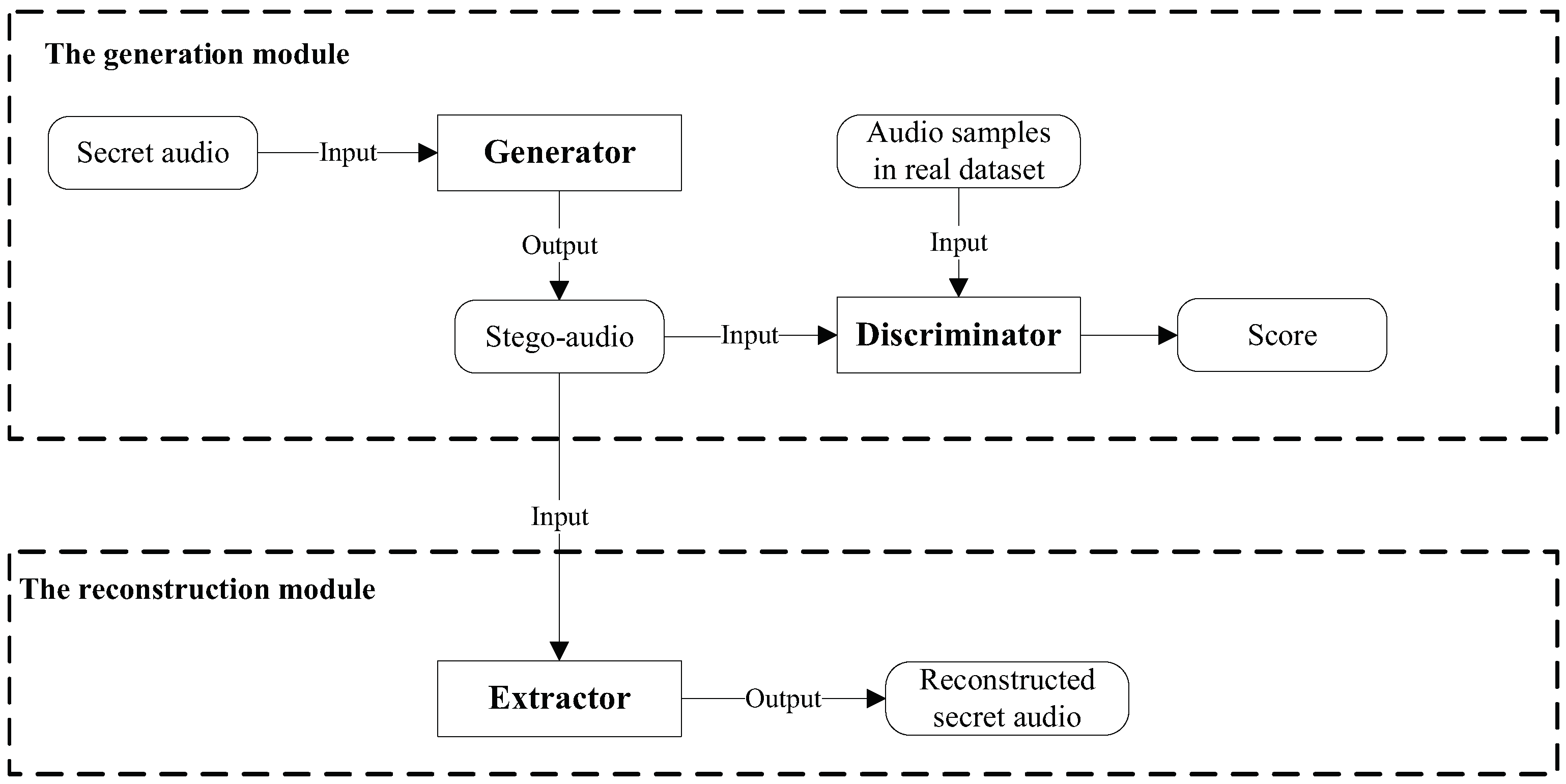
3.1. The Proposed Method
A complete steganography algorithm includes the process of hiding a secret and extracting a secret. Similarly, a complete coverless steganography algorithm also includes the generation module of the stego-audio and the extraction module of the secret messages. Therefore, the proposed model is divided into two subsections: the generation module and the reconstruction module. The entire model is illustrated in
Figure 1. Furthermore, each module is introduced in detail from two perspectives: the function perspective and its network architecture perspective.
3.1.1. The Generation Module
In this paper, the stego-audios are expected to be generated directly. Therefore, the audio synthesis model WaveGAN is applied to the generation module, which consists of a generator and a discriminator, to generate stego-audios. However, it was improved as follows: First, instead of a noise being fed into the WaveGAN, a secret audio is input into the generator. Second, a post-processing layer is added after the generator. Consequently, the secret audio will be transformed into a stego-audio in our model.
