3.1. Network Structure
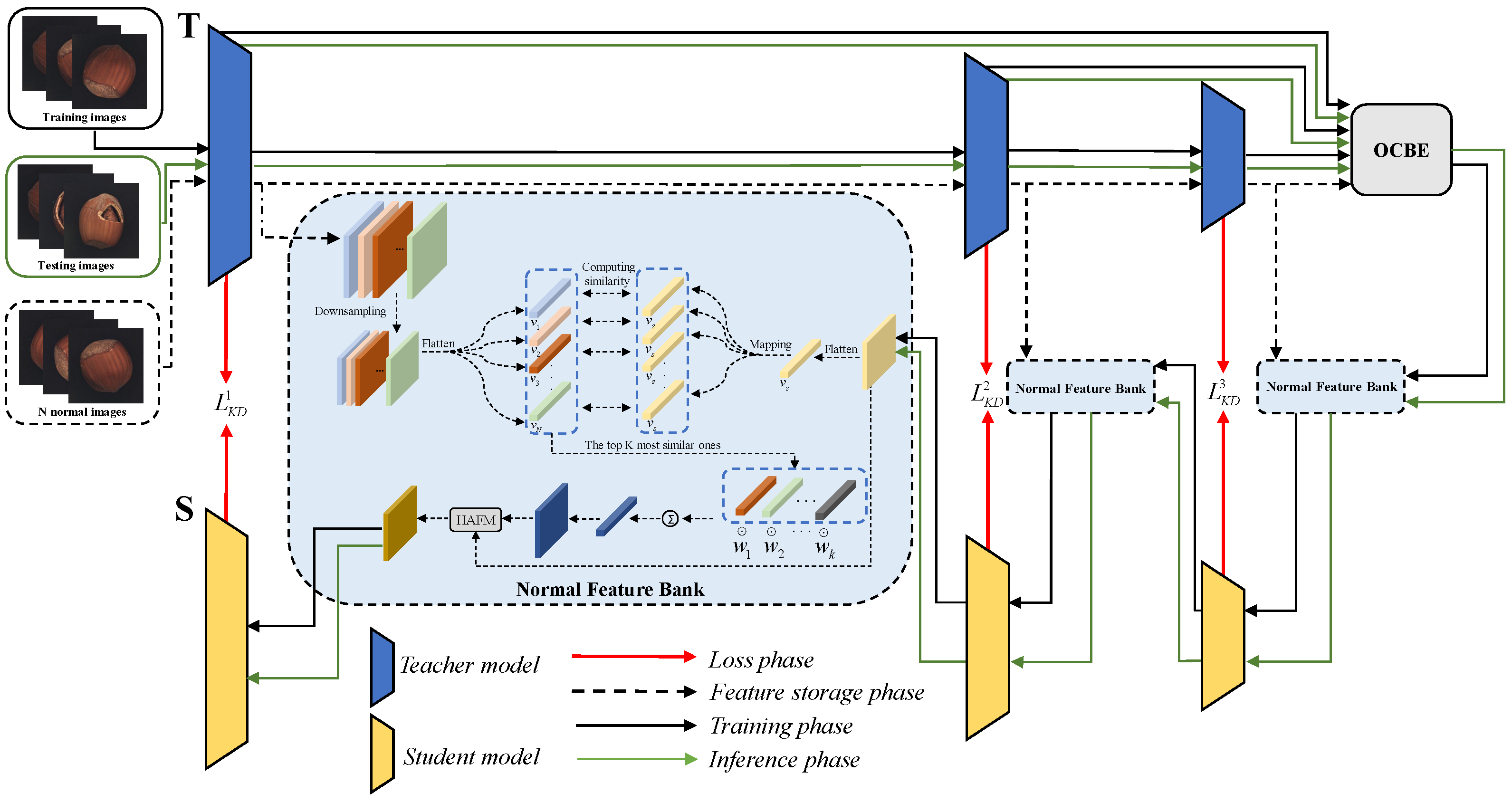
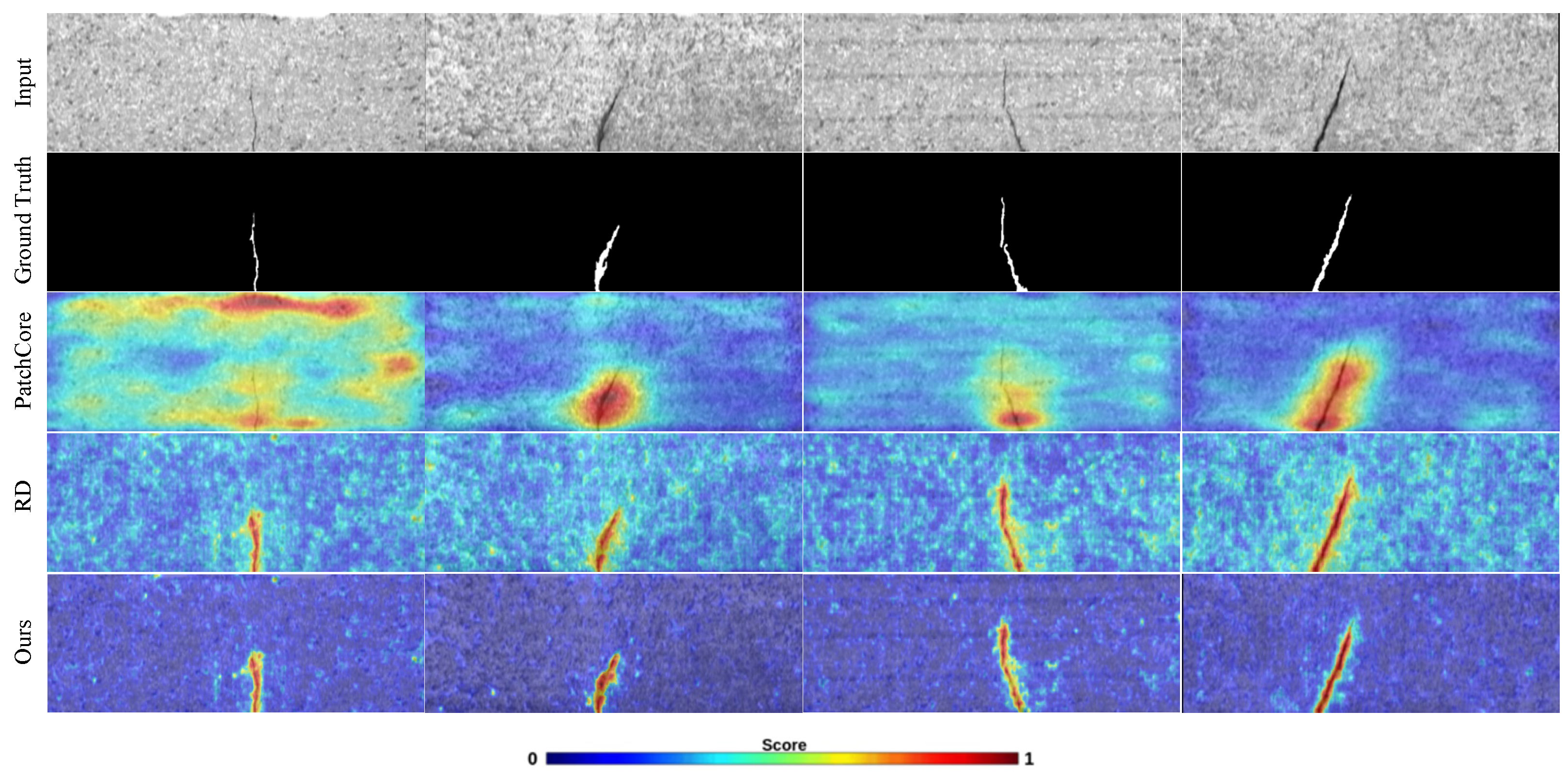
We designed an efficient network framework called Normal Feature-Enhanced Reverse teacher–student Distillation (NFERD) specifically for industrial anomaly detection. As shown in
Figure 2, NFERD consists of three core components: a reverse knowledge distillation network, normal feature bank (NFB), and Hybrid Attention Fusion Module (HAFM). The reverse knowledge distillation network includes a teacher model
T and a student model
S, both of which use the Wide ResNet50 architecture. Among them, the teacher model was pre-trained on the ImageNet dataset, while the student model was trained from scratch. Our goal was to train the student model to mimic the output of the teacher model. As we point out in the Introduction Section, there is a problem of “feature leakage” in the reverse knowledge distillation network, which may result in some normal areas being incorrectly identified as anomalies. To address this issue, we introduce the normal feature bank, which aims at enhancing the student model’s ability to represent normal features, thereby improving the overall anomaly detection accuracy.
