
A Faster and Lightweight Lane Detection Method in Complex Scenarios

Abstract
1. Introduction
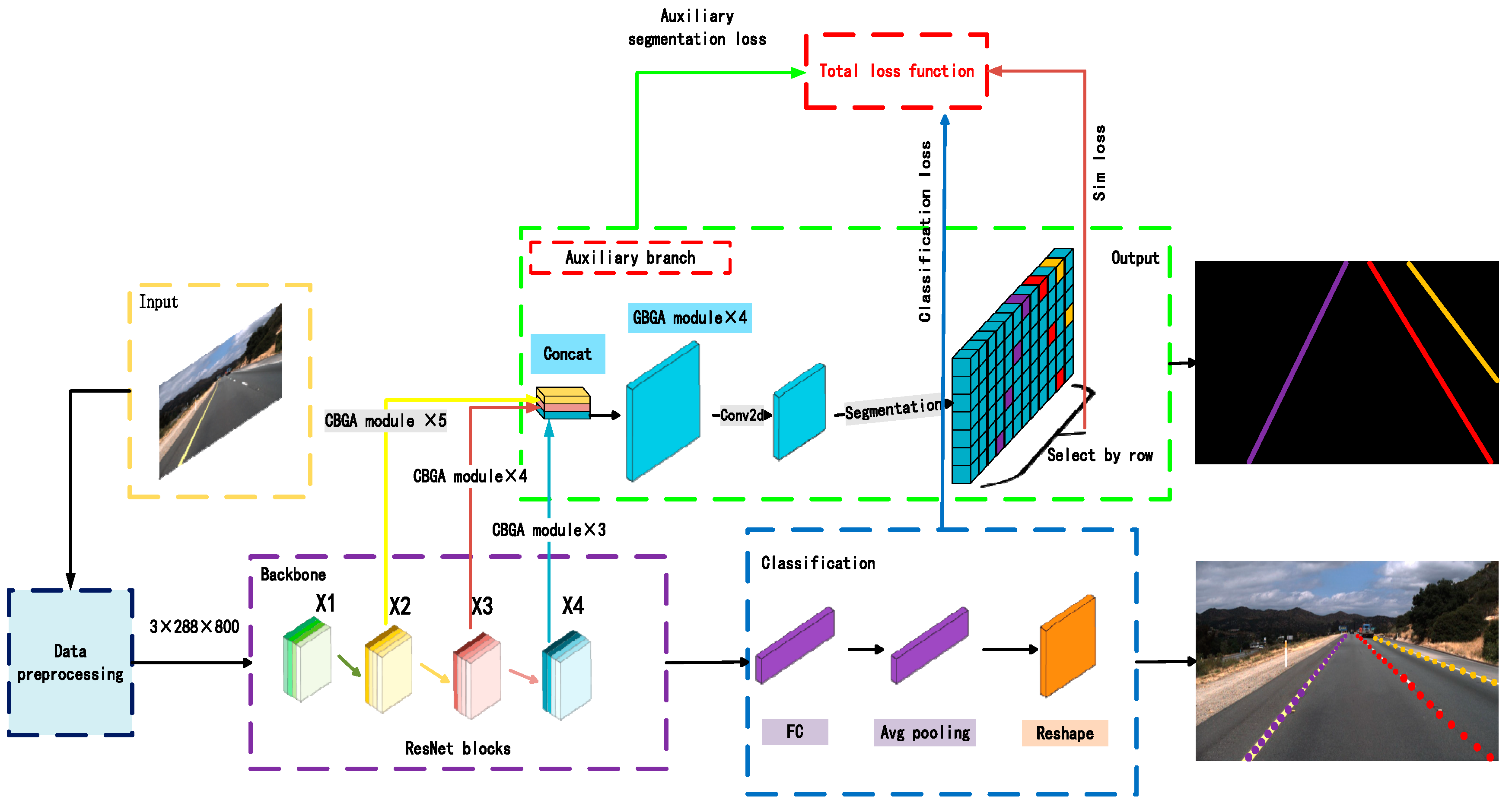
- We propose an efficient and lightweight auxiliary segmentation network (CBGA-Auxiliary). This network shares model parameters and weights with the backbone network, collaborating with the backbone network to complete the segmentation task, thereby enhancing the overall generalization ability and inference speed of the model. The auxiliary segmentation network only functions during the training phase and is not used during inference, thus not affecting the final inference speed.
