
Influence Maximization in Temporal Social Networks with the Mixed K-Shell Method


Abstract
1. Introduction
- We propose the MKS algorithm by considering both the local and global attributes of nodes. For local attributes, we evaluate the nodes’ influence based on degree centrality. For global attributes, we present a temporal k-shell decomposition (TKS) algorithm to layer the network onto a different temporal k-shell. Then, we estimate the global influence of nodes based on the temporal k-shell and classic k-shell methods.
- The proposed MKS algorithm only uses the inherent information of the network and does not need any free parameters or human experience, saving the time needed to adjust optimal parameters.
- We carry out experiments on four real-world temporal datasets. The results show that MKS performs more effectively than other heuristic baselines. The ablation study further demonstrates the effectiveness of MKS in considering the local and global attributes of nodes.
2. Related Work
3. Preliminaries
3.1. Temporal Social Network and Influence Diffusion Model
- (1)
- Set the active start time of to 0, i.e., . At this time, the seed node has an activation probability to activate its inactive neighbor node , and has only one opportunity to activate .
- (2)
- When tries to activate , the model first determines whether is less than or equal to . If it is satisfied, then will activate with . Otherwise, will skip and try to activate the next inactive neighbor node.
- (3)
- Whether or not can activate , in subsequent rounds, will not try to activate again.
- (4)
- Once is successfully activated, record its active start time , where , and .
- (5)
- The influence tries to spread from the newly active nodes to the inactive neighbor nodes in the entire network until no new nodes are activated.
3.2. Influence Maximization of Temporal Social Networks
| Algorithm 1: Greedy |
| Input: , k Output: 1: Let ; 2: for to do 3: ; 4: ; 5: end for 6: return ; |
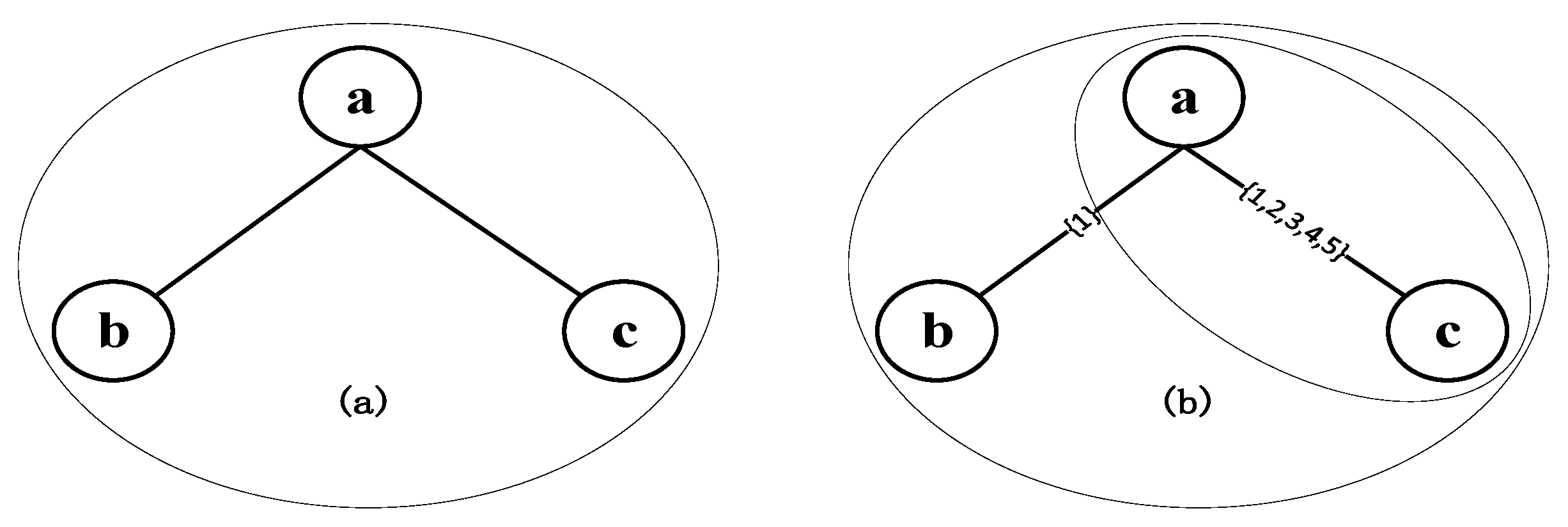
3.3. The K-Shell Decomposition Algorithm
| Algorithm 2: KS |
| Input: Output: 1: initialize 2: while 3: find the set of nodeswith a degree no more than k 4: while is not empty 5: for each node in 6: 7: end for 8: remove all nodes in and their associated edges from 9: recalculate the degree of nodes and from the updated 10: end while 11: 12: end while 13: return |
4. Methods
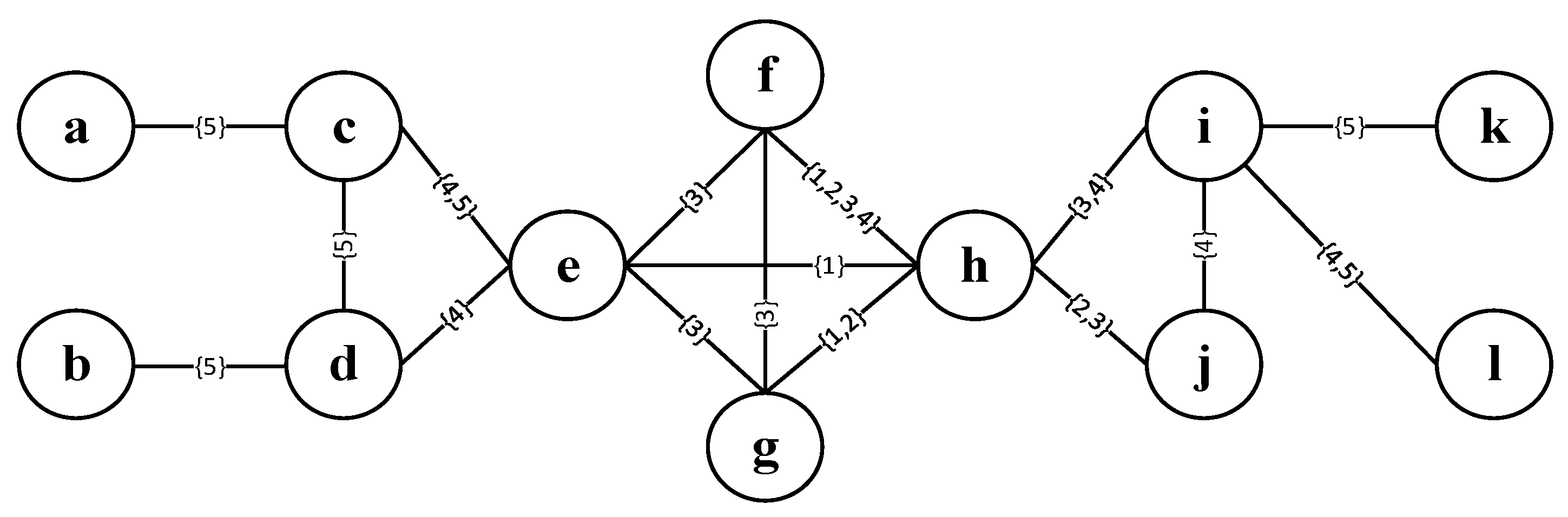
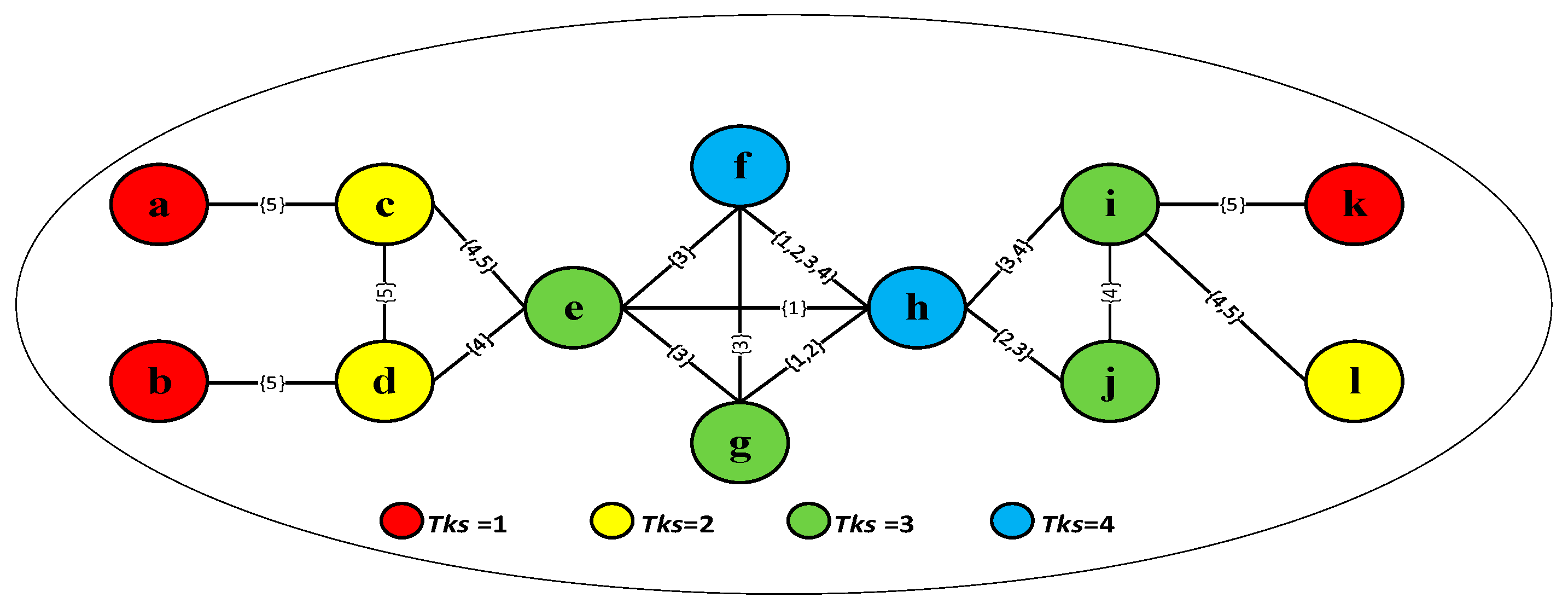
4.1. The Temporal K-Shell Decomposition Algorithm
| Algorithm 3: TKS |
| Input: Output: 1: initialize 2: 3: ) 4: while 5: 6: while is not empty 7: for each node in 8: 9: end for 10: remove all nodes in and their associated edges from 11: recalculate and from the updated 12: end while 13: recalculate 14: 15: end while 16: |
4.2. The Mixed K-Shell Algorithm
| Algorithm 4: MKS |
| Input:, k Output: 1: calculate according to Algorithm 2 2: calculate according to Algorithm 3 3: calculate , based on Equation (8) 4: for each node 5: calculate according to Equations (3), (9), and (10) 6: end for 7: for 8: 9: 10: end for 11: return |
5. Experiments
5.1. Datasets
5.2. Baseline Algorithms
- IMIT [4]. This is a greedy-based simulation algorithm that uses the CELF method to improve efficiency.
- DD [21]. This is a degree-based heuristic algorithm. The basic idea of it is to discount the degree of a node based on the number of neighbors it has in common with already selected seeds.
- PR [7]. This is the classical PageRank algorithm based on the assumption that websites with higher influence are likely to receive more links from other websites.
- KS. Algorithm 2 in our paper. We selected the top nodes with the highest k-shell values as seeds.
- TKS. Algorithm 3 in our paper. We selected the top nodes with the highest temporal k-shell values as seeds.
