

Data-Driven ICS Network Simulation for Synthetic Data Generation



Abstract
1. Introduction
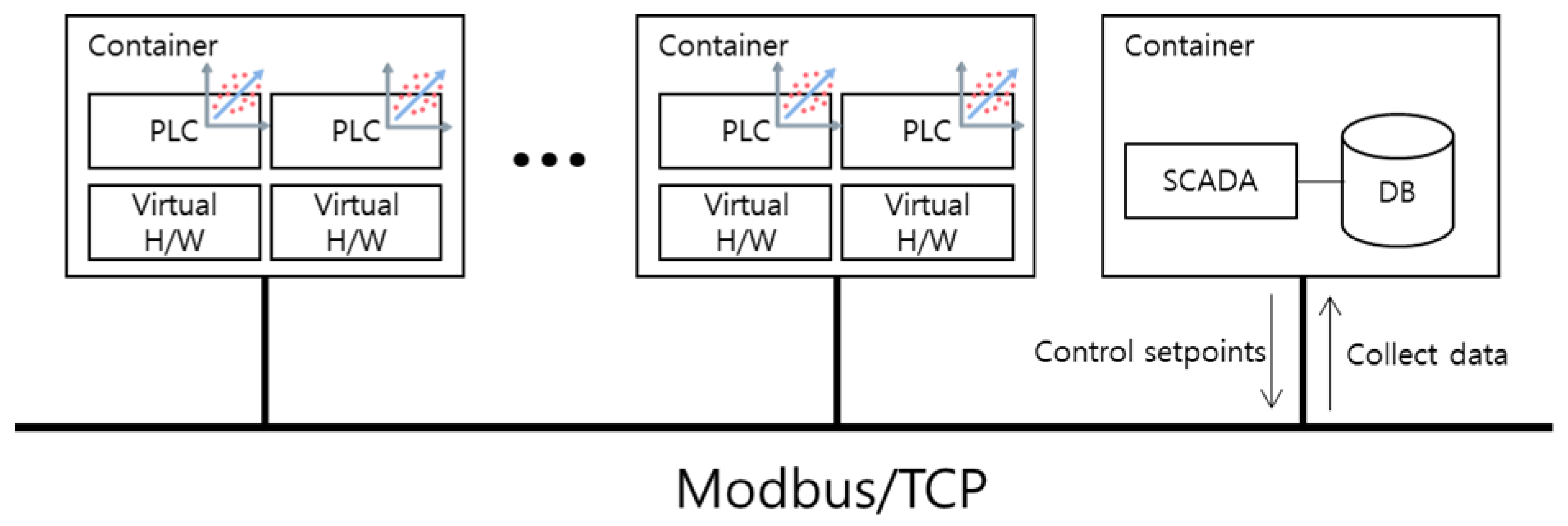
- For a given original ICS dataset, we reproduce the ICS network environment where the dataset was collected with a virtualized container.
- Each container contains a PLC or SCADA, and the control logic of the PLC is regressed from the given ICS dataset.
- SCADA uses setpoints to control PLCs, and the values of setpoints are set probabilistically to ensure the randomness of the collected datasets.
2. Related Work
2.1. Public Datasets for ICS
2.2. Synthetic Data Generation
2.3. Dynamic Time Warping
- Speech recognition: DTW can be used to compare spoken words, accounting for variations in speaking rates.
- Gesture recognition: in analyzing motion data, DTW aids in recognizing gestures even if they are performed at different speeds.
- Biomedical signal processing: DTW is employed to compare biomedical signals like electrocardiograms (ECG) or DNA sequences.
- Pattern recognition: DTW helps in recognizing patterns in sequences with variable lengths, such as handwriting recognition.