- We utilized lightweight GhostConv convolutions to replace standard convolutions in the auxiliary branch, addressing the additional parameters and computational overhead introduced with the auxiliary segmentation network. The addition of an extra auxiliary branch increases the model’s size, parameters, and computational complexity. The experimental results indicate that the replaced GBGA-Auxiliary effectively reduces the model’s parameter count while improving both accuracy and inference speed compared with the initial model.
- We introduce additional structural loss function. This paper adopts a feature extraction method based on row anchors, which has certain structural deficiencies. Considering that the lanes are narrow and continuous, an additional similarity loss between the lanes is added to the original loss function, further improving the model’s detection accuracy.
- The extensive experiments show that our model achieves good performance on the Tusimple and CULane datasets. Additionally, it maintains high inference speed without sacrificing accuracy, striking a good balance between accuracy and inference speed. This validates the effectiveness of the model.
2. Related Work
2.1. Traditional Methods
2.2. Deep Learning Methods
2.2.1. Segmentation-Based Methods
2.2.2. Anchor-Based Methods
2.2.3. Parametric Prediction Methods
2.2.4. Key Point-Based Methods
3. Method
3.1. Model
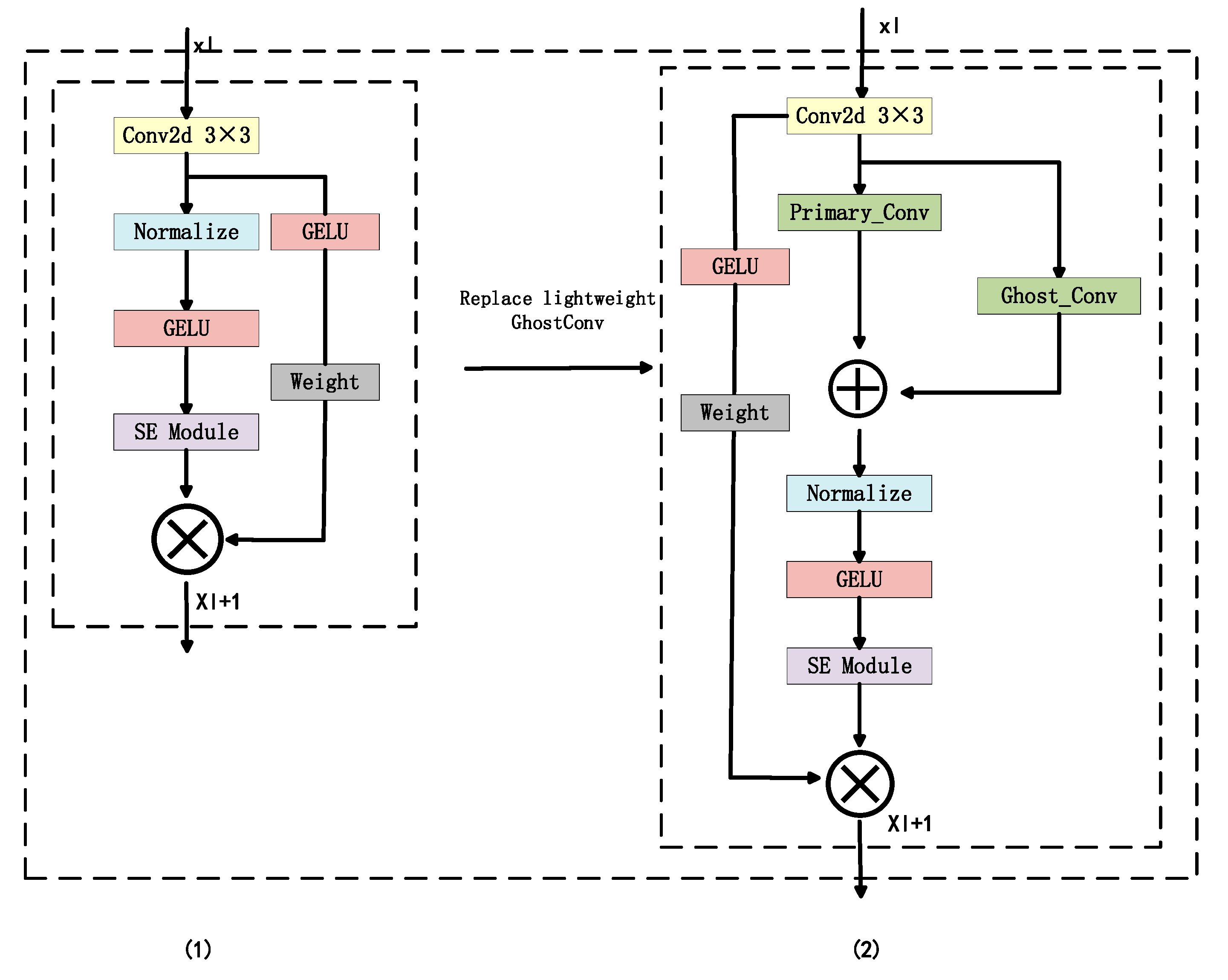
3.1.1. CBGA Module
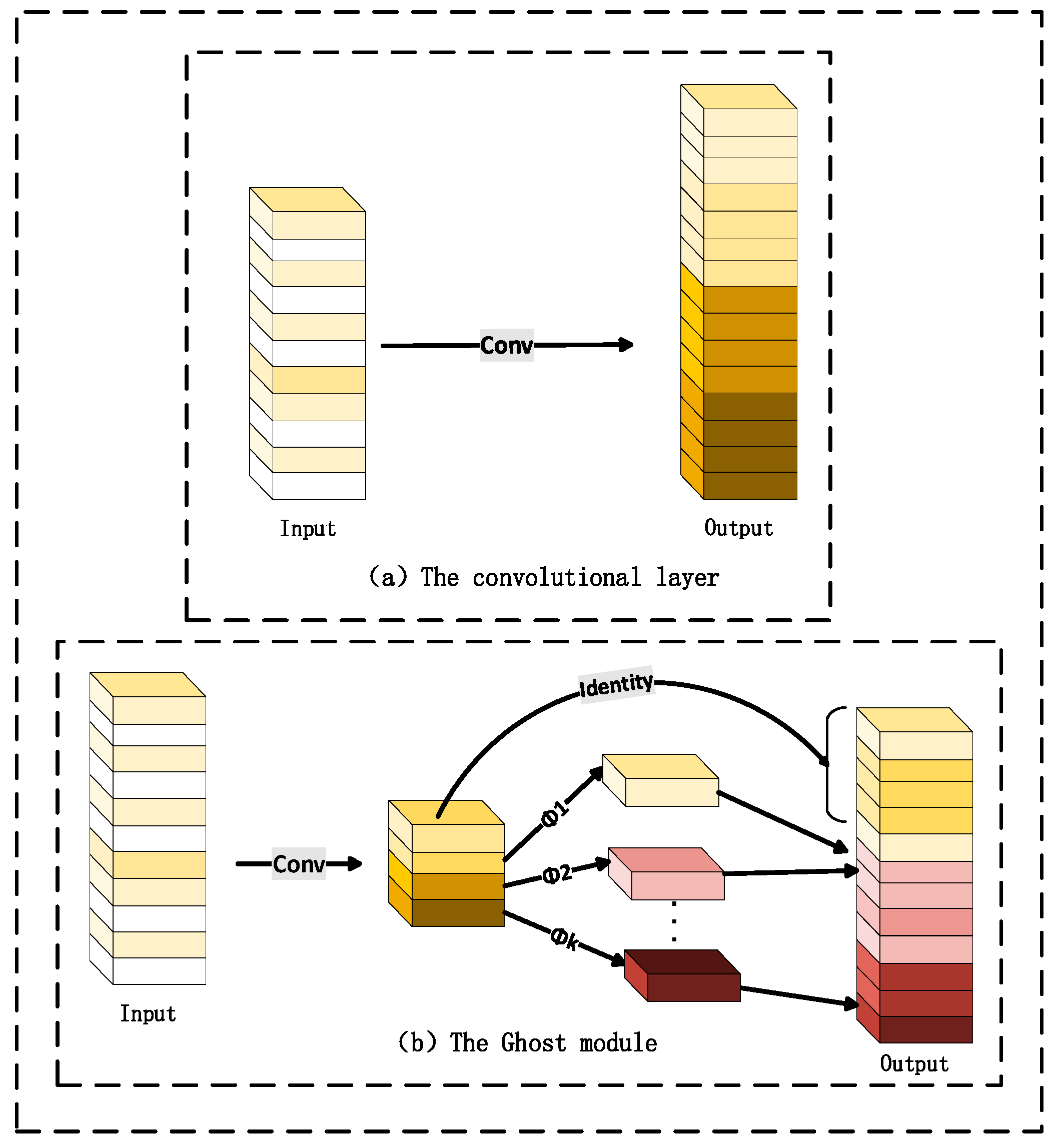
3.1.2. GhostConv Lightweight Module
3.1.3. Auxiliary Attention Segmentation Branches
3.2. Loss Function
4. Experiment
4.1. Datasets
4.2. Experimental Parameters and Environment
4.3. Evaluation Metrics
4.4. Results
4.5. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, R.; Wu, Y.; Gou, W.; Chen, J. RS-lane: A robust lane detection method based on ResNeSt and self-attention distillation for challenging traffic situations. J. Adv. Transp. 