
Dialogue-Rewriting Model Based on Transformer Pointer Extraction


Abstract
1. Introduction
- (1)
- Introduction: introduces the background and significance of multi-round dialogue-rewriting research and introduces the main research content of this paper and the organizational structure of the article.
- (2)
- Related work: outlines the research work and research methods related to dialogue rewriting and introduces the problems solved by the proposed model.
- (3)
- Model: details the transformer-based model designed by the authors.
- (4)
- Experimentation: gives the dataset and evaluation metrics of the authors’ experiments and compares the performance with other models.
- (5)
- Summary: summarizes the scientific results of the whole paper and gives an outlook for subsequent scientific work.
2. Related Work
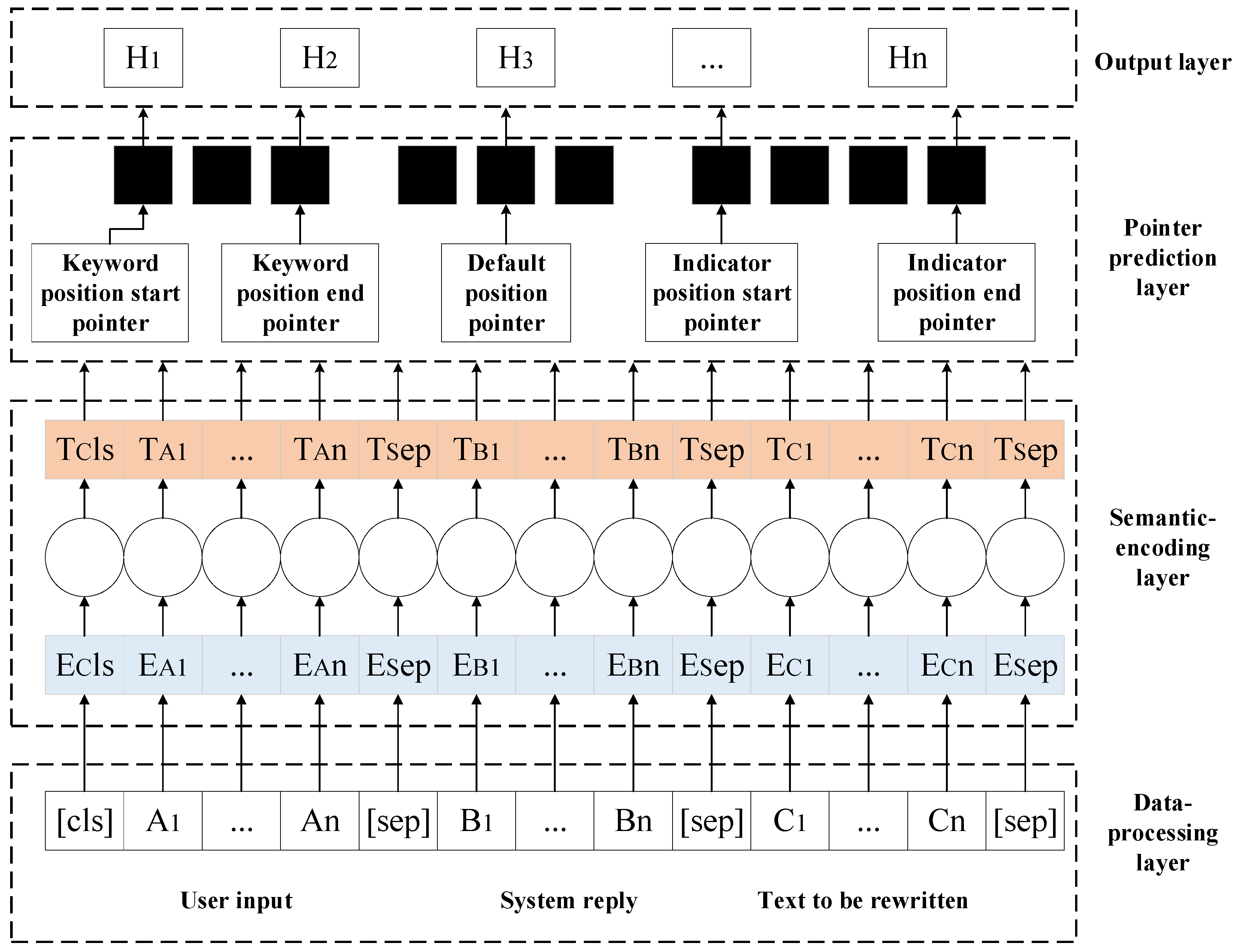
3. Model
3.1. Model Design
- (1)
- Data-processing layer
- (2)
- Semantic-encoding layer
- (3)
- Pointer prediction layer
- (4)
- Output layer
3.2. Model Analysis
4. Experiments
- (1)
- Datasets: describes the source of the dataset for the controlled experiment and the composition of the data.
