

An Attention-Based Uncertainty Revising Network with Multi-Loss for Environmental Microorganism Segmentation



Abstract
:1. Introduction
- (1)
- A new network structure based on an encoder–decoder architecture is proposed. The network integrates two-stage processing, uncertainty feedback, attention, and a mid-pred module, thereby enhancing the segmentation accuracy.
- (2)
- We created a new attention module that can effectively determine the position of EMs and capture weights from the previous encoder with an accurate perception of marginal areas.
- (3)
- The proposed network is integrated with the mid-pred module, which can guide the model in determining the position of the foreground area and avoid false predictions in large, confusing areas.
- (4)
- A new loss function was designed with mixed nominals to accelerate training.
2. Related Work
2.1. Review of Semantic Segmentation Methods in the Field of Computer Vision
2.2. Review of Segmentation Methods in the Field of EM Image Segmentation
3. Method
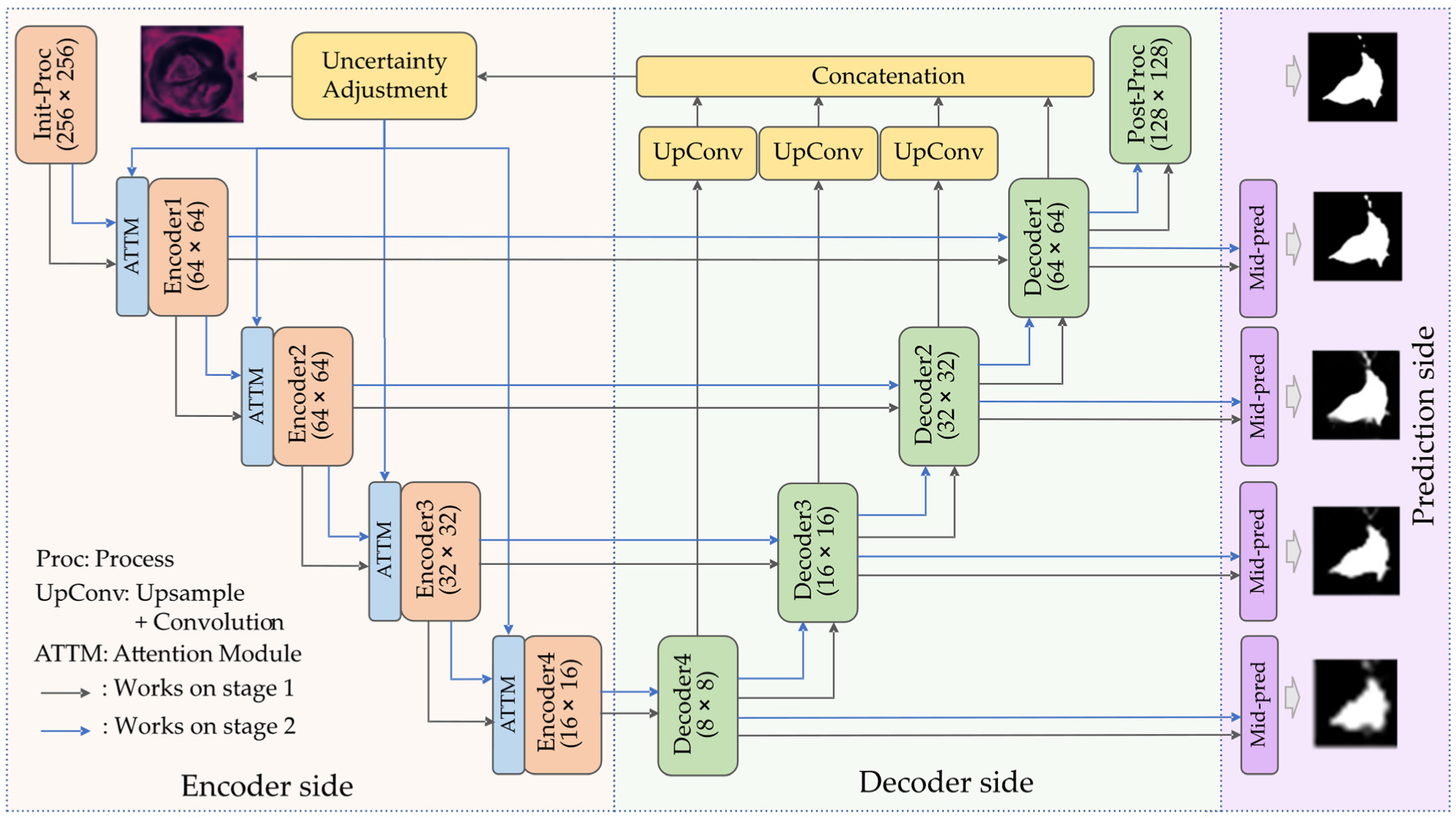
3.1. Network Architecture
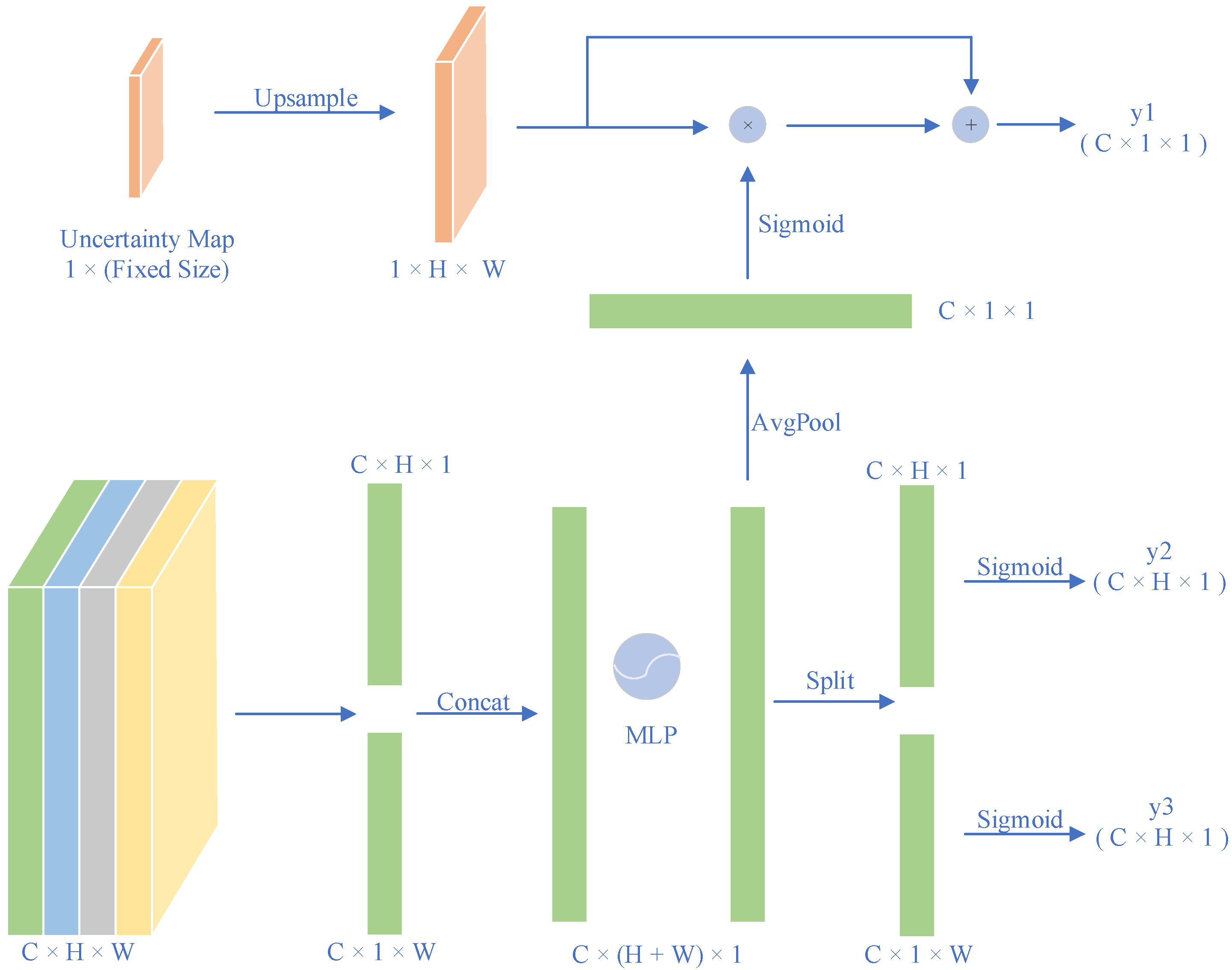
3.2. Uncertainty Revising Network
3.3. Attention Module
3.4. Mid-Pred Module
3.5. Loss Function
4. Experiments and Analysis
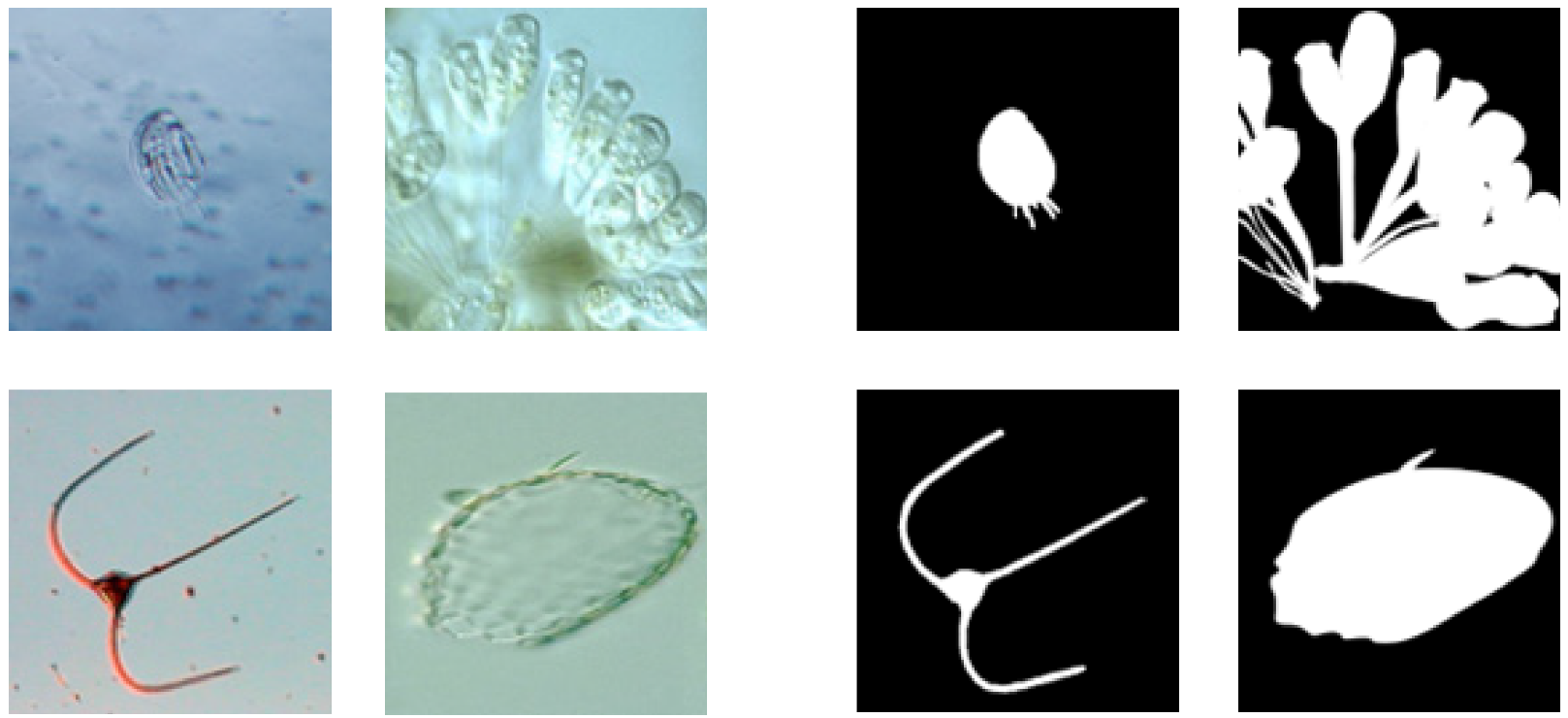
4.1. Experimental Datasets and Preprocessing
4.2. Experimental Setup and Evaluation
4.3. Ablation Experiment
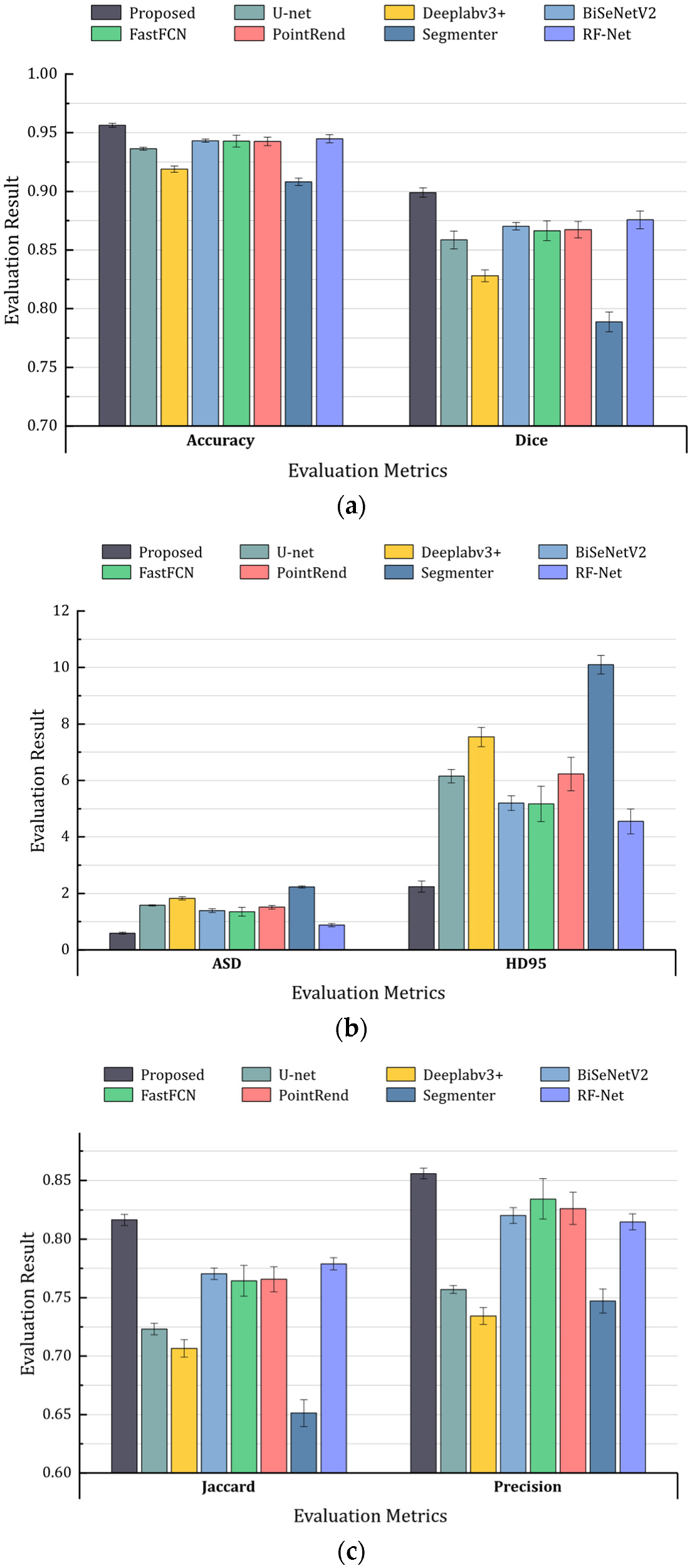
