1. Introduction
The study of ball bearings in rotating machines has evolved over time due to technological advancements. Ancient civilisations developed early rotational devices such as waterwheels and windmills [
1]. The rise of industrialisation further prompted innovation in rotating machines. These advancements led to the development of more efficient and sophisticated rotating machines with novel applications in various fields, including transportation, manufacturing equipment, domestic equipment, and power production. Ball bearings, consisting of outer and inner rings, a set of balls, and a cage, reduce friction and improve smooth rotation. They are an integral part of any rotating machinery and are responsible for 40 percent of machinery breakdowns [
2,
3,
4]. These breakdowns are associated with their installation, poor maintenance strategy, fatigue, and regular wear.
The performance and efficiency of rotating machinery are greatly affected by bearings. Unexpected bearing faults often develop from their installation, maintenance strategy, fatigue, and regular wear, posing diagnostic challenges. These faults can be classified into two categories: distributed defects that affect a wide area, and localised defects that start as single-point defects (ref
Figure 1). Inspection techniques like visual checks, ultrasound, and vibration analysis [
5] help identify these faults, which is vital for machinery reliability.
Distributed Defects: These defects impact bearings significantly and are challenging to identify based on specific frequency. They occur due to various reasons such as heat, vibrations, noise during operation, production errors, and excessive loads [
6]. These faults can cause early rotor system failure or severe damage, making their detection challenging [
7]. However, several inspection techniques such as visual observations and non-destructive methods can be employed [
5].
Localised Defects: These faults are single-point issues caused by flaws in the manufacturing process, quality of raw material, or fitting errors [
8]. Over time, as the bearings age, these localised defects progress and expand, leading to distributed fault patterns. These manifest as distinct vibrations, minimal changes in the load torque, and the emergence of multiple frequencies [
9,
10]. The distributed and localised defects pose a big problem to the throughput and efficiency of modern rotating machines. A timely identification of these faults can greatly improve the efficiency of rotating machines, and machine learning has a huge role to play in this regard.
By investigating failures, industries can identify weaknesses and refine their designs and manufacturing processes, leading to better quality. When products have defects or fail to meet standards, it results in unhappy customers, a decrease in market share, and increased costs due to quality-related problems such as recalls or repairs [
11]. Even brief failures can impact continuous operations, leading to missed deadlines, financial losses, and delayed deliveries. To keep the production line running smoothly and safely, it is essential to have a well-organised system in place that effectively manages all aspects of the equipment, including machines and components. This requires a system that can diagnose potential breakdowns and taking proactive measures to prevent any impending faults or downtime. Implementing preventive measures through condition monitoring systems uncover cost-effective solutions, enhance safety by identifying and minimising hazards, and contribute to product development and innovation by providing valuable insights for iterative improvements. In the past, preventive maintenance techniques like time- and usage-based maintenance, fixed replacement intervals, and manual data analysis have been used. While these traditional methods provided some level of preventive capability, they were often reactive, time-consuming, and imprecise. In future industrial systems, the usage of advanced technologies like Internet of Things (IoT) [
12], digital twin [
13], and data-driven approaches like big data analytics, machine learning, and cloud computing [
14,
15,
16] are being explored and employed.
Compared to existing manual data analysis techniques, the utilisation of Machine Learning (ML) has the potential to perform the function of forecasting and anticipating malfunctions [
17] through the creation of algorithms that can detect patterns from data and use that understanding to make accurate predictions or choices. In particular, machine learning algorithms are very good at recognising anomalies in data, learning from patterns, data analysis, and optimisation of maintenance schedules. In recent years, machine learning [
18] has become widely accepted and is being employed in a broad range of applications. There is hardly an area of everyday life where machine learning or deep learning algorithms are not finding their applications. Today, we see their application in fields such as self-driven cars [
19], smart management of energy consumption in renewable energy communities [
20,
21], healthcare, transportation, supply chain and operations, image classification, and fault detection [
16,
22,
23], to name a few. The integration of machine learning into fault detection for predictive maintenance is crucial as it facilitates the examination of vast quantities of information to recognise patterns and produce precise forecasts. Machine learning supplements maintenance planning in industries by analysing extensive datasets pertaining to a production process [
22], detecting malfunctions and anomalies, and enabling proactive preventive maintenance strategies. Machine learning as a branch of artificial intelligence has proven to be a potent instrument for creating intelligent predictive algorithms across numerous applications. However, the effectiveness of these applications is contingent upon the suitable selection of the machine learning technique [
22].
