Abstract
Recent Machine Learning–Assisted Software Vulnerability Detection (MLAVD) research has focused on large-scale models with hundreds of millions of parameters powered by expensive attention- or graph-based architectures. Despite increased model capacity, current models have limited accuracy and struggle to generalize to unseen data. Additionally, the computational resources required to train and serve the models further reduce their usefulness. We argue this is caused by a misalignment between how human brains process code and how MLAVD models are designed. In this paper, we study resource-efficient approaches to MLAVD with the goal of maintaining or strengthening generalizability while reducing computational costs such that the model may be run on an economy developer machine. Our contributions are as follows: (1) We perform the first known study of resource-efficient MLAVD, showing such models can be competitive with strong MLAVD baselines; (2) We design Vul-Mixer, a resource-efficient architecture inspired by how the human brain processes code; and, (3) We demonstrate that Vul-Mixer is efficient and effective by maintaining of the state-of-the-art generalization ability using only of the parameters and 173 MB of memory.
1. Introduction
The exploitation of software vulnerabilities by malicious actors is a real risk to everyone who uses software. Vulnerabilities in corporate systems have regularly led to the exfiltration of intellectual property and the loss of money. Similar faults in consumer-oriented applications expose private information, such as location, banking details, and login credentials [1]. It is insufficient to rely on developers to write secure code due to the risks of releasing vulnerable software and the human propensity to make mistakes. As such, Software Vulnerability Detection (SVD) is a critical component of secure software development. SVD requires a trade-off between cost and accuracy [2]. Peer code reviews require valuable developer time. An inexperienced reviewer may be less expensive but fail to catch vulnerabilities. Static code analysis is fast and relatively inexpensive but suffers from a high false positive rate requiring manual review to triage the results [3]. Techniques such as fuzzing and dynamic analysis have a low false positive rate but are computationally expensive and require expertise to set up effectively.
The application of machine learning to vulnerability detection has increased as machine learning has demonstrated its ability to perform computer vision and natural language processing tasks with near- or super-human performance [4]. Unfortunately, such applications have been met with limited success. Machine Learning–Assisted Software Vulnerability Detection (MLAVD) models are computationally expensive, requiring high-performance GPUs to train and serve the models. The models also face issues with accuracy and frequently fail to generalize to unseen data. Despite these challenges, MLAVD has focused on models with hundreds of millions of parameters—the large language models (LLM) CodeBERT [5] and CoTexT [6] each use over 125 million. With the rise of publicly available generative AI models, MLAVD models are growing to parameters in the billions and trillions [7]. This is not a theoretical concern which poses practical application challenges. For example, Zhou et al. [8] limited their exploration due to the cost of querying LLMs. The limited real-world deployment of these models indicates that their cost-effectiveness is not yet viable [9].
Interestingly, Chen et al. [10] found that code-specific pre-training tasks affected a model’s ability more than size. Thus, the trend to improve performance by expanding models seems to have floundered. Larger models—such as LLMs—are not the exclusive path to better results. Rather, there is a need to tailor models and methods to the vulnerability detection task. Many MLAVD models have used architectures and techniques imported from the fields of computer vision and natural language processing. CodeBERT is based on the BERT architecture designed for language understanding and CoTexT’s T5 was originally used for text generation. Some attempts to convert code into images before training have been made [11]. Neither vision nor natural languages are strong analogs for modern code. A common approach is to convert the code into a graph representation [12,13,14,15]. However, these techniques rely on fragile code parsing and struggle to learn core vulnerability detection activities [16]. Srikant et al. [17] found the multiple-demand system in human brains decodes execution-related properties while the language system primarily decodes syntax-related properties. The multiple-demand system is associated with fluid intelligence [18]. The authors suggest that human behavior is similar to the activity of computer programs combining operations to achieve a goal. Perhaps then the vision- and language-inspired architectures previously applied are ill-suited to capturing the semantics of vulnerabilities. If so, a model better aligned with the human brain’s processes may be both more efficient and effective.
In this paper, we seek an efficient and effective MLAVD model—such that it could feasibly run on an economy developer machine to scan and evaluate code during development. Rather than “just-in-time” vulnerability detection on commit, we might refer to this work as in-line vulnerability detection [19]. More specifically, in-line vulnerability detection could not only prevent vulnerabilities from being added to software but also prevent them from being written in the first place. Also, we build the detection architecture around code instead of modifying the code format to fit the architecture. Accordingly, we present a new machine learning model, Vul-Mixer, designed specifically for MLAVD. We draw inspiration from current research on how the brain understands code and combine that understanding with the task-specific details of vulnerability detection. To this end, we design a series of paths through a Mixer-style architecture that is selected to promote divergent learning of vulnerability-relevant code features. Further, we design these paths to maximize the resource efficiency (e.g., parameters, training/inference time) of the model.
When a model performs well on a training dataset but does not generalize outside of it, the model has overfit the data [20]. Because overfitting and generalizability are key problems in MLAVD, we integrate them as a core component of our metrics and results. To provide a realistic and unbiased estimate of Vul-Mixer’s performance—rather than its ability to fit a particular dataset—we perform extensive experiments on and across multiple SVD datasets. This is a common practice in other machine learning fields [5,21]. Our experiments demonstrate that Vul-Mixer outperforms all resource-efficient baselines by 6 to . It is an efficient and effective model which is shown by outperforming multiple MLAVD baselines. Vul-Mixer maintains of CodeBERT’s generalization performance while being only of its size. It is the most cost-effective model as measured against multiple ratios. When evaluated against real-world vulnerabilities, Vul-Mixer is superior to all baselines with an score that is 6 to higher. We make the following contributions:
- We perform the first known study of resource-efficient MLAVD, showing that resource-efficient models can be competitive with MLAVD baseline models.
- We design Vul-Mixer, a resource-efficient architecture, inspired by the multiple-demand system and research on how humans process code.
- We produce an efficient and effective model, demonstrating the vastly superior resource-effectiveness and maintained generalizability of Vul-Mixer compared to strong and up-to-date MLAVD baselines.
2. Preliminaries and Motivation
2.1. Problem Statement and Notations
Software vulnerability detection can occur at multiple granularities. We address it at the function level where the objective is to identify whether a given function is vulnerable or not based solely on its source code. We define the source code of a function as and the label set as where 1 is vulnerable and 0 is presumed not. Thus, vulnerability detection may be defined as the mapping function: . In this work, we consider machine learning–assisted software vulnerability detection (MLAVD), where the mapping function f is learned by minimizing a loss function .
Further, we consider the resource efficiency of the machine learning models. Resource efficiency is measured by the number of model parameters and the time it takes certain hardware to perform one million training steps or inference operations. For this paper, we label a model x as “resource efficient” if it contains at least one order of magnitude fewer parameters than a selected conventional model s. That is, if . Commonly used variables are defined in Table 1 for easy reference. Other variables are defined throughout.

Table 1.
Common Notations.
2.2. Motivation
- Efficiency. Consider our goal to produce an efficient and effective MLAVD model that is deployable to economy developer machines. Such a model is desirable for several task-specific reasons.
- Early warning and detection of vulnerabilities reduces costs and increases security [22]. The sooner and more frequently code can be reviewed for security, the less likely vulnerabilities are to be introduced to deployed software. Resource-efficient MLAVD run on development machines could check code in real-time and scan projects on each commit. Developers may be warned about potentially vulnerable code as they write it. Further, a model capable of running on economy developer machines could be updated across teams and organizations using privacy-preserving federated learning [23]. Such a system would allow models to learn from data sources that companies would be otherwise reticent to share.
- Large quantities of code are regularly produced and consumed. Code may be consumed as software, libraries, copy-paste from code-sharing sites, and more. Extensive security testing is required to ensure the safety of consumed code. Resource-efficient MLAVD would allow code to be quickly scanned as it is included in projects and systems. Further, Large language models (LLMs) are increasingly capable of writing functional code [24]. While this code may be functional, it is not necessarily secure. Due to the generative nature of the models, multiple similar code options may be produced. Resource-efficient MLAVD could offer a score to rank the relative security of the code options on the developer machine and alert users to potentially insecure code. In addition to resource efficiency, using an architecture distinctly different from the LLM may offer increased resilience against the biases of a single architecture, an ensemble model of sorts.
