
Leveraging Self-Distillation and Disentanglement Network to Enhance Visual–Semantic Feature Consistency in Generalized Zero-Shot Learning
 , ,
, ,
Abstract
1. Introduction
- We identified that most models typically do not handle visual–semantic inconsistent features and directly align them, which may lead to alignment bias. We propose an approach to enhance the consistency of visual–semantic features by refining visual features and disentangling original visual–semantic features.
- We designed a self-distillation embedding module, which generates soft labels through an auxiliary self-teacher network and employs soft label distillation and feature map distillation methods to refine the original visual features of seen classes and synthesized visual features of unseen classes from the generator, thereby enhancing the semantic consistency of visual features.
- We proposed a disentanglement network, which encodes visual–semantic features into latent representations and promotes visual–semantic consistent features to be separated from original features through semantic relation matching and latent representation independence methods, significantly enhancing the consistency of visual–semantic features.
- Extensive experiments on four GZSL benchmark datasets demonstrate that our model can separate refined visual–semantic features with consistency from original visual–semantic features, thereby alleviating alignment bias caused by visual–semantic inconsistency and improving the performance of GZSL models.
2. Related Work
2.1. Generative-Based Generalized Zero-Shot Learning
2.2. Knowledge Distillation
3. Materials and Methods
3.1. Problem Definition
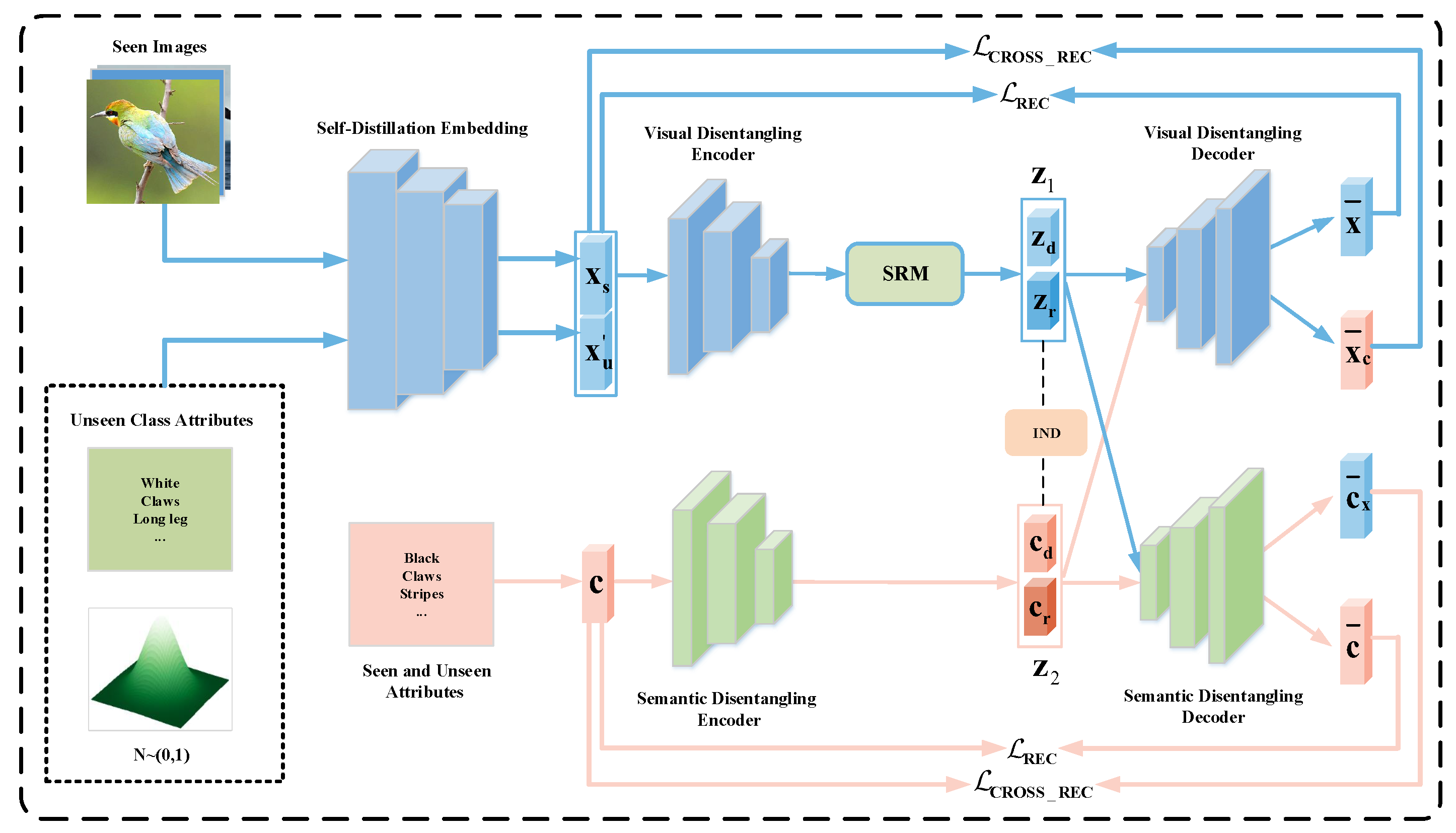
3.2. Overall Framework
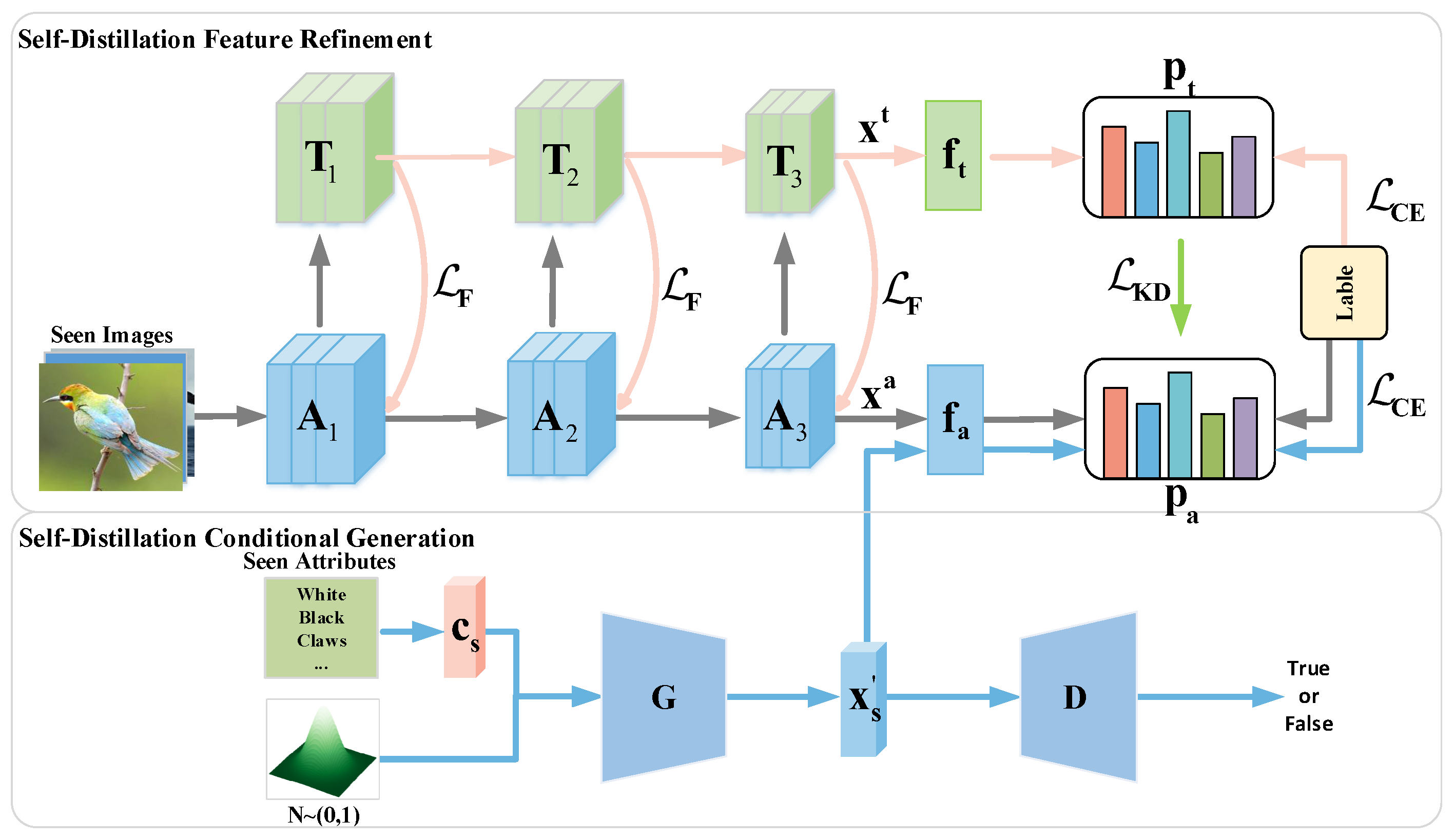
3.3. Self-Distillation Embedding Module
3.3.1. Auxiliary Self-Teacher Network
3.3.2. Self-Distillation Conditional Generation Module
3.4. Disentanglement Network
3.4.1. Visual–Semantic Disentangled Autoencoder
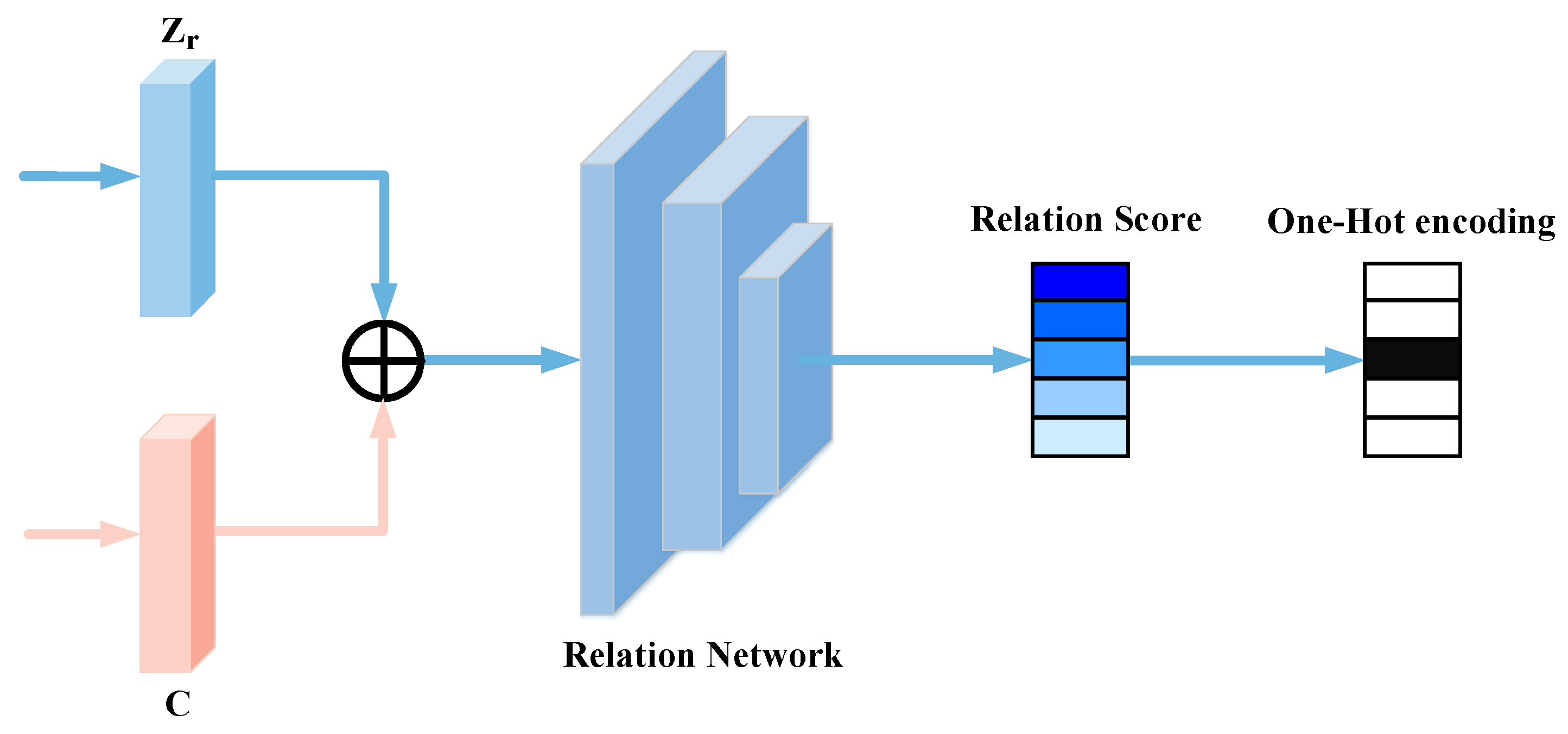
3.4.2. Semantic Relation Matching
3.4.3. Independence between Latent Representations
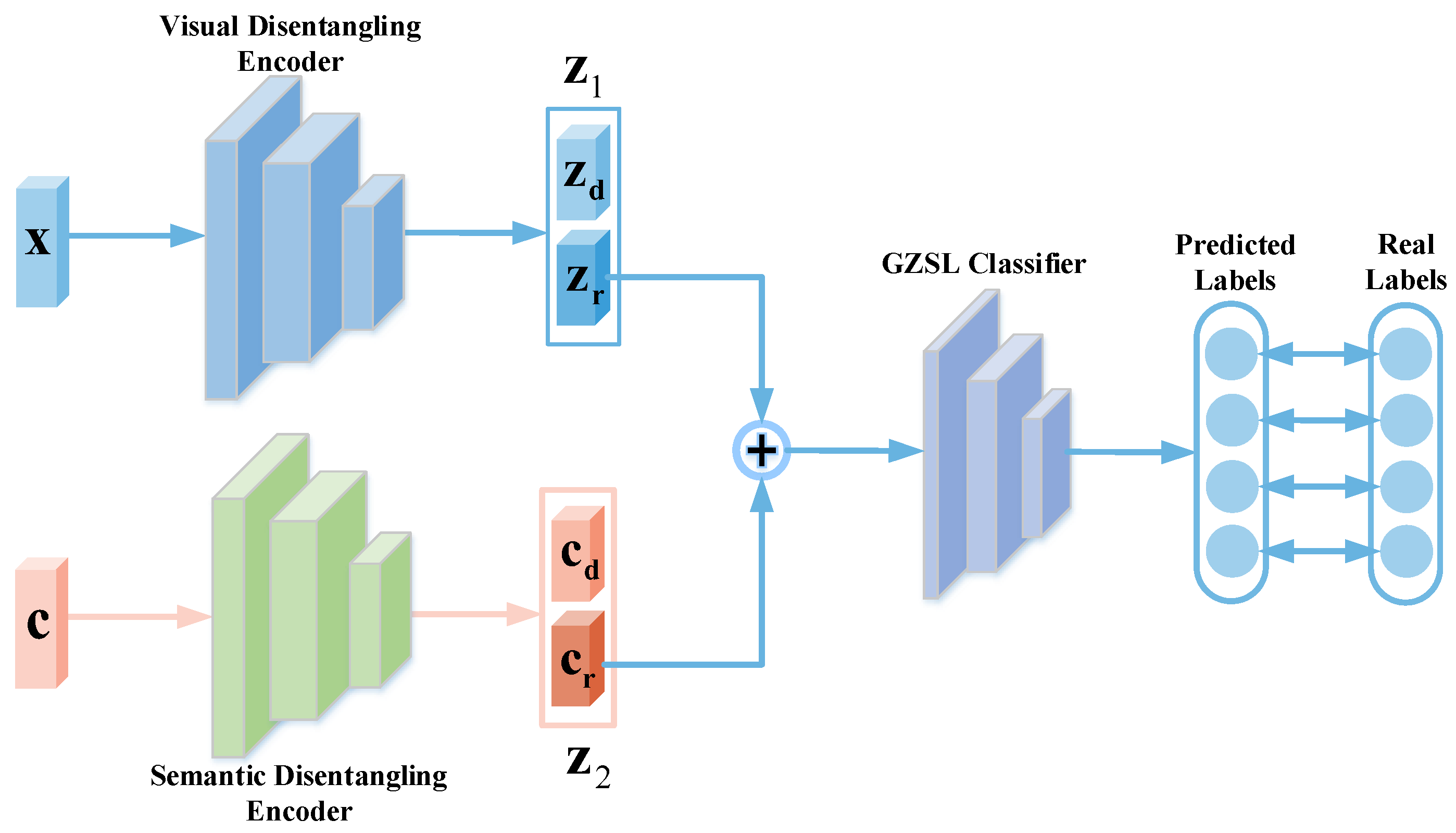
3.5. Classification
4. Experiments
4.1. Datasets
4.2. Evaluation Protocol
4.3. Implementation Details
Comparing with the State of the Art
5. Model Analysis
5.1. Ablation Study
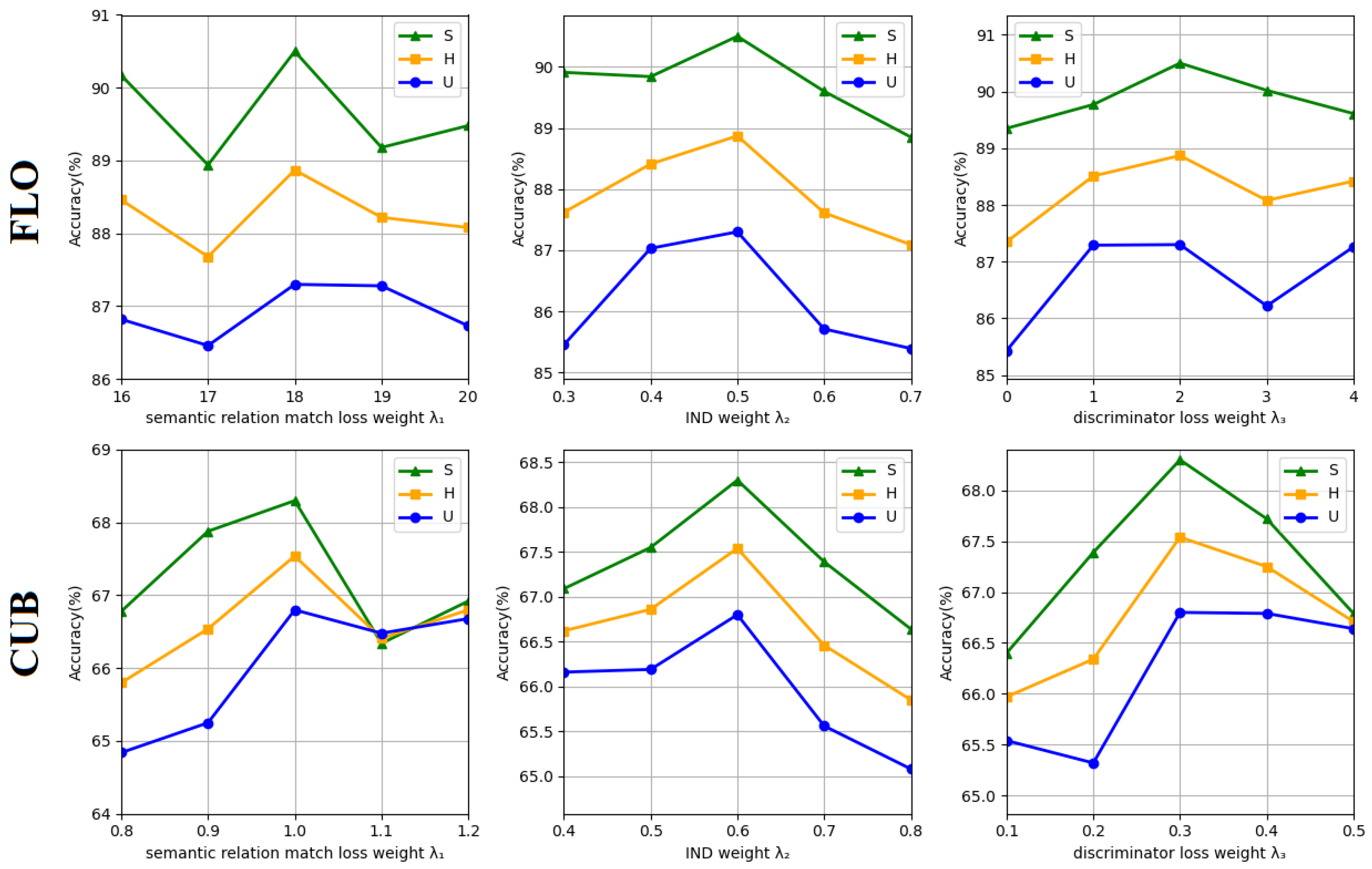
5.2. Hyper-Parameter Analysis
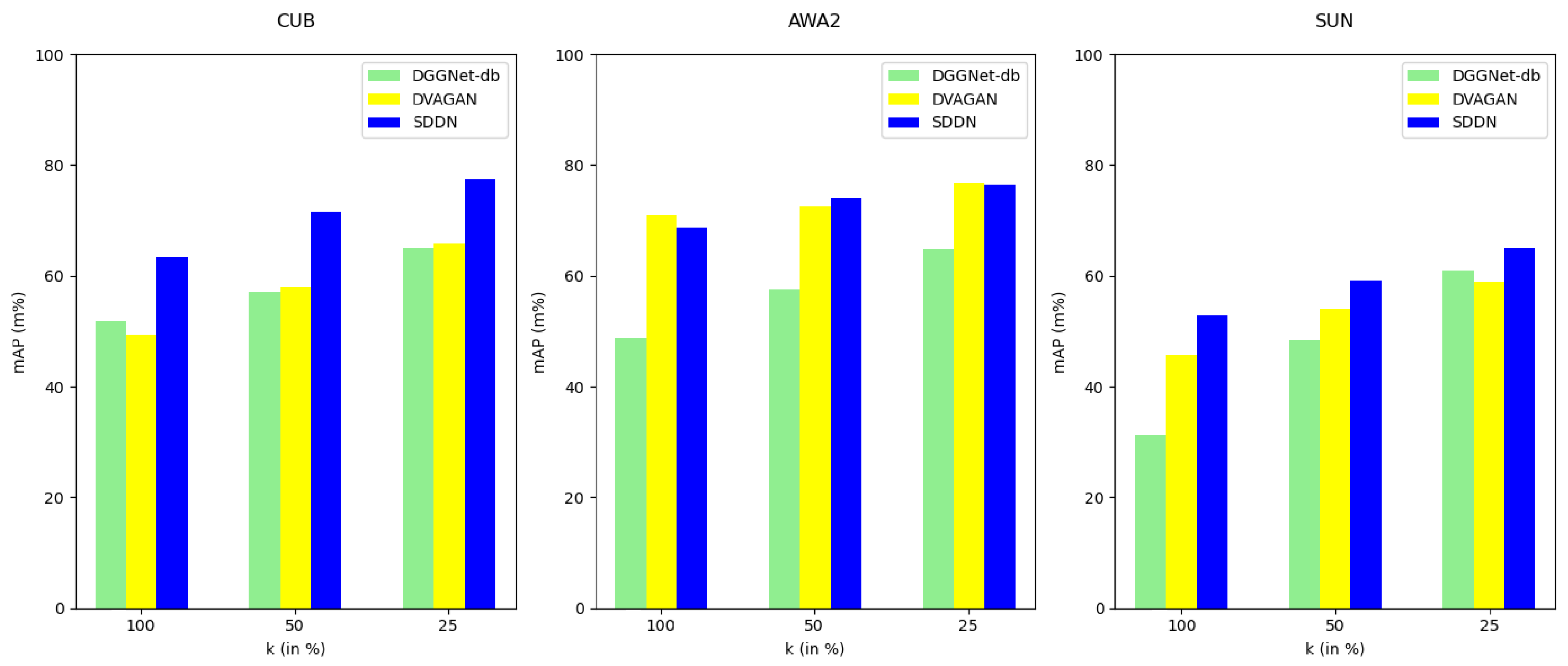
5.3. Zero-Shot Retrieval Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Hao, Y.; Mu, T.; Li, O.; Wang, S.; He, X. Bi-directional distribution alignment for transductive zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19893–19902. [Google Scholar]
- Chen, Z.; Luo, Y.; Qiu, R.; Wang, S.; Huang, Z.; Li, J.; Zhang, Z. Semantics disentangling for generalized zero-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Chen, S.; Wang, W.; Xia, B.; Peng, Q.; You, X.; Zheng, F.; Shao, L. Free: Feature refinement for generalized zero-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Li, X.; Xu, Z.; Wei, K.-J.; Deng, C. Generalized zero-shot learning via disentangled representation. AAAI Conf. Artif. Intell. 2021, 35, 1966–1974. [Google Scholar] [CrossRef]
