
Multi-Objective Combinatorial Optimization Algorithm Based on Asynchronous Advantage Actor–Critic and Graph Transformer Networks

 ,
,
Abstract
1. Introduction
2. Related Work
2.1. Multi-Objective Combinatorial Optimization Problems
2.2. Multi-Objective Combinatorial Optimization Algorithms Based on Deep Reinforcement Learning
2.3. Overview of DRL-MOA
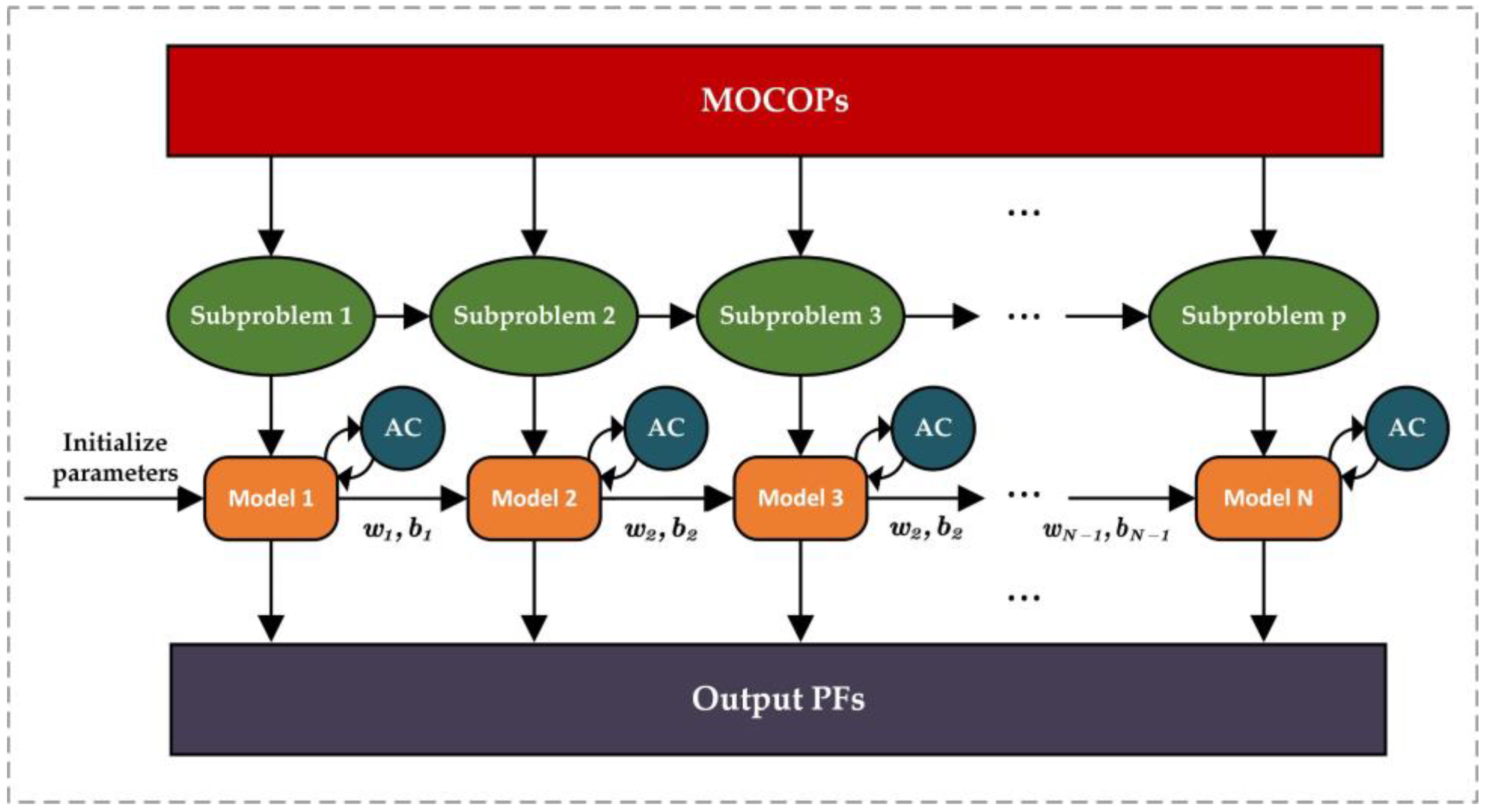
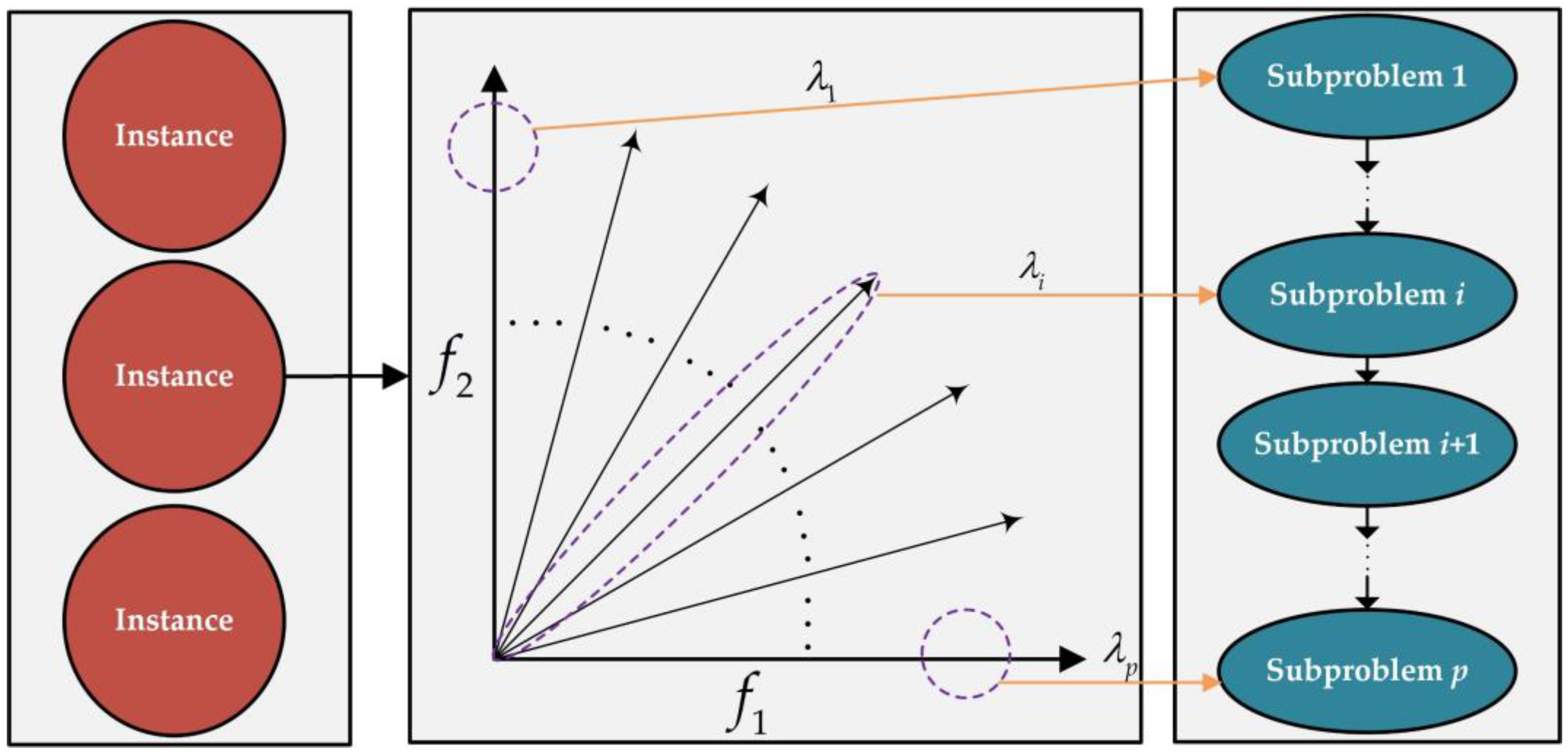
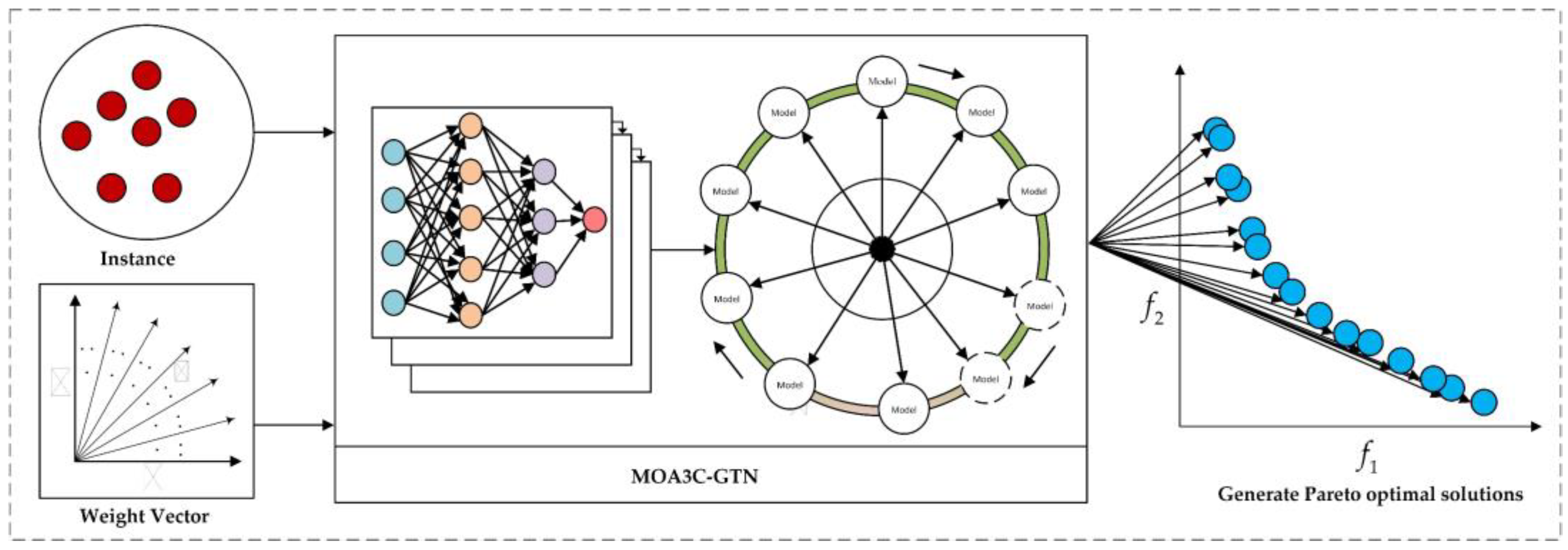
3. MOA3C-GTN Algorithm
3.1. General Solution Process
| Algorithm 1 General framework of MOA3C-GTN |
| Input: Node information , weight vectors . |
| Output: Pareto optimal solution set |
|
|
|
|
|
|
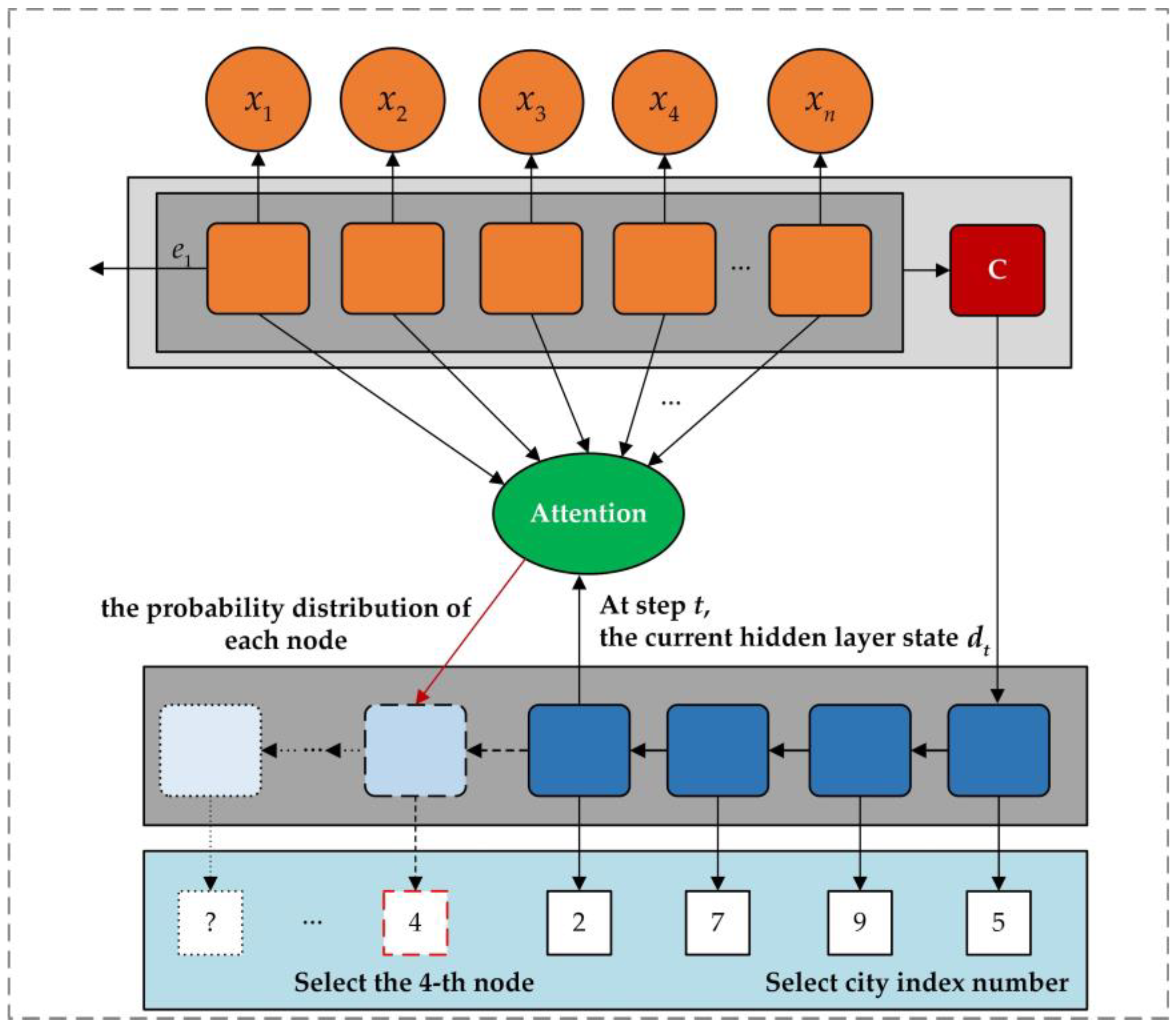
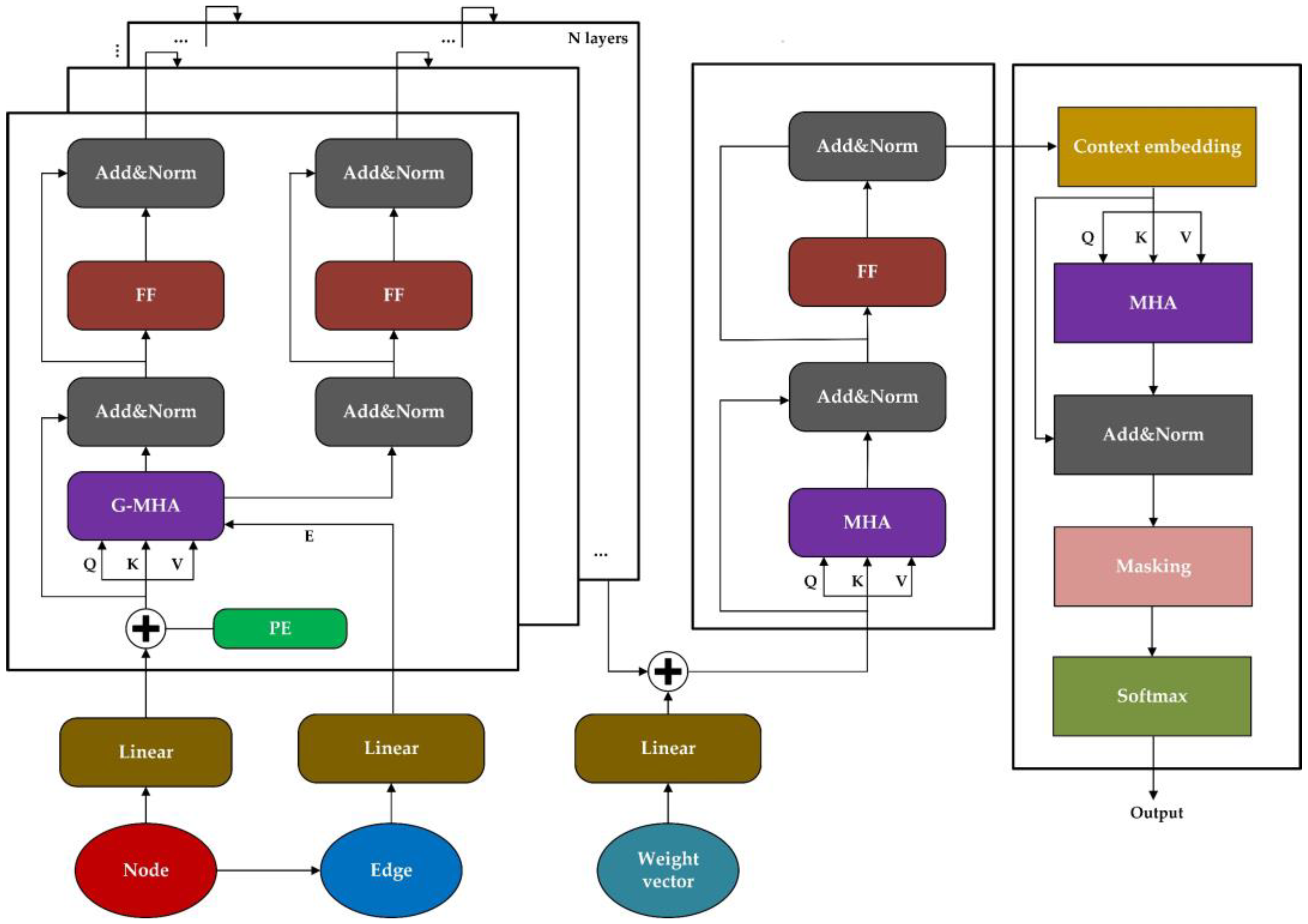
3.2. Graph Transformer Network Integrating Node, Edge, and Target Weight Information
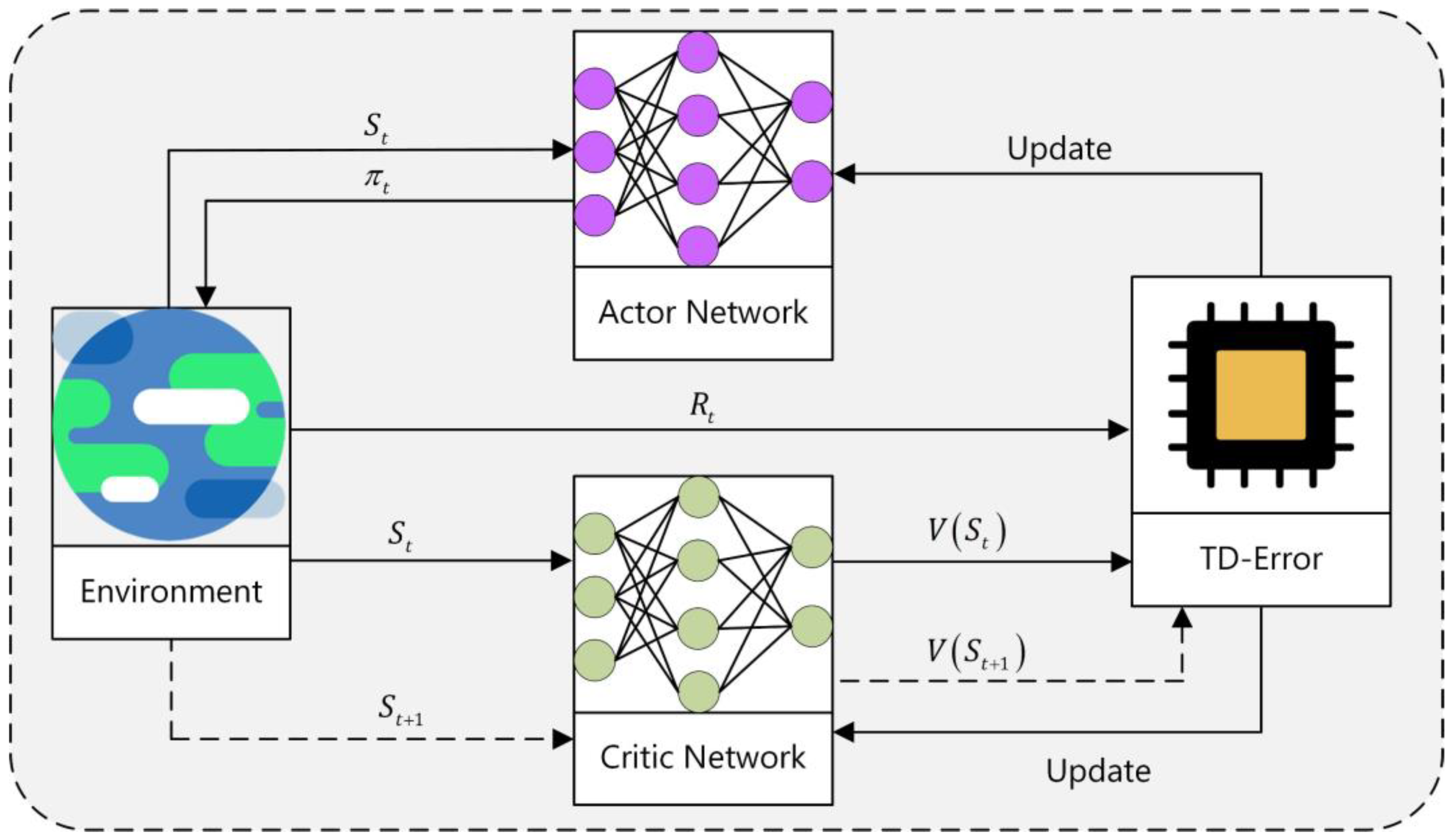
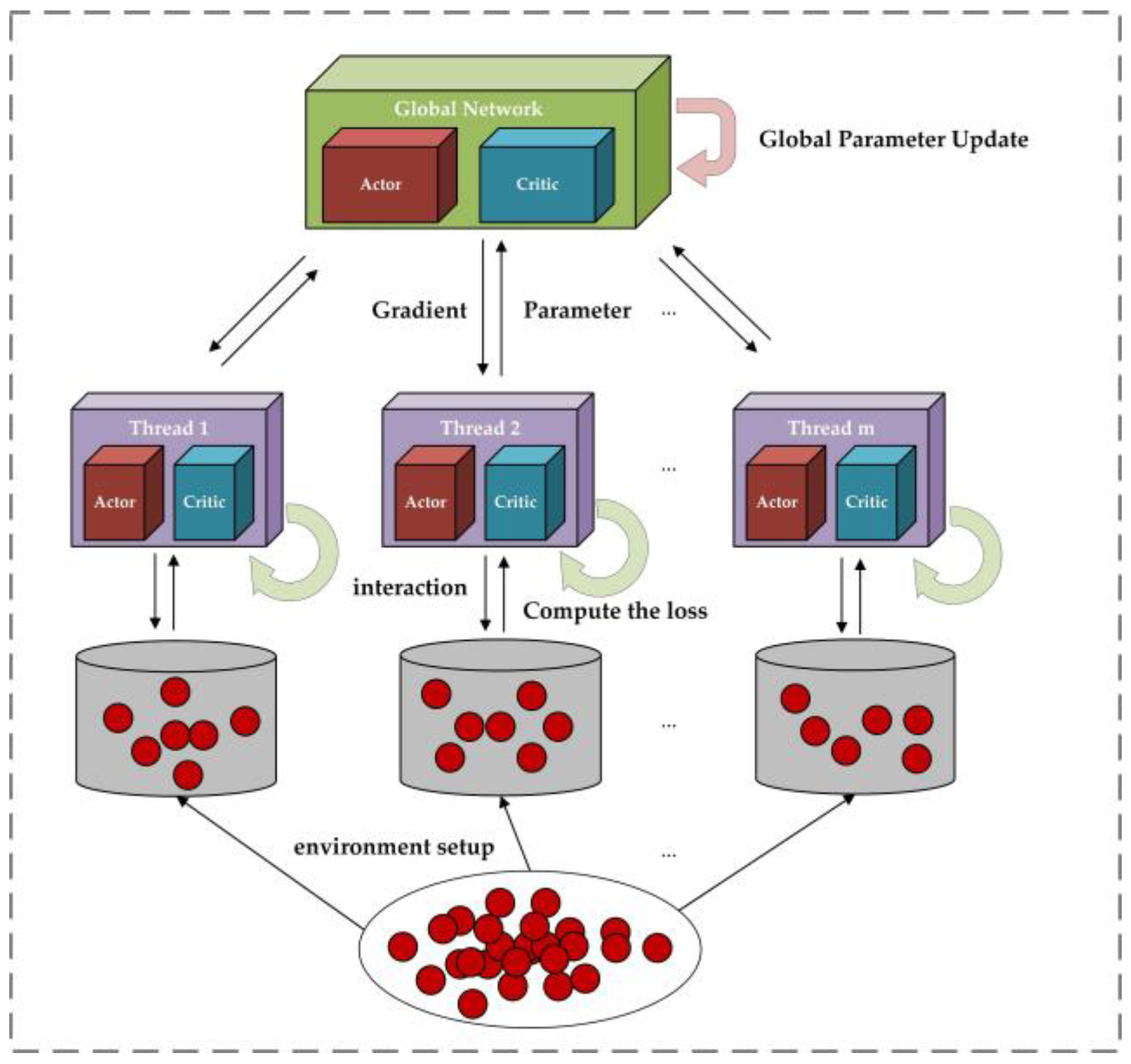
3.3. A3C Training Mode
| Algorithm 2 Asynchronous advantage actor–critic network training algorithm |
| Input: Number of training epochs , number of steps per training epoch , batch size , significance level , dataset , weight vector , global network parameters for actor , global network parameters for critic , local network parameters for actor , local network parameters for critic . |
| Output: Global network parameters for actor , global network parameters for critic . |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.4. Complexity Analysis
4. Results
4.1. Experimental Setup
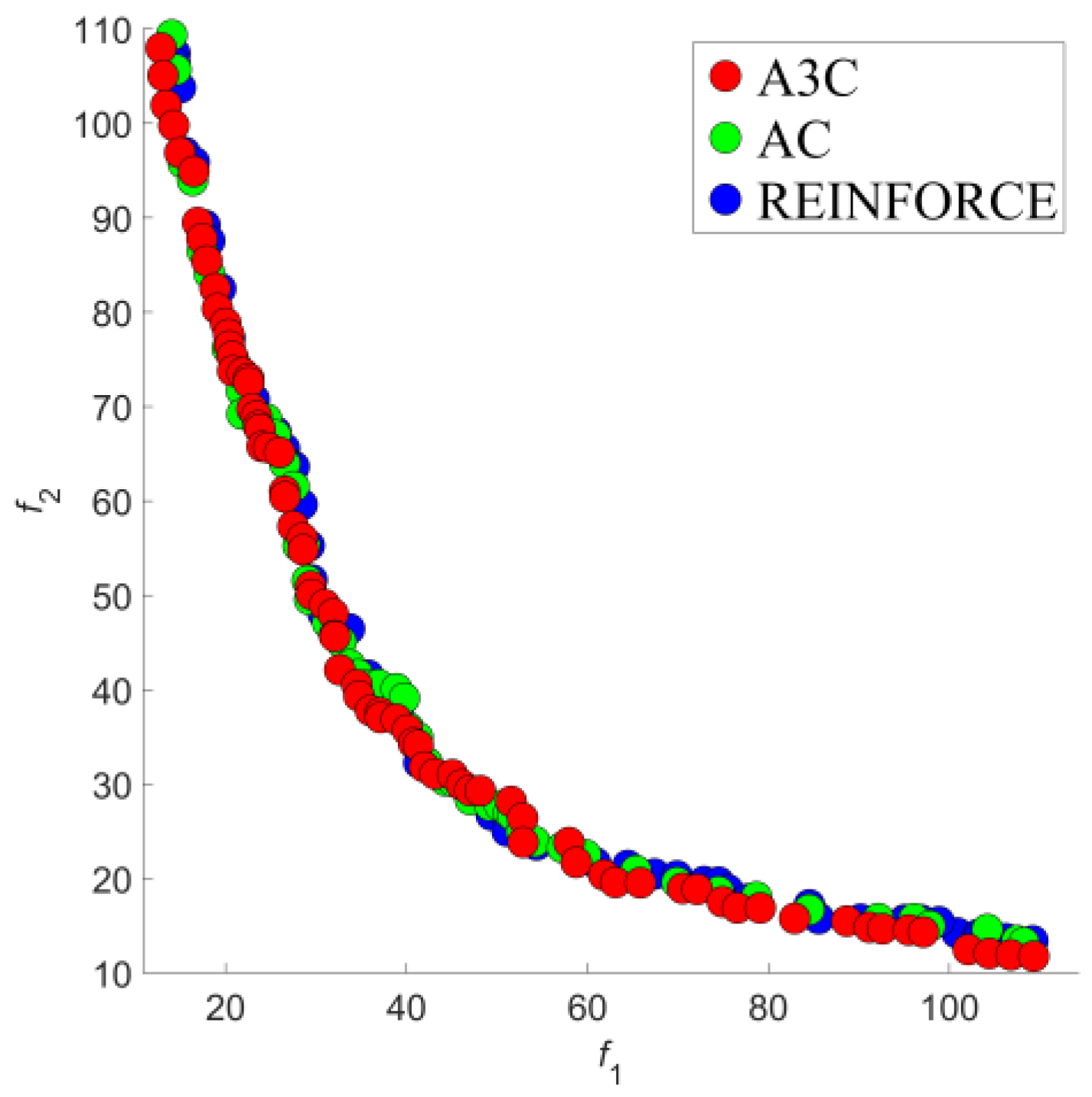
4.2. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MOCOPs | Multi-Objective Combinatorial Optimization Problems |
| DRL | Deep Reinforcement Learning |
| A3C | Asynchronous Advantage Actor–Critic |
| GTNs | Graph Transformer Networks |
| MOEA/D | Multi-objective Evolutionary Algorithm based on Decomposition |
| NSGA-II | Non-dominated Sorting Genetic Algorithm II |
| MOGLS | Multi-Objective Genetic Local Search |
| COPs | Combinatorial Optimization Problems |
| EL | Evolutionary Learning |
| AM | Attention Mode |
| HV | Hypervolume |
References
