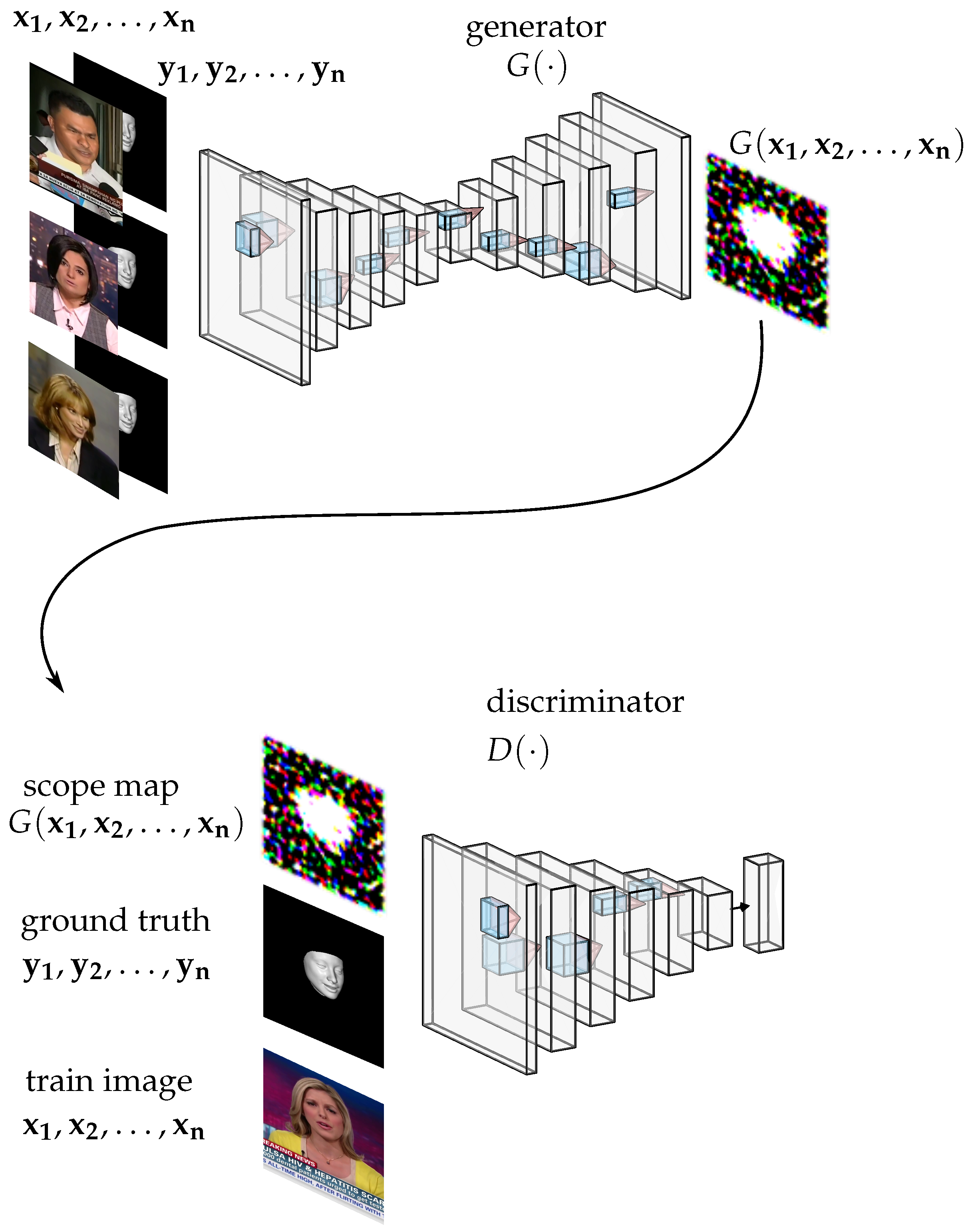
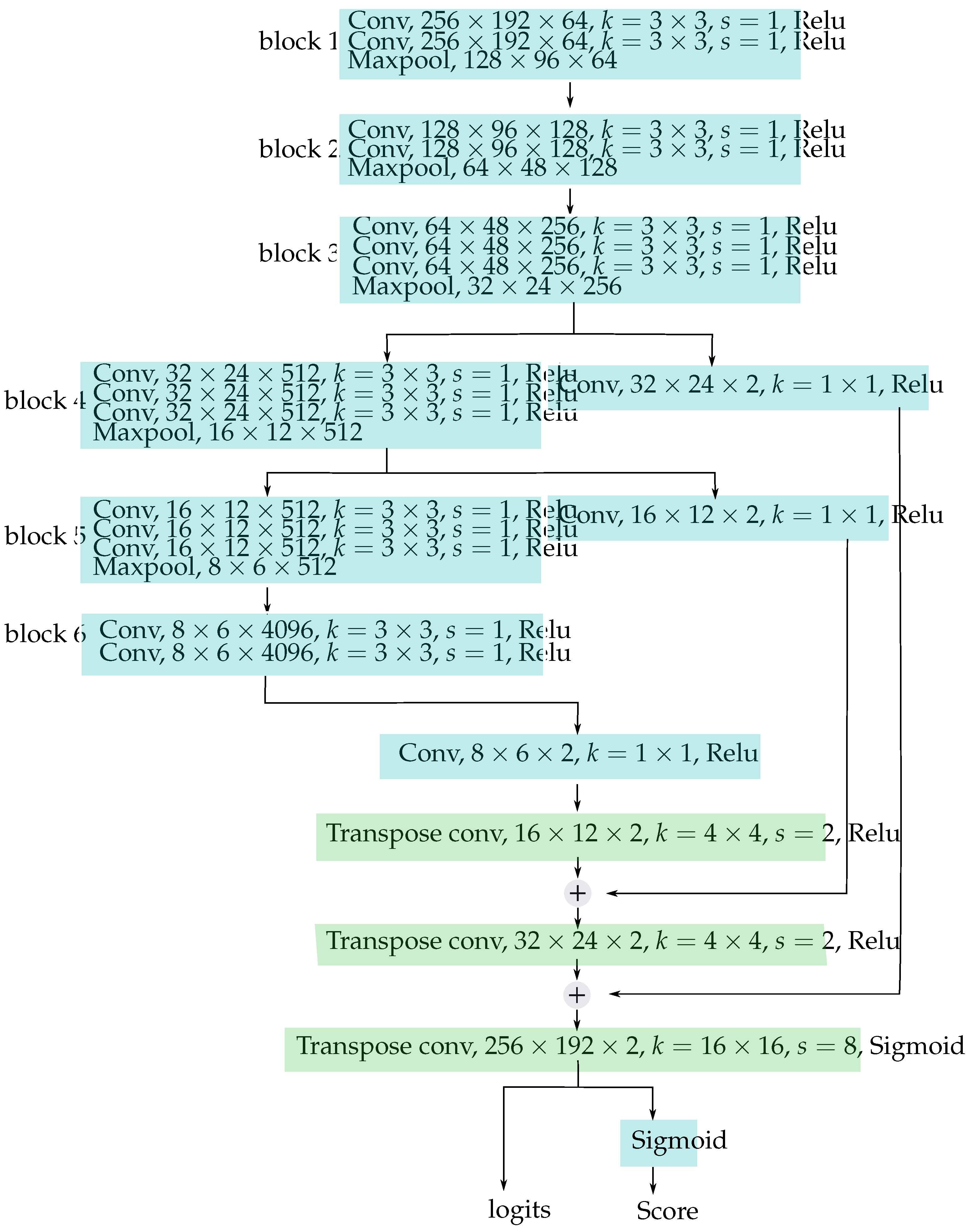
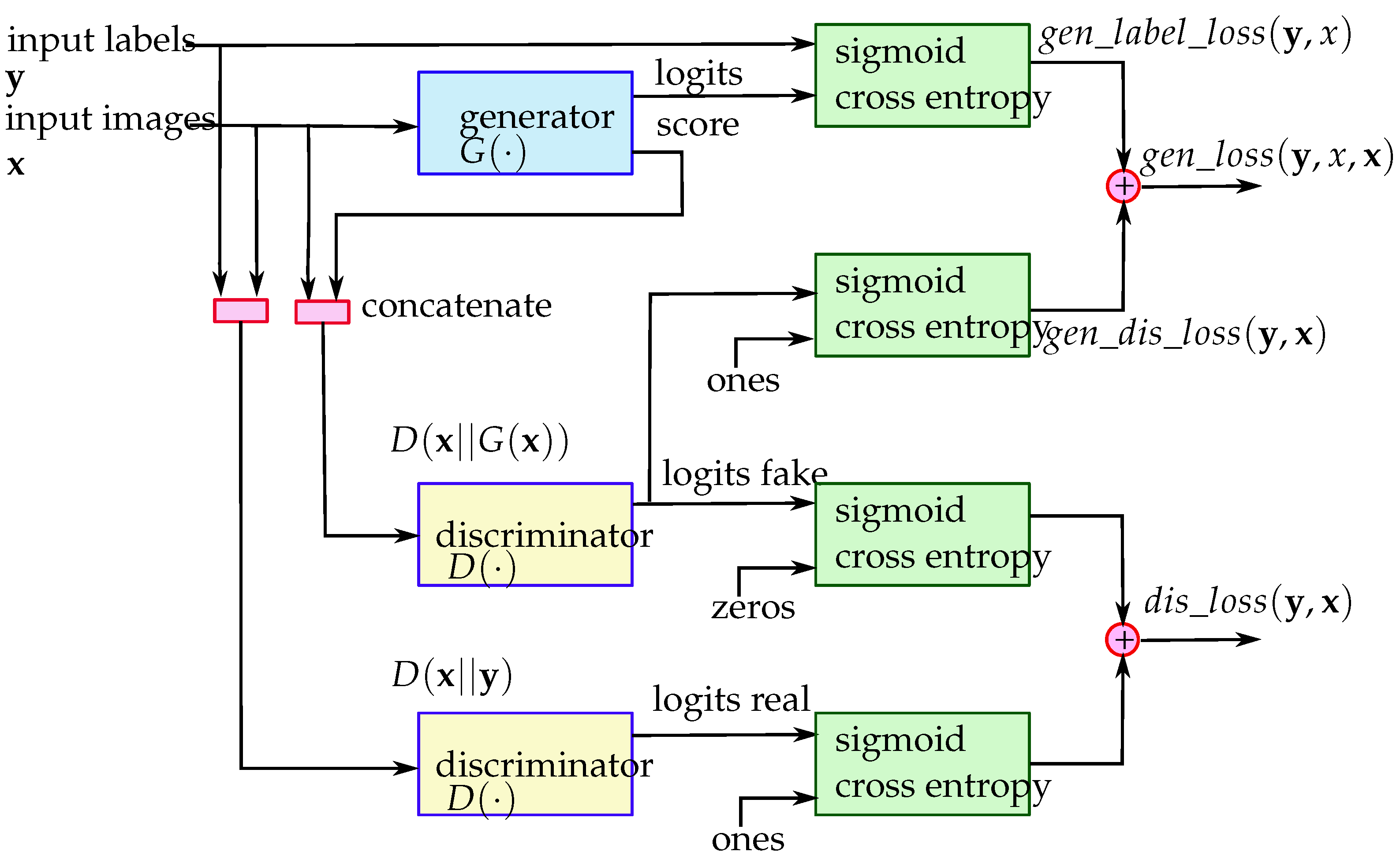
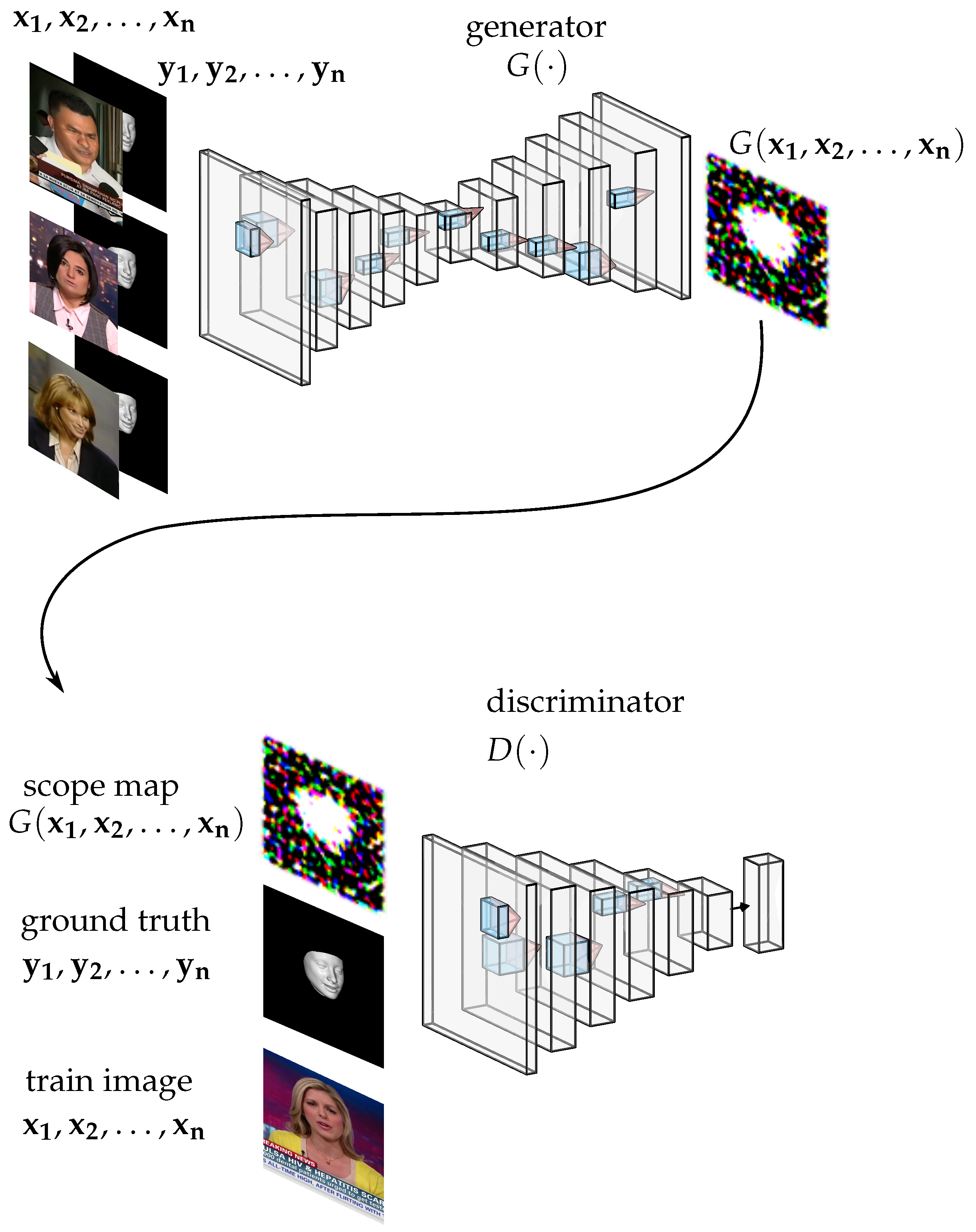
4.1. Experimental Design and Data Collection
To evaluate the proposed method, the dataset
FaceForensics++ [
9] is used to demonstrate the ability of our fake face detection method. The dataset
FaceForensics++ contains 1000 videos. The authors of the dataset downloaded these 1000 videos from YouTube. Figure 3 of paper [