- Chen, Z.; Li, J.; Luo, Y.; Huang, Z.; Yang, Y. Canzsl: Cycle-consistent adversarial networks for zero-shot learning from natural language. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 7–11 January 2019. [Google Scholar]
- Kim, J.; Shim, K.; Shim, B. Semantic feature extraction for generalized zero-shot learning. Proc. Aaai Conf. Artif. Intell. 2022, 3, 1166–1173. [Google Scholar] [CrossRef]
- Feng, L.; Zhao, C. Transfer increment for generalized zero-shot learning. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2506–2520. [Google Scholar] [CrossRef] [PubMed]
- Sun, K.; Zhao, X.; Huang, H.; Yan, Y.; Zhang, H. Boosting generalized zero-shot learning with category-specific filters. J. Intell. Fuzzy Syst. 2023, 45, 563–576. [Google Scholar] [CrossRef]
- Min, S.; Yao, H.; Xie, H.; Wang, C.; Zha, Z.-J.; Zhang, Y. Domain-aware visual bias eliminating for generalized zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Xie, G.-S.; Liu, L.; Zhu, F.; Zhao, F.; Zhang, Z.; Yao, Y.; Qin, J.; Shao, L. Region graph embedding network for zero-shot learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part IV 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 562–580. [Google Scholar]
- Liu, Y.; Zhou, L.; Bai, X.; Huang, Y.; Gu, L.; Zhou, J.; Harada, T. Goal-oriented gaze estimation for zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, C.; Min, S.; Chen, X.; Sun, X.; Li, H. Dual progressive prototype network for generalized zero-shot learning. Adv. Neural Inf. Process. Syst. 2021, 34, 2936–2948. [Google Scholar]
- Wang, C.; Chen, X.; Min, S.; Sun, X.; Li, H. Task-independent knowledge makes for transferable representations for generalized zero-shot learning. Proc. Aaai Conf. Artif. Intell. 2021, 35, 2710–2718. [Google Scholar] [CrossRef]