Specifically, we designed three NFBs with the same structure, each of which stores normal feature maps extracted by the teacher model at different stages of the network. The feature maps at each stage represent information at different levels of abstraction. We aimed to fuse normal features from the NFB with those extracted by the student model. This allows the student model to not only learn normal feature representations imparted by the teacher but also directly obtain normal features stored in the NFB, thereby strengthening its representation capabilities for normal features. However, how to fuse the feature maps extracted by the student model with those picked up from the NFB is also a challenge. Therefore, we designed a Hybrid Attention Fusion Module (HAFM), which ensures that key spatial details are preserved while maintaining information between channels during the fusion process by processing spatial attention and channel attention in parallel. The specific implementation of NFERD is as follows: Before the model training, we first randomly selected N normal images from the training dataset and input these images into the pre-trained teacher model. Then, we stored the normal feature maps extracted by the teacher model at different stages of the network in the corresponding NFB. During the model training, the defect-free training images were input into a pre-trained teacher model, which extracted feature maps from three different stages of the model. Then, the OCBE module fused these feature maps from three different stages and input the fused feature map into the student model that was structurally opposite to the teacher model. At the same time, the student model could access these NFBs. Afterward, the feature maps extracted by the teacher model at different stages were subjected to loss calculation with those extracted by the students at the corresponding stages. The following subsection provides a detailed introduction to each module.
3.2. Normal Feature Bank Module
We observed a phenomenon in the reverse knowledge distillation model, i.e., “feature leakage”, which may result in normal areas being incorrectly identified as anomaly areas. To address this issue, we introduced the NFB module, which stored some normal features extracted by the teacher model so that the student model could better learn the normal features. First, we randomly selected N normal samples from the training set, which were then input into the pre-trained teacher model. The teacher model processed these samples and generated feature maps within its four different stages. The feature maps from the first three stages were used for the subsequent NFB storage and network training, while the last stage was used to construct the one-class bottleneck embedding (OCBE) block, which was used to fuse the feature maps from the first three stages. To this end, we created three NFBs with the same structure, each dedicated to storing feature maps extracted by the teacher model at different stages. Before storing the feature maps in the NFB, the feature maps were first downsampled through bilinear interpolation to adjust their sizes, ensuring that each size matched the output of the student model in the corresponding stage. Then, we adjusted the number of channels in each feature map through a 1 × 1 convolution operation to match the number of channels extracted by the student model in the corresponding stage.
