1. Introduction
With the advent of the age of massive industrial data, in order to guarantee the highly dependable operation of industrial manufacturing equipment, the remaining life prediction of important parts has received extensive attention from scholars. In the context of tool condition monitoring for metal-cutting operations, the most challenging job is the surveillance of tool wear [
1]. Accurately estimating the wear phenomenon of the tool is of great significance in improving production efficiency and reducing processing costs. Therefore, this paper takes the tool wear problem as an example to explore the life prediction problem of mechanical parts.
In recent years, Back Propagation (BP) neural networks, Convolutional Neural Networks (CNN) [
2,
3], Recurrent Neural Networks (RNN) [
4,
5], and other deep learning models [
6] have been widely adopted due to their ability to handle data nonlinearly. Many neural network-based models have been presented for various aspects of tool wear prediction. Yu et al. [
7] presented a method for tool wear monitoring using a weighted Hidden Markov Model with the signals provided by tool condition monitoring techniques. Lin et al. [
8] proposed a hidden semi-Markov model for real-time tool wear prediction based on learning for tool wear detection and remaining life prediction. Duan et al. [
9] used a parallel deep learning model based on a hybrid attention mechanism to learn sensitive features individually or sequentially from many samples for tool state monitoring. To forecast tool wear, He et al. [
10] presented a superimposed sparse autoencoder model based on the BP of the raw temperature signal. F. J. Alonso et al. [
11] used feedforward BP neural network technology to predict tool flank wear, but the accuracy of the prediction effect was not high.
To further improve the accuracy of the model prediction, further optimization is required. Metaheuristic algorithms are widely popular optimization algorithms. Metaheuristic methods are divided into nine different groups: biology-based, physics-based, social-based, music-based, chemical-based, sport-based, mathematics-based, swarm-based, and hybrid methods which are combinations of these [
12]. Metaheuristic algorithms can be used to solve high-dimensional complex engineering structure optimization design problems with nonlinear constraints. Deng et al. [
13] proposed an improved quantum-inspired differential evolution (MSIQDE) algorithm and combined it with a deep belief network (DBN) to propose a fault classification method with a better classification accuracy. Using the elastic net wide learning system (ENBLS) and the grey wolf optimization (GWO) algorithm, Zhao et al. [
14] established a unique technique for predicting bearing performance trends. Their method was based on the combination of these two algorithms. The proposed method combined the ENBLS and GWO algorithms to achieve better results. Zhao et al. [
15] proposed a novel vibration amplitude spectrum imaging feature extraction method. They compared it with other methods, and the experiment showed that the presented method achieved significant improvements. Huang et al. [
16] developed a novel three-phase coevolutionary method to enhance the convergence and searchability of competitive swarm optimizers by combining a novel multi-phase coevolutionary technique. They used it to solve large-scale optimization problems, and the experiments showed that the proposed method obtained better results.
Salp swarm algorithm (SSA) [
17] is a swarm-based metaheuristic algorithm that Mirjalili and other scholars in 2017 proposed. Due to its simple and easy framework, few parameters, and good optimization performance compared to other algorithms, it has been widely used in feature selection [
18], image processing [
19,
20,
21], engineering optimization [
22,
23,
24], and training neural networks in recent years. It is mostly used to identify various ideal decisions or values to provide a candidate solution that solves the issue [
25]. However, many metaheuristic algorithms have shortcomings when faced with multi-dimensional problems, such as slow convergence speed and poor optimization accuracy. Many scholars have made many bold attempts to improve the algorithm. D. Bairathi et al. [
26] used the multi-leader SSA to train a feedforward neural network. It analyzed 13 different data sets, proving the ability of the model to gravitate to the optimal value. S. Kassaymeh et al. [
27] combined the SSA with the simulated annealing algorithm to optimize hyperparameters of the BP neural network, reduce the model prediction error, and improve the prediction accuracy. J. S. Pan et al. [
28] proposed an adaptive multi-group SSA with three new communication strategies, combined it with wind power prediction based on BP, and achieved a nice wind power prediction effect. S. Kassaymeh et al. [
29] combined the SSA algorithm with an artificial neural network to optimize network parameters to solve the prediction problem of software testing team size, and evaluated two datasets, showing that the improved method was superior to other methods. M. Zivkovic et al. [
30] presented an improved SSA, which firstly combined the exploration and replacement mechanism into the SSA and combined it with another meta-heuristic algorithm. Through the CEC2013 benchmark test, it was verified that the improved algorithm outperformed other more competitive metaheuristic algorithms. Zhang et al. [
31] obtained an improved spiral chaotic salp group algorithm by introducing the logarithmic spiral mechanism and combining the chaos search method, which made the development and search capabilities of the algorithm more balanced and further improved the performance of the algorithm. M. H. Qais et al. [
32] improved the crucial parameters in the leader’s position update and added random parameters to the follower’s position update mechanism to facilitate the algorithm to obtain the global optimum. Fan et al. [
33] used Gaussian perturbation to increase the diversity, introduced polynomial mutation to update the leader position, and used the Laplacian crossover operator and mixed opposition learning method to boost algorithm convergence and exploratory power.
