
Remaining Useful Life Prediction for a Catenary, Utilizing Bayesian Optimization of Stacking

Abstract
1. Introduction
- (1)
- Based on the complexity of the catenary equipment, a stacking integration algorithm is designed to predict the RUL of the contact network by selecting a base learner with good prediction effect and high variability.
- (2)
- Each learner’s hyperparameters will be chosen using the Bayesian method. The prediction model’s overall performance is significantly improved thanks to the optimized hyperparameter combination, which also produces better prediction outcomes.
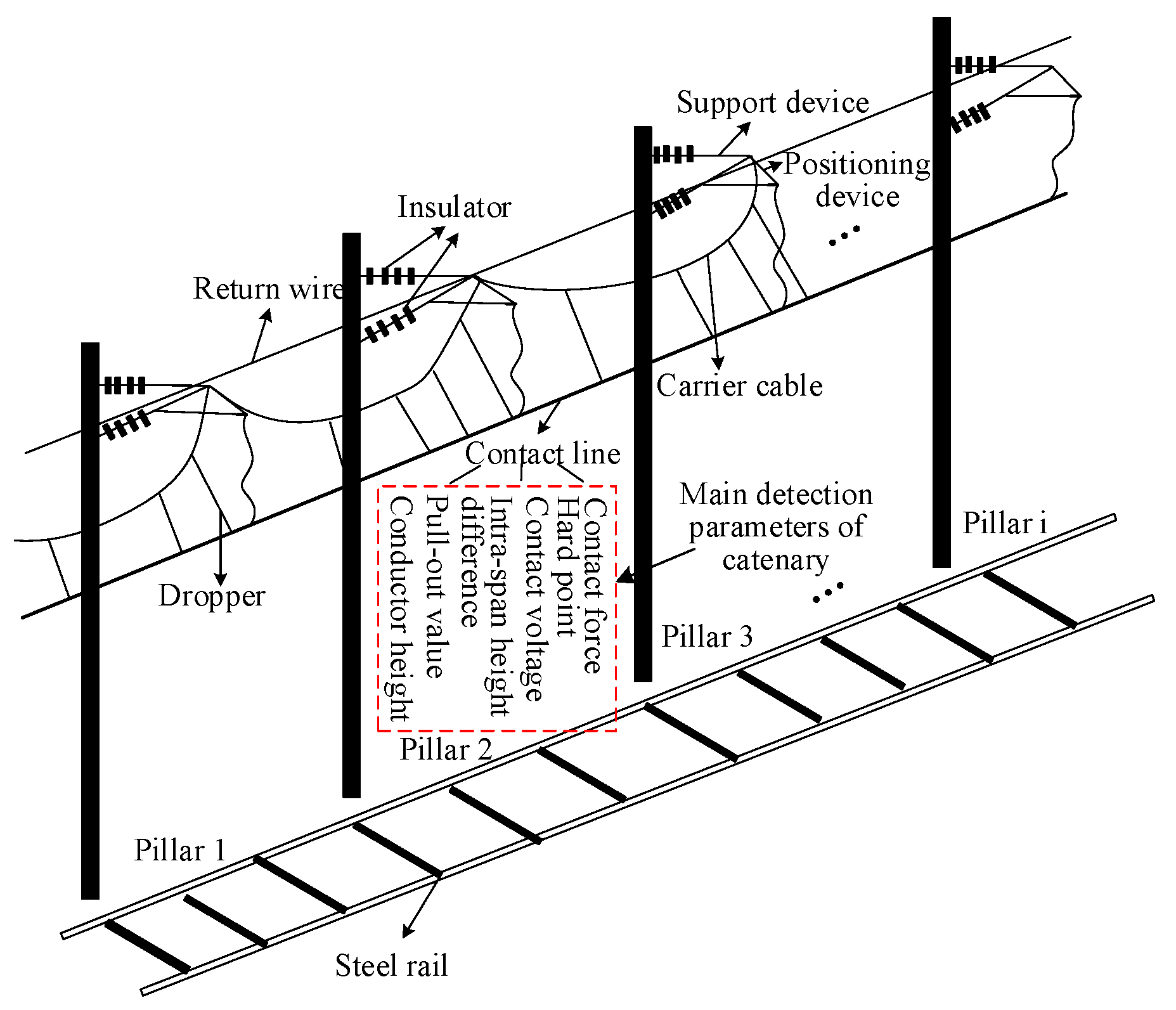
2. High-Speed Rail Catenary
3. Model Design
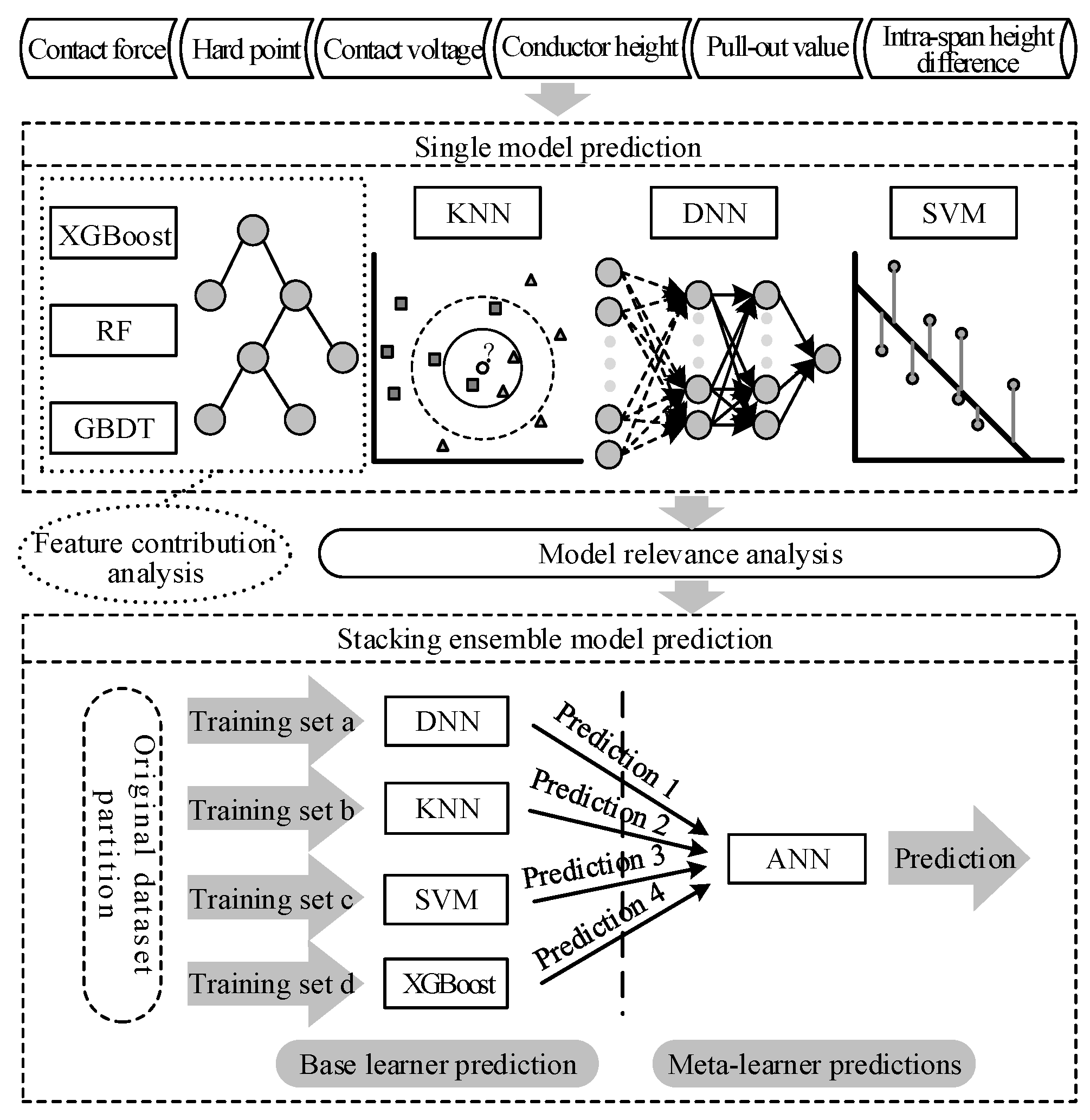
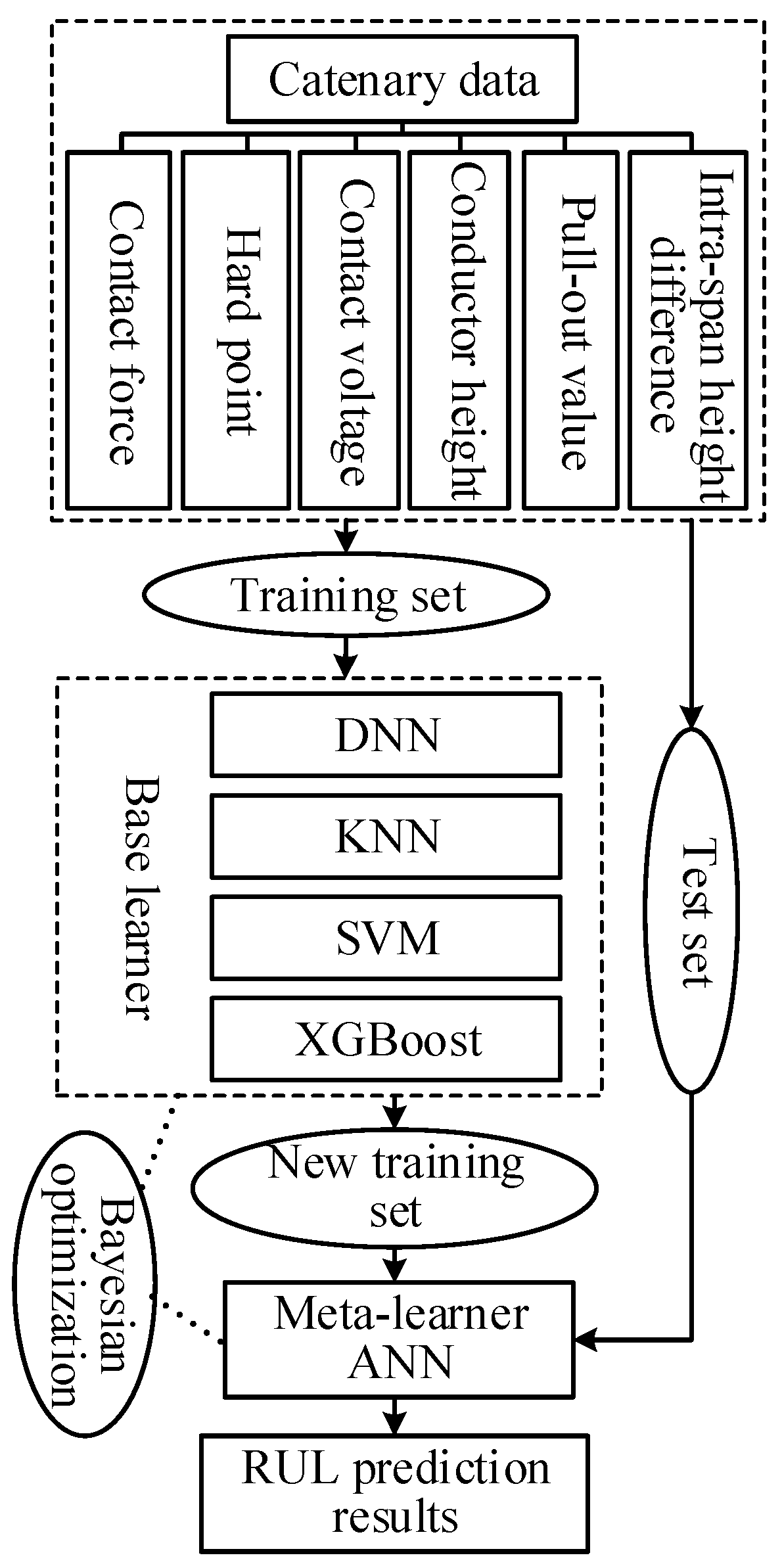
3.1. Design of the RUL Prediction Model
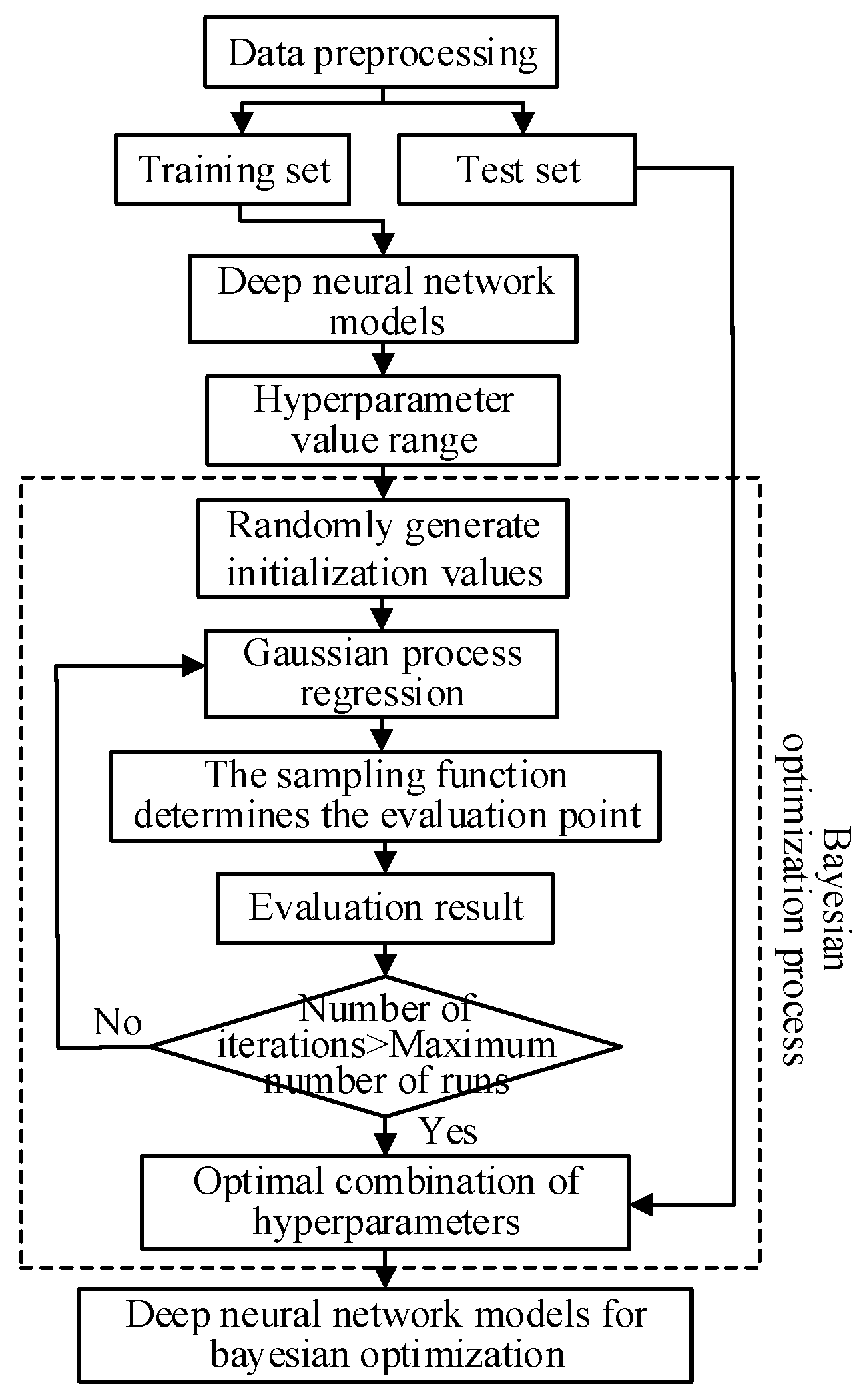
3.2. Bayesian Optimization Design
- (1)
