | 0.6 ms |
| Improved YOLOv5 | √ | √ | 90.10% | 76.50% | 86.10% | 56% | 0.5 ms |
| Models | Precision% | Recall/% | mAP50/% | mAP 50–95% | Speed |
|---|---|---|---|---|---|
| SSD | 67.60% | 64.60% | 71.20% | 51.30% | 2.5 ms |
| YOLOv5 | 84.30% | 76.10% | 84.60% | 54.40% | 0.7 ms |
| YOLOV6 | 73.10% | 72.10% | 75.70% | 48.20% | 1.5 ms |
| YOLOV8 | 74.40% | 70.9% | 76.30% | 49% | 1.8 ms |
| Improved YOLOv5 | 90.10% | 76.50% | 86.10% | 56% | 0.5 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, C.; Du, C.; Li, M.; Shi, T.; Sun, Y.; Wang, Q. Research on Closed-Loop Control of Screen-Based Guidance Operations in High-Speed Railway Passenger Stations Based on Visual Detection Model. Electronics 2024, 13, 4400. https://doi.org/10.3390/electronics13224400
Xu C, Du C, Li M, Shi T, Sun Y, Wang Q. Research on Closed-Loop Control of Screen-Based Guidance Operations in High-Speed Railway Passenger Stations Based on Visual Detection Model. Electronics. 2024; 13(22):4400. https://doi.org/10.3390/electronics13224400
Chicago/Turabian StyleXu, Chunjie, Chenao Du, Mengkun Li, Tianyun Shi, Yitian Sun, and Qian Wang. 2024. "Research on Closed-Loop Control of Screen-Based Guidance Operations in High-Speed Railway Passenger Stations Based on Visual Detection Model" Electronics 13, no. 22: 4400. https://doi.org/10.3390/electronics13224400
APA StyleXu, C., Du, C., Li, M., Shi, T., Sun, Y., & Wang, Q. (2024). Research on Closed-Loop Control of Screen-Based Guidance Operations in High-Speed Railway Passenger Stations Based on Visual Detection Model. Electronics, 13(22), 4400. https://doi.org/10.3390/electronics13224400