1. Introduction
Nowadays, the consumption of perfume products is getting more and more popular, which has promoted the development of the perfume industry. Genuine perfume products of famous brands are commonly produced using confidential professional techniques with selected ingredients. The high profits brought by genuine perfume products stimulated unscrupulous businessmen to counterfeit them with cheap and even noxious ingredients [
1]. The existence of counterfeit perfume products not only affected the legal income of genuine perfume manufacturers, but also harmed the health of perfume consumers. However, since the scents in perfume products interact naturally by synergism, compensation, and masking [
2], it is hard to expose counterfeit perfume by solely using the human nose. To reliably identify the accurate perfume type, it is necessary to consult specifically designed electronic techniques. Moreover, portable and integrated PI solutions, which bring about high efficiency and great convenience, are significant for real applications.
Existing electronic techniques that can be used for PI mainly include EN [
3,
4], fluctuation-enhanced sensing (FES) [
5,
6], gas chromatography (GC) [
7], and GC with mass spectrometry (GC-MS) [
8,
9]. Typical ENs are mainly composed of the measurement acquisition hardware and data processing software. The measurement acquisition hardware comprises the gas route and electronic components. Commonly, the gaseous perfume samples are guided towards the mounted gas sensors. Then, the sensing data of the gas sensors is denoised and stored. Based on the denoised sensing measurements, the perfume type is identified by the data processing software [
3]. In contrary to ENs, FES exploits the information contained in the low measurement noises [
5] or micro-fluctuations of measurements [
5,
6]. Typically, the low measurement noises are successively processed with a band-pass filter and an amplifier. Based on the processed data, FES signature spectrums can be calculated by multiplying the normalized power spectral density and the frequency. In the FES mode, multiple different gases can be identified based on the measurements of only one sensor [
5]. However, compared with the acquisition of denoised measurements in EN systems, the extraction of low measurement noises in FES methods is more difficult and cost-consuming. GC and GC-MS utilize the standard carrier gas stored in large gas cylinders to drive the gas sample through the chromatographic column. Apart from identifying the perfume type, GC and GC-MS can also separate the different perfume ingredients. Nevertheless, the high cost and large volume of GC and GC-MS stagnate their portable on-site usage. In comparison, EN is relatively more cost-effective and portable. Although existing EN solutions have rarely been reported separating the gaseous ingredients, the gas identification capability of ENs can help in exposing counterfeit perfume products. For example, the integrated handheld EN designed in the author’s laboratory, namely SMUENOSEv2, which utilizes an embedded NVIDIA Jetson nano module as the computation kernel, is suitable for quick on-site PI applications [
3].
To improve the PI performance, it is important to design accurate and time-efficient EN-based PI methods. Conventional combinatory EN-based PI methods [
4,
10,
11,
12,
13] involve the combination of multiple successive steps. The raw measurements are first preprocessed to remove the baseline value and noises. Based on the preprocessed measurements, a set of features are generated by normalization, differentiation, and/or integral operations. The dimension of generated features is then reduced by using the feature extraction methods, such as, principal component analysis (PCA) [
14], local linear embedding [
15], maximally collapsing metric learning [
16], and so on. Finally, the features with reduced dimension are classified using machine learning methods, such as support vector machine [
17], back-propagation neural network (BPNN) [
18], extreme gradient boosting (XGBoost) [
19], light gradient boosting machine (LightGBM) [
20], and so on. The perfume type can be identified according to the feature classification result. For each of the above-mentioned steps, there are multiple candidate methods can be selected. Different combinations of selected methods can cause significantly different PI results. The complicated selection process of constituent methods and parameter values influences the time-efficiency and reliability of conventional combinatory methods.
During the past decades, the investigation on deep learning for image classification has aroused worldwide interest [
21], which also induced the implementation of deep learning for EN-based PI applications. Unlike conventional combinatory methods, deep learning methods incorporate the processes of feature generation, extraction, and classification. In the deep learning research field, one of the representative methods is the CNN method. LeCun et al. proposed the LeNet for document recognition [
22], which can be considered as the seminal work of CNN. Afterwards, multiple of improved CNN methods, such as, AlexNet [
23], VGGNet [
24], GoogleNet [
25], ResNet [
26], and so on, were presented for image classification. Inspired by these works, a few CNN models were proposed for solving the EN-based PI problem. To realize gas classification, Peng et al. proposed a very deep CNN with 38 constituent layers, namely GasNet [
27], which mainly comprises six convolution blocks of multiple layers, a global average pooling layer, and a fully connected layer. Syuan et al. [
28] proposed to transfer the gas measurements to feature map images, which are then processed using a deep CNN with seven convolution blocks of three layers, a global averaging pooling layer, and a fully connected layer. Wang et al. [
29] presented a dense CNN, which comprises multiple alternating pairs of dense and transition blocks, to process the EN’s data for identifying the age of mature vinegar. Each of the employed dense and transition blocks are composed of multiple layers. In these works, the computation kernels used for training the CNN models were not detailed. Although all these works utilized deep CNN models, whether a shallow or not very deep CNN model can obtain satisfactory EN-based PI performance needs further investigation. Moreover, with the integrated handheld SMUENOSEv2, the CNN model should be trained on the resource-limited NVIDIA Jetson nano module. For quick on-site EN-based PI, it is necessary to restrict the number of layers in the CNN model.
