
An Efficient Maximum Entropy Approach with Consensus Constraints for Robust Geometric Fitting




Abstract
1. Introduction
- Maximum entropy with consensus constraints (MECC): By proposing a novel approach, MECCs, which integrates the maximum entropy strategy with consensus maximization constraints to effectively distinguish between inliers and outliers, enhances robustness in maximum consensus fitting.
- Enhanced optimization method: Developing an improved version of the relaxed and accelerated alternating direction method of multipliers (R-A-ADMMs) within our framework enables the attainment of a suboptimal solution for the proposed optimization problem.
- Empirical validation and performance efficiency: We performed experimental evaluations on both synthetic and real contaminated datasets to validate the proposed method alongside current state-of-the-art techniques in geometric accuracy and robustness, particularly in high outlier scenarios, despite a modest increase in computational cost.
2. Related Work and Problem Formulation
2.1. Related Work
2.2. Problem Formulation
3. Proposed Methodology
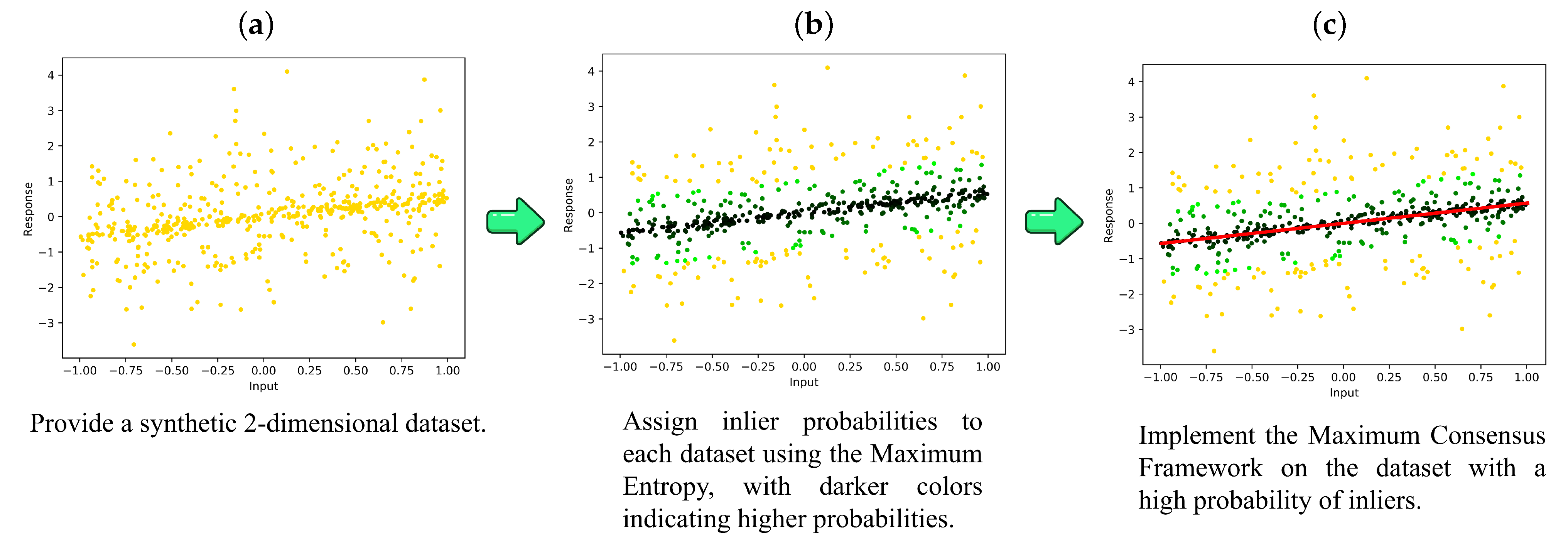
3.1. Entropy Maximum Strategy
3.2. Optimization Analysis
3.2.1. Optimizing
3.2.2. Optimizing and
| Algorithm 1 Maximum entropy with consensus constraints. |
Input: : the contaminated dataset; , , , : the hyperparameters; Output: optimal model with . Process: |
3.3. Direct Linear Transformation
4. Experimental Results
- RANSAC [15]: This iteratively samples a minimal subset of data points to fit a suboptimal model. [Recommended configuration: ].
- BCD-L1 [45]: This learns the optimal of the maximum consensus model using the proximal block co-ordinate descent method with initialization using the norm method. [Recommended configuration: , ].
- EES [30]: This utilizes the deterministic annealing method using the linear assignment problem to ensure both efficiency and accuracy. [Recommended configuration: , , ].
