Abstract
A considerable number of texts encountered daily are somehow connected. For example, Wikipedia articles refer to other articles via hyperlinks, or scientific papers relate to others via citations or (co)authors; tweets relate via users that follow each other or reshare content. Hence, a graph-like structure can represent existing connections and be seen as capturing the “context” of the texts. The question thus arises of whether extracting and integrating such context information into a language model might help facilitate a better-automated understanding of the text. In this study, we experimentally demonstrate that incorporating graph-based contextualization into the BERT model enhances its performance on an example of a classification task. Specifically, in the Pubmed dataset, we observed a reduction in balanced mean error from 8.51% to 7.96%, while increasing the number of parameters just by 1.6%.
1. Introduction
The abundance of texts and data on the Internet makes it challenging for individuals to navigate and understand the information. From social media platforms, such as Twitter, LinkedIn, and Facebook, to scientific papers, the quality and usefulness of existing texts can vary extensively. Therefore, an automatic tool is needed to process and utilize this vast amount of information effectively to reduce information overload and select the most relevant information for the user.
One possible application of such a tool could be effective text classification, which could deliver better text recommendations, hate speech, and/or misinformation detection. For example, the authors of [1] show that Twitter haters tend to interact intensely with each other, forming a clustered network. This finding also highlights the importance of analyzing the graph context of social media posts when processing them.
Also, authors in scientific research often refer to other articles to build upon existing knowledge and compare their work to the state-of-the-art. These references can be captured and aggregated, for instance, through a graph neural network, to provide more context to a language model in natural language processing (NLP) tasks. Websites such as Wikipedia, where articles refer to each other, can likewise benefit from similar contextualization of knowledge. A language model can be trained to include the context of a given article for text classification tasks. Thus, incorporating graph-represented context information into language models can enhance understanding processed texts. This, in turn, can result in more accurate and efficient models.
In this context, this research aims to enhance a deep learning language model by incorporating graph-represented information. Such information captures existing links between documents and is referred to as a graph context. Graph context becomes one of the inputs into a deep learning model, consisting of two components: the GNN (graph neural network) and the LM (language model). As a result, after exploring various ways of connecting these two basic components, we also introduced a new deep learning model named GCBERT (graph context BERT). GCBERT slightly outperforms the BERT model in the text classification task on the Pubmed dataset (our source code and details concerning tuning and setting hyperparameters and seeds are available online on github.com/tryptofanik/gc-bert, accessed on 9 May 2024).
The remaining parts of this paper are organized as follows. Section 2 highlights related work. Section 3 describes the proposed approach and the datasets used in experiments. In Section 4, experimental results are presented and analyzed. Future research directions, including the potential for graph-based networks, are discussed in the last sections, i.e., Limitations Section 5 and Concluding Remarks Section 6.
2. Related Work
To date, several works have explored different ways of combining graph neural networks with language models, such as BERT (Bidirectional Encoder Representations from Transformers) [2]. The following section will discuss how GNN and transformer models have been used to solve various natural language processing (NLP) tasks.
In [3], the BERT-GCN architecture is proposed to recommend context-aware paper citations. The BERT model’s input is a text that includes [REF] tokens, which are used to inform the model where the reference is needed. BERT creates a vector representation of the document to which the user seeks references. In parallel, the citation graph representation is created using a Variational Graph AutoEncoder with a set of papers from a selected domain and their reference network. Both representations are concatenated and processed by a feed-forward neural network (FF-NN), which produces a softmax output indicating the citation label. This model aggregates the entire graph into one vector for FF-NN and does not utilize graph information within the BERT model.
In [4], BERT is combined with metadata and graph-based author data with the goal of text classification. The authors use the PyTorch BigGraph embeddings [5] to create authors’ representations concatenated with metadata and fed to an FF-NN to make predictions. Within this architecture, the language model also lacks awareness of contextual data in the analyzed document.
In contrast to the parallel deep learning architectures that analyze the data independently, compositional models have been proposed. Here, datum x is taken by the model f, and the output is consumed by the model g, which can be written as . The benefit of this solution—pipeline of models—is that it can inject what was learned and noticed by one model into the other in the pipeline. Among these approaches, BertGCN [6] is a straightforward implementation of the composition of BERT and GCN (graph convolutional networks). It extracts text-based representations from each document using BERT, which is then used as input in the GCN. The heterogeneous graph structure, constructed similarly as in the TextGCN study [7], utilizes documents as nodes and additional nodes were created based on words and their concurrence in the documents. However, BertGCN considers no interconnections between texts other than semantic meaning. Separately, authors of [8] combined GCN and BERT, using a gating mechanism, to create a compositional model. A heterogeneous text graph is created and then processed by GCN to produce a set of hidden states of documents. In parallel, BERT embeddings are derived and combined with the hidden states using the gating mechanism. The result is then processed by another GCN network, allowing predictions to be retrieved from tokens representing particular documents.
