1. Introduction
Antenna arrays have been widely used for finding signal sources and concentrating beam energy in addition to suppress communication interferences. For example, the direction of arrival (DOA) estimation with the use of antenna arrays has revealed a diverse range of applications such as wireless communications, radar, and sonar, etc. The most classic DOA estimation algorithms are subspace-based methods, e.g., the multiple signal classification (MUSIC) algorithm [
1], estimation of signal parameters via rotational invariance techniques (ESPRIT) algorithm [
2], etc., and their extended variants [
3,
4,
5,
6]. These methods are developed based on the angle mapping relationship between the signal direction and the antenna array, assumed that the relationship between a mapping and the incident angle is reversible. Based on this assumption, the array output can be matched by the mapping to achieve directional estimation. The DOA estimation performance of these parametric estimation methods depends largely on the mathematical model between the mapping and the incident angle, the mapping from the direction of the signal source to the antenna array output, and the inverse mapping from the antenna output to the direction of the signal source.
Due to non-ideal antenna design, limitations of practical implementation, and mutual interferences between antennas, there may be various imperfections existing in array systems [
7,
8,
9]. In a real system, the mapping between the signal direction and the antenna array output is much more complicated than the mathematical model that is usually expressed in the literature [
10]. There are various drawbacks in array systems because they are not easy to be accurately modeled such that incorrect models can also cause a significant performance degradation on DOA estimation. In order to reduce the impact of various imperfections, the past works, as found in the literature, merely established simplified models to describe the effect of array imperfections. Most of the problems with simplified array imperfections in mathematical models often consider the following factors: antenna position error, antenna gain and phase error, and mutual interference between antennas, etc. [
11]. However, these simplifications and assumptions of parameters and models may still deviate from the actual antenna situation to some degree. In addition, there may be a combination of imperfections in the actual system, which is more difficult to accurately model and calibrate [
12] because developing parametric methods to solve these problems is quite difficult. Therefore, it is difficult to find new parametric methods in this research area.
Recent research works have introduced machine learning and deep learning techniques for DOA estimation problems [
13,
14,
15,
16,
17]. Since machine learning and deep learning methods are data-driven, they do not rely on the mapping between signal direction and antenna arrays as well as their modeling and assumptions about various array imperfection patterns. In the literature, machine learning methods have been proposed to be better than subspace-based methods in computational complexity [
13], and have comparable performance with them in experiments [
14]. However, machine learning techniques demonstrate a satisfying performance in the case when the training and test data have nearly identical distributions. In a practical application of considering many unknown parameters for an imperfect array, it is difficult to reach such an ideal condition with enough training data set to cover the distributions of all test data as noted in [
9]. The autocalibration method is another appealing approach widely studied to deal with imperfect arrays for DOA estimation [
18,
19,
20]. Most autocalibration methods still rely on accurate mathematical modeling for imperfect arrays and, besides, the combined effects of multiple kinds of imperfections probably exist in practical systems. Those practical limitations make the problem difficult to be modeled precisely for perfect calibration. In the past few years, some literature has introduced the use of deep learning techniques to solve the DOA estimation and localization problem for microphone arrays when considering very serious environments such as dynamic acoustic signals [
15], reverberation environments [
16], and broadband signals. In such applications, it is difficult to model the propagation of the signal to be analyzed, and it is also rather difficult to solve these problems using parametric methods. However, deep learning methods can reconstruct complex propagation models based on training data, and then estimate the direction and location of sound sources. This approach first converts the original sound signal into the time–frequency domain, and then takes the converted signal as the input of the deep neural network (DNN) [
17]. DOA estimation of sound signals can be implemented in a similar way to pattern recognition of images.
The use of autoencoders (AE) to handle wireless positioning was mentioned in [
21,
22,
23,
24]. Ref. [
21] designs a sparse AE network to automatically learn discriminative features from the wireless signals and merges the learned features into a softmax-regression-based machine learning framework to simultaneously realize location, activity, and gesture recognition. Ref. [
22] proposes a convolutional AE (CAE) for the device-free localization problem. Different from the fully connected layers in an AE, a CAE consists of a convolutional encoder and the corresponding deconvolutional decoder. The encoder part is implemented to extract feature maps from input images, while the decoder part is used to reconstruct information from the learned feature maps. In [
9,
25], the framework based on the DNN AE (DAE) technique is proposed for DOA estimation concerning array imperfections. Ref. [
9] first calculates the cross space matrix (CSM) of the array output, uses it as the input of the DAE, and then introduces the multitasking AE before multilayer classifiers to decompose the input signal vector into several spatial subregions. A series of parallel multilayer classifiers was finally introduced to implement DOA estimation. It features a multitasking AE executing an operation similar to a spatial filter to preprocess signal samples, which helps to narrow the spatial range covered by DOA estimates for input samples, thereby greatly enhancing the versatility of the proposed method in unknown situations. If a set of training samples is used to train a DAE, the corresponding DOA estimation method does not need to be processed with any prior assumptions about them.
For DOA estimation with DNN [
26,
27], a key point is how to extract important features that represent different locations. In this paper, we integrate a convolutional neural network with AE to build a new CAE structure to deal with DOA estimation problems. To explain the innovation in the new method, we state the following.
- (1)
The new structure combines the advantages of convolutional kernels and DAE, in which the convolutional kernel is better suitable for learning local features in different subregions and a hierarchical framework similar to a DAE remains to deal with DOA estimation.
- (2)
A fully connected neural network is used in a DAE, where every neuron between two adjacent layers is connected. When the feature dimension of the input layer becomes very high, the parameters that a fully connected network needs to train will increase dramatically, leading to the calculation speed becoming slower. In the proposed CAE, the neurons of the convolutional layer are only connected to some neuron nodes in the previous layer.
- (3)
The connections between neurons are not fully connected, and the weight and offset of the connections between some neurons in the same layer are shared, which greatly reduces the number of parameters that need to be trained.
- (4)
The convolutional operation in CAE is essentially an input-to-output mapping with DNN, which can learn a large number of mapping relationships between input and output, without the need for any precise mathematical expression between input and output.
The remainder of this paper is organized as follows.
Section 2 describes a simplified model about the imperfections in a non-ideal array antenna.
Section 3 gives a brief review on the DAE structure while
Section 4 explains the proposed CAE structure.
Section 5 demonstrates the numerical results, and
Section 6 summarizes our work.