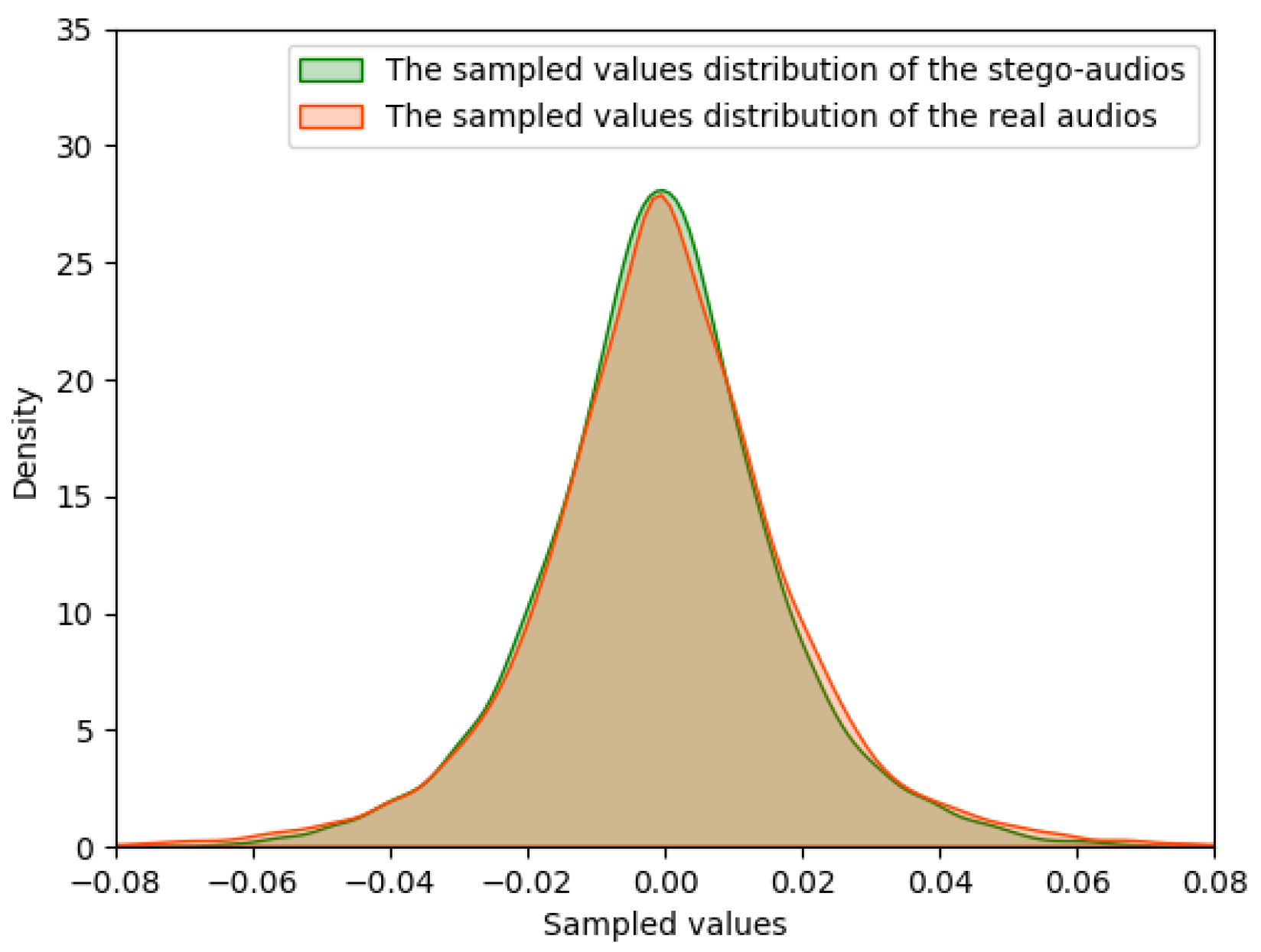
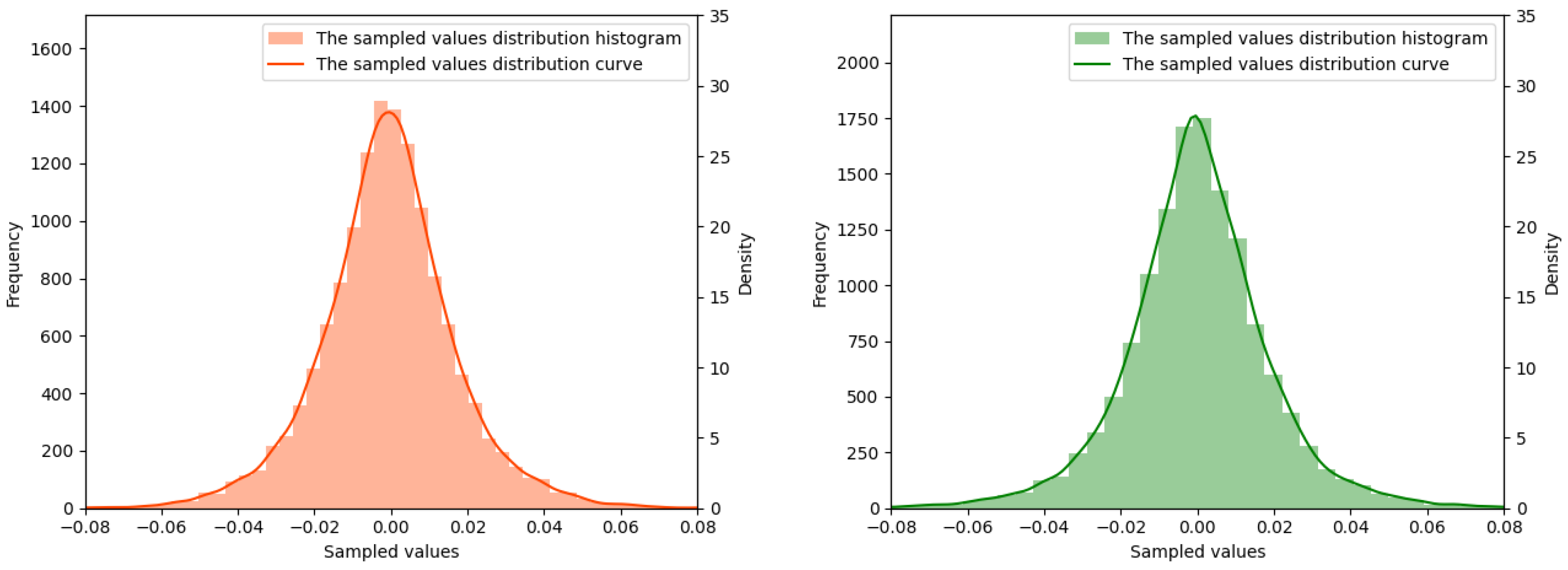
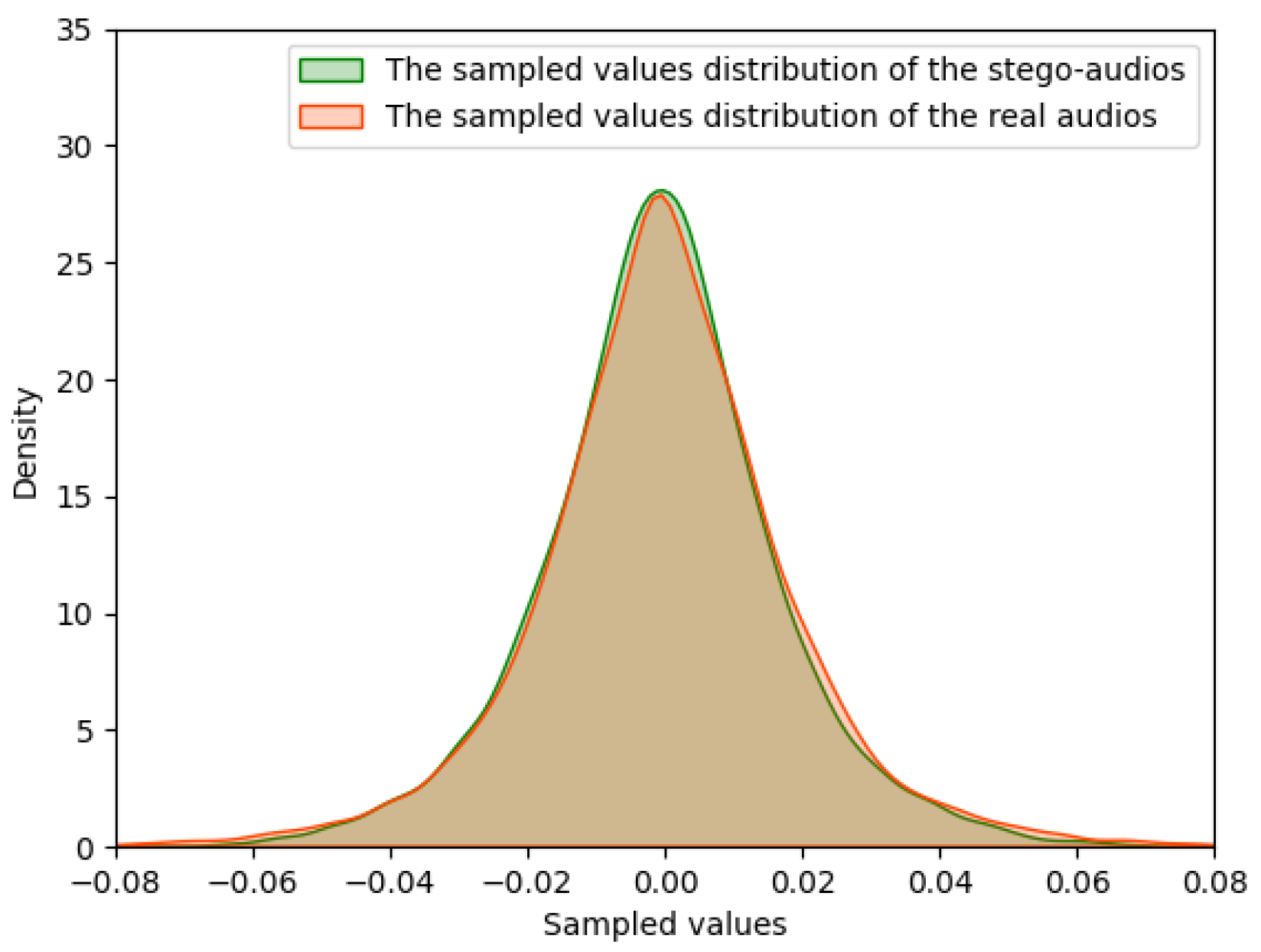
At the same time, for the sake of security, an essential demand is that the feature distribution and the auditory characteristics of the stego-audio should be the same as the audios in the real dataset. In order to meet the above security requirements, the discriminator is used to guide the training of the generator to generate a more authentic stego-audio. When the stego-audio or real audio is input to the discriminator, the discriminant score will be obtained. Specifically, the stego-audio is input to the discriminator to output the probability , and the real audio is input to output the probability . These two probabilities will be used to calculate the loss functions to optimize this model.