- Kwon, G.; AlRegib, G. A Gating Model for Bias Calibration in Generalized Zero-Shot Learning. arXiv 2022, arXiv:2203.04195. [Google Scholar] [CrossRef] [PubMed]
- Narayan, S.; Gupta, A.; Khan, F.S.; Snoek, C.G.M.; Shao, L. Latent embedding feedback and discriminative features for zero-shot classification. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XXII 16; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Zhang, M.; Wang, X.; Shi, Y.; Ren, S.; Wang, W. Zero-shot learning with joint generative adversarial networks. Electronics 2023, 12, 2308. [Google Scholar] [CrossRef]
- Li, N.; Chen, J.; Fu, N.; Xiao, W.; Ye, T.; Gao, C.; Zhang, P. Leveraging dual variational autoencoders and generative adversarial networks for enhanced multimodal interaction in zero-shot learning. Electronics 2024, 13, 539. [Google Scholar] [CrossRef]
- Zhang, Y.; Tian, Y.; Zhang, S.; Huang, Y. Dual-uncertainty guided cycle-consistent network for zero-shot learning. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6872–6886. [Google Scholar] [CrossRef]
- Han, Z.; Fu, Z.; Chen, S.; Yang, J. Contrastive embedding for generalized zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Kim, J.; Park, S.; Kwak, N. Paraphrasing Complex Network: Network Compression via Factor Transfer. arXiv 2020, arXiv:1802.04977v3. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7130–7138. [Google Scholar]
- Koratana, A.; Kang, D.; Bailis, P.; Zaharia, M. Lit: Learned intermediate representation training for model compression. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2019; pp. 3509–3518. [Google Scholar]