9] shows that there are slightly more female characters in the videos compared to male characters. Every video is compressed to two different quality levels: C23 (constant rate quantization parameter equal to
C23) and C0 (constant rate quantization parameter equal to
C0). Each video is manipulated by three manipulation methods
Deepfakes [
1],
Face2Face [
12], and
FaceSwap [
13]. The 1.5 million frames are extracted from the manipulated videos. To compare our experiments with the results mentioned in [
9,
10], we use the same partition settings of the training and testing sets as conducted in the experiments in [
9,
10]. That is, the videos 0–719 are adopted to be the training set and the videos 860–999 are used as the testing set. The dataset
FaceForensics++ comprises ground truth masks that serve as indicators of pixel modifications, denoting whether a pixel has been altered or not. We use ground truth masks to train our model. All experiments in this thesis are conducted using a personal computer equipped with an Intel i7-6850K CPU running at 3.60 GHz and a Nvidia 2080ti GPU. The algorithms for training and inference are implemented using the Python programming language with the TensorFlow library. During model training and fine-tuning, the batch size is set to 10 and the learning rate to 0.0001. The optimizer used for training is “Admin”, and the termination condition for training is fixed at 400 epochs. If the training epochs large than 1000, overfitting appears. The web-based inference of the proposed method is available at
https://ai.nptu.edu.tw/fsg (accessed on 1 February 2023).