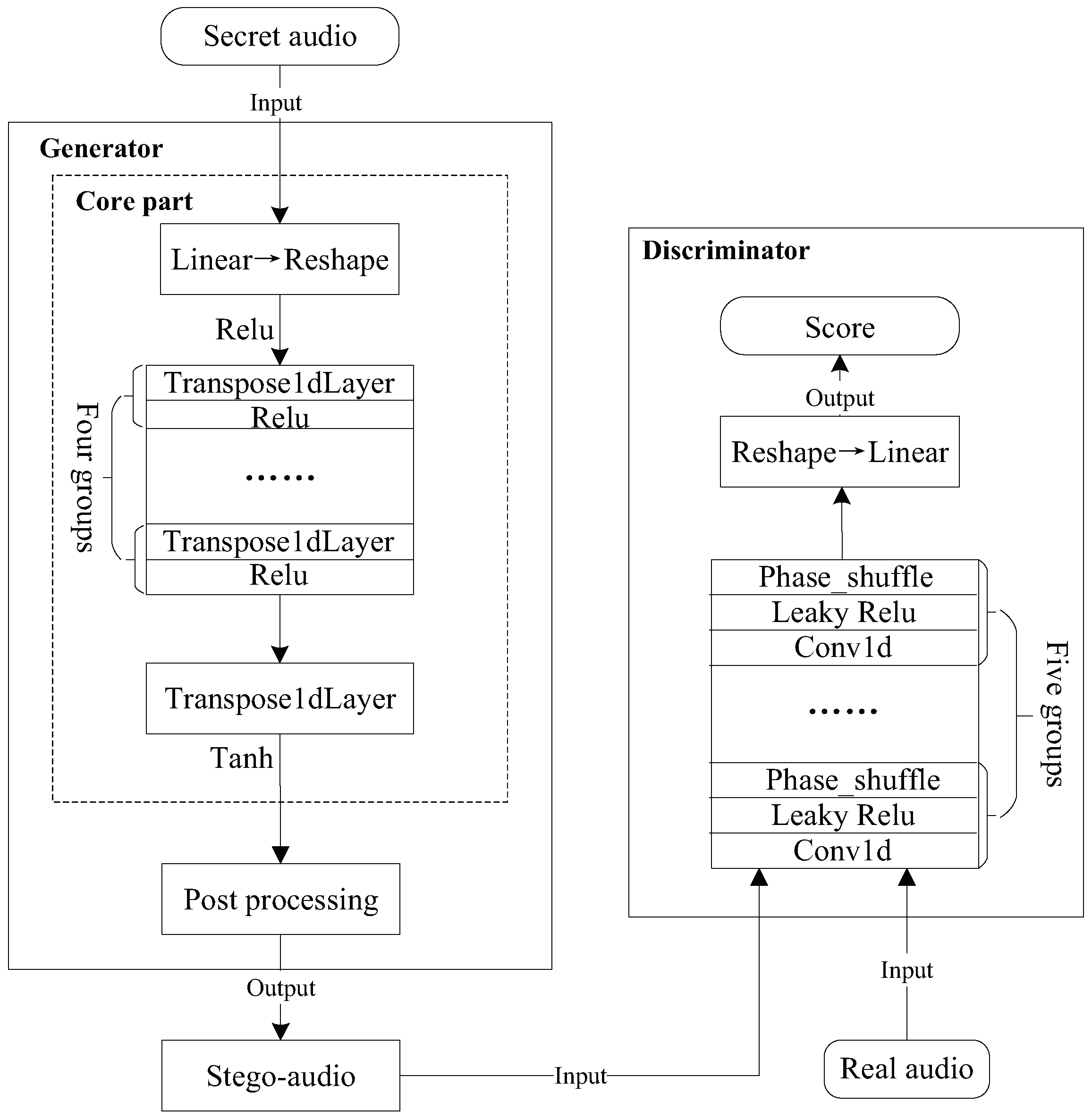
The design principle of the generation module is essentially audio generation, and the audio synthesis model WaveGAN is employed as the basis of the generation module to realize the generative steganography. The generator is composed of two parts: the core part and the post-processing part. The core part and the discriminator are based on the WaveGAN as shown in
Figure 2. Since the audio signal is sequential, the WaveGAN model employs 1D convolution (Conv1d) to extract sequential features. The core part of the generator consists of a linear layer, five groups of transposed convolutions and their activation functions.