3. Proposal
3.1. Overview
3.1.1. Containers for SCADA System
3.1.2. Containers for PLCs
3.2. Reproducing Control Logic for PLCs
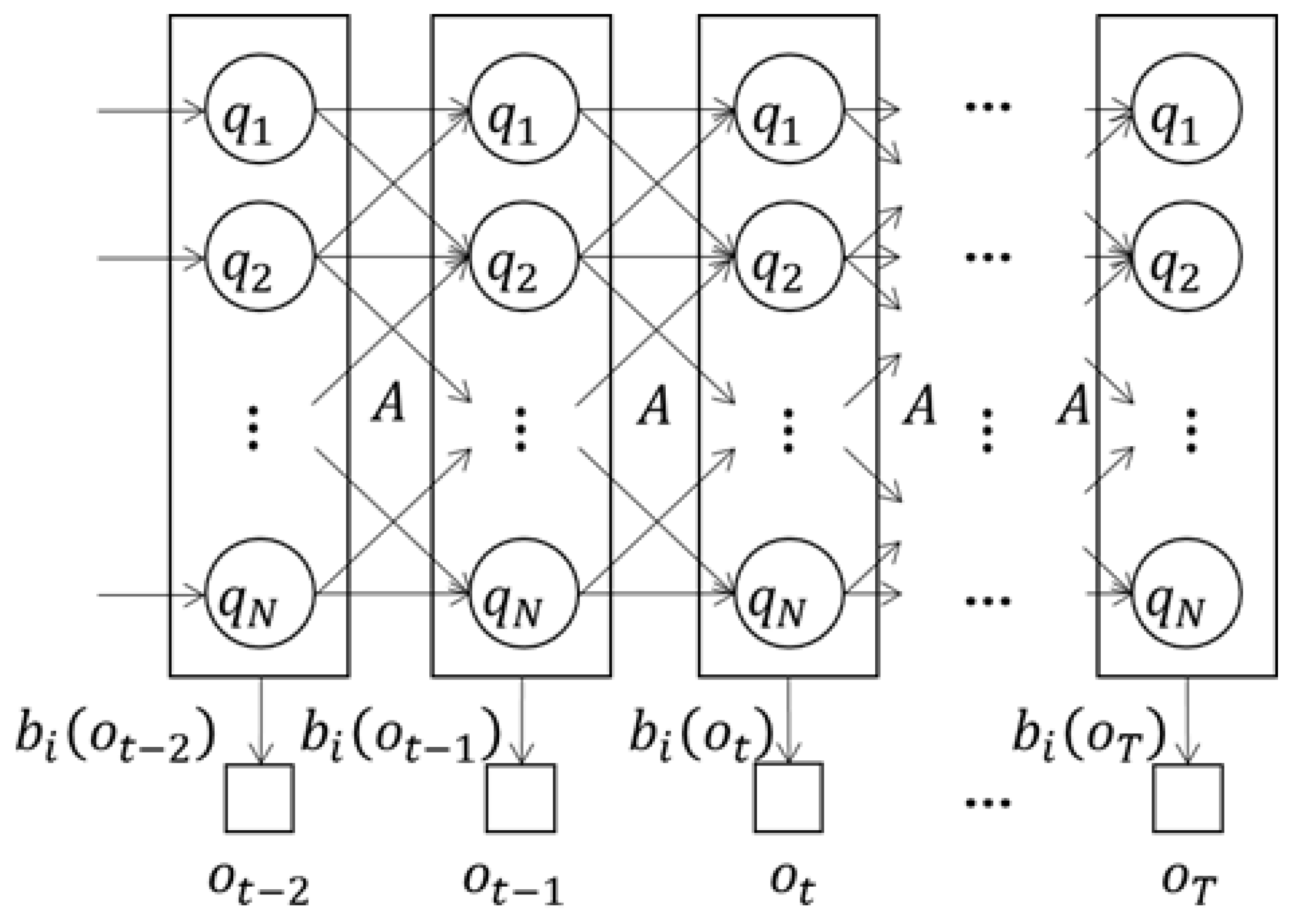
3.3. Hidden Markov Model for Setpoint Generation
| Algorithm 1 Baum-Welch algorithm for training HMM model on setpoint in PLC |
|
| Algorithm 2 Generate Setpoint using Gaussian distribution |
|
4. Evaluation of Simulated ICS
4.1. Implementation
4.2. Experimental Results
4.2.1. Model Creation
4.2.2. Evaluation Metrics
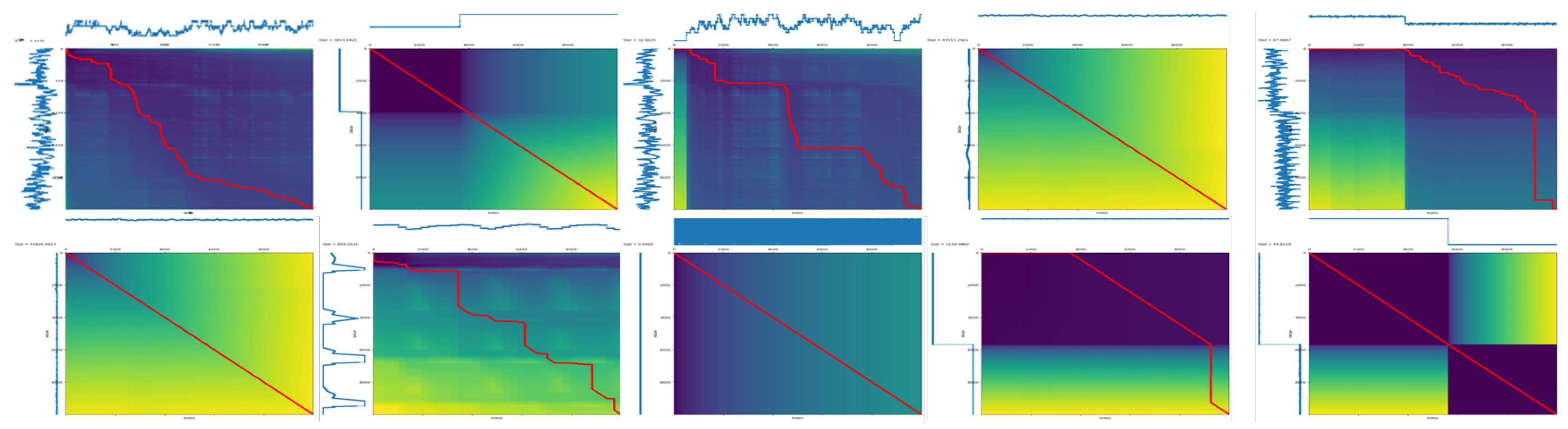
- Dynamic time warping (DTW): This powerful technique measures the similarity between two time series sequences, accounting for temporal distortions and misalignments. We utilized DTW to compare the temporal patterns and dynamics between the generated synthetic data and the benchmark SWaT dataset, ensuring our simulation accurately captures the temporal aspects of real-world network traffic.
- Statistical analysis: We further compared the statistical properties of the generated data with those of the SWaT dataset. This included analyzing key statistical moments such as mean, variance, and higher-order moments to validate that the synthetic data accurately reflect the overall statistical distribution of the real-world network traffic.
4.2.3. Analysis of Dynamic Time Warping (DTW)
- Validation of synthetic data generation: It confirms the effectiveness of our proposed method in generating realistic and representative synthetic ICS network data. This paves the way for its use in various research and development tasks related to ICS security analysis and anomaly detection.
- Improved model performance: By providing realistic training data, our synthetic data can potentially lead to the development of more robust and generalizable models for anomaly detection and other tasks in the domain of ICS cybersecurity.
- Reduced reliance on real-world data: The availability of accurate synthetic data can alleviate the dependence on scarce and sensitive real-world ICS network data for training and evaluation purposes. This can be particularly beneficial for security-sensitive applications or situations where access to real-world data is limited.
4.2.4. Statistical Analysis
- Mean analysis: The mean values of the synthetic data models closely align with those of the benchmark dataset. This suggests that our simulation successfully replicates the central tendencies observed in the real-world ICS network data.
- Variance analysis: Similarly, the variance values of the synthetic data models exhibit similarities to the benchmark dataset. The variance reflects the degree of data dispersion, and our synthetic data capture this dispersion effectively.
4.3. Computational Complexity Analysis
4.3.1. ICS Environment Recreation
- Virtualized container operations: The creation, maintenance, and communication between virtualized containers introduce overhead, and the scalability of the simulation relies on the efficiency of these operations. Analyzing the time complexity of container-related tasks is crucial for understanding how the computational demands grow with the size and complexity of the simulated ICS environment.
- Communication protocol overheads: Simulating the Modbus/TCP protocol for intercontainer communication adds another layer of complexity. Understanding the computational demands of encoding, transmitting, and decoding messages within the simulated environment provides insights into the scalability and efficiency of our approach.
