
SDRC-YOLO: A Novel Foreign Object Intrusion Detection Algorithm in Railway Scenarios



Abstract
1. Introduction
- (1)
- An SSA hybrid attention mechanism with a spatial attention module (SAM) working in tandem with Squeeze and Excitation Network (SENet) channel attention is proposed. This mechanism effectively improves local representation ability, integrates multiple receptive fields, enriches the information, makes the characteristics cover more of the intrusion, better fits the relevant characteristics information, enhances the attention to small targets, and improves the effectiveness of the model in small target recognition;
- (2)
- An efficient decoupled head based on a hybrid channel strategy is proposed and called the DW-Decoupled Head. Compared with the non-decoupled end-to-end method, the DW-Decoupled Head can speed up the network convergence, reduce the computational cost, and achieve faster inference speed;
- (3)
- Large convolutional kernels RepLKNet with heavy parameterization are adopted to build larger perceptual fields. In addition, the lightweight universal upsampling operator CARAFE is used for sampling, and more suitable sizes and ratios for the characteristics of intrusion are adopted;
- (4)
- An RS railway intrusion dataset is built. There is no public railway intrusion dataset at present. As pedestrians, cars, and bicycles are the most frequent intrusions, they were chosen as the main study subjects.
2. Related Work
3. SDRC-YOLO Network Model
3.1. SSA Hybrid Attention Mechanism
3.2. DW-Decoupled Head
3.3. Super-Large Convolutional Kernel Model: RepLKNet
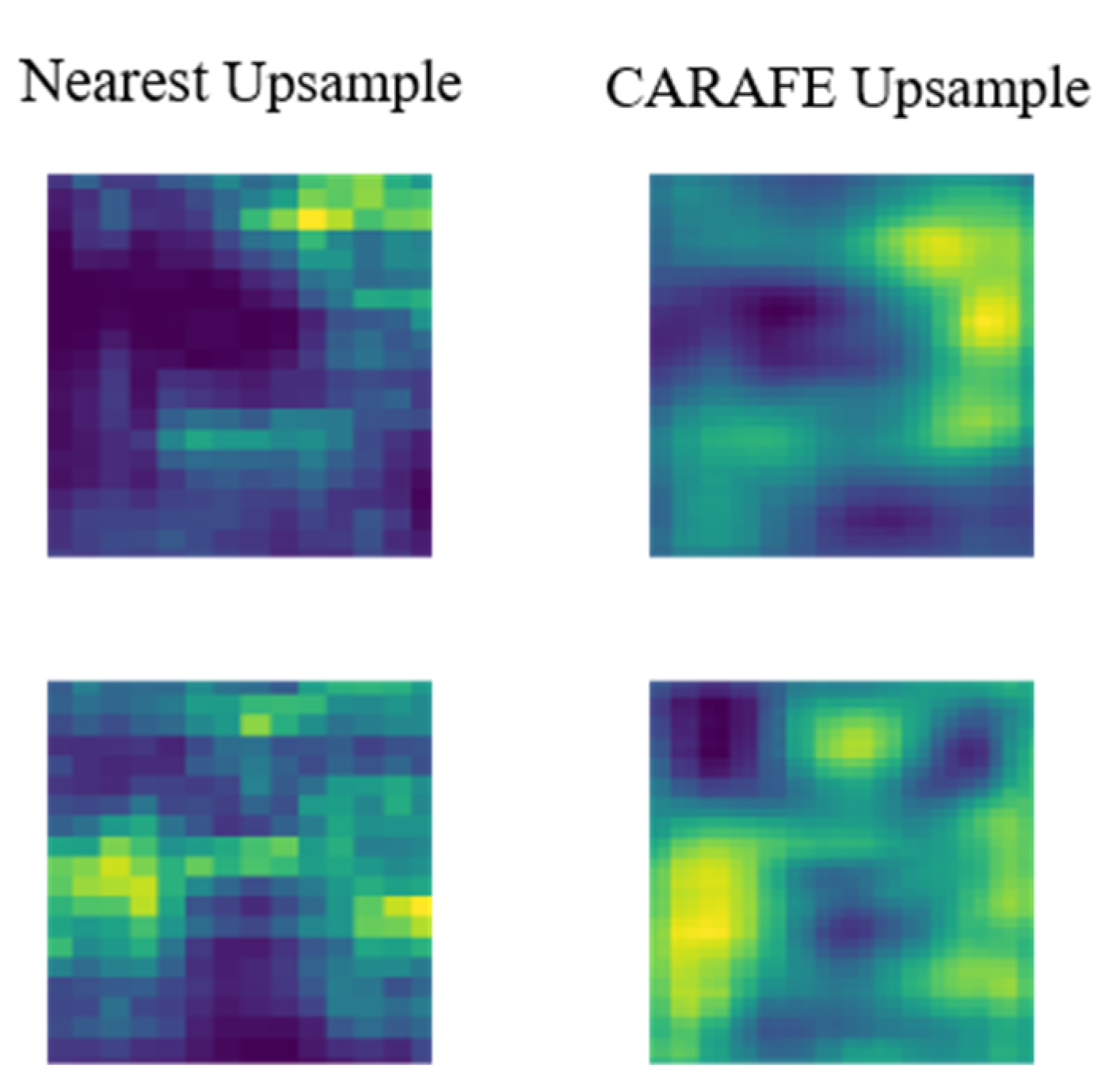
3.4. Lightweight Upsampling Operator CARAFE
4. Experimental Results
4.1. Experimental Setting
4.2. Experimental Dataset
4.3. Evaluation Indicators
4.4. SSA Hybrid Attention Module Experimental Analysis
4.5. Experimental Analysis of DW-Decoupled Head and Super Large Convolutional Kernel
4.6. Experimental Analysis of CARAFE Lightweight Upsampling Operator
4.7. Ablation Experiment
4.8. Comparison Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.; Zhu, L.; Yu, Z. Segmentation and recognition algorithm for high-speed railway sence. Acta Opt. Sin. 2019, 39, 119–126. [Google Scholar]
- Cao, Z.; Qin, Y.; Xie, Z.; Liu, Q.; Zhang, E.; Wu, Z.; Yu, Z. An Effective Railway Intrusion Detection Method Using Dynamic Intrusion Region and Lightweight Neural Network. Measurement 2022, 191, 110564. [Google Scholar] [CrossRef]
- Cai, H.; Li, F.; Gao, D.; Yang, Y.; Li, S.; Gao, K.; Qin, A.; Hu, C.; Huang, Z. Foreign Objects Intrusion Detection Using Millimeter Wave Radar on Railway Crossings. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11 October 2020; IEEE: Toronto, ON, Canada, 2020; pp. 2776–2781. [Google Scholar]
