1. Introduction
Autonomous technology can ease traffic congestion, improve road traffic safety, and reduce greenhouse gas emissions, so it has become a hot research topic in recent years. At the present stage, autonomous technology mainly follows fixed rules and procedures to control vehicles, i.e., through radar, camera, positioning systems, and other sensors that collect sensory data in the actual driving scene, combined with the rules of vehicle driving in the real traffic scene to make driving decisions [
1]. This control method ignores the personalized characteristics of the driverless user and cannot meet the personalized needs of the user. Autonomous technology based on the personalized characteristics of driving users can make autonomous decisions and control for different driving styles, driving habits, and road conditions, which can satisfy different people’s preferences and needs for factors such as safety, comfort, and stability, and then provide a more accurate and high-quality user experience [
2,
3,
4,
5]. Therefore, personalized decision control for autonomous vehicles is necessary for future development, which has important social significance and research value.
At present, the personalized decision control of automatic vehicles is mainly studied from the following three aspects. First, through the study of the driver’s driving intention by reproducing a driver’s driving decision so as to realize personalized driving. Gindele [
6] studied the driver’s driving process and used a hierarchical dynamic Bayesian model to model and reproduce the driver’s decision-making process. Chen [
7] collected vehicle motion trajectories using visual sensors, modeled and reproduced the personalized decision-making process of different drivers using sparse representations, and validated the method using four different datasets. Their results showed that the accuracy of the method for classifying and recognizing driving behaviors was significantly higher than that of traditional methods. Yang [
8] studied the characteristics of driver following behavior, established a Gaussian mixture model, proposed a driving reference trajectory based on personalized driving, and realized the planning and control of vehicle state dynamics under a complex dynamic environment by designing a quadratic planning optimal controller. Second, some studies have directly integrated the driver model with the control module to achieve personalized driving. Abdul [
9] proposed the use of a cerebellar model controller to build a personalized driver’s driving behavior model, which enabled the modeling of different driving behavioral characteristics. Yan [
10] established an adaptive cruise control strategy that mimicked a driver’s driving characteristics by analyzing the driver’s driving data. Wang [
11] used Gaussian mixture models and hidden Markov models to learn from driving data to obtain a personalized driver model, which was used for vehicle motion trajectory prediction, and then established a personalized lane departure warning strategy. Li [
12] established a data-driven personalized vehicle trajectory planning method based on recurrent neural networks with actual driving data. In the third aspect, based on the assisted driving system, lane changing and following during personalized automatic driving were studied. Ramyar [
13], Zhu [
14], and Huang [
15] combined the assisted driving system, considered drivers’ personalized driving behaviors, and designed a control system for lane-changing scenarios in highway environments, which improved driving comfort and ensured driving safety. Zhu [
16] used personalized following driving as a research object and guided the learning process of the DDPG following strategy by setting the objective function of consistency evaluation with driving data. The method obtained an anthropomorphic longitudinal following model through continuous trial-and-error interaction with the environment model. Wang [
17] improved the DDPG algorithm in order to provide personalized driving services in line with driving habits, added a linear transformation process to the output of the algorithm, and designed a driving decision system for the vehicle so that the vehicle could learn different styles of personalized driving strategies. The results showed that the algorithm enabled the vehicle to maintain a higher level of lateral control than a general driver, and the lane offset, i.e., the extent to which a vehicle’s center of mass is offset from the centerline of the lane, decreased by 73.0%.
The aforementioned research on personalized decision control for autonomous vehicles mainly focuses on the identification, modeling, and analysis of driving styles, mostly based on assisted driving systems. A large number of constraints have been added to the research, and the dimensions of the state space and action space considered are lower. These are only applicable to the personalized decision control of autonomous vehicles in specific scenarios, such as following a car and changing lane scenarios, and do not consider multi-dimensional and multi-driving environment scenarios. Therefore, it is impossible to realize the personalized decision control of autonomous vehicles in the real sense and impossible to meet the requirements of different people for safety, comfort, and stability.