4.3.2. Autonomous Control Logic Generation
- Abductive inference: The correlation analysis between input and output signals and subsequent application of linear regression introduce computational complexities. The time complexity of abductive inference relies on the size of the dataset and the efficiency of linear regression algorithms.
- Hidden Markov model learning: The Baum–Welch algorithm used for learning the parameters of the hidden Markov model (HMM) contributes to computational demands. Analyzing the time complexity of the Baum–Welch algorithm provides insights into the efficiency of our setpoint generation approach.
- Reflection on computational efficiency: While our proposed approach offers a comprehensive simulation architecture for ICS environments, it is essential to acknowledge the computational demands associated with the virtualization of containers, communication protocol simulation, and autonomous generation of control logic. The scalability of our approach depends on the efficiency of container management, communication protocol emulation, and algorithms employed for abductive inference and HMM learning.
5. Conclusions
6. Discussion and Future Work
6.1. Limitations
- Lack of real-world control logic: The inability to access the actual control logic from the PLCs in datasets like SWaT or HAI poses a significant challenge. Our abductive inference method relies on correlations between input and output signals, and although effective, it may not capture the intricate details of the original control logic. Future research could explore methods to directly obtain or approximate the control logic to improve the fidelity of the simulated environment.
- Assumed linearity in control logic inference: Our current approach employs simple linear regression for control logic inference, assuming a linear relationship between input and output signals. This assumption may not hold in all scenarios, particularly when dealing with complex control systems. Future work could investigate more sophisticated machine learning models to capture nonlinear relationships and enhance the accuracy of control logic replication.
- Stochastic setpoint generation complexity: While our stochastic setpoint generation using hidden Markov models (HMMs) is effective, the chosen model might oversimplify the complexity of real-world systems. Future research could explore alternative probabilistic modeling approaches, such as Bayesian networks or recurrent neural networks, to better capture the dynamic nature of setpoints in ICS environments.
- Limited validation metrics: Our evaluation of the simulated ICS environment primarily relies on qualitative comparisons and synthetic dataset generation. Introducing quantitative metrics and validation methodologies, such as comparing statistical properties of the simulated and real datasets, would strengthen the reliability of our simulation architecture.
6.2. Future Research Directions
- Enhanced control logic inference: Investigate methods to enhance the fidelity of control logic inference, potentially exploring machine learning techniques that can generalize complex relationships from limited data. Access to more comprehensive datasets with detailed control logic information would be invaluable for improving the accuracy of control logic replication.
- Advanced probabilistic setpoint modeling: Explore advanced probabilistic modeling techniques beyond HMMs for setpoint generation. Bayesian methods or deep learning approaches could offer more nuanced representations of the temporal characteristics of ICS setpoints, allowing for a more realistic simulation.
- Dynamic adjustment of simulation parameters: Develop mechanisms for dynamically adjusting simulation parameters based on the evolving nature of ICS environments. Incorporating adaptive learning algorithms could enable the simulation architecture to continuously improve its accuracy and adapt to changes in control logic or setpoint patterns.
- Security and anomaly injection: Integrate security-related features into the simulation architecture, allowing researchers and practitioners to test the resilience of ICS systems against cyberthreats. Additionally, explore methods to inject realistic anomalies into the simulated environment to evaluate the robustness of detection mechanisms.
