
UnTiCk: Unsupervised Type-Aware Complex Logical Queries Reasoning over Knowledge Graphs


Abstract
1. Introduction
- We propose UnTiCk, an embedding-based unsupervised type-aware complex logical queries reasoning model. It is a novel solution that extends unsupervised type constraints to multi-hop complex logical query embedding models.
- We designed four type compatibility measurement meta-operations that reflect good modularity and generalization. They capture the diversity of entity types in different relations and locations in complex logical queries.
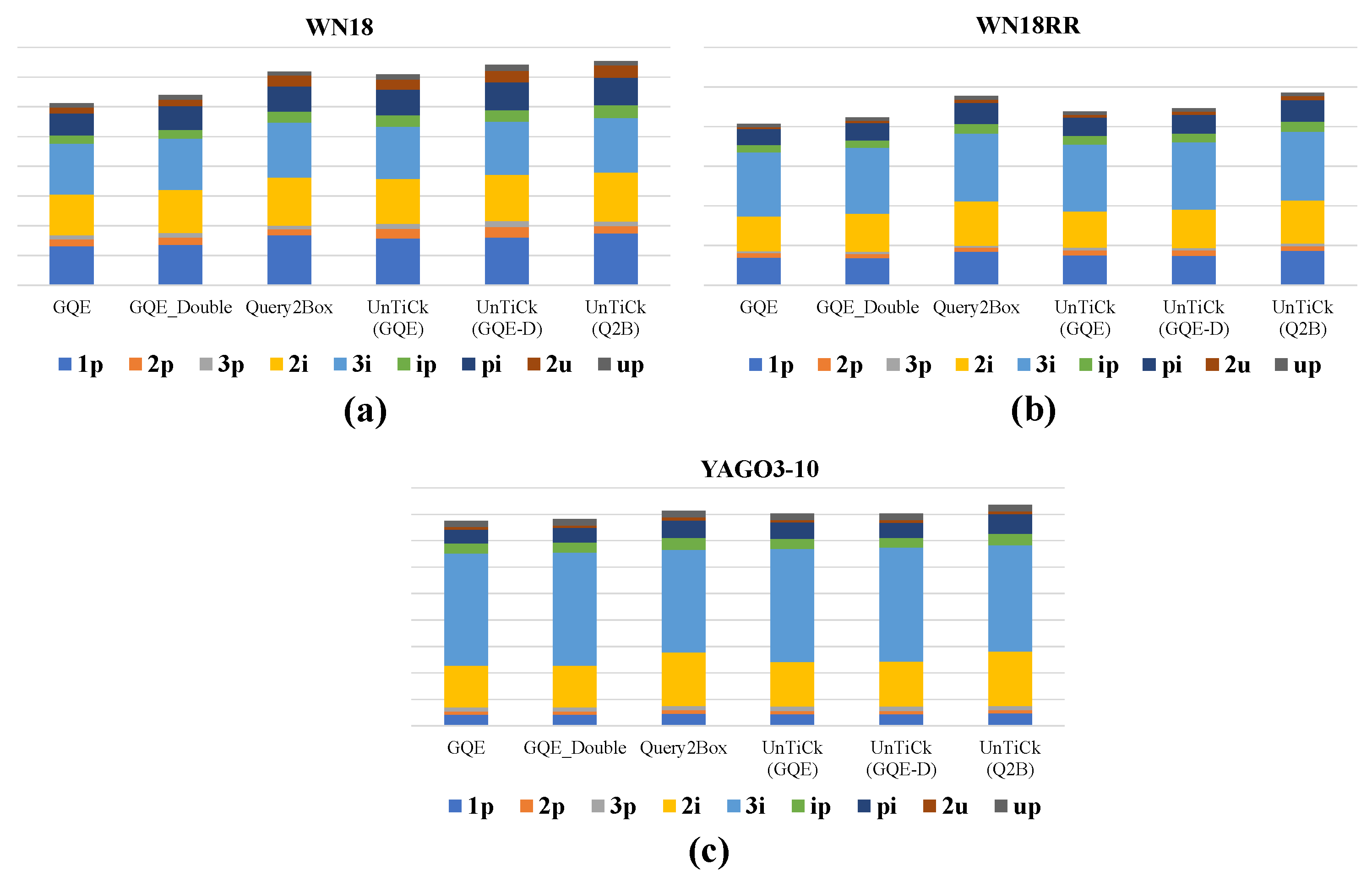
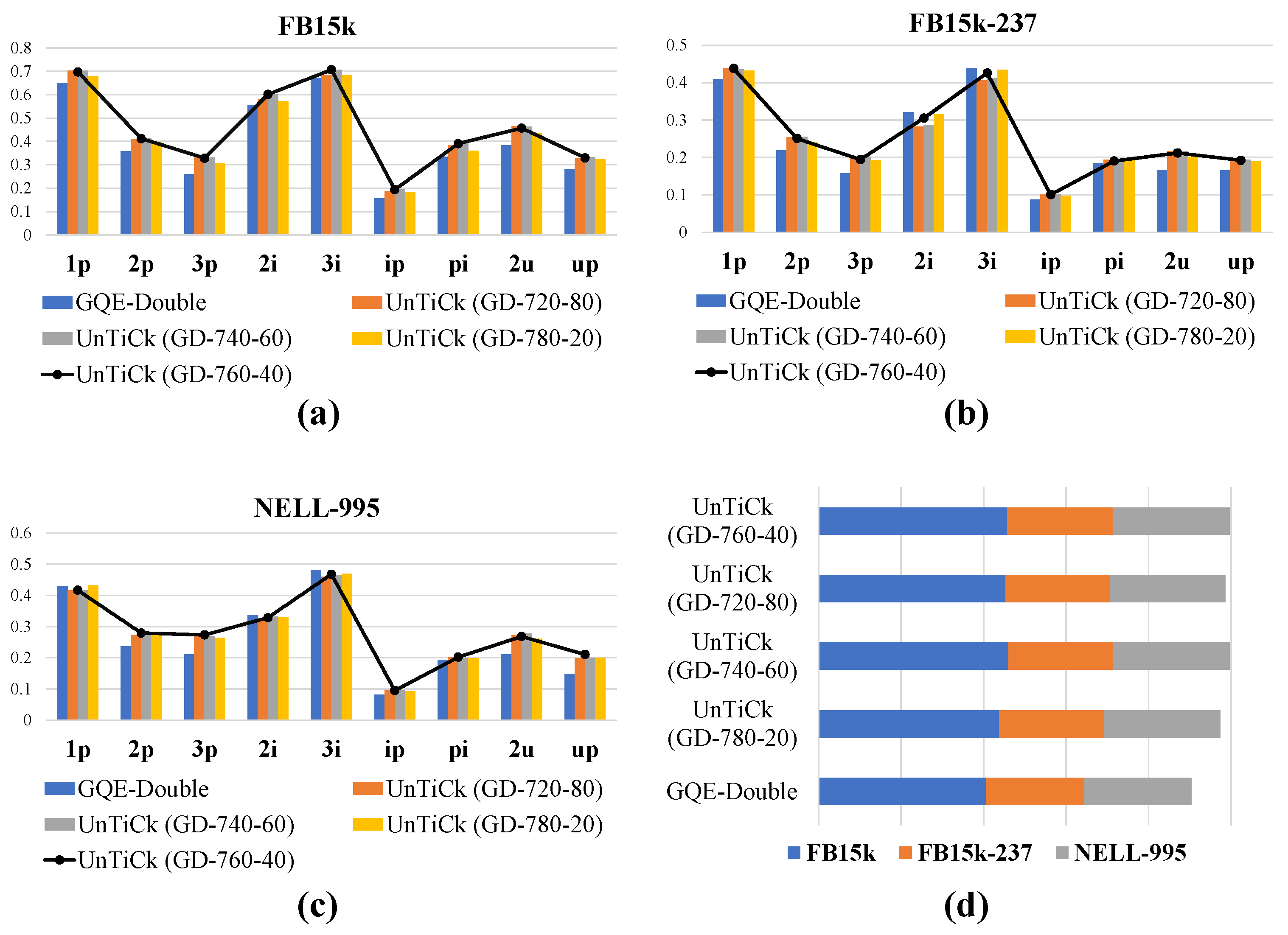
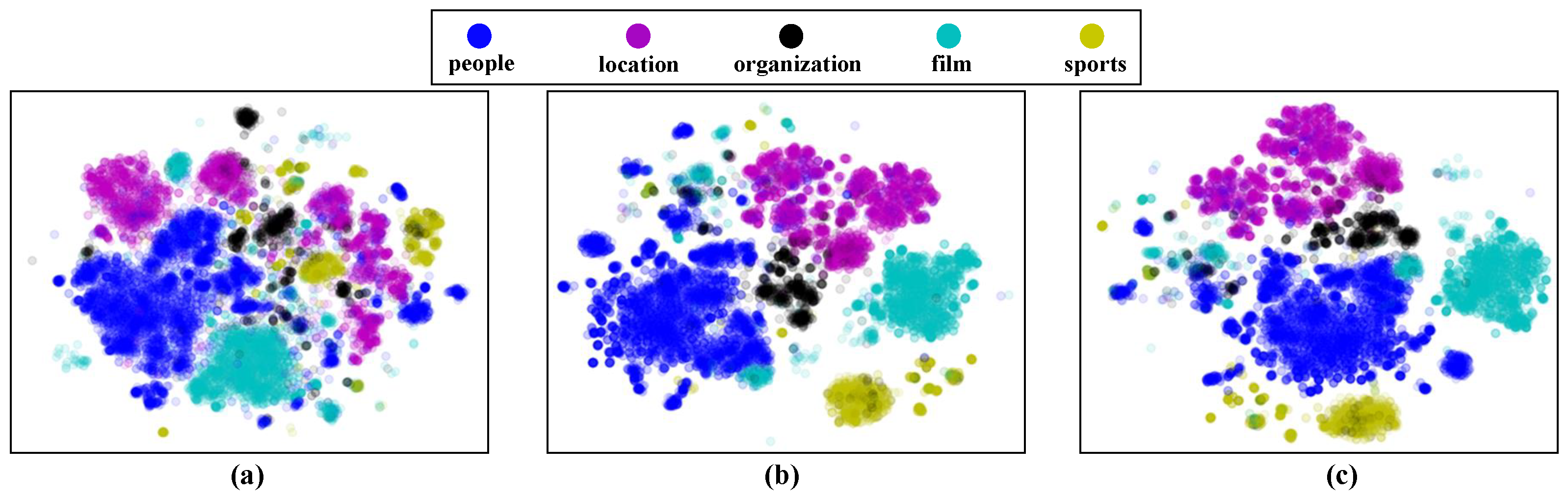
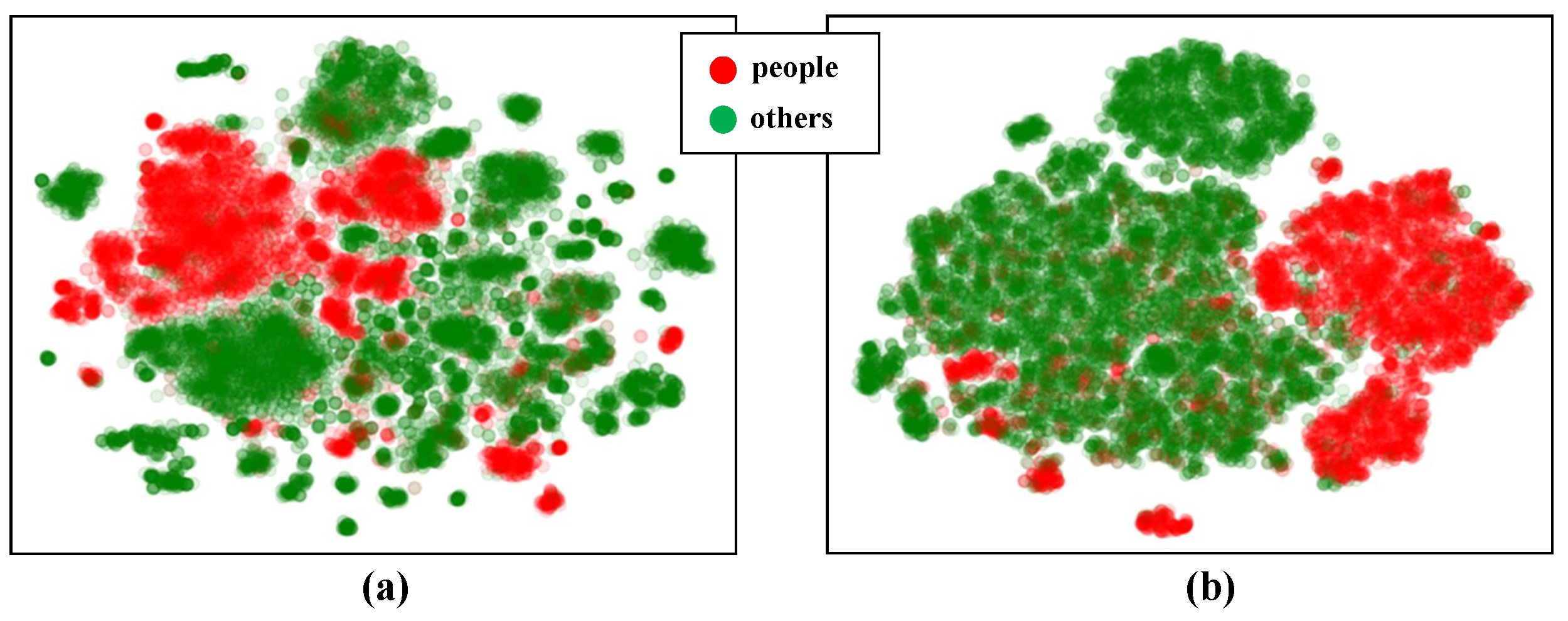
- We conducted experiments on three popular benchmark datasets, combining our model with popular complex logical embedding models. With the same number of embedding dimensions, our models showed better results than the complex logical embedding models, which contain only entity structure information. We also demonstrate the effectiveness of our unsupervised type feature extraction with a visualization.