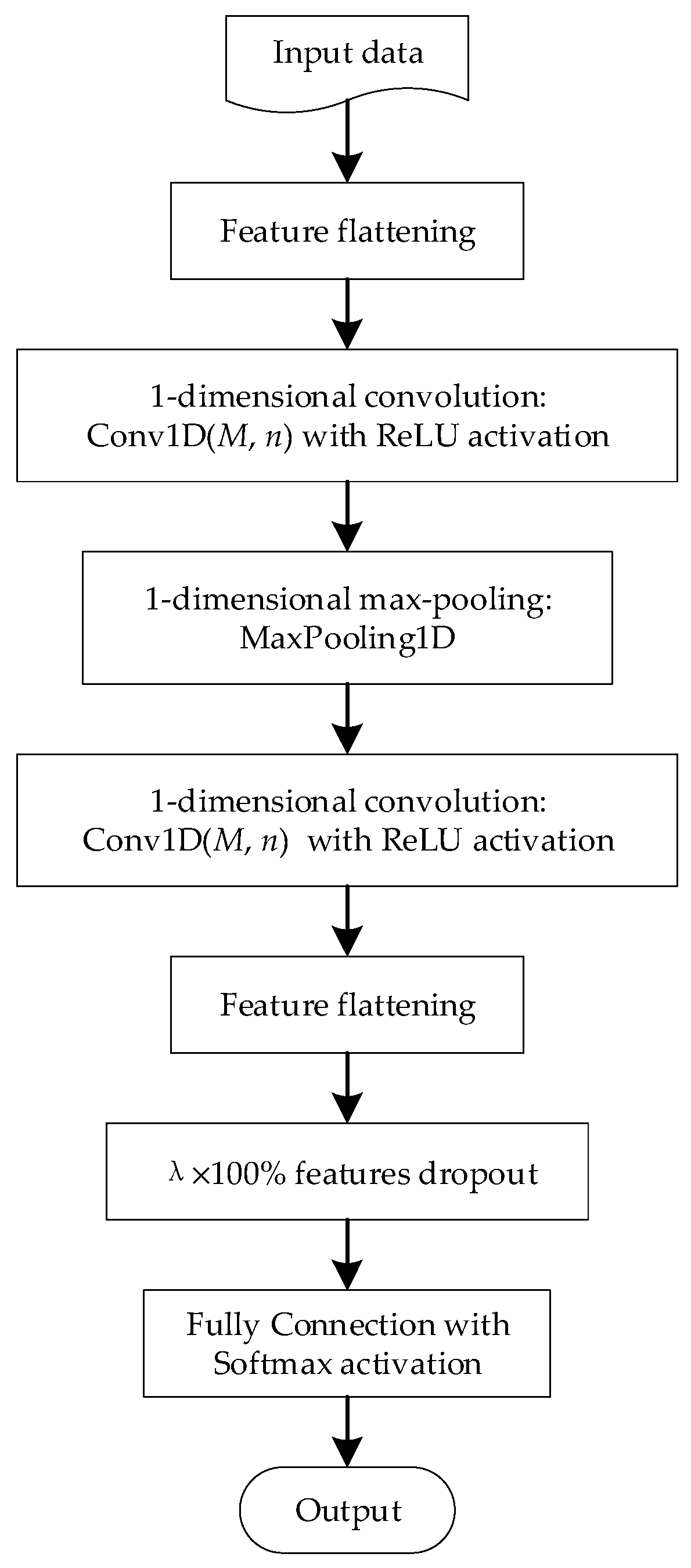
In this paper, a light-weight CNN model, namely LwCNN, is presented for solving the PI problem based on the SMUENOSEv2 platform. Considering the limited computational resource, LwCNN only utilizes two 1D convolutional layers with activation, two feature flattening layers, a 1D max-pooling layer, and a fully connected layer with activation. Among the constituent layers of LwCNN, only the convolutional layers and the fully connected layer contain several trainable weights. Moreover, LwCNN incorporates the sub-processes of feature generation, extraction, and classification, which means the complicated selection of methods and parameter values for these sub-processes are simplified. To comprehensively evaluate the performance of LwCNN, four benchmark methods, those are, XGBoost, LightGBM, BPNN, and GasNet, were compared with LwCNN in extensive real experiments. The novelties of this paper mainly comprise three parts. First, LwCNN employs a feature flattening layer as its first layer, which concatenates the preprocessed measurements of different sensors into a 1D vector. The 1D vector incorporates the information within the junction sections of data sensed by different sensors, which inspired the utilization of 1D convolutional and max-pooling layers. Second, the disposition scheme of the selected constituent layers in LwCNN is novel. The performance of a CNN model is dominated by the selection and disposition of its constituent layer. Third, the experimental PI results of LwCNN obtained on an integrated handheld EN platform are novel. Especially, the evaluated influence of CNN parameters, such as convolution kernel number and length, the dropout proportion, on the PI performance has rarely been studied.