- Ahmed, F.; Deb, K. Multi-objective optimal path planning using elitist non-dominated sorting genetic algorithms. Soft Comput. 2013, 17, 1283–1299. [Google Scholar] [CrossRef]
- Sun, J.; Gan, X.J.; Gong, D.W.; Tang, X.K.; Dai, H.W.; Zhong, Z.M. A self-evolving fuzzy system online prediction-based dynamic multi-objective evolutionary algorithm. Inf. Sci. 2022, 612, 638–654. [Google Scholar] [CrossRef]
- Zhu, Y.; Chen, Y.; Huray, P.; Dong, X. Evolutionary Algorithms for Multiobjective Optimization. Sci. Technol. Inf. 2008, 4, 59–68. [Google Scholar] [CrossRef]
- Gan, X.J.; Sun, J.; Gong, D.W.; Jia, D.B.; Dai, H.W.; Zhong, Z.M. An adaptive reference vector based interval multi-objective evolutionary algorithm. IEEE Trans. Evol. Comput. 2023, 27, 1235–1249. [Google Scholar] [CrossRef]
- Oumayma, B.; Talbi, E.G.; Nahla, B.A. Using Possibility Theory to Solve a Multi-Objective Combinatorial Problem under Uncertainty: Definition of New Pareto-Optimality. Available online: https://scholar.google.fr/citations?view_op=view_citation&hl=fr&user=TM0z7KQAAAAJ&citation_for_view=TM0z7KQAAAAJ:zYLM7Y9cAGgC (accessed on 28 April 2024).
- Zhang, N.; Yan, J.; Hu, C.; Sun, Q.; Yang, L.; Gao, D.W.; Guerrero, J.M.; Li, Y. Price-Matching-Based Regional Energy Market With Hierarchical Reinforcement Learning Algorithm. IEEE Trans. Ind. Inform. 2024, 20, 11103–11114. [Google Scholar] [CrossRef]
- Basseur, M.; Liefooghe, A.; Le, K.; Burke, E.K. The efficiency of indicator-based local search for multi-objective combinatorial optimisation problems. J. Heuristics 2012, 18, 263–296. [Google Scholar] [CrossRef]
- Badica, C.; Popa, A. Exact and approximation algorithms for synthesizing specific classes of optimal block-structured processes. Simul. Model. Pract. Theory Int. J. Fed. Eur. Simul. Soc. 2023, 127, 102777. [Google Scholar] [CrossRef]
- Gao, S.; Yu, Y.; Wang, Y.; Wang, J.; Cheng, J.; Zhou, M. Chaotic Local Search-based Differential Evolution Algorithms for Optimization. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 3954–3967. [Google Scholar] [CrossRef]
- Ungureanu, V. Traveling Salesman Problem with Transportation. Comput. Sci. J. Mold. 2006, 14, 202–206. [Google Scholar] [CrossRef]
