
WRA-MF: A Bit-Level Convolutional-Weight-Decomposition Approach to Improve Parallel Computing Efficiency for Winograd-Based CNN Acceleration



Abstract
:1. Introduction
- ■
- The WRA-MF finds the multiplication operations in the Winograd algorithm mathematically to determine the optimal decomposition object and to screen out the proper parameters, designing a convolution unit with minimal hardware resources;
- ■
- The bit-level convolutional-weight-decomposition approach based on the Winograd algorithm was efficiently implemented. The efficient computation architecture employs a high degree of parallelism;
- ■
- This work proposes a WRA-MF architecture with an eight-bit fixed-point data representation, which is implemented on the Xilinx XCVU9P FPGA. Compared with state-of-the-art works, the evaluation for the area efficiency shows 3.47×–27.55× improvements.
2. Related Work and Motivation
2.1. Related Work
2.2. Motivation
3. Approach
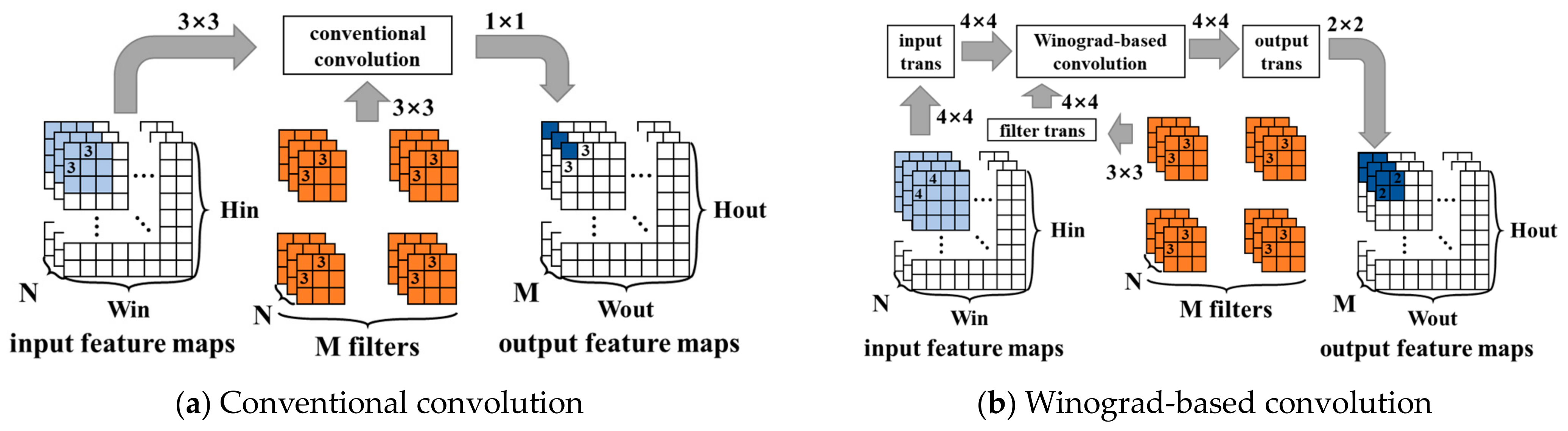
3.1. Preliminary
3.2. Method
- (1)
- Each filter matrix and input pixel matrix is transformed, obtaining () and (), respectively;
- (2)
- The transformed matrix () is decomposed at the bit level so that the multiplication operations can be replaced by accumulation operations and shift operations;
- (3)
- The output transformation matrix is used to transform matrix (), obtained in the second step, and, finally, the convolution result () is obtained.
- (4)
- Steps (1)~(3) are iteratively performed, and then output feature maps of all the convolution channels can be generated.