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Hu, X.; Yang, J. Line-CNN: End-to-End Traffic Line Detection With Line Proposal Unit. IEEE Trans. Intell. Transp. Syst. 2019, 21, 248–258. [Google Scholar] [CrossRef]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning Lightweight Lane Detection CNNs by Self Attention Distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zheng, T.; Huang, Y.; Liu, Y.; Tang, W.; Yang, Z.; Cai, D.; He, X. CLRNet: Cross Layer Refinement Network for Lane Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, L.; Chen, X.; Zhu, S.; Tan, P. CondLaneNet: A Top-to-down Lane Detection Framework Based on Conditional Convolution. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Lu, S.; Luo, Z.; Gao, F.; Liu, M.; Chang, K.; Piao, C. A Fast and Robust Lane Detection Method Based on Semantic Segmentation and Optical Flow Estimation. Sensors 2021, 21, 400. [Google Scholar] [CrossRef] [PubMed]
- Qin, Z.; Wang, H.; Li, X. Ultra Fast Structure-Aware Deep Lane Detection. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Germany, 2018; pp. 276–291. [Google Scholar]
- Qin, Z.; Zhang, P.; Li, X. Ultra Fast Deep Lane Detection with Hybrid Anchor Driven Ordinal Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1234–1245. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Wörgötter, F.; Markelić, I. Combining statistical hough transform and particle filter for robust lane detection and tracking. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), La Jolla, CA, USA, 21–24 June 2010; pp. 993–997. [Google Scholar]
- Kim, Z. Robust lane detection and tracking in challenging scenarios. IEEE Trans. Intell. Transp. Syst. 2008, 9, 16–26. [Google Scholar] [CrossRef]
- Gong, J.; Chen, T.; Zhang, Y. Complex lane detection based on dynamic constraint of the double threshold. Multimed. Tools Appl. 2021, 80, 27095–27113. [Google Scholar] [CrossRef]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Cheng-Yue, R.; et al. An empirical evaluation of deep learning on highway driving. arXiv 2015, arXiv:1504.01716. [Google Scholar]
- Lee, S.; Kim, J.; Shin Yoon, J.; Shin, S.; Bailo, O.; Kim, N.; Lee, T.H.; Seok Hong, H.; Han, S.H.; So Kweon, I. Vpgnet: Vanishing point guided network for lane and road marking detection and recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, J.; Mei, X.; Prokhorov, D.; Tao, D. Deep neural network for structural prediction and lane detection in traffic scene. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 690–703. [Google Scholar] [CrossRef] [PubMed]