The rest of this paper is organized as follows. In
Section 2, the conventional process of EN-based PI is introduced.
Section 3 details the operations in LwCNN.
Section 4 introduces the experimental setup. The experimental results are detailed and discussed in
Section 5.
Section 6 concludes the whole paper.
2. Conventional Process of EN-Based PI
To make the EN-based PI methods more understandable, the employed EN platform is briefly sketched first.
Figure 1 shows the architecture of the employed integrated handheld EN, namely SMUENOSEv2, which comprises two main types of components: the gas route and electronic components.
At the beginning of each sampling cycle, the perfume samples were dripped into the volatilization pot. Fast airflow was generated by the air pump, and then, guided to accelerate the volatilization of the perfume samples. Then, the volatilized gaseous perfume was carried towards the three-way valve. By controlling the three-way valve, the gas route at the downflow side of the volatilization pot can be switched between the sub-routes 1 and 2, which are timely switched to activate the sampling and washing modes. Once the gas route 1 was switched on, the gaseous perfume was carried towards the gas chamber, which means the gas sensors were exposed in the gaseous perfume. Thus, the three-way valve can be timely switched to control the exposure time of the gas sensors. During the exposure time, the sensing voltages were sampled using AD7606 and STM32. The sampling data was then transmitted from the STM32 to the NVIDIA Jetson Nano module, on which the PI methods were conducted to complete the EN-based PI task.
Conventional combinatory EN-based PI methods comprise multiple successive steps: data preprocessing, feature generation, feature dimension reduction, and feature classification. For each step, there are multiple candidate methods can be selected to complete the corresponding task. For each candidate method, multiple hyperparameters should be tuned to improve the PI performance. Different combinations of methods and parameter values can severely influence the final PI performance [
4,
30].
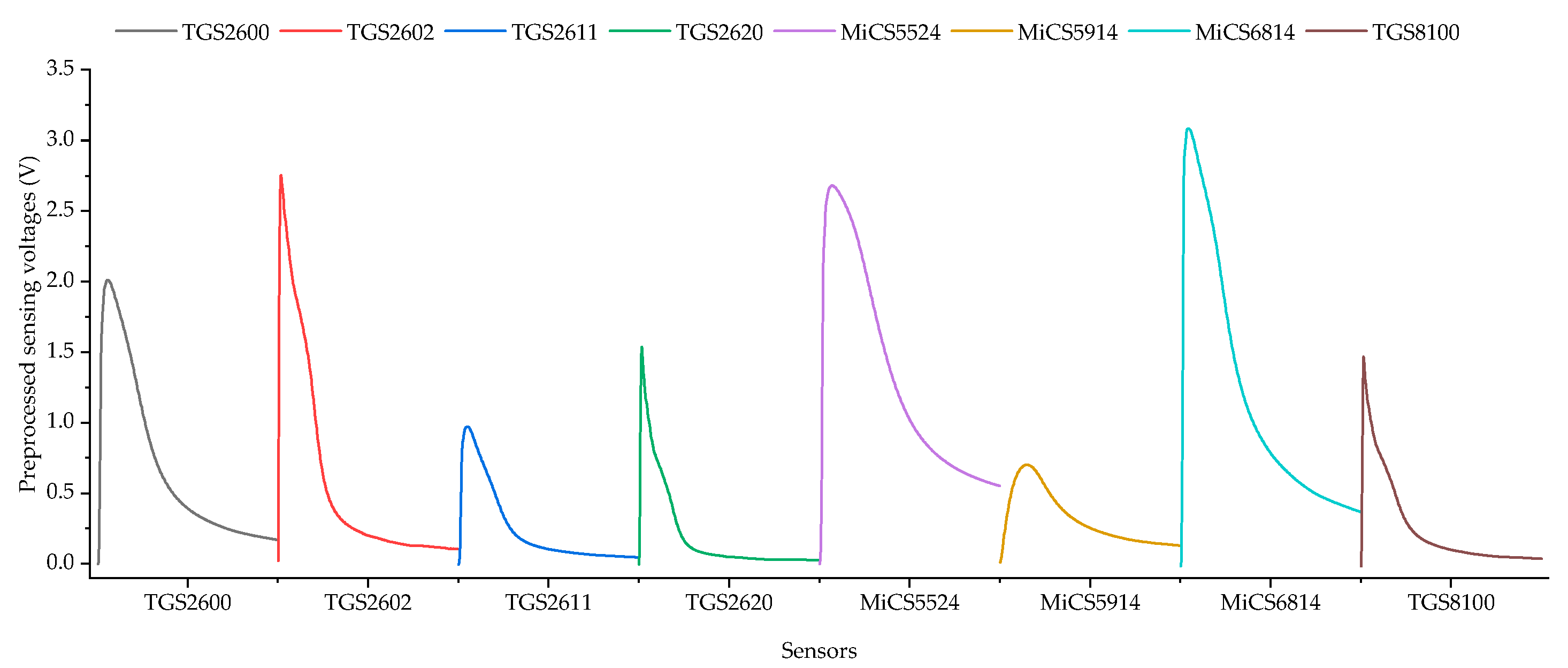