4. Implementation
4.1. WRA-MF Architecture
4.2. Transform Units
4.3. MF-PE
4.4. Comparator Array
4.5. Carry-Save Adder (CSA)
5. Experimental Evaluation
5.1. Evaluation of Operations
5.2. Results and Comparisons
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wodzinski, M.; Skalski, A.; Hemmerling, D.; Orozco-Arroyave, J.R.; Nöth, E. Deep Learning Approach to Parkinson’s Disease Detection Using Voice Recordings and Convolutional Neural Network Dedicated to Image Classification. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 717–720. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Afdhal, A.; Nasaruddin, N.; Fuadi, Z.; Sugiarto, S.; Riza, H.; Saddami, K. Evaluation of Benchmarking Pre-Trained CNN Model for Autonomous Vehicles Object Detection in Mixed Traffic. In Proceedings of the 2022 International Conference on ICT for Smart Society (ICISS), Bandung, Indonesia, 10–11 August 2022; pp. 1–6. [Google Scholar]
- Yang, T.-J.; Chen, Y.-H.; Sze, V. Designing Energy-Efficient Convolutional Neural Networks Using Energy-Aware Pruning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6071–6079. [Google Scholar]
- Suda, N.; Chandra, V.; Dasika, G.; Mohanty, A.; Ma, Y.; Vrudhula, S.; Seo, J.S.; Cao, Y. Throughput-optimized OpenCL-based FPGA accelerator for large-scale convolutional neural networks. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 16–25. [Google Scholar]
- Zeng, H.; Chen, R.; Zhang, C.; Prasanna, V. A framework for generating high throughput CNN implementations on FPGAs. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, New York, NY, USA, 25–27 February 2018; pp. 117–126. [Google Scholar]
- Yang, C.; Wang, Y.; Wang, X.; Geng, L. WRA: A 2.2-to-6.3 TOPS Highly Unified Dynamically Reconfigurable Accelerator Using a Novel Winograd Decomposition Algorithm for Convolutional Neural Networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 3480–3493. [Google Scholar] [CrossRef]
- Wang, D.; Xu, K.; Jia, Q.; Ghiasi, S. ABM-SpConv: A novel approach to FPGA-based acceleration of convolutional neural network inference. In Proceedings of the 56th Annual Design Automation Conference, Las Vegas, NV, USA, 2–6 July 2019; pp. 1–6. [Google Scholar]
- Yue, J.; Liu, R.; Sun, W.; Yuan, Z.; Wang, Z.; Tu, Y.N.; Chen, Y.-J.; Ren, A.; Wang, Y.; Chang, M.-F.; et al. 7.5 A 65nm 0.39-to-140.3TOPS/W 1-to-12b Unified Neural Network Processor Using Block-Circulant-Enabled Transpose-Domain Acceleration with 8.1 × Higher TOPS/mm2and 6T HBST-TRAM-Based 2D Data-Reuse Architecture. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 17–21 February 2019; pp. 138–140. [Google Scholar]
- Wang, J.; Lin, J.; Wang, Z. Efficient Hardware Architectures for Deep Convolutional Neural Network. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 65, 1941–1953. [Google Scholar] [CrossRef]
- Lavin, A.; Gray, S. Fast Algorithms for Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4013–4021. [Google Scholar]
- Yang, C.; Lv, X.; Li, B.; Fan, S.; Mei, K.; Geng, L. MF-Conv: A Novel Convolutional Approach Using Bit-Resolution-based Weight Decomposition to Eliminate Multiplications for CNN Acceleration. In Proceedings of the 2020 IEEE 15th International Conference on Solid-State & Integrated Circuit Technology (ICSICT), Kunming, China, 3–6 November 2020; pp. 1–3. [Google Scholar]