- MAGSAC++ [19]: This is a novel class of M-estimators, which is a robust kernel solved by an iteratively reweighted least squares procedure. It is also combined with progressive NAPSAC, a RANSAC-like robust estimator, to improve its performance. [Recommended configuration: ];
- VSAC [40]: This is the latest RANSAC-type algorithm, incorporating the concept of independent inliers to enhance its effectiveness in handling dominant planes. It enables the accurate rejection of incorrect models without false positives. [Recommended configuration: ].
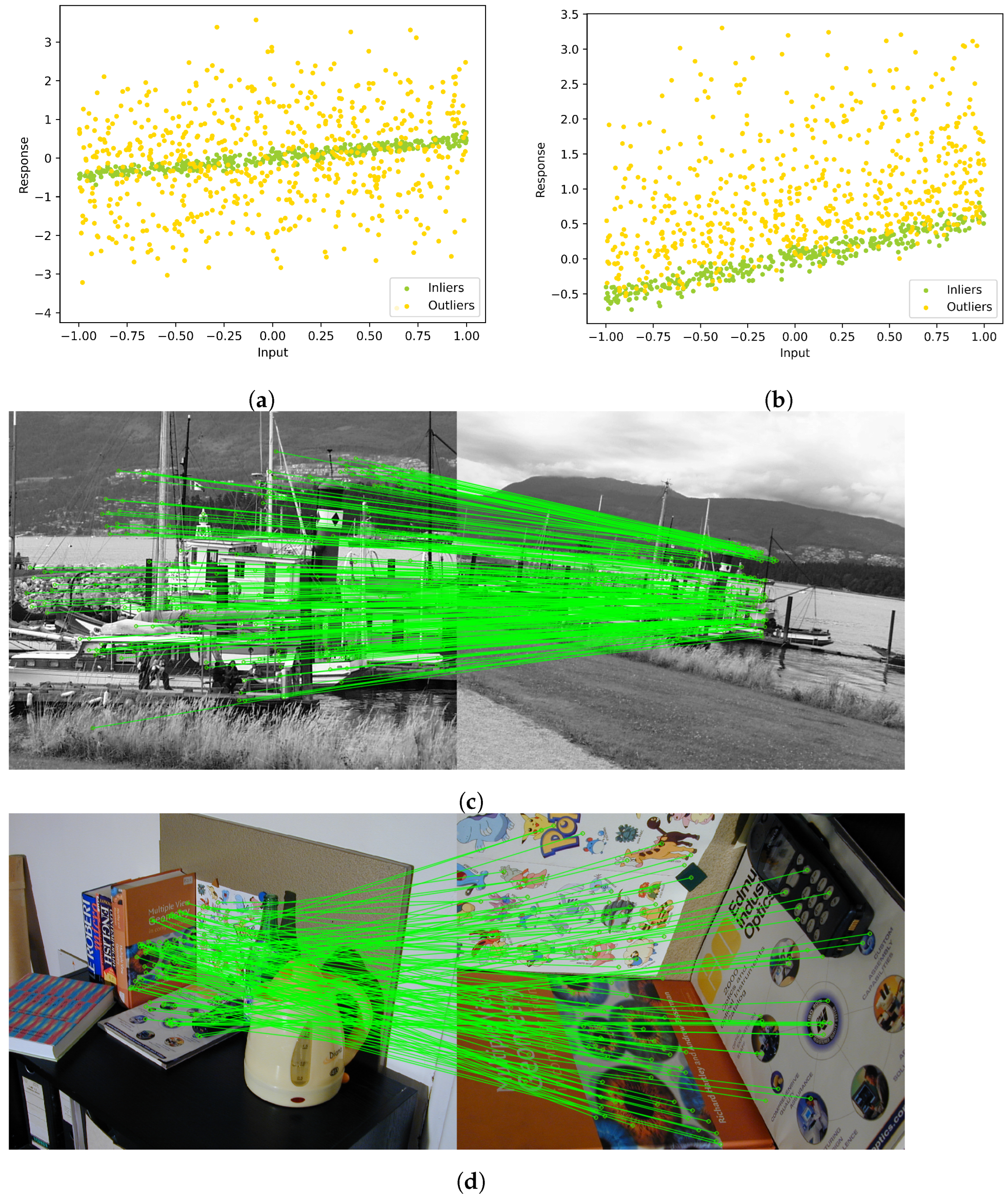
4.1. Robust Linear Regression
- (1)
- Balanced data: The outliers in were contaminated by using Gaussian noise with a standard deviation of .
- (2)
- Unbalanced data: The Gaussian noise was restricted to be positive.