2. Signal Model with Array Imperfections
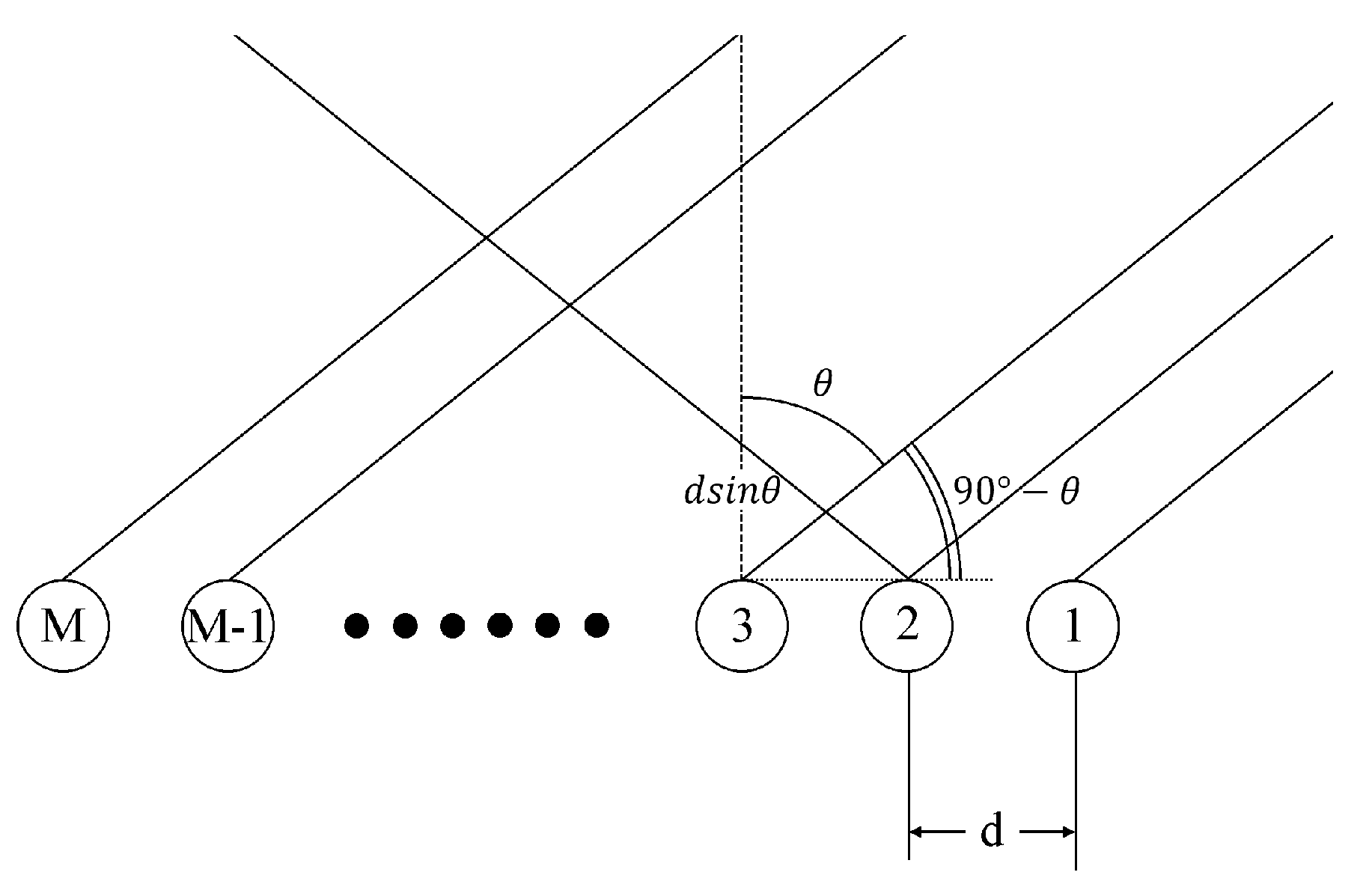
Consider that a planar uniform linear array (ULA) consists of
M antenna elements, and
d represents the distance between two neighboring elements of the receiving array. Assume that the signal source is far-field and the signal
impinges on the antenna elements in straight lines. The azimuth of the incident signal is given by
, as shown in
Figure 1. Let
denote the propagation delay of the
mth antenna element, then
,
, and
c is the speed of light. The wave path difference due to the time delay
will cause a phase shift such that the signal received by the
mth antenna at time
can be written as
where
is the wavelength of the signal. From (
1), the
signal vector
received by
M antennas can be expressed as
where
denotes the transpose of a vector and
is the steering vector. Suppose
⋯
is the additive zero-mean white Gaussian noise (AWGN) vector with covariance matrix
, and the received signal vector with
M antennas can be rewritten as
Three typical kinds of array imperfections are considered in our framework, including gain and phase inconsistence, antenna position error, and inter-antenna mutual coupling. Those imperfections cause different deviations to the steering vector in (
2). Denote the collection of imperfection parameters by
and the ideal steering vector by
. We represent the array responding function due to imperfections as
. In practice, array imperfections are complicated to be formulated with concise mathematical models, and we consider a simplified model in this paper as
.
Let
denote the collection of array imperfections, in which those elements represent for the imperfections of gain and phase biases, position error, and the mutual coupling matrix, respectively. From [
9], the perturbed array responding function can be written as
where
and
are used to indicate whether a certain kind of imperfection exists,
is used to specialize the strength of the imperfection,
is the
identity matrix, and
denotes the diagonal matrix of the given vector in
.
Let
denote the inter-channel mutual coupling coefficient vector, then
where the elements in
contain the power terms of the coupling coefficient
, where
,
and
. Then,
is a Toeplitz matrix with the vector
, that is [
28],
in (
4) represents for the gain bias of
M antennas [
29]
where
.
in (
4) represents for the phase bias of
M antennas
where
.
in (
4) represents for the position bias of
M antennas
where
. When the positions of
M antennas are skewed, the steering responding function
becomes
In the literature, there are mainly four possible approaches to deal with the imperfection problem: model-based algorithms, machine learning methods, such as support vector regression (SVR) mentioned in [
9], autocalibration, and deep learning methods. Those four approaches have their individually better application scenarios and situations. For example, model-based and autocalibration methods rely on the mathematical model of imperfections to find solutions. With a precise model, they can reach a good theoretical RMSE performance. The machine learning methods usually lack robustness to noisy training data sets. However, without the assumption of knowing precise imperfection model as a priori knowledge, machine learning and deep learning algorithms have been recently considered to estimate the angle between the incident signal and the array antennas, which seems more flexible than other approaches and general subspace-based estimation algorithms, such as MUSIC, ESPRIT, etc., to yield robust DOA estimation for imperfect arrays in practical environments.