- Security concerns may preclude using externally hosted LLMs for vulnerability detection. The transfer of code—a highly confidential product—to a third-party server carries inherent risk and increases a company attack surface. Overall, an efficient model with effectiveness comparable to larger models would be easier to adopt due to lowered costs.
- Human Brain–Inspiration and Intuition. Many artificial neural networks have been inspired by natural neural networks leading to significant advances [25]. The visual cortex is often referenced for computer vision and the language system for natural language processing. However, Srikant et al. [17] shows the multiple-demand system decodes run-time properties of code significantly better than the visual or language systems. The multiple-demand system is associated with fluid intelligence [18]. Meanwhile, the language system encodes syntactic information. We posit that aligning a neural architecture with the multiple-demand system will increase the effectiveness of the model.
As Duncan [18] demonstrates, tasks are completed by separately defining and solving a series of subtasks. SVD is no exception. Consider the case of a buffer overflow where data are read or written after the end of a buffer. This may be described as the following series of sub-tasks: (1) identify if the code is using a buffer, (2) find the length of the buffer, (3) determine the location being read or written, and (4) verify that the location is past the end of the buffer. Such tasks require maintaining a high-level goal and broad overview of the task while simultaneously digging into specific details of the code.
3. Proposed Model: Vul-Mixer
3.1. Model Overview
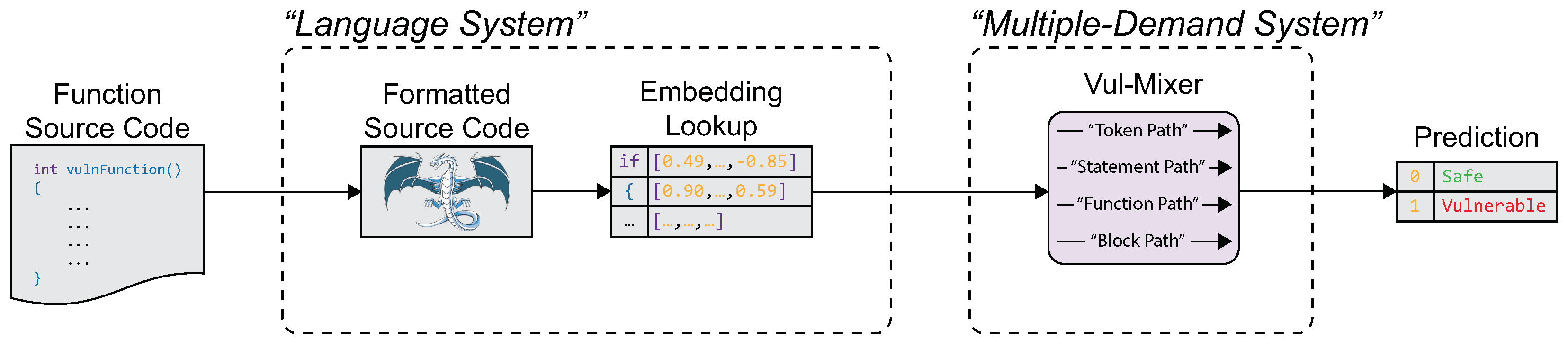
We now propose Vul-Mixer—the first resource-efficient model designed specifically for vulnerability detection. An overview of the system is shown in Figure 1. Functions are accepted as source code which is formatted using Clang then tokenized and embedded using GraphCodeBERT embeddings [26]—similar to the language system. The embeddings are then processed with the Vul-Mixer architecture which is designed to emulate the multiple-demand system. The output follows our problem statement, .
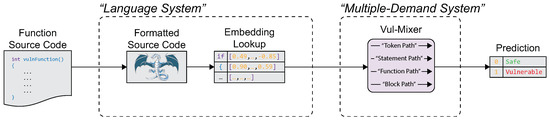
Figure 1.
Overview of Vul-Mixer: using pre-trained embeddings and a custom Mixer architecture to process code snippets and detect their vulnerabilities.
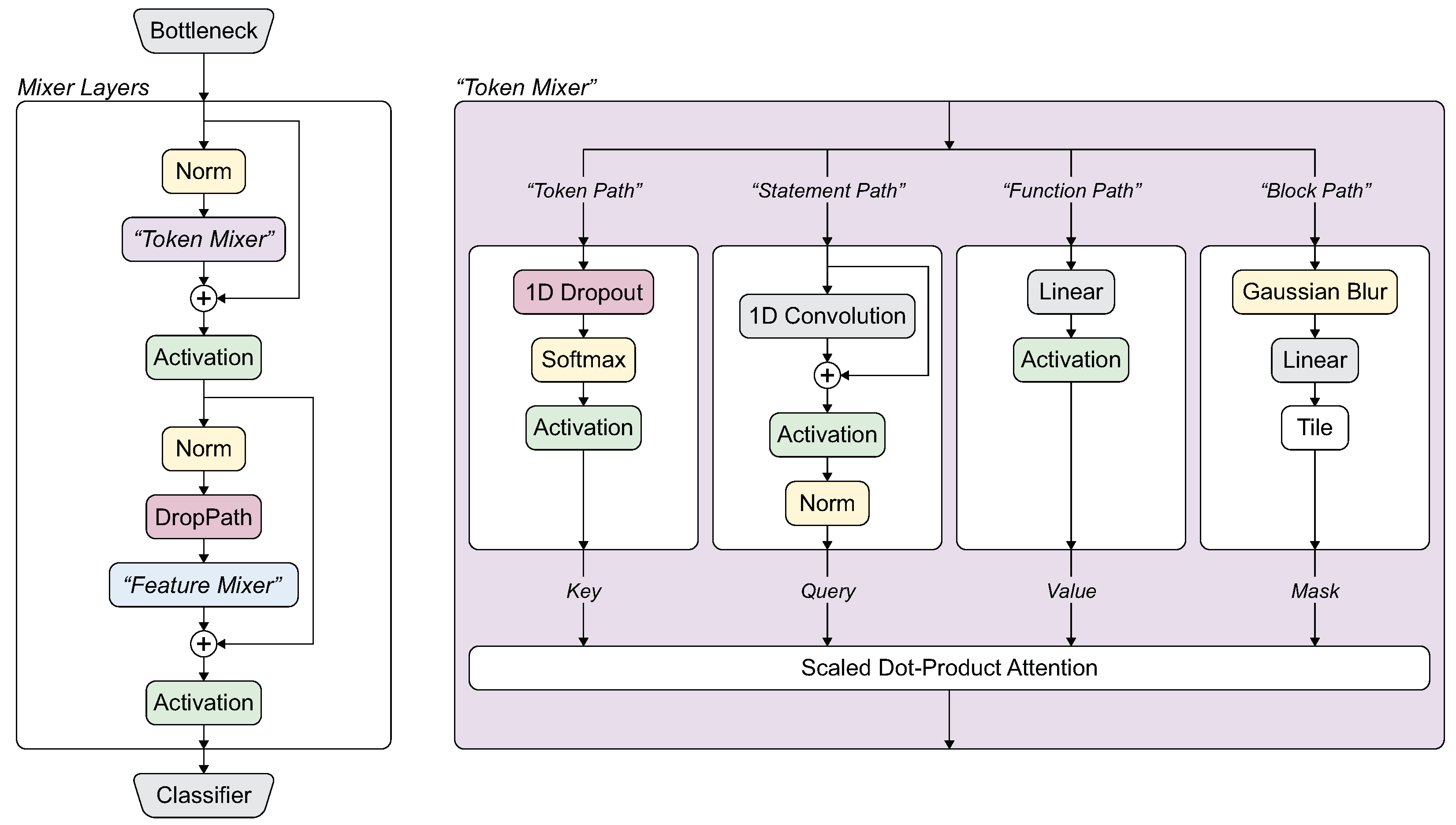
Vul-Mixer is based on the Mixer architecture [27], which contains a series of Mixer layers. Each Mixer layer contains two sub-mixers, which we refer to as the Token Mixer and the Feature Mixer. The token mixer allows connections to be learned across tokens, while the feature mixer allows connections to be learned across features for the same token. Like many Mixers, we use a multi-layer perceptron as a feature mixer. Our token mixer is a novel construction of four distinct “paths” [28]. These paths are drawn from four granularities of code: tokens, statements, blocks, and functions. The paths guide the model to learn from the different aspects of the code. Drawing from the previous example, the block path might identify a buffer use, the token path might find the length of the buffer, and the function path might determine the location of a buffer write. Each path uses different neural components. By constructing these paths, we promote the selection and learning of different sub-tasks, aligning with the current understanding of the multiple-demand system and task decomposition. Since each token mixer is followed by a feature mixer, the paths have the opportunity to interact and share information learned from each path. The model architecture and path construction are shown in Figure 2. In the following sections, we describe this construction in more detail.