Interested readers can utilize the proposed method through a web browser on a personal computer.
Since it is possible that the difference of the feature pattern contained in the background and face area can help the detection of a fake face, we evaluate the effect of different size background areas by setting two versions,
fullsize and
crop, for the training and testing sets. The size of images in the
crop version is
and the size of images in the
fullsize version is
. The
crop version is formed by cropping the area centred on the face from each image in
fullsize. The cropped areas are decided from the locations of the fake mask in the ground truth images provided by
FaceForensics++. See
Figure 6 for an illustration of the relation between the
crop and
fullsize images.
In this paper, the performance of solving the classification problem is evaluated by the metrics accuracy and the area under the receiver operating characteristic curve (AUC). Metric accuracy is widely used to measure the performance of diagnosis objects. For example, metric accuracy is used to evaluate the potential of deep learning methods in thyroid cancer diagnosis [
20]. However, accuracy may not be an appropriate metric for certain types of datasets or tasks, especially when the classes are imbalanced, e.g., when a set of real images have significantly fewer samples than a set of fake images. In such cases, a model that always predicts the ‘real’ would achieve high accuracy. However, our test set is balanced, containing an equal number of real and fake images. As such, we can safely use the metric accuracy. The performance of the segmentation problem is evaluated by the intersection over union (IoU) [
21]. The two evaluation metrics, IoU and Dice, are commonly used to compare the differences between the ground truth and predicted shapes. For instance, in study [
22], the Dice coefficient was utilized to quantify the predicted brain tumour segmentation. The IoU is defined as the area of the intersection between two objects divided by the area of their union. The Dice coefficient is defined as twice the area of the intersection between two objects divided by the sum of the areas of the two objects. According to the formula for the Dice coefficient, it can be observed that a high value is obtained when there is a balance between the true positive rate (TPR) and the positive predictive value (PPV). Since the medical field emphasizes the balance between TPR and PPV in research, the Dice coefficient is often utilized to assess performance in related segmentation studies in the medical field. However, in our work, the ground truth images are generated during the forgery stage that clearly delineate the forgery area. Thus, we do not require the aforementioned properties of the Dice coefficient. Another reason for using IoU in forgery detection research is that its definition is more intuitive and easier to understand in the context of segmentation of the forgery area.
The accuracy is defined as
where TP denotes true positives, TN denotes true negatives, FN denotes false negatives, and FP denotes false positives. Here, TP, TN, FN, and FP are calculated in the fake image classification result. A receiver operating characteristic curve (ROC curve) is a curve plotting the true positive rate fraction of the false positive rate at various thresholds. The area under the receiver operating characteristic curve (AUC) is the area under the ROC curve.
To evaluate the performance of solving the segmentation problem, the metric pixel-wise accuracy is used in some research [
10]. However, when the background area is larger than the target object, the term TN in the accuracy result from Formula (
1) dominates the metric value. Since annotations of the fake area focus on the fake face, the pixel-wise accuracy is not suitable for evaluating the performance of finding the fake area. Thus, in this paper, the segmentation of the fake area is evaluated by intersection over union (IoU) (also called the Jaccard similarity coefficient) [
21]. The IoU is defined as
where TP, TN, FN, and FP are calculated in the per pixel classification result and the
is a small value used to avoid division by zero. The problem of the IoU metric described by Equation (
2) is that when we send a real image into the proposed detector, the detector outputs a black image which is exactly the same as the ground truth, but the IoU of this perfect output black image and ground truth is 0. This situation can easily happen when we are testing a real image. If the input is a real image and the prediction of the proposed method is a small group of pixels, the IoU metric of the result and ground truth is 0. In fact, based on the IoU from Formula (
2), if the input is a real image, any segmentation result of the proposed method is measured as 0. Thus, the IoU metric is only used to measure the result of the detected fake image in this paper. See
Figure 7 for an illustrating of the detection result performed on real images. The left side of every pair of two subi-mages is the real image and the right side of every pair of sub-images is the detection result. As the figure illustrates, the proposed method is good at detecting real images. However, the resulting image is a perfect black image or if it contains a little white area, the IoU of the prediction and the ground truth is 0.
4.2. Data Analysis and Results
On the other hand, the metric IoU is suitable for measuring the images which contain the detection targets, which in our problem is fake faces.