- Wu, W.; Ito, M.; Hu, Y.; Goko, H.; Sasaki, M.; Yagiura, M. Heuristic algorithms based on column generation for an online product shipping problem. Comput. Oper. Res. 2024, 161, 106403. [Google Scholar] [CrossRef]
- Tabrizi, A.M.; Vahdani, B.; Etebari, F.; Amiri, M. A Three-Stage model for Clustering, Storage, and joint online order batching and picker routing Problems: Heuristic algorithms. Comput. Ind. Eng. 2023, 179, 109180. [Google Scholar] [CrossRef]
- Yang, X.X.; Li, X.B.; Xiao, F.; Zhang, W.H. Overview of intelligent optimization algorithm and its application in flight vehicles optimization design. J. Astronaut. 2009, 30, 2051–2061. [Google Scholar] [CrossRef]
- Gong, D.W.; Sun, J.; Miao, Z. A set-based genetic algorithm for interval many-objective optimization problems. IEEE Trans. Evol. Comput. 2018, 22, 47–60. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H. MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Trans. Evol. Comput. 2007, 11, 712–731. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-IIJ. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Jaszkiewicz, A. Genetic local search for multi-objective combinatorial optimization. Eur. J. Oper. Res. 2002, 137, 50–71. [Google Scholar] [CrossRef]
- Ke, L.; Zhang, Q.; Battiti, R. MOEA/D-ACO: A multiobjective evolutionary algorithm using decomposition and antcolony. IEEE Trans. Cybern. 2013, 43, 1845–1859. [Google Scholar] [CrossRef] [PubMed]
- Beed, R.S.; Sarkar, S.; Roy, A.; Chatterjee, S. A study of the genetic algorithm parameters for solving multi-objective travelling salesman problem. In Proceedings of the 2017 International Conference on Information Technology (ICIT), Bhubaneswar, India, 21–23 December 2017; p. 232. [Google Scholar] [CrossRef]
- Quadri, C.; Ceselli, A.; Rossi, G.P. Multi-user edge service orchestration based on Deep Reinforcement Learning. Comput. Commun. 2023, 203, 30–47. [Google Scholar] [CrossRef]
- Kim, M.; Ham, Y.; Koo, C.; Kim, T.W. Simulating travel paths of construction site workers via deep reinforcement learning considering their spatial cognition and wayfinding behavior. Autom. Constr. 2023, 147, 104715. [Google Scholar] [CrossRef]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised Feature Learning via Non-parametric Instance Discrimination. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar] [CrossRef]