- Philion, J. Fastdraw: Addressing the long tail of lane detection by adapting a sequential prediction network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11582–11591. [Google Scholar]
- Dewangan, D.K.; Sahu, S.P.; Sairam, B.; Agrawal, A. VLDNet: Vision-based lane region detection network for intelligent vehicle system using semantic segmentation. Computing 2021, 103, 2867–2892. [Google Scholar] [CrossRef]
- Munir, F.; Azam, S.; Jeon, M.; Lee, B.-G.; Pedrycz, W. LDNet: End to-end lane marking detection approach using a dynamic vision sensor. arXiv 2020, arXiv:2009.08020. [Google Scholar] [CrossRef]
- Zhang, L.; Jiang, F.; Kong, B.; Yang, J.; Wang, C. Real-time lane detection by using biologically inspired attention mechanism to learn contextual information. Cogn. Comput. 2021, 13, 1333–1344. [Google Scholar] [CrossRef]
- Ko, Y.; Jun, J.; Ko, D.; Jeon, M. Key points estimation and point instance segmentation approach for lane detection. arXiv 2020, arXiv:2002.06604. [Google Scholar] [CrossRef]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 286–291. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial CNN for traffic scene understanding. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence (AAAI'18/IAAI'18/EAAI'18), New Orleans, LA, USA, 2–7 February 2018; AAAI Press: Palo Alto, CA, USA, 2018; Volume 891, pp. 7276–7283. [Google Scholar]
- Ghafoorian, M.; Nugteren, C.; Baka, N.; Booij, O.; Hofmann, M. El-gan: Embedding loss driven generative adversarial networks for lane detection. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chougule, S.; Koznek, N.; Ismail, A.; Adam, G.; Narayan, V.; Schulze, M. Reliable multilane detection and classification by utilizing cnn as a regression network. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, Z.; Liu, Q.; Lian, C. Pointlanenet: Efficient end-to-end CNNS for accurate real-time lane detection. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2563–2568. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Olivera-Santos, T. Keep your eyes on the lane: Attention-guided lane detection. arXiv 2020, arXiv:2010.12035. [Google Scholar]