The short-text graph convolutional network [9] is another model used for text classification. Documents are connected with words they contain and topics they refer to. GCN then processes the graph, whereas each node representation is calculated for triples consisting of documents, topics, and words. BERT produces abstracted and contextualized tokens for each word in a document. These tokens are then concatenated with GCN-derived word node representations and used as input for a Bi-LSTM (Bidirectional Long Short-Term Memory) network. The final output category of the document is produced by combining the document representation and the LSTM vector.
Another approach is based on knowledge graphs (KG), which represent real-world entities and their relationships as a graph structure. Nodes in the graph correspond to entities, whereas edges correspond to the relationships between them. KG-BERT (knowledge graph BERT), introduced in [10], is a model that utilizes BERT to inject entities and relationships into the language model. Entities and relationships are represented as vectors and fed into the BERT model, with separation tokens applied to distinguish them. Unlike other graph-based models, KG-BERT does not utilize GNNs; instead, it relies on the language model to understand the language and graph relationships. KG-BERT has been applied as a tool for knowledge graph completion.
An alternative approach to integrating knowledge graph information into a language model in a context-aware manner is presented in [11]. The JAKET architecture consists of a knowledge module that produces entity embeddings corresponding to concepts in KG and a language module that analyzes a text. The knowledge module uses a graph attention network to embed entities, whereas the language module comprises two language models, LM1 and LM2. LM1 is shared and operates on pure text data, providing embeddings for LM2. The knowledge graph embeddings are integrated with LM1’s in LM2, allowing access to textual and contextual knowledge graph information. The prediction phase utilizes the output of LM2. JAKET provides semantic context, using knowledge graph-stored word embeddings. Compared to models created in our study (like GC-BERT), JAKET does not utilize graph information additional to the given text, e.g., relations between texts given by authorships or retweets.
Another somehow related approach, introduced in [12], combines knowledge derived from the text in two ways: (1) universal syntactic knowledge, i.e., sentence parse trees, represented in KERMIT, and (2) knowledge derived totally from experience (based on a given dataset) embedded in BERT. The authors showed that this information combination, even though derived from the same and only text, provided slightly better overall results on several GLUE benchmark datasets [13].
The study presented in [14] addresses the authorship verification problem using a combination of a language model and a graph neural network called LG4AV. The approach calculates a vector representation for each author based on their article embeddings, which is then treated as a classification token ([CLS-a]) in the BERT language model. The BERT processes the document and produces the updated classification token (LM(d)), whereas the GNN computes the author vectors updated by the “neighbours”. The final prediction is obtained by aggregating the vectors multiplied by the LM(d). LG4AV integrates graph context into the architecture design, improving judgment for authorship verification. However, its limitations are that only the language model is trainable, whereas graph representations are static. Additionally, this architecture design enforces the concrete structure of the data, in which documents must be authored by a group of people. (These constraints of the model will be addressed in the current work).
To date, many researchers have worked on linking NLP models with semantics constructed as knowledge graphs that express mapping, organizing, and relating ideas, entities, and concepts expressed in natural language [15]. However, texts do not have to be connected just because they are related semantically. It is enough that they were created by the same user or share a common hashtag on the social media platform. It is hypothesized that some additional predictive information might be available in other related texts, and this could improve “prediction” results. The NLP community has not thoroughly researched this aspect of the text analysis. In the literature, semantics in NLP models are limited primarily to understanding language and its nuances. Current research does not cover additional information hidden in how the texts are organized and related within real-world systems. We have noted that a limited number of studies in the literature currently analyze the network of documents in a way that leverages rich and diversified graph context information. Furthermore, the existing architectures either cannot train simultaneously text and graph representations; each time the model is trained, only one representation is trained. Thus, neither representation is fully dynamic throughout the training process.
3. Proposed Approach
Our work goes beyond the classical semantic enhancement of the language models. It seeks more predictive power in understanding how texts relate to each other, which can be given by additional structural information in addition to the text semantics. The architectures developed in this work aim to be flexible enough for various scenarios where texts have relevant, meaningful, and logical connections and could be used for both graph- and text-based downstream tasks.