- A surrogate model using probability.
- (2)
- Acquisition function
4. Experimental Verification
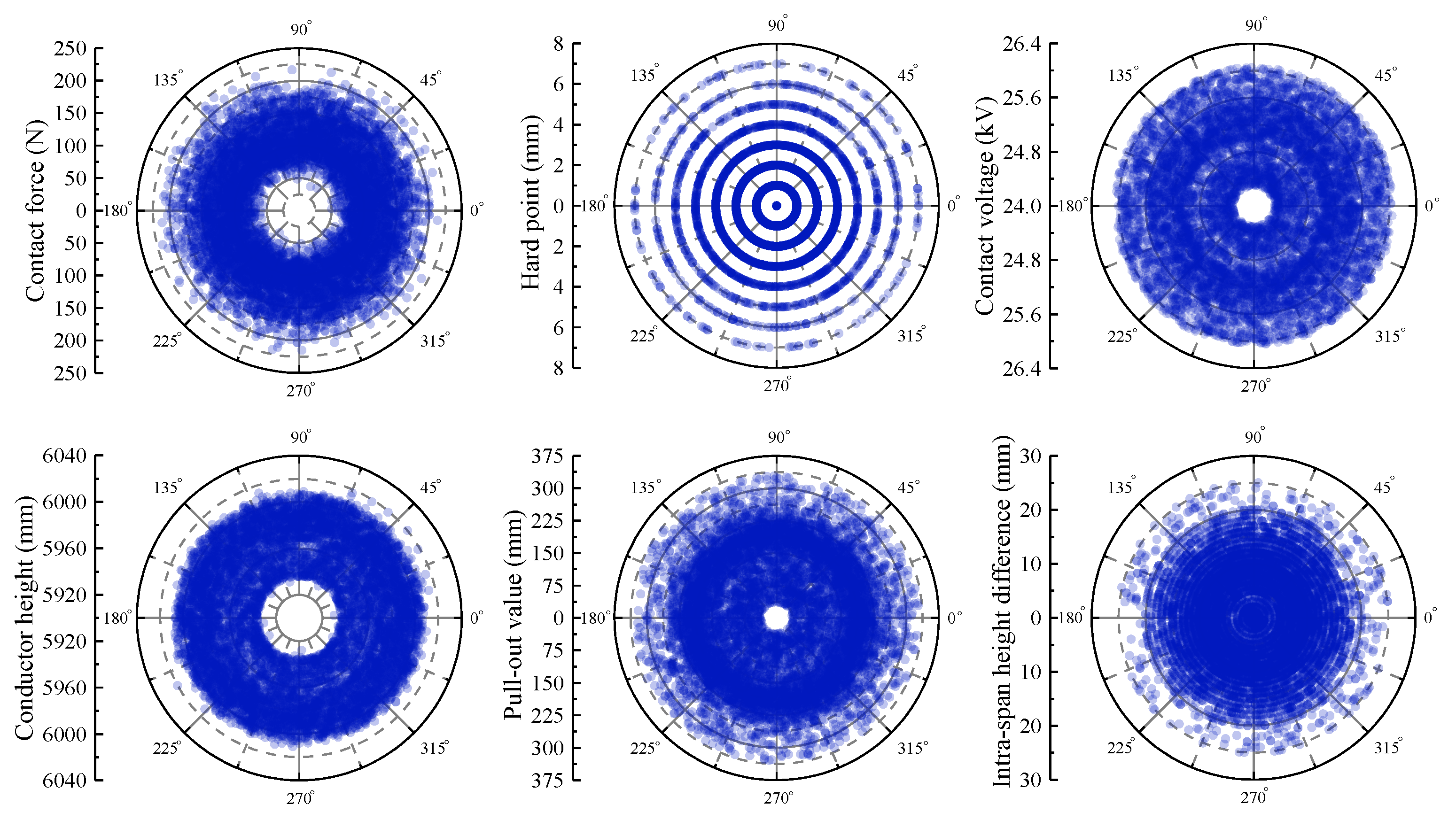
4.1. Dataset Preprocessing
4.1.1. Catenary Dataset
- (1)
- Pull-out value: 36~330 mm
- (2)
- Conductor height: 5928~6020 mm
- (3)
- Contact force: 41~218 N
- (4)
- Hard point: 0~7 mm
- (5)
- Contact voltage: 24.30~26.05 kV
- (6)
- Intra-span height difference: 0~25 mm
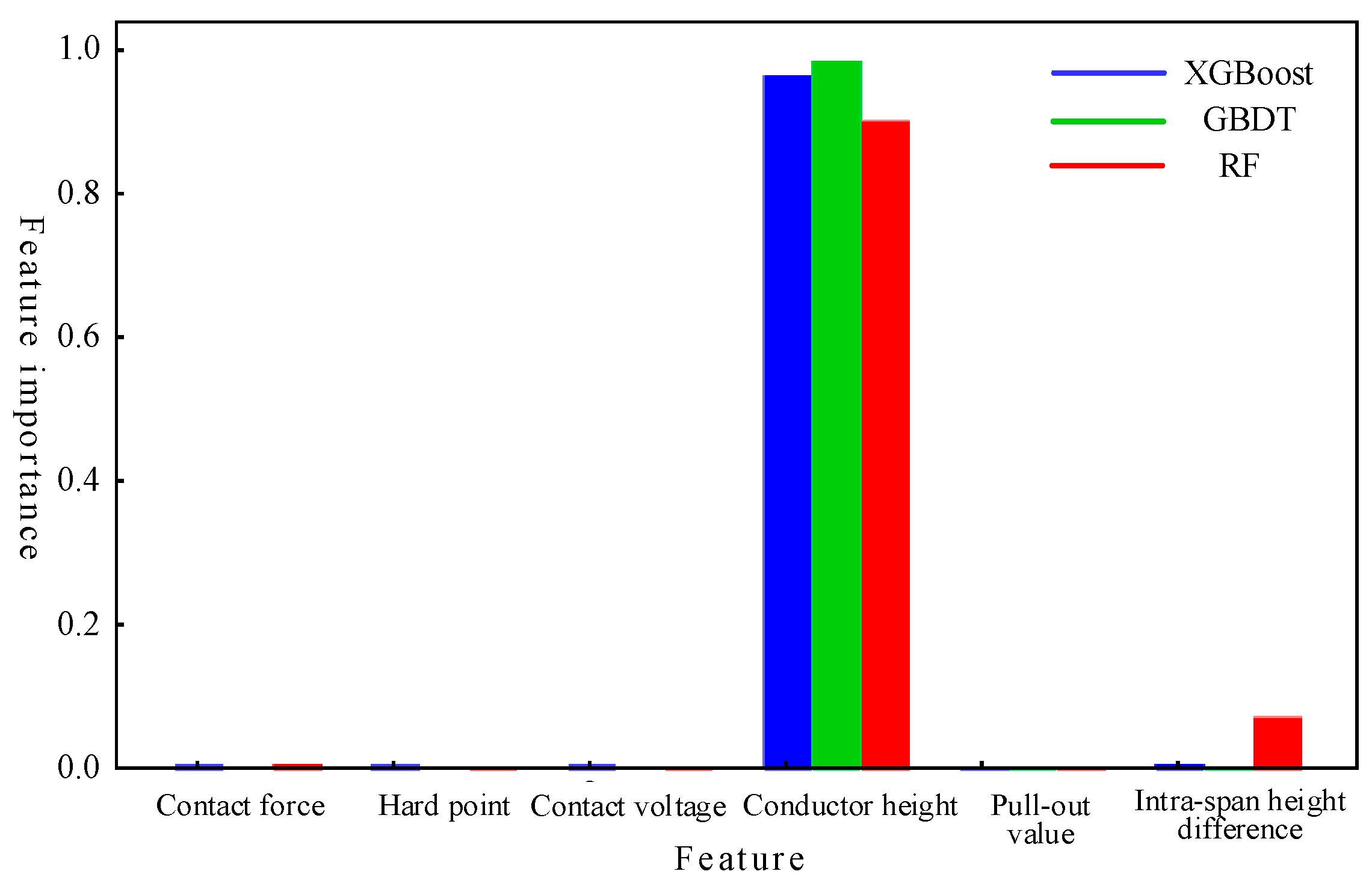