- Liu, R.; Yuan, Z.; Liu, T.; Xiong, Z. End-to-end lane shape prediction with transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3694–3702. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Polylanenet: Lane estimation via deep polynomial regression. In Proceedings of the International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021. [Google Scholar]
- Qu, Z.; Jin, H.; Zhou, Y.; Yang, Z.; Zhang, W. Focus on local: Detecting lane marker from bottom up via key point. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, J.; Ma, Y.; Huang, S.; Hui, T.; Wang, F.; Qian, C.; Zhang, T. A Keypoint-based Global Association Network for Lane Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–23 June 2022. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- TuSimple. Tusimple Lane Detection Benchmark. 2017. Available online: https://github.com/TuSimple/tusimple-benchmark (accessed on 10 June 2024).
- CULane Dataset. Available online: https://xingangpan.github.io/projects/CULane.html (accessed on 1 October 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, L.; Jiang, F.; Yang, J.; Kong, B.; Hussain, A. A real-time lane detection network using two-directional separation attention. Comput.-Aided Civ. Infrastruct. Eng. 2024, 39, 86–101. [Google Scholar] [CrossRef]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient residual factorized convNet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]

 represents the stacked convolution and
represents the stacked convolution and  represents concatenation. The three auxiliary branch heads complete the feature extraction for different levels of residual blocks, and finally, the main branch combines them via concatenation. Lastly, the feature maps are upsampled to complete the segmentation training task (this auxiliary segmentation network only operates during the training phase and does not affect the final inference speed).
represents the stacked convolution and represents concatenation. The three auxiliary branch heads complete the feature extraction for different levels of residual blocks, and finally, the main branch combines them via concatenation. Lastly, the feature maps are upsampled to complete the segmentation training task (this auxiliary segmentation network only operates during the training phase and does not affect the final inference speed).