More formally, this study works on datasets with the following properties: (1) a set of n documents , (2) a set of direct or indirect connections between documents, represented as a set of edges . The input must be a graph of interconnected documents. Noteworthy, the graph information should add some new information to the documents and thus have the potential to improve the final prediction results. Further, in our notation, an adjacency matrix A provides information about edges (i.e., interconnections between documents), such that , if document i relates to document j.
This work is devoted to developing a deep learning architecture that simultaneously consumes graph and text information and can train text and graph context representations. It is also possible to utilize our architectures while only accessing static representations of texts or nodes. In that case, these representations are constant throughout the experiment and can not be changed during training. This can be achieved by using some deterministic function to obtain these representations like TF-IDF (term frequency-inverse document frequency) [16] or by freezing weights of a deep learning model during the training.
3.1. GNN + LM Architectures
The basic building blocks used for this study are the graph convolutional network (GCN) [17] and the encoder of the BERT model [2] (uncased, based version with 110 M parameters: https://huggingface.co/bert-base-uncased, accessed on 9 May 2024).
It was chosen due to its simplicity compared to different LMs and extensive usage in other studies. However, any other language model could be chosen for this task, as the only thing required is to encode the text into a representation vector. Furthermore, any other GNN architecture can be utilized instead of GCN; the only requirement is that it should take as an input vector the representation of nodes and an adjacency matrix.
As part of the performed research, we experimented with four ways to connect a language model and a graph neural network: late fusion, early fusion–GCBERT, compositional architecture GNN(BERT), and looped GCBERT.
The processed text and node representations calculated by the LM and GNN are stored in matrices T (text representation) and N (node representation), respectively, and information about interconnections between nodes is in the A adjacency matrix. The initialization of the T and N matrices is necessary for the LM + GNN model training. The T matrix is initialized using the pretrained BERT model, whereas the N matrix is filled with the GNN model, which utilizes different transformations depending on the following architectures and their training algorithms.
In all GNN + LM experiments, the total model size is 111.84 M parameters (110.07 M BERT + 1.77 M GCN).
3.1.1. Late Fusion
A parallel late fusion architecture is the most basic combination of GNN and BERT (see Figure 1). Here, BERT receives pure text and creates textual representation vectors. In parallel, each document (input text) is vectorized. It can be conducted using TF-IDF or reusing representations created by BERT (in our experiments, we reused BERT representations). The vectorized texts and the graph data are sent to the GNN model, producing a node representation of each text. Next, node and text representations are merged and processed by a classifier (see Figure 1 and Algorithm 1).
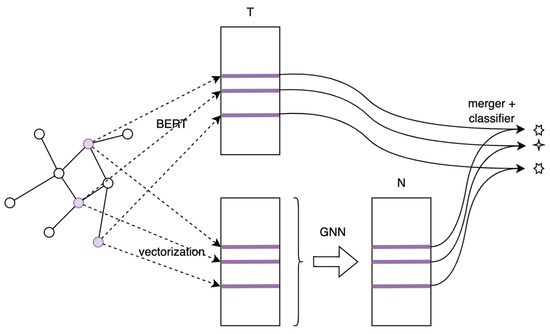
Figure 1.
Late fusion architecture. Note: nodes in the graph are text documents to classify, edges are interconnections between documents (e.g., citations), other notations are given in Algorithm 1, and the outputs are predictions of three classes. Apart from vectorized texts, GNN also consumes the adjacency matrix A, which was not shown in the figure for clarity and simplicity.
In this architecture, each model (GNN and LM) works on the data type it was designed for. However, they do not have a direct opportunity to “strengthen each other”. One model cannot utilize the information contained in the input of the other. Here, BERT analyzes the text to extract semantics and context but cannot access the graph context. In contrast, GNN works on textual and graphical data, but the text data are limited as it is compressed into a single vector. The classifier is the first module that considers both sources of information. As it turns out, it might not have enough flexibility to extract and capture the information hidden in the merged input.
| Algorithm 1 Late fusion algorithm. D—set of documents, T—text representations, A—adjacency matrix, N—node representations, E—number of epochs, I—iterator over training set, i—batch indices |
|
3.1.2. Early Fusion–GCBERT
The second architecture is early fusion, where texts are vectorized into static vectors (via TF-IDF or finetuned and then frozen BERT) processed by GNN, which creates node representations. They are then inserted into the input token sequence of the text and processed by trainable BERT, which produces the text representations. Next, a classifier uses those to make a prediction—see Figure 2 and Algorithm 2. In this scenario, GNN still has access only to the graph and static textual data, whereas BERT is now fed directly with textual and graphical information. It is worth emphasizing that backpropagation will flow from BERT to GNN and can enforce some adjustments in the GNN model. To highlight the fact that BERT is also analyzing the graph context of each of the documents, it is now referred to as GCBERT (Graph Context BERT).