2. Related Work
2.1. Logical Query Embedding Models for Multi-Hop Reasoning
2.2. Unsupervised Type Information Embedding Models
3. Background and Problem Definition
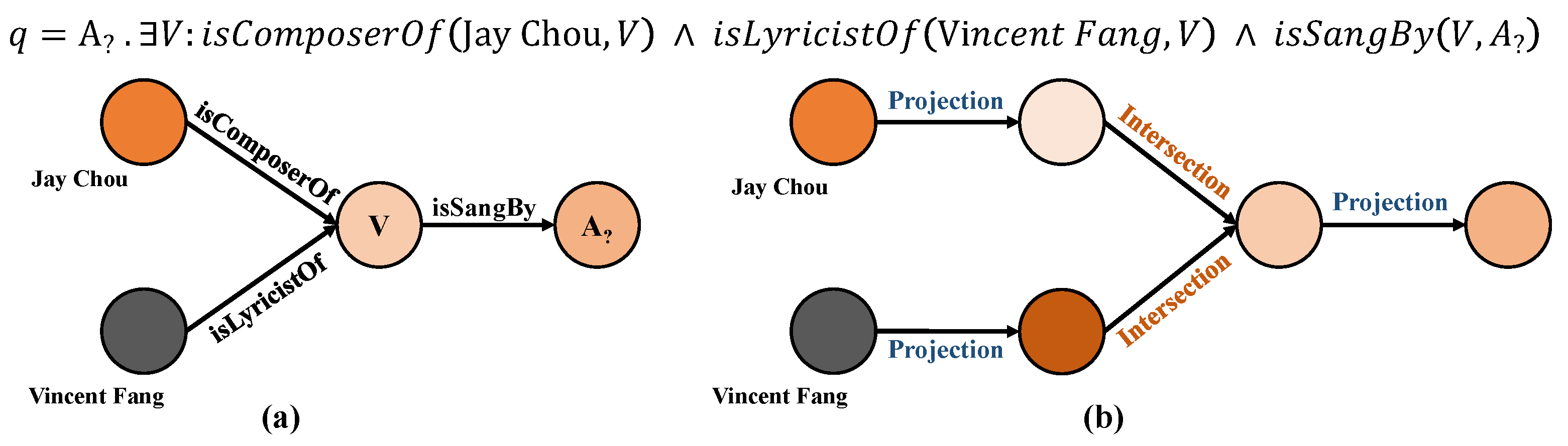
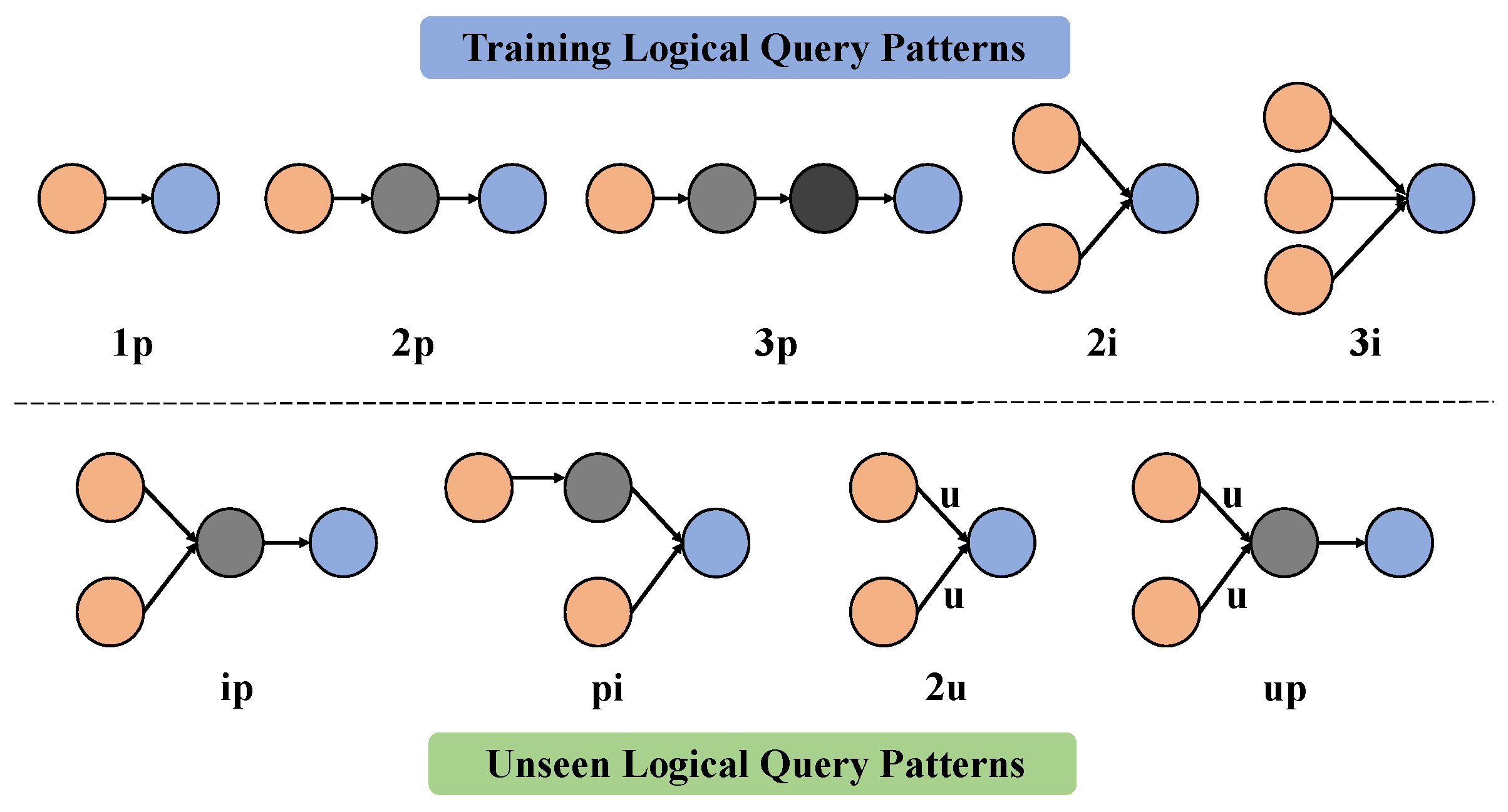
3.1. Logical Query Embedding Operators
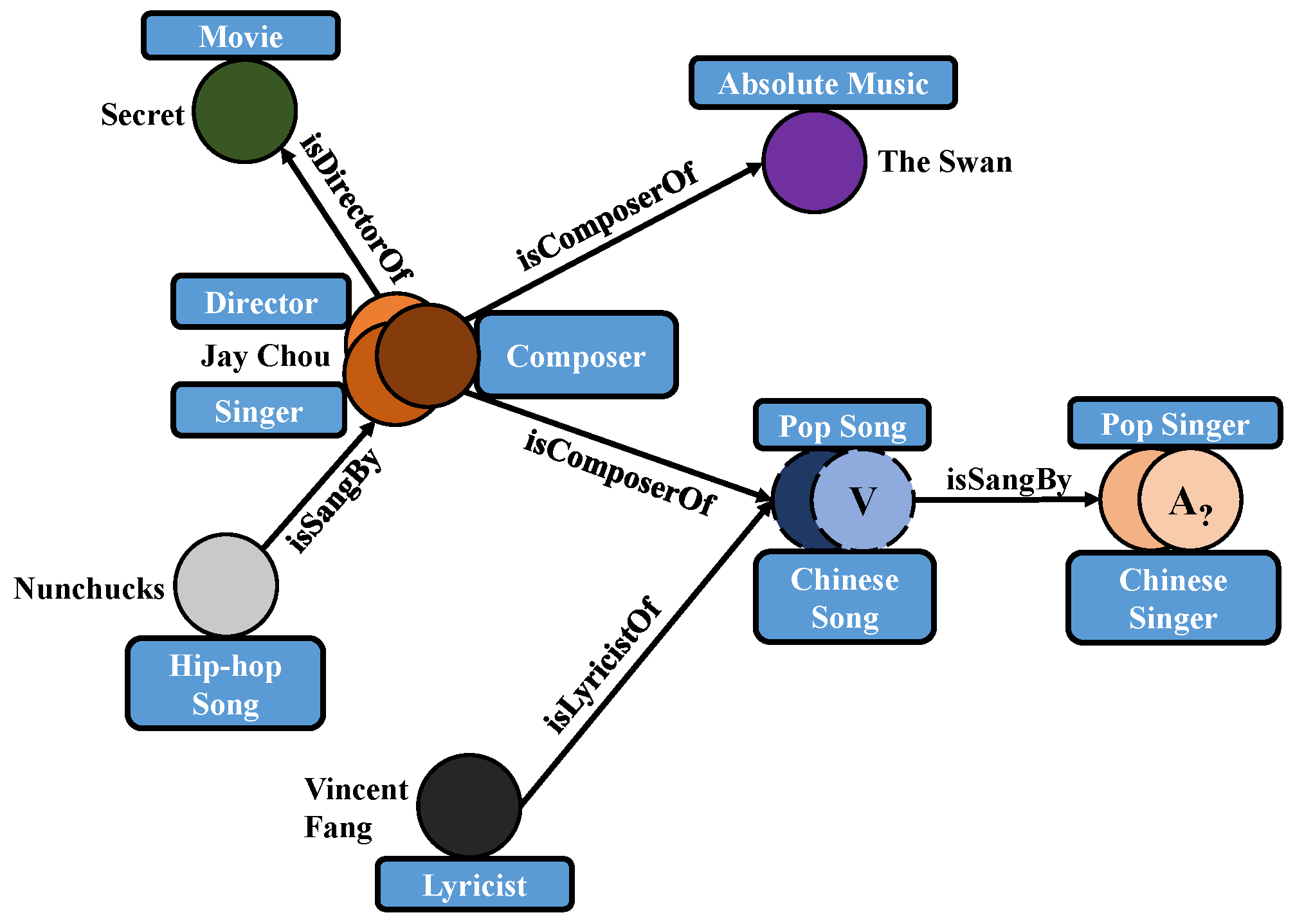
3.2. Type-Aware Logical Query Operations
3.3. UnTiCk Problem Definition
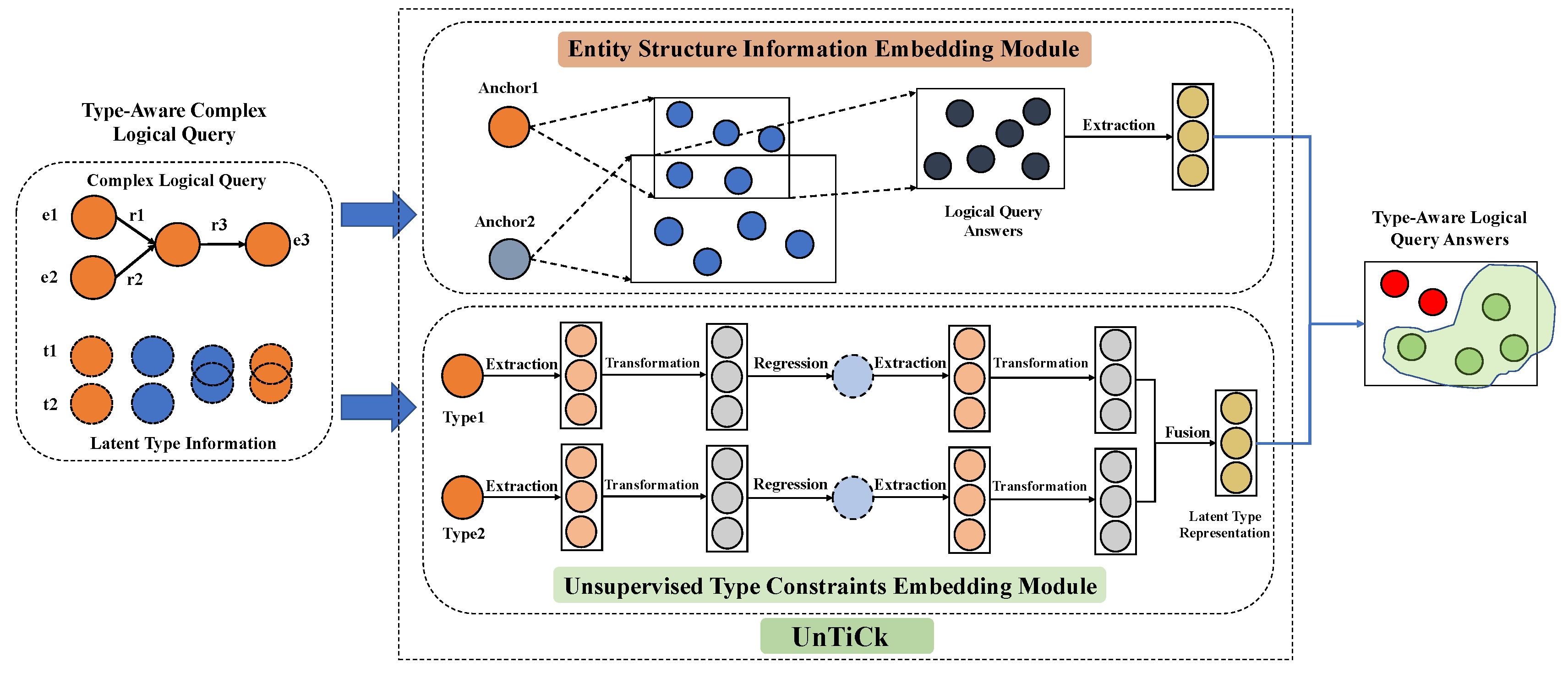
4. UnTiCk: Unsupervised Type-Aware Complex Logical Queries Reasoning Framework
4.1. Type Compatibility Measurement Meta-Operators
4.2. UnTiCk Query Reasoning Process
| Algorithm 1: UnTiCk query embedding generation |
 |
4.3. Optimization Objective
5. Experiments
5.1. Datasets
- FB15k: FB15k [4] is a subset created from Freebase and is a frequently used standard dataset for embedding knowledge graphs. It includes knowledge base relation triples and textual references to Freebase entity pairs.