- Chen, Y.; Lu, C.; Wang, Z. Detection of foreign object intrusion in railway region of interest based on lightweight network. J. Jilin Univ (Eng. Technol. Ed.) 2021, 52, 2405–2418. [Google Scholar] [CrossRef]
- Basak, H.; Kundu, R.; Singh, P.K.; Ijaz, M.F.; Woźniak, M.; Sarkar, R. A Union of Deep Learning and Swarm-Based Optimization for 3D Human Action Recognition. Sci. Rep. 2022, 12, 5494. [Google Scholar] [CrossRef] [PubMed]
- Pan, H.; Li, Y.; Wang, H.; Tian, X. Railway Obstacle Intrusion Detection Based on Convolution Neural Network Multitask Learning. Electronics 2022, 11, 2697. [Google Scholar] [CrossRef]
- Hussain, R.; Karbhari, Y.; Ijaz, M.F.; Woźniak, M.; Singh, P.K.; Sarkar, R. Revise-Net: Exploiting Reverse Attention Mechanism for Salient Object Detection. Remote Sens. 2021, 13, 4941. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, Z.; Zhu, L. Intrusion Detection for High-Speed Railways Based on Unsupervised Anomaly Detection Models. Appl. Intell. 2022, 5, 1–14. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, D.; Ren, R.; Li, K.; Zou, Z.; Ma, R.; Qin, Y.; Yang, W. Urban Rail Transit Obstacle Detection Based on Improved R-CNN. Measurement 2022, 196, 111277. [Google Scholar] [CrossRef]
- He, D.; Qiu, Y.; Miao, J.; Zou, Z.; Li, K.; Ren, C.; Shen, G. Improved Mask R-CNN for Obstacle Detection of Rail Transit. Measurement 2022, 190, 110728. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, D.; Mo, G. High-speed rail foreign body intrusion detection algorithm based on improved YOLOv3. Comput. Technol. Dev. 2022, 32, 69–74. [Google Scholar]
- Ye, T.; Zhao, Z.; Wang, S.; Zhou, F.; Gao, X. A Stable Lightweight and Adaptive Feature Enhanced Convolution Neural Network for Efficient Railway Transit Object Detection. IEEE Trans. Intell. Transport. Syst. 2022, 23, 17952–17965. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 1–25 July 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling Up Your Kernels to 31 × 31: Revisiting Large Kernel Design in CNNs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 11963–11975. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-Aware ReAssembly of FEatures. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 29–31 October 2019; pp. 3007–3016. [Google Scholar]
- Shetty, S. Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 Dataset. Available online: https://arxiv.org/abs/1607.03785 (accessed on 16 November 2022).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations From Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors 2022. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Inference (ms) | FPS (bs = 1) |
|---|---|---|---|---|
| YOLOv5s (r6.1) | 0.84 | 0.583 | 10.3 | 86 |
| +(ECA-Spatial) | 0.839 (−0.1) | 0.59 (+0.7) | 11.5 | 66 |