- KT [11]. This is a heuristic algorithm that selects the seeds with the largest comprehensive degree in each shell layer.
- KTIM [11]. This is an improved version of KT, which selects the seeds with the largest comprehensive degree within the candidate seed set.
5.3. Experimental Setting
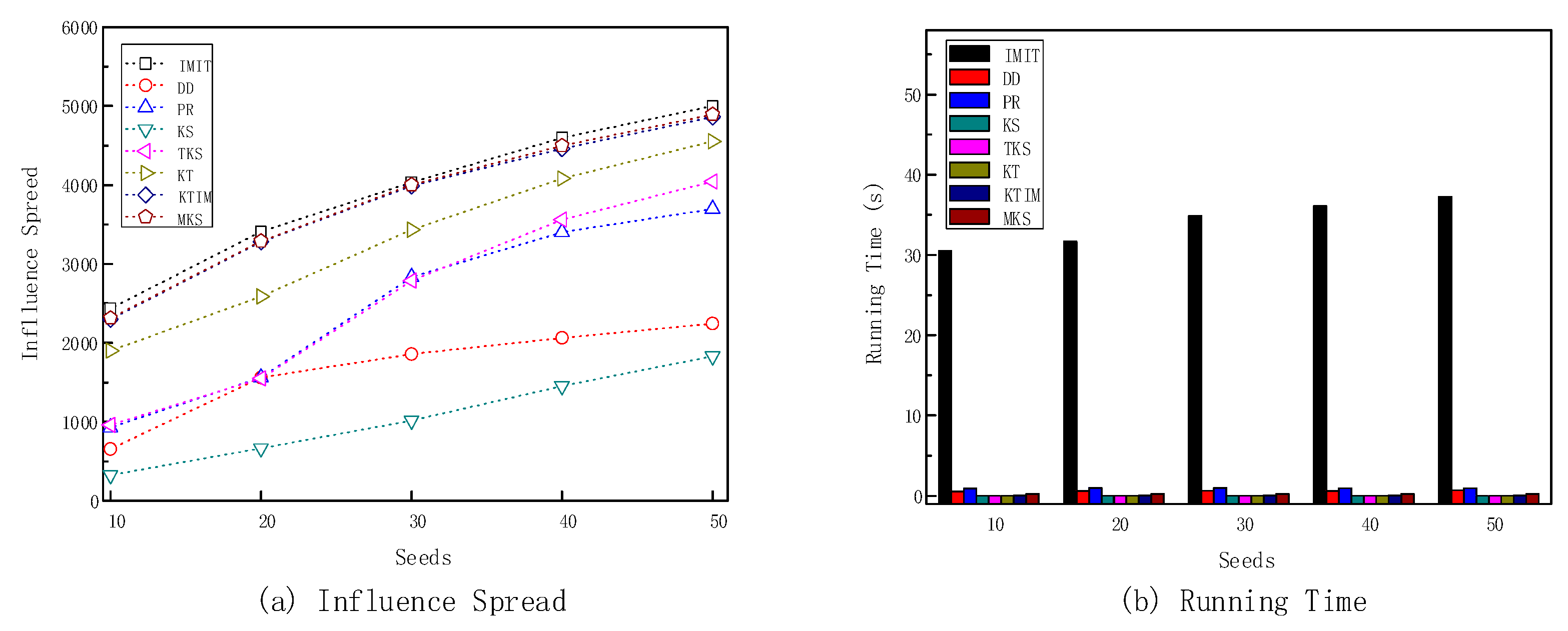
5.4. Main Results
5.5. Ablation Study
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Molaei, R.; Rahsepar Fard, K.; Bouyer, A. An Improved Influence Maximization Method for Online Advertising in Social Internet of Things. Big Data, 2023; online ahead of print. [Google Scholar] [CrossRef]
- Wang, W.; Street, W.N. Modeling and Maximizing Influence Diffusion in Social Networks for Viral Marketing. Appl. Netw. Sci. 2018, 3, 6. [Google Scholar] [CrossRef]
- Manouchehri, M.A.; Helfroush, M.S.; Danyali, H. Temporal Rumor Blocking in Online Social Networks: A Sampling-Based Approach. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 4578–4588. [Google Scholar] [CrossRef]
- Wu, A.; Yuan, Y.; Qiao, B.; Wang, Y.; Ma, Y.; Wang, G. Research on algorithms for maximizing influence of large-scale time series diagrams. Chin. J. Comput. 2019, 42, 2647–2664. [Google Scholar] [CrossRef]
- Chen, W.; Yuan, Y.; Zhang, L. Scalable Influence Maximization in Social Networks under the Linear Threshold Model. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; IEEE: New York, NY, USA, 2010; pp. 88–97. [Google Scholar]
- Bonacich, P. Factoring and Weighting Approaches to Status Scores and Clique Identification. J. Math. Sociol. 1972, 2, 113–120. [Google Scholar] [CrossRef]
- Contreras-Aso, G.; Criado, R.; Romance, M. Can the PageRank Centrality Be Manipulated to Obtain Any Desired Ranking? Chaos Woodbury N. Y. 2023, 33, 083152. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E.J. A Measure of Betweenness Centrality Based on Random Walks. Soc. Netw. 2005, 27, 39–54. [Google Scholar] [CrossRef]
- Liu, Z.; Ye, J.; Zou, Z. Closeness Centrality on Uncertain Graphs. ACM Trans. Web 2023, 17, 29. [Google Scholar] [CrossRef]
- Wang, H.; Li, M.; Chen, X.-B. Influential Spreaders Identification in Complex Networks with Improved Hybrid K-Shell Method. SSRN Electron. J. 2022; preprint. [Google Scholar] [CrossRef]
- Zhu, W.; Miao, Y.; Yang, S.; Lian, Z.; Cui, L. An Influence Maximization Algorithm Based on Improved K-Shell in Temporal Social Networks. Comput. Mater. Contin. 2023, 75, 3111–3131. [Google Scholar] [CrossRef]
- Domingos, P.; Richardson, M. Mining the Network Value of Customers. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26 August 2001; Association for Computing Machinery: New York, NY, USA, 2001; pp. 57–66. [Google Scholar]