- Collaborative simulation frameworks: Investigate the development of collaborative simulation frameworks that allow multiple entities to contribute to the creation and improvement of simulated ICS environments. This collaborative approach could lead to more diverse and representative datasets, benefiting the entire research community.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ICS | Industrial control system |
| SCADA | Supervisory control and data acquisition |
| DCS | Distributed control system |
| PLC | Programmable logic controller |
| HMI | Human–machine interface |
| GAN | Generative adversarial network |
| VAE | Variational autoencoder |
| PAR | Periodic autoregressive |
| PMU | Phasor measurement unit |
| HMM | Hidden Markov model |
| BGAN | Boundary-seeking GAN |
| ST | Structured text |
| LSM | Least square method |
| AR | Autoregressive |
| MA | Moving average |
| ARIMA | Autoregressive integrated moving average |
References
- Subramanian, D.; Murali, P.; Zhou, N.; Ma, X.; Da Silva, G.C.; Pavuluri, R.; Kalagnanam, J. A prediction-optimization framework for site-wide process optimization. In Proceedings of the 2019 IEEE International Congress on Internet of Things, ICIOT 2019—Part of the 2019 IEEE World Congress on Services, Milan, Italy, 8–13 July 2019. [Google Scholar] [CrossRef]
- Min, Q.; Lu, Y.; Liu, Z.; Su, C.; Wang, B. Machine Learning based Digital Twin Framework for Production Optimization in Petrochemical Industry. Int. J. Inf. Manag. 2019, 49, 502–519. [Google Scholar] [CrossRef]
- Mathur, A.P.; Tippenhauer, N.O. SWaT: A water treatment testbed for research and training on ICS security. In Proceedings of the 2016 International Workshop on Cyber-Physical Systems for Smart Water Networks, CySWater 2016, Vienna, Austria, 11 April 2016. [Google Scholar] [CrossRef]
- Shin, H.K.; Lee, W.; Yun, J.H.; Kim, H.C. HAI 1.0: HIL-based augmented ICS security dataset. In Proceedings of the CSET 2020—13th USENIX Workshop on Cyber Security Experimentation and Test, Co-Located with USENIX Security 2020, Virtual, 10 August 2020. [Google Scholar]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 1–22. [Google Scholar] [CrossRef]
- Craggs, B.; Rashid, A.; Hankin, C.; Antrobus, R.; Serban, O.; Thapen, N. A reference architecture for IIoT and industrial control systems testbeds. In Proceedings of the IET Conference Publications 2019, London, UK, 1–2 May 2019. [Google Scholar] [CrossRef]
- Ayodeji, A.; Liu, Y.K.; Chao, N.; Yang, L.Q. A new perspective towards the development of robust data-driven intrusion detection for industrial control systems. Nucl. Eng. Technol. 2020, 52, 2687–2698. [Google Scholar] [CrossRef]
- Ling, J.; Zhu, Z.; Luo, Y.; Wang, H. An intrusion detection method for industrial control systems based on bidirectional simple recurrent unit. Comput. Electr. Eng. 2021, 91, 107049. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014—Conference Track Proceedings, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Beaver, J.M.; Borges-Hink, R.C.; Buckner, M.A. An evaluation of machine learning methods to detect malicious SCADA communications. In Proceedings of the 2013 12th International Conference on Machine Learning and Applications, ICMLA, Miami, FL, USA, 4–7 December 2013; Volume 2. [Google Scholar] [CrossRef]
- Tommy, M. Industrial Control System (ICS) Cyber Attack Datasets. Available online: https://sites.google.com/a/uah.edu/tommy-morris-uah/ics-data-sets (accessed on 20 January 2023).
- Morris, T.; Gao, W. Industrial control system traffic data sets for intrusion detection research. IFIP Advances in Information and Communication Technology 2014, 441, 65–78. [Google Scholar]
- Morris, T.H.; Thornton, Z.; Turnipseed, I. Industrial Control System Simulation and Data Logging for Intrusion Detection System Research. In Proceedings of the Seventh Annual Southeastern Cyber Security Summit, Huntsville, AL, USA, 3–4 June 2015. [Google Scholar]
- Tushar, W.; Huang, S.; Yuen, C.; Zhang, J.A.; Smith, D.B. Synthetic generation of solar States for smart grid: A multiple segment Markov chain approach. In Proceedings of the IEEE PES Innovative Smart Grid Technologies Conference Europe, Istanbul, Turkey, 12–15 October 2014. [Google Scholar] [CrossRef]