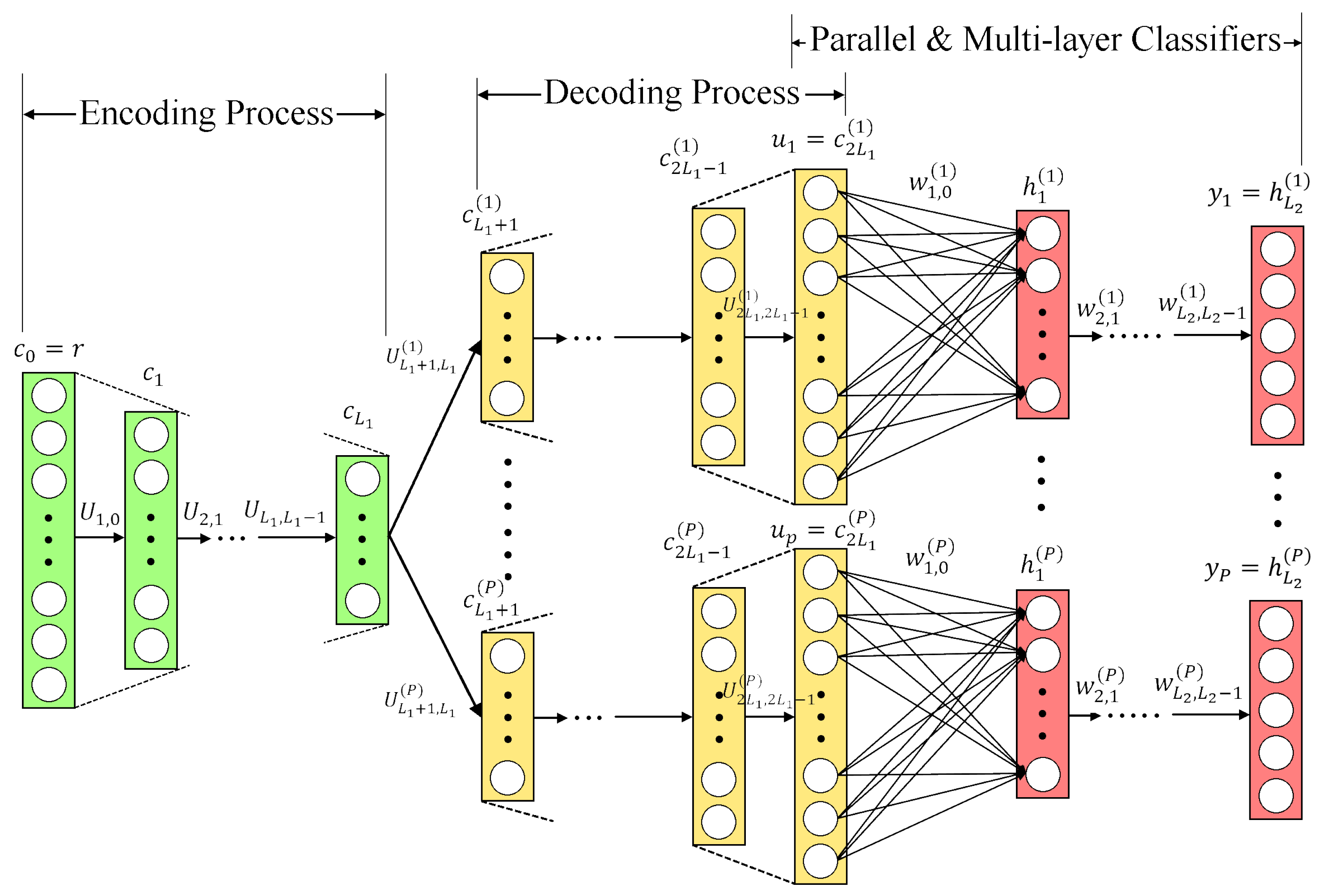
3. DOA Estimation with DNN Autoencoder
The DAE method uses parallel multilayer classifiers and performs as a spatial filter to divide the full input DOA range into multiple subregions, helping to reduce the computational burden required in the classifiers. There are two main parts in a DAE: the front-end is the multitasking AE behaving as a spatial filter, and then parallel multilayer classifiers are connected at the back-end to estimate the DOA of the incident signal. In [
9], the multitasking AE is designed to decompose the incident signal into
P spatial subregions, and when the input signal is located in the
pth subregion, the output of the
pth decoder is used as the input of the
pth multilayer classifier. If the input DOA does not belong to the
pth subregion, the
pth decoder output equals to
. The main advantage is that in a multitasking AE, each decoder output covers a narrower spatial subregions, making the incident signal distribution more concentrated. This allows subsequent parallel multilayer classifiers to learn the DOA features located in corresponding subregions, and therefore makes training easier.
3.1. Data Preprocessing for DAE
Consider that the signal received by the antenna array is contaminated by AWGN, where all noise
are not related to the source signal
. However, with the
M antennas and over a period of time for the received signal vector
, antenna’s imperfections can be found through the statistical characteristics related to each other. We collect the received signal of
N snapshots and calculate the CSM of the signals as [
30]
Reformulate all the elements of the matrix
as a vector
where
represents the
th element in matrix
,
and
take the values from the real part and the imaginary part, respectively, and finally we rearrange the vector
as the input for AE.
The data length for preprocessing of the AE can vary depending on the selected collection of
. All elements of the CSM can be used as the input vector, in which case
. In order to reduce the size of the input vector to the AE, only some elements in CSM can be taken as the input vector. For example, in [
22], the elements of the diagonal matrix are excluded to reduce the noise effect, and considering the conjugate symmetry of the CSM, the elements of the lower left triangular matrix are discarded. Only the elements of the upper right triangular matrix are selected as the input vector to the AE. In this case,
, while
. It is worth noting that
N should be large enough to reduce the influence of noise on off-diagonal upper right or lower left matrix elements in order to calculate the CSM for better results.
3.2. Encoding and Decoding for DAE
As depicted in
Figure 2, the encoder of AE compresses the dimension of the input vector for a lower one to extract the main components in the original input, and then goes through the decoding process to recover the original dimension, in which the input vector will be decoded and restored in the subregion to which it belongs. The encoding–decoding process is efficient to reduce the influence of noise and input perturbations.
First, assume that each of the encoder and decoder has
layers, and the vector
has the same dimension in the
th and the
th layers for
. Additionally, notice that the dimension of
is smaller than that of
. The adjacent layers of the AE are fully connected using a feedforward neural network structure, expressed as
where superscript
is associated with the
pth subregion, subscripts
and
denote the layer indices,
is the
th layer output of the
pth AE,
represents for the initial input vector of the AE,
is the weight matrix from the
th to the
th layer for the
pth subregion,
is the additive bias in the
layer, and
denotes the activation function in the
layer, which can be the Relu function, that is,
The multitasking AE intends to decompose the input into P spatial subregions. A simple partition method is to choose directions , satisfying and is the full spatial range covered by the incident signal. If a signal impinging from the pth subregion is used as the input to the AE, the pth decoder output equals to the input while other decoder outputs equal zero.
3.3. DAE Multilayer Classifiers
Each of the
P groups of parallel multilayer classifiers takes the output of its decoder as input, and then a set of fully connected multilayer neural networks are used to estimate the spatial spectrum for the corresponding subregions individually. The output of each AE
is only located in a smaller spatial range than the full range. Since the antenna array has a similar steering responding function in adjacent space, the output of the AE
is more centrally distributed than the original input signal
, and the adjacent layers of parallel multilayer classifiers are connected using feedforward neural networks as
where
is the output vector in the
th layer of the
pth classifier,
is the weight matrix between the
th and the
th layer of the
p subregion,
is the additive bias vector in the
th layer of the
pth subregion, and
is the activation function in the
th layer. Denote
as the output of the last layer. After obtaining all the outputs of the
P parallel classifiers, the
P outputs are combined in order as a vector
to estimate the spatial spectrum with the input
. To achieve DOA estimation based on the spectrum estimate, the nodes close to the true signal direction in the output
have positive values, while other node outputs equal zero.