- FB15k-237: FB15k-237 [41] is a variant of the original FB15k dataset in which inverse relations have been eliminated because it was discovered that inverting triplets in the training set yielded many test triplets, which may cause test leakage.
- WN18: WN18 [4] is a dataset commonly used for knowledge graph linkage prediction, deriving its name from it as a subset of WordNet containing 18 different relations. Its entities correspond to senses, and the relation types define the lexical relations between senses.
- WN18RR: WN18RR [43] is a subset created from WN18 in order to handle test leakage due to training set triplet inversion in WN18.
- YAGO3-10: YAGO3-10 is a publicly available and commonly used dataset, which is a subset of YAGO3 [44], which only contains entities with at least ten relations. Most triples are descriptive attributes of people. We processed it to fit our experiments, as described below.
5.2. Evaluation Metrics
5.3. Baselines and Hyperparameter Settings
- (1)
- (2)
- GQE-Double, which has the same basic model settings as GQE, but uses double-embedding dimensionality to enable the model dimensionality to be on the same level as other models;
- (3)
- Query2Box [21] models the query as a box embedding, projection as a linear transformation, intersection as the center using the attention mechanism, offset using Deepsets, and the sigmoid function to shrink, and union uses the same DNF-query rewriting strategy.
5.4. Experimental Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. YAGO: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Alberta, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A nucleus for a web of open data. In The Semantic Web; Aberer, K., Choi, K.S., Noy, N., Allemang, D., Lee, K.I., Nixon, L., Golbeck, J., Mika, P., Maynard, D., Mizoguchi, R., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A three-way model for collective learning on multi-relational data. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Yang, B.; Yih, S.W.t.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge graph embedding by relational rotation in complex space. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, L.; Wang, B.; Guo, L. Jointly embedding knowledge graphs and logical rules. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 192–202. [Google Scholar]
- Xiong, W.; Hoang, T.; Wang, W.Y. DeepPath: A reinforcement learning method for knowledge graph reasoning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 564–573. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, L.; Wang, B.; Guo, L. Knowledge graph embedding with iterative guidance from soft rules. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Wang, H.; Ren, H.; Leskovec, J. Relational message passing for knowledge graph completion. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021; pp. 1697–1707. [Google Scholar]
- Hamilton, W.; Bajaj, P.; Zitnik, M.; Jurafsky, D.; Leskovec, J. Embedding logical queries on knowledge graphs. In Proceedings of the 32th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Xie, R.; Liu, Z.; Sun, M. Representation learning of knowledge graphs with hierarchical types. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York City, NY, USA, 9–15 July 2016; pp. 2965–2971. [Google Scholar]
- Zhao, Y.; Zhang, A.; Xie, R.; Liu, K.; Wang, X. Connecting embeddings for knowledge graph entity typing. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 5–10 July 2020; pp. 6419–6428. [Google Scholar]
- Lu, Y.; Ichise, R. ProtoE: Enhancing knowledge graph completion models with unsupervised type representation learning. Information 2022, 13, 354:1–354:25. [Google Scholar] [CrossRef]
- Niu, G.; Li, B.; Zhang, Y.; Pu, S.; Li, J. AutoETER: Automated entity type representation for knowledge graph embedding. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Virtual, 16–20 November 2020; pp. 1172–1181. [Google Scholar]
- Jain, P.; Kumar, P.; Chakrabarti, S. Type-sensitive knowledge base inference without explicit type supervision. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Melbourne, Australia, 15–20 July 2018; pp. 75–80. [Google Scholar]
- Lu, Y.; Ichise, R. Unsupervised type constraint inference in bilinear knowledge graph completion models. In Proceedings of the 2021 IEEE International Conference on Big Knowledge (ICBK), Auckland, New Zealand, 7–8 December 2021; pp. 15–22. [Google Scholar]
- Ren, H.; Hu, W.; Leskovec, J. Query2box: Reasoning over knowledge graphs in vector space using box embeddings. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Liu, L.; Du, B.; Ji, H.; Zhai, C.; Tong, H. Neural-answering logical queries on knowledge graphs. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021; pp. 1087–1097. [Google Scholar]
- Ren, H.; Leskovec, J. Beta embeddings for multi-hop logical reasoning in knowledge graphs. In Proceedings of the the 34th International Conference on Neural Information Processing Systems, Virtual, 6–12 December 2020. [Google Scholar]
- Hu, Z.; Gutiérrez-Basulto, V.; Xiang, Z.; Li, X.; Li, R.; Pan, J.Z. Type-aware embeddings for multi-hop reasoning over knowledge graphs. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, Vienna, Austria, 23–29 July 2022; pp. 3078–3084. [Google Scholar]
