1. Introduction
The accurate monitoring of a machine’s degradation plays a pivotal role in condition-based predictive maintenance, facilitating timely maintenance actions and maximizing the lifespan of critical assets [
1]. Contemporary assets are monitored by several sensors in order to detect potential defects at an early stage and estimate the remaining useful life (RUL) of the asset. Typically, the machine deterioration is assessed by evaluating a so-called health index (HI). A HI is a numerical value derived from the raw data samples for each measurement of the monitored asset. It is intended to reflect the health status of the system.
If evaluated over time, this so-called HI curve develops either an increasing or decreasing slope. The direction of the trend is depending on the HI definition. In conventional condition monitoring, this definition is based on the assessment of a device maintenance expert [
2]. Hence, the HI is constructed by evaluating relevant trending parameters from a range of possible features [
3] to monitor the device’s health. Typically, RUL is then assessed by comparing HI curves of multiple devices [
4]. However, the approach depends on prior knowledge about the potential faults in the monitored device to select the correct parameters, as individual features may only be relevant to certain types of faults. This time-consuming, expert-guided selection may therefore suffer from a human-induced bias that limits their general applicability to a wider range of potential problems.
To counteract the human selection bias, more extensive HI estimation approaches have emerged. These either construct the HI based on autonomous evaluation of multiple traditional features [
5] or use data-driven supervised learning methods to extract expert-independent features from the raw data [
6]. Supervised machine learning methods have been heavily used in predictive maintenance [
7,
8,
9,
10].
Nonetheless, these methods necessitate a certain degree of human domain expertise. For instance, supervised methods require sets of labeled data, which are initially generated through time-consuming expert assessment. Thus, the extensive data volumes required to effectively train these supervised models present operational challenges. In addition, these methods make assumptions about the degradation shape [
11], which do not hold in real-world scenarios, emphasizing the necessity for more efficient domain knowledge-independent approaches. In the remainder of this paper, we introduce a novel methodology that eliminates the need for human labeling in the context of HI generation and operates without making any assumptions regarding degradation shape.
2. Related Literature, Problem Statement and Contribution
