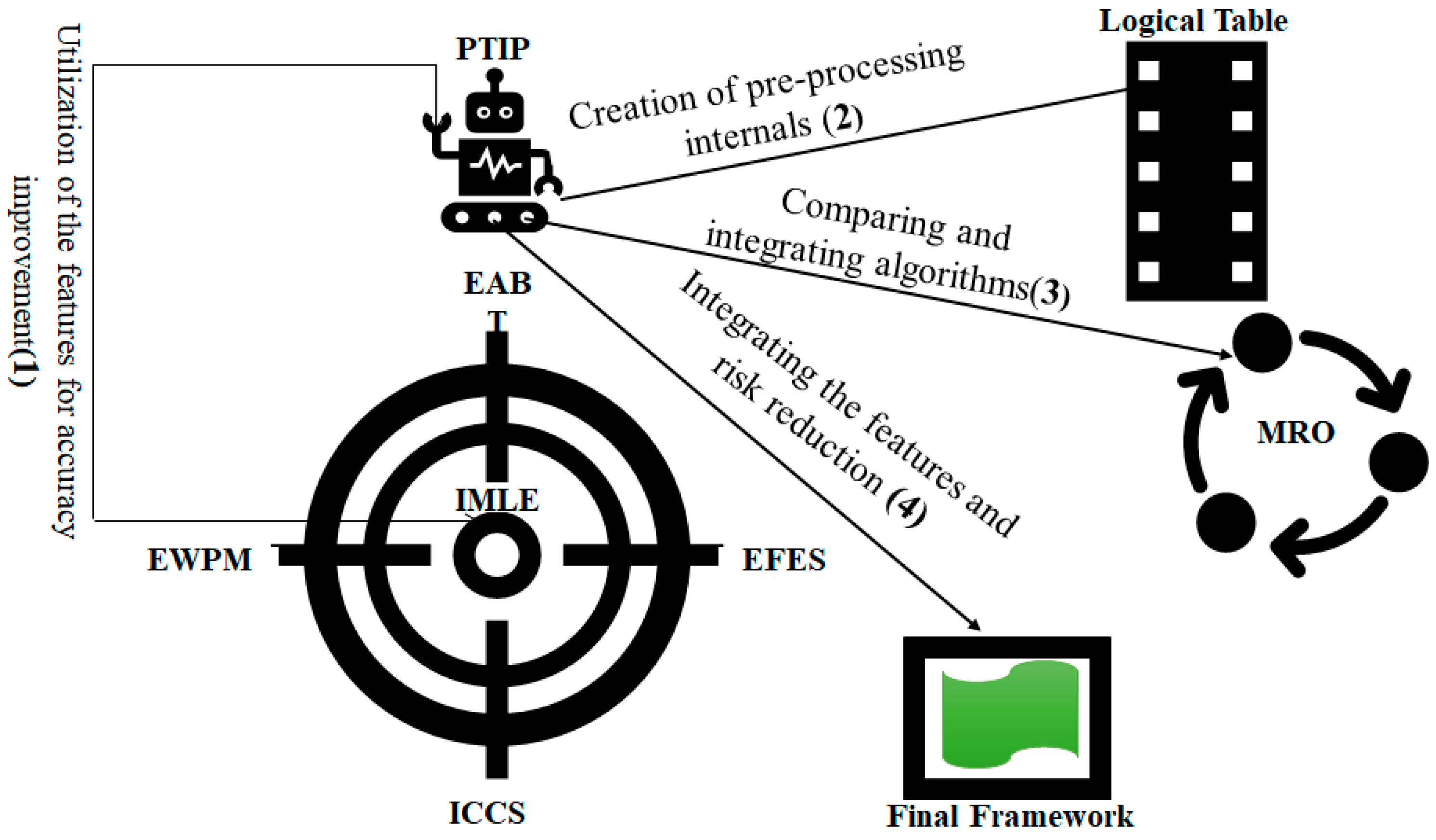
The measurement and risk optimization (MRO) component deals with applying various algorithms one by one to observe the outcomes (i.e., measures), and then prepares the model for risk estimation and algorithm blending. This construct also compares the two algorithms at the same time and then groups them based on Euclidean distance for similarity scores in terms of fitness. This sub-model finally produces the set of algorithms for the best fit for a given dataset. The end goal is to engineer inaccuracy removal that can be done through classifier function.