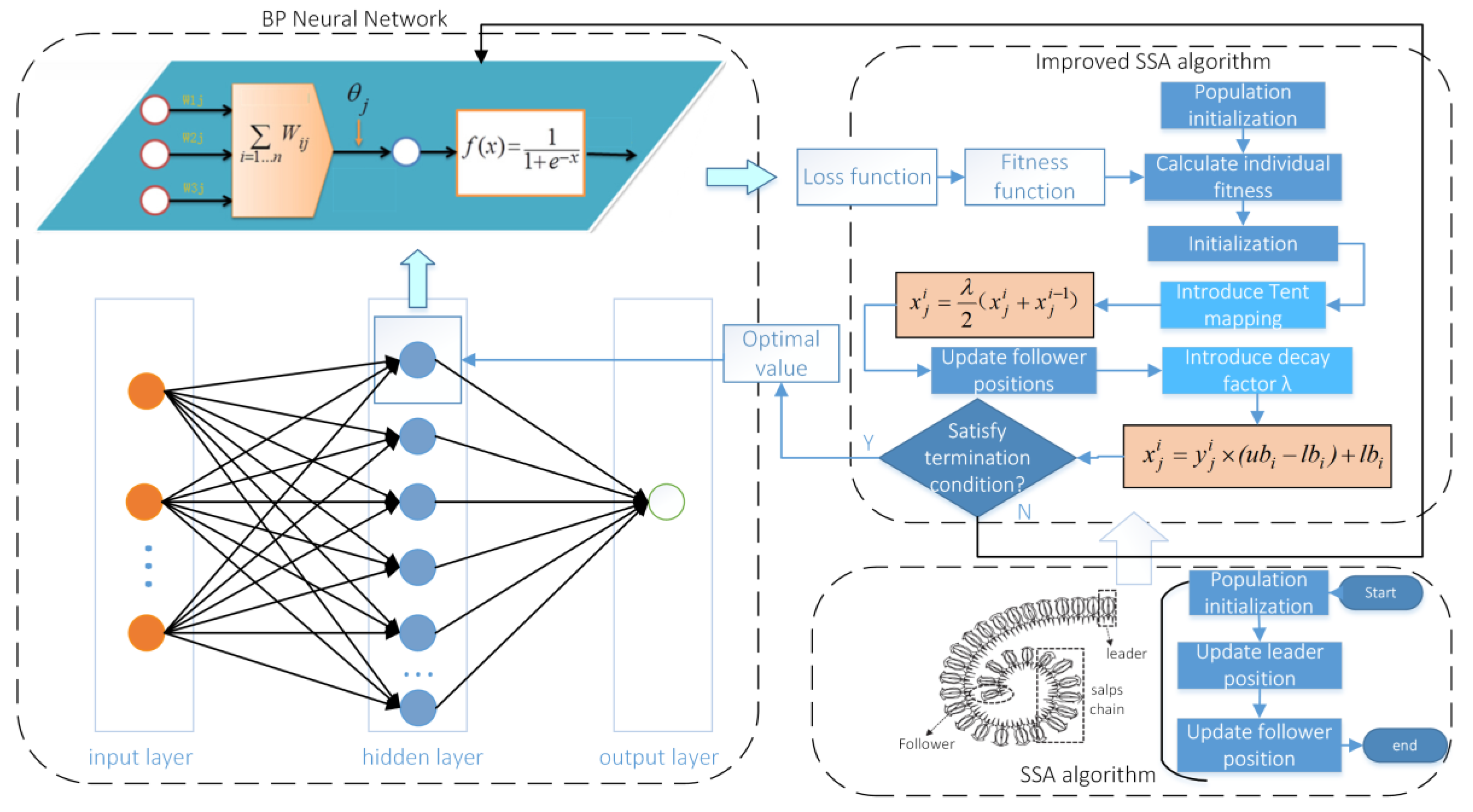
Thus, due to the defects of the salp swarm algorithm such as slow convergence speed and ability to easily fall into local minimum, a new salp swarm algorithm combining chaotic mapping and decay factor is proposed. Considering that the solution accuracy of the neural network is greatly influenced by the relevant initial parameters, the new SSA optimized BP neural network is used to further improve the prediction performance and achieve effective prediction of tool wear. Firstly, the chaotic mapping is used to enhance the formation, which facilitates the iterative search and reduces the trapping in the local optimum; secondly, the decay factor is introduced to improve the update of the followers so that the followers can be updated adaptively with the iterations, and the theoretical analysis and validation of the improved SSA are carried out using benchmark test functions. Finally, the improved SSA with a strong optimization capability is used to solve BP neural networks for optimal values of the hyperparameters. The validity of this is verified by using the actual tool wear data set.