- (2)
- Evaluation indicators: introduces the evaluation indicators of the controlled experiment.
- (3)
- Comparison experiment: introduces the characteristics of different comparison models.
- (4)
- Experimental results: introduces the experimental environment and analysis of the experimental results.
4.1. Datasets
4.2. Evaluation Indicators
- (1)
- BLUE Index
- (2)
- ROUGE Index
- (3)
- EM Index
- (4)
- Time Consumption Index
4.3. Compared Models
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hao, J.; Song, L.; Wang, L.; Xu, K.; Tu, Z.; Yu, D. Robust Dialogue Utterance Rewriting as Sequence Tagging. U.S. Patent 17/192,260, 8 September 2022. [Google Scholar]
- Jiang, W.; Gu, X.; Chen, Y.; Shen, B. DuReSE: Rewriting Incomplete Utterances via Neural Sequence Editing. Neural Process. Lett. 2023, 55, 8713–8730. [Google Scholar] [CrossRef]
- Su, H.; Shen, X.; Zhang, R.; Sun, F.; Hu, P.; Niu, C.; Zhou, J. Improving Multi-turn Dialogue Modelling with Utterance ReWriter. arXiv 2019, arXiv:1906.07004. [Google Scholar]
- Niehues, J.; Cho, E.; Ha, T.L.; Waibel, A. Pre-Translation for Neural Machine Translation. arXiv 2016, arXiv:1610.05243. [Google Scholar]
- Junczys-Dowmunt, M.; Grundkiewicz, R. An Exploration of Neural Sequence-to-Sequence Architec-tures for Automatic Post-Editing. arXiv 2017, arXiv:1706.04138. [Google Scholar]
- Gu, J.; Wang, Y.; Cho, K.; Li, V.O. Search engine guided neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2−7 February 2018; Volume 32, pp. 5133–5140. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- Chen, Y.C.; Bansal, M. Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting. arXiv 2018, arXiv:1805.11080. [Google Scholar]
- Cao, Z.; Li, W.; Li, S.; Wei, F. Retrieve, rerank and rewrite: Soft template based neural summarization. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volu-me 1: Long Papers), Melbourne, Australia, 15−20 July 2018; pp. 152–161. [Google Scholar]
- Weston, J.; Dinan, E.; Miller, A.H. Retrieve and Refine: Improved Sequence Generation Models for Dialogue. arXiv 2018, arXiv:1808.04776. [Google Scholar]
- Quan, J.; Xiong, D.; Webber, B.; Hu, C. GECOR: An End-to-End Generative Ellipsis and Co-reference Resolution Model for Task-Orien-ted Dialogue. arXiv 2019, arXiv:1909.12086. [Google Scholar]
- Wu, W.; Wang, F.; Yuan, A.; Wu, F.; Li, J. CorefQA: Coreference resolution as query-based span prediction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5−10 July 2020; pp. 6953–6963. [Google Scholar]
- Song, S.; Wang, C.; Xie, Q.; Zu, X.; Chen, H.; Chen, H. A two-stage conversational query rewriting model with multi-task learning. In Proceedings of the Companion Proceedi-ngs of the Web Conference, Taipei Taiwan, 20−24 April 2020; pp. 6–7. [Google Scholar]
- Xu, K.; Tan, H.; Song, L.; Wu, H.; Zhang, H.; Song, L.; Yu, D. Semantic Role Labeling Guided Multi-turn Dialogue ReWriter. arXiv 2020, arXiv:2010.01417. [Google Scholar]
- Vakulenko, S.; Longpre, S.; Tu, Z.; Anantha, R. Question rewriting for conversational question answering. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8−12 March 2021; pp. 355–363. [Google Scholar]