4.2. Fundamental Matrix and Homography Estimation
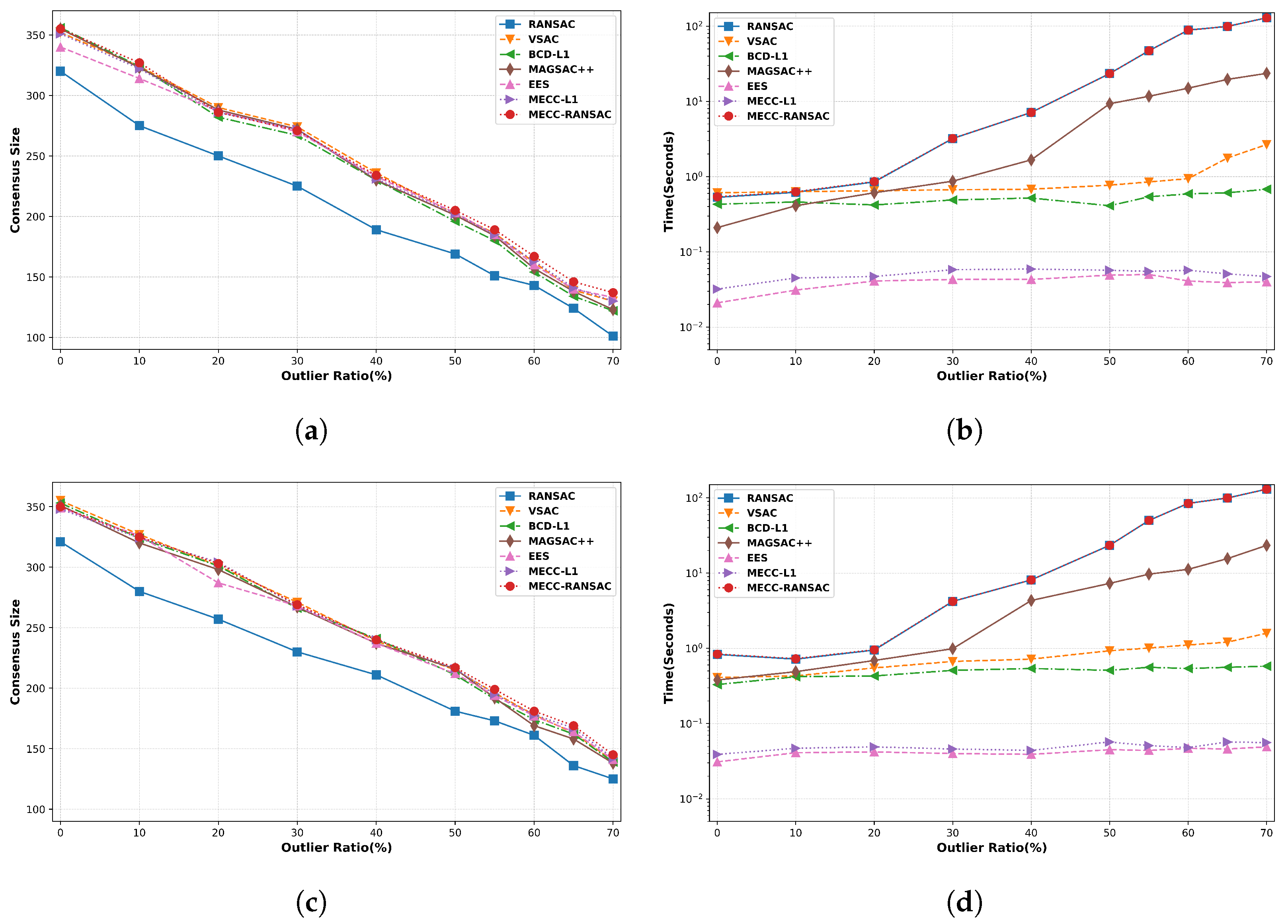
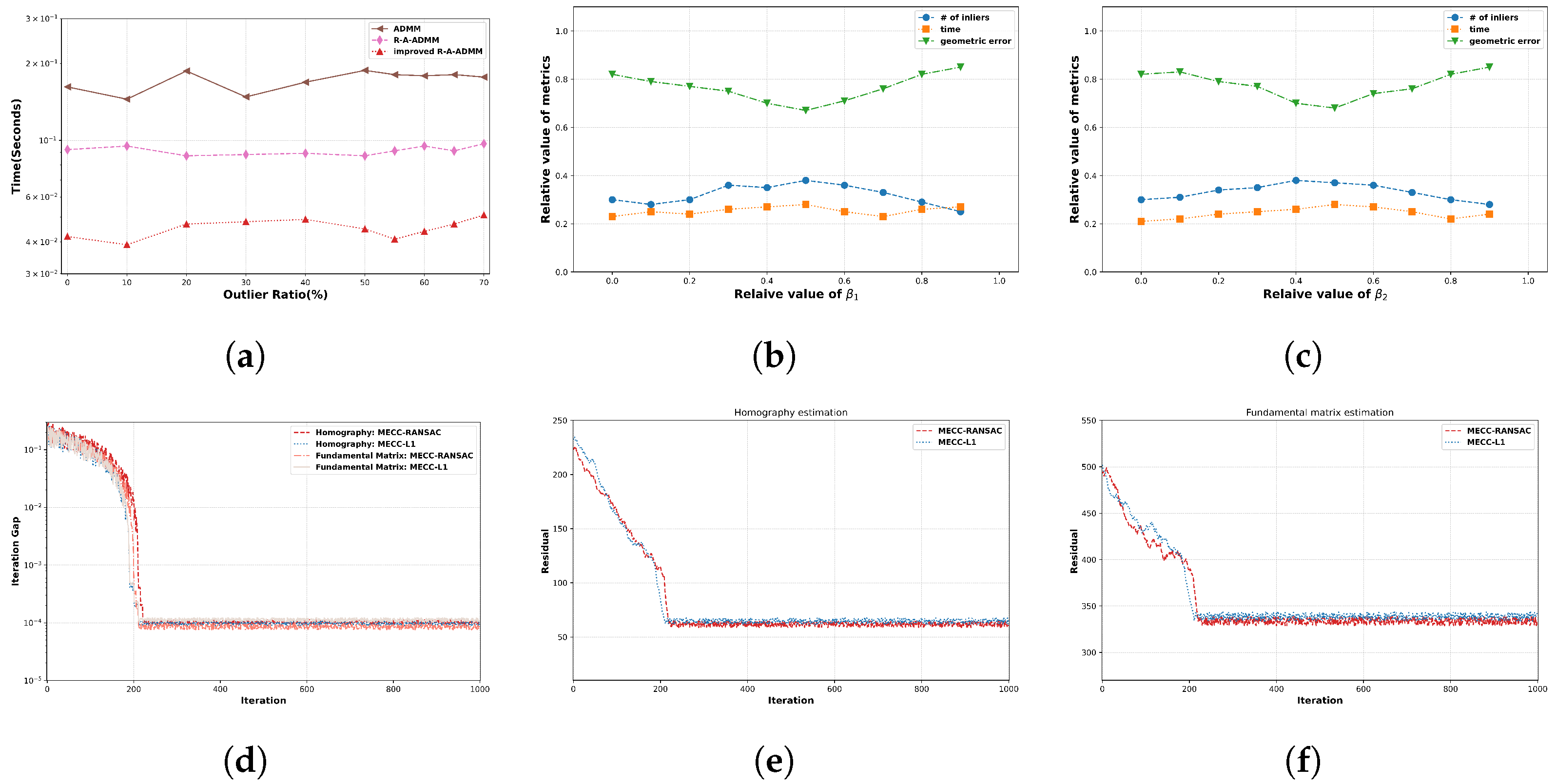
4.3. Algorithmic Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Isack, H.; Boykov, Y. Energy-based geometric multi-model fitting. Int. J. Comput. Vis. 2012, 97, 123–147. [Google Scholar] [CrossRef]
- Pham, T.T.; Chin, T.-J.; Schindler, K.; Suter, D. Interacting geometric priors for robust multimodel fitting. IEEE Trans. Image Process. 2014, 23, 4601–4610. [Google Scholar] [CrossRef] [PubMed]
- Brown, M.; Lowe, D.G. Automatic panoramic image stitching using invariant features. Int. J. Comput. Vis. 2007, 74, 59–73. [Google Scholar] [CrossRef]
- Pritchett, P.; Zisserman, A. Wide baseline stereo matching. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 7 January 1998; pp. 754–760. [Google Scholar]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Mishkin, D.; Matas, J.; Perdoch, M. Mods: Fast and robust method for two-view matching. Comput. Vis. Image Underst. 2015, 141, 81–93. [Google Scholar] [CrossRef]
- Meer, P. Robust techniques for computer vision. Emerg. Top. Comput. Vis. 2004, 2004, 107–190. [Google Scholar]
- Martinec, D.; Pajdla, T. Robust rotation and translation estimation in multiview reconstruction. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. Orb-slam: A versatile and accurate monocular slam system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Abdigapporov, S.; Miraliev, S.; Kakani, V.; Kim, H. Joint multiclass object detection and semantic segmentation for autonomous driving. IEEE Access 2023, 11, 37637–37649. [Google Scholar] [CrossRef]
- Abdigapporov, S.; Miraliev, S.; Alikhanov, J.; Kakani, V.; Kim, H. Performance comparison of backbone networks for multi-tasking in self-driving operations. In Proceedings of the 2022 22nd International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 27 November–1 December 2022; pp. 819–824. [Google Scholar]
- Irfan, M.; Munsif, M.V. Deepdive: A learning-based approach for virtual camera in immersive contents. Virtual Real. Intell. Hardw. 2022, 4, 247–262. [Google Scholar] [CrossRef]
- Ullah, M.; Amin, S.U.; Munsif, M.; Yamin, M.M.; Safaev, U.; Khan, H.; Khan, S.; Ullah, H. Serious games in science education: A systematic literature. Virtual Real. Intell. Hardw. 2022, 4, 189–209. [Google Scholar] [CrossRef]
- Chum, O.; Matas, J.; Kittler, J. Locally optimized ransac. In Proceedings of the Pattern Recognition: 25th DAGM Symposium, Magdeburg, Germany, 10–12 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 236–243. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Lebeda, K.; Matas, J.; Chum, O. Fixing the locally optimized ransac–full experimental evaluation. In Proceedings of the British Machine Vision Conference, Citeseer Princeton, NJ, USA, 3–7 September 2012. [Google Scholar]