Figure 2 and
Figure 7 show eight randomly selected images from the result of detecting the
Deepfakes fake and real images by the model trained with the
Deepfakes dataset. The left side of every pair of sub-images is the test image and the right side of every pair of sub-images is the prediction result. It is obvious that the score of IoU matches the visualization of the prediction results which contain fake images.
Figure 8 and
Figure 9 show similar results of detecting the
Face2Face dataset. Also,
Figure 10 and
Figure 11 show similar results of detecting the
FaceSwap dataset. Based on the comparison of
Figure 2 and
Figure 8, the IoU measuring the results of detecting
crop images in the
Face2Face dataset is lower than the IoU of measuring the result of images in the
Deepfakes on average.
We first experiment with images forged by the same forgery method in the training and testing sets. The result of testing the
crop C23 and C0 dataset altered by the three manipulation methods using the different trained models is shown in
Table 1. That is, we use the model trained by the
Deepfakes training set to test the testing set altered by the
Deepfakes method. Furthermore, we use the model trained by the
Face2Face training set to test the testing set produced by the
Face2Face method. Furthermore, we use the model trained by the
FaceSwap training set to test the testing set produced by the
FaceSwap method. The same experiment performed on the
fullsize dataset is shown in
Table 2. A comparison of the average IoU of images in the datasets
Deepfakes,
FaceSwap, and
Face2Face is shown in
Table 1 and
Table 2. The average IoU of detecting C23 and C0 quality images of
crop FaceSwap is 0.883 and 0.892, respectively. The average IoU of detecting the C23 and C0 of
crop Face2Face is 0.720 and 0.750, respectively. The average IoU of detecting the C23 and C0 of
crop Deepfakes is 0.938 and 0.941, respectively. These results show that the fakeness of C23 images is more difficult to detect than C0 images. As expected, the fuzzier the pictures, the harder it is to tell if they are fakes. That is, fainter images are less likely to be identified as forgeries.
To measure the effect of the background area, the average IoU of detecting
fullsize FaceSwap and
Deepfakes datasets are lower than detecting the
crop version. The average IoU of detecting C23 and C0 quality
fullsize FaceSwap images is 0.748 and 0.755, respectively. The average IoU of detecting C23 and C0 quality
fullsize Face2Face images is 0.744 and 0.787, respectively. The average IoU of detecting C23 and C0 quality
fullsize Deepfakes images is 0.853 and 0.861, respectively. In the
fullsize version dataset, showing the same trend as the
crop version, the result shows that the fakeness of C23 images is more difficult to detect than C0 images. Based on the above observation, we believe that detecting the
fullsize datasets is harder than the
crop one. Based on
Table 1, the fake images altered by the
Face2Face method are harder to detect than
Deepfakes and
FaceSwap. The compression level in C23 images also makes the fake images altered by
Face2Face more difficult to detect than the C0 level. The accuracy of deciding C23 and C0 images altered by
Face2Face is 0.835 and 0.873, respectively.
Table 2 records the experiments performed on the
fullsize dataset. Based on the comparison of
Table 1 and
Table 2, the
fullsize dataset is more difficult to detect than the
crop dataset. The large background area cannot help the proposed model to make the right decision, but it confuses the decision. A possible explanation is that the large background area dilutes the statistical features of the fake area. Furthermore, based on the comparison of the IoU in
Table 1 and
Table 2, among the three manipulation methods, the fake area segmentation of
Face2Face is harder than the images altered by the other two methods whenever input is
crop or
fullsize.
To test the generalization ability of the proposed method, we test the three altered methods with the models trained by different datasets. The number of images in the training and testing sets is fixed for all experiments. In
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7, we vary the size of the fine-tuning set to evaluate the performance of our method under different fine-tuning set sizes. We tested all combinations of training and testing/fine-tuning sets. Specifically, in any experimental design, images used as a testing set or fine-tuning are not used for training, and images used for fine-tuning are not included in the testing set. For example, in the first row of
Table 7, we test
Deepfakes images with models trained by
Face2Face and
FaceSwap, respectively. Furthermore, in the second row of
Table 7, we use the
FaceSwap testing set to test the performance of the proposed models trained by the
Deepfakes and
Face2Face training sets, respectively. Furthermore, in the third row of
Table 7, we use the
Face2Face testing set to evaluate the performance of the proposed models trained by
FaceSwap and
Deepfakes, respectively. Based on
Table 7, the performance of the detector drops dramatically to a very low level when the detectors meet the unseen altered method. In order to solve this problem, we use a small number of images produced by new forgery methods to adjust old models that have already been trained by the training set produced by other forgery methods. That is, a few images generated by an unseen method are used to adjust the trained model to suit the newly emerged altered method.