Aiming at the current problem of low dimensionality in the state space and the action space considered in personalized decision control for autonomous vehicles and poor adaptability, this paper innovatively introduces human feedback and designs a personalized decision control algorithm for autonomous vehicles based on the RLHF strategy. This strategy combines two reinforcement learning algorithms, namely, DDPG and PPO, and trains agents in three phases, including pre-training, human evaluation, and parameter optimization, so that the algorithm can be adapted to different styles of people and different scenarios. Then, simulation scenarios were built to train the designed control algorithms based on different driving styles, and finally, the effectiveness of the algorithms designed in this paper was verified through typical scenario simulations. The algorithm proposed in this paper can provide personalized decision control schemes for people with different driving styles and can adapt to different driving environments to maximize the satisfaction of human needs while ensuring safety, thus providing a reference for the personalized control of unmanned vehicles.
The main contributions of this paper lie firstly in proposing a personalized decision-making framework for automated driving that incorporates policy transfer and human–computer interactions. The framework utilizes knowledge learned from large-scale driving data to pre-train a generic policy, employs active learning to efficiently query human preferences for the most informative driving trajectories, and finally, finely tunes the pre-trained policy according to the individual’s driving style so as to adapt rapidly in the presence of limited personalized driving data. Secondly, the proposed RLHF approach offers higher interpretability and transparency as the model’s reward signals are derived from human-preferred trajectories rather than human-annotated labels, which reduces the influence of human factors on the learning outcome. This is a promising alternative to traditional approaches relying on predefined reward functions and can help to overcome the challenge of designing reward functions that accurately reflect the complexity of real-world situations.
4. Building the Simulation System and Human Feedback-Based DDPG Algorithm Training
4.1. Building the Simulation Environment
The construction of the training environment for autonomous vehicle control strategies based on complex traffic scenarios was completed in CARLA software [
24]. Among them, the controller of the autonomous vehicle obtains state information by interacting with the traffic environment so as to formulate the control strategy and output the next action. The controller on the client controls the autonomous vehicle’s steering, throttle, brake, and other action outputs by sending commands to the simulated vehicle.
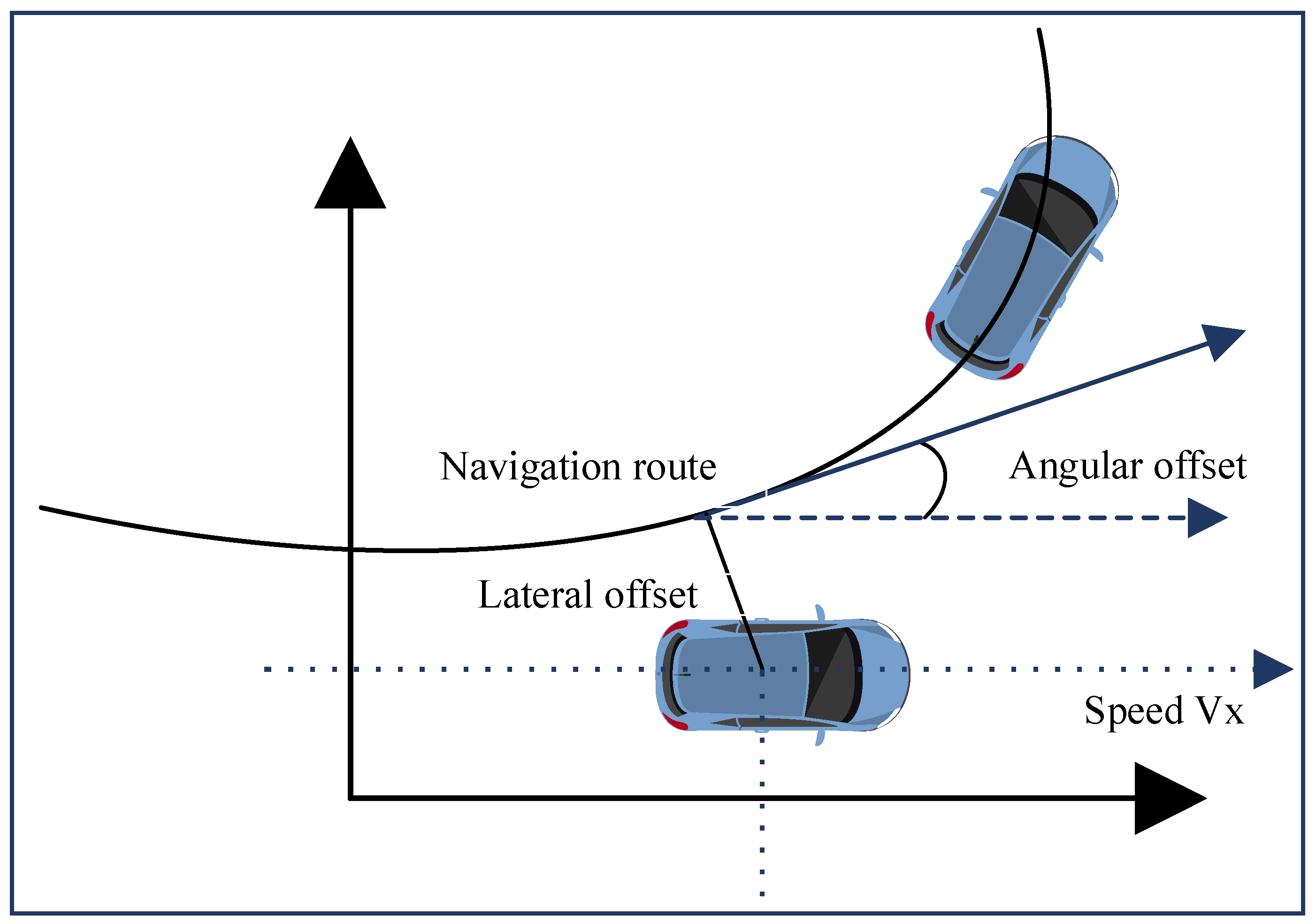