After the secret audio is input to the generator, the secret audio will be input to the post-processing part after passing through the core part to obtain the final stego-audio. The structure of the discriminator is in the opposite state to the core part of the generator. The discriminator is composed of five groups of Conv1d, a linear layer and the activation function between them. The discriminator introduces the phase shuffle operation after each activation function. The reason why phase shuffle is introduced is that the transposed convolution in the generator gives the generated stego-audio strong periodic information. Furthermore, the kind of periodic information makes the discriminator judge the authenticity of the stego-audio only through periodicity.
Consequently, the discriminator will not work well, and the generator cannot generate high-quality stego-audio. In order to solve the above problem, a phase-shuffling operation is added between each Conv1d to randomly change the phase of the audio, which can remove the periodic noise effect. Consequently, the discriminator can judge more accurately, and the audio generated by the generator sounds more realistic.
In this work, WaveGAN is used to directly generate stego-audio and realize coverless audio steganography. However, for the security of the steganography algorithm, it is necessary to guarantee the audio quality of the stego-audio first. Therefore, on the basis of using WaveGAN as the generation module, a post-processing layer is replenished to reduce the noise and improve the quality of the generated stego-audio. The post-processing part is supplied after the core part of the network structure in the generation module. Furthermore, it is composed of a Conv1d layer. Subsequent ablation experiment in
Section 4.4 show that the post-processing layer effectively improves the audio quality of the generated stego-audio.
3.1.2. The Reconstruction Module
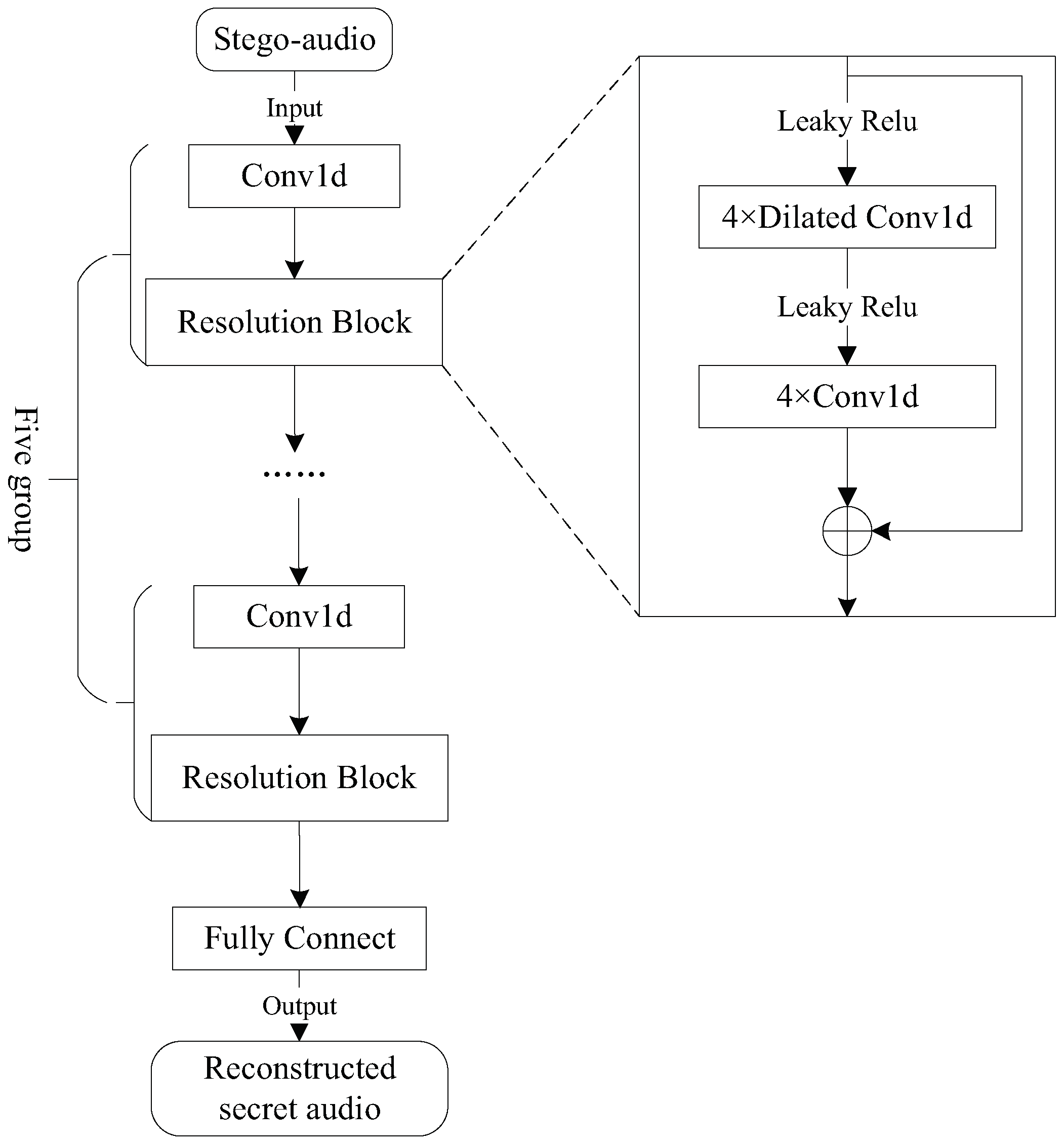
The reconstruction module is carefully designed as an extractor denoted as E. Its design principle is that the receiver directly inputs the stego-audios into the extractor to reconstruct the secret audios. In the scenario considered in this work, the receiver does not have prior knowledge of the original secret audio. Therefore, in the beginning, the reconstruction module should be trained until the reconstruction module can effectively reconstruct the complete secret audio. The sender and receiver share the trained model. After receiving the stego-audio, the receiver inputs it into the trained reconstruction module to obtain the secret audio. Therefore, unlike the traditional steganography, the proposed method does not need an extra secret key. In other words, for the steganography framework proposed in this paper, the received stego-audio itself is the key.