- Jo, G.; Lee, K.-S.; Chandra, D.; Jang, C.-H.; Ga, M.-H. Ransac versus cs-ransac. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Wei, T.; Patel, Y.; Shekhovtsov, A.; Matas, J.; Barath, D. Generalized differentiable ransac. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 17649–17660. [Google Scholar]
- Barath, D.; Noskova, J.; Ivashechkin, M.; Matas, J. Magsac++, a fast, reliable and accurate robust estimator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1304–1312. [Google Scholar]
- Barath, D.; Matas, J. Graph-cut ransac: Local optimization on spatially coherent structures. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4961–4974. [Google Scholar] [CrossRef] [PubMed]
- Chum, O.; Matas, J. Matching with prosac-progressive sample consensus. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), Diego, CA, USA, 20–25 June 2005; pp. 220–226. [Google Scholar]
- Olsson, C.; Enqvist, O.; Kahl, F. A polynomial-time bound for matching and registration with outliers. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zheng, Y.; Sugimoto, S.; Okutomi, M. Deterministically maximizing feasible subsystem for robust model fitting with unit norm constraint. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1825–1832. [Google Scholar]
- Enqvist, O.; Ask, E.; Kahl, F.; Åström, K. Robust fitting for multiple view geometry. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 738–751. [Google Scholar]
- Li, H. Consensus set maximization with guaranteed global optimality for robust geometry estimation. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1074–1080. [Google Scholar]
- Cai, Z.; Chin, T.-J.; Le, H.; Suter, D. Deterministic consensus maximization with biconvex programming. In Proceedings of the European Conference on Computer Vision (ECCV), Mulish, Germany, 8–14 September 2018; pp. 685–700. [Google Scholar]
- Le, H.; Chin, T.-J.; Eriksson, A.; Do, T.-T.; Suter, D. Deterministic approximate methods for maximum consensus robust fitting. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 842–857. [Google Scholar] [CrossRef] [PubMed]
- Park, D.H.; Kakani, V.; Kim, H. Automatic radial un-distortion using conditional generative adversarial network. J. Inst. Control. Robot. Syst. 2019, 25, 1007–1013. [Google Scholar] [CrossRef]
- Kakani, V.; Kim, H. Adaptive self-calibration of fisheye and wide-angle cameras. In Proceedings of the TENCON 2019-2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 976–981. [Google Scholar]
- Fan, A.; Ma, J.; Jiang, X.; Ling, H. Efficient deterministic search with robust loss functions for geometric model fitting. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8212–8229. [Google Scholar] [CrossRef]
- Ghimire, A.; Kakani, V.; Kim, H. Ssrt: A sequential skeleton rgb transformer to recognize fine-grained human-object interactions and action recognition. IEEE Access 2023, 11, 51930–51948. [Google Scholar] [CrossRef]