This study aims at exploring machine learning models that can accurately analyse vibration data collected from ball bearings. To achieve this goal, vibration data under various operating conditions are collected. Due to the availability of labelled target data, supervised learning is considered. Raw time-series data are transformed into a structured dataset with statistical features, which are then used as input data. Random Forest (RF), Linear Regression (LR), Support Vector Machine (SVM), and Extreme Gradient Boost (XGBoost) algorithms are trained on the dataset before testing and comparing them for performance evaluation purposes. These models are compared with a neural network long short-term memory (LSTM) to determine the model that provides the best classification result for predictive maintenance of ball bearing systems. The success metrics depends on how well these trained models can predict different health states of the ball bearing. The models can be useful in industrial analysis to optimise machine safety and reduce maintenance cost. Comparison results show that XGBoost gives the best trade-off in terms accuracy and computation time.
The rest of this paper is organised as follows.
Section 2 gives a detailed overview of the related work.
Section 2 also details the novelty and contribution of this work.
Section 3 explains the experimental setup developed and used in this work. This section gives details about the experimental configuration, data preprocessing, feature engineering, and data transformation. The simulation results and critical analysis of those results is presented in
Section 4. This work is concluded in
Section 5 with a discussion on future work.
2. Related Works
In recent years, machine learning, which is a sub-field of artificial intelligence [
18], has become widely accepted and has been employed in a broad range of applications such as self-driven cars [
19], forecasting and anticipating malfunctions [
17], smart management of waste water treatment [
24,
25,
26], smart building in healthcare [
27,
28], transportation, supply chain and operations, image classification, and fault detection [
16,
22,
23]. The integration of machine learning into fault detection for predictive maintenance is crucial as it facilitates the examination of vast quantities of information to recognise patterns and produce precise forecasts. Prognostic and diagnostic maintenance models are two basic approaches to ML-enabled predictive maintenance that are used to identify and address equipment issues before they lead to failure. Diagnostics maintenance involves using various tools and techniques to inspect equipment and identify any issues after they have occurred [
29]. Vibration analysis is utilised to detect faults in rotating machinery or perform regular inspections to identify wear or damage in components. Once these faults have been identified, maintenance personnel can take action to repair or replace the affected parts. Prognostic maintenance, on the other hand, uses data analytics and machine learning algorithms to analyse data from sensors and other sources to identify patterns and trends that may indicate future issues [
29]. This approach monitors the performance of a machine and uses data analysis to predict when it may fail based on changes in performance metrics. Prognostic maintenance allows maintenance personnel to take proactive steps to address potential issues before they lead to unplanned downtime or equipment failure.