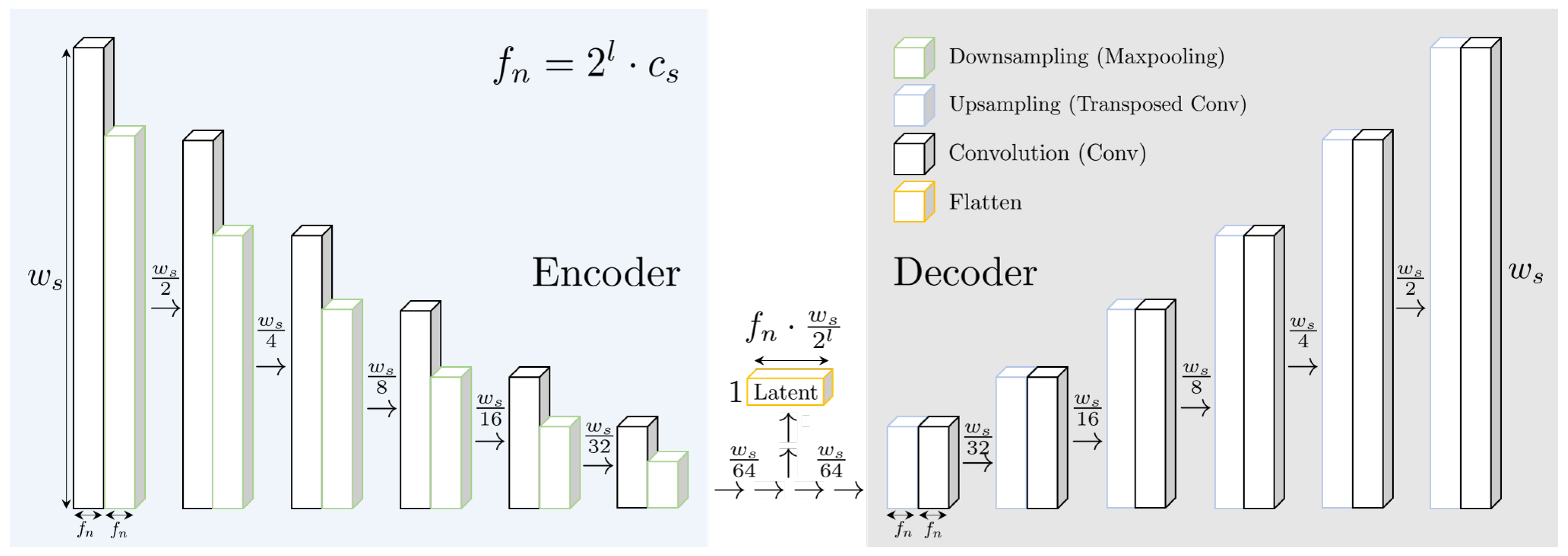
In recent advancements, unsupervised learning-based HI methods based on autoencoders are proposed in order to minimize time-consuming human evaluation of the individual measurements and eliminate assumptions about the degradation of the asset [
12]. Autoencoder are trained to reconstruct given input through an architecture bottleneck, the so-called latent vector. By training a reconstruction task, these models are expected to learn valuable features of the process of generating the data without requiring label information. Autoencoders are related to transformer networks [
13], which are state-of-the-art models in many sequence-related tasks such as language translation or time-series forecasting. However, transformers require unsupervised training on large datasets, which is not available in many predictive maintenance scenarios. For this reason, recent studies mostly leverage unsupervised autoencoder approaches based on long short-term memory (LSTM) [
14] or convolutional neural network (CNN) [
15].
In the context of unsupervised HI curve generation, the autoencoder is trained exclusively on healthy unlabeled measurements of a monitored functional device, which is usually present at the beginning of a test-to-failure experiment. As depicted in
Figure 1, the HI curve generation is centered around the idea that any autoencoder output, trained solely on healthy data, achieves worse reconstruction results as the wear-induced signal changes, which were not present in the training data, emerge over time. Therefore, the autoencoder HI is supposed to increase as the device is affected by wear over time.
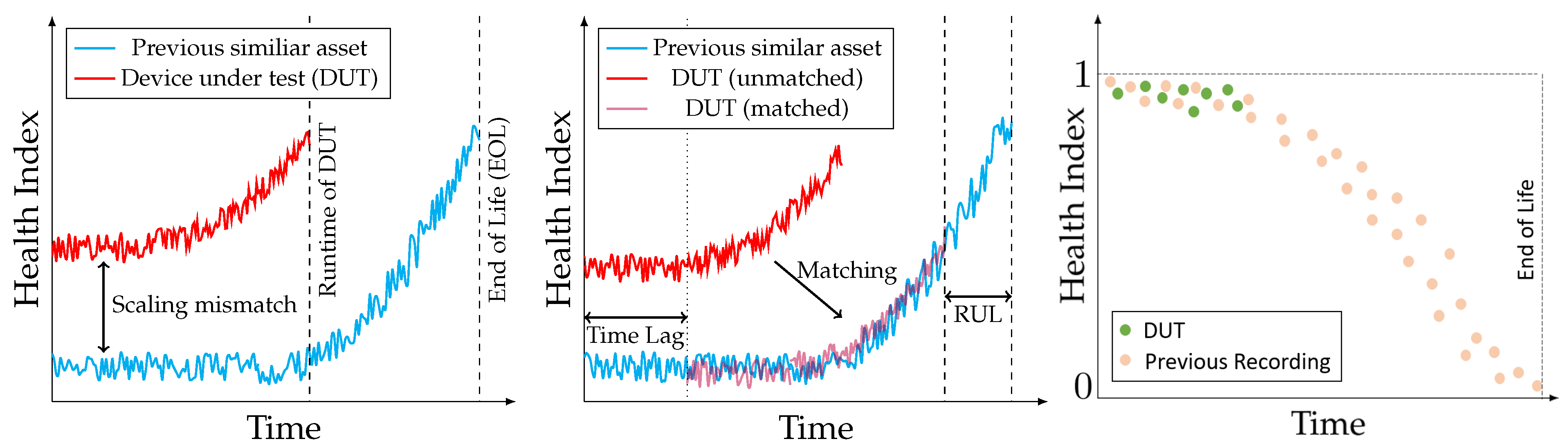
Previous work provided evidence that unsupervised HI curves based on autoencoders can be used to achieve state-of-the-art RUL estimation performances [
16]. In this work, the RUL is determined by matching HI curves from devices under test (DUT) with pre-recorded curves derived from historical data of a similar asset by minimizing their Euclidean distance between the individual curves [
17]. However, deriving the RUL of a device based on HI curves that are generated by unsupervised methods suffers from various limitations that we aim to address. Firstly, the initial value of the functional device is different for each individual machine. As stated above, any subsequent RUL estimation typically requires the comparison of multiple HI curves. Therefore, RUL estimation based on unsupervised HI evaluation is affected by a scaling discrepancy between individual curves, even when monitoring similar assets. An illustration of the scaling mismatch and the traditional matching-based RUL estimation is depicted in
Figure 2.