4.1.2. Feature Contribution Analysis
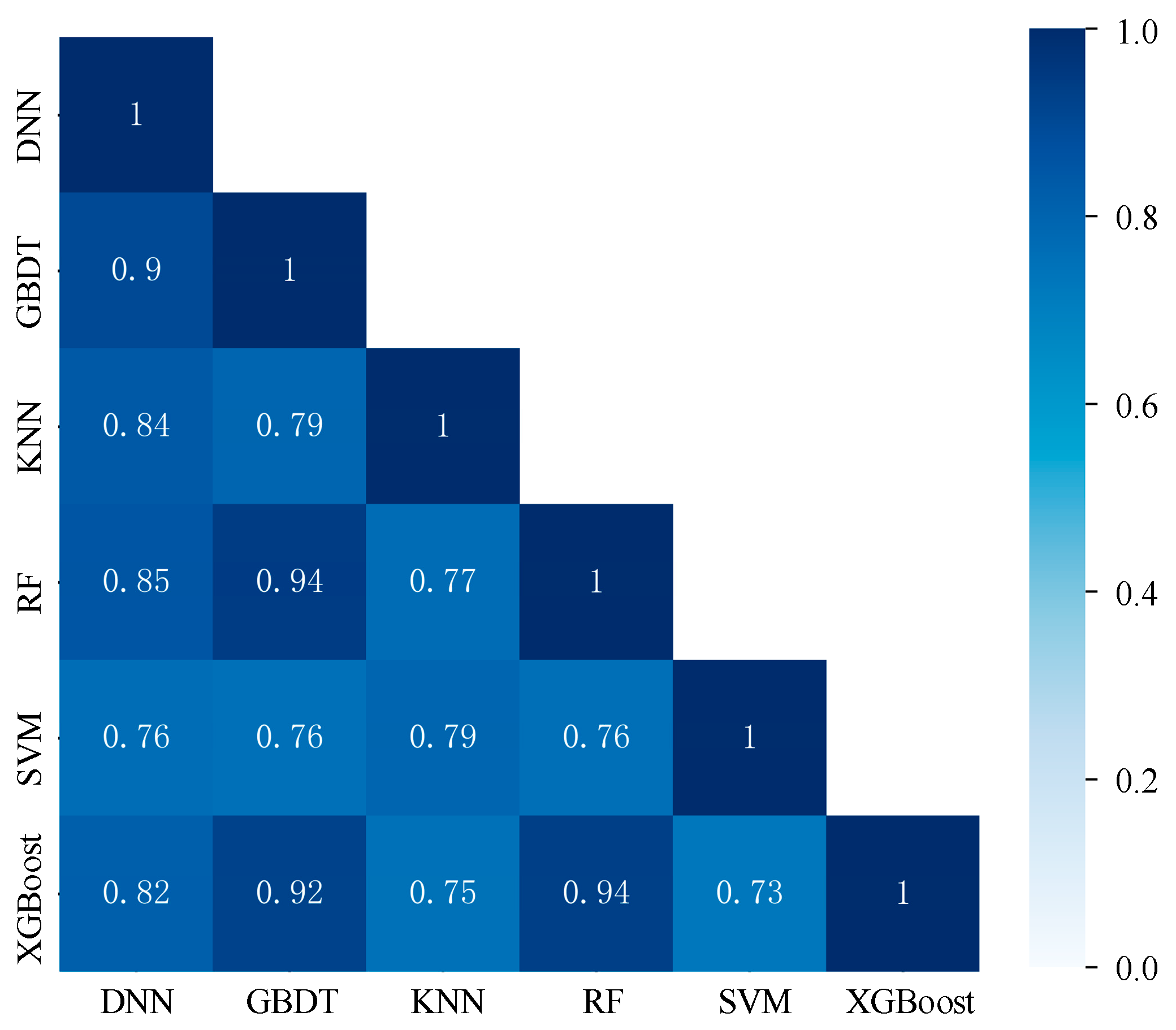
4.2. Correlation Analysis of Each Model
4.3. Building the Stacking Integration Model
4.4. Stacking Ensemble Algorithm Hyperparameter Optimization
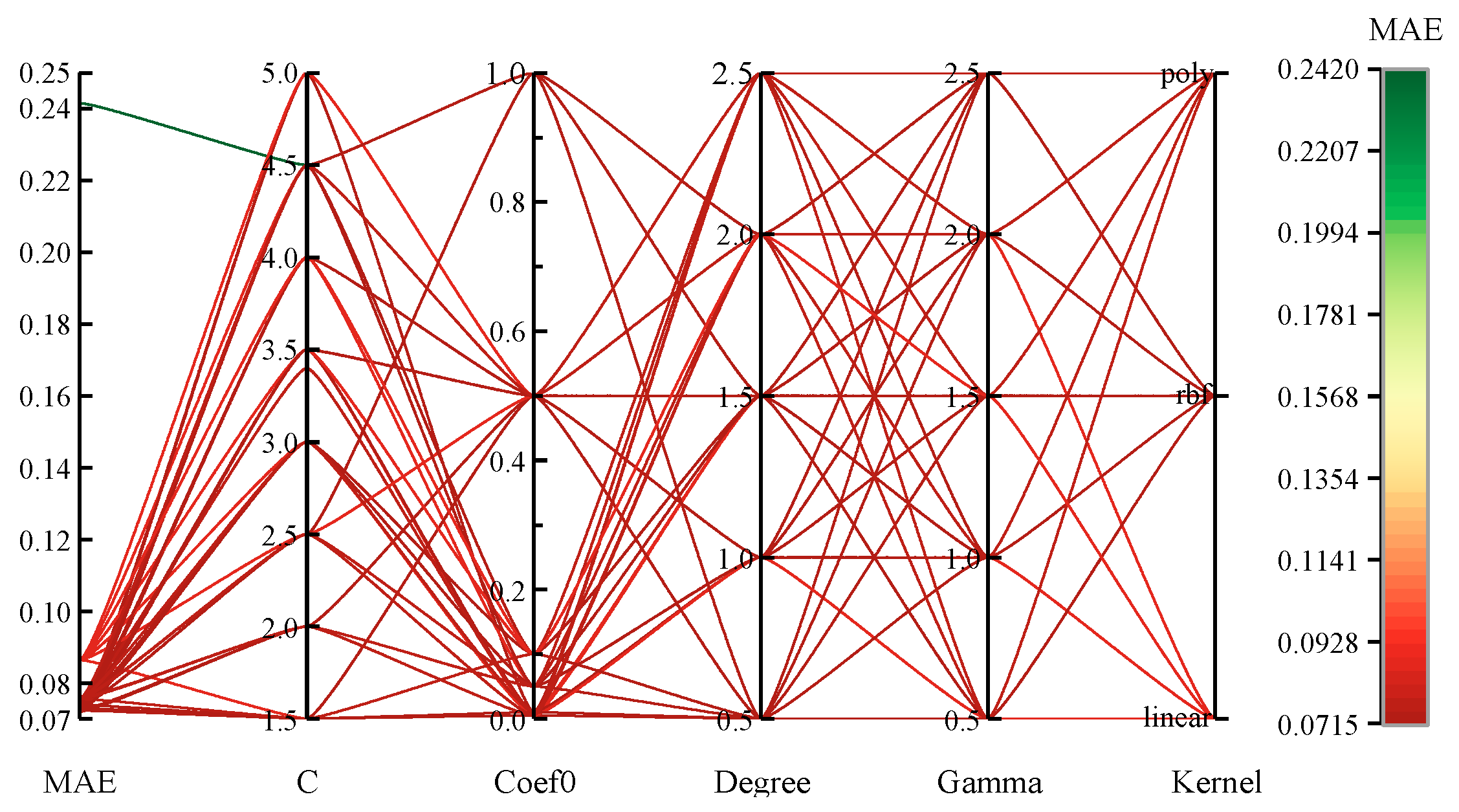
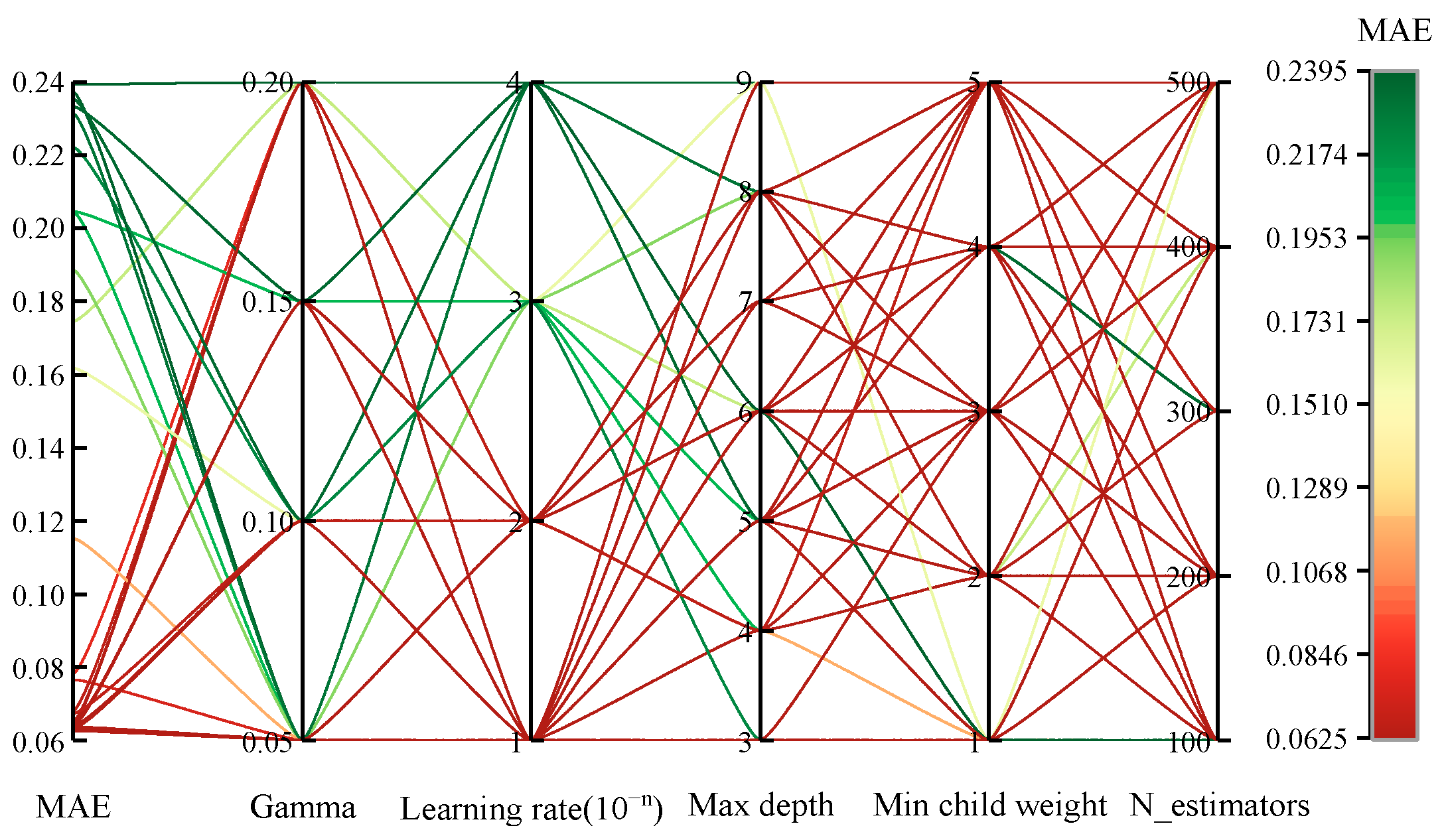
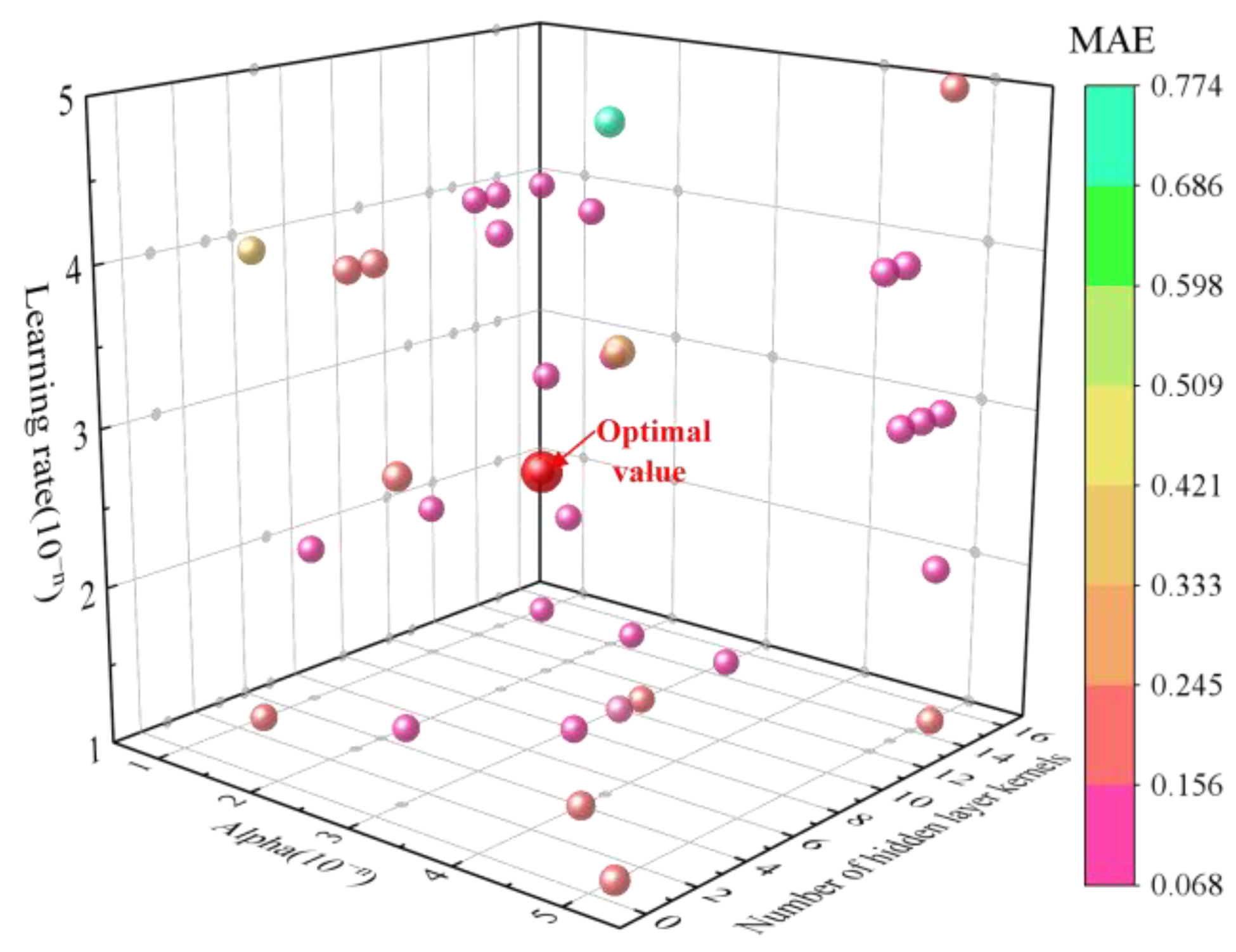
4.4.1. Choosing the Appropriate Hyperparameters for the Fundamental Learner