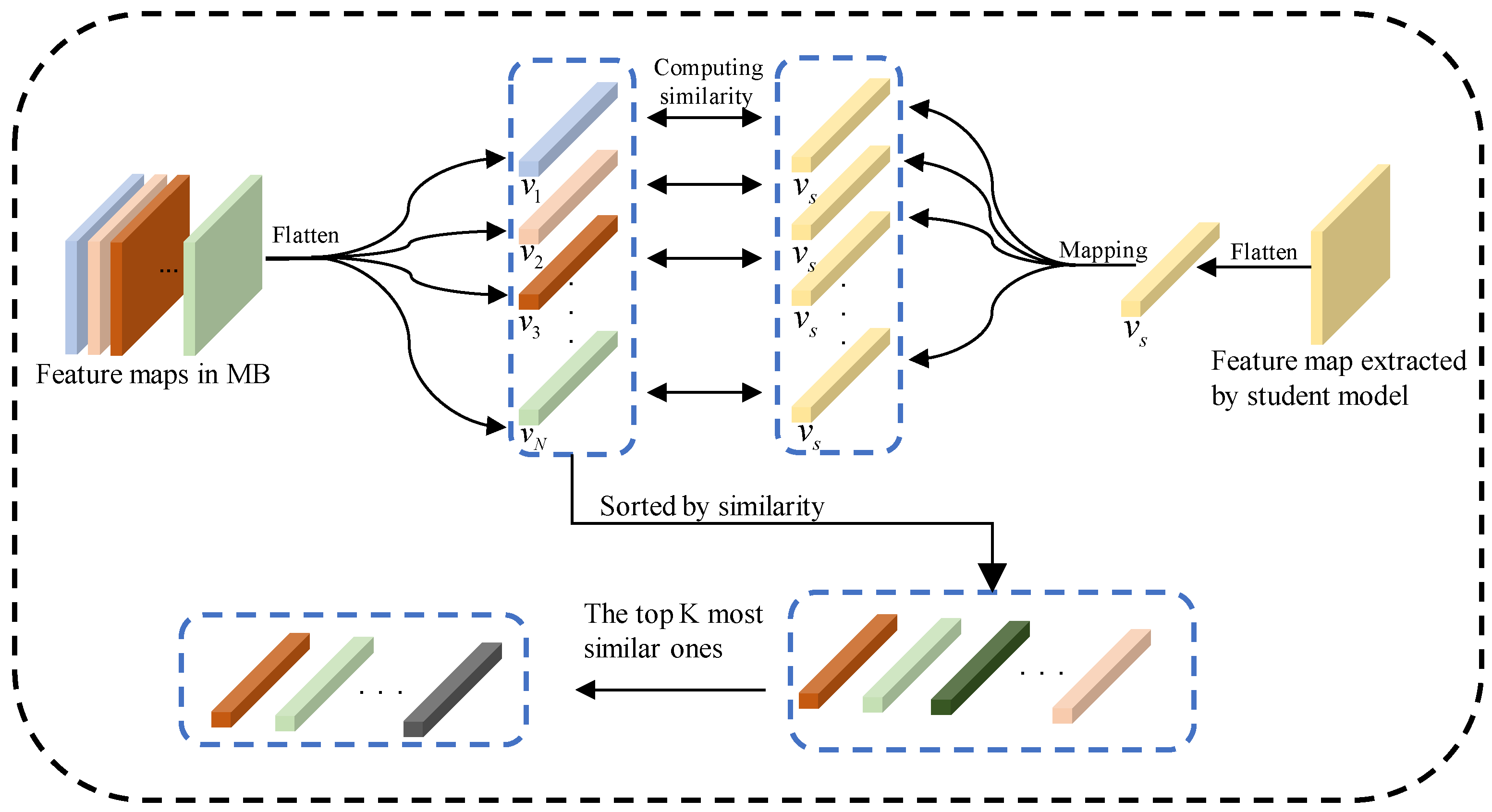
In the student model stage, we hoped to fuse the feature maps extracted by the student model with those in the NFBs. For optimal utilization, we assessed the similarity between the student’s feature maps and all NFB feature maps. Specifically, we flattened the feature maps in NFBs and the feature maps extracted by the student model into one-dimensional vectors to calculate their similarity. The specific steps were as follows: First, we flattened
N feature maps stored in the NFBs into one-dimensional vectors and recorded them as
. A similar flattening operation was also applied to the feature map extracted by the student model and recorded as
. Then, we calculated the cosine similarity between
and
separately, to obtain the similarity set
S. In this way, we could quantify the similarity between the features extracted by the student model and the features stored in the NFBs. Note that
represents the similarity between the feature map extracted by the student model and the
i-th feature map in the NFB. The similarity
and similarity set
S can be calculated by the following formula:
Feature maps with a high similarity usually contain information similar to the feature maps extracted by the student model, which means that these feature maps are more likely to contain information that is more useful for the learning of the student model. In contrast, feature maps with a lower similarity may contain different or irrelevant information, and using this information may interfere with the learning process of the student models. If the similarity between the vector
and vectors
is low, excluding these vectors is advisable, as they may not contain relevant normal feature information. Therefore, we selected
K vectors with the highest similarity from
. Specifically, we sorted the similarity set
S from high to low to obtain the similarity set
. Then, we selected the top
K vectors from
to obtain the similarity subset
. The process of obtaining the top
K most similar ones is shown in
Figure 3.
To enable the student model to obtain more valuable information from the NFB, thereby improving the learning effectiveness and model performance, we calculated the corresponding weight
w for the similarity set
, which represents how many relevant normal features need to be recalled from the corresponding feature maps. The main purpose of introducing weight
w was to ensure that the student model could focus on extracting the most valuable information from the NFB, thereby optimizing the distillation process. By aggregating the weight and corresponding feature vector, the final weighted feature vector recalled from the NFB could be obtained. The weighted feature vector was then reshaped into a weighted feature map and returned to the student model. The weight
w and the final returned feature vector
v could be calculated using the following specific formula:
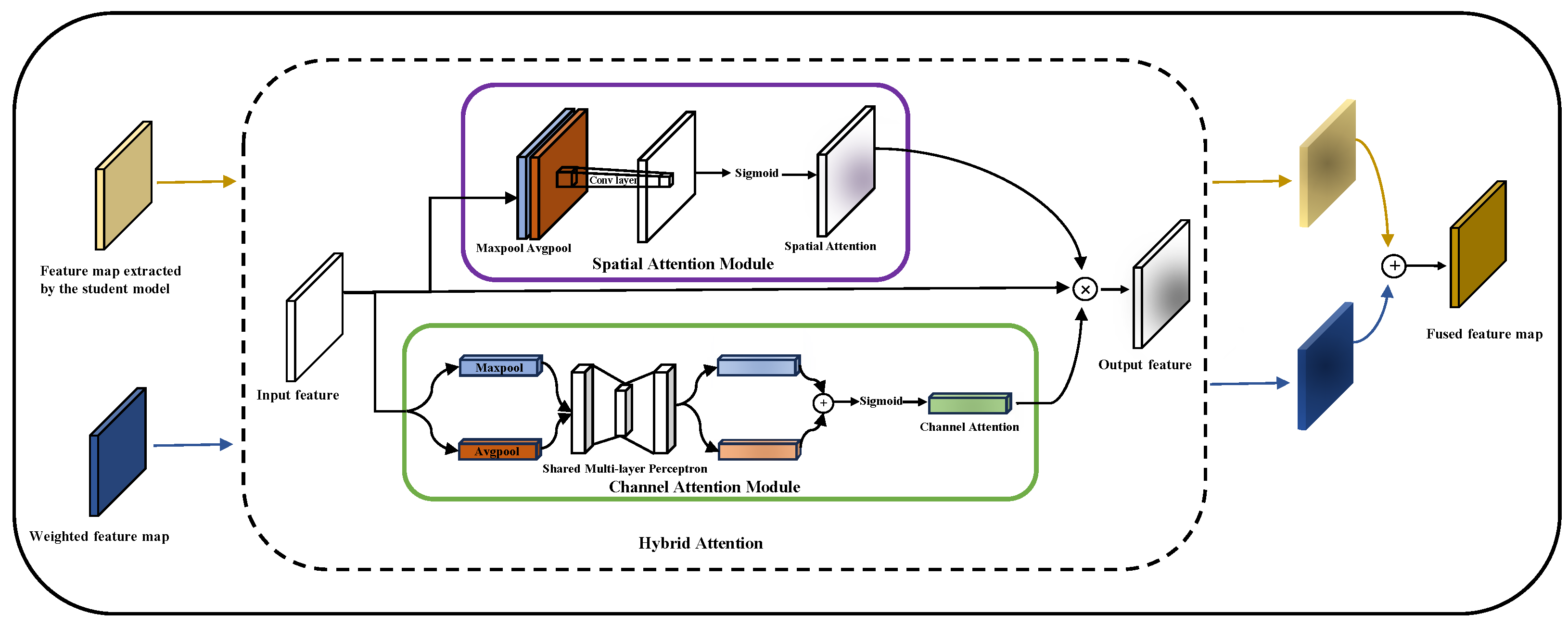