- Yang, S.; Fu, B.; Yu, C.; Hu, C. Multi-Turn Conversation Rewriter Model Based on Masked-Pointer. Beijing Da Xue Xue Bao 2021, 57, 31–37. [Google Scholar]
- Yi, Z.; Ouyang, J.; Liu, Y.; Liao, T.; Xu, Z.; Shen, Y. A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems. arXiv 2024, arXiv:2402.18013. [Google Scholar]
- Liu, Q.; Chen, B.; Lou, J.G.; Zhou, B.; Zhang, D. Incomplete Utterance Rewriting as Semantic Segmentations. arXiv 2020, arXiv:2009.13166. [Google Scholar]
- Li, J.; Chen, Z.; Chen, L.; Zhu, Z.; Li, H.; Cao, R.; Yu, K. DIR: A Large-Scale Dialogue Rewrite Dataset for Cross-Domain Conversational Text-to-SQL. Appl. Sci. 2023, 13, 2262. [Google Scholar] [CrossRef]

{kind=link}
| Conversation Rounds | Conversation Information |
|---|---|
| Question 1 | What is C language? |
| Reply 1 | C language is a programming language. |
| Question 2 | What are its characteristics? |
| Reply 2 | ? |
| Question 3 | What is a computer? |
| Reply 3 | Computers are machines that can perform data operations. |
| Question 4 | Who is the inventor? |
| Reply 4 | ? |
| Data Property | Value |
|---|---|
| Total number of samples | 20,000 |
| Pronouns refer to sample size | 9200 |
| Information default sample size | 6600 |
| Number of complete semantic samples | 4200 |
| Average character length | 12.5 |
| Model | BLUE-1 | BLUE-2 | BLUE-3 | ROUGE-1 | ROUGE-2 | ROUGE-L | EM |
|---|---|---|---|---|---|---|---|
| LSTM-Gen [3] | 73.23 | 63.12 | 48.17 | 74.57 | 58.62 | 75.43 | 52.32 |
| Trans-Gen [3] | 78.75 | 69.16 | 54.32 | 77.52 | 62.63 | 78.83 | 56.84 |
| RUN-BERT [18] | 80.05 | 72.35 | 56.43 | 81.21 | 65.13 | 80.46 | 65.63 |
| LSTM-Exa | 74.15 | 64.28 | 49.22 | 76.34 | 59.82 | 76.37 | 53.29 |
| Trans-Exa (our model) | 80.31 | 71.02 | 56.82 | 81.43 | 65.39 | 80.69 | 68.72 |
| Model | 15,000 Samples | 8000 Samples | 2000 Samples | 1000 Samples |
|---|---|---|---|---|
| LSTM-Gen | 73.26 | 69.53 | 38.75 | 15.32 |
| Trans-Gen | 76.32 | 72.69 | 39.62 | 17.62 |
| LSTM-Exa | 74.67 | 72.28 | 71.21 | 69.45 |
| Trans-Exa (our model) | 81.82 | 77.12 | 76.63 | 74.62 |
| Model | 3000 Samples | 1000 Samples | 500 Samples | 100 Samples |
|---|---|---|---|---|
| LSTM-Gen | 320 | 124 | 68 | 21 |
| Trans-Gen | 102 | 35 | 18 | 3 |
| RUN-BERT | 32 | 10 | 3 | 1 |
| LSTM-Exa | 160 | 62 | 30 | 6 |
| Trans-Exa (our model) | 50 | 15 | 6 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pu, C.; Sun, Z.; Li, C.; Song, J. Dialogue-Rewriting Model Based on Transformer Pointer Extraction. Electronics 2024, 13, 2362. https://doi.org/10.3390/electronics13122362
Pu C, Sun Z, Li C, Song J. Dialogue-Rewriting Model Based on Transformer Pointer Extraction. Electronics. 2024; 13(12):2362. https://doi.org/10.3390/electronics13122362
Chicago/Turabian StylePu, Chenyang, Zhangjie Sun, Chuan Li, and Jianfeng Song. 2024. "Dialogue-Rewriting Model Based on Transformer Pointer Extraction" Electronics 13, no. 12: 2362. https://doi.org/10.3390/electronics13122362
APA StylePu, C., Sun, Z., Li, C., & Song, J. (2024). Dialogue-Rewriting Model Based on Transformer Pointer Extraction. Electronics, 13(12), 2362. https://doi.org/10.3390/electronics13122362