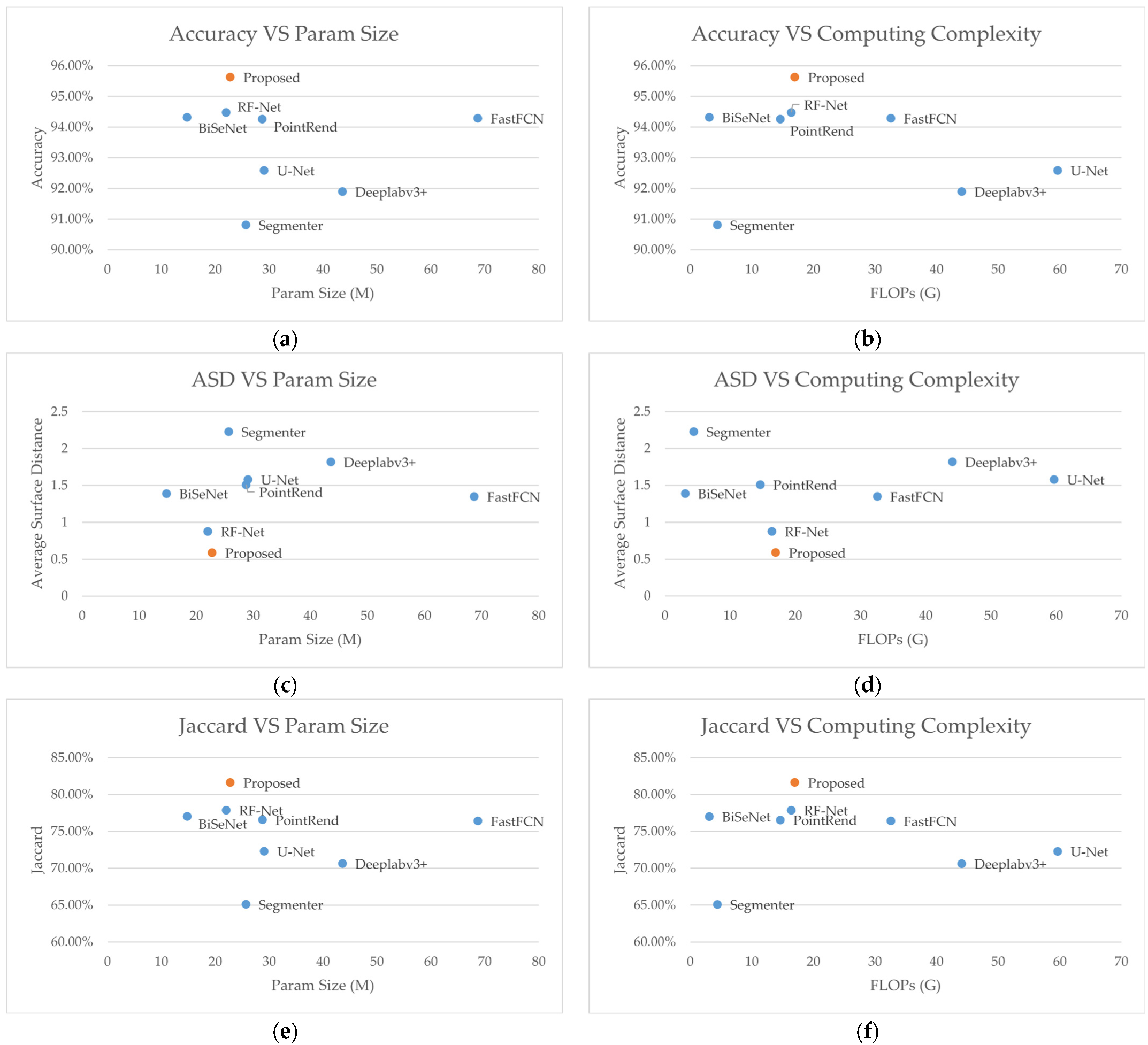
4.4. Comparison with the Latest Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pepper, I.L.; Gentry, T.J. Microorganisms Found in the Environment. In Environmental Microbiology; Elsevier: Amsterdam, The Netherlands, 2015; pp. 9–36. [Google Scholar]
- Buszewski, B.; Rogowska, A.; Pomastowski, P.; Z\loch, M.; Railean-Plugaru, V. Identification of Microorganisms by Modern Analytical Techniques. J. AOAC Int. 2017, 100, 1607–1623. [Google Scholar]
- Luo, Z.; Yang, W.; Gou, R.; Yuan, Y. TransAttention U-Net for Semantic Segmentation of Poppy. Electronics 2023, 12, 487. [Google Scholar] [CrossRef]
- Wang, K.; Liang, S.; Zhang, Y. Residual Feedback Network for Breast Lesion Segmentation in Ultrasound Image. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 471–481. [Google Scholar]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar]
- Nock, R.; Nielsen, F. Statistical Region Merging. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1452–1458. [Google Scholar]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An Efficient K-Means Clustering Algorithm: Analysis and Implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar]
- Najman, L.; Schmitt, M. Watershed of a Continuous Function. Signal Process. 1994, 38, 99–112. [Google Scholar]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast Approximate Energy Minimization via Graph Cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar]