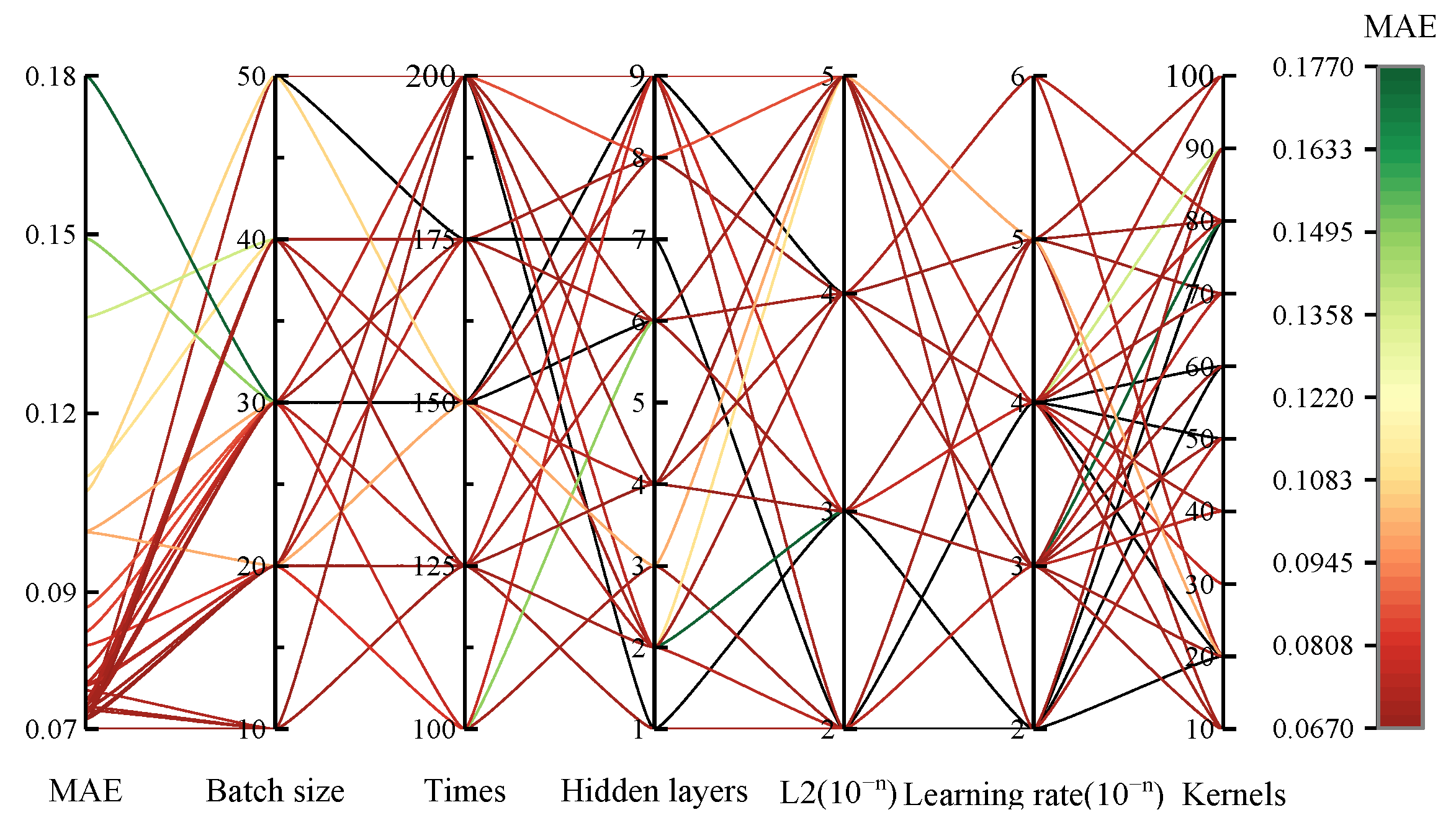
4.4.2. Hyperparameter Selection for Meta-Learners
5. Analysis and Comparison
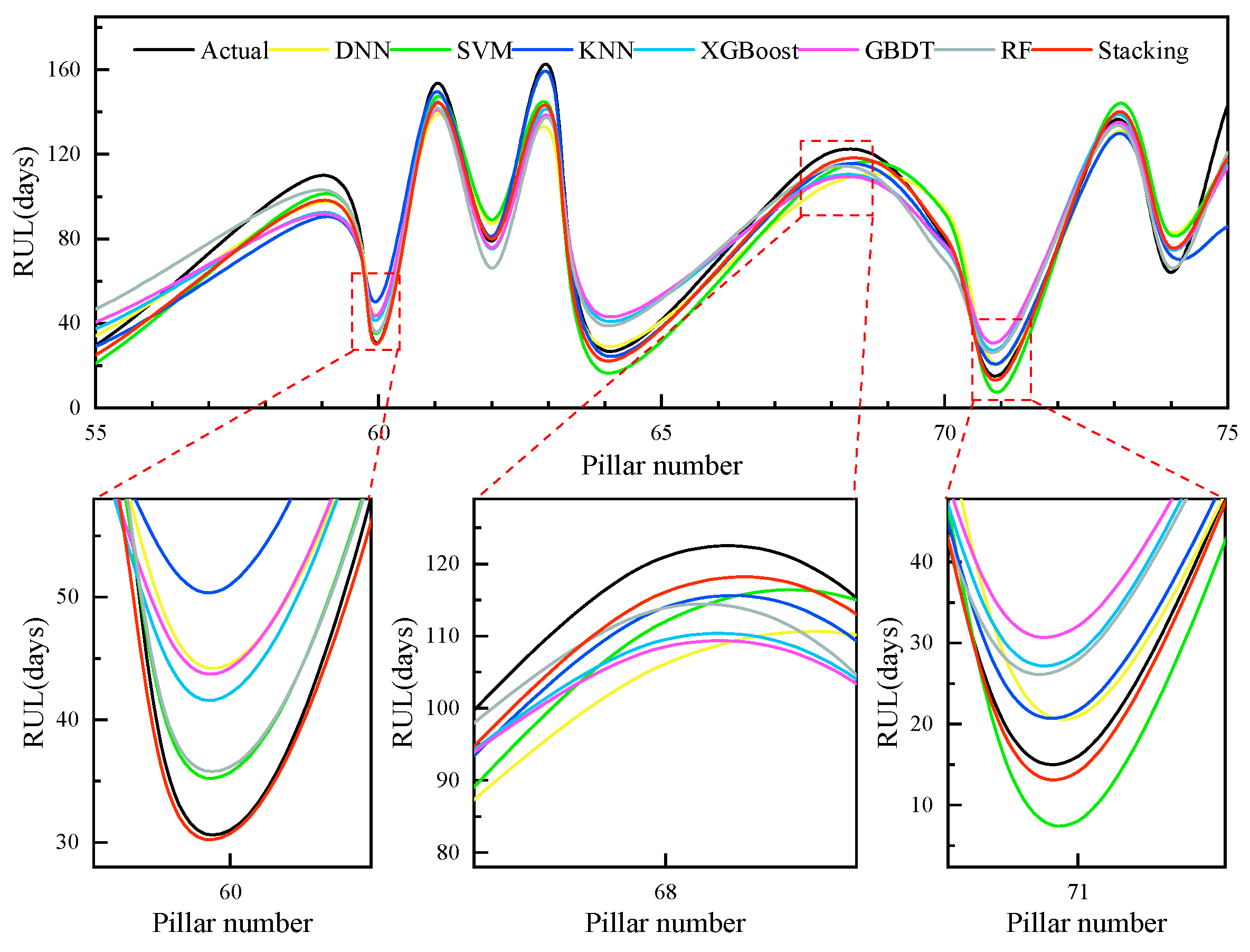
5.1. Comparison of the Stacking Model’s Prediction Outcomes with Those of Other Models
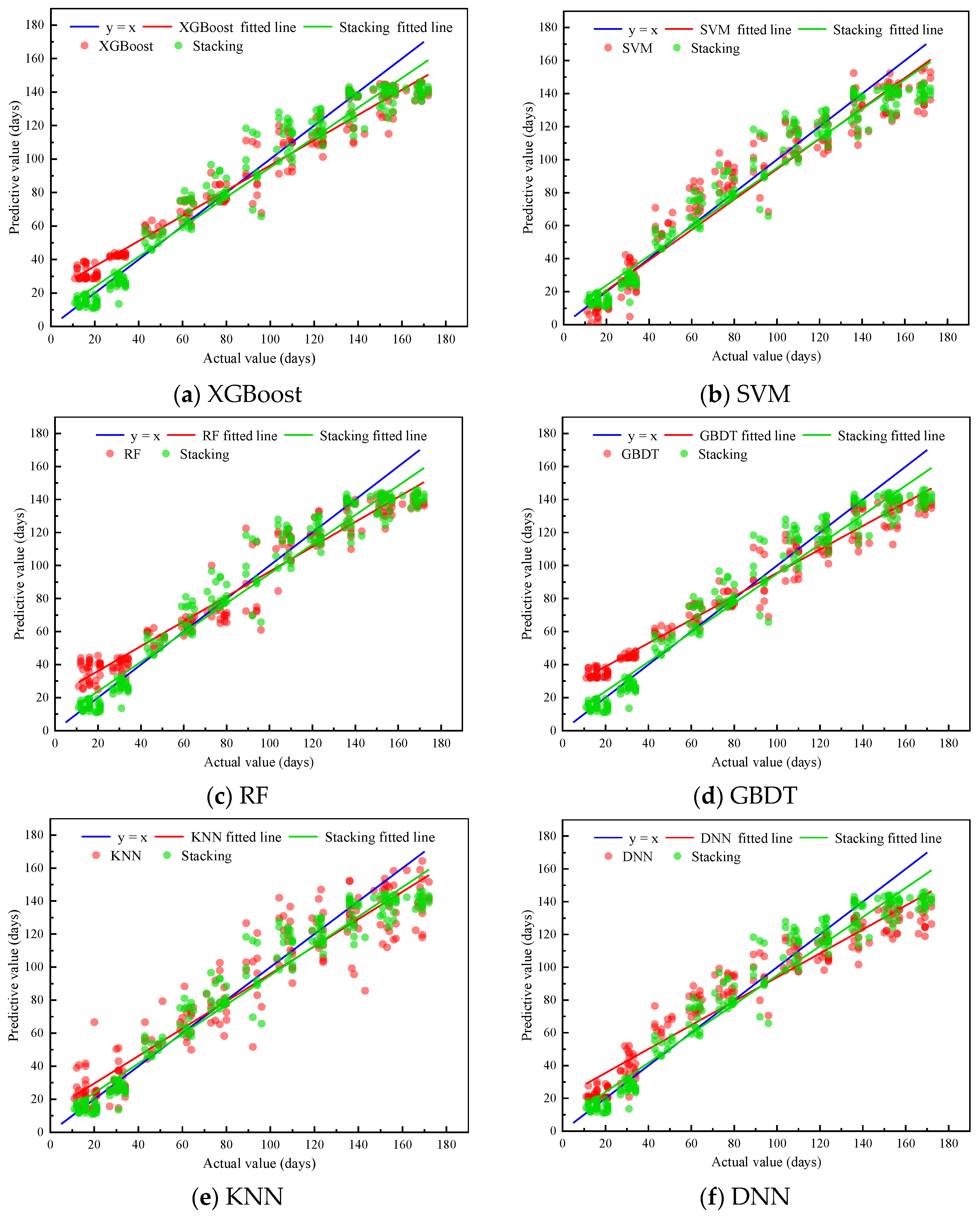
5.1.1. Comparison Using Just One Model
5.1.2. Comparison and Analysis of Stacking Models with Various Base Learners
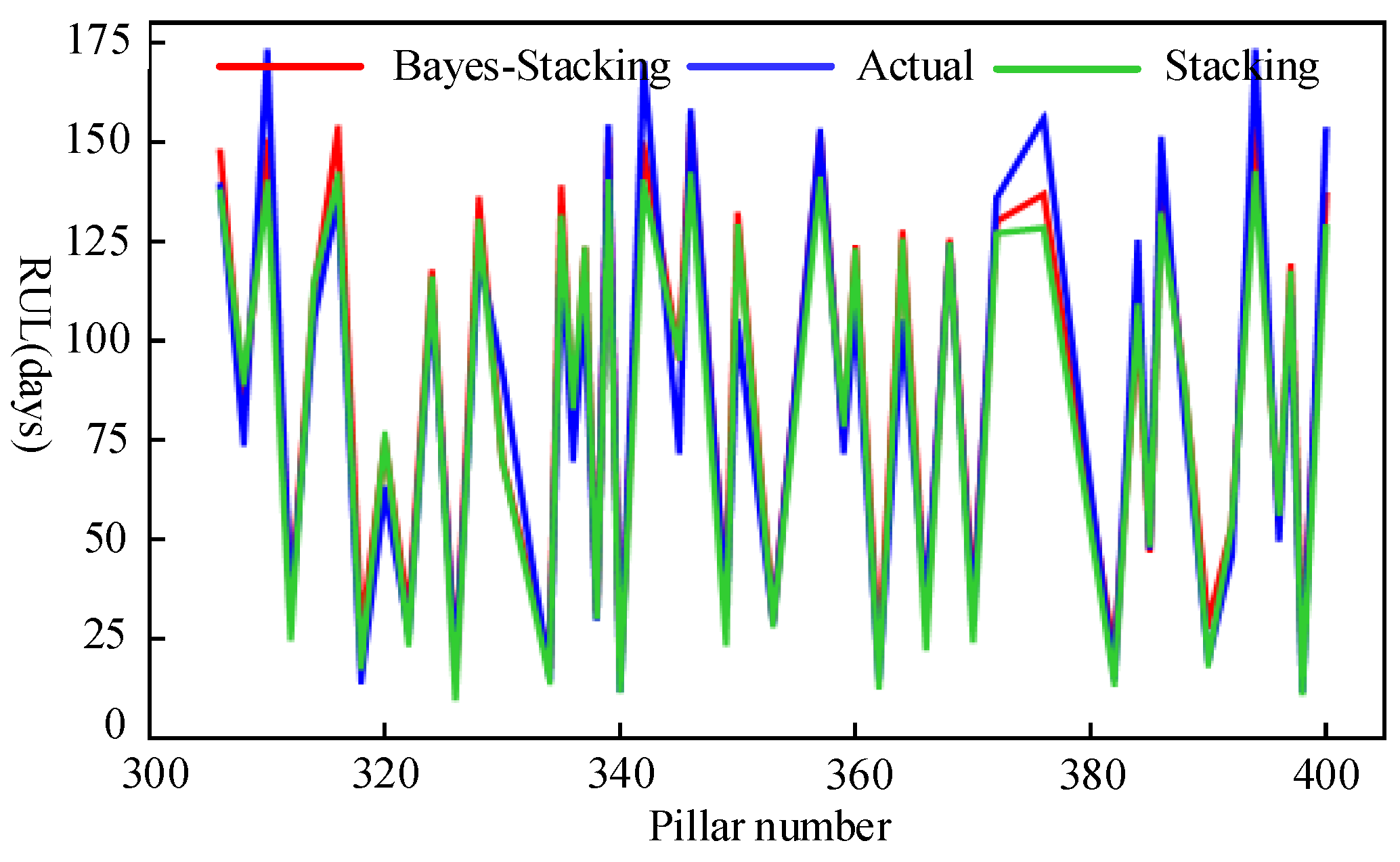