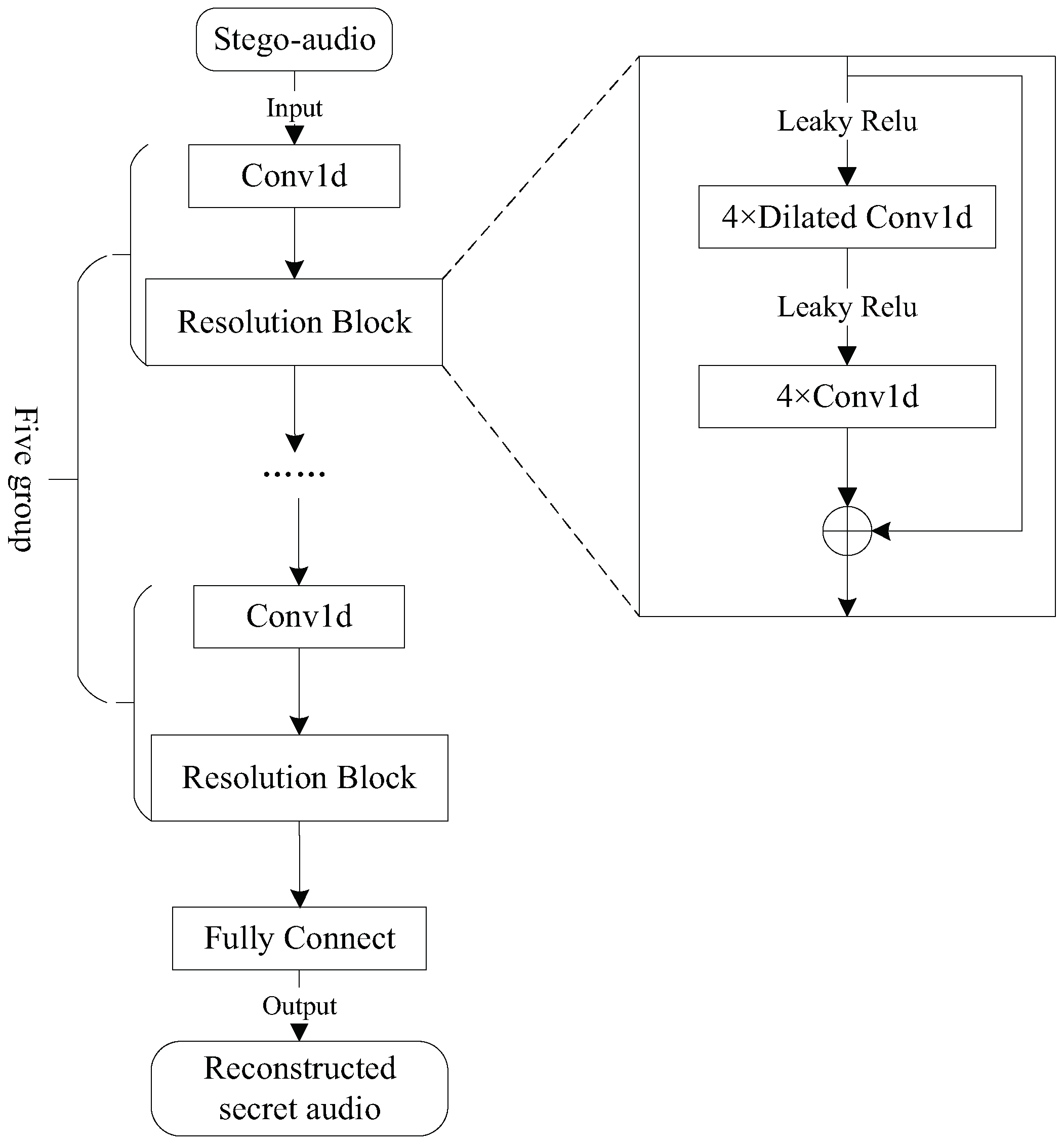
Its network structure is illustrated in
Figure 3. The generated stego-audios are input into the extractor. This network includes five groups of convolution neural networks and a full connection layer. Each group consists of a Conv1d operation and a resolution block. The resolution block is a residual network structure consisting of four Dilated Conv1d layers and four Conv1d layers. The Dilated Conv1d in the resolution block can provide the different receptive fields. In addition, a residual network structure is used in the resolution block to learn the acoustic features of different frequency bands on the audio spectrum, which effectively reduces feature loss during training. Finally, a feature transformation is performed through the fully connected layer to obtain the final reconstructed secret audio.
3.2. The Loss Function
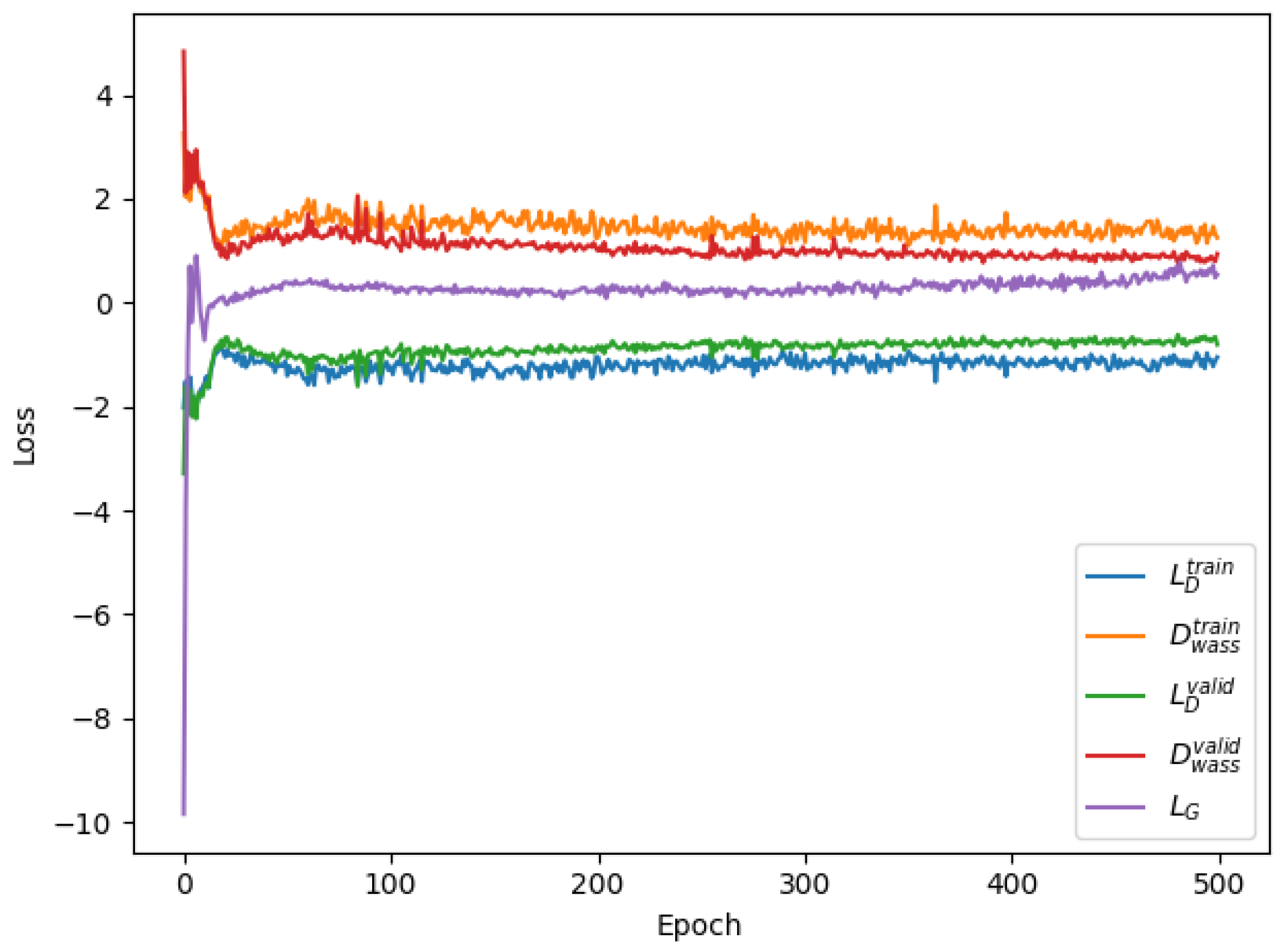
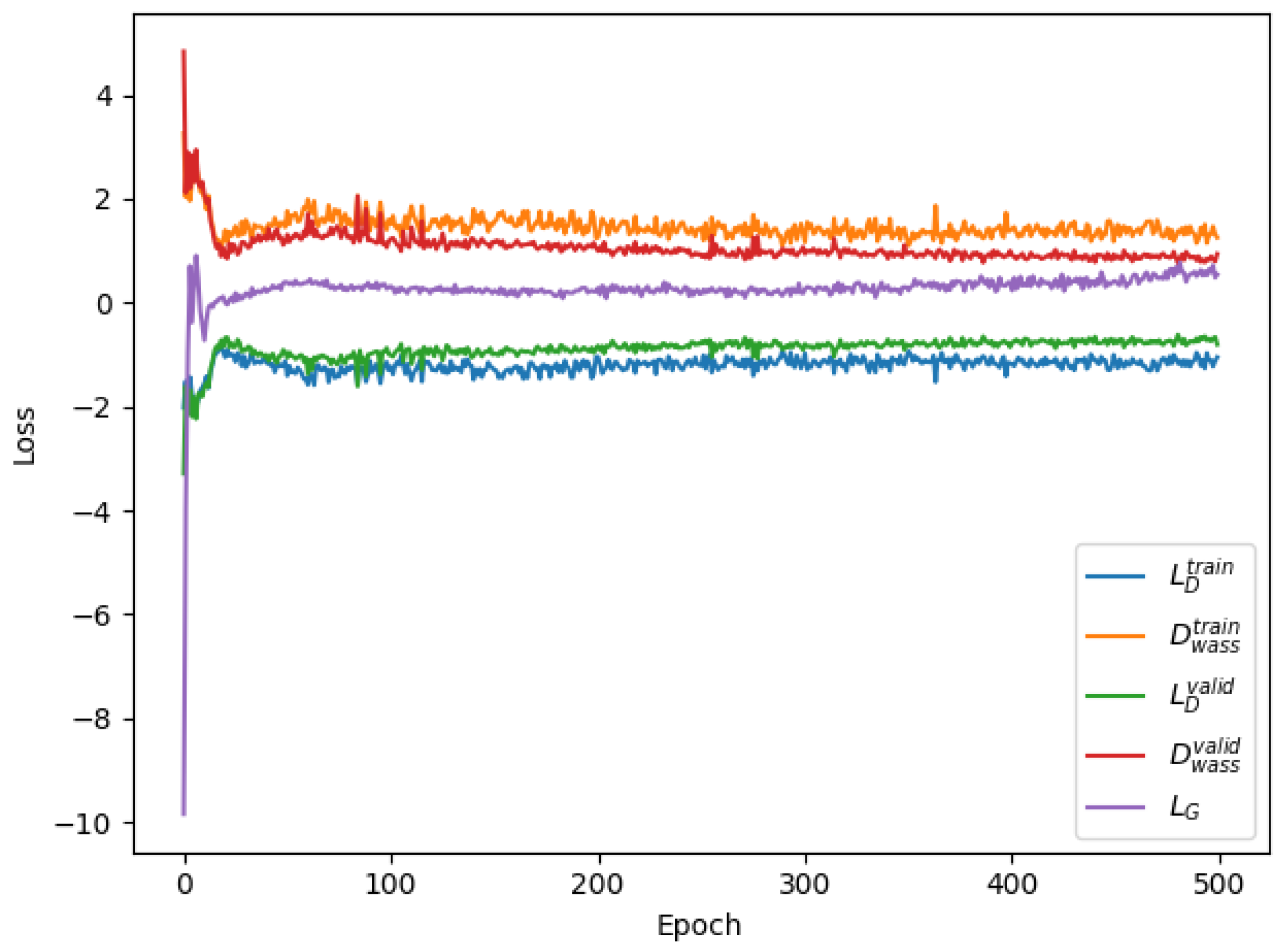
In this paper, two types of loss functions are defined. One is only involved in backpropagation to guide the training; and the other is used to verify the results without participating in the backpropagation. Among them, four loss functions are defined to guide the model training, including , , , and .
The first two loss functions (namely, and ) improve the discriminator to judge accurately; guides the generator to generate more realistic stego-audios; and ensures that the reconstructed secret audios by the extractor are less loss and more sound. At the same time, four loss functions are defined to verify the results—namely, , , , and . and are used to verify the distinctive ability of the discriminator, and and are employed to verify the reconstruction ability of the extractor. The above loss functions are described as follows in the module that they are located in.
In the generation module, the generator and the discriminator are trained iteratively. The generator is optimized by minimizing
to make the generated stego-audio increasingly realistic, and its loss function is shown below:
For the discriminator, the generated stego-audio and the audio samples from the real dataset are fed at the same time. The same loss indicators as used in the WaveGAN are employed to optimize the discriminator, including
and
, and they are calculated as follows:
The former minimizes the distribution difference between the generated stego-audio and the samples from the real dataset by minimizing the Wasserstein distance; the latter replaces the weight clipping in [
40] and adds the gradient penalty [
41] to strengthen the constraints to successfully train the model.
At the same time, the discriminator, as a steganalyzer, determines whether the input data is real audio or stego-audio, that is to say, the discriminator is used to determine whether the input data contains the secret or not. After the continuous optimization on the generator and the discriminator, the statistic features of the generated stego-audio are near to the real ones to such an extent that the steganalyzer cannot determine whether the input audio contains a secret.