- Tung, F.; Mori, G. Similarity-preserving knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Peng, B.; Jin, X.; Liu, J.; Zhou, S.; Wu, Y.; Liu, Y.; Li, D.; Zhang, Z. Correlation congruence for knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive representation distillation. arXiv 2019, arXiv:1910.10699. [Google Scholar]
- Liu, Y.; Cao, J.; Li, B.; Yuan, C.; Hu, W.; Li, Y.; Duan, Y. Knowledge distillation via instance relationship graph. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Park, W.; Kim, D.; Lu, Y.; Cho, M. Relational knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Xu, T.-B.; Liu, C.-L. Data-distortion guided self-distillation for deep neural networks. Proc. Aaai Conf. Artif. Intell. 2019, 33, 5565–5572. [Google Scholar] [CrossRef]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3713–3722. [Google Scholar]
- Shen, Y.; Xu, L.; Yang, Y.; Li, Y.; Guo, Y. Self-distillation from the last mini-batch for consistency regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11943–11952. [Google Scholar]
- Ji, M.; Shin, S.; Hwang, S.; Park, G.; Moon, I.-C. Refine myself by teaching myself: Feature refinement via self-knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-Ucsd Birds-200–2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-shot learning—A comprehensive evaluation of the good, the bad and the ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2251–2265. [Google Scholar] [CrossRef] [PubMed]
- Patterson, G.; Hays, J. Sun attribute database: Discovering, annotating, and recognizing scene attributes. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2751–2758. [Google Scholar]