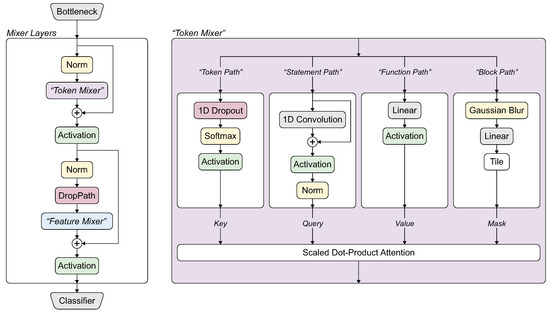
Figure 2.
Mixer architecture with pathways for tokens, statements, blocks, and functions.
3.2. Model Design
- Feature Mixer. The feature mixer uses a standard multi-layer perceptron with two linear layers being separated by a Gaussian Error Linear Unit (GELU) activation function (GELU acts as regularization and activation by applying an identity or zero map to each neuron’s input with an increasing probability of zero as the neuron value decreases) [29]. This is the same feature mixer used by the majority of mixer-based architectures, including MLP-Mixer [27]. The equation for this layer is shown below:
- Token Mixer. The token mixer used by Vul-Mixer employs four pathways to promote differentiated learning of vulnerability-relevant features.
- Token path. The first pathway through the token mixer encourages the regularization of tokens and features through the application of Dropout and scaling. Because Dropout masks entire tokens, we describe this as the token path. It applies a 1D-Dropout followed by the Softmax [30] along the feature dimension and a GELU activation function [29]. The token path is defined as:where produces a sample for each row in the matrix n from the Bernoulli distribution with probability p. Unlike the binomial sampling method used by Liu et al. [28], the 1D-Dropout is applied only during training. This prevents stochastic outputs inherent to a model that applies randomized calculations during inference.
- Statement path. The second path captures information from the tokens surrounding a particular token using a 1D Convolution (1D convolution applies a sliding filter along a single dimension of the input data to extract local features at the “statement” level). We relate this conceptually to statements in source code. To focus the model on the statement level, we choose relatively small kernel sizes that will allow the kernel to contain approximately one statement. A residual connection is applied to the output of the convolution followed by a GELU activation and layer normalization. This statement path is defined as:
- Function path. The simplest path applies a single linear layer followed by a GELU activation. Due to the nature of the linear layer, every token will be able to interact with every other token without restriction. This allows for long-term dependency learning but does not bias the model towards tokens that are close to each other. We call this the function path as it provides the model the ability to learn from the entirety of the function. The formula for this function path is as follows:
- Block path. The final path is designed around the concept of a block. In source code, a block is a series of statements that do not branch—they will always execute sequentially. This level of abstraction is larger than a statement, but usually shorter than a function. In Vul-Mixer, we prompt the model to learn at this level by using a Gaussian blur (Gaussian blur is equivalent to a convolution using the Gaussian kernel). Compared to the Statement path, the Gaussian is not learnable and uses a larger kernel than the convolution. Due to the blur, this path is not able to learn fine-grained vulnerabilities but is constrained to broader features. Because of this constraint, it is a natural fit for an attention mask. After the Gaussian blur, we use a linear layer to reduce each token to a single scalar, which is then tiled to reach the mask size needed for attention. This block path is defined as:
- Merging Paths through Scaled Dot-Product Attention. As previously indicated, the four paths through Vul-Mixer’s token mixer are combined using scaled dot-product attention. The formula is shown below:Further, we make use of a multi-heading mechanism. For the input , where l is the length of the sequence and e is the embedding dimension, we project the input to , where n is the number of heads. The projection is applied before the paths and removed after the scaled dot-product attention.
3.3. Input Normalization and Representation
Code may be written in many ways without affecting functionality. As illustrated by the ubiquity of coding style guides and format checkers, features such as white space, variable names, and comments can be changed for aesthetic purposes alone. We normalize all code using the Clang formatter with a custom style based on the LLVM style. By standardizing these aspects of the input, we reduce the likelihood that the models will learn to predict based on stylistic differences [11]. As a further normalization method, we apply the Drop-Path algorithm proposed by Larsson et al. [31] in place of the standard dropout. Drop-Path is used to prevent the co-adaptation of parallel paths by randomly disabling feature mixers for entire samples within a layer.
Although similar models use a projection to map input tokens to features [32], we opt to leverage the syntactic learning performed by pre-trained models. In particular, we use the tokenizer and embeddings trained by GraphCodeBERT [26]. This aligns with the interaction of the multiple-demand system with the language system. While the language system/pre-trained embeddings learn syntax features, the multiple-demand/Vul-Mixer can interpret the run-time features. The embeddings are frozen and never updated during training. Before the Mixer layers, we follow the standard practice of passing the inputs through a learnable linear bottleneck to reduce the input embedding to a lower dimension across the sequence. After the Mixer layers, a linear classifier is used to map the features to the vulnerable/safe outputs.
3.4. Model Optimization
We train the model using the Adam with decoupled weight decay (AdamW) optimizer [33] and cross-entropy loss. We weigh the loss according to the proportion of safe and vulnerable code in each dataset. The cross-entropy loss is formulated as follows:
where p denotes the predictions, t represents the true class indices, and w signifies the weights for each class.
4. Experimental Setup
4.1. Vulnerability Detection Benchmark Datasets
We use five separate vulnerability detection datasets that have been extensively tested and evaluated by previous works [16,34]. Three (CodeXGLUE, D2A, Draper VDISC) are used to train and test the models to show a comparison against each other. The two remaining—Big-Vul and DiverseVul—are used to evaluate how the models will perform on unseen data in a real-world environment. The data statistics are summarized in Table 2.
Table 2.
Vulnerability Detection Datasets—The datasets listed below were used for the training and evaluation of the models. Empty test information was not present or used. Big-Vul numbers differ slightly from the original publication due to the preparation method.
- CodeXGLUE Defect Detection task is one of 11 code-related tasks aggregated into a code-understanding meta-benchmark. It was originally published as the Devign dataset [35] and was drawn from four open-source projects. Samples are extracted from security-related commits and manually labeled in a cross-verified process.
- D2A is another vulnerability detection dataset sampled from commit messages [36]. Unlike the other datasets in this work, D2A includes data beyond the vulnerable function. However, we use only the vulnerable function which is named the “Function” task by the authors. Samples are labeled using differential analysis of the Infer analyzer bug results from before and after commits. Code in this dataset was deduplicated. Because D2A has a held-out test dataset and our evaluations extend beyond D2A, we use the validation set as the test set. To prevent overfitting, we performed no hyperparameter tuning on the D2A dataset.
- Draper VDISC (VDISC) is the largest dataset considered in the experiment [37]. This size is thanks to an automated labeling process that uses the output from Clang, Cppcheck, and Flawfinder. The dataset was deduplicated but was not subsampled and is thus imbalanced.
- Big-Vul was created by Fan et al. [38] as a method for building a dataset by crawling the Common Vulnerabilities and Exposures (CVE) database. Vulnerability-fixing commits are included as part of the database, so the dataset contains human-verified vulnerabilities. Additionally, each sample contains code from before and after the CVE. This allows us to analyze each of the MLAVD models against code with and without real-world vulnerabilities and fixes. Although Big-Vul contains issues that complicate training a model on it directly [34], these are not relevant as we use Big-Vul only for evaluation and do not train any model on it.