The following are all this paper’s key contributions:
A new salp swarm algorithm for chaotic mapping and decay factor is presented;
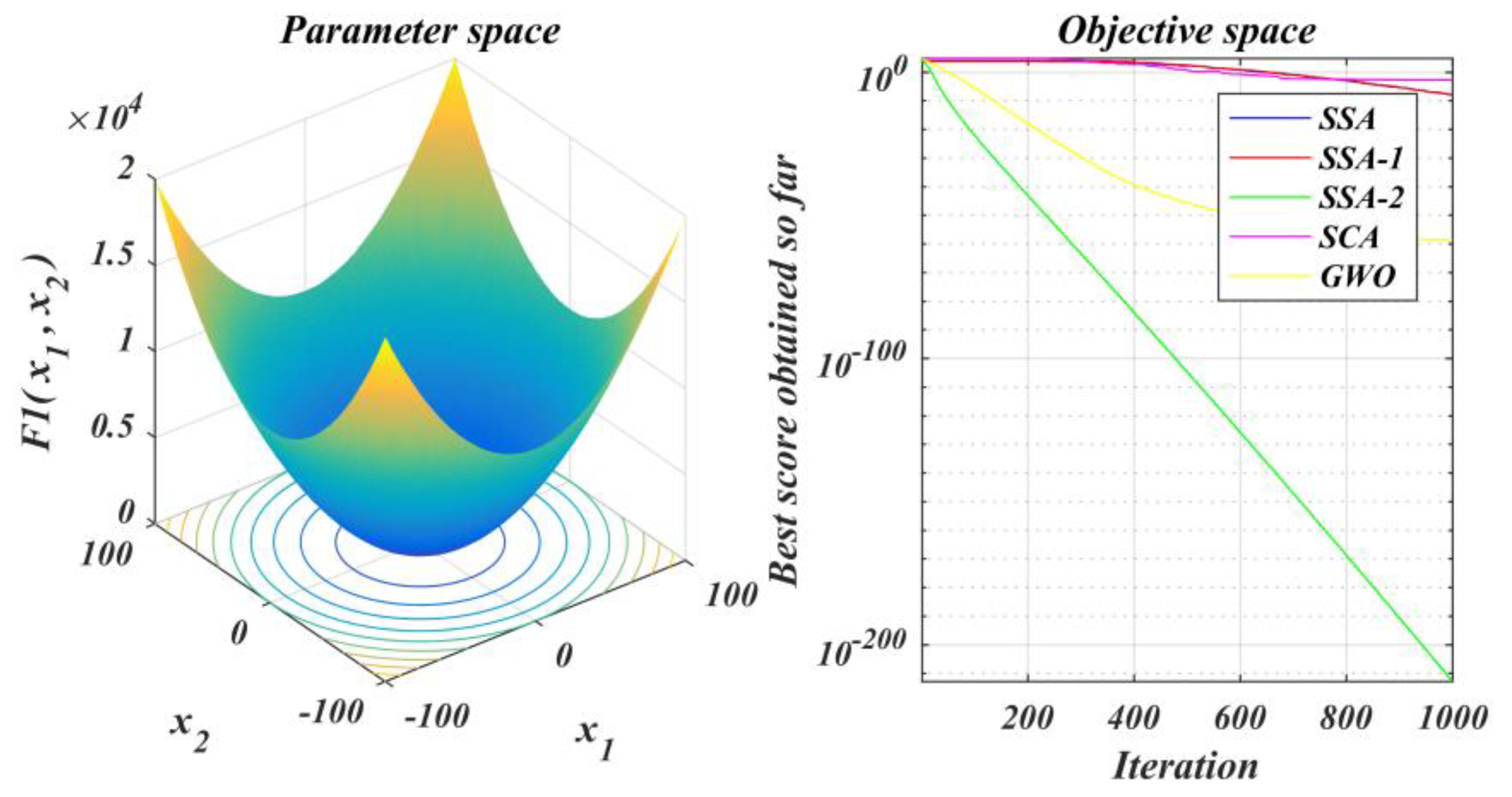
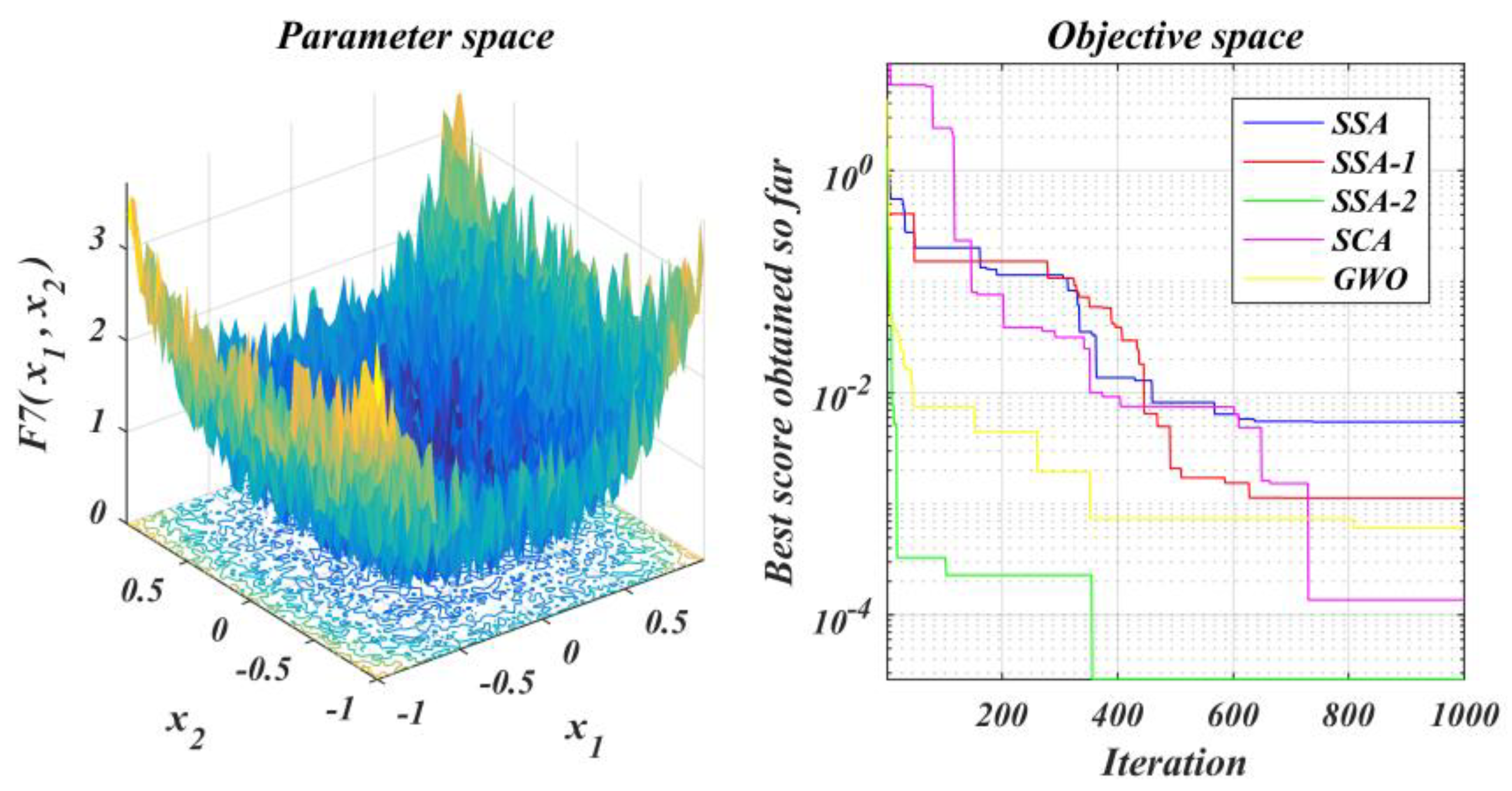
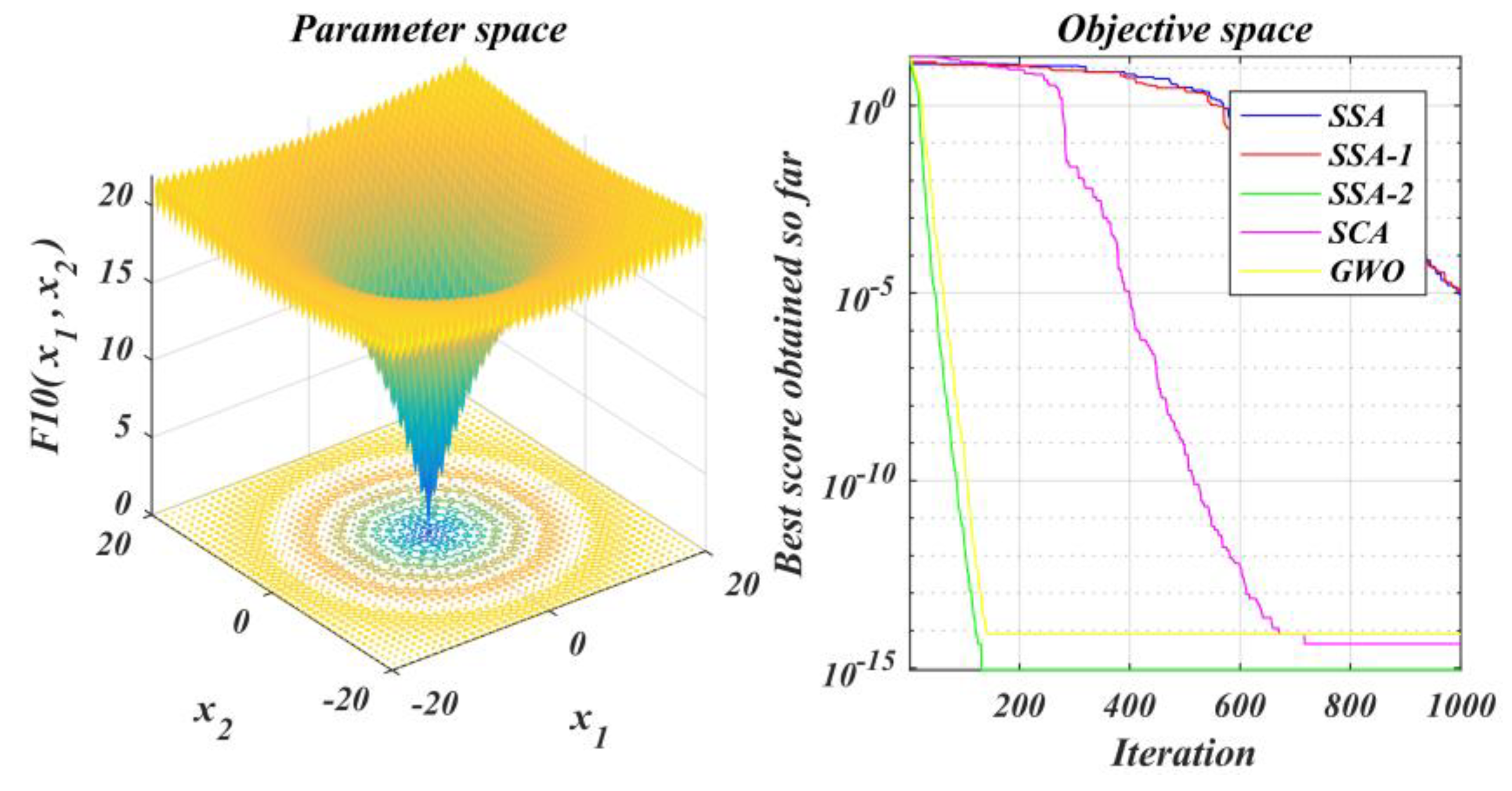
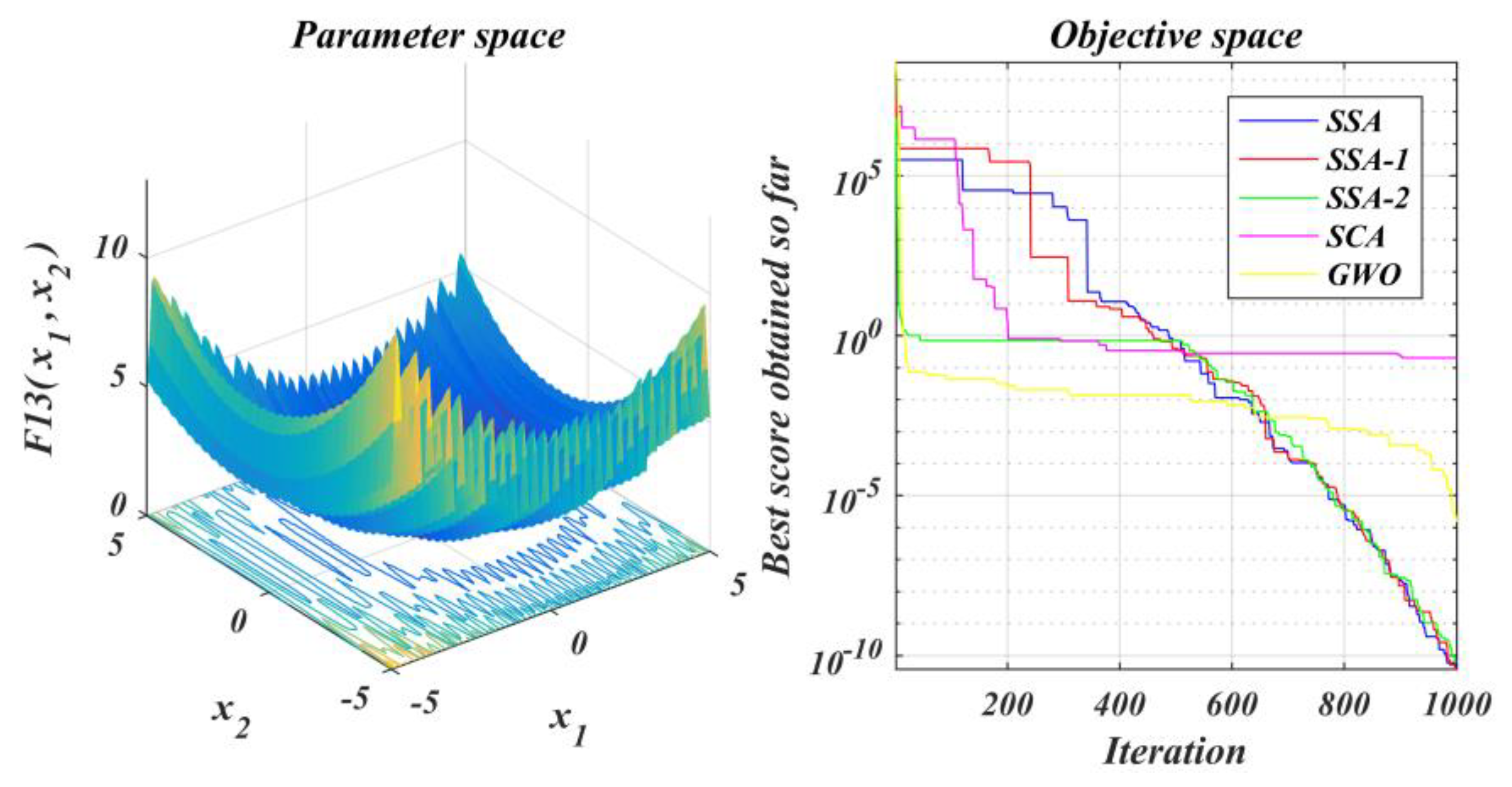
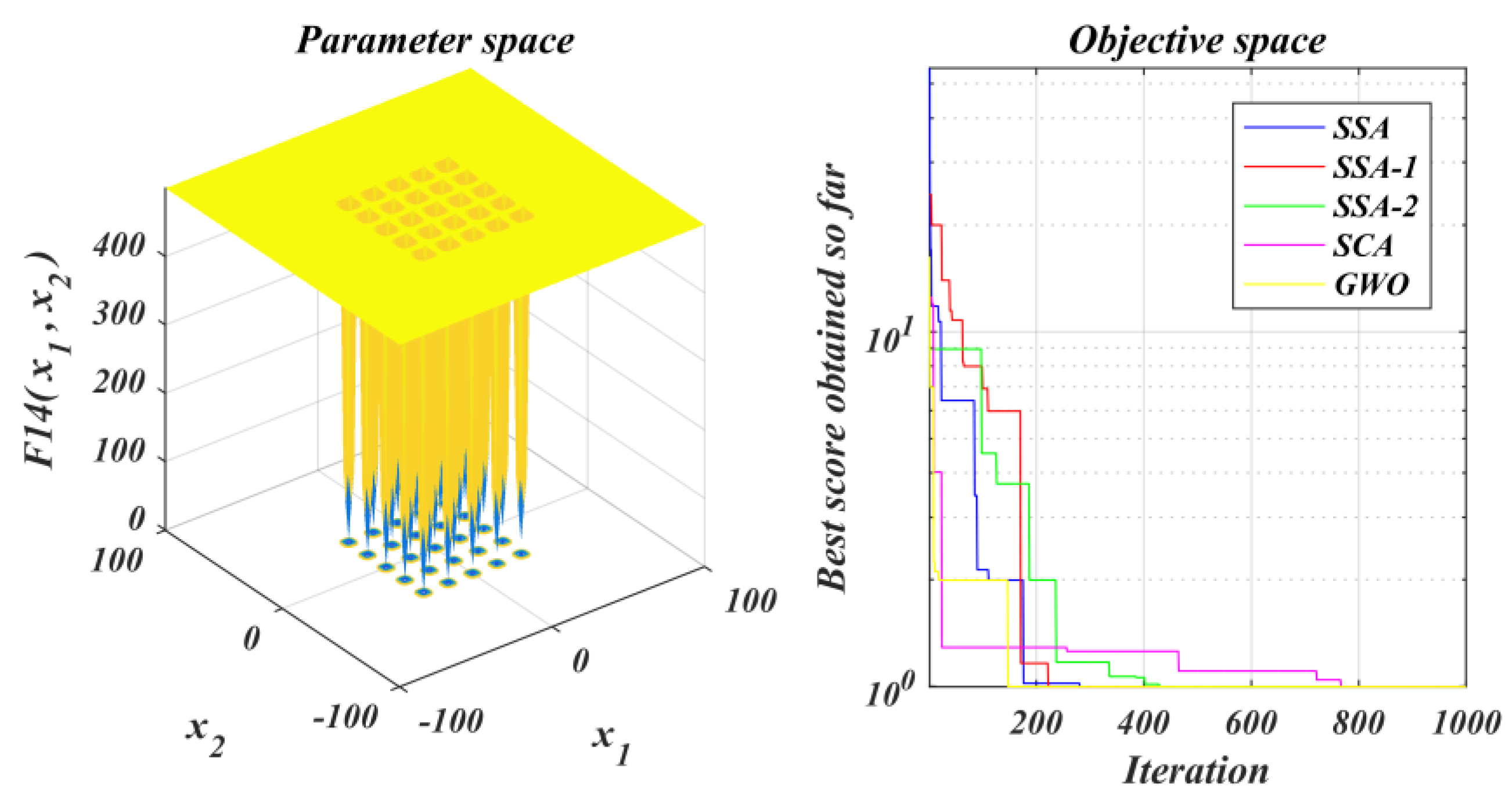
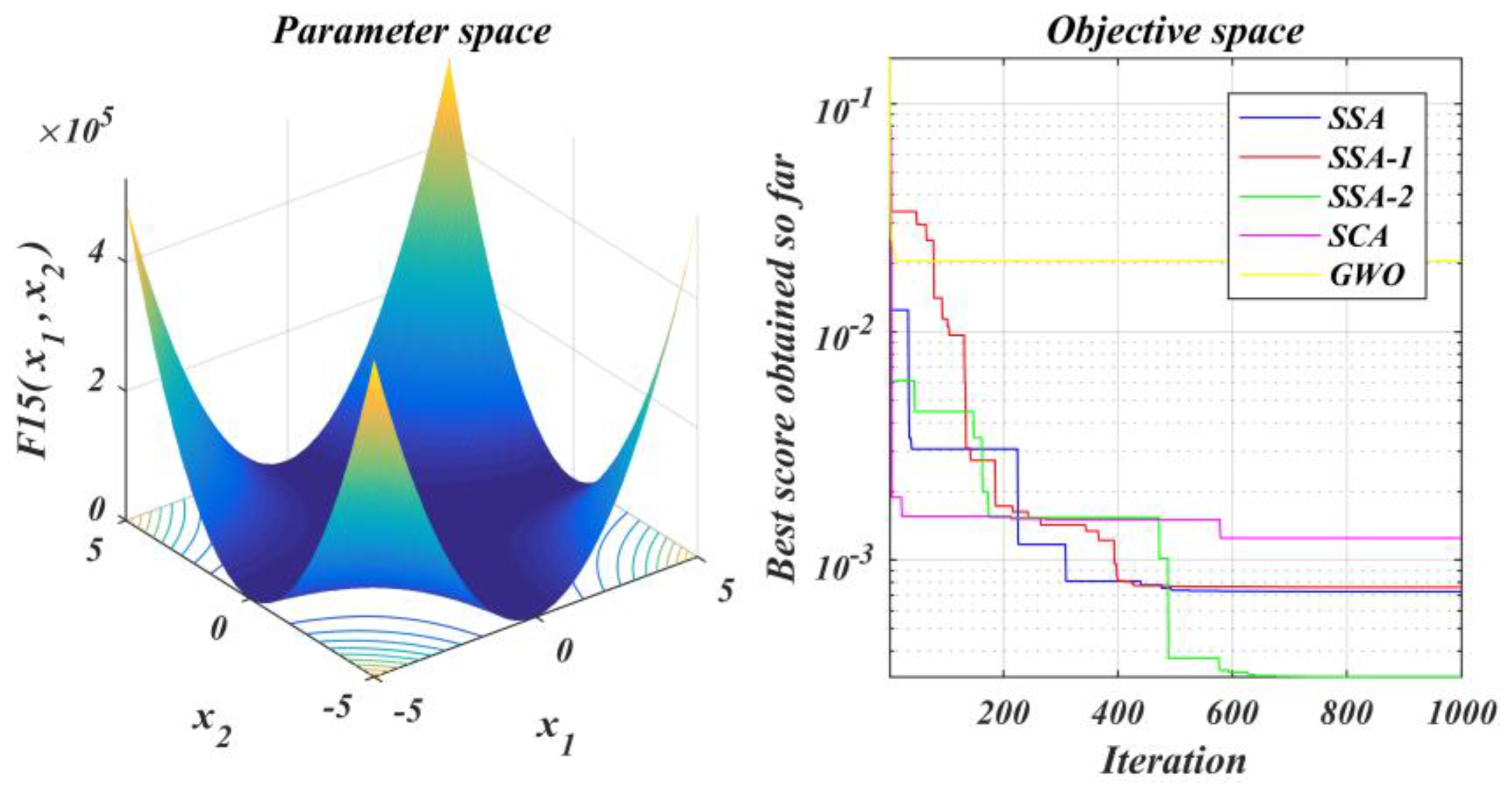
The performance of the improved algorithm is tested under the test function set and contrasted with that of the original SSA and other methods;
Introduction of improved salp swarm algorithm to optimize the neural network parameters and improve the predictive power of the prediction model;
The actual tool wear data set is selected to verify its effectiveness.
In this paper,
Section 2 briefly reviews the SSA algorithm and the BP neural network and its optimization.
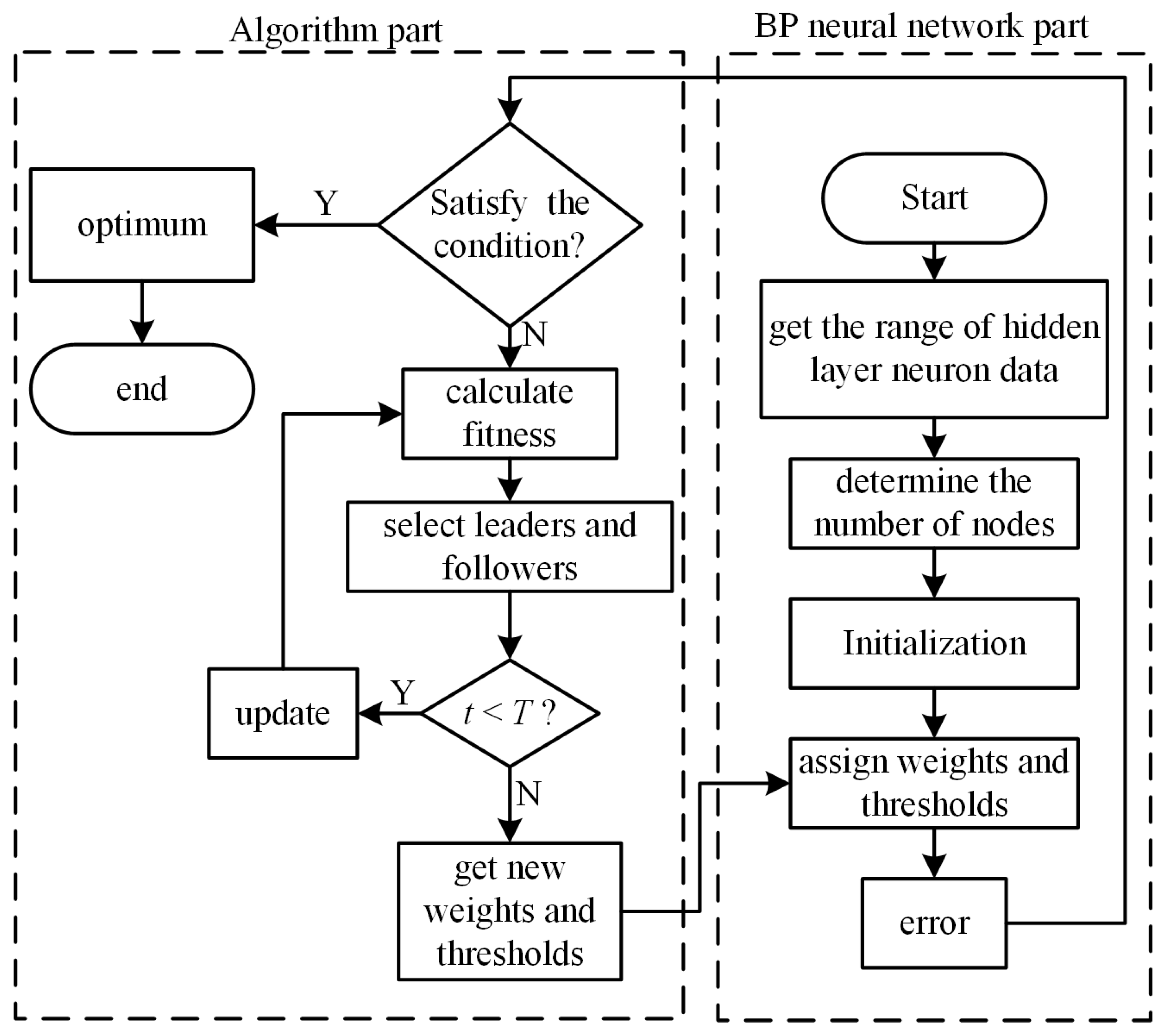
Section 3 proposes a new SSA algorithm, combines the proposed SSA2 algorithm with BP neural network to obtain the SSA2-BP prediction model, and conducts a performance comparison analysis between the improved algorithm and the original algorithm.