- Wu, Z.; Dijkstra, P.; Koch, G.W.; Peñuelas, J.; Hungate, B.A. Responses of terrestrial ecosystems to temperature and precipitation change: A meta-analysis of experimental manipulation. Glob. Chang. Biol. 2011, 17, 927–942. [Google Scholar] [CrossRef]
- Yao, Q.; Zheng, Z.; Qi, L.; Yuan, H.; Guo, X.; Zhao, M.; Liu, Z.; Yang, T. Path Planning Method with Improved Artificial Potential Field—A Reinforcement Learning Perspective. IEEE Access 2020, 8, 135513–135523. [Google Scholar] [CrossRef]
- Gronauer, S.; Diepold, K. Multi-agent deep reinforcement learning: A survey. Artif. Intell. Rev. 2021, 55, 895–943. [Google Scholar] [CrossRef]
- Gao, S.; Zhou, M.; Wang, Z.; Sugiyama, D.; Cheng, J.; Wang, J.; Todo, Y. Fully Complex-valued Dendritic Neuron Model. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 2105–2118. [Google Scholar] [CrossRef] [PubMed]
- Jia, D.B.; Xu, W.X.; Liu, D.Z.; Xu, Z.X.; Zhong, Z.M.; Ban, X.X. Verification of classification model and dendritic neuron model based on machine learning. Discret. Dyn. Nat. Soc. 2022, 2022, 3259222. [Google Scholar] [CrossRef]
- Gao, S.; Zhou, M.; Wang, Y.; Cheng, J.; Yachi, H.; Wang, J. Dendritic neuron model with effective learning algorithms for classification, approximation, and prediction. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 601–614. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar] [CrossRef]
- Jia, D.; Xu, Z.; Wang, Y.; Ma, R.; Jiang, W.; Qian, Y.; Wang, Q.; Xu, W. Application of intelligent time series prediction method to dew point forecast. Electron. Res. Arch. 2023, 31, 2878–2899. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Jia, D.; Dai, H.; Takashima, Y.; Nishio, T.; Hirobayashi, K.; Hasegawa, M.; Hirobayashi, S.; Misawa, T. EEG processing in internet of medical things using non-harmonic analysis: Application and evolution for SSVEP responses. IEEE Access 2019, 7, 11318–11327. [Google Scholar] [CrossRef]