- Plath, N.; Toussaint, M.; Nakajima, S. Multi-Class Image Segmentation Using Conditional Random Fields and Global Classification. In Proceedings of the 26th Annual International Conference on Machine learning, Montreal, QC, Canada, 14–18 June 2009; pp. 817–824. [Google Scholar]
- Li, S.Z. Ch. 13. Modeling Image Analysis Problems Using Markov Random Fields. Handb. Stat. 2003, 21, 473–513. [Google Scholar]
- Gabaix, X. A Sparsity-Based Model of Bounded Rationality. Q. J. Econ. 2014, 129, 1661–1710. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar]
- Chen, D.; Hu, F.; Mathiopoulos, P.T.; Zhang, Z.; Peethambaran, J. MC-UNet: Martian Crater Segmentation at Semantic and Instance Levels Using U-Net-Based Convolutional Neural Network. Remote Sens. 2023, 15, 266. [Google Scholar] [CrossRef]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Visin, F.; Kastner, K.; Cho, K.; Matteucci, M.; Courville, A.; Bengio, Y. ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks. arXiv 2015, arXiv:1505.00393. [Google Scholar]
- Byeon, W.; Breuel, T.M.; Raue, F.; Liwicki, M. Scene Labeling with Lstm Recurrent Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3547–3555. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2010, arXiv:11929 2020. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12179–12188. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Yang, C.; Wu, W.; Wang, Y.; Zhou, H. Multi-Modality Global Fusion Attention Network for Visual Question Answering. Electronics 2020, 9, 1882. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wu, J.; Liu, W.; Li, C.; Jiang, T.; Shariful, I.M.; Sun, H.; Li, X.; Li, X.; Huang, X.; Grzegorzek, M. A State-of-the-Art Survey of U-Net in Microscopic Image Analysis: From Simple Usage to Structure Mortification. arXiv 2022, arXiv:06465 2022. [Google Scholar]
- Dubuisson, M.-P.; Jain, A.K.; Jain, M.K. Segmentation and Classification of Bacterial Culture Images. J. Microbiol. Methods 1994, 19, 279–295. [Google Scholar]
- Kyan, M.; Guan, L.; Liss, S. Refining Competition in the Self-Organising Tree Map for Unsupervised Biofilm Image Segmentation. Neural Netw. 2005, 18, 850–860. [Google Scholar]
- Kosov, S.; Shirahama, K.; Li, C.; Grzegorzek, M. Environmental Microorganism Classification Using Conditional Random Fields and Deep Convolutional Neural Networks. Pattern Recognit. 2018, 77, 248–261. [Google Scholar]
- Hung, J.; Carpenter, A. Applying Faster R-CNN for Object Detection on Malaria Images. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 56–61. [Google Scholar]
- Zhang, J.; Li, C.; Kosov, S.; Grzegorzek, M.; Shirahama, K.; Jiang, T.; Sun, C.; Li, Z.; Li, H. LCU-Net: A Novel Low-Cost U-Net for Environmental Microorganism Image Segmentation. Pattern Recognit. 2021, 115, 107885. [Google Scholar]