4. Convolutional Autoencoder for DOA Estimation
The CAE structure integrates the advantages of convolutional neural networks (CNNs) and AE. Before elaborating the CAE method for DOA estimation, three points about CAE can be stated as follows.
Motivation. The main feature of CAE differing from DAE [
9] is to introduce convolutional kernels used in CNN to the AE structure. CNN is known for its excellent 2D image processing capabilities, which learns extracted features in a nonlinear manner based on convolutional and pooling layers in specific regions of the input feature maps, and is paired with a few fully connected layers for the output. CNN does not only reduce computational costs, but also improves feature extraction capabilities. The encoder part of AE learns the low-dimensional representation characteristics of the input data, called the code layer, and the decoder part reconstructs the code layer back to the original dimension. It is worth noting that under the structure of an AE, the input data are processed in a vector form, and the layers are fully connected. CAE consists of a convolutional encoder and the corresponding deconvolution decoder, which extracts feature maps from the input matrix in the encoder part while reconstructing information from feature maps in the decoder.
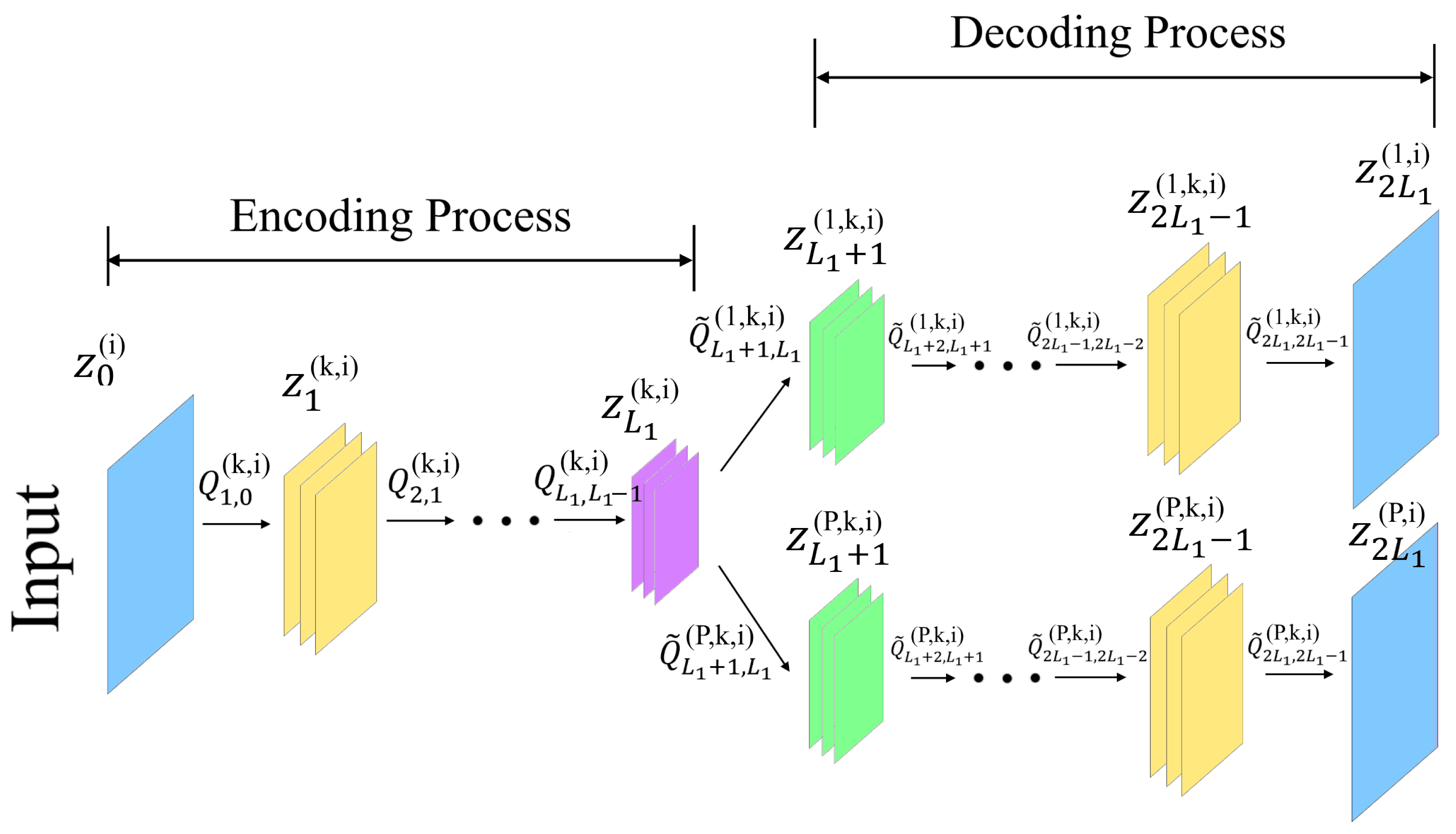
Structure. The proposed CAE structure is plotted in
Figure 3. Assume that the full DOA range is decomposed into
P subregions in the decoding process. In addition to data preprocessing, a CAE is divided into two parts: a multitasking AE for spatial filters, and a set of parallel multilayer classifiers for DOA estimation. For data preprocessing in CAE, the real and imaginary parts of the CSM are separated as two individual input channels. The multitasking AE is conceptually similar to that used in DAE. The inputs are first compressed through the encoding process, and then the feature maps are recovered through the decoding process. The training process learns from the difference between the output of the decoder and the original input to obtain the CAE parameters.
Innovation. The CAE adds each node of the AE to a kernel to perform convolutional operation. The main purpose of the convolutional operation is to capture features, where some regional features of the input channel are selected by the kernel to produce all feature maps. Hence, CAE can capture features in a more efficient manner than DAE and reduce the number of parameters that are required to be trained in the neural networks.
4.1. Data Preprocessing for CAE
Imagine that when CAE is applied to image processing, a color image is used as a matrix input such as a size of
color image containing three channels, R, G, and B, regarded as matrices of
. Here we take a similar approach, decomposing the real and imaginary parts of the CSM in (
11) as the input matrices of two independent channels
where
and
represent the two channel input matrices to CAE.
4.2. Encoding and Decoding for CAE
The structure of CAE is intuitively similar to that of AE, except for the convolutional operation. Assuming that each layer operates the convolution with
K kernels,
K feature maps can be produced correspondingly. The representation of the
kth feature map during encoding is
where
is the output of the convolutional operation with the
kth kernel in the
th layer,
is the
kth kernel for convolutional operation between the
th and the
th layers,
is the bias in the
th layer, and
is the nonlinear activation function in the
th layer. Here,
represents the initial input of the
ith channel. Assuming that the original CSM size is
and the kernel size is
, the size of the produced feature map is reduced to
if not supplementing the boundary of the CSM with zeros.