In this paper, we mainly use a camera as the sensor input, and the action outputs are steering, throttle, and brake. As stated previously, since the throttle and brake are not used at the same time, the throttle and brake of the autonomous vehicle are combined into the same action with a limit value of [−1, 1], where the value less than 0 is considered as the brake and greater than 0 is considered as the throttle. The state information used in the simulation is shown in
Table 3.
The action information to be output during the simulation is shown in
Table 4. To ensure the stability of the training, the state information provided by CARLA software, including tracking error and velocity, is normalized to limit its value to the range [−1, 1] to minimize the impact of the difference in state information on the network training.
4.2. DDPG-Based Algorithm Training
Given the appropriate network structure and reward function, a network model is then constructed on the PyTorch framework. Its network output is transformed into a control signal for controlling the CARLA software autonomous vehicle simulation system, followed by the training of the autonomous vehicle control strategy by the DDPG algorithm.
The training scheme is as follows: CARLA software’s Town 3 map is used as the environment, which includes various complex urban traffic scenarios, such as intersections, traffic circles, crossroads, tunnels, etc. Each training session uses CARLA-Simulator to adjust the number of other traffic participants to 50, and the weather is the default “clear daylight”. Each time, the starting point of the vehicle is randomly adjusted, and the infinitely generated navigation route is given by Gym-CARLA to ensure that the agent learns to complete the task safely and efficiently in different traffic scenarios and to ensure the training efficiency and improve the convergence speed of the agent. The maximum number of steps per episode is limited to 5000 in this paper.
During the training of autonomous vehicles, the speed and efficiency of training can be improved by setting the end-of-episode conditions. The episode ends when the following three conditions occur:
- (1)
The vehicle runs in reverse.
- (2)
Vehicle collision or red light running.
- (3)
The return is too low within a certain number of steps (e.g., less than 5 in 100 steps).
To evaluate the performance of the trained model, the trained model was tested every 100 episodes. As shown in
Figure 5, as the number of training episodes increased, the increase in the number of steps was gradually obvious by about 2000 episodes. This indicates that the agent learned the method to complete the task and thus also proves the feasibility and effectiveness of the DDPG algorithm in dealing with complex traffic scenarios.
4.3. Algorithm Training with the Introduction of Human Feedback
When the DDPG training is completed, even if the reward value converges and is high enough, it may only fall into a certain local optimum, and its performance does not necessarily satisfy human preferences [
25]. In order to make the behavior of the agent satisfy human preferences, we introduce human feedback to evaluate the decision control trajectory for the autonomous vehicle model trained by DDPG, train a reward model, and let it guide DDPG to continue iterative optimization, which can effectively satisfy human preferences.