This non-coherent behavior of unsupervised HI curves is typically explained by the influence of slightly different device initial conditions [
12,
18]. For this reason, recent RUL methods introduce a time shift variable, the so-called “time lag”. However, the real initial conditions of the DUT are unknown in practical application, compromising the accuracy and reliability of the RUL estimates of the method.
Secondly, to make the HI definition more intuitive, it is desirable for any HI curve to start with an initial health of 1 and to decrease over time, tending towards 0 as the device becomes worn out. This is indicated in
Figure 2(right). Without additional time-lag estimation-based post-processing, this has not been implemented in autonomous HI generation [
5,
12,
19].
To address these limitations, we propose a novel approach to HI generation based on self-supervised learning. Self-supervised learning has shown superior performance in data-heavy domains such as medical imaging [
20] and general pattern recognition tasks [
21]. Recently, self-supervised learning has been introduced to the field of condition monitoring and failure diagnosis to detect specific faults in electric powertrain data by using unsupervised support vector machines [
22]. Unlike conventional supervised approaches, self-supervised methods do not require human-labeled data to train meaningful models. Instead, these methods aim to generate their own so-called ‘weak labels’ by evaluating unlabeled training data [
23,
24]. Note that in the literature, any label generated by a non-human expert is referred to as a weak label.
As illustrated in
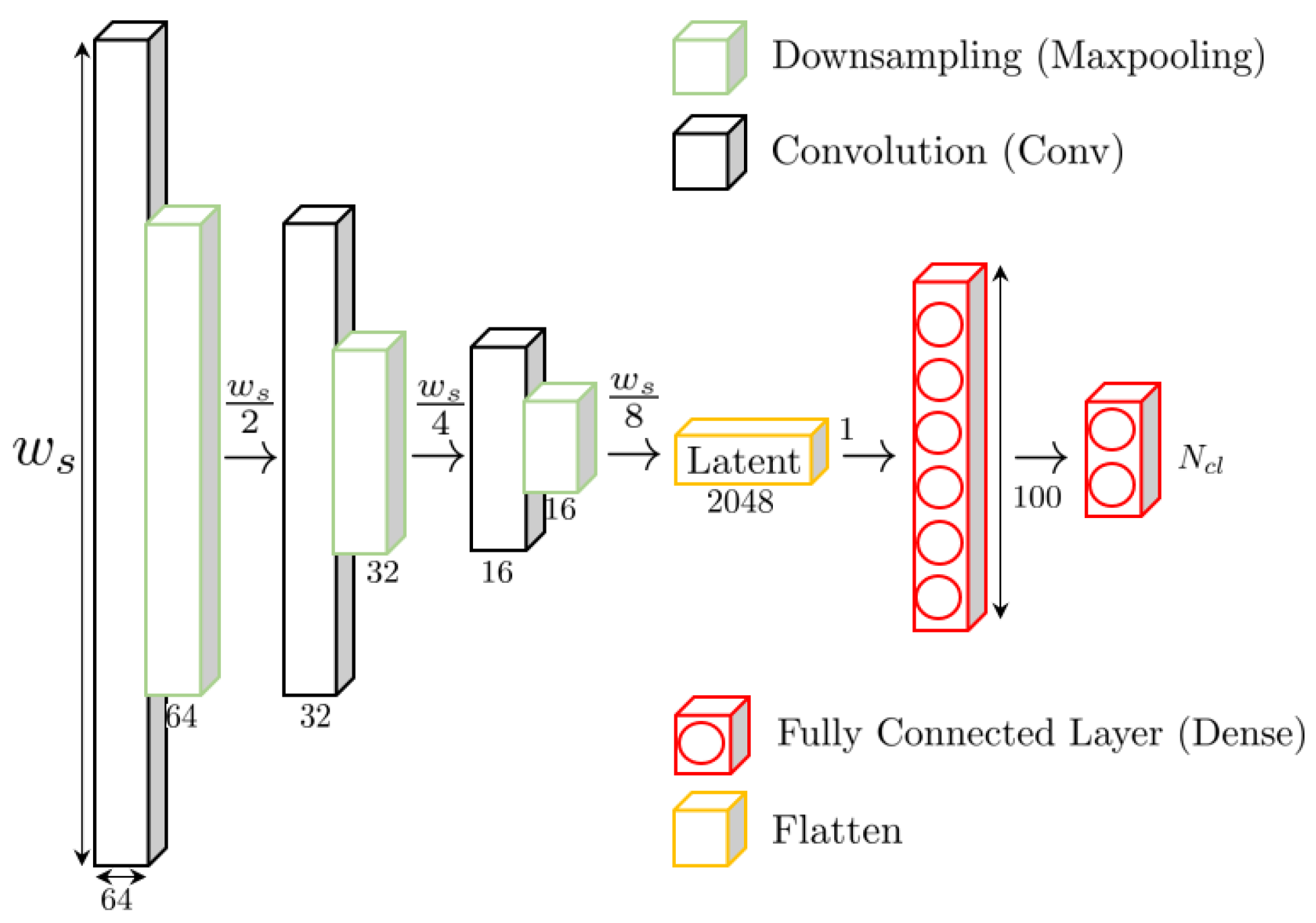
Figure 3, our method is based on a three-step appraoch: First, an autoencoder is going to learn an unsupervised representation of a data-generating process. Second, the trained model is used to detect the initial fault in the test-to-failure dataset. The initial fault, which is described in detail in