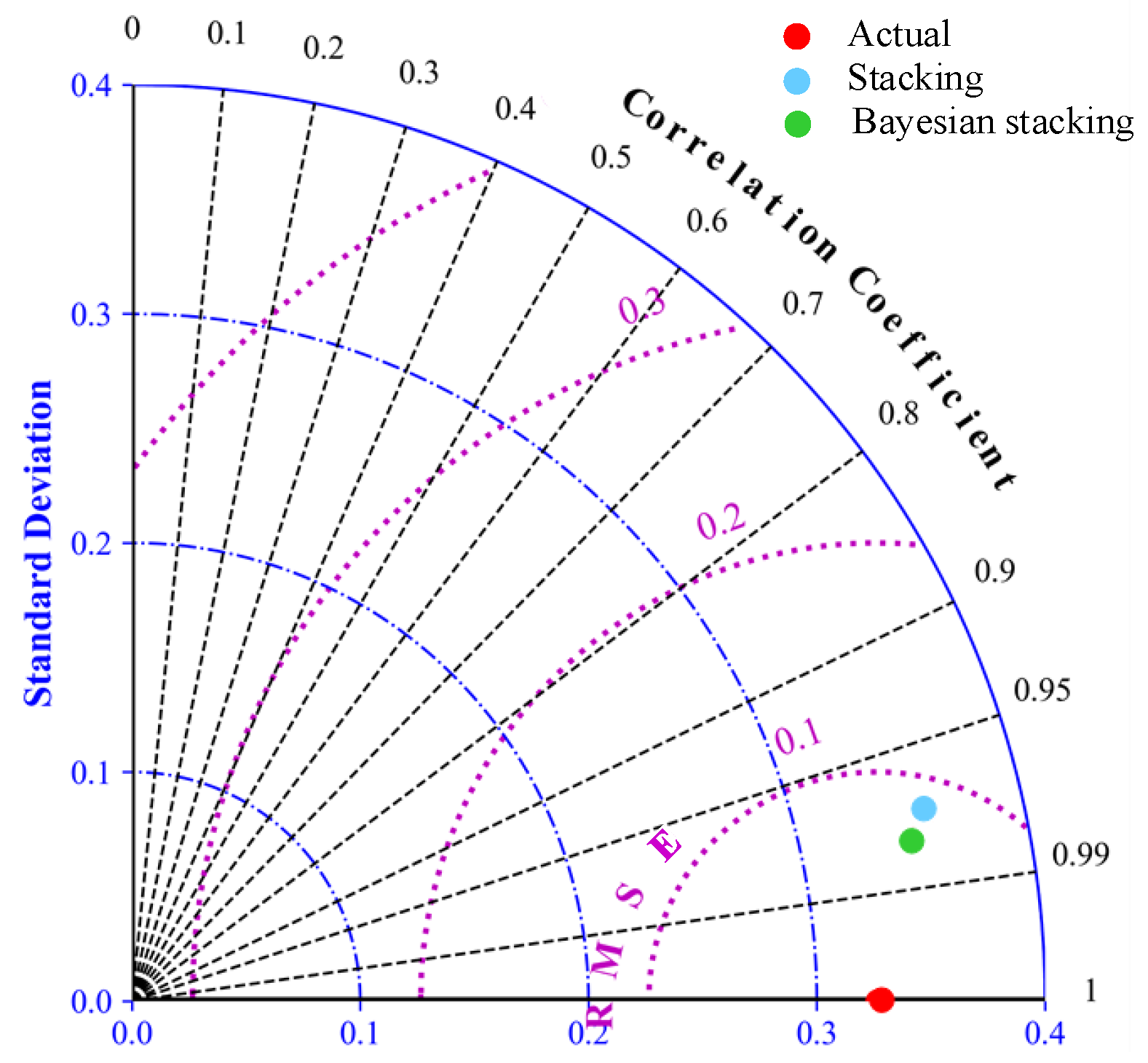
5.2. Results of Stacking Model Hyperparameter Optimization Are Analyzed and Compared
6. Conclusions
- (1)
- The stacking, two-layer framework is computationally expensive due to its complexity and the need for many trained models. The decomposition of the training model into numerous minor components for independent processing using distributed computing significantly increases the computing efficiency.