- DiverseVul was created by Chen et al. [10] with code from 797 projects. The labeling of the vulnerabilities came from snyk.io (accessed on 23 June 2024) and bugzilla.redhat.com (accessed on 23 June 2024). It was deduplicated based on the MD5 hash of non-normalized code.
4.2. Baselines
We compare Vul-Mixer to a set of strong baselines from both existing MLAVD and resource-efficient literature. Models are selected based on their performance, and usage in literature, and to ensure a diversity of model types. CodeBERT (LLM) [5], CoTexT (LLM) [6], LineVul (LLM) [39], and ReGVD (Graph-CNN) [40] are selected as MLAVD baselines. For resource-efficient feature mixers, we use an MLP [27], Average Pooling [41], Multi-Head Attention [42], Triple-Concept Attention (TCA) [28], and Shifting [43]. The details of each model are presented in Section 7.
4.3. Parameters, Environment, and Implementation Details
For Vul-Mixer training, we use the hyperparameters specified in Table 3. Vul-Mixer consists of four mixers with kernel sizes of 5, 3, 3, and 3, respectively. The Gaussian blur kernel is set to 17 for all layers. The learnable bottleneck reduces the input embedding from 768 to 128, where the maximum sequence length is set at 1024. It is worth noting that no algorithmic hyperparameter tuning was performed for the evaluations. During experimentation, the results remained relatively consistent regardless of the kernel and blur sizes. We have selected the model that balanced the smallest size with high-performing results. Mixers have been observed to follow scaling laws [41] similar to other model architectures and we believe a larger-scale Vul-Mixer would be no exception. Increasing the size of Vul-Mixer would diminish the benefits of its efficiency. In an informal ablation test where each mixer path was iteratively removed, all paths were critical to the reported metrics. For the MLAVD baselines, we adopt the weights provided by Grahn et al. [16]. For each resource-efficient model, we follow the same training protocol as Vul-Mixer changing only the token mixer and, where necessary due to computational limitations, the batch size. Each model was trained for 20 epochs, regardless of batch size or dataset, on an NVIDIA RTX 3070 GPU with 8 GB of RAM. Validation metrics were monitored and the best-performing results were used. Full details on implementation and training along with the source code are available in the reproduction repository (https://github.com/mlavd/vulmixer, accessed on 23 June 2024).
Table 3.
Hyperparameters—The hyperparameters used to train Vul-Mixer.
4.4. Evaluation Metrics
4.4.1. Effectiveness
CodeXGLUE and D2A are balanced datasets for which accuracy is an appropriate metric while Draper VDISC is an imbalanced dataset. To compare performance, we use average precision (). AP is appropriate for balanced and imbalanced data and considers information at different classification thresholds. Because of this, AP is a useful measure of how well a model has learned a task beyond a specific classification threshold. We combine AP in two ways to capture different aspects of the model’s performance. Mean Average Precision is the harmonic mean of the APs for a model across datasets:
where . incorporates the model’s ability to learn a dataset and to generalize to unseen data. Generalization Average Precision is the harmonic mean of the APs for a model across the datasets on which the model was not trained:
where T is the training dataset. demonstrates the model’s ability to generalize to unseen data. Because this is a known shortcoming of many MLAVD models, it is critical to evaluate this ability as a safeguard against optimizing an already overfit model on a well-used dataset.
4.4.2. Efficiency
A cost-effectiveness ratio is defined as benefit divided by cost and represents the benefit gained per cost unit. In this paper, our cost is a reduction in or while our benefit is a reduction in , , or . Because the number of parameters is significantly different, we take the logarithm of the benefit to weigh the result. Thus, our cost-effectiveness ratio is as follows:
where . An incremental cost-effectiveness ratio compares two options based on the difference in cost divided by the difference in benefit. In healthcare, these metrics are often used to determine the difference in financial costs between two treatments based on the quality-adjusted life years gained. We calculate the incremental cost-effectiveness ratio using the relative change in costs and benefits using the equation:
where and are the metrics for the top-performing model (i.e., CodeBERT), , and with and being the training and inference time from Table 4. It can be understood as the log percent difference in benefit per percent difference in cost. This metric is not calculated for baselines with a negative benefit.
Table 4.
Model Efficiency—Resource-efficient models can be trained and served at least 5 times faster than CodeBERT, the top-performing MLAVD baseline. Timing is for 1M functions sampled from the Wild C dataset [34] on an NVIDIA RTX 3070.
5. Experimental Results and Analysis
In this section, we aim to evaluate our model for vulnerability detection to answer the following research questions.
- RQ1: How efficient is Vul-Mixer compared to baselines?
- RQ2: How effective is Vul-Mixer compared to resource-efficient baselines?
- RQ3: How effective is Vul-Mixer compared to MLAVD baselines?
- RQ4: How cost-effective is Vul-Mixer compared to baselines?
- RQ5: Is Vul-Mixer useful in real-world settings?
5.1. RQ1: How Efficient Is Vul-Mixer Compared to the Baselines?
Table 4 shows the number of parameters associated with each baseline and Vul-Mixer. Additionally shown is the time it takes to run training or inference on one million samples randomly drawn from the Wild C dataset [34]. As initialized, all resource-efficient baselines meet the definition presented in Section 2.
Result 1: Vul-Mixer is 492–980x smaller than MLAVD baselines. Vul-Mixer has parameters, which is slightly more than the resource-efficient baselines with the fewest parameters Avg Pool and Shift, both with . Shift and Avg Pool do not have any trainable parameters in their token mixers. Thus, Vul-Mixer has only 22,000. While MLP-Mixer is a single order of magnitude smaller than the MLAVD baselines, Vul-Mixer and the other resource-efficient baselines are two orders of magnitude smaller. When run with a batch size of 1, to estimate the minimum requirements, Vul-Mixer requires only 173 MB of memory—small enough to run on any modern system.
Result 2: Vul-Mixer is 3–60x faster than MLAVD baselines. We time each model on functions sampled from the Wild C dataset. It is important to note that the times shown are not the total training time required for the models. In practice, the time required to train the models is dependent upon the size of the dataset, the number of epochs, the hardware, and other factors. Based on our timings, Vul-Mixer takes more time to train and infer than other resource-efficient models by 29 and 1 s, respectively. This represents an increase in training time and a increase in inference time. Despite this increase, Vul-Mixer is two times faster to train and three times faster to infer than the fastest baseline, ReGVD. CodeBERT and LineVul are two orders of magnitude slower than Vul-Mixer while CoTexT is three orders of magnitude slower to train and nearly three to infer.
5.2. RQ2: How Effective Is Vul-Mixer Compared to Resource-Efficient Baselines?
We first compare Vul-Mixer to the strong resource-efficient baselines trained and tested on the MLAVD task. Each model is trained and tested on three datasets: CodeXGLUE, D2A, and Draper VDISC. The models are tested on all three datasets regardless of the model on which they were trained. The corresponding and metrics are displayed in Table 5. The and are lower when trained on CodeXGLUE and D2A because the models have low generalization precision and Draper VDISC is an imbalanced dataset.
Table 5.
Vul-Mixer vs. Resource-Efficient Baselines—Vul-Mixer has a higher and than the resource-efficient baselines by a significant margin demonstrating both its ability to learn and generalize the task.
Result 3: Vul-Mixer has a MAP that is 6–13% higher than resource-efficient baselines. Vul-Mixer consistently outperforms the resource-efficient baselines. This is most notable on CodeXGLUE where Vul-Mixer achieves a of – higher than the second-ranked TCA. When calculated over all training datasets, Vul-Mixer achieves a of which is higher than the next model.
Result 4: Vul-Mixer generalizes 7–14% better than resource-efficient baselines. Vul-Mixer is also able to generalize better than resource-efficient baselines. It has the highest with a score of , which is higher than the next-highest . Note, that the second ranked models for and are not the same.
5.3. RQ3: How Effective Is Vul-Mixer Compared to MLAVD Baselines?
We next compare Vul-Mixer to baseline models from existing MLAVD literature using the same process as RQ2. The results are shown in Table 6. The MLAVD baseline results vary across datasets. For instance, CodeBERT is the top overall baseline but ranks third for both and when trained on CodeXGLUE.