- Wang, M.; Wang, R.; Liu, J.; Chen, Y.; Zhang, L.; Qi, G. Towards empty answers in SPARQL: Approximating querying with RDF embedding. In Proceedings of the International Semantic Web Conference, Monterey, CA, USA, 8–12 October 2018; pp. 513–529. [Google Scholar]
- Wang, Y.; Khan, A.; Wu, T.; Jin, J.; Yan, H. Semantic guided and response times bounded top-k similarity search over knowledge graphs. In Proceedings of the IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 445–456. [Google Scholar]
- Wang, Y.; Xu, X.; Hong, Q.; Jin, J.; Wu, T. Top-k star queries on knowledge graphs through semantic-aware bounding match scores. Knowl. Based Syst. 2021, 213, 106655. [Google Scholar] [CrossRef]
- Dalvi, N.N.; Suciu, D. Efficient query evaluation on probabilistic databases. VLDB J. 2007, 16, 523–544. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, J.; Chen, J.; Ji, S.; Wu, F. ConE: Cone embeddings for multi-hop reasoning over knowledge graphs. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, Virtual, 6–14 December 2021; pp. 19172–19183. [Google Scholar]
- Bai, J.; Wang, Z.; Zhang, H.; Song, Y. Query2Particles: Knowledge graph reasoning with particle embeddings. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, WA, USA, 10–15 July 2022; pp. 2703–2714. [Google Scholar]
- Ren, H.; Dai, H.; Dai, B.; Chen, X.; Yasunaga, M.; Sun, H.; Schuurmans, D.; Leskovec, J.; Zhou, D. LEGO: Latent execution-guided reasoning for multi-hop question answering on knowledge graphs. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8959–8970. [Google Scholar]
- Venn, J.I. On the diagrammatic and mechanical representation of propositions and reasonings. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1880, 10, 1–18. [Google Scholar] [CrossRef]
- Ma, S.; Ding, J.; Jia, W.; Wang, K.; Guo, M. TransT: Type-based multiple embedding representations for knowledge graph completion. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Skopje, Macedonia, 18–22 September 2017; pp. 717–733. [Google Scholar]
- Ge, X.; Wang, Y.C.; Wang, B.; Kuo, C.J. CORE: A knowledge graph entity type prediction method via complex space regression and embedding. Pattern Recognit. Lett. 2022, 157, 97–103. [Google Scholar] [CrossRef]
- Hu, Z.; Gutiérrez-Basulto, V.; Xiang, Z.; Li, R.; Pan, J.Z. Transformer-based entity typing in knowledge graphs. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 5988–6001. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Guu, K.; Miller, J.; Liang, P. Traversing knowledge graphs in vector space. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 318–327. [Google Scholar]
- Zaheer, M.; Kottur, S.; Ravanbakhsh, S.; Poczos, B.; Salakhutdinov, R.R.; Smola, A.J. Deep sets. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Davey, B.A.; Priestley, H.A. Introduction to Lattices and Order, 2nd ed.; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations Workshop, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Toutanova, K.; Chen, D. Observed versus latent features for knowledge base and text inference. In Proceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality, Beijing, China, 31 July 2015; pp. 57–66. [Google Scholar]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R.; Mitchell, T.M. Toward an architecture for never-ending language learning. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Dettmers, T.; Pasquale, M.; Pontus, S.; Riedel, S. Convolutional 2D knowledge graph embeddings. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1811–1818. [Google Scholar]
- Mahdisoltani, F.; Biega, J.; Suchanek, F. YAGO3: A knowledge base from multilingual wikipedias. In Proceedings of the Seventh Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, 4–7 January 2015. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn Res. 2008, 9, 2579–2605. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fields | Model Name | Model Category | Type Constraint | ||
|---|---|---|---|---|---|
| Logical Query | Type Information | Unsupervised | Supervised | ||
| Logical Query Embedding | GQE [14] | Point | – | – | – |
| Query2Box [21] | Box region | – | – | – | |
| NewLook [22] | Box region | – | – | – | |
| BetaE [23] | Beta distribution | – | – | – | |
| Type Information Embedding | TypeDM and TypeComplex [19] | – | Entity-relation matching | 🗸 | |
| CooccurX [20] | – | Entity-relation matching | 🗸 | ||
| ProtoE [17] | – | Entity-relation matching | 🗸 | ||
| AutoETER [18] | – | Relation-specific extraction | 🗸 | ||
| TEMP [24] | Plug-in module | Message passing | 🗸 | ||
| Items | Statistics | Training | Validation | Test | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Entities | Relations | Single 1 | Complex 2 | Triples | Single | Complex | Triples | Single | Complex | Triples |
| FB15k | 14,951 | 1345 | 273,710 | 273,710 | 483,142 | 59,097 | 8000 | 50,000 | 67,016 | 8000 | 59,071 |
| FB15k-237 | 14,505 | 237 | 149,689 | 149,689 | 272,115 | 20,101 | 5000 | 17,526 | 22,812 | 5000 | 20,438 |
| NELL-995 | 63,361 | 200 | 107,982 | 107,982 | 114,213 | 16,927 | 4000 | 14,324 | 17,034 | 4000 | 14,267 |
| WN18 | 40,943 | 18 | 171,254 | 171,254 | 141,442 | 9006 | 3000 | 5000 | 9028 | 3000 | 5000 |