- França, G.; Robinson, D.P.; Vidal, R. A nonsmooth dynamical systems perspective on accelerated extensions of admm. IEEE Trans. Autom. Control. 2023, 68, 2966–2978. [Google Scholar] [CrossRef]
- Torr, P.H.; Nasuto, S.J.; Bishop, J.M. Napsac: High noise, high dimensional robust estimation-it’s in the bag. Br. Mach. Vis. Conf. (BMVC) 2002, 2, 3. [Google Scholar]
- Ni, K.; Jin, H.; Dellaert, F. Groupsac: Efficient consensus in the presence of groupings. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2193–2200. [Google Scholar]
- Fragoso, V.; Sen, P.; Rodriguez, S.; Turk, M. Evsac: Accelerating hypotheses generation by modeling matching scores with extreme value theory. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2472–2479. [Google Scholar]
- Torr, P.H.; Zisserman, A. Mlesac: A new robust estimator with application to estimating image geometry. Comput. Vis. Image Underst. 2000, 78, 138–156. [Google Scholar] [CrossRef]
- Torr, P.H.S. Bayesian model estimation and selection for epipolar geometry and generic manifold fitting. Int. J. Comput. Vis. 2002, 50, 35–61. [Google Scholar] [CrossRef]
- Barath, D.; Matas, J. Graph-cut ransac. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6733–6741. [Google Scholar]
- Barath, D.; Matas, J.; Noskova, J. Magsac: Marginalizing sample consensus. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10197–10205. [Google Scholar]
- Ivashechkin, M.; Barath, D.; Matas, J. Vsac: Efficient and accurate estimator for h and f. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15243–15252. [Google Scholar]
- Bazin, J.-C.; Li, H.; Kweon, I.S.; Demonceaux, C.; Vasseur, P.; Ikeuchi, K. A branch-and-bound approach to correspondence and grouping problems. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1565–1576. [Google Scholar] [CrossRef] [PubMed]
- Chin, T.-J.; Purkait, P.; Eriksson, A.; Suter, D. Efficient globally optimal consensus maximisation with tree search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2413–2421. [Google Scholar]
- Cai, Z.; Chin, T.-J.; Koltun, V. Consensus maximization tree search revisited. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1637–1645. [Google Scholar]
- Chin, T.-J.; Kee, Y.H.; Eriksson, A.; Neumann, F. Guaranteed outlier removal with mixed integer linear programs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June –1 July 2016; pp. 5858–5866. [Google Scholar]
- Wen, F.; Ying, R.; Gong, Z.; Liu, P. Efficient algorithms for maximum consensus robust fitting. IEEE Trans. Robot. 2019, 36, 92–106. [Google Scholar] [CrossRef]
- Ke, Q.; Kanade, T. Quasiconvex optimization for robust geometric reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1834–1847. [Google Scholar] [CrossRef]