3-D Cube Logic for Security Provision
In encryption transmission, the 3D cube logic is used to maintain a security, and the activity is carried out based on the pattern generated by the transmitting side rather than supplying the whole cube structure. A key that is utilized for encryption and decryption is deduced through a sequence of steps that match the 3D CUBE pattern.
The proposed technique decrypts the encrypted text provided by the receiver using a key derived by completing the shuffling of 3D CUBE based on artificial intelligence (AI), which overcomes the challenge of secured key exchange by removing the key exchange procedure from the conventional symmetric key encryption. Because it is impossible to deduce a key used by a third party using AI-based learning, the 3D CUBE logic can also provide higher security than the conventional symmetric key encryption scheme.
As it is used to handle keys and transmit them correctly in the symmetric key encryption system, the procedure after generating the key in the 3D CUBE technique is identical to that in that mechanism. In the symmetric encryption system, instead of participants sharing keys used during initial encryption communication, the transmitter sends a 3D element key pattern as a randomized 3D CUBE sequence by which the key can be activated, and the recipient obtains the secret key by incorporating it through AI-based learning. By using the XOR operation on the sequence’s 3D CUBE pattern, the secret key is formed here based on the randomized order as a sequence.
Assume a dataset
, where “sig” denotes the signal and “noi” denotes the noisy component of the dataset that can be transmitted. The classifier function with a loss function
for which we loop in n-sample blocks such that loss function remains in the defined boundary as estimated, for which the feature sets exist in the function
with optimal score > 0.5. The classifier for the upper boundaries of generalization error in the probability
, for n blocks of data sample can be provided by:
where
is the pattern identified as signals (removing noises) with the probability of 1 − p. Here, we create a straightforward approach to calculate the loss function in noisy and signal data(N) that affects classifier construction.
Thus, for each algorithm in the pool, the optimum fitness can simply be determined as:
Based on the Equations (4)–(6), the optimum fitness values can be calculated, which are given in
Table 2.
As previously mentioned, our model is built on 3-D space for the x, y, and z dimensions, which the algorithm employs to optimize the blend’s fitness (Op.F) to the supplied data. It is important to highlight that using this technique, the model is designed to be highly generalizable for any supplied data with any kind of attributes. We thus engineer the mix utilizing matrix (real-valued) space manipulation and the Frobenius norm provided by:
The matrix manipulation for each dimension to evaluate the blend can be built as:
The illustration in
Figure 2 supports the mechanics of the Theorem 1. As we observe the visualization of three functions, err|Err
, Op.F and Cost (C) being rotated based on distance function, as shown. Thus, Blender Filter Switch (logical) connect the value to the Suitability and Evaluation Score 3-D logical construct. The value of
in each dimension swing between 0 and 1, based on Op.F response from Tuning Synthesizer block.
Table 3 shows the results of developed functions.
Theorem 2. Risk Estimation, Local Errors, and Metrics Evaluation—
The algorithm generalization evaluation error {AGE(Err)} is inbound of all LE err(n), for which each occurrence of the error at any point in x and y space, exists inside all theoretical values of Err, such that. Let there be a maximum risk function (Φ) with mean square erroron the set of features asand unknown means as
The algorithm generalization assessment error, or AGE(Err), is an aggregate of all LE err(n), in which each instance of the error at any location in x and y space occurs within all conceivable values of Err, so that. Assume that the maximum risk function (Φ) has unknown means (m 1, m 2, m 3, m n) and mean square error (MSE) on the set of features (F= f 1, f 2, f 3, …, f n).