Table 6.
Vul-Mixer vs. MLAVD Baselines—Vul-Mixer is the third-ranked model compared to MLAVD baselines with a lower and lower than CodeBERT.
Result 5: Vul-Mixer has a MAP 97–120% that of MLAVD baselines. Vul-Mixer ranks third by amongst the MLAVD baselines, outperforming CoTexT and ReGVD. Because CodeBERT and LineVul share a common architecture, Vul-Mixer is the second-ranked overall. It retains of CodeBERT’s performance with a of .
Result 6: Vul-Mixer generalizes 98–121% as well as MLAVD baselines. Vul-Mixer effectively closes the gap between resource-efficient and MLAVD baselines with a that is of CodeBERT. There is only a absolute difference and a relative difference between their scores. This confirms that Vul-Mixer performs significantly better than both CoTexT and ReGVD.
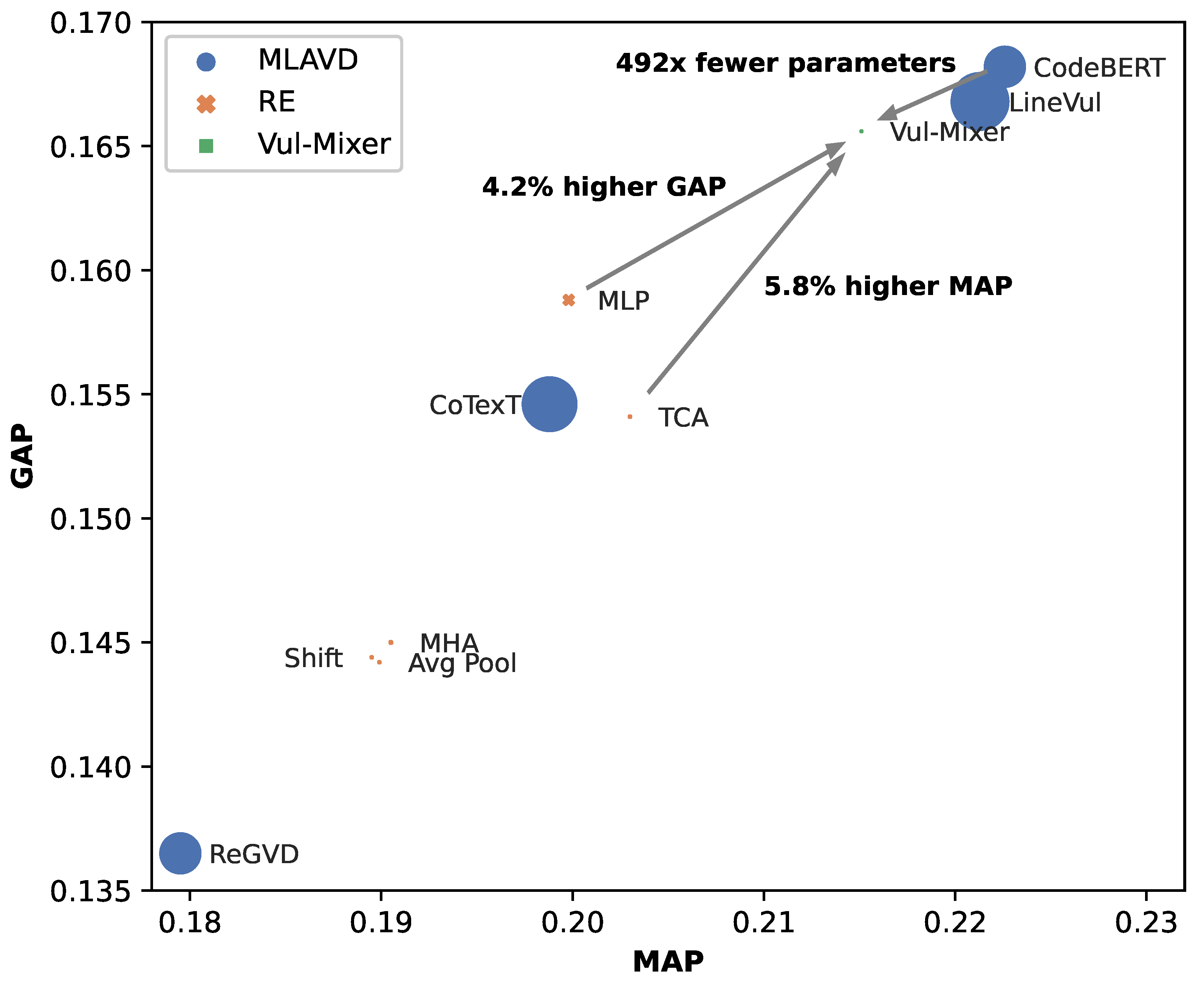
A visualization of the and scores with the number of parameters is shown in Figure 3. Vul-Mixer is aligned with CodeBERT and LineVul for the top and scores and is separated from all other baselines. However, the size of the plotted points shows a clear separation in size between the models. In summary, Vul-Mixer is the resource-efficient model that is as effective as state-of-the-art MLAVD baselines.
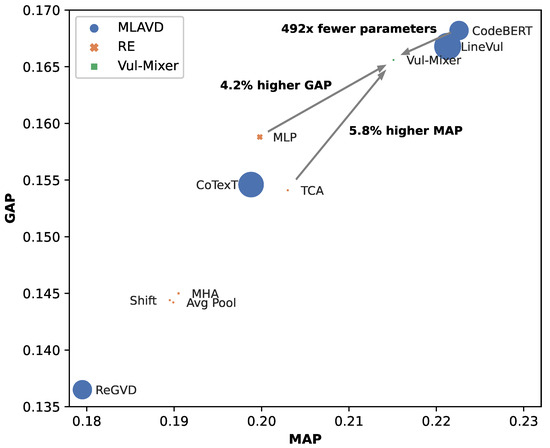
Figure 3.
Vul-Mixer is the top-ranked resource-efficient model and third highest-performing model with significantly fewer parameters than MLAVD baselines. Points are scaled by model size.
5.4. RQ4: How Cost-Effective Is Vul-Mixer Compared to Baselines?
We now quantify the trade-off between efficiency and efficacy using cost-effectiveness and incremental cost-effectiveness ratios (ICER) [44]. The results are shown in Table 7.
Table 7.
Resource-Effectiveness—Vul-Mixer is the most resource-efficient model compared to resource-efficient and MLAVD baselines on all cost-effectiveness ratios. Incremental-cost effectiveness ratios are calculated using CodeBERT.