Section 4 applies the proposed SSA2-BP algorithm to tool wear prediction, and the model prediction performance is verified by experimental comparison.
Section 5 reviews the whole paper and gives recommendations for further research.
4. Tool Wear Prediction Application
The metaheuristic algorithm is capable of solving global solutions in a multidimensional search space and is widely used in the training of neural networks. Therefore, we optimized the network using the proposed improved SSA algorithm to accomplish tool wear prediction.
The 2010 American PHM Association public tool wear data set was selected, and the c1, c4, and c6 data were combined with a sample size of 945. The data contained eight items (x, y, and z-axis cutting forces, acoustic emission signals, x, y, and z-axis vibration, and tool wear). The data were divided using the hold-out method, with 80% used for training and 20% for testing.
4.1. Data Preprocessing
The original data’s cutting force, vibration, and acoustic emission signal were periodic high-frequency signals. The actual data were processed using the time-domain-frequency-domain feature extraction method. The root means square values of the time domain features of the cutting force and vibration signals,
Xrms, were selected. The Fourier transform was used to convert the acoustic emission signals into frequency domain signals, which were normalized and then used as feature inputs. The formula for the root-mean-square values of the time-domain features is shown in Equation (13).
N symbolizes the total number of signals, whereas
Xi represents signal points. The acoustic emission signal data points were divided into odd and even groups, and Fourier transforms using Equations (14) and (15) were selected as inputs, respectively, with the following expressions.
where
is the rotation factor, which is obtained from the following equation.
4.2. Model Network Structure Design
This paper used a multi-input single-output BP network containing one hidden layer to build a prediction model. The indicators of each data set were taken as the input, and the tool wear was taken as the output. The