| Algorithm 2 Early fusion GCBERT algorithm. D—set of documents, T—text representations, A—adjacency matrix, N—node representations, E—number of epochs, I—iterator over training set, i—batch indices, GCBERT—BERT that consumes graph context data |
|
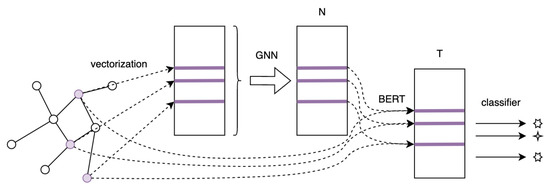
Figure 2.
Early fusion—GCBERT architecture. (Notation is the same as in Figure 1).
3.1.3. Compositional Architecture–GNN(BERT)
The third architecture is compositional architecture GNN(BERT), where BERT processes the pure text data to create text representations, which GNN then consumes to produce node representations for classification—see Figure 3 and Algorithm 3. In this scenario, GNN is supplied with dynamic BERT textual representation that should contain more information than vectors obtained via TF-IDF or static, precalculated BERT vectors. However, the transformer does not have direct access to the information about the graph context of the processed document. Similarly, as in the previous architecture—GCBERT, it is worth emphasizing that in this architecture, the backpropagation will flow from GNN to BERT and can enforce some adjustments in the BERT model.
| Algorithm 3 Compositional architecture GNN(BERT) algorithm. D—set of documents, T—text representations, A—adjacency matrix, N—node representations, E—number of epochs, I—iterator over training set, i—batch indices |
|
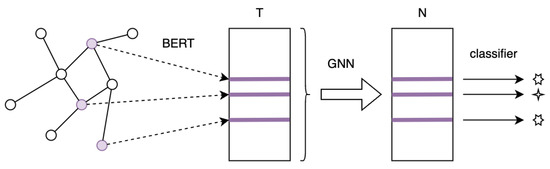
Figure 3.
Compositional architecture GNN(BERT). (Notation is the same as in Figure 1).
3.1.4. Looped GCBERT
The fourth architecture is looped GCBERT, which combines early fusion and compositional architecture. BERT receives textual data and the latest node context vector and produces the graph-augmented text representation. It is then processed by GNN, which produces updated node representations then used for classification—see Figure 4 and Algorithm 4. During each epoch of training, the text representation of a document is produced based on the node representation from the previous epoch, allowing both components to interchange what they have learned directly. This model combines early fusion and compositional architecture in which the whole architecture works on dynamic (trainable) text and node representations. This means that GNN and BERT must be unfrozen in this architectural choice.
| Algorithm 4 Looped GCBERT architecture algorithm. D—set of documents, T—text representations, A—adjacency matrix, N—node representations, E—number of epochs, I—iterator over training set, i—batch indices |
|
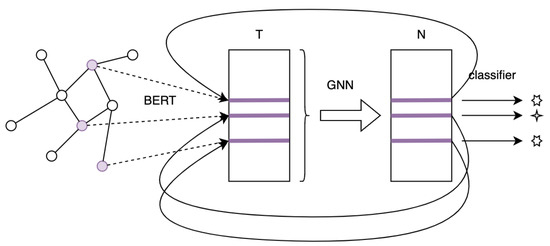
Figure 4.
Looped GCBERT with BERT vectorization. (Notation is the same as in Figure 1).
3.1.5. Architectural Modifications
The modifications that can be applied to our models include the following:
- Skip connections: Transferring node representation N or text representation T into the classifier (the last element of all the architectures) to prevent information loss and allow later modules to analyze all the available representations. Before the classifier, both the representations should be merged with a merger function (as it is in a basic late fusion algorithm). In this case, the merger has both representations at its disposal, regardless of whether one was created using the other.
- Freezing/Unfreezing: Models can be frozen to obtain static representations or unfrozen to obtain dynamic representations, which can potentially improve performance but are more challenging to train. In our experiments, we mostly unfroze representations so that the models GNN or BERT are trainable throughout the training process. Otherwise, if we freeze them, we also state it clearly in the description of a particular test.
- Merger function: the merging of and vectors before classifier (as it is in a basic late fusion algorithm) can be concatenated, added in an element-wise manner, or combined using other functions like max, to preserve information and reduce parameters.
3.1.6. Language Model Augmentation with Graph Context Token
The standard BERT architecture takes as input a sequence of tokens, each of which can represent words, subwords, or special signs like ‘?’, ‘-’, etc. BERT uses special tokens, such as the classification token [CLS], as a document embedding after the final BERT layer. Each token is represented by a vector in space, and a positional embedding is added to each vector to convey information about the token’s order in the sequence [2].