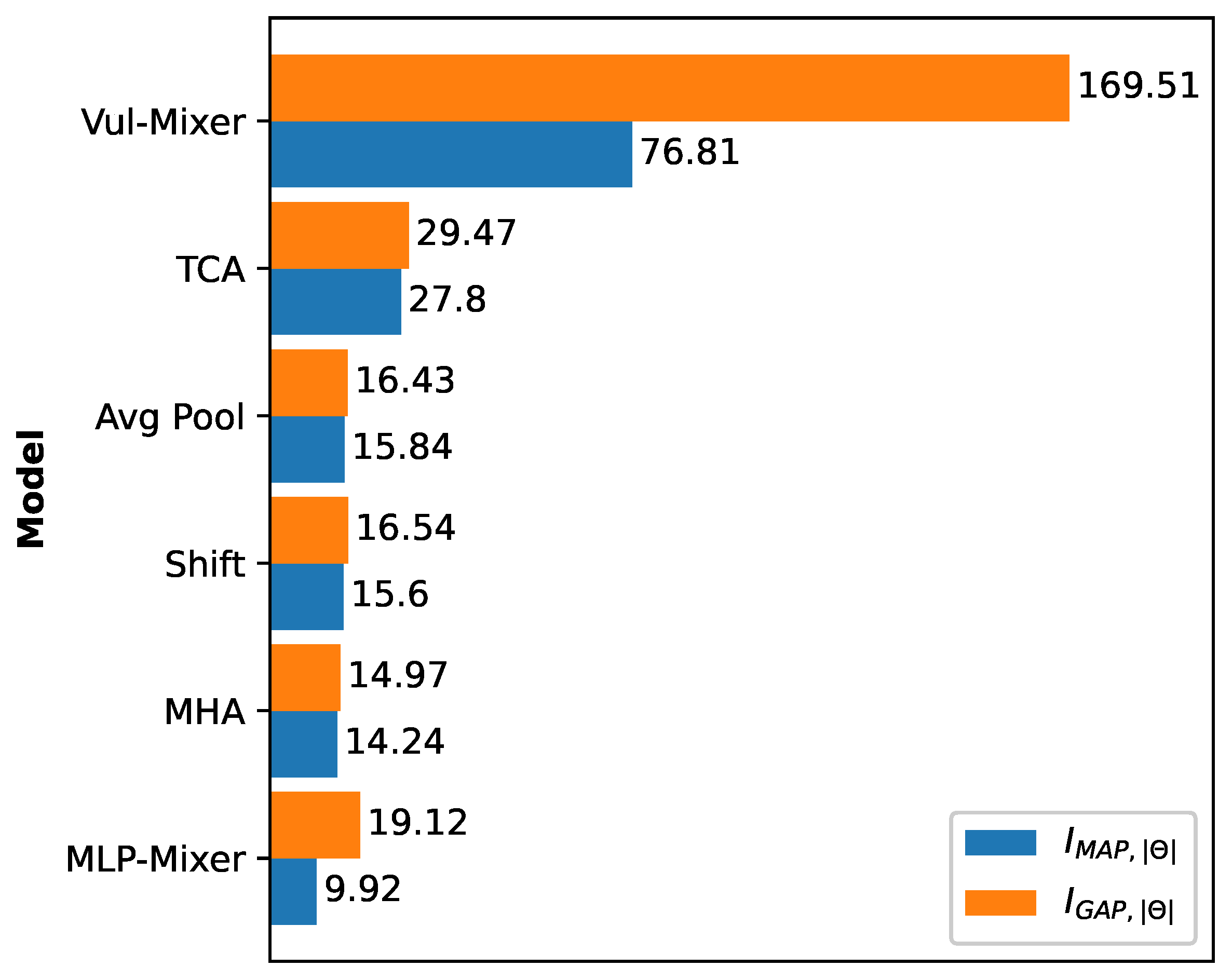
Result 7: Vul-Mixer is the most cost-effective MLAVD model. Across all ratios of effectiveness, Vul-Mixer obtains the top score. In other words, Vul-Mixer uses parameters and computational time more efficiently than all MLAVD and resource-efficient baselines. This is an indication that the architecture has been well-designed to promote the learning of features relevant to vulnerabilities. While TCA is the second most efficient architecture, it has far lower and scores than Vul-Mixer. The comparative results are further visualized in Figure 4.
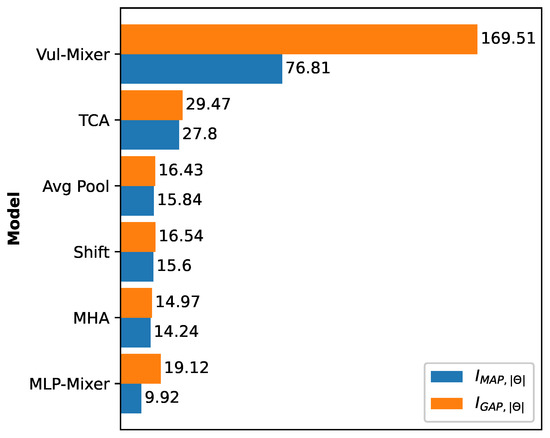
Figure 4.
Evaluation of resource-effectiveness by comparing Vul-Mixer to other resource-efficient models in terms of their incremental MAP and GAP with the difference in the number of parameters , which represents the log percent difference in benefit per percent difference in cost.
5.5. RQ5: Is Vul-Mixer Useful in Real-World Settings?
Finally, we wish to evaluate if Vul-Mixer is useful in a real-world setting. Rather than demonstrate Vul-Mixer’s ability to find a handful of vulnerabilities within a project, we quantify its performance in terms of , precision, and recall on a collection of previously unseen vulnerabilities using the Big-Vul and DiverseVul datasets. They are both collected from high-quality sources providing high-accuracy true positives. We use three pieces of data from Big-Vul: (1) the vulnerable functions before being fixed, (2) the vulnerable functions after being fixed, and (3) the safe functions. The inclusion of functions before and after fixing intentionally increases the difficulty of the dataset. The prediction results for Vul-Mixer and the MLAVD baselines on this formulation of Big-Vul are shown in Table 8.
Table 8.
Real-World Evaluation—Vul-Mixer is the new state-of-the-art model when tested on real-world vulnerabilities available through Big-Vul. It increases recall by and precision by when compared to LineVul, the previous top model.
Result 8: Vul-Mixer is state-of-the-art for generalizing to Big-Vul. Vul-Mixer obtains the highest score of which is a improvement over LineVul’s . This includes a increase in precision ( to ) and a increase in recall ( to ). Precision and recall can often be too abstract to evaluate actual performance. To translate this into more interpretable numbers, assume a project contains 100 vulnerabilities. Vul-Mixer would have 62 true positives and 1588 false positives. LineVul would have 47 true positives and 1654 false positives. CodeBERT, which has the highest precision at , would have 26 true positives and 1526 false positives.
Result 9: Vul-Mixer is state-of-the-art for generalizing to DiverseVul. Although a direct comparison with Chen et al. [10] is not possible due to a lack of details, these metrics are in line with their results testing the generalization of baselines trained on a combination of datasets slightly smaller than Draper VDISC. Vul-Mixer performs similarly on DiverseVul to Big-Vul. It posts the top score demonstrating the robustness of these results.
We suspect that the lower overall metrics are a continued symptom of biased datasets. However, the low cost of Vul-Mixer makes it particularly useful for prioritizing functions for more accurate but expensive vulnerability detection methods. Due to its high recall, it is well-suited to the applications discussed in Section 2.2.
5.6. Error Analysis
To understand the errors that Vul-Mixer makes, we first perform a Kolmogorov–Smirnov test between the distribution of predictions generated from safe and vulnerable samples in the D2A validation set. With the null hypothesis that the vulnerable distribution is less than or equal to the safe distribution, we may reject the null with a p-value of . This demonstrates that Vul-Mixer separates safe and vulnerable code sufficiently to detect a distributional shift.
Due to the fact that the datasets contain limited information about the structural details of the vulnerabilities contained within the code, it is challenging to say with certainty what are the most or least frequent errors that Vul-Mixer makes. Rather than cherry-picking relevant results, we present the two worst predictions based on the discrepancy between the predicted and target values—one safe and one vulnerable. Figure 5 depicts a function with a prediction score of , whose ground truth, however, is safe. It is related to the FFMPEG library and heavily uses buffers and bitwise operations. Although safe, it is certainly a complex function.

Figure 5.
Safe function with the highest vulnerability prediction score.
Similarly, Figure 6 illustrates a function with a prediction score of that is actually vulnerable. This function relates to OpenSSL’s verification of an X.509 digital certificate, which allocates space with OPENSSL_malloc but never releases it. In the context of this function, this counts as a memory leak. It is worth noting that this pattern is commonly used by the OpenSSL library, and similar functions remain in its current code base (https://github.com/openssl/openssl/blob/master/crypto/x509/x509_vpm.c#L82, accessed on 23 June 2024). Given that D2A labels data through a differential analysis, it is arguable whether this function should be truly labeled as a vulnerability.

Figure 6.
Vulnerable function with the lowest vulnerability prediction score.
6. Discussion: Threats to Validity
The primary threat to validity is whether vulnerability detection datasets are sufficiently diverse and unbiased for a model to learn the vulnerability detection task. For instance, Grahn et al. [34] found MLAVD datasets have a tendency towards code that uses registers and the extern keyword. Juliet, a common MLAVD dataset that was not used in this work, includes significant pre-split data augmentation. In addition, Zheng et al. [45] also identified some data issues such as duplicated data, incomplete information, and inaccurate labels. Biases present in the dataset may result in models learning those misleading patterns rather than the underlying task. To mitigate these issues, we train and test each model across multiple datasets, ensuring a more comprehensive evaluation and reducing the impact of any single dataset’s biases. Previous research indicates that the dataset biases are inconsistent, and the ability of a model to generalize to unseen datasets is a better indicator of its overall performance [16].