- (2)
- AI technology has improved the failure and RUL prediction at the application level [39]. Future high-speed rail system development will focus on fault prediction and health management, and the combination of deep learning and high-speed rail system prediction will continue to be extremely valuable.
- (3)
- Building information modeling (BIM) also has the potential to reduce planned and reactive high-speed rail catenary maintenance costs, thus in-creasing the RUL prediction of a high-speed rail catenary.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Feng, D.; He, Z.Y.; Lin, S.; Wang, Z.; Sun, X.J. Risk index system for catenary lines of high-speed railway considering the characteristics of time-space differences. IEEE Trans. Transp. Electrif. 2017, 3, 739–749. [Google Scholar] [CrossRef]
- Guo, L.; Gao, X.J.; Li, Q.Z.; Huang, W.X.; Shu, Z.L. Online antiicing technique for the catenary of the high-speed electric railway. IEEE Trans. Power Deliv. 2015, 30, 1569–1576. [Google Scholar] [CrossRef]
- Qin, Y.; Xiao, S.; Lu, L.; Yang, B.; Zhu, T.; Yang, G. Fatigue failure of integral droppers of high-speed railway catenary under impact load. Eng. Fail. Anal. 2022, 134, 106086. [Google Scholar] [CrossRef]
- Moghaddass, R.; Zuo, M.J. An integrated framework for online diagnostic and prognostic health monitoring using a multistate deterioration process. Reliab. Eng. Syst. Saf. 2014, 124, 92–104. [Google Scholar] [CrossRef]
- Elsheikh, A.; Yacout, S.; Ouali, M.-S. Bidirectional handshaking LSTM for remaining useful life prediction. Neurocomputing 2019, 323, 148–156. [Google Scholar] [CrossRef]
- Xu, X.; Wu, Q.; Li, X.; Huang, B. Dilated convolution neural network for remaining useful life prediction. J. Comput. Inf. Sci. Eng. 2020, 20, 021004. [Google Scholar] [CrossRef]
- Sikorska, J.Z.; Hodkiewicz, M.; Ma, L.J.M.S.; Processing, S. Prognostic modelling options for remaining useful life estimation by industry. Mech. Syst. Signal Process. 2011, 25, 1803–1836. [Google Scholar] [CrossRef]
- Wang, Y.W.; Gogu, C.; Binaud, N.; Bes, C.; Haftka, R.T.; Kim, N.H. Predictive airframe maintenance strategies using model-based prognostics. Proc. Inst. Mech. Eng. Part O-J. Risk Reliab. 2018, 232, 690–709. [Google Scholar] [CrossRef]
- Cai, Z.Y.; Wang, Z.Z.; Chen, Y.X.; Guo, J.S.; Xiang, H.C. Remaining useful lifetime prediction for equipment based on nonlinear implicit degradation modeling. J. Syst. Eng. Electron. 2020, 31, 194–205. [Google Scholar] [CrossRef]
- Li, N.; Lei, Y.; Gebraeel, N.; Wang, Z.; Cai, X.; Xu, P.; Wang, B. Multi-sensor data-driven remaining useful life prediction of semi-observable systems. IEEE Trans. Ind. Electron. 2021, 68, 11482–11491. [Google Scholar] [CrossRef]
- Wu, J.; Hu, K.; Cheng, Y.; Zhu, H.; Shao, X.; Wang, Y. Data-driven remaining useful life prediction via multiple sensor signals and deep long short-term memory neural network. ISA Trans. 2020, 97, 241–250. [Google Scholar] [CrossRef] [PubMed]
- Cai, B.P.; Shao, X.Y.; Liu, Y.H.; Kong, X.D.; Wang, H.F.; Xu, H.Q.; Ge, W.F. Remaining useful life estimation of structure systems under the influence of multiple causes: Subsea pipelines as a case study. IEEE Trans. Ind. Electron. 2020, 67, 5737–5747. [Google Scholar] [CrossRef]
- Chen, Z.H.; Wu, M.; Zhao, R.; Guretno, F.; Yan, R.Q.; Li, X.L. Machine remaining useful life prediction via an attention-based deep learning approach. IEEE Trans. Ind. Electron. 2021, 68, 2521–2531. [Google Scholar] [CrossRef]
- Sunar, Ö.; Fletcher, D. A new small sample test configuration for fatigue life estimation of overhead contact wires. Proc. Inst. Mech. Eng. Part F J. Rail Rapid Transit 2022, 237, 438–444. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.Q.; Wang, J.J.; Mao, K.Z. Learning to monitor machine health with convolutional bi-directional LSTM networks. Sensors 2017, 17, 273. [Google Scholar] [CrossRef]
- Rahimi, A.; Kumar, K.D.; Alighanbari, H. Failure prognosis for satellite reaction wheels using kalman filter and particle filter. J. Guid. Control. Dyn. 2020, 43, 585–588. [Google Scholar] [CrossRef]
- Guo, R.X.; Sui, J.F. Remaining useful life prognostics for the electrohydraulic servo actuator using hellinger distance-based particle filter. IEEE Trans. Instrum. Meas. 2020, 69, 1148–1158. [Google Scholar] [CrossRef]
- Zan, T.; Liu, Z.; Wang, H.; Wang, M.; Gao, X.; Pang, Z. Prediction of performance deterioration of rolling bearing based on JADE and PSO-SVM. Proc. Inst. Mech. Eng. 2020, 235, 1684–1697. [Google Scholar] [CrossRef]
- Zhen, L.; Wenjuan, M.; Xianping, Z.; Chenglin, Y.; Xiuyun, Z.J.S. Remaining useful life estimation of insulated gate biploar transistors (IGBTs) based on a novel volterra k-nearest neighbor optimally pruned extreme learning machine (VKOPP) model using degradation data. Sensors 2017, 17, 2524. [Google Scholar] [CrossRef]
- Zhang, Y.; Peng, Z.; Guan, Y.; Wu, L.J.E. Prognostics of battery cycle life in the early-cycle stage based on hybrid model. Energy 2021, 221, 119901. [Google Scholar] [CrossRef]
- Reddy Maddikunta, P.K.; Srivastava, G.; Reddy Gadekallu, T.; Deepa, N.; Boopathy, P. Predictive model for battery life in IoT networks. IET Intell. Transp. Syst. 2020, 14, 1388–1395. [Google Scholar] [CrossRef]
- Gupta, M.; Kumar, N.; Singh, B.K.; Gupta, N.; Damaševičius, R. NSGA-III-based deep-learning model for biomedical search engines. Math. Probl. Eng. 2021, 2021, 1–8. [Google Scholar] [CrossRef]
- Kodepogu, K.R.; Annam, J.R.; Vipparla, A.; Krishna, B.V.N.V.S.; Kumar, N.; Viswanathan, R.; Gaddala, L.K.; Chandanapalli, S.K. A novel deep convolutional neural network for diagnosis of skin disease. Trait. Du Signal 2022, 39, 1873–1877. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Z.Y.; Jia, W.Q.; Lin, X.K. Remaining useful life prediction using a novel feature-attention-based end-to-end approach. IEEE Trans. Ind. Inform. 2021, 17, 1197–1207. [Google Scholar] [CrossRef]
- Yi, L.; Zhao, J.; Yu, W.; Long, G.; Sun, H.; Li, W. Health status evaluation of catenary based on normal fuzzy matter-element and game theory. J. Electr. Eng. Technol. 2020, 15, 2373–2385. [Google Scholar] [CrossRef]
- Wang, P.; Qin, J.; Li, J.; Wu, M.; Zhou, S.; Feng, L. Device status evaluation method based on deep learning for PHM scenarios. Electronics 2023, 12, 779. [Google Scholar] [CrossRef]
- Wang, H.R.; Nunez, A.; Liu, Z.G.; Zhang, D.L.; Dollevoet, R. A bayesian network approach for condition monitoring of high-speed railway catenaries. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4037–4051. [Google Scholar] [CrossRef]
- Qu, Z.J.; Yuan, S.G.; Chi, R.; Chang, L.C.; Zhao, L. Genetic optimization method of pantograph and catenary comprehensive monitor status prediction model based on adadelta deep neural network. IEEE Access 2019, 7, 23210–23221. [Google Scholar] [CrossRef]