The decoding process can be written as
where
is associated with the
pth subregion. (
21) represents the full convolution operation of the feature map
with the kernel
. Supplementing the boundary of the feature map with zeros first, the matrix size after convolution operation becomes
. In the last layer
of the decoding process, the
K feature maps need to be added to restore the dimension of the input CSM as follows:
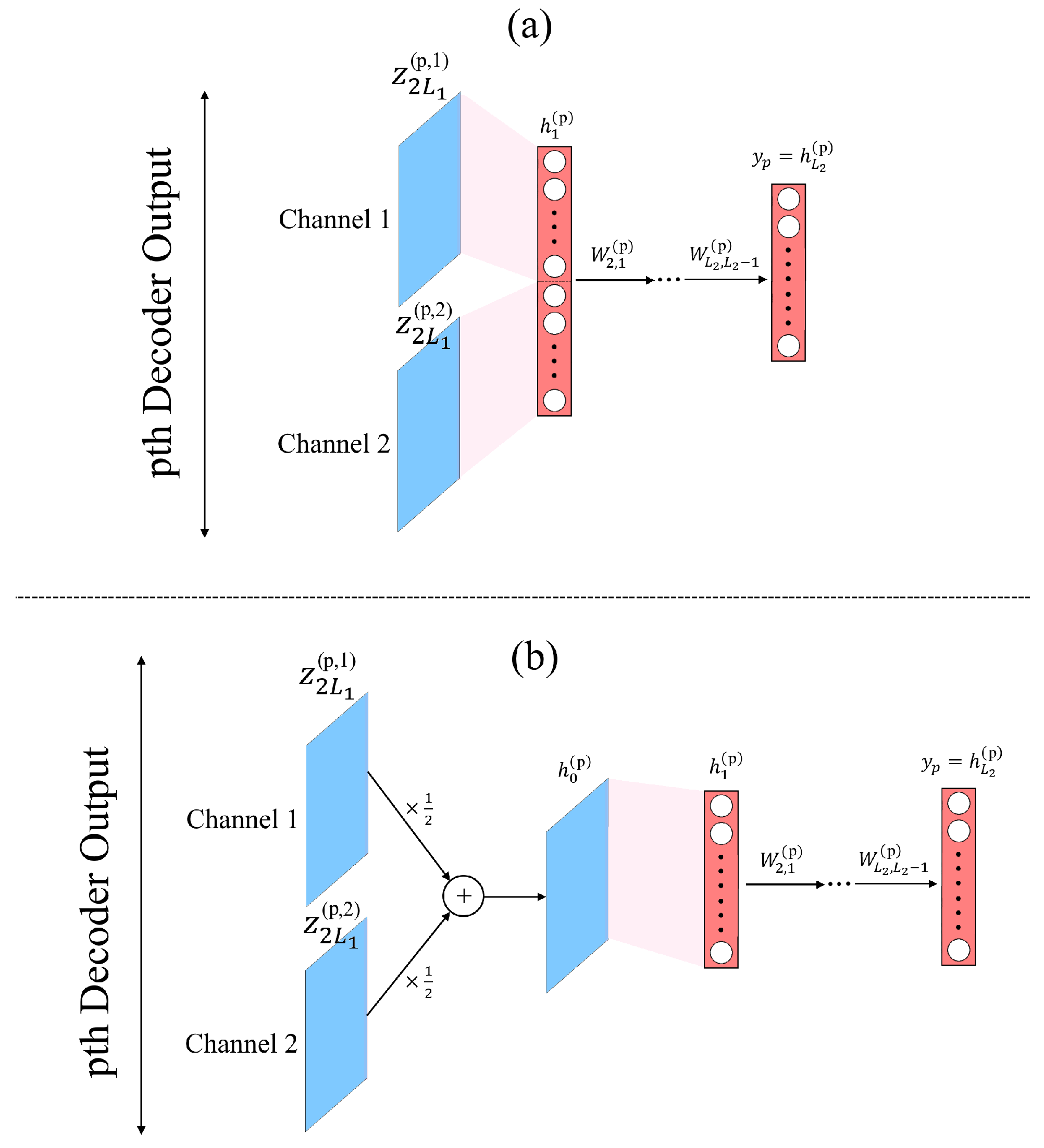
4.3. CAE Multilayer Classifiers
The outputs of the
P spatial subregions of the decoder are used as the inputs of the
P groups of the parallel multilayer classifiers, and the layers of two channels for each group of classifiers are connected by a fully connected layer neural network. The spatial spectrum of the corresponding subregion is estimated after
layers. Finally, the outputs of the
P groups of parallel classifiers are combined into
as written in (
17) to determine the direction of the incident signal.
As plotted in
Figure 4, the parallel multilayer classifiers in CAE can have two different structures: the first is to directly process the data of the two channels, and the second is to merge the separate channels into one input vector for the classifier, with which the entire feature map has a smaller dimension than the first structure, described as follows:
where
and
denote the two channel outputs associated with the
pth convolutional kernel and
is the input of the
pth classifier.