3.3. Hybrid Attention Fusion Module
How to fully utilize these feature maps in NFBs is also an important challenge. Although adding feature maps directly or concatenating them by channel is a common feature fusion method, direct addition may result in information loss, while concatenating them by channel may cause problems of dimensionality expansion and redundant information. In addition, a Convolutional Block Attention Module (CBAM) [
23] sequentially processes the Channel Attention Module (CAM) and Spatial Attention Module (SAM) through concatenation. This serial processing means that the input of the latter module depends on the output of the previous module. In deep network architectures, this serial processing order may cause delays or information loss during transmission. To overcome these limitations, we designed a Hybrid Attention Fusion Module (HAFM), which parallelizes the spatial attention and channel attention to ensure that key spatial details are preserved and inter-channel information is maintained during the fusion process. The designed HAFM is shown in
Figure 4. Specifically, in the HAFM, the spatial attention mechanism is used to capture important regions in the feature map, emphasizing or suppressing feature responses at certain spatial positions by learning a weight matrix. Meanwhile, the channel attention mechanism focuses on the interdependence between different feature channels, assigning a weight to each channel to highlight the more critical features of the task. The parallel processing of these two attention mechanisms will result in a more robust and informative feature representation. Through this, the HAFM can effectively integrate feature information from different sources, providing more refined and targeted feature representations for subsequent task processing.
3.4. Loss Function
Cosine similarity is an effective method for measuring the similarity between feature maps. It is widely used in various applications. In this study, we used cosine similarity to measure the similarity between the output feature maps of the teacher model and the student model. Specifically, we used
to represent the output feature map of the teacher model in the
i-th stage of the network, and
to represent the output feature map of the student model in the same stage. Our training objective was to make the output feature map of the student model as close as possible to the output feature map of the teacher model. Therefore, the two-dimensional anomaly score graph
in the
i-th stage could be calculated using the following formula:
where
represents the spatial position in the feature map. When the value of
is large, it indicates that the similarity between the feature map
and
at position
is small. Given that the teacher model and student model output feature maps at multiple stages, the distillation loss function
that guides the optimization of the student model can be defined as
where
and
, respectively, represent the width and height of the feature map output by the network in the
i-th stage, and
I represents the number of feature maps output by the network and was set to three in this paper.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}