- Wang, D.; Xu, K.; Guo, J.; Ghiasi, S. DSP-Efficient Hardware Acceleration of Convolutional Neural Network Inference on FPGAs. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 4867–4880. [Google Scholar] [CrossRef]
- Wang, X.; Wang, C.; Cao, J.; Gong, L.; Zhou, X. WinoNN: Optimizing FPGA-Based Convolutional Neural Network Accelerators Using Sparse Winograd Algorithm. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 4290–4302. [Google Scholar] [CrossRef]
- Yepez, J.; Ko, S.-B. Stride 2 1-D, 2-D, and 3-D Winograd for Convolutional Neural Networks. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 853–863. [Google Scholar] [CrossRef]
- Abtahi, T.; Shea, C.; Kulkarni, A.; Mohsenin, T. Accelerating Convolutional Neural Network With FFT on Embedded Hardware. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1737–1749. [Google Scholar] [CrossRef]
- Wang, H.; Xu, W.; Zhang, Z.; You, X.; Zhang, C. An Efficient Stochastic Convolution Architecture Based on Fast FIR Algorithm. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 984–988. [Google Scholar] [CrossRef]
- Li, X.; Gong, X.; Wang, D.; Zhang, J.; Baker, T.; Zhou, J.; Lu, T. ABM-SpConv-SIMD: Accelerating Convolutional Neural Network Inference for Industrial IoT Applications on Edge Devices. IEEE Trans. Netw. Sci. Eng. 2023, 10, 3071–3085. [Google Scholar] [CrossRef]
- Dupuis, E.; Novo, D.; O’Connor, I.; Bosio, A. A Heuristic Exploration of Retraining-free Weight-Sharing for CNN Compression. In Proceedings of the 2022 27th Asia and South Pacific Design Automation Conference (ASP-DAC), Taipei, Taiwan, 17–20 January 2022; pp. 134–139. [Google Scholar]
- Liu, Y.; Zhao, B.; Zhang, S.; Xiao, W. Motor Imagery EEG Recognition Based on Weight-Sharing CNN-LSTM Network. In Proceedings of the 2022 34th Chinese Control and Decision Conference (CCDC), Hefei, China, 15–17 August 2022; pp. 1382–1386. [Google Scholar]
- Takahashi, R.; Matsubara, T.; Uehara, K. A Novel Weight-Shared Multi-Stage CNN for Scale Robustness. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 1090–1101. [Google Scholar] [CrossRef]
- Cameron, J.A.D. Design considerations for the processing system of a CNN-based automated surveillance system. Expert Syst. Appl. 2019, 136, 105–114. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Y.; Wang, X.; Geng, L. A Stride-Based Convolution Decomposition Method to Stretch CNN Acceleration Algorithms for Efficient and Flexible Hardware Implementation. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 3007–3020. [Google Scholar] [CrossRef]
- Gysel, P.; Pimentel, J.; Motamedi, M.; Ghiasi, S. Ristretto: A Framework for Empirical Study of Resource-Efficient Inference in Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5784–5789. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Ni, C.; Wang, Z. ETA: An Efficient Training Accelerator for DNNs Based on Hardware-Algorithm Co-Optimization. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7660–7674. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Wu, H.; Chen, Q.; Luo, C.; Zeng, S.; Li, T.; Huang, Y. FPGA-Based High-Throughput CNN Hardware Accelerator With High Computing Resource Utilization Ratio. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4069–4083. [Google Scholar] [CrossRef] [PubMed]