- Kempe, D.; Kleinberg, J.; Tardos, É. Maximizing the Spread of Influence through a Social Network. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24 August 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 137–146. [Google Scholar]
- Leskovec, J.; Krause, A.; Guestrin, C.; Faloutsos, C.; VanBriesen, J.; Glance, N. Cost-Effective Outbreak Detection in Networks. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12 August 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 420–429. [Google Scholar]
- Goyal, A.; Lu, W.; Lakshmanan, L.V.S. CELF++: Optimizing the Greedy Algorithm for Influence Maximization in Social Networks. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 47–48. [Google Scholar]
- Borgs, C.; Brautbar, M.; Chayes, J.; Lucier, B. Maximizing Social Influence in Nearly Optimal Time. In Proceedings of the Twenty-Fifth Annual ACM-SIAM Symposium on Discrete Algorithms, Portland, OR, USA, 5 January 2014; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2014; pp. 946–957. [Google Scholar]
- Tang, Y.; Xiao, X.; Shi, Y. Influence Maximization: Near-Optimal Time Complexity Meets Practical Efficiency. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird, UT, USA, 18 June 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 75–86. [Google Scholar]
- Tang, Y.; Shi, Y.; Xiao, X. Influence Maximization in Near-Linear Time: A Martingale Approach. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Victoria, Australia, 27 May 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1539–1554. [Google Scholar]
- Chen, W.; Wang, C.; Wang, Y. Scalable Influence Maximization for Prevalent Viral Marketing in Large-Scale Social Networks. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25 July 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1029–1038. [Google Scholar]
- Jung, K.; Heo, W.; Chen, W. IRIE: Scalable and Robust Influence Maximization in Social Networks. In Proceedings of the 2012 IEEE 12th International Conference on Data Mining, Brussels, Belgium, 10–13 December 2012; pp. 918–923. [Google Scholar]
- Chen, W.; Wang, Y.; Yang, S. Efficient Influence Maximization in Social Networks. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 199–208. [Google Scholar]
- Liu, P.; Li, L.; Wen, Y.; Fang, S. Identifying Influential Nodes in Social Networks: Exploiting Self-Voting Mechanism. Big Data 2023, 11, 296–306. [Google Scholar] [CrossRef]
- Wang, G.; Alias, S.B.; Sun, Z.; Wang, F.; Fan, A.; Hu, H. Influential Nodes Identification Method Based on Adaptive Adjustment of Voting Ability. Heliyon 2023, 9, e16112. [Google Scholar] [CrossRef]
- Liang, Z.; He, Q.; Du, H.; Xu, W. Targeted Influence Maximization in Competitive Social Networks. Inf. Sci. 2023, 619, 390–405. [Google Scholar] [CrossRef]