The way we insert a graph context token into the language model is essential for its proper utilization and for boosting its performance. In this study, when the BERT architecture is augmented with the output of GNN, it is carried out by adding a new token—the graph context token [GC], which delivers information about the graph context of the document to the BERT. The [GC] token is placed as the second token in the sequence, following the [CLS] token and preceding the first-word token. It comprises two elements: (1) the document node representation and (2) the positional embedding. The sequence of tokens is then normalized. (We also tested other ways of adding GNN output to the BERT; however, the results were much worse.)
3.2. Dataset Selection
This work focused on solving NLP classification tasks for text documents with interconnections with other documents forming a graph. These connections might be derived from the information about citations, hyperlink references, or authorship.
More formally, this study can potentially utilize datasets with the following properties: (1) a set of n documents , (2) a set of (direct or indirect) connections between documents, represented as a set of edges . The input must be a graph of interconnected texts. Notably, the graph information should add new information to the texts, with a piece of additional information to the texts, and thus has the potential to improve the results.
We chose the Pubmed dataset [18], containing 19,717 scientific articles from the Pubmed database, classified into three diabetes-related topics (https://paperswithcode.com/dataset/pubmed, accessed on 9 May 2024). The dataset forms a graph of abstracts linked through citations.
Citation information was obtained from the Pubmed API along with other metadata. An alternative connection method could be through co-authors or shared tags. The articles form a connected, directed, and unweighted graph, with no assigned weights to the citations as they are represented as binary (existing or not) information. A richer representation of citations (calculated by the number of times a given study was referred to in the text) would require access to the full text, which is not provided directly in the Pubmed dataset.
We found several other interesting datasets that fit into our design; however, due to problems with data accessibility or integrity, it was not possible to use them. For example, in [1], the authors created a curated and manually labeled dataset containing Twitter data (tweets, users, and their various connections) to investigate hateful user detection. Unfortunately, publicly available data contained preprocessed text without original tweets. Another example of a dataset that could have been used is a DBpedia dataset [19]. It consists of various articles fetched from Wikipedia, each belonging to one of 14 classes, like company, person, etc. However, the original dataset lacked information about hyperlinks between the articles, and it was impossible to obtain this information from the Wikipedia dump.
3.3. Experimental Setup
Due to the limited number of documents in the Pubmed dataset, overfitting can occur with the BERT architecture. To mitigate this, the training procedure uses smaller batches of 32 documents per epoch, and the final hidden state of the [CLS] classification token is saved to T matrix for each batch. Backpropagation is performed based on the predictions of the documents from each batch. The Adam optimizer [20] was used for all training in this study.
The documents are split into three sets: 70% for training, 10% for validation, and 20% for testing. The validation set is used to monitor when the model starts to overfit. The best-performing version is evaluated on the test set. To ensure unbiased evaluation, we independently split our dataset 10 times into train, validation, and test sets using 10 different seed values. Each variant of the models was trained and evaluated on these 10 splits, and the presented results are averaged.
Due to a slight class imbalance in the Pubmed dataset, balanced error and macro -score are used as the main evaluation metrics. The balanced error is calculated as 100% minus balanced accuracy, which is the average accuracy of each class, whereas the macro -score is calculated for each class separately and then averaged over all classes.
4. Experimental Results and Analysis
In this work, we evaluated GNN + LM models on the Pubmed dataset on the classification task. Before that, basic building blocks (BERT and GNN) were benchmarked independently to establish their default performance on the task.
We experimented with two benchmark GNNs: graph attention network (GAT) [21] and graph convolutional network (GCN) [17]. When trained alone, these models took a feature matrix (n observations, each of which have a dimensionality of m) and an adjacency matrix as inputs, where the feature matrix consists of vectorized text representations using TF-IDF. Further experiments were performed with a pre-trained BERT encoder that was fine-tuned on the Pubmed dataset. However, no significant improvements in results have been observed. Therefore, only results obtained using TF-IDF vectorization are reported in Table 1.

Table 1.
Classification results of all the proposed architectures and their modifications on the Pubmed dataset. Each experiment is repeated 10 times with different dataset splits. Both metrics, error and F1, are balanced, meaning all classes are treated equally and averaged through 10 data splits. (Note: (concat/add)—is a strategy for merging representation before a classifier; “skip conn” means that the experiment utilizes a modification of skipping connections. For metrics, (↓)—means that the lower the metric is the better, and (↑)—otherwise, the higher the better).