4.3.1. Human Data Collection
In order to obtain different styles of the reward model, two people with different driving styles, A and B, were chosen. A has a more aggressive driving style and is willing to increase speed as much as possible in a safe situation. On the contrary, B likes stability, believes that overtaking and other behaviors are very dangerous, and is unwilling to perform such dangerous behaviors and tries to keep the distance between cars to ensure safety. The model is trained to guide optimization according to the RLHF algorithm’s second phase of training. The trained DDPG agent collects data by driving repeatedly through different complex traffic environments, while the number of other traffic participants is configured by CARLA software’s own traffic flow manager.
In order to train a more accurate reward model so that it has a good effect without overfitting and affecting the generalization ability of the model, a total of 4000 sets of data are selected here, and a set of starting points and task target points are set at each intersection to make the vehicle follow the given trajectory.
Figure 6 shows a comparison of the different trajectories preferred by agents
A and
B in a certain identical situation. The black car is the agent of this paper, and a red arrow is used to mark the current direction of vehicle travel. The other vehicles (blue car and white car) are the randomly set traffic participants by CARLA software.
In this paper, a neural network containing input state actions and output rewards is used as the reward model. During the training process, two sets of trajectories, Traj.1 and Traj.2, are collected from a human expert and evaluated for their goodness or badness using the human feedback u. Then, these data are saved in a ternary () and used to train the reward function of the reward model.
4.3.2. Reward Model Training
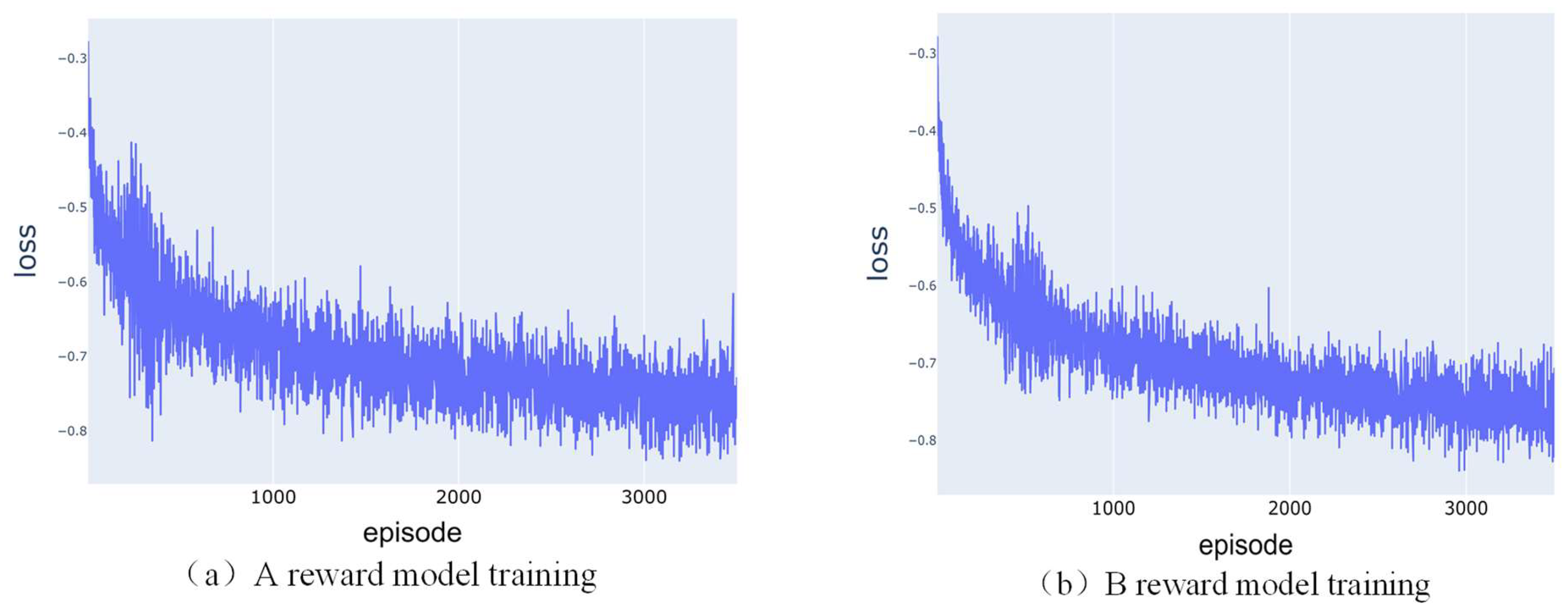
During the training process, the loss is calculated using the cross-entropy loss function, where a smaller the loss value indicates that the model output results are closer to the evaluation results of human feedback. During the training process, the Adam optimizer is used to update the parameters of the reward model, which minimizes the loss. Through iterative updates, an excellent reward model can be trained and used to guide the agent to obtain better performance in reinforcement learning tasks.