- Aydin, A.S.; Dubey, A.; Dovrat, D.; Aharoni, A.; Shilkrot, R. CNN Based Yeast Cell Segmentation in Multi-Modal Fluorescent Microscopy Data. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, Hawaii, USA, 21–26 July 2017; pp. 753–759. [Google Scholar]
- Ang, R.B.Q.; Nisar, H.; Khan, M.B.; Tsai, C.-Y. Image Segmentation of Activated Sludge Phase Contrast Images Using Phase Stretch Transform. Microscopy 2019, 68, 144–158. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic Understanding of Scenes through the ADE20K Dataset. Int. J. Comput. Vis. 2018, 127, 302–321. [Google Scholar]
- Zhao, P.; Li, C.; Rahaman, M.M.; Xu, H.; Ma, P.; Yang, H.; Sun, H.; Jiang, T.; Xu, N.; Grzegorzek, M. EMDS-6: Environmental Microorganism Image Dataset Sixth Version for Image Denoising, Segmentation, Feature Extraction, Classification, and Detection Method Evaluation. Front. Microbiol. 2022, 13, 1334. [Google Scholar]
- Wang, L.; Lee, C.-Y.; Tu, Z.; Lazebnik, S. Training Deeper Convolutional Networks with Deep Supervision. arXiv 2015, arXiv:1505.02496. [Google Scholar]
- Zhao, X.; Zhang, P.; Song, F.; Ma, C.; Fan, G.; Sun, Y.; Feng, Y.; Zhang, G. Prior Attention Network for Multi-Lesion Segmentation in Medical Images. IEEE Trans. Med. Imaging 2022, 41, 3812–3823. [Google Scholar]
- Wang, K.; Liang, S.; Zhong, S.; Feng, Q.; Ning, Z.; Zhang, Y. Breast Ultrasound Image Segmentation: A Coarse-to-Fine Fusion Convolutional Neural Network. Med. Phys. 2021, 48, 4262–4278. [Google Scholar]