represents concatenation. The three auxiliary branch heads complete the feature extraction for different levels of residual blocks, and finally, the main branch combines them via concatenation. Lastly, the feature maps are upsampled to complete the segmentation training task (this auxiliary segmentation network only operates during the training phase and does not affect the final inference speed).
represents the stacked convolution and represents concatenation. The three auxiliary branch heads complete the feature extraction for different levels of residual blocks, and finally, the main branch combines them via concatenation. Lastly, the feature maps are upsampled to complete the segmentation training task (this auxiliary segmentation network only operates during the training phase and does not affect the final inference speed).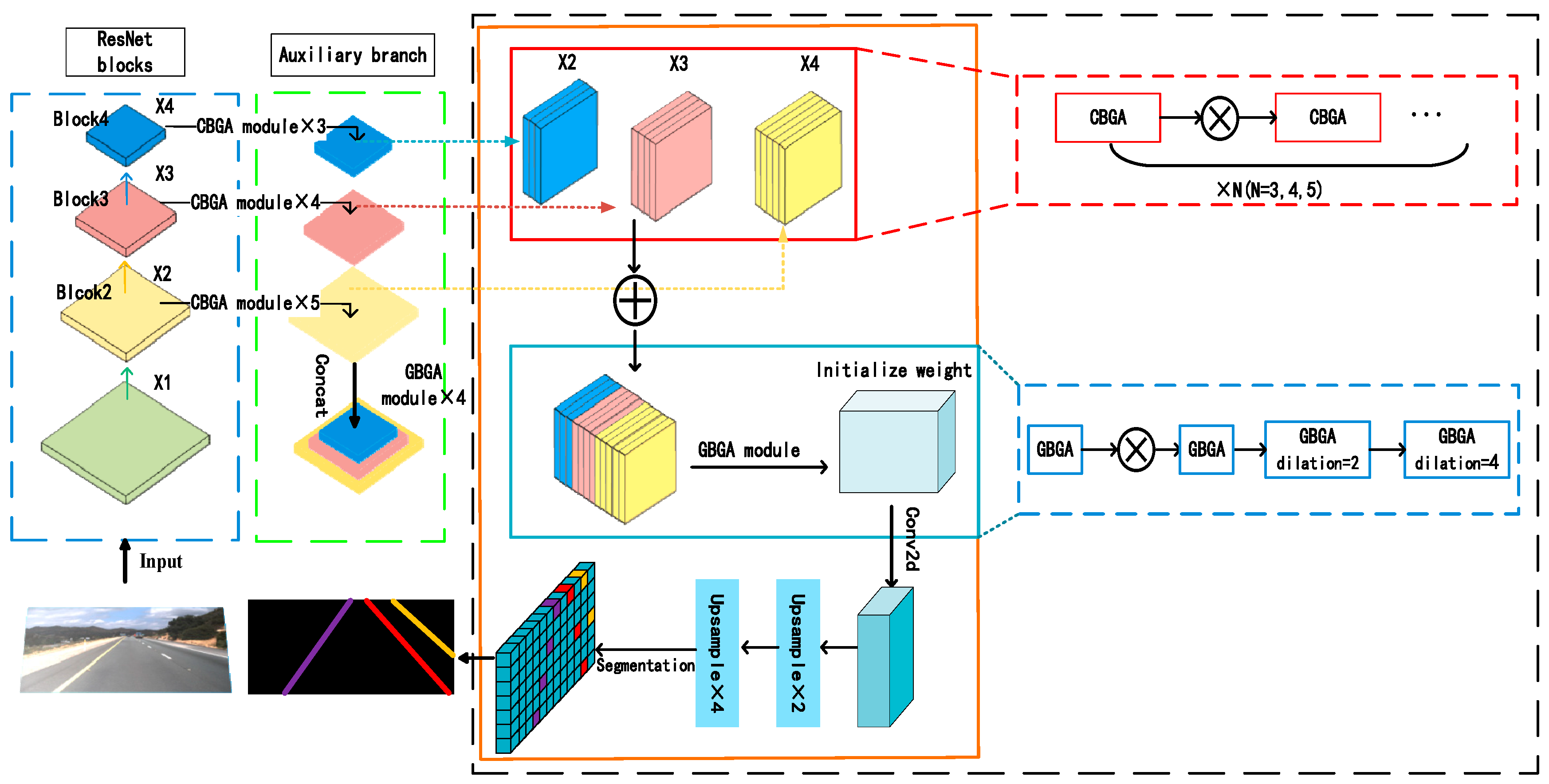



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Val | Test | Road Type | Fork | Scenarios | Resolution |
|---|---|---|---|---|---|---|---|
| Tusimple | 3.3 K | 0.4 K | 2.8 K | Highway | × | 1 | 1280 × 720 |
| CULane | 88.9 K | 9.7 K | 34.7 K | Urban and highway | √ | 9 | 1640 × 590 |
| Method | F1 | Acc% | FP% | FN% | FPS | Params(M) | FLOPs(G) |
|---|---|---|---|---|---|---|---|
| SCNN [25] | 95.97 | 96.53 | 6.17 | 1.80 | 7.5 | 20.27 | 328.4 |
| LaneNet [20] | 96.10 | 96.4 | 7.80 | 2.40 | 52 | 31.66 | 12475.8 |
| LaneATT [29] | 96.06 | 96.10 | 5.64 | 2.17 | 26 | - | 70.5 |
| UFLD [7] | 87.87 | 95.82 | 19.05 | 3.92 | 312 | - | - |
| CondLaneNet [5] | 97.24 | 96.54 | 2.01 | 3.50 | 58 | 44.8 | |
| ResNet-18 [33] | 92.34 | 92.69 | 9.48 | 8.22 | - | 11.69 | 0.91 |
| ResNet-34 [33] | 92.50 | 92.84 | 9.18 | 7.96 | - | 21.80 | 1.84 |
| LNet [34] | 94.38 | 94.43 | 11.5 | 5.3 | 143 | 2.07 | 228.2 |
| ERFNet [35] | 94.78 | 95.20 | 11.9 | 6.2 | 59 | 2.68 | 21.5 |
| Ours (ResNet-18) | 95.10 | 95.82 | 19.1 | 4.01 | 410 | 14.88 | 1.8 |
| Ours (ResNet-34) | 95.93 | 96.10 | 18.80 | 3.61 | 277 | 23.39 | 2.78 |
| Method | Total | Normal | Crowded | Dazzle | Shadow | No line | Curve | Crossroad | Arrow | Night |
|---|---|---|---|---|---|---|---|---|---|---|
| SCNN [25] | 71.6 | 90.6 | 58.5 | 58.5 | 43.4 | 69.7 | 64.4 | 1990 | 84.1 | 66.1 |