| +(Spatial-ECA) | 0.84 (+0.0) | 0.585 (+0.2) | 11.3 | 75 |
| +(CA-Spatial) | 0.846 (+0.6) | 0.576 (−0.7) | 11.0 | 84 |
| +(Spatial-CA) | 0.844 (+0.4) | 0.589 (+0.6) | 10.9 | 74 |
| +(SENet-Spatial) | 0.838 (−0.2) | 0.585 (+0.2) | 10.0 | 78 |
| +(Spatial-SENet) | 0.851 (+1.1) | 0.598 (+1.5) | 9.8 | 90 |
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Inference (ms) | FPS (bs = 1) |
|---|---|---|---|---|
| YOLOv5s (r6.1) | 0.84 | 0.583 | 10.3 | 86 |
| +SENet | 0.846 (+0.6) | 0.588 (+0.5) | 12.5 | 78 |
| +CA | 0.842 (+0.2) | 0.592 (+0.9) | 12.7 | 91 |
| +CBAM | 0.84 (+0.0) | 0.591 (+0.8) | 12.0 | 84 |
| +ECA | 0.848 (+0.8) | 0.58 (−0.3) | 12.1 | 74 |
| +SSA | 0.851 (+1.1) | 0.598 (+1.5) | 9.8 | 90 |
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Inference (ms) | FPS (bs = 1) |
|---|---|---|---|---|
| YOLOv5s (r6.1) | 0.674 | 0.462 | 9.7 | 79 |
| +SENet | 0.672 (−0.2) | 0.463 (+0.1) | 8.7 | 94 |
| +CA | 0.676 (+0.2) | 0.464 (+0.2) | 8.1 | 101 |
| +CBAM | 0.677 (+0.3) | 0.464 (+0.2) | 8.5 | 102 |
| +ECA | 0.677 (+0.3) | 0.466 (+0.4) | 9.5 | 90 |
| +SSA | 0.681 (+0.7) | 0.468 (+0.6) | 9.7 | 77 |
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Parameters (M) | GFLOPs | FPS (bs = 1) |
|---|---|---|---|---|---|
| YOLOv5s (r6.1) | 0.84 | 0.583 | 7.2 | 16.5 | 86 |
| +DW-Decoupled Head | 0.851 (+1.1) | 0.586 (+0.3) | 7.3 | 16.6 | 75 |
| +RepLKNet | 0.852 (+1.2) | 0.586 (+0.3) | 7.0 | 16.3 | 82 |
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Parameters (M) | GFLOPs | FPS (bs = 1) |
|---|---|---|---|---|---|
| YOLOv5s (r6.1) | 0.674 | 0.462 | 7.0 | 16.1 | 79 |
| +DW-Decoupled Head | 0.686 (+1.2) | 0.483 (+2.1) | 7.3 | 16.8 | 72 |
| +RepLKNet | 0.692 (+1.8) | 0.493 (+3.1) | 6.7 | 15.6 | 85 |
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Parameters (M) | GFLOPs | FPS (bs = 1) |
|---|---|---|---|---|---|
| YOLOv5s (r6.1) | 0.84 | 0.583 | 7.2 | 16.5 | 86 |
| +CARAFE | 0.848 (+0.8) | 0.592 (+0.9) | 7.2 | 16.3 | 74 |
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Parameters (M) | GFLOPs | FPS (bs = 1) |
|---|---|---|---|---|---|
| YOLOv5s (r6.1) | 0.674 | 0.462 | 7.0 | 16.1 | 79 |
| +CARAFE | 0.680 (+0.6) | 0.468 (+0.6) | 7.2 | 16.4 | 70 |
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Parameters (M) | GFLOPs | FPS (bs = 1) |
|---|---|---|---|---|---|
| YOLOv5s (r6.1) | 0.84 | 0.583 | 7.2 | 16.5 | 86 |
| +RepLKNet (RLK) | 0.854 (+1.4) | 0.596 (+1.6) | 7.0 | 16.3 | 82 |
| +DW-DecoupledHead (DWHead) | 0.851 (+1.1) | 0.59 (+0.7) | 7.2 | 16.6 | 75 |
| +SSA | 0.851 (+1.1) | 0.598 (+1.5) | 7.0 | 15.8 | 90 |
| +CARAFE | 0.848 (+0.8) | 0.592 (+0.9) | 7.1 | 16.3 | 74 |
| +RLK + SSA + CARAFE | 0.866 (+2.6) | 0.602 (+1.9) | 7.1 | 16.5 | 81 |
| +RLK + SSA + DWHead | 0.861 (+2.1) | 0.601 (+1.8) | 7.3 | 16.3 | 75 |