In
Table 3, we show the classification accuracy, IoU, and pixel-wise accuracy for detecting C23
crop images altered by the
Deepfakes manipulation method using the
Face2Face-,
FaceSwap-, and
none-based models and fine-tuned with small 700, 100, and 20 size
Deepfakes training sets. Here, we use the
none-based model to denote that the model was only trained by 700, 100, or 20 images without the base model. In order to compare with the results of other papers, we also calculated the pixel-wise accuracy. In
Table 3,
Table 4 and
Table 5, acc-pixel stands for pixel-wise accuracy.
In
Table 4, we show the classification accuracy, IoU, and pixel-wise accuracy for detecting C23
crop images altered by the
FaceSwap manipulation method using the
Face2Face-,
Deepfakes- and
none-based models and fine-tuned with small 700, 100, and 20 size
FaceSwap training sets. In
Table 5, we show the classification accuracy, IoU, and pixel-wise accuracy for detecting C23
crop images altered by the
Face2Face manipulation method using the
Face2Face-,
FaceSwap- and
Deepfakes-based models and fine-tuned with small 700, 100, and 20 size
Face2Face training sets.
The percentage of performance improvement brought by few-shot learning is summarized in
Table 6. For example, the accuracy of the model trained by the
Face2Face to detect images forged by the
Deepfakes method is 0.522 (see
Table 7). The accuracy of the same model but fine-tuned with 700
Deepfakes samples becomes 0.881 (see
Table 3). Therefore, the percentage increase is
. Based on
Table 6, few-shot learning with only 20 samples can bring a 29 to 380% percentage increase in the IoU metric. This indicates that our GAN architecture is well suited for few-shot learning.
Due to the fact that the main contribution of the proposed method is utilizing a small number of samples to achieve the training goal, we are particularly interested in the improvement per fine-tune sample. In
Table 8, we present the combinations of each training and fine-tune set and calculate the improvement per sample. In other words,
Table 8 contains the values from
Table 6 divided by the number of fine-tune samples. From
Table 8, it can be observed that when the fine-tuning sample size is small, the training performance achieved per sample is higher than when the sample size is large. This result indicates that the proposed method is indeed effective for few-shot learning.
In
Table 9, we compare the classification accuracy of our scheme with the methods proposed in Cozzolino et al. [
7], Rahmouni et al. [
8], Bayar et al. [
6], MesoNet [
9], and Full Image XceptionNet [
9] for detecting either raw, C23
crop or high-quality images altered by the
Face2Face,
FaceSwap, and
Deepfakes manipulation methods using the same difference-based models. That is, we use the
Face2Face-trained model to detect the
Face2Face testing set, the
FaceSwap-trained model to detect the
FaceSwap testing set and so on. The proposed method has the best accuracy of 0.917, 0.873, and 0.929 on the
Deepfakes,
Face2Face, and
FaceSwap testing sets, respectively.
In
Table 10, we compare our scheme with the methods proposed by Cozzolino et al. [
23], and Nguyen et al. [
10] using classification accuracy, IoU, and pixel-wise accuracy to detect C23
crop images altered by the
FaceSwap manipulation methods using the
Face2Face-based models and fine-tuned with
FaceSwap. The classification accuracy of Nguyen’s “New” method has the best accuracy of 0.837 and our proposed method has the second best result of 0.835, almost the same as the best. On the other hand, the proposed method has the best accuracy of 0.930 and Nguyen’s “New” method has the second best result of 0.926 when the metric pixel-wise accuracy is used to measure the result. In papers [
10,
23], the IoU was not used to measure the performance of segmentation, thus in
Table 10, we use “-” to denote that there is no metric value.