- Iftikhar, N.; Liu, X.; Nordbjerg, F.E.; Danalachi, S. A Prediction-Based Smart Meter Data Generator. In Proceedings of the NBiS 2016—19th International Conference on Network-Based Information Systems, Ostrava, Czech Republic, 7–9 September 2016. [Google Scholar] [CrossRef]
- Iftikhar, N.; Liu, X.; Danalachi, S.; Nordbjerg, F.E.; Vollesen, J.H. A Scalable Smart Meter Data Generator Using Spark. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2017; p. 10573. [Google Scholar]
- Zhang, C.; Kuppannagari, S.R.; Kannan, R.; Prasanna, V.K. Generative Adversarial Network for Synthetic Time Series Data Generation in Smart Grids. In Proceedings of the 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids, SmartGridComm, Aalborg, Denmark, 29–31 October 2018. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, B.; Xie, L. Synthetic dynamic PMU data generation: A generative adversarial network approach. In Proceedings of the 2019 International Conference on Smart Grid Synchronized Measurements and Analytics, SGSMA, College Station, TX, USA, 21–23 May 2019. [Google Scholar] [CrossRef]
- Razghandi, M.; Zhou, H.; Erol-Kantarci, M.; Turgut, D. Variational Autoencoder Generative Adversarial Network for Synthetic Data Generation in Smart Home. arXiv 2022, arXiv:2201.07387v1. [Google Scholar]
- Esteban, C.; Hyl, S.L.; Rätsch, G. Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs. arXiv 2017, arXiv:1706.02633v2. [Google Scholar]
- Dahmen, J.; Cook, D. SynSys: A synthetic data generation system for healthcare applications. Sensors 2019, 19, 1181. [Google Scholar] [CrossRef] [PubMed]
- Imtiaz, S.; Arsalan, M.; Vlassov, V.; Sadre, R. Synthetic and Private Smart Health Care Data Generation using GANs. In Proceedings of the International Conference on Computer Communications and Networks, ICCCN, Virtual, 19–22 July 2021. [Google Scholar] [CrossRef]
- Berndt, D.J.; Clifford, J. Using dynamic time warping to find patterns in time series. In Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 31 July–1 August 1994. [Google Scholar]
- Docker, Inc. Available online: https://www.docker.com/ (accessed on 8 March 2023).
- Alves, T.; Morris, T. OpenPLC: An IEC 61,131–3 compliant open-source industrial controller for cyber security research. Comput. Secur. 2018, 78, 364–379. [Google Scholar] [CrossRef]
- SCADA-BR. Available online: https://www.scadabr.com.br/ (accessed on 8 March 2023).
- Arduino. Available online: https://www.arduino.cc/ (accessed on 9 March 2023).
- Raspberry Pi. Available online: https://www.raspberrypi.com/ (accessed on 9 March 2023).

{kind=link}
{kind=link}
{kind=link}
| P1-CC (P1_PP04SP) | P1-CC (P1_PP04) | P1-FC (P1_B3005) | P1-FC (P1_FCV03D) | P1-TC (P1_B4022) | P1-TC (P1_FCV01D) | P2-SC (P2_AutoSD) | P2-SC (P2_SCO) | P1-PC (P1_B2016) | P1-PC (P1_PCV01D) | |
|---|---|---|---|---|---|---|---|---|---|---|
| Original mean | 27.418 | 29.4 | 993.211 | 49.044 | 30.971 | 18.872 | 113.989 | 54,747.254 | 1.109 | 30.723 |
| Predicted mean | 27.528 | 24.058 | 1010.991 | 49.043 | 30.951 | 18.874 | 118.053 | 54,747.22 | 1.111 | 472.913 |
| Original variance | 0.061 | 103.586 | 912.649 | 2.143 | 0.435 | 246.328 | 116.114 | 3216.688 | 0.013 | 11.322 |
| Predicted variance | 0.08 | 4.018 | 440.815 | 1.34 | 0.446 | 229.671 | 94.342 | 3215.406 | 0.011 | 107.278 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Jeon, S.; Cho, J.; Gong, S. Data-Driven ICS Network Simulation for Synthetic Data Generation. Electronics 2024, 13, 1920. https://doi.org/10.3390/electronics13101920
Kim M, Jeon S, Cho J, Gong S. Data-Driven ICS Network Simulation for Synthetic Data Generation. Electronics. 2024; 13(10):1920. https://doi.org/10.3390/electronics13101920
Chicago/Turabian StyleKim, Minseo, Seungho Jeon, Jake Cho, and Seonghyeon Gong. 2024. "Data-Driven ICS Network Simulation for Synthetic Data Generation" Electronics 13, no. 10: 1920. https://doi.org/10.3390/electronics13101920
APA StyleKim, M., Jeon, S., Cho, J., & Gong, S. (2024). Data-Driven ICS Network Simulation for Synthetic Data Generation. Electronics, 13(10), 1920. https://doi.org/10.3390/electronics13101920