In the research work of [
22], the authors explored Support Vector Machine (SVM), Artificial Neural Network (ANN), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Deep Generative Systems (DGN) to identify mechanical part failure by using low-cost sensors for preventive fault detection. The study highlights their effectiveness in fault detection with CNN and RNN resulting in higher accuracy. However, this comes with higher computational costs, the need for reliable data and labelling, and the potential for treating fault diagnosis as a clustering problem. The authors in [
2] presented a time-frequency procedure for fault diagnosis of ball bearings in rotating equipment using an Adaptive Neuro-Fuzzy Inference System (ANFIS) technique for fault classification. It combines a wavelet packet decomposition energy distribution with a new method that selects spontaneous frequency bands utilising a combination of Fast Fourier Transform (FFT) and Short Frequency Energy (SFE) algorithms. This method is potentially effective and efficient for bearing fault detection and classification in various conditions, making it appropriate for online applications. In [
30], the researchers performed experimental findings involving a comprehensive analysis of the roller bearing’s inner ring and cylindrical rollers. Several conventional techniques such as visual observation, Vickers Hardness (HV) testing, 3D Stereo-microscopy, Scanning Electron Microscopy (SEM), and lubricant inspection were employed. The study attributes severe wear to three-body abrasive wear and the introduction of metallic debris from broken gear teeth outside the roller bearing. Lubricant inspection was performed incorporating Fourier transform infrared spectroscopy, which concludes that the lubricant had not deteriorated significantly. The authors of [
31] proposed the self-attention ensemble lightweight CNN with Transfer Learning (SLTL), combining signal processing via continuous wavelet transform (CWT) and integrating a self-attention mechanism into a SqueezeNet-based model for fault diagnosis. This method can be utilised on hardware platforms with limited capabilities while delivering high performance levels with a reduced amount of training dataset. SLTL achieves significant classification accuracy while keeping model parameters and computations low. However, challenges faced by the authors include manual sample selection and the absence of adaptive methods, hampering its optimisation and resource-efficient deployment.
In [
32], the authors employed frequency domain vibration analysis and envelope analysis, in combination with Kernel Naive Bayes (KNB), Decision Tree (DT), and k-nearest neighbors (KNN), to detect bearing failures. The authors in [
33] incorporated a Random Forest (RF) classifier and Principal Component Analysis (PCA) to detect bearing failures in induction motors utilising a time-varying dataset while similar work of [
34] considered using Linear Discriminant Analysis (LDA), Naive Bayes (NB), and SVM to evaluate waveform length, slope sign changes, simple sign integral, and Wilson amplitude for bearing faults detection in induction motors.
In the light of the comprehensive literature review, it is evident that a lot of existing work has previously used conventional predictive maintenance mechanisms to improve the efficiency of industrial systems. There is some recent work that has used deep learning models but mainly for mechanical part failure prediction. Deep learning models are often favoured for vibration data analysis, which is well suited for complex and very large datasets. However, this study introduces a comparison framework for ML models and a deep learning model. Statistical methods are employed to extract features from vibration signals, while ensemble techniques serve as tools for feature classification. This research incorporates methodical experimental setup and modelling for bearing state classification. These features are fed into the suggested classifiers to diagnose bearing faults state using multi-class logic. Finally, this study presents a holistic view of various machine learning models, indicating the advantage of using ensemble method like XGBoost for classification prediction of ball bearings, with a specific emphasis on the uniqueness of each model’s computational efficiency. To the best of our knowledge, this kind of comprehensive work has not been conducted before for the predictive maintenance of ball bearing-based mechanical systems. The contributions of this work are also summarised below:
Employment of statistical methods for feature extraction and usage of ensemble techniques for feature classification of vibration data of the ball bearings.
Development of framework for various machine learning and deep learning algorithms’ performance evaluation.
Comprehensive comparison of different machine learning and deep learning algorithms’ performance with a special emphasis on their computational efficiency.
4. Results and Analysis
This section provides a complete summary, interpretation, and analysis of the results of this study. The performance metrics employed are examined to enhance the depth and clarity of the models’ interpretation. The tests were conducted on a computer with an Intel Core i5—12450H processor featuring Octa core processor with a burst speed of 4.4 GHz. This machine had 16GB of RAM, NVIDIA RTX 30 Series 3050 graphics card with 4 GB RAM GDDR6, and ran on a 64-bit Windows 11 operating system. Once the initial setup and configuration were accomplished, standardisation tests were conducted prior to the main tests to prevent background tasks from influencing the model execution process.
4.1. Exploratory Data Analysis
The crucial step of this section provides understanding and insights into the dataset to uncover patterns, inconsistencies, trends, and relationships within the vibration data as discussed in
Section 3. In
Figure 3, four test files are presented. The patterns show how the vibration varies over time as the bearings go through their cycles. The vibration intensity is measured in “g” units and ranges from −0.8 to 0.8. The cycles, numerically identified from 0 to 20,480, represent the operational phases of the ball bearings. Within the vibration data, traceable spikes emerge. Between cycles 3000 and 8000, there are noticeable spikes indicating moments when vibration suddenly increased quite a bit and then rises significantly. These occurrences likely indicate sudden changes in operating conditions or as a result of external factors impacting its performance. Between cycles 11,000 and 16,000, there is a recurring pattern of spikes in the vibration amplitude. This anomaly shows a consistent occurrence in the vibration behaviour of the ball bearings during this cycle range.