- Leng, Z.; Tan, M.; Liu, C.; Cubuk, E.D.; Shi, X.; Cheng, S.; Anguelov, D. PolyLoss: A Polynomial Expansion Perspective of Classification Loss Functions. arXiv 2022, arXiv:2204.12511. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 17–24 May 2018; pp. 801–818. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar]
- Wu, H.; Zhang, J.; Huang, K.; Liang, K.; Yu, Y. Fastfcn: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation. arXiv 2019, arXiv:1903.11816. [Google Scholar]
- Kirillov, A.; Wu, Y.; He, K.; Girshick, R. PointRend: Image Segmentation as Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9799–9808. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Architecture | |||||
|---|---|---|---|---|---|---|
| P | Convolutions | U | S | Notes | ||
| Initial encoder | √ | (7 × 7, 64, stride = 2) | Similar to ResNet-50 | |||
| Encoder | 1 | √ | ((1 × 1, 64) -> (3 × 3, 64) -> (1 × 1, 128)) × 3 | |||
| 2 | √ | ((1 × 1, 128) -> (3 × 3, 128) -> (1 × 1, 256)) × 4 | ||||
| 3 | √ | ((1 × 1, 256) -> (3 × 3, 256) -> (1 × 1, 512)) × 6 | ||||
| 4 | √ | ((1 × 1, 512) -> (3 × 3, 512) -> (1 × 1, 1024)) × 3 | ||||
| Decoder | 4 | (1 × 1, 128) -> (3 × 3, 128) -> (1 × 1, 512) | √ | Pooling: (3 × 3), stride = 2 Upsample: scale factor = 2 ×n: repeat for n times | ||
| 3 | (1 × 1, 64) -> (3 × 3, 64) -> (1 × 1, 256) | √ | ||||
| 2 | (1 × 1, 32) -> (3 × 3, 32) -> (1 × 1, 128) | √ | ||||
| 1 | (1 × 1, 16) -> (3 × 3, 16) -> (1 × 1, 64) | √ | ||||
| Final process | (3 × 3, 64) × 2 -> (3 × 3, 1) | √ | √ | |||