Based on these tests, we can infer that despite supplying GNNs with feature vectors calculated by BERT, they can still not outperform the transformer model despite having access to additional graph information. There are two potential explanations for this observation: either (1) there is no new discriminative information in the graph that is not already present in the text, or (2) GNNs lose or dilute information from the strong feature vectors produced by BERT when incorporating data from the neighboring nodes.
BERT architecture alone achieved an average error rate of 8.51% on the Pubmed test set, significantly lower than all sole GNN models. However, BERT models have more parameters, making them more flexible than GNNs. Furthermore, in our experiments, the text features extracted for GNNs are based solely on word occurrences, whereas BERT considers the entire semantic context in the text.
Our evaluation results show that the GNNs achieve diversified performances, with error rates ranging from 22.7% using GAT to 14.39% using GCN (see Table 1 and Figure 5).
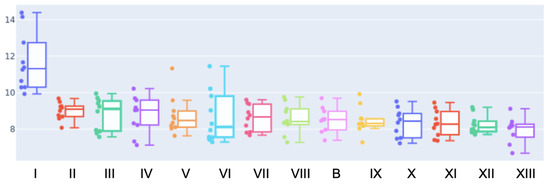
Figure 5.
Variability of errors in our experiments. Results for each (LM + GNN) architecture configuration (depicted in Table 1, column No) were repeated 10 times with different dataset splits.
Table 1 shows that the compositional architecture underperforms, with a balanced error rate of 11.67%. Although it improves the performance of all GNN models, it loses some information learned by BERT, resulting in BERT alone performing better. One possible explanation for this behavior is that although BERT produces high-quality text representations compared to TF-IDF, GNN is not deep and flexible enough, compared to a dense network, to capture all the information in the input. Moreover, connections between irrelevant documents might lead to confusion in the network. Therefore, skip connections were added in later experiments, or the GNN was moved to an earlier pipeline stage to overcome this problem.
For late fusion architecture, an 8.33% error rate on the Pubmed test set by concatenating the text and graph representations and 8.62% by adding them in an element-wise manner is reported. Notably, one of these architectures slightly outperforms the “plain BERT” architecture. This was expected, as the model that leverages data from two independent sources should outperform the individual basic models.
The early fusion GCBERT architecture, in which GNN is executed before BERT, has variable performance, depending on the modifications used. The basic GCBERT architecture (without any modifications) achieved results comparable to BERT alone, with an error rate of 8.57%. However, the addition of skip connections in this architecture can cause the results to be worse. In the case of the concatenation merging strategy, the error rate rose to 8.82%, and in the additional merging strategy, it rose to 8.76%. Interestingly, operating on static node representations by finetuning and then freezing the GNN seems to boost the architecture’s performance, with a resulting error rate of 8.34%. Additionally, by adding a skip connection with concatenation as a merging strategy, the model reaches a 7.97%.
The cause of the unsatisfactory performance of vanilla GCBERT might result from a new graph token inserted into the input sequence of BERT. To assess how this insertion affects the behavior of the model, an experiment in which BERT was supplied with random vectors generated from Gaussian distribution was conducted. It turns out that the model loses 0.3% of the accuracy.
Till now, neither architecture allowed an exchange of learned information between components. The looped GCBERT architecture addresses this issue by connecting GNN and BERT into one model, components of which can interact with each other. In looped GCBERT, both representations are always dynamic, allowing the network to improve and adjust to new data constantly. The model reaches 9% of the error rate. It significantly improved the compositional architecture, which lacked BERT augmentation.
However, it is still not enough to outperform basic BERT. The introduction of skip connection with concatenation merge strategy recovers the performance to the level comparable with BERT (8.49% of error rate), whereas the one with additive merging strategy outperforms BERT, reaching 8.26% of the error rate.
In the end, the best architecture tested is the early fusion GCBERT with a frozen GNN (Each time we denoted that GNN is frozen, we trained GNN on our task (adding a classifier for that purpose). Then, the GNN was frozen and reused in GCBERT architecture to train the BERT.), and then a skip connection was added at the end of the pipeline. It outperforms the baseline by 0.54 percentage points.
Summarizing our experiments, we tried to improve the performance of the BERT model, which has an 8.51% error rate. We utilized different modifications and combinations of BERT and GCN architectures to improve the results. The sole GCN model is much weaker than BERT, having almost twice the higher error rate (14.39%). However, the final results showed it is worth supporting a strong BERT model with a weaker and much smaller GCN model to boost its performance by a decent value.