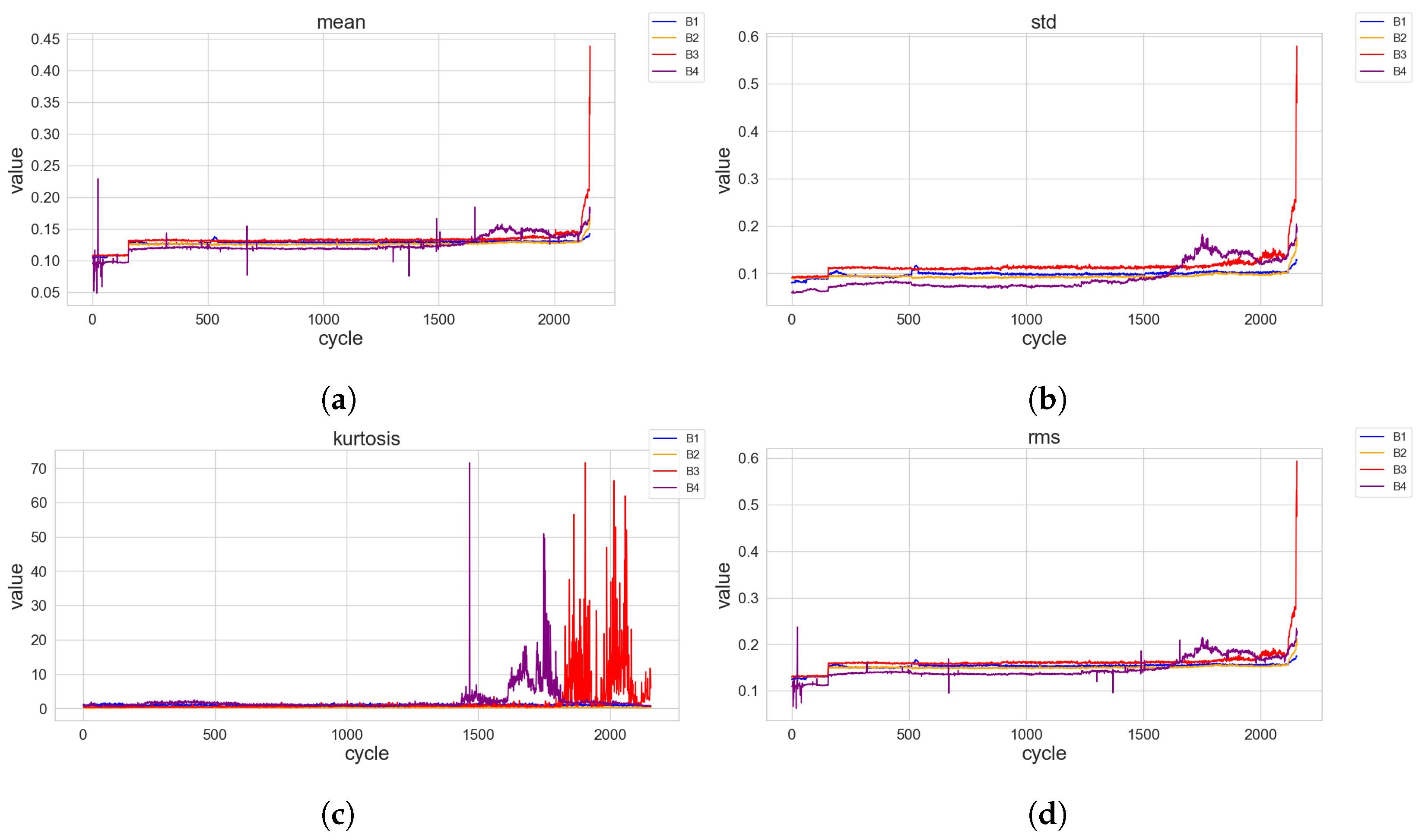
The data had been carefully cleaned to eliminate potential outliers in terms of noise, irregularities and abnormal vibration readings that might affect the accuracy of the feature extraction process, as depicted in
Figure 4. By employing an array of statistical and mathematical techniques, diverse range of significant features from the vibration data were computed for a more insightful knowledge. Fundamental measurements such as mean, standard deviation, kurtosis, root mean square (RMS), skewness, entropy, maximum amplitude, peak-to-peak amplitude, crest factor, clearance factor, shape factor, and impulse were involved.