Section 3.1.4, is used to provide weak preliminary labels for each measurement in a test-to-failure dataset by assigning individual measurements to either the ‘functional’ or ‘faulty’ class. Third, the weakly labeled data is used to train a subsequent two-class classifier generating the HI in a binary classification setting.
To the best of our knowledge, self-supervised learning remains unexplored in the context of HI curve generation and it provides a valuable contribution to the current literature on HI generation. This paper shows:
The capability of self-supervised learning to estimate coherent HI curves of a device.
The enhanced self-supervised HI performance of CNN- over LSTM autoencoder.
That self-supervised HI curves indicate wear in the device prior to human experts.
The effects of imperfect weak labels on our proposed self-supervised HI method.
The rest of the paper is organized as follows: The proposed method is explained in
Section 3. The experimental setup used for verification is introduced in
Section 4 and the main results are presented in
Section 5.
Section 6 concludes this article.
5. Results and Discussion
5.1. Unsupervised Generation of Preliminary Labels
In this section, we carefully evaluate the quality of our proposed CNN autoencoder model trained using the functional data. In addition, we compare our method with the LSTM-based autoencoder of Malhotra et al. [
14] in terms of its suitability in the context of generating weakly labeled data. Our proposed self-supervised architecture relies on successful weak labeling of the unlabeled test-to-failure experiment data. It is therefore necessary that our model trained on functional device data achieves sufficient reconstruction performance on unseen data of this type. In addition, significantly worse performance should be evident on measurements affected by wear.