6. Conclusions
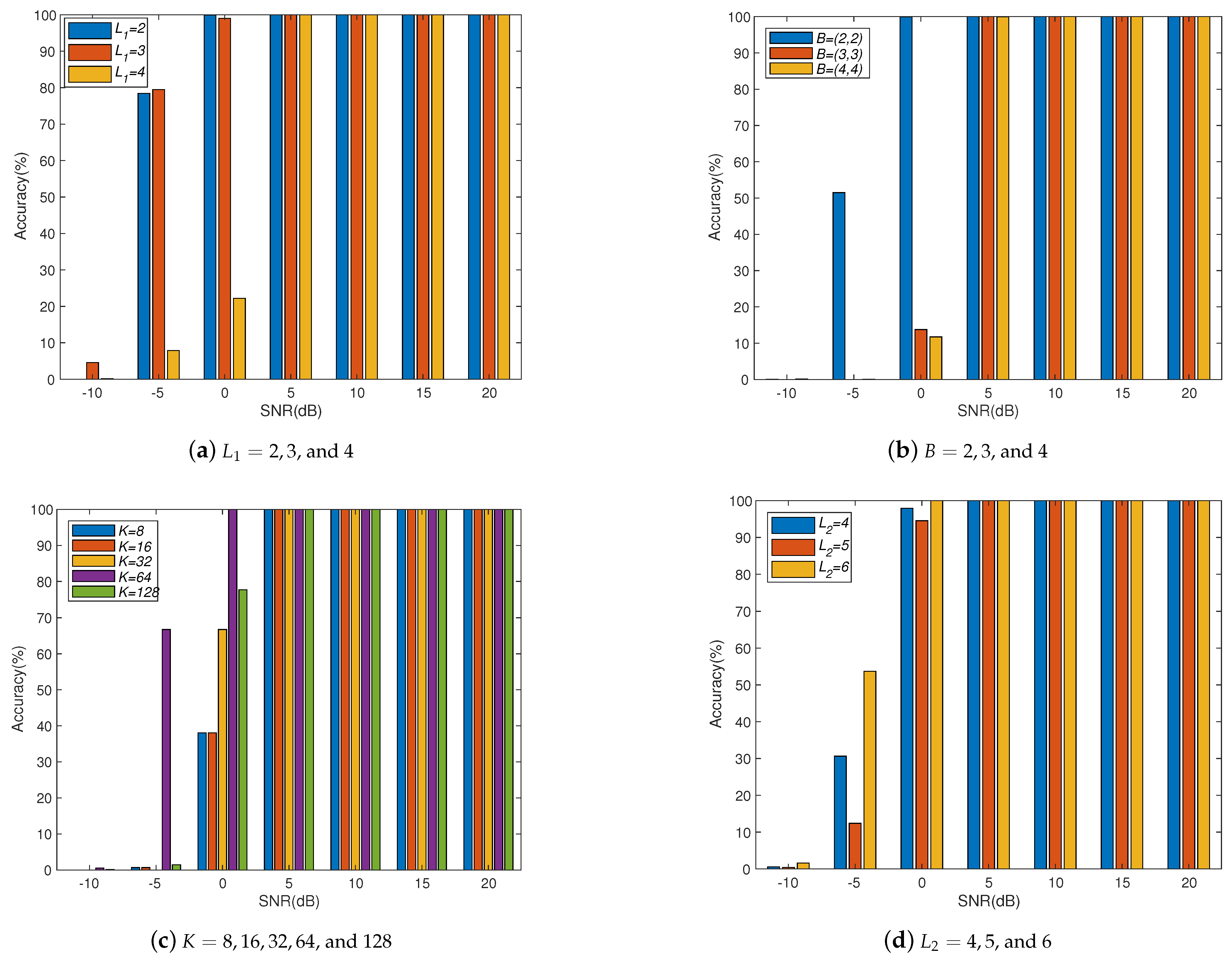
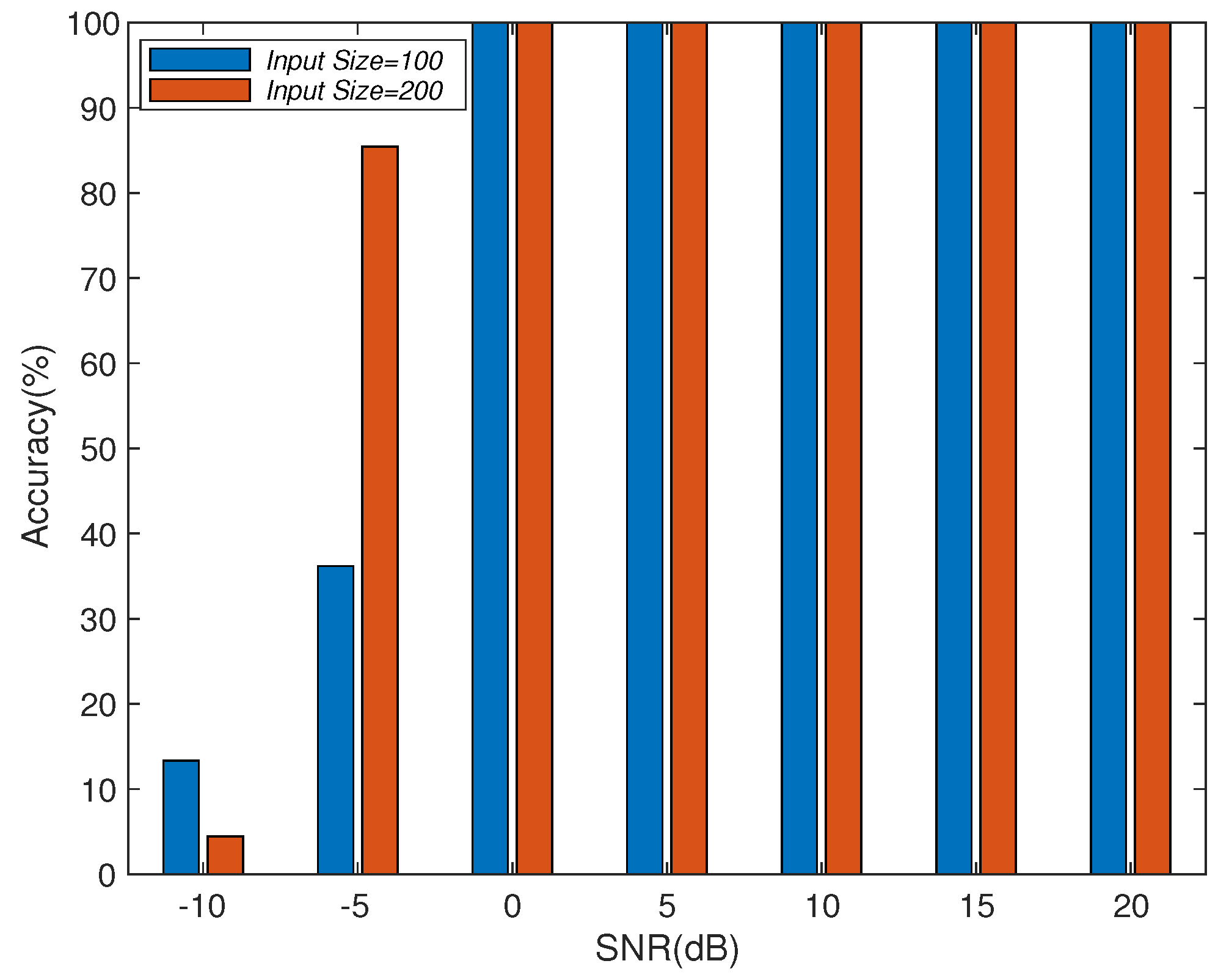
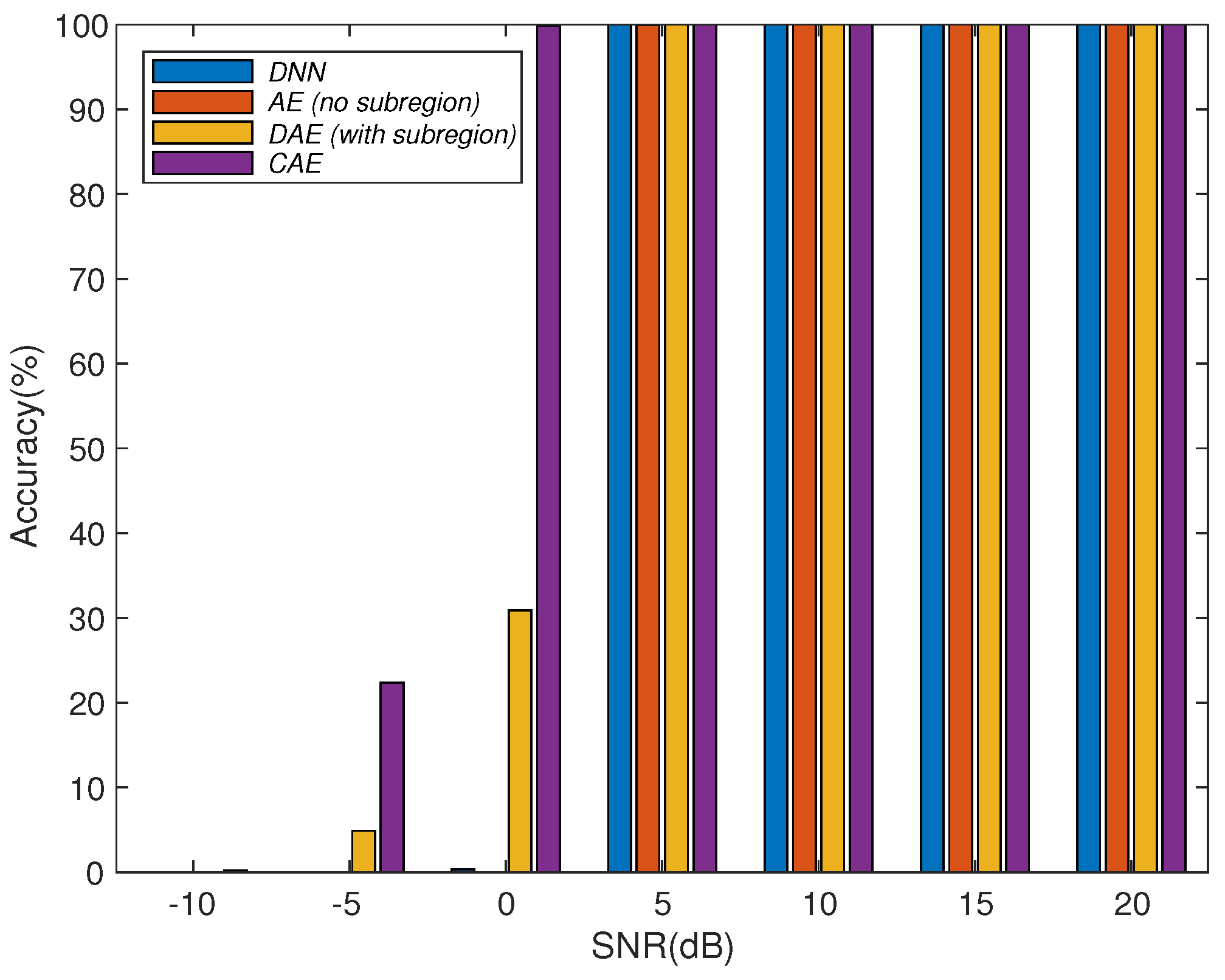
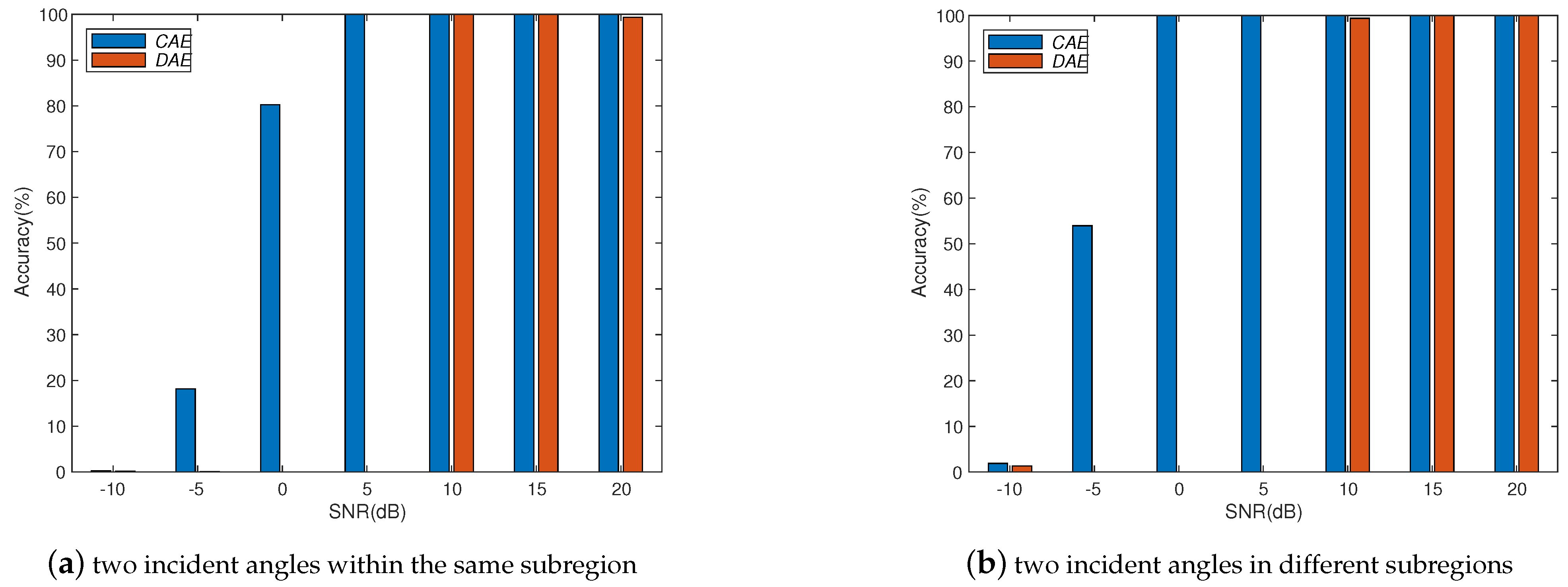
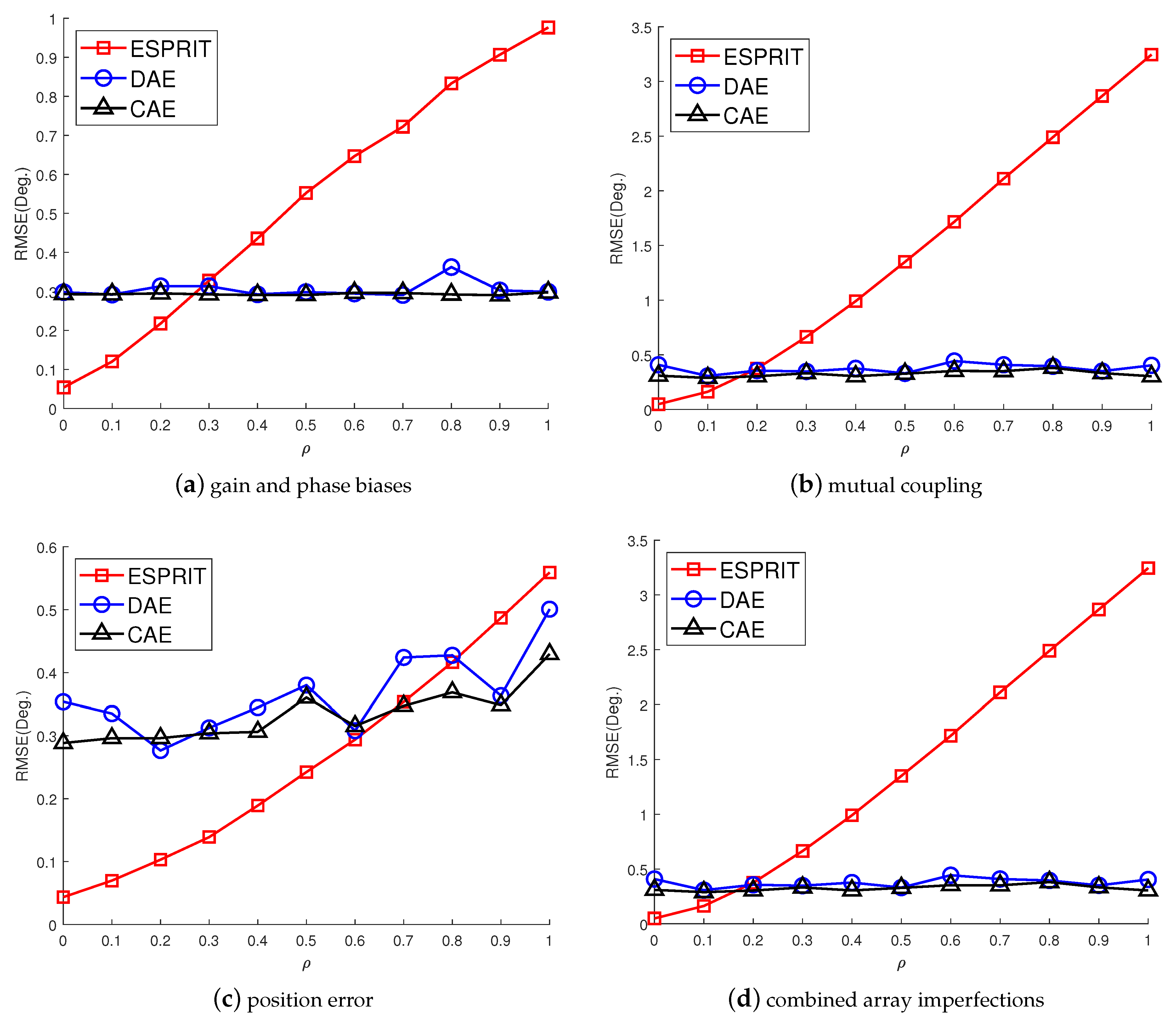
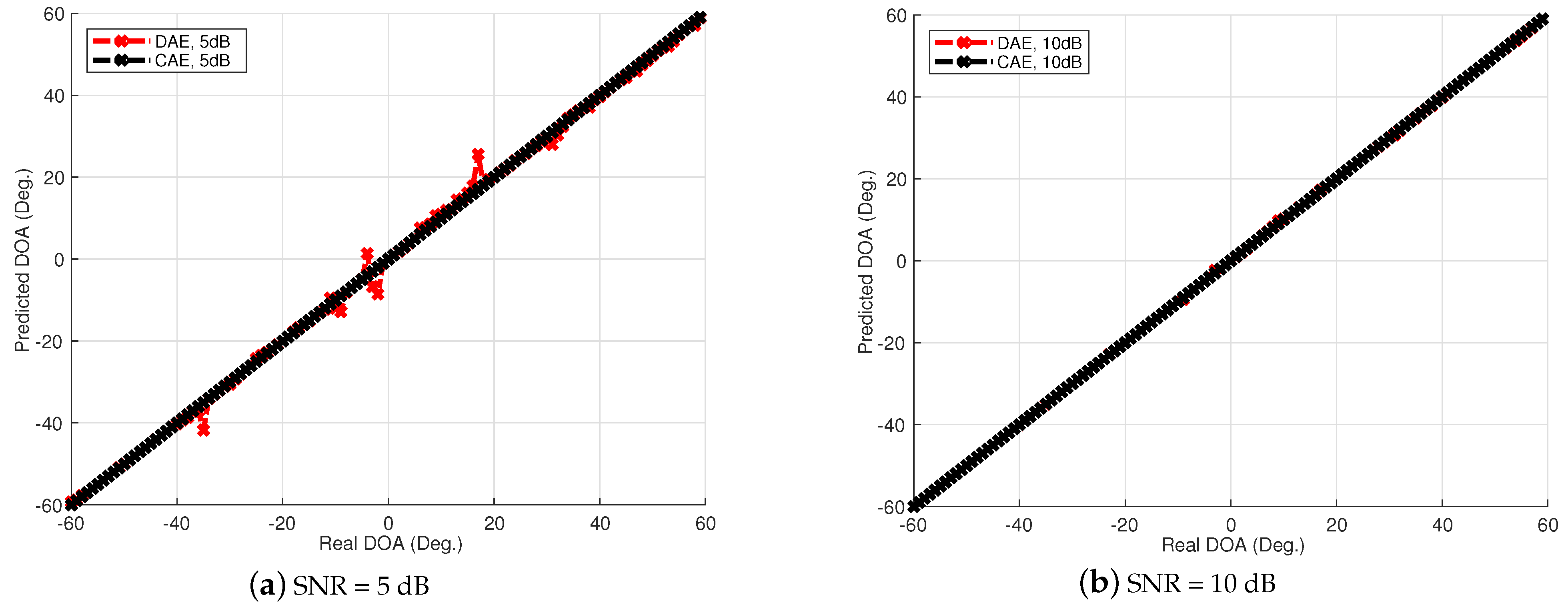
We study a CAE structure to deal with array imperfections for obtaining robust DOA estimation, which combines the advantages of convolutional operations to learn local spatial features and the use of spatial filters to concentrate the training information. Through numerical experiments, we study different system parameters to improve system accuracy with the proposed CAE. In the case of increasing the number of layers in CAE, the overall accuracy will not be improved due to the overfitting effect. Therefore, the CAE parameters need to be properly determined to obtain better accuracy with reasonable training load according to the applications. In addition, we also show the performance of the proposed CAE method with multiple signal sources. When multiple signal sources occur in different subregions, the performance of the proposed CAE is still similar to that of a single source. After evaluating the noise immunity performance of the DNN, DAE, and CAE methods, we find out that CAE has better noise immunity than others. Although deep learning methods for DOA estimation are inferior to subspace-based methods, such as MUSIC and ESPRIT, without array imperfections, the performance is worse due to the resolution limitation of the finite output grids of the multilayer classifiers. The proposed CAE method demonstrates a robust performance in solving complex array imperfection problems.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}