Data preprocessing aims to reduce the influence of measurement noises and gas residuals within the EN’s gas route. For filtering the measurement noises, the wavelet denoising method was employed. In the author’s previous work, it has been proven that the wavelet denoising method are capable of filtering out most spiky noises. Subsequently, a baseline subtraction operation was conducted to inhibit the influence of gas residuals within the EN. The term ‘baseline’ means the sensing voltages measured before the gas sensors were exposed in the gaseous perfume. The baseline voltages were mainly caused by the gas residuals left over during the former inexhaustive washing cycle, since the working mode of SMUENOSEv2 can be consecutively switched between the sampling and washing modes.
After data preprocessing, the data dimension was still retained at a high value. Due to the curse of dimensionality, directly conducting feature classification with the preprocessed data is time consuming. To generate the features for further classification, multiple statistics were calculated, including normalized peak of the sensing value, normalized time when the voltage peak appeared, final falling proportion, falling proportion at 10 s after the maximum sensing value, and normalized time when the first-order derivative reached the maximum value. Due to the metal oxide semiconductor sensors used in our EN, the sampled sensing voltages demonstrate a fast rising and relatively slow recovery dynamics. It is expected that the generated features are capable of characterizing the dynamics of the sampling data, and thus, contain distinctive information that can be used for further classification. Typically, further feature extraction or dimension reduction was also required. PCA can be used to extract the principal components with lower dimensions as the final features.
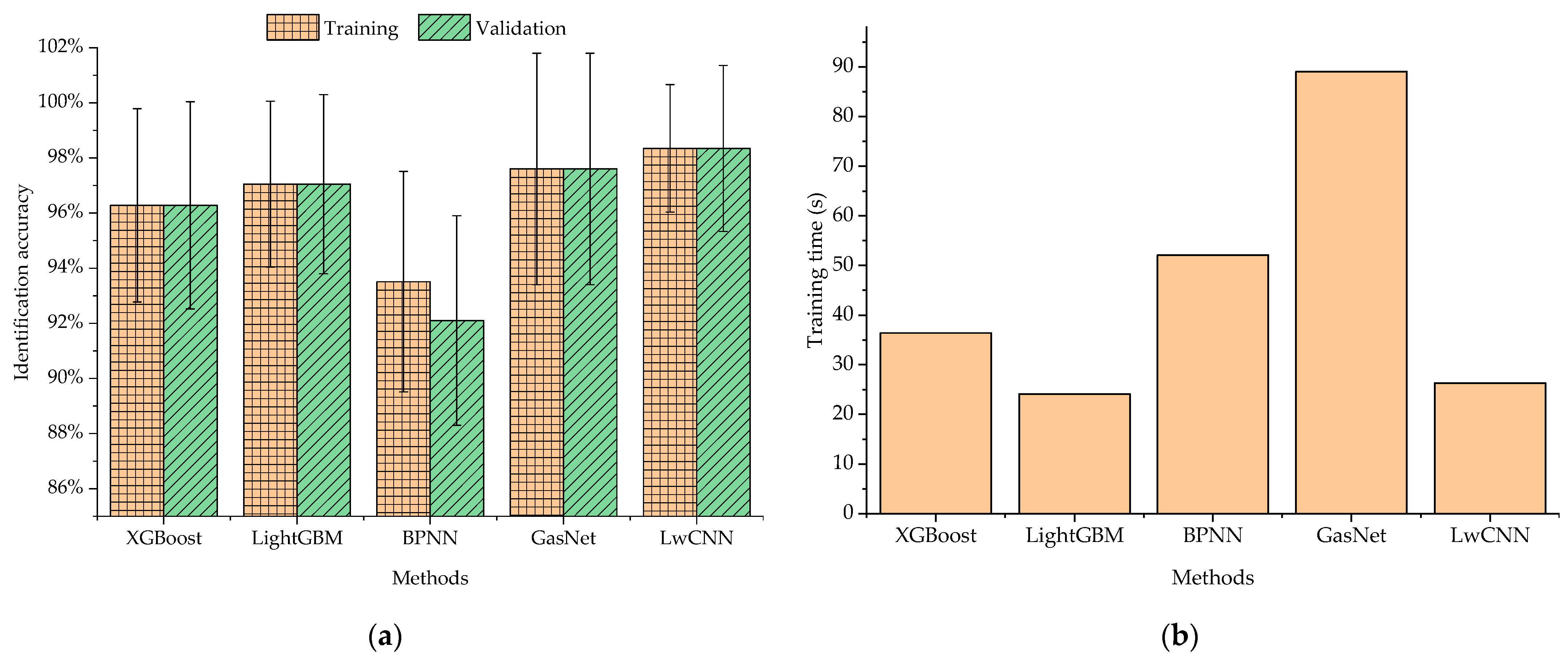
Finally, the generated features with reduced dimension were classified to complete the PI task. As three conventional EN-based PI methods, BPNN, XGBoost, and LightGBM methods were separately used as the benchmark methods for feature classification. BPNN is the canonical form of neural network. XGBoost and LightGBM are two improved implementation forms of the gradient-boosting decision tree method, in which the results of multiple decision trees are ensembled to form a better result. According to the author’s previous works [
4], XGBoost outperformed other tested methods in terms of mean identification accuracies, while LightGBM obtained similar identification accuracies with relatively higher time-efficiencies.