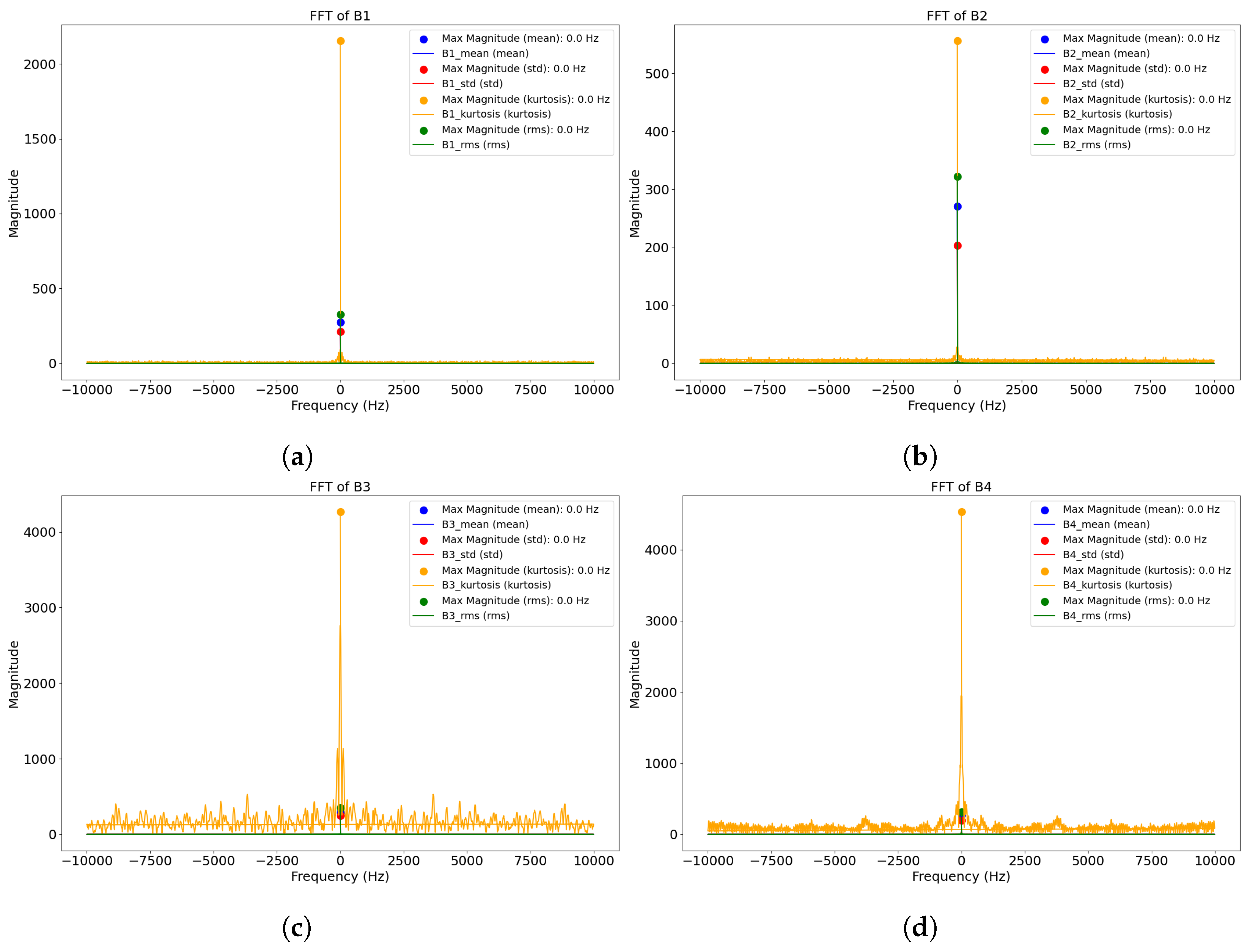
Fast Fourier Transform, Cepstrum Analysis, and Amplitude Envelope were employed to explore the periodic components and anomalies in the vibration signals are illustrated in
Figure 5,
Figure 6 and
Figure 7. In the Fast Fourier Transform, it can be deduced that the bearings have energy distributed symmetrically around zero frequency (both positive and negative showing a projecting DC offset close to 0) with a dominant frequency component at about 290 magnitudes for mean, standard deviation, and root mean square. The Cepstrum Analysis reveals a significant Cepstrum value around data point zero, indicating an excited frequency close to 0 Hz. The Amplitude Envelope plots shared more insights into the relationship and trends between the data signals and the amplitude envelope. This suggests that there is a significant magnitude of energy around 0 Hz, indicating dominant harmonic in the signal while the presence of energy forming a “tiny cone” shape indicates the presence of noise or other low-frequency components in the signal. This perspective is based on the zoomed-out image represented in
Figure 5,
Figure 6 and
Figure 7. We know that the fault for inner race and ball spin has been determine by [
36]. However, in reality this is not the case. The kurtosis feature of the bearings has a concentrated distribution of signal levels across the frequency series with the presence of short spikes signifying distinct periodic events. Close to the zero frequency, there is the presence of widening DC component with rapid decline in energy as it moves upwards in magnitudes.
4.2. Performance Metrics and Model Evaluation
It is essential to carefully select the appropriate metrics when assessing the effectiveness of ML models on ball bearing vibration data. Considering the characteristics of the vibration data and the importance of identifying early faults in ball bearings, the following performance metrics were considered:
- 1.