- Babaeizadeh, M.; Frosio, I.; Tyree, S.; Clemons, J.; Kautz, J. Reinforcement Learning through Asynchronous Advantage Actor-Critic on a GPUJ. arXiv preprint 2016, arXiv:1611.06256. [Google Scholar] [CrossRef]
- Yun, S.; Jeong, M.; Kim, R.; Kang, J.; Kim, H.J. Graph Transformer Networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]
- Jia, D.; Fujishita, Y.; Li, C.; Todo, Y.; Dai, H. Validation of large-scale classification problem in dendritic neuron model using particle antagonism mechanism. Electronics 2020, 9, 792. [Google Scholar] [CrossRef]
- Dwivedi, V.P.; Bresson, X. A Generalization of Transformer Networks to Graphs. arXiv 2020, arXiv:2012.09699. [Google Scholar] [CrossRef]
- Gebreyesus, G.; Fellek, G.; Farid, A.; Fujimura, S.; Yoshie, O. Gated-Attention Model with Reinforcement Learning for Solving Dynamic Job Shop Scheduling Problem. IEEJ Trans. Electr. Electron. Eng. 2023, 18, 932–944. [Google Scholar] [CrossRef]
- Lin, X.; Yang, Z.; Zhang, Q. Pareto Set Learning for Neural Multi-objective Combinatorial Optimization. arXiv 2022, arXiv:2203.15386. [Google Scholar] [CrossRef]
- Huang, Z.; Jiang, D.; Wang, X.; Yao, E. An Ising Model-Based Annealing Processor With 1024 Fully Connected Spins for Combinatorial Optimization Problems. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 3074–3078. [Google Scholar] [CrossRef]
- Li, K.; Zhang, T.; Wang, R. Deep Reinforcement Learning for Multiobjective OptimizationJ. IEEE Trans. Cybern. 2020, 51, 3103–3114. [Google Scholar] [CrossRef]
- Liu, T.; Zou, Y.; Liu, D.; Sun, F. Reinforcement Learning of Adaptive Energy Management With Transition Probability for a Hybrid Electric Tracked Vehicle. IEEE Trans. Ind. Electron. 2015, 62, 7837–7846. [Google Scholar] [CrossRef]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. Proc. Adv. Neural Inf. Process. Syst. 2015, 2692–2700. [Google Scholar]
- Wu, H.; Wang, J.; Zhang, Z. MODRL/D-AM: Multiobjective Deep Reinforcement Learning Algorithm Using Decomposition and Attention Model for Multiobjective Optimization. In International Symposium on Intelligence Computation and Applications; Springer: Singapore, 2020. [Google Scholar] [CrossRef]