3. Light-Weight CNN for EN-Based PI
Figure 2 shows the architecture of LwCNN. The main operations of LwCNN comprise a sequence of operation layers. Due to the different gas residuals left over in the EN’s inner space, a baseline subtraction was employed to preprocess the raw measurements. The preprocessed measurements were used as the input of LwCNN. Then, the output of each individual layer is considered as the input of its below layer. Unlike the multiple separated algorithms successively employed in conventional combinatory methods, the operation layers in LwCNN are connected with each other to construct a single network-shaped algorithm.
The operations in the layers of LwCNN are detailed as follows.
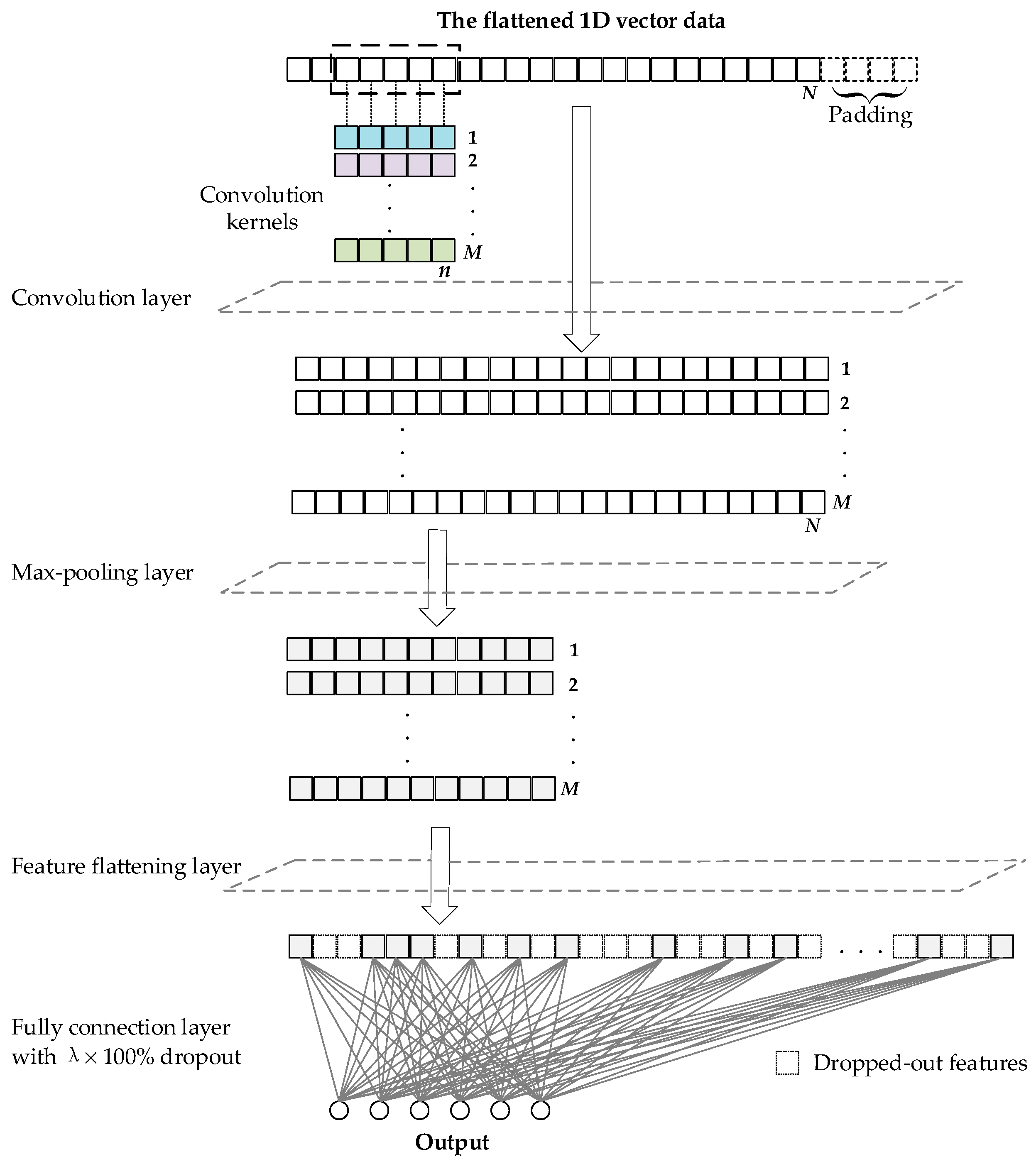
As shown in
Figure 2, the input data was first processed with the feature flattening operation, in which the preprocessed measurements of the eight different gas sensors were concatenated with each other in a one-by-one manner. In consequence, a 1D vector data was constructed based on the sampling data obtained with an individual perfume sample in each sampling cycle. The 1D vector data inspired the usage of the 1D convolution kernel in the subsequent layer.