| WN18RR | 40,943 | 11 | 103,509 | 103,509 | 86,835 | 5202 | 2000 | 3034 | 5356 | 2000 | 3034 |
| YAGO3-10 | 51,374 | 36 | 64,420 | 40,000 | 53,554 | 3998 | 1500 | 2250 | 4160 | 1500 | 2333 |
| Datasets | Models | Avg | 1p | 2p | 3p | 2i | 3i | ip | pi | 2u | up |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FB15k | GQE | 0.3979 | 0.6448 | 0.3508 | 0.2543 | 0.5434 | 0.6567 | 0.1491 | 0.3191 | 0.3865 | 0.2764 |
| GQE-Double | 0.4058 | 0.6498 | 0.3578 | 0.2596 | 0.5566 | 0.6732 | 0.1564 | 0.3349 | 0.3828 | 0.2812 | |
| Query2Box | 0.4872 | 0.7883 | 0.4175 | 0.3087 | 0.5908 | 0.7119 | 0.2111 | 0.4124 | 0.6122 | 0.3317 | |
| UnTiCk (GQE) | 0.4484 | 0.6924 | 0.4071 | 0.3191 | 0.5843 | 0.6869 | 0.1846 | 0.3759 | 0.4576 | 0.3275 | |
| UnTiCk (GQE-D) | 0.4577 | 0.6977 | 0.4124 | 0.3287 | 0.6016 | 0.7068 | 0.1937 | 0.3909 | 0.4571 | 0.3300 | |
| UnTiCk (Q2B) | 0.5010 | 0.7913 | 0.4420 | 0.3547 | 0.6178 | 0.7310 | 0.2286 | 0.4413 | 0.6199 | 0.3631 | |
| FB15k-237 | GQE | 0.2305 | 0.4044 | 0.2141 | 0.1557 | 0.2993 | 0.4179 | 0.0859 | 0.1728 | 0.1634 | 0.1613 |
| GQE-Double | 0.2388 | 0.4100 | 0.2190 | 0.1577 | 0.3206 | 0.4374 | 0.0877 | 0.1851 | 0.1662 | 0.1656 | |
| Query2Box | 0.2702 | 0.4692 | 0.2504 | 0.1893 | 0.3208 | 0.4486 | 0.1091 | 0.2087 | 0.2453 | 0.1902 | |
| UnTiCk (GQE) | 0.2473 | 0.4286 | 0.2465 | 0.1932 | 0.2829 | 0.3999 | 0.0961 | 0.1795 | 0.2080 | 0.1914 | |
| UnTiCk (GQE-D) | 0.2565 | 0.4378 | 0.2507 | 0.1943 | 0.3049 | 0.4258 | 0.1006 | 0.1906 | 0.2120 | 0.1922 | |
| UnTiCk (Q2B) | 0.2753 | 0.4715 | 0.2619 | 0.2082 | 0.3056 | 0.4471 | 0.1122 | 0.2061 | 0.2562 | 0.2087 | |
| NELL-995 | GQE | 0.2514 | 0.4262 | 0.2295 | 0.2060 | 0.3205 | 0.4585 | 0.0788 | 0.1840 | 0.2120 | 0.1468 |
| GQE-Double | 0.2588 | 0.4282 | 0.2368 | 0.2110 | 0.3369 | 0.4821 | 0.0814 | 0.1930 | 0.2113 | 0.1481 | |
| Query2Box | 0.3078 | 0.5549 | 0.2652 | 0.2354 | 0.3492 | 0.4822 | 0.1328 | 0.2113 | 0.3695 | 0.1693 | |
| UnTiCk (GQE) | 0.2770 | 0.4165 | 0.2685 | 0.2659 | 0.3205 | 0.4585 | 0.0910 | 0.1972 | 0.2745 | 0.2000 | |
| UnTiCk (GQE-D) | 0.2823 | 0.4166 | 0.2793 | 0.2731 | 0.3286 | 0.4678 | 0.0948 | 0.2020 | 0.2684 | 0.2104 | |
| UnTiCk (Q2B) | 0.3189 | 0.5457 | 0.2936 | 0.2800 | 0.3431 | 0.4804 | 0.1349 | 0.2123 | 0.3781 | 0.2017 |
| Datasets | Models | Avg | 1p | 2p | 3p | 2i | 3i | ip | pi | 2u | up |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FB15k | GQE | 0.3371 | 0.5114 | 0.3056 | 0.2241 | 0.4614 | 0.5626 | 0.1375 | 0.2769 | 0.3066 | 0.2479 |
| GQE-Double | 0.3440 | 0.5067 | 0.3113 | 0.2274 | 0.4775 | 0.5840 | 0.1449 | 0.2910 | 0.3024 | 0.2509 | |
| Query2Box | 0.4153 | 0.6604 | 0.3795 | 0.2778 | 0.4934 | 0.6021 | 0.1933 | 0.3499 | 0.4762 | 0.3053 | |
| UnTiCk (GQE) | 0.3909 | 0.5816 | 0.3721 | 0.2933 | 0.5025 | 0.6030 | 0.1703 | 0.3258 | 0.3697 | 0.3000 | |
| UnTiCk (GQE-D) | 0.3987 | 0.5764 | 0.3773 | 0.2991 | 0.5201 | 0.6239 | 0.1782 | 0.3420 | 0.3649 | 0.3065 | |
| UnTiCk (Q2B) | 0.4396 | 0.6760 | 0.4048 | 0.3208 | 0.5209 | 0.6266 | 0.2081 | 0.3775 | 0.4882 | 0.3334 | |
| FB15k-237 | GQE | 0.2047 | 0.3469 | 0.1941 | 0.1430 | 0.2566 | 0.3631 | 0.0850 | 0.1583 | 0.1441 | 0.1509 |
| GQE-Double | 0.2127 | 0.3503 | 0.1965 | 0.1477 | 0.2776 | 0.3860 | 0.0893 | 0.1690 | 0.1467 | 0.1512 | |
| Query2Box | 0.2369 | 0.4033 | 0.2276 | 0.1760 | 0.2737 | 0.3769 | 0.1060 | 0.1847 | 0.2050 | 0.1793 | |
| UnTiCk (GQE) | 0.2218 | 0.3754 | 0.2242 | 0.1794 | 0.2458 | 0.3541 | 0.0953 | 0.1663 | 0.1768 | 0.1751 | |
| UnTiCk (GQE-D) | 0.2286 | 0.3772 | 0.2279 | 0.1815 | 0.2657 | 0.3774 | 0.0973 | 0.1748 | 0.1766 | 0.1792 | |
| UnTiCk (Q2B) | 0.2414 | 0.4100 | 0.2397 | 0.1917 | 0.2654 | 0.3765 | 0.1061 | 0.1821 | 0.2080 | 0.1935 | |
| NELL-995 | GQE | 0.2133 | 0.3161 | 0.1952 | 0.1769 | 0.2799 | 0.4072 | 0.0780 | 0.1667 | 0.1647 | 0.1349 |
| GQE-Double | 0.2188 | 0.3189 | 0.1999 | 0.1797 | 0.2901 | 0.4274 | 0.0791 | 0.1744 | 0.1643 | 0.1352 | |
| Query2Box | 0.2560 | 0.4145 | 0.2297 | 0.2106 | 0.2915 | 0.4183 | 0.1251 | 0.1918 | 0.2657 | 0.1566 | |
| UnTiCk (GQE) | 0.2364 | 0.3228 | 0.2329 | 0.2371 | 0.2766 | 0.4039 | 0.0871 | 0.1815 | 0.2073 | 0.1781 | |
| UnTiCk (GQE-D) | 0.2419 | 0.3253 | 0.2409 | 0.2408 | 0.2856 | 0.4157 | 0.0899 | 0.1846 | 0.2110 | 0.1837 | |
| UnTiCk (Q2B) | 0.2658 | 0.4106 | 0.2494 | 0.2513 | 0.2879 | 0.4156 | 0.1253 | 0.1935 | 0.2766 | 0.1816 |
| Datasets | Models | Avg | 1p | 2p | 3p | 2i | 3i | ip | pi | 2u | up |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FB15k | GQE | 0.2185 | 0.3310 | 0.2009 | 0.1400 | 0.3213 | 0.4214 | 0.0786 | 0.1690 | 0.1492 | 0.1554 |
| GQE-Double | 0.2234 | 0.3171 | 0.2032 | 0.1391 | 0.3392 | 0.4499 | 0.0826 | 0.1829 | 0.1411 | 0.1555 | |
| Query2Box | 0.2904 | 0.5043 | 0.2790 | 0.1867 | 0.3442 | 0.4553 | 0.1183 | 0.2271 | 0.2879 | 0.2107 | |
| UnTiCk (GQE) | 0.2758 | 0.4291 | 0.2759 | 0.2039 | 0.3696 | 0.4753 | 0.1006 | 0.2097 | 0.2116 | 0.2068 | |
| UnTiCk (GQE-D) | 0.2829 | 0.4147 | 0.2804 | 0.2077 | 0.3895 | 0.5012 | 0.1072 | 0.2285 | 0.2029 | 0.2136 | |
| UnTiCk (Q2B) | 0.3175 | 0.5326 | 0.3068 | 0.2235 | 0.3762 | 0.4871 | 0.1316 | 0.2537 | 0.3095 | 0.2367 | |
| FB15k-237 | GQE | 0.1203 | 0.2277 | 0.1196 | 0.0818 | 0.1433 | 0.2455 | 0.0430 | 0.0868 | 0.0540 | 0.0806 |
| GQE-Double | 0.1277 | 0.2295 | 0.1198 | 0.0861 | 0.1653 | 0.2719 | 0.0472 | 0.0963 | 0.0543 | 0.0785 | |