- Olsson, C.; Eriksson, A.; Hartley, R. Outlier removal using duality. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1450–1457. [Google Scholar]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Goldstein, T.; O’Donoghue, B.; Setzer, S.; Baraniuk, R. Fast alternating direction optimization methods. SIAM J. Imaging Sci. 2014, 7, 1588–1623. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, Y. Alternating direction algorithms for ∖ell_1-problems in compressive sensing. SIAM J. Sci. Comput. 2011, 33, 250–278. [Google Scholar] [CrossRef]
- Balntas, V.; Lenc, K.; Vedaldi, A.; Mikolajczyk, K. Hpatches: A benchmark and evaluation of handcrafted and learned local descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5173–5182. [Google Scholar]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Photo tourism: Exploring photo collections in 3d. In Proceedings of the ACM Siggraph 2006 Papers, Boston, MA, USA, 30 July–3 August 2006; pp. 835–846. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Research Study | Methodology | Key Aspects & Limitations |
|---|---|---|---|
| RANSAC-based | GC-RANSAC [38] | A hybrid method utilizing the graph-cut algorithm | This method improves inlier detection to refine the geometric model fitting, but it introduces significant computational overhead. |
| MAGSAC++ [19] | A combined progressive NAPSAC method with a novel class of M-estimators | This method improves geometric model fitting accuracy by using a new model quality to reject outliers but is sensitive to parameter settings and data distribution. | |
| VSAC [40] | A dominant plane-handling method featuring a novel concept of independent inliers | This method leverages independent inliers for accurate model rejection and better handling of dominant planes but suffers from the limitations of RANSAC in terms of reduced accuracy and efficiency with high outlier ratios. | |
| Optimization-based | GORE [44] | An outlier removal method using MILP in an iterative process | This method uses MILP to iteratively identify and remove outliers. However, its efficiency is significantly reduced due to the repeated application of consensus maximization after each removal. |
| BCD-L1 [45] | A method utilizing a block co-ordinate descent framework | A method using block co-ordinate descent ensures finite iteration convergence to a local minimizer but is vulnerable to sensitive local optima due to data uncertainties. | |
| EAS [30] | A method incorporating a deterministic annealing approach | A method leveraging deterministic annealing handles the nonconvexity of truncated losses and reduces the risk of local optima but relies heavily on singular value decomposition, yielding only approximate suboptimal solutions. | |
| MECC (Ours) | A consensus maximization method incorporating a maximum consensus framework | This method employs an enhanced R-A-ADMM solver within the maximum entropy framework and consensus maximization constraints to effectively differentiate between inliers and outliers, thereby improving robustness in maximum consensus fitting. |