- Kool, W.; van Hoof, H.; Welling, M. Welling attention, learn to solve routing problems. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019; pp. 1–25. [Google Scholar]
- Haque, A.; Alahi, A.; Fei-Fei, L. Recurrent Attention Models for Depth-Based Person Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Haroon, S.; Hafsath, C.A.; Jereesh, A.S. Generative Pre-trained Transformer (GPT) based model with relative attention for de novo drug design. Comput. Biol. Chem. 2023, 106, 107911. [Google Scholar] [CrossRef]
- Jia, D.; Yanagisawa, K.; Hasegawa, M.; Hirobayashi, S.; Tagoshi, H.; Narikawa, T.; Uchikata, N.; Takahashi, H. Timefrequency based non-harmonic analysis to reduce line noise impact for LIGO observation system. Astron 2018, 25, 238–246. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv preprint 2014, arXiv:1412.3555. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Zhang, Z.; Zhou, Y. MODRL/D-EL: Multiobjective Deep Reinforcement Learning with Evolutionary Learning for Multiobjective Optimization. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021. [Google Scholar] [CrossRef]
- Espinosa, R.; FJiménez Palma, J. Surrogate-Assisted and Filter-Based Multiobjective Evolutionary Feature Selection for Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef] [PubMed]
- Jia, D.; Yanagisawa, K.; Ono, Y.; Hirobayashi, K.; Hasegawa, M.; Hirobayashi, S.; Tagoshi, H.; Narikawa, T.; Uchikata, N.; Takahashi, H. Multiwindow nonharmonic analysis method for gravitational waves. IEEE Access 2018, 6, 48645–48655. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, Z.; Zhang, H.; Wang, J. Meta-Learning-Based Deep Reinforcement Learning for Multiobjective Optimization Problems. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 7978–7991. [Google Scholar] [CrossRef] [PubMed]
- Shao, Y.; Lin, J.C.-W.; Srivastava, G.; Guo, D.; Zhang, H.; Yi, H.; Jolfaei, A. Multi-Objective Neural Evolutionary Algorithm for Combinatorial Optimization Problems. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 2133–2143. [Google Scholar] [CrossRef]
- Xu, W.; Jia, D.; Zhong, Z.; Li, C.; Xu, Z. Intelligent dendritic neural model for classification problems. Symmetry 2022, 14, 11. [Google Scholar] [CrossRef]