Construction. To prevent underfitting and overfitting in terms of the errors to be regulated by the upper and lower bounds. We construct the minimum and maximum error boundaries logical limit. We initially force the mistake to be at a low threshold before making it high. The algorithm then learns to keep between the min(e:0.2) and max(e:0.8) boundaries, and accuracy is obtained.
Let us define our optimum error (dynamically governed by algorithm tuning and blending process), as:
where the PTIP algorithm generates (g.f), the error gain factor. Each method tends to cause more mistakes when they are combined, hence the combined errors of both global and local functions must stay within the given range. There are two types of errors for generic machine learning modelling: estimation and approximation [
27]. Its collective name is generalization error, and finding a specific function f′(x, y) that tends to reduce the risk of training in the targeted space is what we aim to do in this case (i.e., X, Y, Z), shown as:
Figure 3 shows the concept of correlation of error bounds and risk function. As we propose the novel idea of limiting the error between 20% and 80% for optimum realistic fitness for the real-world prediction, it shows that the Risk Estimation (emp) stays in bounds of logical cube shown on the right. The center point shows the ideal co-variance of function
. P (x, Y, Z) will be unknowable at this time. Based on the “empirical risk minimization principle”, which is statistical learning theory that can employed to determine the risk.
Here, we require to fulfill two conditions, which are given below:
- (i)
- (ii)
.
These two conditions could be binding when
is comparatively trivial. The second condition needs minimal convergence. Thus, following bound can be constructed that is being held valid with probability of 1 −
is
. Thus,
can be determined as:
The sub-estimator function is
. Hence, the regularization parameter
is positive and it has been observed that the sub-estimator function
such that,
. We deduce that
, corresponds to maximal shrinking, which is