- Nilsback, M.-E.; Zisserman, A. Automated flower classification over a large number of classes. In Proceedings of the 2008 6th Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar]
- Biswas, K.; Kumar, S.; Banerjee, S.; Pandey, A.K. Smooth maximum unit: Smooth activation function for deep networks using smoothing maximum technique. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 794–803. [Google Scholar]
- Jiang, H.; Wang, R.; Shan, S.; Chen, X. Transferable contrastive network for generalized zero-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Feng, Y.; Huang, X.; Yang, P.; Yu, J.; Sang, J. Non-generative generalized zero-shot learning via task-correlated disentanglement and controllable samples synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9346–9355. [Google Scholar]
- Xian, Y.; Sharma, S.; Schiele, B.; Akata, Z. f-vaegan-d2: A feature generating framework for any-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, J.; Jin, M.; Lu, K.; Ding, Z.; Zhu, L.; Huang, Z. Leveraging the invariant side of generative zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Kong, X.; Gao, Z.; Li, X.; Hong, M.; Liu, J.; Wang, C.; Xie, Y.; Qu, Y. En-compactness: Self-distillation embedding & contrastive generation for generalized zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9306–9315. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | |||||
|---|---|---|---|---|---|
| AWA2 | 2048 | 85 | 40 | 10 | 37,322 |
| CUB | 2048 | 312 | 150 | 50 | 11,788 |
| FLO | 2048 | 1024 | 82 | 20 | 8189 |
| SUN | 2048 | 102 | 645 | 72 | 14,340 |