- Zhu, W.; Yang, W.; Xuan, S.; Man, D.; Wang, W.; Du, X.; Guizani, M. Location-Based Seeds Selection for Influence Blocking Maximization in Social Networks. IEEE Access 2019, 7, 27272–27287. [Google Scholar] [CrossRef]
- Li, Q.; Cheng, L.; Wang, W.; Li, X.; Li, S.; Zhu, P. Influence Maximization through Exploring Structural Information. Appl. Math. Comput. 2023, 442, 127721. [Google Scholar] [CrossRef]
- Liqing, Q.; Jinfeng, Y.; Xin, F.; Wei, J.; Wenwen, G. Analysis of Influence Maximization in Temporal Social Networks. IEEE Access 2019, 7, 42052–42062. [Google Scholar] [CrossRef]
- Chen, J.; Qi, Z. Research on social network influence maximization algorithm based on time sequential relationship. J. Commun. 2020, 41, 211–221. [Google Scholar] [CrossRef]
- Wang, J.; Fang, H.; Li, S.; Jiang, J. Research on Influence Maximization Algorithm Based on Temporal Social Network. In Proceedings of the 2023 IEEE International Conference on Dependable, Autonomic and Secure Computing, Abu Dhabi, United Arab, 14–17 November 2023; pp. 0123–0129. [Google Scholar]
- Zhu, W.; Miao, Y.; Yang, S.; Lian, Z.; Cui, L. Maximizing Influence in Temporal Social Networks: A Node Feature-Aware Voting Algorithm. Comput. Mater. Contin. 2023, 77, 3095–3117. [Google Scholar] [CrossRef]
- Dondi, R.; Guzzi, P.H.; Hosseinzadeh, M.M.; Milano, M. Dense Subgraphs in Temporal Social Networks. Soc. Netw. Anal. Min. 2023, 13, 128. [Google Scholar] [CrossRef]
- Salavati, C.; Abdollahpouri, A.; Manbari, Z. Ranking Nodes in Complex Networks Based on Local Structure and Improving Closeness Centrality. Neurocomputing 2019, 336, 36–45. [Google Scholar] [CrossRef]
- Michalski, R.; Jankowski, J.; Pazura, P. Entropy-Based Measure for Influence Maximization in Temporal Networks. In Proceedings of the Computational Science—ICCS 2020: 20th International Conference, Amsterdam, The Netherlands, 3–5 June 2020; Proceedings, Part IV. Springer: Berlin/Heidelberg, Germany, 2020; pp. 277–290. [Google Scholar]
- Zhang, L.; Li, K. Influence Maximization Based on Snapshot Prediction in Dynamic Online Social Networks. Mathematics 2022, 10, 1341. [Google Scholar] [CrossRef]
- Chandran, J.; Viswanatham, V.M. Dynamic Node Influence Tracking Based Influence Maximization on Dynamic Social Networks. Microprocess. Microsyst. 2022, 95, 104689. [Google Scholar] [CrossRef]
- Kumar, S.; Hooi, B.; Makhija, D.; Kumar, M.; Faloutsos, C.; Subrahmanian, V.S. REV2: Fraudulent User Prediction in Rating Platforms. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 2 February 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 333–341. [Google Scholar]
- Panzarasa, P.; Opsahl, T.; Carley, K.M. Patterns and Dynamics of Users’ Behavior and Interaction: Network Analysis of an Online Community. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 911–932. [Google Scholar] [CrossRef]