Accuracy provides an overview of how the model’s true outcomes align with the actual outcomes. In the case where faults are uncommon, a high accuracy could be misleading. For instance, a model that predicts “no fault” can have a misleading high accuracy.
- 2.
Precision informs how many of the predicted positives are actual positives. In rotating machines, a model with high precision minimises false alarms, ensuring reliability and productivity.
- 3.
Recall evaluates the model’s efficiency at detecting and spotting all true positive instances. It is essential for ball bearing health monitoring, because industries want to ensure as many true positives as possible are detected. Misclassifying a fault could lead to mechanical failure, leading to significant financial loss or safety risks.
- 4.
Harmonising precision and recall, thereby providing a unified performance metric like F1, is essential. This balance aids imbalance data such as infrequent fault occurrences when comparing different models.
Different ML models are evaluated based on the four performance metrics mentioned above. The analysis of ML models covers the initial outcomes produced by each model and a detailed exploration of hyperparameters aimed at optimising their performance at various stages of the models evaluation process. Further details on the different ML model results are provided next.
4.2.1. Logistic Regression
After 20 test trials, the best outcome (lowest value) was an objective value of about 0.3179. This corresponds to an accuracy of 1–0.3179. The most effective setting for the C-value was about 95.28. In
Table 1, the model shows accuracy of 67.71% of all predictions made by the model are correct. The harmonic mean of Precision and Recall have given a better assessment of the incorrectly classified cases than the accuracy outcome. It is essential to consider the F1 score when data classes are not evenly distributed. Of all positive predictions made by the model, about 79.45% are correct. From all actual positive cases, the model successfully detects around 55.41% of them.