- Yin, Q.; Li, Y.; Huang, H.; Li, H.; Zhang, Q.; Cao, B.; Zhang, J. FPGA-based High-performance CNN Accelerator Architecture with High DSP Utilization and Efficient Scheduling Mode. In Proceedings of the 2020 International Conference on High Performance Big Data and Intelligent Systems (HPBD&IS), Shenzhen, China, 23–23 May 2020; pp. 1–7. [Google Scholar]
- Li, S.; Wang, Q.; Jiang, J.; Sheng, W.; Jing, N.; Mao, Z. An Efficient CNN Accelerator Using Inter-Frame Data Reuse of Videos on FPGAs. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2022, 30, 1587–1600. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.; Hao, C.; Dhar, A.; Chen, D. WinoCNN: Kernel Sharing Winograd Systolic Array for Efficient Convolutional Neural Network Acceleration on FPGAs. In Proceedings of the 2021 IEEE 32nd International Conference on Application-specific Systems, Architectures and Processors (ASAP), Piscataway, NJ, USA, 7–9 July 2021; pp. 258–265. [Google Scholar]
- Chen, J.; Zhang, Z.; Lu, H.; Hu, J.; Sobelman, G.E. An Intra-Iterative Interference Cancellation Detector for Large-Scale MIMO Communications Based on Convex Optimization. IEEE Trans. Circuits Syst. I Regul. Pap. 2016, 63, 2062–2072. [Google Scholar] [CrossRef]
- Wang, W.-C.; Hung, Y.-C.; Du, Y.-H.; Yang, S.-H.; Huang, Y.-H. FPGA-Based Tensor Compressive Sensing Reconstruction Processor for Terahertz Single-Pixel Imaging Systems. IEEE Open J. Circuits Syst. 2022, 3, 336–350. [Google Scholar] [CrossRef]
- Ho, P.-P.; Chen, C.-E.; Huang, Y.-H. Low-Latency Lattice-Reduction-Aided One-Bit Precoding Processor for 64-QAM 4×64 MU–MIMO Systems. IEEE Open J. Circuits Syst. 2021, 2, 472–484. [Google Scholar] [CrossRef]
- Tu, J.; Lou, M.; Jiang, J.; Shu, D.; He, G. An Efficient Massive MIMO Detector Based on Second-Order Richardson Iteration: From Algorithm to Flexible Architecture. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 4015–4028. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OpenCL [6] | FDConv [7] | WRA [8] | ABM-SpConv [9] | |
|---|---|---|---|---|
| Logic Usage | 23% | 46% | 19% | 68% |
| DSP Usage | 96% | 100% | 60% | 94% |
| Usage Ratio | 0.24/1 | 0.46/1 | 0.31/1 | 0.72/1 |
| for row = 0; row < H; row += s do | //row_loop |
| for col = 0; col < W; col += s do | //col_loop |
| for ti = 0; ti < N; ++ti do | //ich_loop |
| for to = 0; to < M; ++to do | //och_loop |
| for k = 0; k < K; ++k do | //filter_loop |
| for k′ = 0; k′ < K; ++k′ do | |
| y[row][col][to] += w[ti][to][k][k′] × x[row + k][col + k′][ti] | |
| for q = 0; q < Q − 1 do |
| if u[q] = 1 then v′[q] = v |
| else v′[q] = 0 |
| end |
| Network | Number of OPs | |||
|---|---|---|---|---|
| Approach | LeNet | AlexNet | VGG16 | |
| Conventional | Add | 2448 | 3,376,896 | 17,794,560 |
| Mult | 2550 | 3,745,824 | 20,018,880 | |
| ABM-SpConv [9] | Add | 2448 | 3,376,896 | 17,794,560 |
| Mult | 2330 | 2,850,363 | 13,164,757 | |
| WRA [8] | Add | 4590 | 4,659,840 | 13,227,120 |
| Mult | 1632 | 1,656,832 | 4,702,976 | |
| WRA-MF | Add | 18,054 | 18,143,916 | 52,026,672 |
| Mult | 0 | 0 | 0 | |
| Layer | Input 1 | OP Type 2 | OP Size 3 | Output | Layer | Input | OP Type | OP Size | Output |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 224 × 224 × 3 | Conv | 3 × 3/1 × 3 × 64 | 224 × 224 × 64 | 12 | 28 × 28 × 512 | Conv | 3 × 3/1 × 512 × 512 | 28 × 28 × 512 |
| 2 | 224 × 224 × 64 | Conv | 3 × 3/1 × 64 × 64 | 224 × 224 × 64 | 13 | 28 × 28 × 512 | Conv | 3 × 3/1 × 512 × 512 | 28 × 28 × 512 |