Figure 7 shows the loss curves of the reward model training process for agents A and B. It can be seen that the loss values at the end of training are both much smaller relative to the beginning.
After the reward model is trained with enough data, it is used instead of the reinforcement learning reward function to continue to fine tune the policy model. Then, the reward models corresponding to A and B are plugged into the original training process to obtain two agents with different policies.
4.4. Assessment of Strategy Style Changes
In order to measure the magnitude of the change in the strategy style of the two agents
A and
B after iteration and to ensure that the agents have learned the human style, the three features of average speed, average lateral offset, and average angular offset during the training iterations are used to construct vectors. The difference between different agents are measured by the Euclidean distance between the vectors, and the Euclidean distance is calculated as follows:
where both
A and
B are
n-dimensional vectors and
denotes the Euclidean distance between vectors
A and
B. It can be seen that the larger the similarity value, the smaller the difference between the two vectors and the higher the similarity.
During the fine-tuning process, every 1000 episodes, the average speed, average lateral offset, and average angular offset are calculated by testing with agents A and B and constructing the feature vectors. The following plots show the correlation coefficients of each agent style at the 1000th episode, the 2000th episode, the 3000th episode, and the 4000th episode. Both the horizontal and vertical coordinates are divided into four categories, and each cell indicates the similarity between the corresponding styles, the larger the value and the darker the color, the higher the similarity.
From
Figure 8, it can be found that there are four different styles, namely, A_human, B_human, A_agent, and B_agent. A_human and B_human are based on the feature styles corresponding to human data, while A_agent and B_agent are the feature styles corresponding to the data generated by the agent as the training time increases. At the beginning, the similarity between A_agent and B_agent in
Figure 8a is 0.86, which means that the style gap between them is not big. However, with the increase in training time, the similarity between A_agent and B_agent in
Figure 8d becomes 0.23, which indicates that the style gap between them becomes larger. Meanwhile, the style gap between A_agent and A_human increases from 0.3 to 0.76, and the style similarity between B_agent and B_human increases from 0.29 to 0.63, indicating that after fine-tuning, two different styles of agents are indeed produced and that these two agents are much closer to A_human and B_human humans, respectively.
6. Conclusions
Based on the deep reinforcement learning algorithm with human feedback, this paper proposes an efficient and personalized decision control algorithm for autonomous vehicles. The algorithm combines two reinforcement learning algorithms, DDPG and PPO, and divides the control scheme into three phases including the pre-training phase, the human evaluation phase, and the parameter optimization phase. In the pre-training phase, the algorithm uses the DDPG algorithm to train an agent. In the human evaluation phase, the agent uses different trajectories generated by the DDPG algorithm to allow for different styles of people to rate them and, in turn, train their respective reward models based on the trajectories. In the parameter optimization phase, the network parameters are updated using the PPO algorithm and the reward values given by the reward models. Ultimately, the algorithm can adapt to different styles of people and give personalized decision-control solutions while ensuring safety.
Different behaviors of autonomous vehicles in avoiding pedestrians and vehicles in the face of intersections and complex traffic flow are tested through typical scenario experiments. The experimental results show that the algorithm can provide personalized decision-control solutions for different styles of people and satisfy human needs to the maximum extent while ensuring safety.
Driving style can be very complex. At present, only three dimensions of feature vectors are used in this paper to judge user preference. In future research, a deeper network structure and a more complex reward model can be tested to obtain better performance. At the same time, more feature data can be considered to judge the user preference so as to satisfy the user’s needs better.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}