. In this case we use Stein’s unbiased risk estimate (SURE) and cross validation (CV) technique, where prominent estimators include (lasso), (ridge) and (pretest). We use the squared error loss function, sometimes called compound loss, as the basis for loss and risk estimation.
where
shows the distribution of Features F {p, q, r}. It should be observed that Loss is highly dependent on ‘D’ through value of ‘m’. We can construct the regularization parameter for which the algorithm blend fits the model to maximum relevance, such that:
.
Therefore, the risk of algorithm
can be calculated as:
Consequently, Equations (15) and (16) can be used to determine the maximum risk of algorithm
.
where
is the risk of distribution features of algorithm.
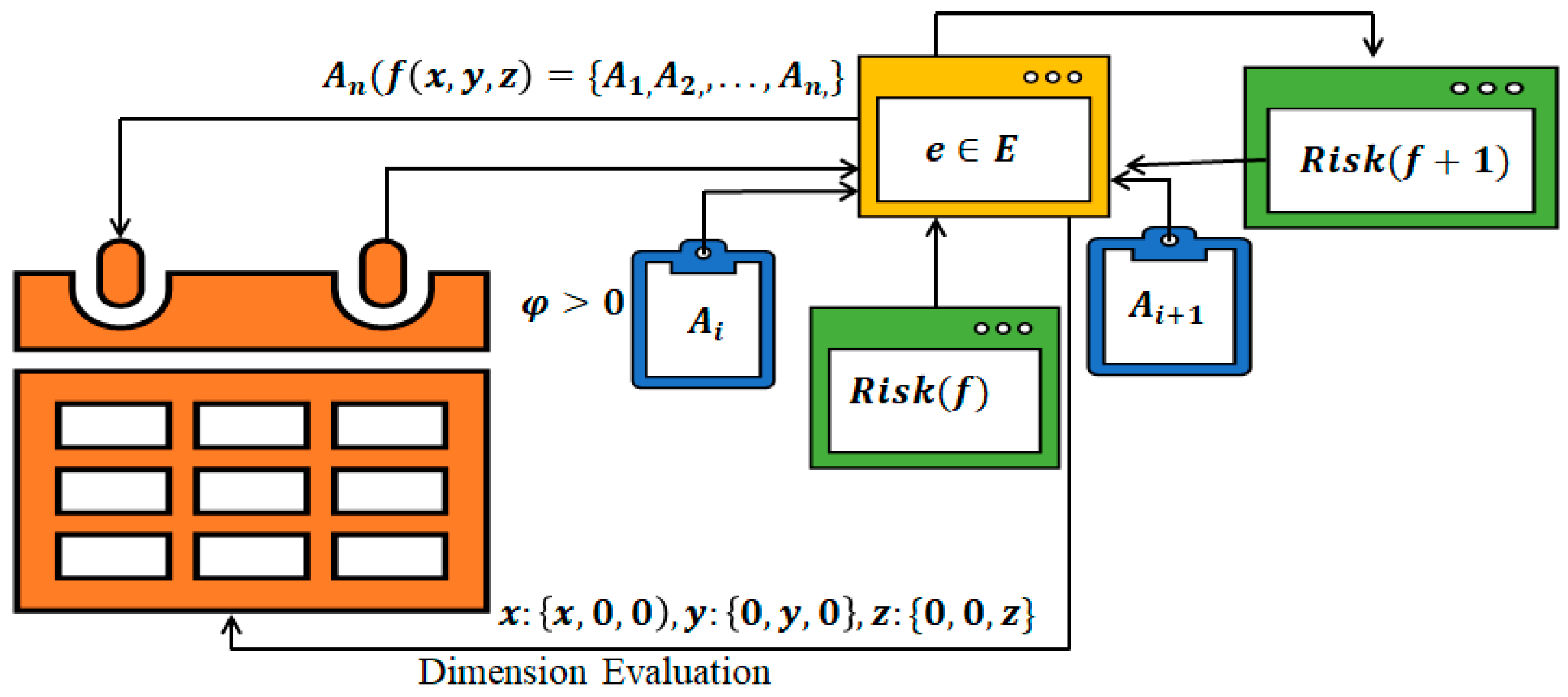
The risk estimation process of algorithm in 3-d space is depicted in
Figure 4 to support in-bound local evaluation (LE) and global evaluation (GE).
Algorithm 2 maximizes fitness, this algorithm computes the risk estimation function, local error bounds, and metrics evaluation. It builds on Theorem 1. It tunes the blend to stay within error bounds for ensuring optimum fitness based on the Risk Estimation Function and observed errors, and then assesses metrics to ensure the blend’s overall performance.
| Algorithm 2: Computation of risk estimation process |
| Input: classifier Function, Features set for sampling |
| Output: , |
| Initialization: |
Create: LTObject, , Generate ObjectIMLE(h)/* Generate an object reference for improved machine learning engine application programming interface (API)*/ Set ObjectIMLE.PublicFunctions(h.IMLE, h.EFES, h.EWPM, h.ICCS)/* managing the four constructs*/ While (Do Compute max(e) and min(e) bounds Compute /* The optimum error function */ Create Logical Table Object Create h.ICCS( /* Create Test Train Split using ICCS library. */ For (Each node in ) Do Compute Compute Loss Function If) then Replace Recompute Loss Function End If Compute Set Examine error bounds for regularization If (error > 0.2 and < 0.8) Then Update the LTobject.LT(x, y, z) Update x, y, z from Logical Table End If End For Compute, LT) Compute Compute e, E and /*Using Risk Function and LTobject Update * End While Return,
|
Theorem 3. ,andsupport the parallel Turing integration paradigm.