| +RLK + DWHead + CARAFE | 0.864 (+2.4) | 0.598 (+1.5) | 7.3 | 16.5 | 83 |
| +SSA + DWHead + CARAFE | 0.858 (+1.8) | 0.602 (+1.9) | 7.3 | 16.5 | 79 |
| +RLK + SSA + DWHead + CARAFE | 0.868 (+2.8) | 0.606 (+2.3) | 7.3 | 16.5 | 80 |
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Parameters (M) | GFLOPs | FPS (bs = 1) |
|---|---|---|---|---|---|
| YOLOv5s (r6.1) | 0.674 | 0.462 | 7.0 | 16.1 | 79 |
| +RepLKNet (RLK) | 0.692 (+1.8) | 0.493 (+3.1) | 6.7 | 15.6 | 85 |
| +DW-DecoupledHead (DWHead) | 0.684 (+1.0) | 0.474 (+1.2) | 7.3 | 16.8 | 80 |
| +SSA | 0.68 (+0.6) | 0.468 (+0.6) | 7.0 | 15.9 | 77 |
| +CARAFE | 0.68 (+0.6) | 0.468 (+0.6) | 7.2 | 16.4 | 70 |
| +RLK + SSA + CARAFE | 0.694 (+2.0) | 0.495 (+3.3) | 7.0 | 16.1 | 74 |
| +RLK + SSA + DWHead | 0.697 (+2.3) | 0.498 (+3.6) | 7.2 | 16.4 | 76 |
| +RLK + DWHead + CARAFE | 0.693 (+1.9) | 0.494 (+3.2) | 7.3 | 16.4 | 75 |
| +SSA + DWHead + CARAFE | 0.691 (+1.7) | 0.477 (+1.5) | 7.3 | 16.4 | 80 |
| +RLK + SSA + DWHead + CARAFE | 0.698 (+2.4) | 0.493 (+3.1) | 7.3 | 16.4 | 75 |
| Method | mAP@0.5 (%) | mAP@0.5:.95 (%) | Parameters (M) | GFLOPs | FPS (bs = 1) |
| YOLOv5s (r6.1) | 0.84 | 0.583 | 7.2 | 10.3 | 86 |
| YOLOv5m (r6.1) | 0.862 | 0.635 | 20.9 | 18.8 | 69 |
| SSD | 0.654 | 0.404 | 100.2 | 22.1 | 54 |
| Fast R-CNN | 0.685 | 0.426 | 56.3 | 18.1 | 34 |
| Faster R-CNN | 0.703 | 0.448 | 136.7 | 45.6 | 22 |
| YOLOv3-SPP | 0.823 | 0.544 | 9.56 | 11.3 | 80 |
| YOLOv4-tiny | 0.734 | 0.512 | 5.9 | 8.9 | 110 |
| YOLOv4 | 0.815 | 0.543 | 244.8 | 54.5 | 34 |
| YOLOX-tiny | 0.825 | 0.562 | 5.1 | 15.8 | 42 |
| YOLOX-S | 0.846 | 0.595 | 9.0 | 22.5 | 24 |
| YOLOv6-tiny | 0.862 | 0.604 | 15.0 | 21.5 | 80 |
| YOLOv7-tiny | 0.831 | 0.564 | 6.1 | 7.3 | 118 |
| SDRC-YOLO | 0.868 | 0.606 | 7.3 | 13.8 | 80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, C.; Wang, Z.; Shi, L.; Gao, Y.; Tao, Y.; Wei, L. SDRC-YOLO: A Novel Foreign Object Intrusion Detection Algorithm in Railway Scenarios. Electronics 2023, 12, 1256. https://doi.org/10.3390/electronics12051256
Meng C, Wang Z, Shi L, Gao Y, Tao Y, Wei L. SDRC-YOLO: A Novel Foreign Object Intrusion Detection Algorithm in Railway Scenarios. Electronics. 2023; 12(5):1256. https://doi.org/10.3390/electronics12051256
Chicago/Turabian StyleMeng, Caixia, Zhaonan Wang, Lei Shi, Yufei Gao, Yongcai Tao, and Lin Wei. 2023. "SDRC-YOLO: A Novel Foreign Object Intrusion Detection Algorithm in Railway Scenarios" Electronics 12, no. 5: 1256. https://doi.org/10.3390/electronics12051256
APA StyleMeng, C., Wang, Z., Shi, L., Gao, Y., Tao, Y., & Wei, L. (2023). SDRC-YOLO: A Novel Foreign Object Intrusion Detection Algorithm in Railway Scenarios. Electronics, 12(5), 1256. https://doi.org/10.3390/electronics12051256