Furthermore, we perform a set of tests directly on known CVE vulnerabilities. We believe that the aggregate metrics provide a more accurate and unbiased representation of how each model performs on the task, independent of the dataset, programming language, or vulnerability type. Therefore, when trained on a sufficiently large and diverse dataset, we expect each model’s relative ranking to remain consistent.
Additionally, a lack of understanding of how the brain processes code (either on our part or in current research) could mean that this architecture is not well aligned with how the brain functions. While we argue that better-aligned models would perform better, the motivation of this paper was to draw inspiration from the brain’s functionality, not necessarily to emulate it. The results presented are not affected by how well-aligned the model is with brain processes.
7. Related Work
Machine learning has been extensively adopted for vulnerability detection, leading to significant advancements in the field. In this section, we primarily review the research related to the MLAVD and resource-efficiency models.
7.1. MLAVD Models
CodeBERT is a BERT-style model that was pre-trained on code, natural language, and pairs of code and natural language [5]. The data included code samples from Python, Java, JavaScript, PHP, Ruby, and GO. Despite CodeBERT not being trained in C/C++ language, it is frequently used for MLAVD on these languages [46,47]. Upon its release, CodeBERT was the leader for the CodeXGLUE Defect Detection task [48].
“Code and TExt Transfer Transformer” or CoTexT is a T5-based model [6]. Since T5 is a sequence-to-sequence model, vulnerable code is mapped to “true” and non-vulnerable code to “false”. At the time of the research, it was the second-ranked model for the CodeXGLUE Defect Detection task (The top-ranked model is UniXcoder-nine-MLP from the “Academy of Military Sicences”, but no other information is available [49]).
LineVul is a larger version of CodeBERT, trained by Fu et al. [39] on Big-Vul. This dataset is known to contain significant near-duplicate data leakage between the training and test data [34]. However, LineVul performs far better than others on the dataset. Its inclusion facilitates comparison against different model sizes and pretraining techniques on the same architecture.
“Rethinking Graph Vulnerability Detection” or ReGVD is a graph-based model that constructs its graph based on the adjacency and similarity of tokens [40]. Each token is used as a node and the edges are added if two different tokens co-occur within a sliding window. The node features are created from CodeBERT embeddings. ReGVD offers an alternative to the LLM-based methods and a novel graph-construction method.
7.2. Resource-Efficient Models
MLP-Mixer was the first “Mixer-style” architecture to be proposed [27]. Although designed for vision tasks, it has since been expanded to text [32]. The goal of the mixer architecture is to separate feature- and token-mixing operations. Both of these operations are performed by MLPs. The MLP equation is shown in Equation (1). The token mixer (the first MLP) is the primary area of variation in subsequently described baselines. In this work, all mixer-style models share the same feature mixer with MLP-Mixer. MLP-Mixer was the first Mixer architecture proposed and is a commonly used resource-efficient baseline.
The Multi-Head Attention–mixer (MHA) is equivalent to the Transformer Encoder proposed by Vaswani et al. [42]. For its token-mixer, it uses the multi-head scaled dot-product attention, where attention is defined as:
where is the dimensionality of the query (Q) and key (K). Unlike CodeBERT or LineVul, the MHA-Mixer is deliberately initialized as a resource-efficient model with limited parameters. MHA offers an opportunity to observe how a small LLM might perform and demonstrate the effects of scaling.
Average Pooling as a token mixer is proposed by Yu et al. [41]. Although their paper centers on the description of the MetaFormer architecture as a generalization of Mixers and Transformers, their PoolFormer achieves competitive performance when scaled to a size similar to other vision architectures. Pooling is an extremely simple operation that has achieved remarkable results despite adding no trainable parameters.
Shifting has been used by multiple works as a mixer [43,50]. Each work offers slightly different variations on the shifting operation, where a basic formulation can be defined as:
Shifting functions similarly to a convolutional neural network (CNN)’s receptive fields or local attention, yet with far simpler calculations.
Triple-Concept Attention (TCA) is a complex attention variant introduced by Liu et al. [28]. TCA is the inspiration and predecessor of Vul-Mixer. TCA does not use Vul-Mixer’s block path. Further, it is equivalent to the token path using a Bernoulli sampling method that is applied both during training and inference. The result is that the mapping of inputs to outputs is affected by a hidden, random calculation. TCA performs well in NLP problems and, as the inspiration for Vul-Mixer, shows the effects of our architectural changes.
8. Conclusions
In this paper, we consider vulnerability detection at the function level using machine learning focusing particularly on efficient and effective MLAVD. We introduce Vul-Mixer, an MLAVD-specific model inspired by the multiple-demand system and how the brain processes code. Vul-Mixer separates syntactic from runtime learning by using a pre-trained embedding matrix. To demonstrate the effectiveness of Vul-Mixer, we conduct detailed experiments focusing on the generalizability shortcomings of MLAVD models. Our results show that Vul-Mixer is an efficient and effective model. When tested on unseen data in a real-world setting, Vul-Mixer obtains state-of-the-art results with significantly higher recall. This enhanced recall indicates that Vul-Mixer may be successfully applied as an early-detection model on economy developer machines—even a Raspberry Pi Zero—or in high-volume pipelines. Future research may explore whether scaling Vul-Mixer will reduce the generalization problem.
Author Contributions
Conceptualization, D.G.; methodology, D.G., L.C. and J.Z.; software, D.G.; validation, D.G.; writing—original draft, D.G.; writing—review and editing, L.C. and J.Z.; supervision, L.C. and J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
https://github.com/mlavd/vulmixer, accessed on 23 June 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Tian, Z.; Tian, B.; Lv, J.; Chen, Y.; Chen, L. Enhancing vulnerability detection via AST decomposition and neural sub-tree encoding. Expert Syst. Appl. 2024, 238, 121865. [Google Scholar] [CrossRef]
- Elahi, G.; Yu, E. A goal oriented approach for modeling and analyzing security trade-offs. In Proceedings of the Conceptual Modeling-ER 2007: 26th International Conference on Conceptual Modeling, Auckland, New Zealand, 5–9 November; Springer: Berlin/Heidelberg, Germany, 2007; pp. 375–390. [Google Scholar]
- Austin, A.; Holmgreen, C.; Williams, L. A comparison of the efficiency and effectiveness of vulnerability discovery techniques. Inf. Softw. Technol. 2013, 55, 1279–1288. [Google Scholar] [CrossRef]
- Wurman, P.R.; Barrett, S.; Kawamoto, K.; MacGlashan, J.; Subramanian, K.; Walsh, T.J.; Capobianco, R.; Devlic, A.; Eckert, F.; Fuchs, F.; et al. Outracing champion Gran Turismo drivers with deep reinforcement learning. Nature 2022, 602, 223–228. [Google Scholar] [CrossRef] [PubMed]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. Codebert: A pre-trained model for programming and natural languages. arXiv 2020, arXiv:2002.08155. [Google Scholar]
- Phan, L.; Tran, H.; Le, D.; Nguyen, H.; Anibal, J.; Peltekian, A.; Ye, Y. Cotext: Multi-task learning with code-text transformer. arXiv 2021, arXiv:2105.08645. [Google Scholar]
- Fu, M.; Tantithamthavorn, C.; Nguyen, V.; Le, T. ChatGPT for Vulnerability Detection, Classification, and Repair: How Far Are We? arXiv 2023, arXiv:2310.09810. [Google Scholar]
- Zhou, X.; Zhang, T.; Lo, D. Large Language Model for Vulnerability Detection: Emerging Results and Future Directions. arXiv 2024, arXiv:2401.15468. [Google Scholar]
- Wakabayashi, M. Experiments Show AI Could Help Audit Smart Contracts, But Not Yet. Available online: https://cointelegraph.com/news/ai-could-help-audit-smart-contracts-but-not-yet (accessed on 23 June 2024).