| Method | FLO | CUB | AWA2 | SUN | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TCN [43] | - | - | - | 52.6 | 52.0 | 52.3 | 61.2 | 65.8 | 63.4 | 31.2 | 37.3 | 34.0 |
| DVBE [9] | - | - | - | 53.2 | 60.2 | 56.5 | 63.6 | 70.8 | 67.0 | 45.0 | 37.2 | 40.7 |
| RGEN [10] | - | - | - | 60.0 | 73.5 | 66.1 | 67.1 | 76.5 | 71.5 | 44.0 | 31.7 | 36.8 |
| TDCSS [44] | 54.1 | 85.1 | 66.2 | 44.2 | 62.8 | 51.9 | 59.2 | 74.9 | 66.1 | - | - | - |
| f-VAEGAN-D2 [45] | 56.8 | 74.9 | 64.6 | 48.4 | 60.1 | 53.6 | 57.6 | 70.6 | 63.5 | 45.1 | 38.0 | 41.3 |
| LisGAN [46] | 57.7 | 83.8 | 68.3 | 46.5 | 57.9 | 51.6 | 52.6 | 76.3 | 62.3 | 42.9 | 37.8 | 40.2 |
| CANZSL [5] | 58.2 | 77.6 | 66.5 | 47.9 | 58.1 | 52.5 | 49.7 | 70.2 | 58.2 | 46.8 | 35.0 | 40.0 |
| SE-GZSL [6] | - | - | - | 41.5 | 53.3 | 46.7 | 58.3 | 68.1 | 62.8 | 30.5 | 40.9 | 34.9 |
| TIZSL [7] | 70.4 | 68.7 | 69.5 | 52.1 | 53.3 | 52.7 | 76.8 | 66.9 | 71.5 | 32.3 | 24.6 | 27.9 |
| FREE [3] | 67.4 | 84.5 | 75.0 | 55.7 | 59.9 | 57.7 | 60.4 | 75.4 | 67.1 | 47.4 | 37.2 | 41.7 |
| SDGZSL [2] | 83.3 | 90.2 | 86.6 | 59.9 | 66.4 | 63.0 | 64.6 | 73.6 | 68.8 | 48.2 | 36.1 | 41.3 |
| JG-ZSL [16] | - | - | - | 60.8 | 63.9 | 62.3 | 63.1 | 68.3 | 65.6 | 50.2 | 37.9 | 43.2 |
| ICCE [47] | 66.1 | 86.5 | 74.9 | 67.3 | 65.5 | 66.4 | 65.3 | 82.3 | 72.8 | - | - | - |
| DGCNet-db [18] | - | - | - | 51.5 | 57.5 | 54.4 | 50.4 | 72.8 | 59.6 | 26.8 | 39.6 | 32.0 |
| DVAGAN [17] | - | - | - | 52.5 | 57.3 | 54.8 | 65.9 | 82.0 | 73.1 | 44.7 | 37.9 | 41.0 |
| Our SDDN | 87.3 | 90.5 | 88.9 | 66.8 | 68.3 | 67.5 | 65.6 | 74.3 | 69.7 | 48.6 | 42.3 | 45.2 |
| Method | FLO | CUB | ||||
