In this section, we describe the proposed ETCNLog method in detail. The ETCNLog framework is presented first. After introducing the framework, we suggest a log processing step to convert the raw logs into log sequence vectors. Finally, ECA and a TCN are used to learn log sequence relationships and perform log anomaly detection by modeling.
3.2. Log Processing
Developers can write free-text log messages in the source code, so the raw logs are usually semi-structured. Log parsing is thus the first step of log processing. The constant and variable parts are the two components of the raw logs. For example, the BGL log shown in
Figure 1 is: “- 1136389988 2006.01.04 R35-M0-N0-C:J11-U11 2006-01-04-07.53.08.946438 R35-M0-N0-C:J11-U11 RAS KERNEL INFO total of 5 ddr error (s) detected and corrected over 27362 s”, and can be considered as consisting of the constants “total of <*> ddr error(s) detected and corrected over <*> seconds” and the variables “’5’, ’27362”’. Furthermore, “total of <*> ddr error(s) detected and corrected over <*> seconds” can be represented as a template for all similar log messages.
In short, log parsing is equivalent to reversing log printing and is a common processing step for semi-structured logs. Parsed log templates provide the foundation for log anomaly detection. However, while Drain is currently a better log parsing tool, it does not correctly parse the raw logs. It is challenging to obtain the best results if Drain is utilized directly to build log templates for anomaly detection.
The BGL dataset is our study object, which can more accurately reflect the ETCNLog method’s reliability. After parsing the log data through Drain, 374 different types of BGL log templates are produced, as shown in
Table 1. We can see that some log templates are duplicated. For instance, there are similarities between the two log templates in {E67, E68}, and E67 may contain another one. Similarly, the two log templates in {E69, E70} are similar, and E69 can contain another one. The effectiveness of log anomaly detection will be significantly impacted if these templates are utilized to build log event sequences directly. In this research, we improve the effect of log parsing by adding the step of cleaning the duplicate data of templates.
To improve the accuracy of log parsing, we must conduct a cleaning operation. First, we select a few representative log entries that match each log template and check if they are duplicates. According to the occurrences of log templates, if they are duplicated, they are combined into the log template that appears the most frequently. The outcomes of cleaning log templates in
Table 1 are displayed in
Table 2.
The second step of log processing is feature extraction. We use the Word2Vec [
19] to convert log templates into semantic vectors. The mapping function preserves the semantic similarity of the template and projects it into a 300-dimensional vector. We further decrease these semantic vectors using PPA [
26] to provide more compact and effective feature representations. PPA is a dimensionality reduction technique combined with principal component analysis (PCA) to further construct efficient word embeddings. Additional features are embedded from the zero space of principal component analysis but provide more concise feature representations. The algorithm is divided into two steps. The first step reduces the dimensionality of the semantic vector by PCA. The second step removes the mean vector and dominating directions from the PCA space by reprocessing the processed vectors by PPA. The hyperparameter d, set by default to 7 by following the implementation in [
26], determines the number of removed feature directions.
An illustration of the log template vectorization procedure is shown in
Figure 3. We use Word2Vec and PCA-PPA to extract features to create a more compact and effective 30-dimensional vector from the log template. A better log vector representation can be achieved by fully using the semantic information in the log.
3.3. Anomaly Detection Model