| Uncertainty feedback | (3 × 3, 64) -> (3 × 3, 1) | √ | ||||
| UpConv | (3 × 3, 64) | √ | Resample to (128, 128) | |||
| Mid-pred | Mentioned below | |||||
| Attention | ||||||
| Evaluation Indicators | Formula | Note |
|---|---|---|
| Accuracy | ||
| Dice | ||
| Jaccard | ||
| Recall | ||
| Precision | ||
| ASD | ||
| HD95 |
| Network | Accuracy | Dice | Jaccard | Recall | ASD | HD95 | Precision |
|---|---|---|---|---|---|---|---|
| Baseline | 94.48% | 87.57% | 77.89% | 94.64% | 0.88 | 4.55 | 81.48% |
| Baseline + MP | 94.55% | 87.81% | 78.28% | 95.53% | 0.97 | 3.95 | 81.25% |
| Baseline + MP + A | 95.40% | 89.27% | 80.61% | 93.13% | 0.62 | 3.04 | 85.71% |
| Baseline + MP + A + ML | 95.63% | 89.90% | 81.65% | 94.68% | 0.59 | 2.24 | 85.58% |
| Network | FLOPs | Params |
|---|---|---|
| Baseline | 16.38 G | 22.01 M |
| Baseline + MP | 16.96 G | 22.50 M |
| Baseline + MP + A | 16.98 G | 22.77 M |
| Baseline + MP + A+ML | 16.98 G | 22.77 M |
| Accuracy | Dice | Jaccard | Recall | ASD | HD95 | Precision | |
|---|---|---|---|---|---|---|---|
| Proposed | 95.63% | 89.90% | 81.65% | 94.68% | 0.59 | 2.24 | 85.58% |
| U-Net | 92.59% | 83.93% | 72.31% | 94.16% | 1.58 | 6.15 | 75.70% |
| Deeplabv3+ | 91.90% | 82.80% | 70.65% | 94.92% | 1.82 | 7.54 | 73.42% |
| BiSeNetv2 | 94.32% | 87.03% | 77.04% | 92.68% | 1.39 | 5.2 | 82.03% |
| FastFCN | 94.29% | 86.64% | 76.44% | 90.11% | 1.35 | 5.17 | 83.44% |