| Method | RANSAC | BCD-L1 | MAGSAC++ | EES | VSAC | MECC-L1 | MECC-RANSAC | |
|---|---|---|---|---|---|---|---|---|
| homogr | failure ratio (%) | 17.86 | 14.47 | 11.08 | 9.34 | 9.14 | 9.20 | 9.15 |
| 16 image pairs | geometric error (pixel) | 2.02 | 1.36 | 1.19 | 1.06 | 1.05 | 1.04 | 1.03 |
| time (milliseconds) | 255.3 | 97.6 | 101.5 | 65.3 | 70.2 | 69.7 | 271.2 | |
| EVD | failure ratio (%) | 23.27 | 15.33 | 17.62 | 16.37 | 14.91 | 14.88 | 14.69 |
| 15 image pairs | geometric error (pixel) | 1.80 | 1.20 | 1.03 | 0.97 | 0.91 | 0.96 | 0.93 |
| time (milliseconds) | 339.1 | 103.6 | 143.3 | 49.3 | 53.1 | 51.4 | 350.9 | |
| Hpatches | failure ratio (%) | 26.86 | 10.49 | 8.61 | 7.33 | 6.91 | 6.74 | 6.82 |
| 142 image pairs | geometric error (pixel) | 3.46 | 1.55 | 1.34 | 1.24 | 1.26 | 1.23 | 1.20 |
| time (milliseconds) | 361.3 | 94.6 | 112.5 | 46.0 | 74.6 | 46.3 | 372.1 | |
| kusvod2 | failure ratio (%) | 21.49 | 12.01 | 11.15 | 9.63 | 9.20 | 9.23 | 9.26 |
| 16 image pairs | geometric error (pixel) | 2.13 | 1.41 | 1.27 | 0.89 | 0.90 | 0.91 | 0.86 |
| time (milliseconds) | 348.2 | 65.4 | 171.6 | 34.2 | 48.2 | 35.3 | 362.1 | |
| Adelaide | failure ratio (%) | 15.23 | 9.21 | 7.61 | 6.99 | 6.47 | 6.73 | 6.54 |
| 19 image pairs | geometric error (pixel) | 1.48 | 0.95 | 0.87 | 0.78 | 0.56 | 0.57 | 0.53 |
| time (milliseconds) | 307.4 | 58.6 | 143.1 | 33.7 | 43.7 | 34.6 | 320.1 | |
| PhotoTour | failure ratio (%) | 20.05 | 13.32 | 9.24 | 7.09 | 7.18 | 7.08 | 7.10 |
| 500 image pairs | geometric error (pixel) | 1.57 | 1.05 | 0.85 | 0.68 | 0.61 | 0.65 | 0.64 |
| time (milliseconds) | 292.4 | 95.9 | 189.9 | 40.3 | 78.1 | 40.9 | 333.6 | |
| ALL | failure ratio (%) | 20.79 | 12.47 | 10.89 | 9.46 | 8.97 | 8.98 | 8.93 |
| geometric error (pixel) | 2.08 | 1.25 | 1.09 | 0.94 | 0.88 | 0.89 | 0.86 | |
| 708 image pairs | time (milliseconds) | 317.28 | 85.95 | 143.65 | 44.80 | 61.32 | 46.37 | 335.00 |
| Image (Correspondence Size) | RANSAC | BCD-L1 | MAGSAC++ | EES | VSAC | MECC-L1 | MECC-RANSAC |
|---|---|---|---|---|---|---|---|
| Christ (515) | 287 | 292 | 295 | 296 | 300 | 297 | 298 |
| University (603) | 471 | 506 | 505 | 508 | 509 | 508 | 510 |
| Bodleian (249) | 166 | 166 | 168 | 170 | 173 | 173 | 174 |
| Magdalen (1429) | 1286 | 1285 | 1288 | 1289 | 1291 | 1288 | 1290 |
| Radcliffe (287) | 169 | 172 | 173 | 175 | 175 | 176 | 177 |
| Aerial I (545) | 315 | 317 | 318 | 320 | 323 | 320 | 322 |
| Corridor (490) | 374 | 376 | 377 | 377 | 380 | 378 | 379 |
| Kapel (537) | 320 | 322 | 323 | 322 | 325 | 324 | 323 |
| Merton II (1125) | 845 | 853 | 854 | 855 | 856 | 855 | 856 |
| Merton III (891) | 550 | 548 | 549 | 550 | 551 | 552 | 551 |
| Valbonne (505) | 269 | 276 | 277 | 278 | 280 | 276 | 278 |
| Boat (1002) | 782 | 779 | 784 | 785 | 788 | 786 | 788 |
| Bark (1011) | 880 | 882 | 885 | 887 | 886 | 884 | 885 |
| Bikes (2061) | 1531 | 1528 | 1533 | 1533 | 1536 | 1534 | 1537 |