- 2.
1D convolution
The defining characteristic of a 1D convolutional layer is that the dimension of the utilized convolution kernel is one. As illustrated in
Figure 3, the length of input vector, the number of convolution kernels, and the length of each convolution kernel are denoted as
N,
M, and
n, respectively. In the 1D convolution operation, each convolution kernel is used to generate a new intermediate vector, which is also called tensor. A total of
M tensors or vectors are generated with the
M convolution kernels.
Figure 3 illustrates the case that
n equals 5. In specific, as indicated by the dashed rectangle in
Figure 3, a set of five successive elements of the input data are selected as the factor. A point multiplication between the selected factor and the convolution kernel is conducted. The result of the point multiplication is recorded as one element of the newly generated tensor. As the dashed rectangle moves from the left beginning to right end of the input vector, multiple factors are selected to activate multiple times of point multiplication with the convolution kernel, which result in multiple elements to form the new tensor. To generate a new tensor with the same length as the input vector, four random elements are padded at the end of the input vector. With the padding operation, a total of
N factors are selected, and a tensor with the length of
N is generated with each convolution kernel.
- 3.
Activation
Each convolutional layer is followed with an activation operation. In the activation operation, all elements in the tensor are separately substituted into a transfer function. An individual result is generated by the transfer function with each element in the tensor. The results are combined to form a new tensor. Thus, the tensor length is kept invariant in the activation layer.
There are two different types of activation operations used in LwCNN. As shown in
Figure 2, the activation functions used after the convolutional layer and the fully connected layer are the ReLU function and the Softmax function, respectively. The ReLU function replaces the negative elements in the tensors with zero-value elements, which can be represented as follows.
The Softmax function, which maps the value of multiple elements into probability values within the range (0, 1), can be represented as follows.
- 4.
1D max-pooling
In the 1D max-pooling layer, the elements of input tensor are categorized into successive units. The maximum element in each unit is calculated. Then, all the resulting maximum elements are used to construct a new tensor.
Figure 3 illustrates the case that the size of each unit is 2. Then, the tensor length is reduced to
N/2 by the 1D max-pooling layer. The max-pooling layer can help reducing the tensor length and complexity of the LwCNN.
- 5.
Feature dropout
In the feature dropout layer, a portion of randomly selected elements in the tensor are deactivated or dropped out in the current epoch. The proportion of deactivated elements is denoted as λ. The feature dropout layer directly cut down the number of weights in the LwCNN model. Note that, on top of the feature dropout layer in
Figure 2, a feature flattening layer is employed to flatten the
M tensors into a new 1D tensor.
- 6.
Fully connected
In the fully connected layer, each input element is connected with each of its output element. Since LwCNN was designed for feature classification in EN-based PI applications, the number of output elements of the fully connected layer in LwCNN equals the number of perfume types.
Figure 3 illustrates the case that the number of perfume types is 6. Supposing the number of elements output by the above feature flattening layer is
N′, the fully connected operation in
Figure 3 can be represented as follows.
where
ai,
i = 1, 2, …, 6, are the outputs,
wij,
i = 1, 2, …, 6,
j = 1, 2, …,
N′, and
bi,
i = 1, 2, …, 6 are trainable weights. The values of outputs
ai,
i = 1, 2, …, 6 are then substituted into the Softmax function shown in Equation (2) to calculate the corresponding probabilities, which can be directly used for feature classification.