- Paranjape, A.; Benson, A.R.; Leskovec, J. Motifs in Temporal Networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 2 February 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 601–610. [Google Scholar]
- Doha, A.; Elnahla, N.; McShane, L. Social Commerce as Social Networking. J. Retail. Consum. Serv. 2019, 47, 307–321. [Google Scholar] [CrossRef]
- Anastasiei, B.; Dospinescu, N.; Dospinescu, O. Individual and Product-Related Antecedents of Electronic Word-of-Mouth. arXiv 2024, arXiv:2403.14717. [Google Scholar]
- Zhao, Y.; Kou, G.; Peng, Y.; Chen, Y. Understanding Influence Power of Opinion Leaders in E-Commerce Networks: An Opinion Dynamics Theory Perspective. Inf. Sci. 2018, 426, 131–147. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Nodes | Edges | Temporal Edges |
|---|---|---|---|
| Bitcoin-OTC | 5881 | 35,592 | 35,592 |
| CollegeMsg | 1899 | 20,269 | 59,835 |
| Math-Overflow | 13,840 | 81,121 | 195,330 |
| Ask-Ubuntu | 75,555 | 178,210 | 356,822 |
| Method | Bitcoin-OTC | CollegeMsg | Math-Overflow | Ask-Ubuntu | ||||
|---|---|---|---|---|---|---|---|---|
| k = 10 | k = 50 | k = 10 | k = 50 | k = 10 | k = 50 | k = 10 | k = 50 | |
| normal | 1309.3 | 2363.8 | 386.1 | 847.8 | 721.2 | 1626.4 | 2315.2 | 4892.5 |
| only ks | 1308.5 | 2361.5 | 385.2 | 845.1 | 704.1 | 1620 | 2349.7 | 4890.2 |
| only tks | 1308.6 | 2360.1 | 384.5 | 831.3 | 719.7 | 1622.5 | 2288.1 | 4761.7 |
| only degree | 1305.6 | 2361.8 | 385.5 | 839.2 | 712 | 1614.3 | 2264.3 | 4748.6 |
| degree + ks | 1306.8 | 2363.2 | 385.8 | 842.2 | 717.8 | 1621.7 | 2278.9 | 4868.4 |
| degree + tks | 1306.1 | 2361.1 | 387.7 | 832.7 | 711.5 | 1623.2 | 2214.2 | 4749.1 |
| ks + tks | 1308.5 | 2358.5 | 384.4 | 844.4 | 703.2 | 1620.5 | 2345.4 | 4748 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Zhu, W.; Zhang, K.; Diao, Y.; Bai, Y. Influence Maximization in Temporal Social Networks with the Mixed K-Shell Method. Electronics 2024, 13, 2533. https://doi.org/10.3390/electronics13132533
Yang S, Zhu W, Zhang K, Diao Y, Bai Y. Influence Maximization in Temporal Social Networks with the Mixed K-Shell Method. Electronics. 2024; 13(13):2533. https://doi.org/10.3390/electronics13132533
Chicago/Turabian StyleYang, Shuangshuang, Wenlong Zhu, Kaijing Zhang, Yingchun Diao, and Yufan Bai. 2024. "Influence Maximization in Temporal Social Networks with the Mixed K-Shell Method" Electronics 13, no. 13: 2533. https://doi.org/10.3390/electronics13132533
APA StyleYang, S., Zhu, W., Zhang, K., Diao, Y., & Bai, Y. (2024). Influence Maximization in Temporal Social Networks with the Mixed K-Shell Method. Electronics, 13(13), 2533. https://doi.org/10.3390/electronics13132533