| 3 | 224 × 224 × 64 | Maxpool | 2 × 2/2 | 112 × 112 × 64 | 14 | 28 × 28 × 512 | Maxpool | 2 × 2/2 | 14 × 14 × 512 |
| 4 | 112 × 112 × 64 | Conv | 3 × 3/1 × 64 × 128 | 112 × 112 × 128 | 15 | 14 × 14 × 512 | Conv | 3 × 3/1 × 512 × 512 | 14 × 14 × 512 |
| 5 | 112 × 112 × 128 | Conv | 3 × 3/1 × 128 × 128 | 112 × 112 × 128 | 16 | 14 × 14 × 512 | Conv | 3 × 3/1 × 512 × 512 | 14 × 14 × 512 |
| 6 | 112 × 112 × 128 | Maxpool | 2 × 2/2 | 56 × 56 × 128 | 17 | 14 × 14 × 512 | Conv | 3 × 3/1 × 512 × 512 | 14 × 14 × 512 |
| 7 | 56 × 56 × 128 | Conv | 3 × 3/1 × 128 × 256 | 56 × 56 × 256 | 18 | 14 × 14 × 512 | Maxpool | 2 × 2/2 | 7 × 7 × 512 |
| 8 | 56 × 56 × 256 | Conv | 3 × 3/1 × 256 × 256 | 56 × 56 × 256 | 19 | 7 × 7 × 512 | FC | 4096 | 4096 |
| 9 | 56 × 56 × 256 | Conv | 3 × 3/1 × 256 × 256 | 56 × 56 × 256 | 20 | 4096 | FC | 4096 | 4096 |
| 10 | 56 × 56 × 256 | Maxpool | 2 × 2/2 | 28 × 28 × 256 | 21 | 4096 | FC | 1000 | 1000 |
| 11 | 28 × 28 × 256 | Conv | 3 × 3/1 × 256 × 512 | 28 × 28 × 512 | 22 | Softmax | |||
| TNNLS 2022 [26] | TNNLS 2022 [27] | TCAD 2020 [14] | HPBD&IS 2020 [28] | TCAS-I 2019 [8] | TVLSI 2022 [29] | ASAP 2021 [30] | This Work | |
|---|---|---|---|---|---|---|---|---|
| Precision | Fixed 8 | Fixed 8/16 FP | Fixed 8 | Fixed 8 | Fixed 8 | Fixed 8 | Fixed 8–16 | Fixed 8 |
| Platform | VC709 | VX980T | Stratix-V GXA7 | XCVU9P | XCVU9P | ZCU104 | ZCU102 | XCVU9P |
| Model | VGG16 | VGG16 | VGG16 | AlexNet | VGG16 | yolov3-tiny | VGG16 | VGG16 |
| Logic cell 1 | 132 K | 335 K | 144 K | 135 K | 224.7 K | 123 K | 221.9 K | 351.7 K |
| BRAM (kb) 2 | 8640 | 53,712 | 51,200 | 30,186 | 20,224 | 5868 | 28,563.8 | 20,291 |
| DSP | 1728 | 3395 | 69 | 2148 | 4096 | 146 | 2345 | 0 |
| Clocks (MHz) | 200 | 150 | 200 | 300 | 330 | 200 | 214 | 509 |
| Power (W) | 8.44 | 14.36 | n/a | 10.14 | 35.0 | 3.301 | n/a | 52.0 |
| Throughput (GOP/s) | 610.98 | 1000 | 1013 | 2815.2 | 5288 | 348 | 3120.2 | 7559 5 |
| NRC 3 | 615.84 K | 1285.6 K | 163.32 K | 736.44 K | 1371.58 K | 163.88 K | 878.5 K | 351.7 K |
| Area efficiency 4 | 0.99 | 0.78 | 6.20 | 3.82 | 3.86 | 2.12 | 3.55 | 21.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, S.; Lv, X.; Meng, Y.; Wang, J.; Lu, C.; Yang, C. WRA-MF: A Bit-Level Convolutional-Weight-Decomposition Approach to Improve Parallel Computing Efficiency for Winograd-Based CNN Acceleration. Electronics 2023, 12, 4943. https://doi.org/10.3390/electronics12244943
Xiang S, Lv X, Meng Y, Wang J, Lu C, Yang C. WRA-MF: A Bit-Level Convolutional-Weight-Decomposition Approach to Improve Parallel Computing Efficiency for Winograd-Based CNN Acceleration. Electronics. 2023; 12(24):4943. https://doi.org/10.3390/electronics12244943
Chicago/Turabian StyleXiang, Siwei, Xianxian Lv, Yishuo Meng, Jianfei Wang, Cimang Lu, and Chen Yang. 2023. "WRA-MF: A Bit-Level Convolutional-Weight-Decomposition Approach to Improve Parallel Computing Efficiency for Winograd-Based CNN Acceleration" Electronics 12, no. 24: 4943. https://doi.org/10.3390/electronics12244943
APA StyleXiang, S., Lv, X., Meng, Y., Wang, J., Lu, C., & Yang, C. (2023). WRA-MF: A Bit-Level Convolutional-Weight-Decomposition Approach to Improve Parallel Computing Efficiency for Winograd-Based CNN Acceleration. Electronics, 12(24), 4943. https://doi.org/10.3390/electronics12244943