4.2.2. Random Forest
A broad hyperparameter tuning was conducted to optimise the model’s performance. The primary goal was to achieve the highest accuracy and reduce inconsistences as much as possible. During the optimisation process, various sets of hyperparameters were assessed while undergoing 20 trials with each trials testing different combination of hyperparameters. The best configurations identified were: ‘n_estimators’: 967, ‘max_depth’: 10, ‘min_samples_split’: 4, ‘min_samples_leaf’: 2, ‘max_features’: ‘sqrt’}. These optimal settings attained a good accuracy rate of 84.46%, as shown in
Table 2. This suggests that in all 85% of the instances, the RF model made true predictions. A high precision value indicates that a significant amount of the RF model’s positive predictions were correct as it accurately detected about 79.71% of all true positive cases.
4.2.3. Support Vector Machine (SVM)
A study was conducted to optimise the SVM model. The objective was to fine-tune the model’s performance by leveraging different hyperparameters. Each trial represented a unique combination of these hyperparameters, and after each test, the model’s performance was assessed. For instance, during the first trial, the model employed a linear approach with parameters such as C = 9.63, gamma = 10, coef0 = −0.28, and class_weights = None. This trial resulted in an accuracy of approximately 0.5560. After 20 trials of study, the model indicated the average cross validation score of about 0.7420. Once the model was fine-tuned, an accuracy value of 83.69% was achieved while F1 score was approximately 0.8465, depicting the model’s capability in balancing precision and recall.
Table 3 shows the SVM classifier made positive predictions with about 91.37% accuracy and managed to correctly detect about 80.94% of all true positive instances.
4.2.4. Extreme Gradient Boosting (XGBoost)
The non-boosted XGBoost classifier was initially employed for this application to compare with the performances of the other classifiers. The XGBoost accurately predicted about 85.01% of cases in the test dataset, which is a strong performance.
A new hyperparameter optimisation task was initiated to improve the performance of the model. This task consisted of 20 trials, with the first iteration giving the best improvement with a value of around 0.9661. The key hyperparameters tested involved a learning rate of 0.2469 and the use of 535 estimators. The model presented an overall improvement when compared to other models employed in this study. As shown in
Table 4, the model achieved about 96.61% accuracy, which reveals the percentage of predictions made from all predictions. A harmonious balance between the accuracy of positive predictions and the fraction of positives that were captured was approximately 0.9710. The values 0.9810 and 0.9617 of precision and recall, respectively, show a high consistency of the model’s predictions. The average cross validation score on the training data is approximately 0.8516. The model learning curve is represented in
Figure 8.
4.2.5. Long Short-Term Memory (LSTM)
According to literature, the LSTM, which is a type of RNN designed to handle sequence of data such as time series has been employed as a deep learning model to compare with other machine learning models in terms of performance and computational time. The LSTM model was trained for 50 epochs with both training and validation metrics recorded at the end of each epoch. The loss and accuracy on the training set started at 1.2653 and 0.5326, respectively, and by the tenth epoch, they improved to 0.8678 and 0.5977, respectively. This is an indication that the model was learning and improving its predictions on the training set over time. The validation loss and accuracy provide insight into how the model might perform on unseen data. There exist a decrease in validation loss and an increase in validation accuracy across the epochs. However, there were variations, indicating model overfitting.
To improve the training process and model convergence, amplitude scaling was also employed to transform the input data. The boosted LSTM model correctly detected about 79.30% of the instances, as shown in
Table 5. While a better value of 0.7748 F1 score was achieved over the non-boosted algorithm. This indicates a reasonable balance between the precision and recall. Precision numbers indicate that 86.83% of the instances detected as positives are true positives of the ball bearing health state. The model was able to identify about 73.87% of the true positive instances for each class. After 50 tested epochs, ‘unit’ and ‘dense_units’ values of 128 and 128 were found as the best choices, respectively. Activation was evaluated with ‘tanh’ and ‘softmax’, with ‘tanh’ being the better configuration. The Adaptive Moment Estimation (Adam) was employed to combine the Root Mean Square Propagation (RMSprop) and Momentum for a faster convergence and effectiveness of the model. The training and validation accuracy for this model is shown in
Figure 9.