|---|---|---|---|---|---|---|
| U | S | H | U | S | H | |
| SDDN w/o LSRM and IND and LSDE | 39.6 | 50.2 | 44.2 | 35.3 | 40.1 | 37.5 |
| SDDN w/o LSRM and IND | 48.7 | 54.5 | 51.4 | 38.6 | 43.2 | 40.8 |
| SDDN w/o LSRM | 60.3 | 71.6 | 65.5 | 48.1 | 57.8 | 52.5 |
| SDDN w/o IND | 79.6 | 81.2 | 80.4 | 56.7 | 60.9 | 58.7 |
| SDDN w/o LSDE | 86.9 | 88.7 | 87.8 | 65.5 | 67.9 | 66.7 |
| SDDN | 87.3 | 90.5 | 88.9 | 66.8 | 68.2 | 67.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Wang, C.; Yang, G.; Wang, C.; Long, Y.; Liu, J.; Zhang, Z. Leveraging Self-Distillation and Disentanglement Network to Enhance Visual–Semantic Feature Consistency in Generalized Zero-Shot Learning. Electronics 2024, 13, 1977. https://doi.org/10.3390/electronics13101977
Liu X, Wang C, Yang G, Wang C, Long Y, Liu J, Zhang Z. Leveraging Self-Distillation and Disentanglement Network to Enhance Visual–Semantic Feature Consistency in Generalized Zero-Shot Learning. Electronics. 2024; 13(10):1977. https://doi.org/10.3390/electronics13101977
Chicago/Turabian StyleLiu, Xiaoming, Chen Wang, Guan Yang, Chunhua Wang, Yang Long, Jie Liu, and Zhiyuan Zhang. 2024. "Leveraging Self-Distillation and Disentanglement Network to Enhance Visual–Semantic Feature Consistency in Generalized Zero-Shot Learning" Electronics 13, no. 10: 1977. https://doi.org/10.3390/electronics13101977
APA StyleLiu, X., Wang, C., Yang, G., Wang, C., Long, Y., Liu, J., & Zhang, Z. (2024). Leveraging Self-Distillation and Disentanglement Network to Enhance Visual–Semantic Feature Consistency in Generalized Zero-Shot Learning. Electronics, 13(10), 1977. https://doi.org/10.3390/electronics13101977