In order to prevent the overfitting phenomenon, the following loss function is given to verify the distinctive ability of the discriminator
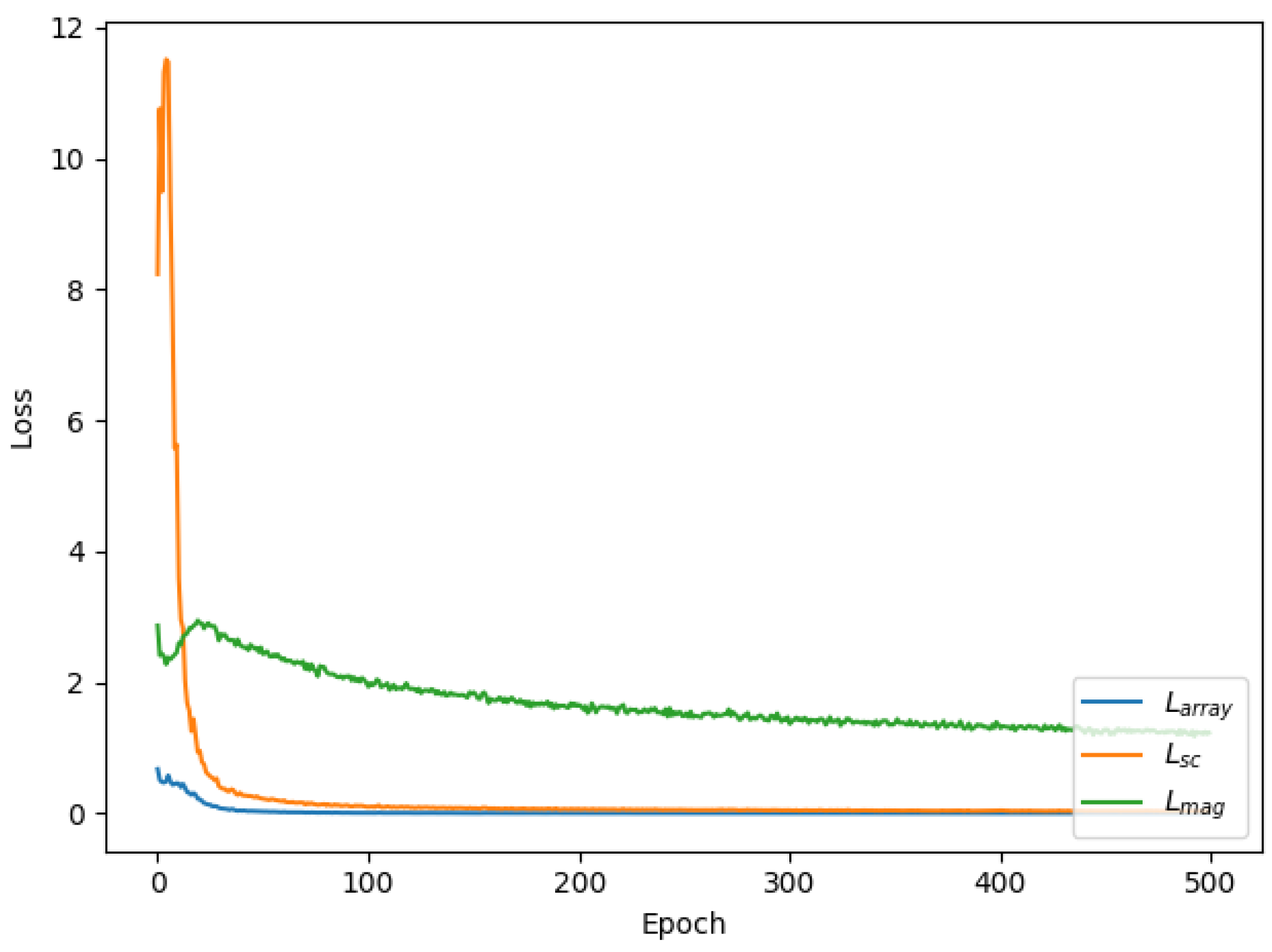
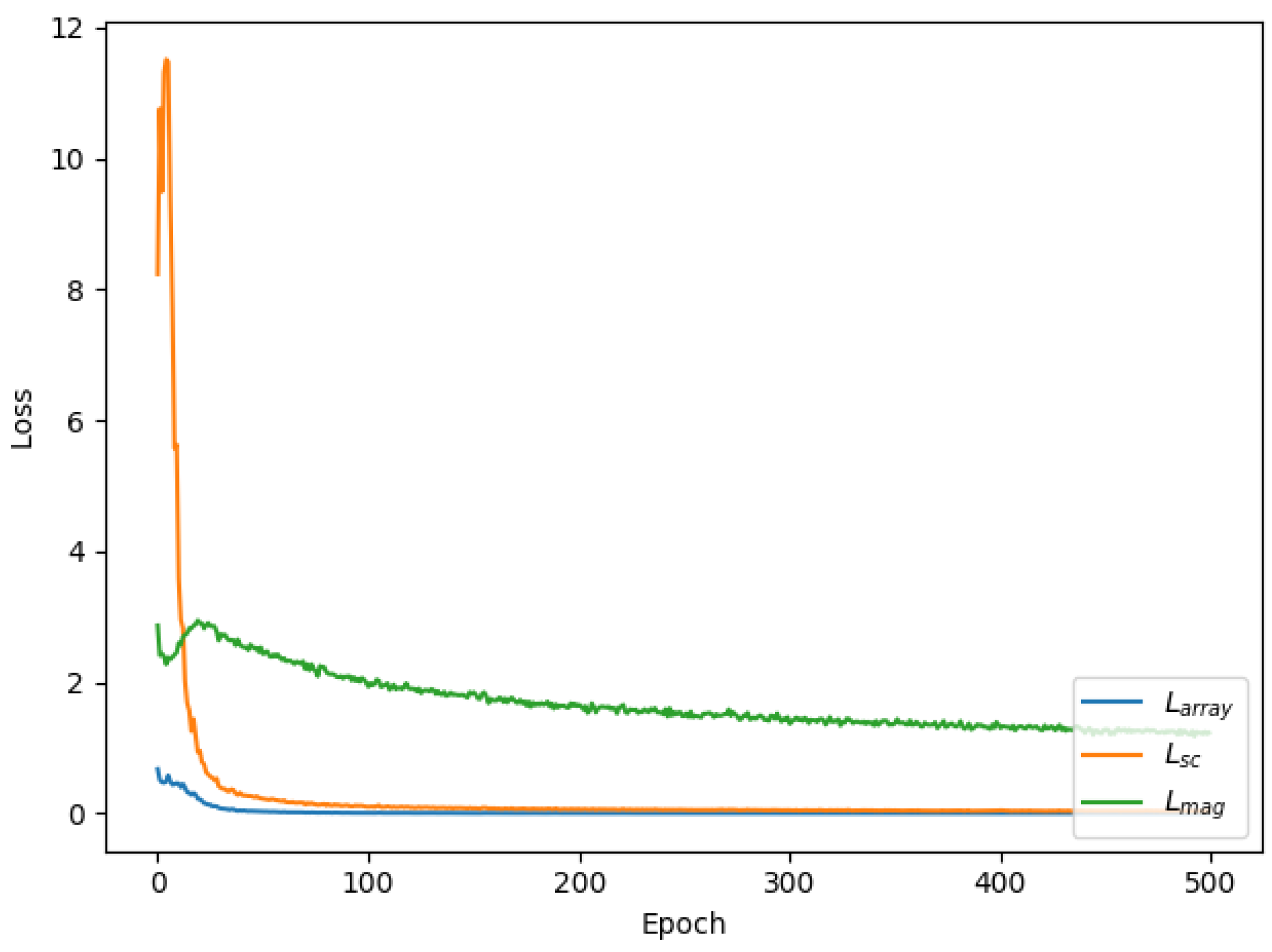
During the training, after a batch of secret audios are fed into the generator, stego-audios are synthesized. In the reconstruction module, the stego-audios are fed into the extractor to reconstruct the secret audios. Every original secret audio has one corresponding reconstructed secret audio. Herein, the first extractor loss
is defined as the function (
6), and it is used to optimize the extractor in the gradient back propagation.