- Chen, Y.; Ding, Z.; Alowain, L.; Chen, X.; Wagner, D. Diversevul: A new vulnerable source code dataset for deep learning based vulnerability detection. In Proceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses, Hong Kong, China, 16–18 October 2023. [Google Scholar]
- Wu, Y.; Zou, D.; Dou, S.; Yang, W.; Xu, D.; Jin, H. VulCNN: An image-inspired scalable vulnerability detection system. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 25–27 May 2022; pp. 2365–2376. [Google Scholar]
- Sun, H.; Cui, L.; Li, L.; Ding, Z.; Li, S.; Hao, Z.; Zhu, H. VDTriplet: Vulnerability detection with graph semantics using triplet model. Comput. Secur. 2024, 139, 103732. [Google Scholar] [CrossRef]
- Cheng, B.; Wang, K.; Gao, C.; Luo, X.; Sui, Y.; Li, L.; Guo, Y.; Chen, X.; Wang, H. The Vulnerability Is in the Details: Locating Fine-grained Information of Vulnerable Code Identified by Graph-based Detectors. arXiv 2024, arXiv:2401.02737. [Google Scholar]
- Jiang, H.; Ji, S.; Zha, C.; Liu, Y. Software vulnerability detection method based on code attribute graph presentation and Bi-LSTM neural network extraction. In Proceedings of the International Conference on Computer Network Security and Software Engineering (CNSSE 2024), Sanya, China, 23–25 February 2024; SPIE: Bellingham, DC, USA, 2024; Volume 13175, pp. 404–413. [Google Scholar]
- Cao, S.; Sun, X.; Wu, X.; Lo, D.; Bo, L.; Li, B.; Liu, W. Coca: Improving and Explaining Graph Neural Network-Based Vulnerability Detection Systems. arXiv 2024, arXiv:2401.14886. [Google Scholar]
- Grahn, D.; Chen, L.; Zhang, J. Code Execution Capability as a Metric for Machine Learning-Assisted Software Vulnerability Detection Models. In Proceedings of the 2023 IEEE 22nd International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Exeter, UK, 1–3 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1606–1613. [Google Scholar]
- Srikant, S.; Lipkin, B.; Ivanova, A.; Fedorenko, E.; O’Reilly, U.M. Convergent Representations of Computer Programs in Human and Artificial Neural Networks. Adv. Neural Inf. Process. Syst. 2022, 35, 18834–18849. [Google Scholar]
- Duncan, J. The multiple-demand (MD) system of the primate brain: Mental programs for intelligent behaviour. Trends Cogn. Sci. 2010, 14, 172–179. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, S.; Nguyen, T.T.; Vu, T.T.; Do, T.D.; Ngo, K.T.; Vo, H.D. Code-centric learning-based just-in-time vulnerability detection. J. Syst. Softw. 2024, 214, 112014. [Google Scholar] [CrossRef]
- Ying, X. An overview of overfitting and its solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Bjerke-Gulstuen, K.; Larsen, E.W.; Stålhane, T.; Dingsøyr, T. High level test driven development–shift left. In Proceedings of the Agile Processes in Software Engineering and Extreme Programming: 16th International Conference, XP 2015, Helsinki, Finland, 25–29 May 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 239–247. [Google Scholar]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 15 November 2019. [Google Scholar]
- Bairi, R.; Sonwane, A.; Kanade, A.; Iyer, A.; Parthasarathy, S.; Rajamani, S.; Ashok, B.; Shet, S. CodePlan: Repository-level Coding using LLMs and Planning. arXiv 2023, arXiv:2309.12499. [Google Scholar]
- Perconti, P.; Plebe, A. Brain inspiration is not panacea. In Proceedings of the Brain-Inspired Cognitive Architectures for Artificial Intelligence: BICA* AI 2020: Proceedings of the 11th Annual Meeting of the BICA Society 11, Virtual, 10–15 October 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 359–364. [Google Scholar]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. Graphcodebert: Pre-training code representations with data flow. arXiv 2020, arXiv:2009.08366. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Liu, X.; Tang, H.; Zhao, J.; Dou, Q.; Lu, M. TCAMixer: A lightweight Mixer based on a novel triple concepts attention mechanism for NLP. Eng. Appl. Artif. Intell. 2023, 123, 106471. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Bridle, J.S. Probabilistic interpretation of feedforward classification network outputs, with relationships to statistical pattern recognition. In Neurocomputing: Algorithms, Architectures and Applications; Springer: Berlin/Heidelberg, Germany, 1990; pp. 227–236. [Google Scholar]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Fractalnet: Ultra-deep neural networks without residuals. arXiv 2016, arXiv:1605.07648. [Google Scholar]
- Fusco, F.; Pascual, D.; Staar, P. pNLP-mixer: An efficient all-MLP architecture for language. arXiv 2022, arXiv:2202.04350. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Grahn, D.; Zhang, J. An Analysis of C/C++ Datasets for Machine Learning-Assisted Software Vulnerability Detection. In Proceedings of the CAMLIS, Arlington, VA, USA, 4–5 November 2021. [Google Scholar]
- Zhou, Y.; Liu, S.; Siow, J.; Du, X.; Liu, Y. Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks. arXiv 2019, arXiv:1909.03496. [Google Scholar]
- Zheng, W.; Gao, J.; Wu, X.; Liu, F.; Xun, Y.; Liu, G.; Chen, X. The impact factors on the performance of machine learning-based vulnerability detection: A comparative study. J. Syst. Softw. 2020, 168, 110659. [Google Scholar] [CrossRef]
- Russell, R.; Kim, L.; Hamilton, L.; Lazovich, T.; Harer, J.; Ozdemir, O.; Ellingwood, P.; McConley, M. Automated vulnerability detection in source code using deep representation learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 757–762. [Google Scholar]
- Fan, J.; Li, Y.; Wang, S.; Nguyen, T.N. AC/C++ code vulnerability dataset with code changes and CVE summaries. In Proceedings of the MSR, Seoul, Republic of Korea, 25–26 May 2020; pp. 508–512. [Google Scholar]
- Fu, M.; Tantithamthavorn, C. LineVul: A transformer-based line-level vulnerability prediction. In Proceedings of the MSR, Pittsburgh, PA, USA, 23–24 May 2022; pp. 608–620. [Google Scholar]
- Nguyen, V.A.; Nguyen, D.Q.; Nguyen, V.; Le, T.; Tran, Q.H.; Phung, D. ReGVD: Revisiting graph neural networks for vulnerability detection. In Proceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, Pittsburgh, PA, USA, 22–24 May 2022. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Yu, T.; Li, X.; Cai, Y.; Sun, M.; Li, P. S2-mlp: Spatial-shift mlp architecture for vision. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 297–306. [Google Scholar]
- Sanders, G.D.; Maciejewski, M.L.; Basu, A. Overview of cost-effectiveness analysis. JAMA 2019, 321, 1400–1401. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Wang, D.; Cao, H.; Qian, C.; Kuang, X.; Zhuang, H. A Study on Vulnerability Code Labeling Method in Open-Source C Programs. In Proceedings of the International Conference on Database and Expert Systems Applications, Penang, Malaysia, 28–30 August 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 52–67. [Google Scholar]
- Hin, D.; Kan, A.; Chen, H.; Babar, M.A. LineVD: Statement-level Vulnerability Detection using Graph Neural Networks. arXiv 2022, arXiv:2203.05181. [Google Scholar]
- Yuan, X.; Lin, G.; Tai, Y.; Zhang, J. Deep Neural Embedding for Software Vulnerability Discovery: Comparison and Optimization. Secur. Commun. Netw. 2022, 2022, 5203217. [Google Scholar] [CrossRef]
- Lu, S.; Guo, D.; Ren, S.; Huang, J.; Svyatkovskiy, A.; Blanco, A.; Clement, C.; Drain, D.; Jiang, D.; Tang, D.; et al. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation. arXiv 2021, arXiv:2102.04664. [Google Scholar]
- Microsoft. CodeXGLUE Leaderboard. Available online: https://microsoft.github.io/CodeXGLUE/ (accessed on 23 June 2024).
- Lian, D.; Yu, Z.; Sun, X.; Gao, S. As-mlp: An axial shifted mlp architecture for vision. arXiv 2021, arXiv:2107.08391. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).