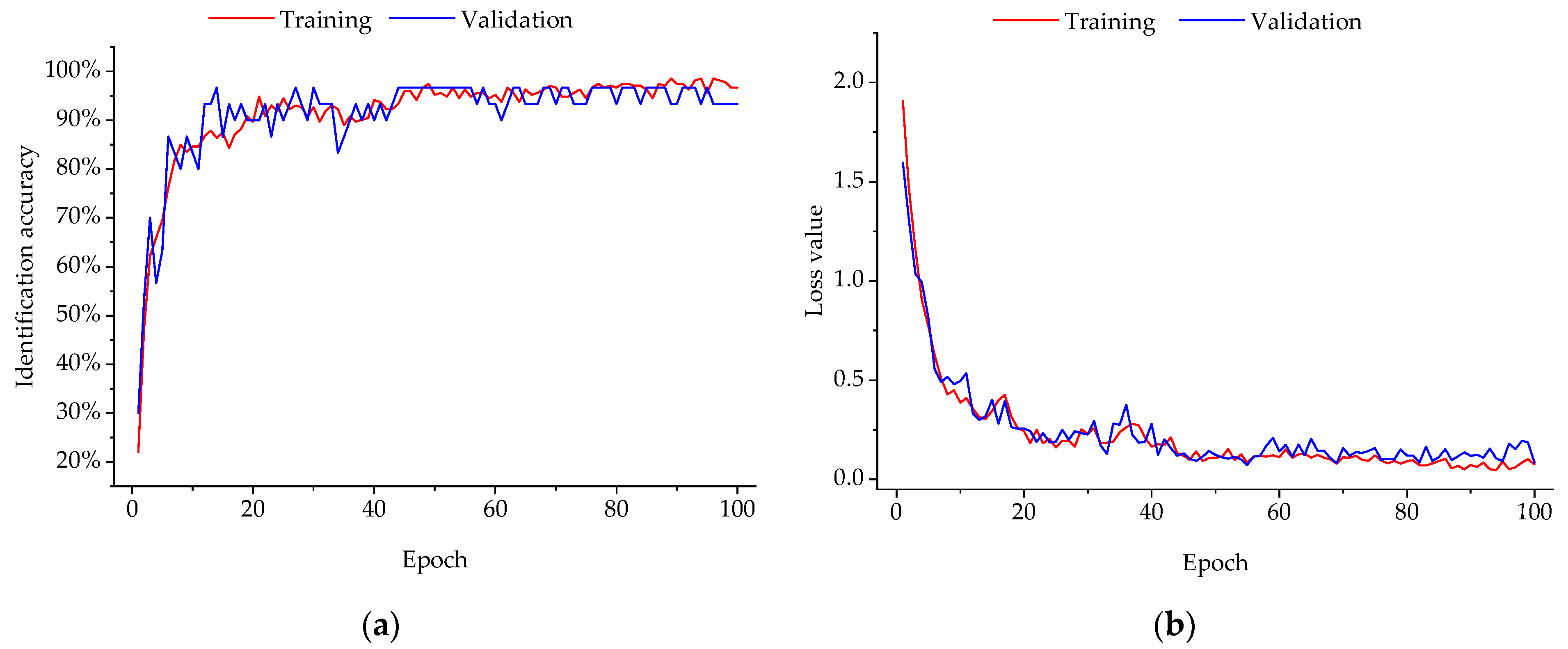
Last, but not the least, in order to improve the classification accuracy, the operations shown in
Figure 1 can be repeated for multiple epochs. In multiple training epochs, the preprocessed measurement data was repeatedly used as the input of LwCNN. The weights of the LwCNN model were incrementally updated for multiple times.
4. Experimental Setup
Six perfume products of the same brand “Scent library” were used as the perfume samples in our experiments. The model names of these perfume products are Golden Osmanthus, Misty Rainbow, L.B.K. Water, Rose Rose I Love You, Tao Hua Yun, and White Rabbit, which are abbreviated as GO, MR, LBK, RR, THY, and WR, respectively. According to the ingredients, the main common constituents of these perfume products are denatured ethanol, essence, propylene glycol, and so on. Moreover, perfume products with different model names have some specific constituents, such as, GO contains tridecanol polyether-9, RR contains oaklirin, WR contains tertiary butanol, and so on. Commonly, the combinations of constituent content are different for perfume products with different model names. To obtain experimental sampling data, each perfume product was sampled for 50 times. Thus, a set of 300 samples were obtained in our experiments.
In each sampling cycle, 1 uL of perfume product was dripped into the volatilization pot of SMUENOSEv2. Fast airflow generated by the air bump was guided to accelerate the volatilization of the perfume sample, and to carry the volatilized perfume towards the surroundings of the eight gas sensors. In the meantime, the sensing voltages of these sensors are simultaneously sampled. To reduce the computational burden, a down-sampling technique was utilized in SMUENOSEv2 to cut down the sampling frequency from 150 Hz to 7.5 Hz. At the beginning of each sampling cycle, the sampling mode was activated by switching on the gas route 1 shown in
Figure 1. The first 500 voltage measurements of each sensor were used in our experiments. By feature flattening, the eight measurement sequences with the length of 500 were then concatenated into a single 1D input vector. Therefore, the length of the 1D vector used for the first convolutional layer of LwCNN is
N = 500 × 8 = 4000.