| ERFNet [35] | 73.1 | 91.5 | 71.6 | 66.0 | 71.3 | 45.1 | 66.3 | 2199 | 87.2 | 67.1 |
| UFLD-Res18 [7] | 68.4 | 87.70 | 66.0 | 58.4 | 63.8 | 40.2 | 57.9 | 1743 | 81.0 | 62.1 |
| UFLD-Res34 [7] | 72.3 | 90.7 | 70.2 | 59.5 | 69.3 | 44.4 | 69.5 | 2037 | 85.7 | 66.7 |
| LNet [34] | 74.1 | 92.7 | 72.9 | 61.9 | 65.7 | 40.1 | 57.8 | 2118 | 81.3 | 65.1 |
| ResNet18-SAD [3] | 70.5 | 89.8 | 68.1 | 59.8 | 67.5 | 42.5 | 65.5 | 1995 | 83.9 | 64.2 |
| ResNet34-SAD [3] | 70.7 | 89.9 | 68.1 | 59.9 | 67.7 | 42.2 | 66.0 | 1960 | 83.8 | 64.6 |
| Ours (ResNet-18) | 70.1 | 89.0 | 67.8 | 58.1 | 61.6 | 41.0 | 58.2 | 1741 | 84.0 | 63.7 |
| Ours (ResNet-34) | 71.0 | 90.8 | 70.8 | 61.6 | 71.4 | 44.5 | 65.1 | 2028 | 86.3 | 66.1 |
| Method | FPS | Params (M) | FLOPs (G) |
|---|---|---|---|
| SCNN [25] | 7.5 | 20.27 | 328.40 |
| ERFNet [35] | 59 | 2.68 | 21.50 |
| LNet [34] | 143 | 2.07 | 22.49 |
| CondLaneNet [5] | 152 | - | 19.60 |
| TSA-LNet [3] | 142 | 2.28 | 47.02 |
| ResNet-34 | - | 21.80 | 1.84 |
| Ours (ResNet-18) | 334 | 14.88 | 1.80 |
| Ours (ResNet-34) | 280 | 23.39 | 2.78 |
| Baseline | CBGA-Auxiliary | Ghost Module | New Loss | FPS | Params (M) | FLOPs (G) | Acc% | Runtime |
|---|---|---|---|---|---|---|---|---|
| √ | 312 | 21.80 | 1.84 | 92.84 | 5.9 | |||
| √ | √ | 400 | 25.75 | 2.84 | 95.82 | 3.5 | ||
| √ | √ | √ | 430 | 23.39 | 2.78 | 95.20 | 2.1 | |
| √ | √ | √ | 394 | 25.75 | 2.98 | 96.30 | 3.7 | |
| √ | √ | √ | √ | 410 | 23.39 | 2.84 | 96.10 | 2.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, S.; Zhang, G.; Yun, L.; Liu, S. A Faster and Lightweight Lane Detection Method in Complex Scenarios. Electronics 2024, 13, 2486. https://doi.org/10.3390/electronics13132486
Nie S, Zhang G, Yun L, Liu S. A Faster and Lightweight Lane Detection Method in Complex Scenarios. Electronics. 2024; 13(13):2486. https://doi.org/10.3390/electronics13132486
Chicago/Turabian StyleNie, Shuaiqi, Guiheng Zhang, Libo Yun, and Shuxian Liu. 2024. "A Faster and Lightweight Lane Detection Method in Complex Scenarios" Electronics 13, no. 13: 2486. https://doi.org/10.3390/electronics13132486
APA StyleNie, S., Zhang, G., Yun, L., & Liu, S. (2024). A Faster and Lightweight Lane Detection Method in Complex Scenarios. Electronics, 13(13), 2486. https://doi.org/10.3390/electronics13132486