- Awang, M.K.; Makhtar, M.; Udin, N.; Mansor, N.F. Improving customer churn classification with ensemble stacking method. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 277. [Google Scholar] [CrossRef]
- Agrawal, S.; Sarkar, S.; Srivastava, G.; Maddikunta, P.K.R.; Gadekallu, T.R. Genetically optimized prediction of remaining useful life. Sustain. Comput. Inform. Syst. 2021, 31, 100565. [Google Scholar] [CrossRef]
- Li, B.; Cui, F. Inception module and deep residual shrinkage network-based arc fault detection method for pantograph–catenary systems. J. Power Electron. 2022, 22, 991–1000. [Google Scholar] [CrossRef]
- Jiang, T.; Rønnquist, A.; Song, Y.; Frøseth, G.T.; Nåvik, P. A detailed investigation of uplift and damping of a railway catenary span in traffic using a vision-based line-tracking system. J. Sound Vib. 2022, 527, 116875. [Google Scholar] [CrossRef]
- Oleiwi, H.W.; Mhawi, D.N.; Al-Raweshidy, H. A meta-model to predict and detect malicious activities in 6G-structured wireless communication networks. Electronics 2023, 12, 643. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, H.; Wang, C.; Zhou, X. Wind power forecasting based on stacking ensemble model, decomposition and intelligent optimization algorithm. Neurocomputing 2021, 462, 169–184. [Google Scholar] [CrossRef]
- Pinto, T.; Praça, I.; Vale, Z.; Silva, J. Ensemble learning for electricity consumption forecasting in office buildings. Neurocomputing 2021, 423, 747–755. [Google Scholar] [CrossRef]
- Torres-Barrán, A.; Alonso, Á.; Dorronsoro, J.R. Regression tree ensembles for wind energy and solar radiation prediction. Neurocomputing 2019, 326, 151–160. [Google Scholar] [CrossRef]
- Shin, S.; Lee, Y.; Kim, M.; Park, J.; Lee, S.; Min, K. Deep neural network model with Bayesian hyperparameter optimization for prediction of NOx at transient conditions in a diesel engine. Eng. Appl. Artif. Intell. 2020, 94, 103761. [Google Scholar] [CrossRef]
- Sun, J.; Wu, S.; Zhang, H.; Zhang, X.; Wang, T. Based on multi-algorithm hybrid method to predict the slope safety factor-- stacking ensemble learning with bayesian optimization. J. Comput. Sci. 2022, 59, 101587. [Google Scholar] [CrossRef]
- Kumar, N.; Hashmi, A.; Gupta, M.; Kundu, A. Automatic diagnosis of Covid-19 related pneumonia from CXR and CT-Scan images. Eng. Technol. Appl. Sci. Res. 2022, 12, 7993–7997. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Parameter Definition |
|---|---|
| Pull-out value (mm) | Lateral offset of the contact line at the detection point. |
| Conductor height (mm) | The vertical distance from the contact line at the detection point to the ground. |
| Intra-span height difference (mm) | The height difference of the contact line between the two pillars at the detection point. |
| Contact force (N) | The interaction force between the contact wire and the pantograph at the detection point. |
| Hard point (mm) | The location of the sudden change in contact pressure on the contact line. |
| Contact voltage (kV) | Voltage on the contact line at the detection point. |
| Method | Initial Hyperparameter Set | Single Model Prediction Error | ||
|---|---|---|---|---|
| RMSE | R2 | MAE | ||
| XGBoost | max depth: 8; learning rate: 0.05; n-estimators: 350; min child weight: 5; gamma: 0.05 | 0.095 | 0.914 | 0.080 |
| SVM | kernel: poly; C: 2; gamma: 1; coef0: 0.01; degree: 1.5 | 0.098 | 0.909 | 0.080 |
| RF | max depth: 6; n-estimators: 200; min samples leaf: 5; min samples split: 5 | 0.101 | 0.904 | 0.083 |
| GBDT | max depth: 6; learning rate: 0.01; n-estimators: 150; min samples leaf: 10 | 0.106 | 0.895 | 0.090 |
| KNN | n-neighbors: 3 | 0.108 | 0.890 | 0.080 |
| DNN | hidden layers: 6; number of hidden layer kernels: 30; learning rate: 0.0001; activation: relu | 0.113 | 0.881 | 0.091 |
| Hyperparameter Category | Hyperparameter Meaning | Range | Optimal Value |
|---|---|---|---|
| Batch size | Training batch size | 10, 20, 30, 40, 50 | 30 |
| Times | Training times | 100, 125, 150, 175, 200 | 200 |
| Hidden layers | Number of hidden layers | 1, 2, 3, 4, 5, 6, 7, 8, 9 | 6 |
| L2 | L2 regularization penalty coefficient | 10−2, 10−3, 10−4, 10−5 | 10−4 |
| Learning rate | Step size of model training | 10−2, 10−3, 10−4, 10−5, 10−6 | 10−3 |
| Kernels | Number of hidden layer kernels | 10, 20, 30, 40, 50, 60, 70, 80, 90 | 70 |
| Hyperparameter Category | Hyperparameter Meaning | Range | Optimal Value |
|---|---|---|---|
| C | Regularization parameter | 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5 | 4 |
| Coef0 | Constant term of the kernel function | 0.005, 0.05, 0.1, 0.5, 1 | 0.1 |
| Degree | Dimensions of the polynomial poly function | 0.5, 1, 1.5, 2, 2.5 | 0.5 |
| Gamma | Coefficients of the kernel function | 0.5, 1.5, 2, 2.5 | 1 |
| Kernels | Type of kernel function | Poly, Rbf, Linear | Rbf |
| Hyperparameter Category | Hyperparameter Meaning | Range | Optimal Value |
|---|---|---|---|
| Gamma | Minimum loss reduction required to make a further partition on a leaf node of the tree | 0.05, 0.1, 0.15, 0.2 | 0.05 |
| Learning rate | Step size of model training | 10−1, 10−2, 10−3, 10−4 | 10−1 |
| Max depth | Maximum depth of a tree | 3, 4, 5, 6, 7, 8, 9 | 5 |
| Min child weight | Minimum sum of instance weight needed in a child | 1, 2, 3, 4, 5 | 3 |
| N-estimators | Total number of iterations | 100, 200, 300, 400, 500 | 400 |
| Basic Learner Combination | RMSE | R2 | MAE |
|---|---|---|---|
| XGBoost | 0.095 | 0.914 | 0.080 |
| SVM | 0.098 | 0.909 | 0.080 |
| RF | 0.101 | 0.904 | 0.083 |
| GBDT | 0.106 | 0.895 | 0.090 |
| KNN | 0.108 | 0.890 | 0.080 |
| DNN | 0.113 | 0.881 | 0.091 |
| Stacking | 0.080 | 0.940 | 0.059 |
| Basic Learner Combination | RMSE | R2 | MAE |
|---|---|---|---|
| XGBoost, DNN, SVM, KNN | 0.080 | 0.940 | 0.059 |
| GBDT, SVM, KNN | 0.083 | 0.935 | 0.063 |
| RF, KNN | 0.089 | 0.926 | 0.070 |
| GBDT, DNN, SVR, KNN | 0.090 | 0.924 | 0.070 |
| DNN, SVM, KNN | 0.095 | 0.915 | 0.073 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Zhang, Z.; Qu, Z.; Bell, A. Remaining Useful Life Prediction for a Catenary, Utilizing Bayesian Optimization of Stacking. Electronics 2023, 12, 1744. https://doi.org/10.3390/electronics12071744
Liu L, Zhang Z, Qu Z, Bell A. Remaining Useful Life Prediction for a Catenary, Utilizing Bayesian Optimization of Stacking. Electronics. 2023; 12(7):1744. https://doi.org/10.3390/electronics12071744
Chicago/Turabian StyleLiu, Li, Zhihui Zhang, Zhijian Qu, and Adrian Bell. 2023. "Remaining Useful Life Prediction for a Catenary, Utilizing Bayesian Optimization of Stacking" Electronics 12, no. 7: 1744. https://doi.org/10.3390/electronics12071744
APA StyleLiu, L., Zhang, Z., Qu, Z., & Bell, A. (2023). Remaining Useful Life Prediction for a Catenary, Utilizing Bayesian Optimization of Stacking. Electronics, 12(7), 1744. https://doi.org/10.3390/electronics12071744