5. Limitations
We highlight many promising results that other researchers can use to further improve the topic. However, the issue still needs to be fully exploited, as there are numerous possible ways of performing even more experiments.
The most crucial limitation of this research is that we experimented only with one dataset and slightly improved the final results (on average). Finding an appropriate dataset was a challenge. We can conclude and indicate that as an essential further research direction for the research community, we need to collect and prepare datasets with diversified data sources of various modalities and structures, including graph interconnections of many different types. With such datasets, even artificial ones, our community might extensively experiment with different architectures and ways of fusing data and research the interpretability and contributions of particular modalities and data structures (also of particular neural network components) to the final dataset task. In further experiments, other tasks should be explored, possibly those in which fine-grained information can have more impact on the final results, e.g., recommendations, topic modeling, information extraction, and machine translation.
Moreover, analyzing our results, one can observe that both the general architecture layouts and the applied modifications have comparable impacts on model performance. Adding a skip connection improves the model, but not in all cases. The type of merging of node and text representations also matters significantly. However, there is no clear pattern of which one is better. Its impact depends on other architectural details. In some cases, freezing node representations also improves the results, which might seem counterintuitive. Thus, our experiments should be further extended with many ablation studies to measure the influence of each architectural decision and other modifications more precisely. Indeed, more tests and experiments should be conducted to find the best architectures to capture and fuse all the relevant information effectively.
6. Concluding Remarks
Integrating data from different modalities (from various sources or of different structures) can potentially increase the performance of a deep learning model; however, it is still a challenge in deep learning research. As we can see from our research, it is not trivial to connect two distinct neural networks that operate on different types of data in such a way as to build a superior architecture compared to its vanilla counterparts. In this study, the goal was to integrate the graph and text data. The neural network was to work on a graph of connected documents instead of a graph of words or topics, as was the case in most studies so far.
This study proposed and tested four possible architectural designs: late fusion, early fusion (GCBERT), compositional GNN(BERT), and looped GCBERT. Moreover, we experimented with several modifications that can significantly improve the performance of the models: (1) skip connections, (2) static or dynamic representations, and (3) ways of merging text and node representations. It has been shown that it can outperform the BERT model by supplying it with frozen GNN vectors and adding a skip connection that allows the classifier to analyze both representations. This architecture turned out to be the best and improved the results of BERT by 7% (relative error). The GCBERT network has only 1.7 M parameters, much less than the sole BERT, which has 110 M parameters. So, adding a negligibly small GNN component into the BERT model can improve its performance by a decent value.
Summing up, we experimented with injecting additional graph-based information into language model architecture. The graph information is separate from the semantics of the texts (it is not the classical ontological context). However, it can state additional relevant information sources for the text’s understanding. Our results show that there is a place to enrich language models. Our approach can be easily extended to exchange network components and other language models. Thus, it is a very convenient framework for further research and studies on fusing graph-based and text data into neural networks.
Author Contributions
Conceptualization, A.R. and M.G.; methodology, A.R. and M.G.; software, A.R.; validation, A.R. and A.W.; formal analysis, A.R. and A.W.; investigation, A.R., M.G. and A.W.; resources, M.G.; data curation, A.R.; writing—original draft preparation, A.R., M.G. and A.W.; writing—review and editing, A.W.; visualization, A.R.; supervision, M.G.; project administration, M.G.; funding acquisition, M.G. and A.W. All authors have read and agreed to the published version of the manuscript.
Funding
The research leading to these results has received funding from weSub and the Smart Growth Operational Program for 2014-2020, Digital Innovations via the National Centre for Research and Development in Poland. Project registration number: POIR.01.01.01-00-0066/22.
Data Availability Statement
All the utilized datasets are open.
Acknowledgments
We are particularly grateful to Marcin Paprzycki for their invaluable remarks at the final stage of our work. This research was carried out with the support of the Laboratory of Bioinformatics and Computational Genomics and the High-Performance Computing Center of the Faculty of Mathematics and Information Science at Warsaw University of Technology. Anna Wróblewska wishes to acknowledge that her contribution to this paper were carried out within the framework of the Smart Growth Operational Program for 2014–2020, Digital Innovations: grant no POIR.01.01.01-00-0066/22 financed by the National Centre for Research and Development and weSub in Poland.
Conflicts of Interest
The authors declare that this study received funding from weSub and NCBR. The funder was not involved in the study design, collection, analysis, interpretation of data, the writing of this article or the decision to submit it for publication.