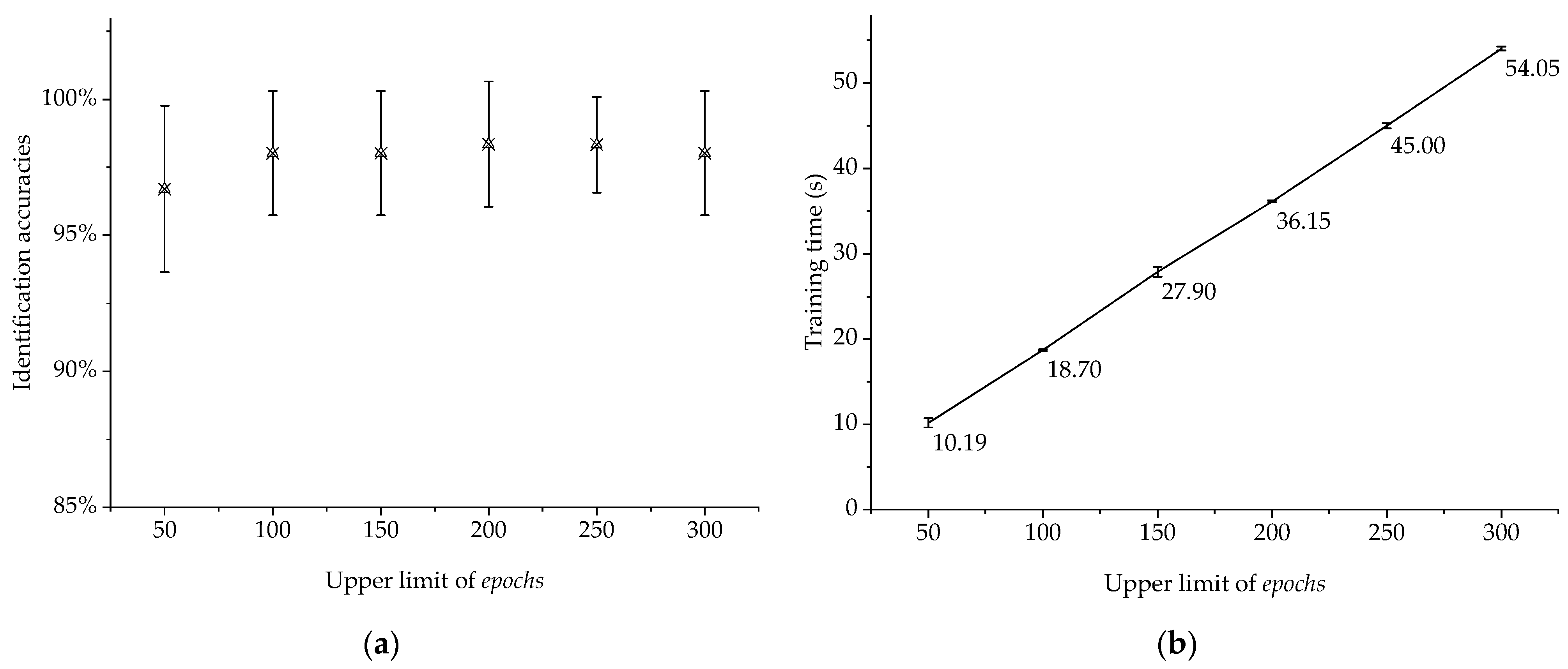
Based on the sampling data, three groups of experiments were conducted. First, the optimal value of maximum training epochs was determined for LwCNN by statistical comparison. Empirically, the number of training epochs can seriously influence the spent training time, which is one of main concerns about using the integrated handheld EN in this paper. Then, a set of orthogonal experiments [
31] were conducted to determine the optimal values of the three hyperparameters in LwCNN, which are the convolution kernel number
M, the convolution kernel length
n, and the dropout proportion
λ. Finally, the four benchmark methods, those are, XGBoost, LightGBM, BPNN, and GasNet, were evaluated in 10-fold cross-validation experiments. Based on the experimental results, the performance of LwCNN was compared with the four benchmark methods. As tested in the author’s previous works [
3,
4], the hyperparameters of XGBoost, LightGBM, BPNN were automatically tunned using the
hyperopt Python module [
32], which models the parameter tuning process as solving a multi-variant function optimization problem. The time spent for automatic parameter tuning was included in the model training time, since the parameter values are also part of the trained model. For GasNet, the parameter values were fixed as those used in [
27].









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}