Proof. Let us take the pools of the supervised learning algorithms such as , which acquires the given data ; thus, the correlation exists. Therefore, matching factor can be expressed as . The LG exists for each algorithm such that GG is available in optimized fashion that is illustrated as . The optimization functions exist for each algorithm. Therefore, each algorithm possesses the set of predictor characteristics, such that and targeted variables, . Thus, each given algorithm performs well in the blend for each set of features . Hence, the enhanced weighted performance metric should be for each specified parameter, which remains above the threshold value of the measurement until falls below 0.75. Therefore, . The LE becomes very unstable in blend, and thus the model creates a complex error function ( such that > 0, and let be the measure of complexity of the GE within a probability . There must be a hypothesis “h” on GE that travels in the x, y, and z directions. It shows nonlinearity that is dependent on the number of algorithms in the blend. Moreover, it is distributed linearly throughout the space in the LE. □
Construction. The functions can be employed in the space. The optimum GG is used for induction. Therefore, Euclidean distance can be used for measuring the distance that is given by:
Similarity can then be obtained using Hamming distance
, which is specified by:
Thus, Minkowski distance
can be calculated as:
We create the related matching factor (MF) based on these data at the point when each distance reduces to the smallest potential value with the least amount of theoretical GE (Err).
The triangles are built for our blend using the 3-D space and axis align method. Let
, which specifies the immeasurable number of triangles in disseminated fashion which are given as:
The following function describes the search for optimal coordinates: where
and EWPM is obtainable through IMLE API. Let us assume that EWPM should remain above 0.5 for optimal zone in the 3D rational space. Thus, the co-ordinates for the y-axis can be expressed as:
As a result, given corresponding values and blend of the algorithms switches from multidimensional space to lower dimension. After tuning has been accomplished (Theorems 1–3), an error happened as a complicated function, dependent on a variety of variables and the fundamental blend of algorithms. The global err is displayed in
Figure 5 as every algorithm’s LE is no longer applicable mathematically. The Each algorithm’s standard deviation error (