Abbreviations
The following abbreviations are used in this manuscript:
| MDPI | Multidisciplinary Digital Publishing Institute |
| BERT | Bidirectional Encoder Representations from Transformers, given in [2] |
| GNN | Graph Neural Network |
| GCBERT | Graph Context BERT |
| GNN(BERT) | GNN with the input given by BERT |
| GCN | Graph Convolutional Network |
| GAT | Graph Attention Network, introduced in [21] |
| TF-IDF | Term Frequency-Inverse Document Frequency Representation |
| LM | Language Model |
| CLS | Classification Token |
| NLP | Natural Language Processing |
| GC | Graph Context Token |
| N | Node Representation |
| T | Text Representation |
| LOSS | Loss Function |
| A | Adjacency Matrix |
| LSTM | Long Short-Term Memory Network |
| Bi-LSTM | Bidirectional Long Short-Term Memory Network |
| KG | Knowledge Graph |
| LG4AV | Combinations of language model and a graph neural network introduced in [14] |
| JAKET | A method of integrating knowledge graph information into a language model introduced in [11] |
References
- Horta Ribeiro, M.; Calais, P.; dos Santos, Y.; Almeida, V.; Meira, W., Jr. Characterizing and Detecting Hateful Users on Twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018; Volume 12. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Jeong, C.; Jang, S.; Park, E.; Choi, S. A context-aware citation recommendation model with BERT and graph convolutional networks. Scientometrics 2020, 124, 1907–1922. [Google Scholar] [CrossRef]
- Ostendorff, M.; Bourgonje, P.; Berger, M.; Schneider, J.M.; Rehm, G.; Gipp, B. Enriching BERT with Knowledge Graph Embeddings for Document Classification. In Proceedings of the 15th Conference on Natural Language Processing, KONVENS 2019, Erlangen, Germany, 9–11 October 2019. [Google Scholar]
- Lerer, A.; Wu, L.; Shen, J.; Lacroix, T.; Wehrstedt, L.; Bose, A.; Peysakhovich, A. Pytorch-BigGraph: A Large Scale Graph Embedding System. Proc. Mach. Learn. Syst. 2019, 1, 120–131. [Google Scholar]
- Lin, Y.; Meng, Y.; Sun, X.; Han, Q.; Kuang, K.; Li, J.; Wu, F. BertGCN: Transductive Text Classification by Combining GNN and BERT. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 1456–1462. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. Proc. Aaai Conf. Artif. Intell. 2019, 33, 7370–7377. [Google Scholar] [CrossRef]
- Gao, W.; Huang, H. A gating context-aware text classification model with BERT and graph convolutional networks. J. Intell. Fuzzy Syst. 2021, 40, 4331–4343. [Google Scholar] [CrossRef]
- Ye, Z.; Jiang, G.; Liu, Y.; Li, Z.; Yuan, J. Document and Word Representations Generated by Graph Convolutional Network and BERT for Short Text Classification. In Proceedings of the ECAI; Giacomo, G.D., Catalá, A., Dilkina, B., Milano, M., Barro, S., Bugarín, A., Lang, J., Eds.; IOS Press: Amsterdam, The Netherlands, 2020; Volume 325, pp. 2275–2281. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for Knowledge Graph Completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Yu, D.; Zhu, C.; Yang, Y.; Zeng, M. JAKET: Joint Pre-training of Knowledge Graph and Language Understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 11630–11638. [Google Scholar] [CrossRef]
- Ranaldi, L.; Pucci, G. Knowing Knowledge: Epistemological Study of Knowledge in Transformers. Appl. Sci. 2023, 13, 677. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar] [CrossRef]
- Stubbemann, M.; Stumme, G. LG4AV: Combining Language Models and Graph Neural Networks for Author Verification. In Proceedings of the Advances in Intelligent Data Analysis XX: 20th International Symposium on Intelligent Data Analysis, IDA 2022, Rennes, France, 20–22 April 2022; pp. 315–326. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; D’amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge Graphs. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Wu, H.C.; Luk, R.W.P.; Wong, K.F.; Kwok, K.L. Interpreting TF-IDF Term Weights as Making Relevance Decisions. ACM Trans. Inf. Syst. 2008, 26, 1–37. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR’17, Toulon, France, 24–26 April 2017. [Google Scholar]
- Sen, P.; Namata, G.; Bilgic, M.; Getoor, L.; Gallagher, B.; Eliassi-Rad, T. Collective Classification in Network Data Articles. AI Mag. 2008, 29, 93–106. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In Proceedings of the The Semantic Web; Aberer, K., Choi, K.S., Noy, N., Allemang, D., Lee, K.I., Nixon, L., Golbeck, J., Mika, P., Maynard, D., Mizoguchi, R., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).