model had seven input nodes and one output node. The hidden layer’s neuron depends on the actual problem’s sophistication and anticipated error threshold. During network design, the hidden layer neuron count must be determined. In this study, the empirical formula determined the hidden layer’s neuron range, and then experience and various tests decided its neuron count. The empirical formula is given in Equation (17).
where
a and
b represent the neuron numbers of input and output layers, respectively, and
i is a positive integer from 1 to 10.
An experimental comparison determined the ideal number of hidden-layer nodes in the range of hidden-layer neurons, as shown in the
Table 6 below, where Num is the number of hidden-layer’s neurons and Error means the training set mean squared error.
Therefore, twelve neurons were selected for the hidden layer in this experiment.
4.3. Selection of the Excitation Function and Fitness Function
The network usually adopts Sigmoid differentiable function and linear function as the excitation function, and the S-type tangent function was selected as the excitation function in this paper. The formula is given in Equation (18).
The fitness function, also known as the objective function, was set to the mean square error of the predicted and true values of the training data in the model training. The formula is as follows.
y denotes the true value and
denotes the predicted value.
Considering the decision variables as the weights and thresholds of the neural network, the range of taken values was restricted to [−1.5,1.5], which was the constraint. When the taken value exceeded the bound, the corresponding boundary value was taken instead of the value.
4.4. Model Evaluation Indicators
For model quality, the following three commonly used parameters were applied for assessment, including MAE, MSE, RMSE, and
R2 (coefficient of determination) with the following equations.
where
is the true value,
indicates the predicted value. The smaller the error, the more accurate the model prediction. The
R2 measured how well the predicted value fits the true value, and the value ranged from 0 to 1. The closer
R2 is to 1, the better the model’s prediction.