4.3. Computational Time Analysis
To achieve an efficient training time suitable for real-world applications, the time taken for each model’s training was used to evaluate its computational efficiency. The models were configured and optimised. The parameters of the ML models, including the number of LSTM units and dense units, were tuned to find the best configuration. The start and end times of each model training were recorded to calculate the training time for each experiment. The analysis reveals that the training time for each model varied based on the hyperparameter configurations. The training time variations are shown in
Table 6, highlighting the impact of optimising algorithm parameters on computational efficiency.
4.4. Comparative Analysis
In a data-driven industrial setting, the evaluation of model performance is of great necessity. A thorough comparative analysis of various models is often conducted to determine a well-suited process for a given task. Each of Equations (
1)–(
4) plays a distinct and fundamental role in the evaluation process. The comparative analysis highlights the vital role of performance metrics in assessing the effectiveness of ML models. The selection of the most appropriate model focuses on the specific objectives of the task at hand. The performance metrics comparison of different ML models under consideration is shown in
Table 7.
In the context of accuracy, XGBoost achieved an overall measure of 96.61% at a training time of 0.76 s, indicating how well the model predicted both the positive and negative categories. This reflects the research work of [
52], who demonstrated the effectiveness of XGBoost in various classification tasks. In contrast, Logistic Regression recorded the lowest accuracy of 67.71% at a training time of 0.13 s. The XGBoost model recorded the highest F1 score of 97.10%, which offers a balanced metric especially in cases of imbalanced class distribution. On the other hand, Logistic Regression logged the lowest value at 59.72%. This inconsistency highlights the challenges of Logistic Regression in imbalanced datasets, as discussed by [
53].
It is evident that XGBoost is not only superior in terms of performance but is also significantly efficient in terms of training times. This efficiency can be attributed to its use of parallel and distributed computing, enabling it to reach optimal solutions faster. Furthermore, XGBoost introduces randomness in its logic, making it more robust to over-fitting, and it handles missing values proficiently, resulting in accurate tree structures.
Based on these comparative analysis and observations, it is evident that XGBoost consistently out-performed other models across various key performance metrics evaluated in this study. It is also noteworthy to recognise the performance of RF, which aligns with the findings of [
54], surpassing the more sophisticated LSTM exhibiting accuracy value of 79.30% at a training time of 80.58 s. This could suggest that, for this dataset, tree-based models might be more efficient than deep learning models. On the other hand, the under-performing Logistic Regression suggests its shortcomings for this dataset.
5. Conclusions
In the modern industrial systems, inefficient operations, unplanned plant downtime, and huge maintenance expenses can be caused by mechanical failures in the plant. To avoid this, conventional preventive maintenance mechanisms like time-based maintenance, oil analysis, and manual data analysis have been used previously. However, these conventional methods are time-consuming, reactive, and imprecise. Recently, advanced technologies like IoTs, big data analytics, machine learning, and cloud computing have been employed to make the modern industrial systems more efficient. In this work, we have used different machine learning models because of their high performance, ability to handle large data and adaptability to learn quickly from their experience. For comparison among different machine learning models, we have developed a framework to handle the large data from four ball bearings and extract useful features. The data preprocessing and feature extraction provided a significant insight of the data. This aided a better understanding of important patterns from vibration signals that are vital for fault detection. By comparing five distinct machine learning models, a holistic view on their computational efficiency and capability in identifying different fault categories was achieved. This comparison made it obvious how each model performed with ball bearing health status data and highlighted the effectiveness of early fault detection in modern industrial systems.
This study leverages machine learning models to evaluate various health status of four ball bearings with a total 2155 samples of vibration signals. Among the machine learning models compared, XGBoost emerges as the most favoured choice in predicting about 96.61% of all instances and 96.17% of all true positive instances at a training time of 0.76s. This study also demonstrated the superiority of XGBoost over other models under consideration when comparing the ratio of accuracy to computational time while detecting fault occurrences of the ball bearing. In the future, we would like to generate indigenous data and expand the dataset size. Larger data size would give us a better understanding of the accuracy of different ensemble algorithms and would allow us to perform an in-depth comparison with more deep learning algorithms.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}