Herein, the secret audio and the reconstructed secret audio are represented in the form of multi-dimension arrays, and M and N represent the number of rows and columns of the array, respectively. M is the frame of the audio, N is the channel of the audio, and B is the batch size. represents the sampling value of the jth channel in the ith frame in the original secret audio; represents the element in the reconstructed secret audio extracted by the extractor E.
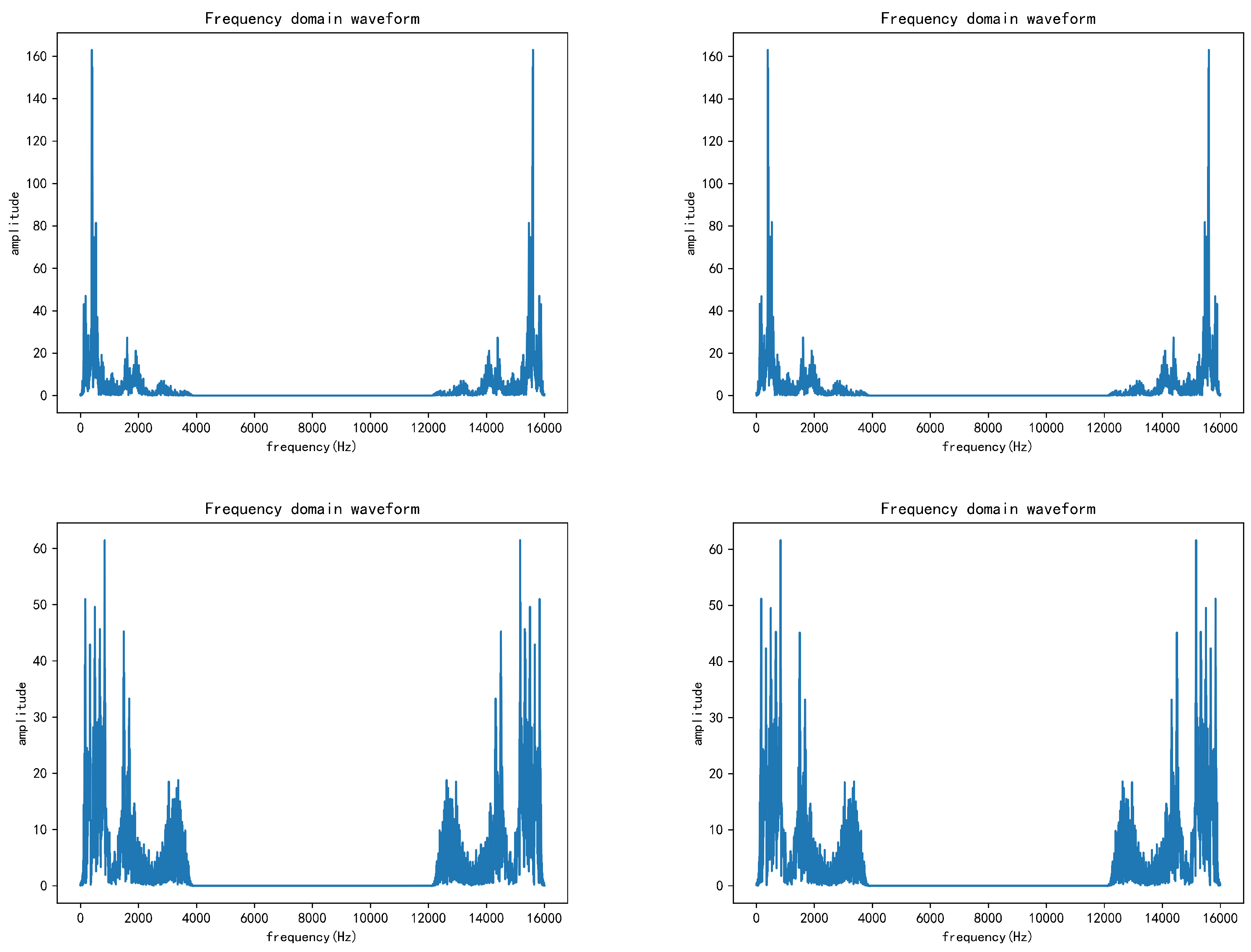
To further verify the integrity of the reconstructed secret audio, the following two loss indicators are defined, namely,
and
. The former is to evaluate the differences in amplitude, and the latter is to evaluate the differences in the frequency domain. In addition, they are only verification indicators and do not participate in the gradient back propagation.
where
and
represent the matrix obtained by short-time Fourier transform of the secret audio and the reconstructed secret audio, respectively.
X and
Y are the norm matrix, whose values are the norms of the corresponding elements in
and
, respectively.
where
is the element in
X. Concretely,
represents the value of the element whose time is
i and frequency is
j in the
bth audio. Similarly,
represents an element in
Y.
The whole training process is shown in the following pseudocode marked as Algorithm 1.
| Algorithm 1 The training process of the proposed model. |
- 1:
Initialize the real dataset R and the secret dataset S, Batch size B; - 2:
Initialize the generator net G with random ; - 3:
Initialize the discriminator net D with random ; - 4:
Initialize the extractor net E with random ; - 5:
for each training iteration do - 6:
Sample a batch of real data (denoted as r) from R; - 7:
Sample a batch of secret data (denoted as ) from S; - 8:
Obtain fake audio by inputting to ; - 9:
Obtain by inputting fake audio to ; - 10:
Update parameters by minimizing: - 11:
+ - 12:
- 13:
Sample another batch of secret data (denoted as ) from S; - 14:
Update parameters by minimizing: - 15:
- 16:
- 17:
Freeze parameters and parameters ; - 18:
Sample another batch of secret data (denoted as ) from S; - 19:
Update parameters by minimizing: - 20:
- 21:
- 22:
end for
|




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}