| PointRend | 94.26% | 86.73% | 76.58% | 91.29% | 1.51 | 6.23 | 82.62% |
| Segmenter | 90.81% | 78.87% | 65.12% | 83.54% | 2.23 | 10.1 | 74.70% |
| RF-Net | 94.48% | 87.57% | 77.89% | 94.64% | 0.88 | 4.55 | 81.48% |
| Network | FLOPs | Params |
|---|---|---|
| Proposed | 16.98 G | 22.77 M |
| U-Net | 59.64 G | 29.06 M |
| Deeplabv3+ | 44.05 G | 43.58 M |
| BiSeNetv2 | 3.09 G | 14.78 M |
| FastFCN | 32.56 G | 68.70 M |
| PointRend | 14.61 G | 28.73 M |
| Segmenter | 4.40 G | 25.68 M |
| RF-Net | 16.38 G | 22.01 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Na, H.; Liu, D.; Wang, S. An Attention-Based Uncertainty Revising Network with Multi-Loss for Environmental Microorganism Segmentation. Electronics 2023, 12, 763. https://doi.org/10.3390/electronics12030763
Na H, Liu D, Wang S. An Attention-Based Uncertainty Revising Network with Multi-Loss for Environmental Microorganism Segmentation. Electronics. 2023; 12(3):763. https://doi.org/10.3390/electronics12030763
Chicago/Turabian StyleNa, Hengyuan, Dong Liu, and Shengsheng Wang. 2023. "An Attention-Based Uncertainty Revising Network with Multi-Loss for Environmental Microorganism Segmentation" Electronics 12, no. 3: 763. https://doi.org/10.3390/electronics12030763
APA StyleNa, H., Liu, D., & Wang, S. (2023). An Attention-Based Uncertainty Revising Network with Multi-Loss for Environmental Microorganism Segmentation. Electronics, 12(3), 763. https://doi.org/10.3390/electronics12030763