- Jia, D.; Li, C.; Liu, Q.; Yu, Q.; Meng, X.; Zhong, Z.; Ban, X.; Wang, N. Application and evolution for neural network and signal processing in large-scale systems. Complexity 2021, 2021, 6618833. [Google Scholar] [CrossRef]
- Han, M.; Zhang, L.; Wang, J.; Pan, W. Actor-Critic Reinforcement Learning for Control With Stability Guarantee. IEEE Robot. Autom. Lett. 2020, 5, 6217–6224. [Google Scholar] [CrossRef]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. arXiv 2021, arXiv:2101.00190. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar] [CrossRef]
- Ngatchou, P.N.; Zarei, A.; Fox, W.L.J.; El-Sharkawi, M.A. Pareto Multiobjective Optimization; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005. [Google Scholar] [CrossRef]
- Ronald, J. Williams, Simple statistical gradient-following algorithms for connec tionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. arXiv 2016, arXiv:1602.01783. [Google Scholar] [CrossRef]
- Yelve, N.P.; Mitra, M.; Mujumdar, P.M. High-Dimensional Continuous Control Using Generalized Advantage Estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar] [CrossRef]
- Tian, Y.; Zhu, W.; Zhang, X.; Jin, Y. A practical tutorial on solving optimization problems via PlatEMO. Neurocomputing 2023, 518, 190–205. [Google Scholar] [CrossRef]
- Riquelme, N.; Von Lucken, C.; Baran, B. Performance metrics in multi-objective optimization. In Proceedings of the 2015 Latin American Computing Conference (CLEI), Arequipa, Peru, 19–23 October 2015; pp. 1–11. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Algorithm | Core Technology | Main Contributions |
|---|---|---|---|
| 2020 | DRL-MOA | DRL | Solving MOCOPS for the first time using end-to-end DRL techniques. |
| 2020 | MODRL/D-AM | DRL | Incorporating graph attention mechanisms. |
| 2021 | MODRL/D-EL | DRL + EL | Replacing parameter transfer techniques with evolutionary learning. |
| 2022 | ML-AM | DRL + ML | Substituting transfer-learning techniques with meta-learning. |
| 2023 | MOAMDM | DRL | Integrating weight encoding in the encoder and adopting a structure that utilizes multiple encoders for solution. |