4.5. Experimental Results
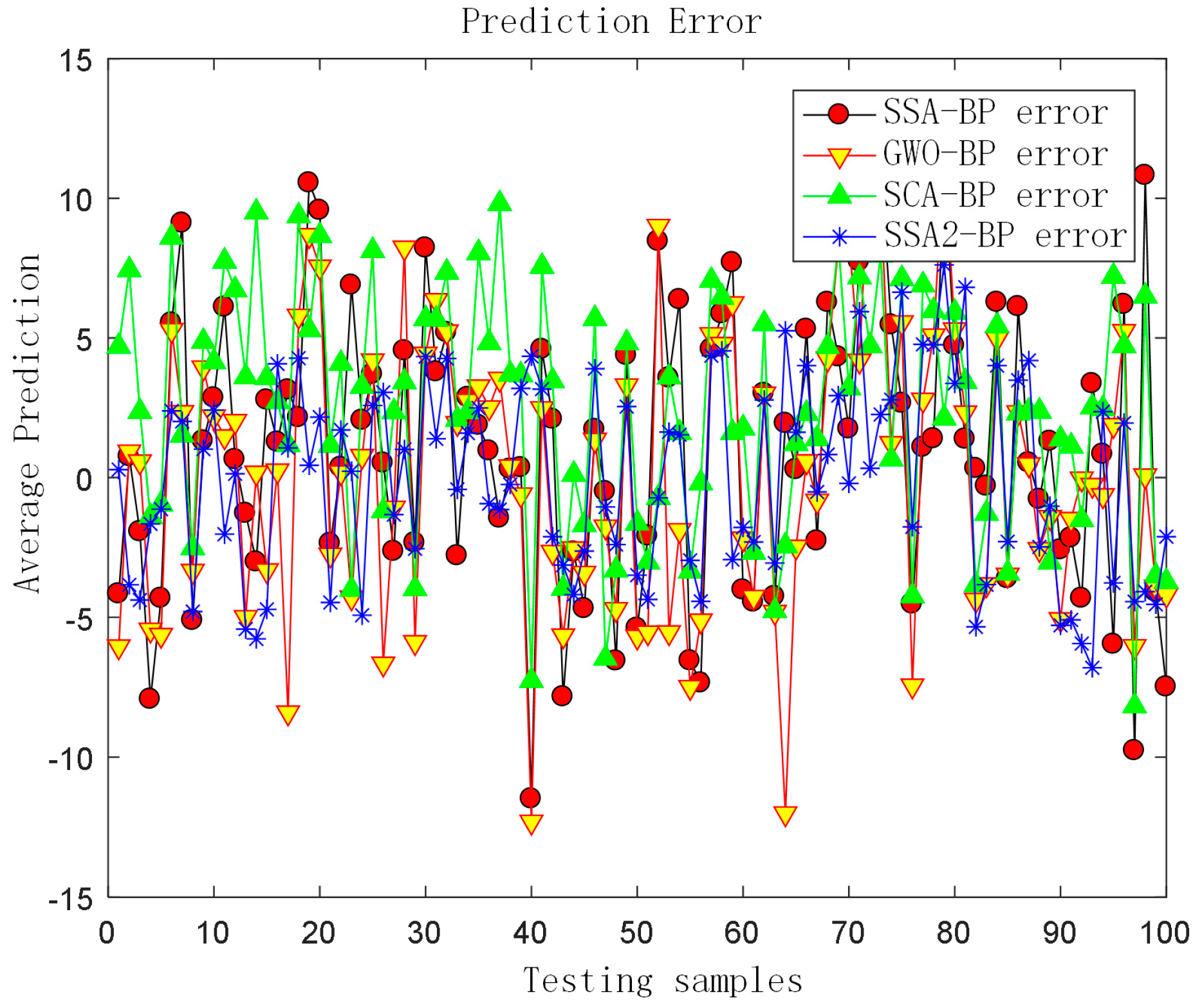
The combination algorithm of SCA and BP (SCA-BP), the combination algorithm of GWO and BP (GWO-BP), the SSA-BP algorithm, and the SSA2-BP algorithm were compared and analyzed. Some sample data were selected and the predictions of the four prediction models’ Values, the true value comparison chart (
Figure 9), and the prediction error chart were drawn (
Figure 10).
The prediction error values of the algorithm-optimized prediction model were recorded, and to avoid chance, they were run several times and averaged. The results are shown in
Table 7.
From the above graphs, it can be seen that the SSA2-BP prediction model had higher R2 values and smaller prediction error values compared to the other algorithms in the graphs. Compared with the original algorithm model SSA-BP, the R2 value of the SSA2-BP model improved from 0.962 to 0.989, and the MSE value was reduced from 34.4 to 9.36, which is a 72% improvement compared to the original algorithm. This was due to the addition of chaotic mapping and decay factor to the algorithm, which gave SSA2 better solution accuracy compared with other algorithms, which made the SSA2-BP model have a better prediction ability and further proved the algorithm enhancement technique is feasible and successful.
5. Conclusions
This research provided a tool wear life prediction approach using chaotic mapping salp swarm. To address the model’s shortcomings, firstly, chaotic mapping and decay factor were introduced to improve the salp swarm algorithm, improve the BP network’s convergence speed and other flaws using the updated algorithm., and then improve the prediction ability of the prediction model.
The experimental findings revealed that the improved algorithm SSA2 had a higher solution accuracy and could leave the local optimum several times and converge rapidly compared with other metaheuristic algorithms. In addition, in applying tool wear prediction, the SSA2-BP model achieved higher R2 values and smaller prediction error values. Compared with the original algorithm model SSA-BP, the R2 value of the SSA2-BP model improved from 0.962 to 0.989, and the MSE value was reduced from 34.4 to 9.36, which is a 72% improvement compared with the original algorithm. In other words, the improved algorithm proposed in this paper had a better solution accuracy than other algorithms.
However, the improved algorithm still has shortcomings. The effectiveness of SSA2 may decrease significantly with the increase in variables due to the fast convergence rate and stimulation of development toward local optimal solutions when solving difficult optimization problems with many alternatives and local solutions. Meanwhile, the neural network model is greatly affected by the amount of training data and other parameters, and further research on the robustness of the algorithm and the accuracy and generalization of the model is needed in subsequent studies to further improve the model prediction accuracy.
In addition, some novel metaheuristic algorithms can also be used to solve the prediction problem of deep learning models, and in the next work, combining these new algorithms and extending this type of optimization problem need to be considered. Meanwhile, some representative new multi-objective optimization algorithms can be used to solve complex multi-objective optimization problems, and research related to multi-objective optimization algorithms is also necessary in the next work.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}