Log is an unique type of text data, and its semantic and temporal information is worthy of deeper mining and research. We thus utilize a sliding window to split the log events to acquire the log event sequences. The log event sequences are then converted into the log sequence vectors based on the semantic vectors obtained from feature extraction and the log sequence vectors are supplied to the anomaly detection model. We design a model based on ECA and TCN for log anomaly detection.
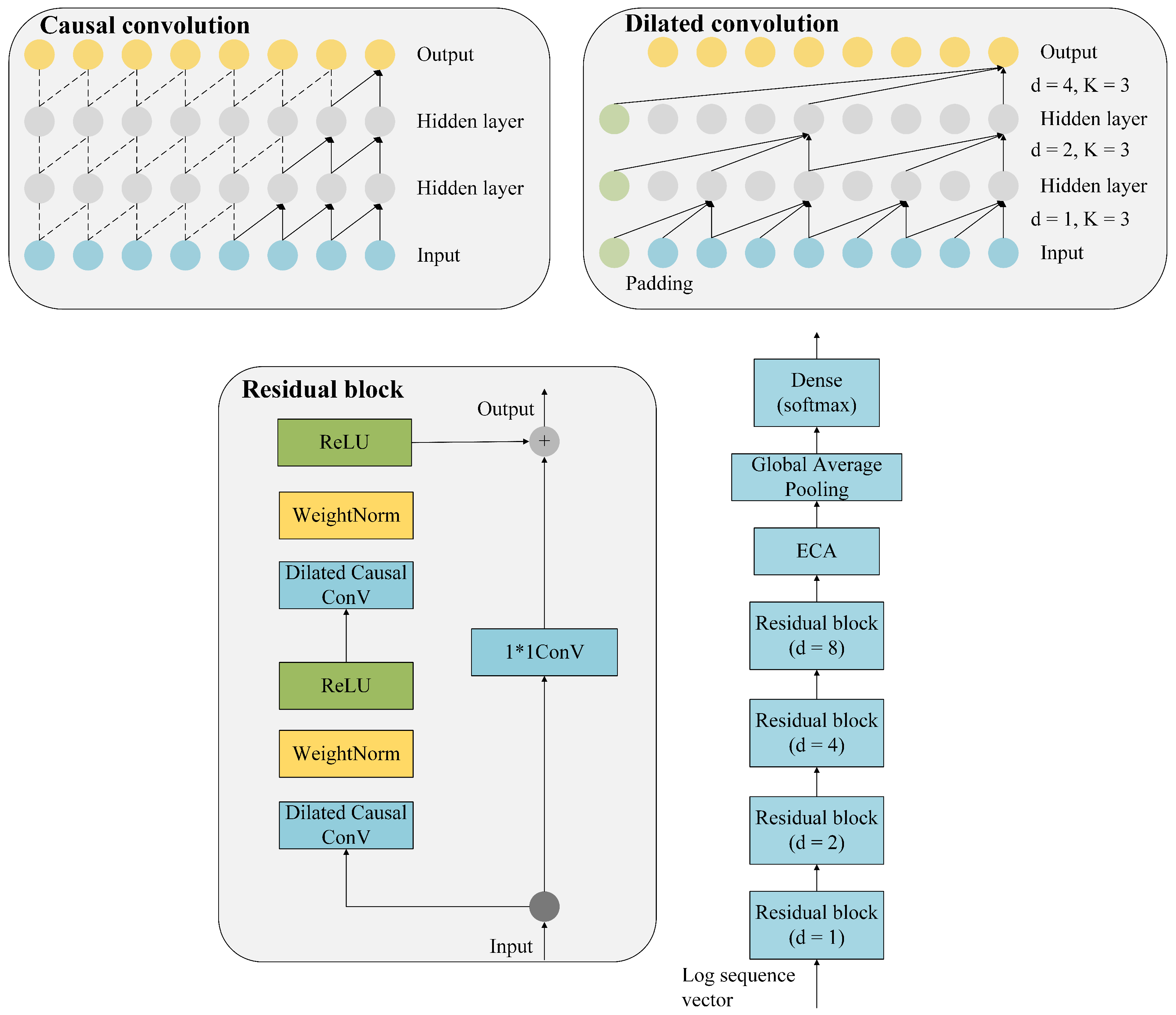
Figure 4 shows the architecture of the anomaly detection model.
A TCN is a special kind of convolutional neural network. Due to the limitation of convolutional kernel size, it is generally believed that traditional convolutional neural networks are not well suited for modeling temporal problems and unable to capture long-time dependency information well. The number of layers, convolutional kernel size and dilation rate determine the size of the receptive field of a TCN. A TCN can be flexibly customized based on the unique requirements of various tasks.
Causal convolution is required to deal with the sequence problem. Predict
according to
. Define causal convolution: filter
, sequence
, and the causal convolution at
(
) is:
Let us assume that the last two nodes of the input layer are
, respectively, and the last node of the first hidden layer is
. The filter
,
can be calculated using the following formula:
The size of the convolutional kernel restricts the length of the causal convolution over time modeling. Longer dependencies can be captured by dilated convolution. By adding voids to the regular convolution, dilated convolution expands the receptive field. It also has an additional hyperparameter dilation rate, which refers to the number of intervals of the kernel. Dilated convolution makes the size of the effective window grow exponentially with the number of layers. With fewer layers, the convolutional network can achieve a wide receptive field in this way. The hyperparameters of dilated convolution are the dilation rate
d and the kernel size
K. The definition of the dilated convolution is given below, including the filter
and sequence
. The dilated convolution with a dilation rate equal to
d at
(
) is:
When
d = 2, and
K = 3, assume that
are the last five nodes of the first hidden layer, respectively, and the last node of the second hidden layer is
. The filter
, according to the formula:
The size of the receptive field for the dilated convolution is , so increasing either K or d can increase the receptive field. In actuality, d usually increases exponentially by 2 as the number of layers in the network increases.
Deep network training has proven to be successful when using residual connection. It enables cross-layer information transfer inside the network. In this architecture, the causal convolution operation ensures that only input data before the current timestamp t are used to predict the output at timestamp t. Moreover, the dilated convolution enhances the feature representation extracted from various receptive regions. In our work, we set four dilation rates, i.e., d to be 1, 2, 4, and 8. When d = 1, the dilated convolution degenerates to normal convolution.
Without dimensionality reduction, the ECA module [
31] aggregates convolutional features using global average pooling (GAP) [
32]. After the adaptive determination of the kernel size
K for one-dimensional convolution, a Sigmoid function learns the channel attention. ECA uses a predetermined number of high-dimensional (low-dimensional) channels with long (short) convolution for each group. A nonlinear function represents the channel dimension
C, proportional to the convolutional kernel size
K. The channel dimension
C is set to the
kth power of 2 because the channel size is typically 2. The equation reads as follows:
The size of the convolutional kernel is:
where
denotes the nearest odd number to
t.
and
b are taken as 2 and 1, respectively.
We propose two improvements below for the anomaly detection model:
The output feature mapping of the final convolutional layer is then averaged using GAP rather than a fully connected layer. The number of parameters in our model is extremely small, which prevents overfitting and increases the reliability of the model.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}