tends to rise when it is coupled with another algorithm. A common statistical method that models relationships between n+ variables using a linear equation to determine its fitness is developed by:
The distribution can be written using Bernoulli Distribution process:
The bounds of 20% and 80% should be tuned. The small circles demonstrate the
infinite space in the logical cube depicted in
Figure 6. Note that each point varies between 0 and 100%. It is ideally used when output is binary, such as 1 or 0, Yes or No, etc. A logit function governs the linear model in LR. Thus, we can finally construct using Equation (25).
Normally we encounter classification error with training error and testing error. If we assume D to be the distribution and ‘exp’ is an example from D, and let us define target function to be f(exp) indicating the true labeling of each example, exp. During the experiment of training, we give the set of examples as and labelled as .
We examine for incorrectly classified examples with the likelihood of failure in distribution D in order to identify the overfitting.
Then, for each algorithm, we build a gain function that is dependent on fundamental performance metrics including bias, underfitting, overfitting, accuracy, speed and error [
28]. We only consider bias-ness (B), underfitness (UF), and overfitness (OF) as factors that influence how the fundamental algorithm learns. As a result, we may start creating the gain function
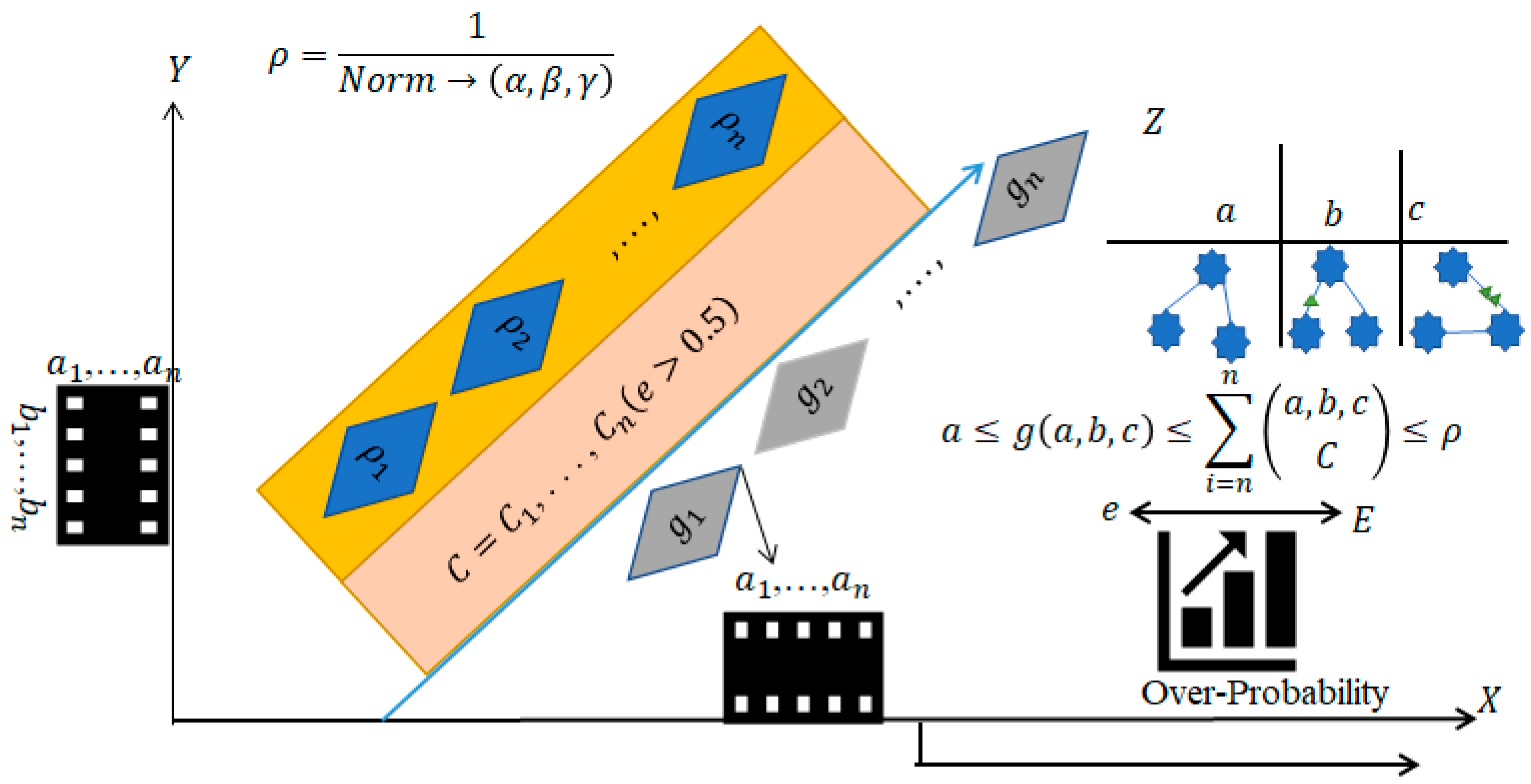
. As illustrated in
Figure 7, we establish the GG to ensure that the LG for every blend reduces the distance between the two triangles in order to create the blend function. Furthermore,
Figure 7 also illustrates over-probability stretch using three dimensions. The correlation of the features
, gain function
and over probability
can be determined as:
Overfitness (z) is observed to be reduced in the and coordinates. The primary purpose of GG is to maintain the point in the area where the mistake “err” is acceptable.
We tweak the gain function to ensure that in the final blend we may filter the algorithm and progressively blend to be as optimal as is feasible. This is done in considering the fact that LG will be extremely high in lower dimension, and GG designated as
will be lower in lower dimension. As rationally demonstrated in the algorithm formulation, the approximation function (AF) connects the score factor between a collection of predictor characteristics
= {1, 2, 3, 4,......,
} and target variables
= {1, 2, 3, 4,......,
}. As a result, we compute GG by employing Equations (24)–(28).


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}