| Query2Box | 0.1432 | 0.2791 | 0.1457 | 0.1077 | 0.1541 | 0.2472 | 0.0559 | 0.1025 | 0.0917 | 0.1049 | |
| UnTiCk (GQE) | 0.1354 | 0.2614 | 0.1447 | 0.1104 | 0.1403 | 0.2418 | 0.0500 | 0.0944 | 0.0771 | 0.0988 | |
| UnTiCk (GQE-D) | 0.1415 | 0.2587 | 0.1467 | 0.1114 | 0.1595 | 0.2681 | 0.0503 | 0.1027 | 0.0730 | 0.1032 | |
| UnTiCk (Q2B) | 0.1495 | 0.2903 | 0.1604 | 0.1206 | 0.1467 | 0.2477 | 0.0554 | 0.1051 | 0.1017 | 0.1176 | |
| NELL-995 | GQE | 0.1140 | 0.1481 | 0.1026 | 0.0952 | 0.1598 | 0.2852 | 0.0363 | 0.0960 | 0.0436 | 0.0594 |
| GQE-Double | 0.1186 | 0.1513 | 0.1055 | 0.0963 | 0.1678 | 0.3082 | 0.0363 | 0.1012 | 0.0435 | 0.0569 | |
| Query2Box | 0.1466 | 0.2309 | 0.1336 | 0.1298 | 0.1655 | 0.2883 | 0.0727 | 0.1164 | 0.1036 | 0.0786 | |
| UnTiCk (GQE) | 0.1348 | 0.1719 | 0.1371 | 0.1492 | 0.1587 | 0.2850 | 0.0400 | 0.1090 | 0.0696 | 0.0925 | |
| UnTiCk (GQE-D) | 0.1404 | 0.1742 | 0.1469 | 0.1520 | 0.1679 | 0.2990 | 0.0408 | 0.1115 | 0.0740 | 0.0970 | |
| UnTiCk (Q2B) | 0.1563 | 0.2329 | 0.1522 | 0.1671 | 0.1651 | 0.2882 | 0.0712 | 0.1177 | 0.1147 | 0.0972 |
| Datasets | Models | Avg | 1p | 2p | 3p | 2i | 3i | ip | pi | 2u | up |
|---|---|---|---|---|---|---|---|---|---|---|---|
| FB15k | GQE | 0.5574 | 0.8136 | 0.5046 | 0.3825 | 0.7212 | 0.8151 | 0.2485 | 0.4876 | 0.6125 | 0.4314 |
| GQE-Double | 0.5687 | 0.8220 | 0.5142 | 0.3901 | 0.7362 | 0.8276 | 0.2643 | 0.5034 | 0.6196 | 0.4410 | |
| Query2Box | 0.6422 | 0.9060 | 0.5799 | 0.4536 | 0.7564 | 0.8518 | 0.3384 | 0.5812 | 0.8112 | 0.5013 | |
| UnTiCk (GQE) | 0.6090 | 0.8379 | 0.5621 | 0.4752 | 0.7474 | 0.8371 | 0.3039 | 0.5531 | 0.6749 | 0.4896 | |
| UnTiCk (GQE-D) | 0.6173 | 0.8425 | 0.5729 | 0.4809 | 0.7586 | 0.8472 | 0.3137 | 0.5669 | 0.6723 | 0.5009 | |
| UnTiCk (Q2B) | 0.6611 | 0.9013 | 0.6042 | 0.5096 | 0.7748 | 0.8646 | 0.3544 | 0.6108 | 0.7993 | 0.5312 | |
| FB15k-237 | GQE | 0.3711 | 0.5741 | 0.3349 | 0.2625 | 0.4881 | 0.5976 | 0.1618 | 0.2965 | 0.3337 | 0.2909 |
| GQE-Double | 0.3802 | 0.5773 | 0.3428 | 0.2704 | 0.5047 | 0.6140 | 0.1661 | 0.3101 | 0.3417 | 0.2950 | |
| Query2Box | 0.4207 | 0.6402 | 0.3887 | 0.3128 | 0.5119 | 0.6225 | 0.2014 | 0.3432 | 0.4396 | 0.3257 | |
| UnTiCk (GQE) | 0.3921 | 0.5945 | 0.3824 | 0.3192 | 0.4593 | 0.5758 | 0.1801 | 0.3062 | 0.3837 | 0.3275 | |
| UnTiCk (GQE-D) | 0.4004 | 0.6023 | 0.3869 | 0.3228 | 0.4826 | 0.5906 | 0.1843 | 0.3147 | 0.3871 | 0.3327 | |
| UnTiCk (Q2B) | 0.4251 | 0.6410 | 0.4042 | 0.3399 | 0.4925 | 0.6161 | 0.2016 | 0.3362 | 0.4413 | 0.3527 | |
| NELL-995 | GQE | 0.4076 | 0.6047 | 0.3767 | 0.3252 | 0.5386 | 0.6546 | 0.1526 | 0.3044 | 0.4151 | 0.2967 |
| GQE-Double | 0.4151 | 0.6111 | 0.3829 | 0.3341 | 0.5461 | 0.6666 | 0.1581 | 0.3151 | 0.4190 | 0.3033 | |
| Query2Box | 0.4673 | 0.7116 | 0.4244 | 0.3652 | 0.5534 | 0.6757 | 0.2265 | 0.3417 | 0.5784 | 0.3289 | |
| UnTiCk (GQE) | 0.4392 | 0.5912 | 0.4313 | 0.4095 | 0.5219 | 0.6429 | 0.1762 | 0.3239 | 0.4903 | 0.3660 | |
| UnTiCk (GQE-D) | 0.4426 | 0.5915 | 0.4331 | 0.4088 | 0.5280 | 0.6502 | 0.1845 | 0.3263 | 0.4955 | 0.3659 | |
| UnTiCk (Q2B) | 0.4765 | 0.6983 | 0.4419 | 0.4176 | 0.5448 | 0.6686 | 0.2275 | 0.3386 | 0.5913 | 0.3600 |
| Anchor Entities | Relation | Target Entities | Query2Box Predication | UnTiCk (Q2B) Predication |
|---|---|---|---|---|
| The Last King of Scotland (film) | (1) films_in_this_ genre_reverse, (2) titles, (3) production_ companies | (1) Channel 4 (organization), (2) SONY (organization) | (1) Walt Disney Animation Studios (organization), (2) Walt Disney Studios Motion Pictures (organization), (3) drama film (film_genre), (4) Pixar (organization), (5) historical drama (film_genre) | (1) Walt Disney Animation Studios (organization), (2) Magnolia Pictures (organization), (3) Walt Disney Studios MotionPictures (organization), (4) Pixar (organization), (5) BBC (organization) |
| (1) Chester County (location), (2) Latin Grammy Award for Album of the Year (award_category) | (1) contains, (2) award_reverse, (3) people_with_ this_profession_ reverse | (1) model (profession), (2) audio engineer (profession), (3) songwriter (profession) | (1) songwriter (profession), (2) Chester County (location), (3) composer (profession), (4) actor (profession), (5) artist (profession) | (1) songwriter (profession), (2) artist (profession), (3) actor (profession), (4) composer (profession), (5) guitarist (profession) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Li, Q.; Gu, J. UnTiCk: Unsupervised Type-Aware Complex Logical Queries Reasoning over Knowledge Graphs. Electronics 2023, 12, 1445. https://doi.org/10.3390/electronics12061445
Chen D, Li Q, Gu J. UnTiCk: Unsupervised Type-Aware Complex Logical Queries Reasoning over Knowledge Graphs. Electronics. 2023; 12(6):1445. https://doi.org/10.3390/electronics12061445
Chicago/Turabian StyleChen, Deyu, Qiyuan Li, and Jinguang Gu. 2023. "UnTiCk: Unsupervised Type-Aware Complex Logical Queries Reasoning over Knowledge Graphs" Electronics 12, no. 6: 1445. https://doi.org/10.3390/electronics12061445
APA StyleChen, D., Li, Q., & Gu, J. (2023). UnTiCk: Unsupervised Type-Aware Complex Logical Queries Reasoning over Knowledge Graphs. Electronics, 12(6), 1445. https://doi.org/10.3390/electronics12061445