| MOA3C-GTN | MOEA/D | NSGA-II | DRL-MOA | MODRL/D-AM | ML-AM | MODRL/D-EL | |
|---|---|---|---|---|---|---|---|
| 40-city | 0.6875 | 0.6375 | 0.6256 | 0.6493 | 0.6512 | 0.6751 | 0.6812 |
| 70-city | 0.7292 | 0.6651 | 0.6330 | 0.6926 | 0.6921 | 0.7074 | 0.7147 |
| 100-city | 0.7586 | 0.6327 | 0.6159 | 0.7027 | 0.751 | 0.7212 | 0.7337 |
| 150-city | 0.7845 | 0.6216 | 0.6122 | 0.7397 | 0.7524 | 0.7565 | 0.7612 |
| 200-city | 0.8334 | 0.6543 | 0.6318 | 0.7670 | 0.7817 | 0.7112 | 0.8278 |
| MOA3C-GTN | MOEA/D | NSGA-II | DRL-MOA | MODRL/D-AM | ML-AM | MODRL/D-EL | |
|---|---|---|---|---|---|---|---|
| 40-city | 3.45 | 67.99 | 13.47 | 2.52 | 5.06 | 3.528 | 6.47 |
| 70-city | 6.62 | 70.32 | 16.02 | 4.71 | 8.25 | 6.58 | 10.87 |
| 100-city | 12.01 | 73.98 | 28.75 | 7.24 | 13.08 | 11.58 | 17.62 |
| 150-city | 15.87 | 78.82 | 21.41 | 9.72 | 19.44 | 14.60 | 24.13 |
| 200-city | 28.07 | 82.42 | 23.04 | 13.18 | 26.39 | 18.44 | 30.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, D.; Cao, M.; Hu, W.; Sun, J.; Li, H.; Wang, Y.; Zhou, W.; Yin, T.; Qian, R. Multi-Objective Combinatorial Optimization Algorithm Based on Asynchronous Advantage Actor–Critic and Graph Transformer Networks. Electronics 2024, 13, 3842. https://doi.org/10.3390/electronics13193842
Jia D, Cao M, Hu W, Sun J, Li H, Wang Y, Zhou W, Yin T, Qian R. Multi-Objective Combinatorial Optimization Algorithm Based on Asynchronous Advantage Actor–Critic and Graph Transformer Networks. Electronics. 2024; 13(19):3842. https://doi.org/10.3390/electronics13193842
Chicago/Turabian StyleJia, Dongbao, Ming Cao, Wenbin Hu, Jing Sun, Hui Li, Yichen Wang, Weijie Zhou, Tiancheng Yin, and Ran Qian. 2024. "Multi-Objective Combinatorial Optimization Algorithm Based on Asynchronous Advantage Actor–Critic and Graph Transformer Networks" Electronics 13, no. 19: 3842. https://doi.org/10.3390/electronics13193842
APA StyleJia, D., Cao, M., Hu, W., Sun, J., Li, H., Wang, Y., Zhou, W., Yin, T., & Qian, R. (2024). Multi-Objective Combinatorial Optimization Algorithm Based on Asynchronous Advantage Actor–Critic and Graph Transformer Networks. Electronics, 13(19), 3842. https://doi.org/10.3390/electronics13193842