| Graff (1444) | 800 | 805 | 806 | 805 | 807 | 805 | 806 |
| Trees (1848) | 1131 | 1129 | 1134 | 1134 | 1136 | 1133 | 1136 |
| Build 4 (454) | 217 | 204 | 219 | 220 | 224 | 221 | 225 |
| Build 5 (873) | 550 | 552 | 553 | 557 | 556 | 555 | 554 |
| Build 22 (807) | 469 | 471 | 473 | 474 | 473 | 471 | 473 |
| Build 24 (501) | 255 | 258 | 260 | 261 | 264 | 265 | 266 |
| Build 28 (504) | 232 | 237 | 239 | 241 | 246 | 245 | 248 |
| Build 37 (413) | 181 | 183 | 184 | 185 | 187 | 185 | 186 |
| Build 59 (644) | 319 | 324 | 325 | 325 | 326 | 324 | 325 |
| Build 67 (571) | 231 | 234 | 236 | 235 | 239 | 237 | 240 |
| Build 199 (613) | 286 | 286 | 288 | 289 | 289 | 290 | 290 |
| Image (Correspondence Size) | RANSAC | BCD-L1 | MAGSAC++ | EES | VSAC | MECC-L1 | MECC-RANSAC |
|---|---|---|---|---|---|---|---|
| House (656) | 240 | 267 | 276 | 277 | 278 | 278 | 280 |
| Aerial (583) | 264 | 285 | 290 | 289 | 290 | 288 | 291 |
| Merton (590) | 295 | 317 | 322 | 324 | 326 | 323 | 325 |
| Wadham (618) | 305 | 325 | 333 | 334 | 335 | 334 | 336 |
| Corridor (684) | 310 | 386 | 390 | 390 | 393 | 389 | 391 |
| University Library (439) | 224 | 249 | 248 | 251 | 253 | 251 | 254 |
| Christ Church (524) | 258 | 313 | 315 | 317 | 319 | 319 | 320 |
| Kapel (449) | 160 | 211 | 213 | 215 | 217 | 217 | 217 |
| Invalides (558) | 180 | 228 | 230 | 232 | 232 | 233 | 234 |
| Union House (520) | 230 | 288 | 291 | 292 | 291 | 292 | 291 |
| Old Classic Wing (561) | 310 | 386 | 390 | 390 | 393 | 389 | 391 |
| Ball Hall (538) | 170 | 212 | 215 | 217 | 219 | 220 | 220 |
| Build 04 (394) | 181 | 192 | 197 | 198 | 197 | 196 | 196 |
| Build 10 (546) | 214 | 252 | 255 | 257 | 259 | 258 | 260 |
| Build 23 (699) | 315 | 330 | 332 | 332 | 335 | 333 | 334 |
| Build 36 (651) | 275 | 321 | 322 | 323 | 324 | 322 | 325 |
| Build 64 (529) | 187 | 235 | 237 | 238 | 240 | 239 | 240 |
| Build 81 (525) | 262 | 311 | 316 | 317 | 320 | 318 | 320 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, G.M.; Min, Z.; Kakani, V.; Jo, G.-S. An Efficient Maximum Entropy Approach with Consensus Constraints for Robust Geometric Fitting. Electronics 2024, 13, 2972. https://doi.org/10.3390/electronics13152972
Hassan GM, Min Z, Kakani V, Jo G-S. An Efficient Maximum Entropy Approach with Consensus Constraints for Robust Geometric Fitting. Electronics. 2024; 13(15):2972. https://doi.org/10.3390/electronics13152972
Chicago/Turabian StyleHassan, Gundu Mohamed, Zijian Min, Vijay Kakani, and Geun-Sik Jo. 2024. "An Efficient Maximum Entropy Approach with Consensus Constraints for Robust Geometric Fitting" Electronics 13, no. 15: 2972. https://doi.org/10.3390/electronics13152972
APA StyleHassan, G. M., Min, Z., Kakani, V., & Jo, G.-S. (2024). An Efficient Maximum Entropy Approach with Consensus Constraints for Robust Geometric Fitting. Electronics, 13(15), 2972. https://doi.org/10.3390/electronics13152972