Our approach can provide a forgery region prediction for suspicious images to forensic examiners when new forgery methods have just emerged and only a few training samples are available. This can enhance the practicality of forensic work when dealing with new forgery techniques. A limitation of our approach is that it still requires collecting a small amount of training data. However, until a method emerges that can recognize all unknown forgery techniques without the need for further training, collecting a small number of training samples is an acceptable approach. Another limitation of our method is that the image needs to be first identified as a human face. If the forgery method used renders the facial detection system unable to detect the position of the face, the proposed method cannot be effective.



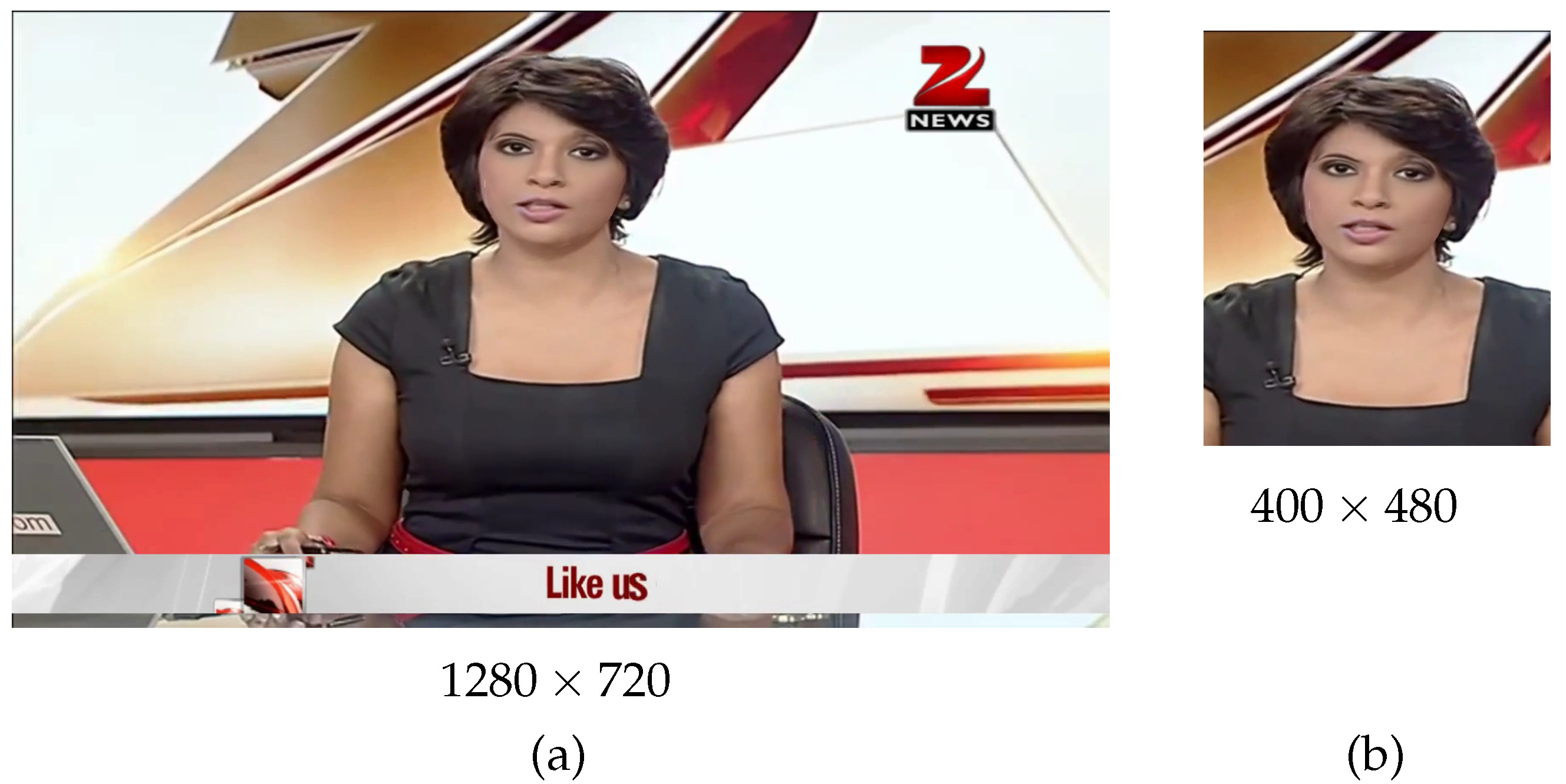






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}