5.1.1. Evaluation of the Autoencoder Training Quality
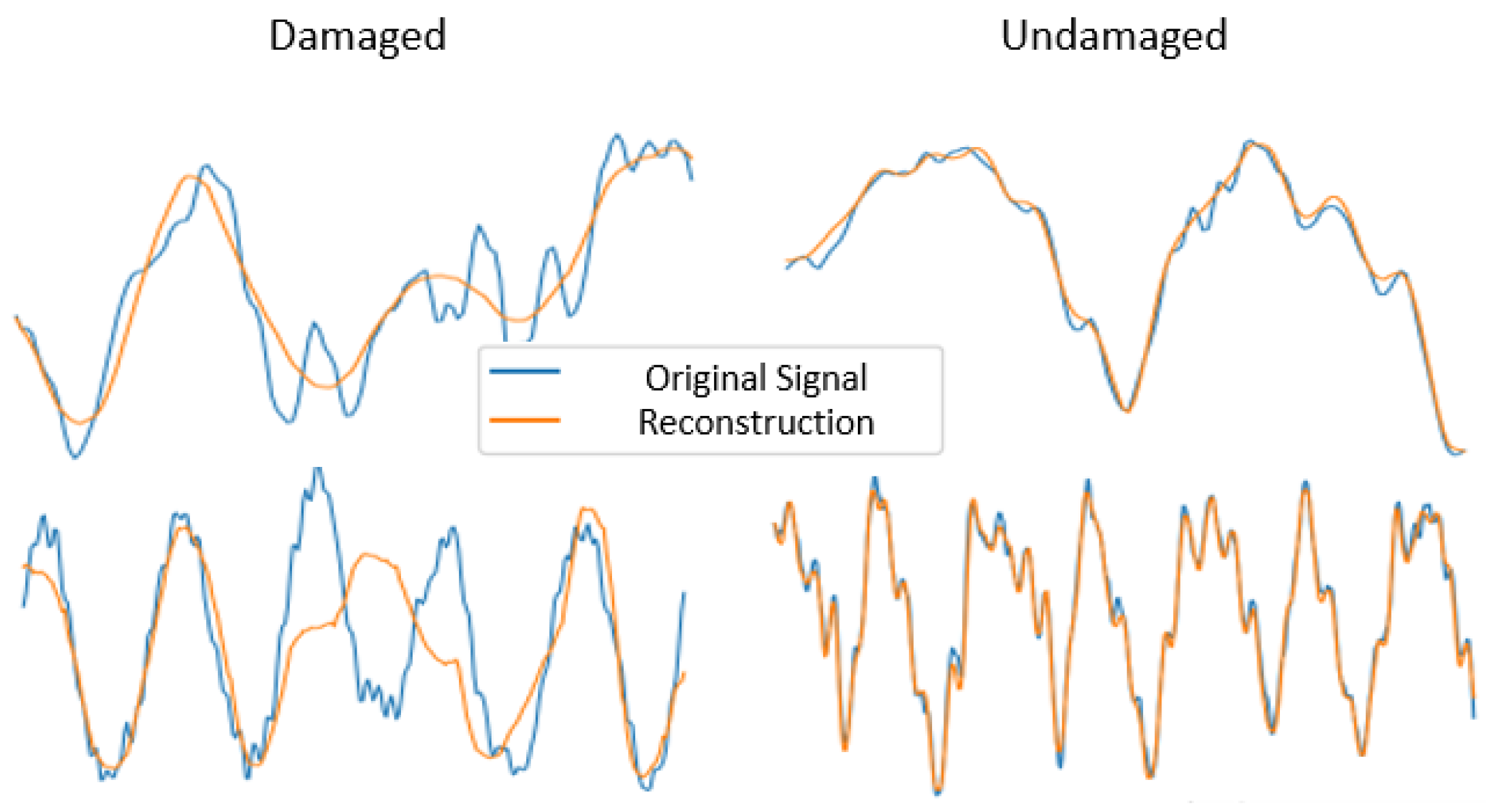
Figure 9 shows normalized example reconstructions generated by our 1D-autoencoder for functional and faulty test signals.
Visually, the trained model achieves a suitable reconstruction performance for undamaged samples. However, it encounters challenges when reconstructing damaged data. As a result, the autoencoder appears to have learned an accurate model of the machine under normal operating conditions, which, as anticipated, proves less effective for data stemming from a degraded machine. In accordance with
Section 3.1.4, we calculate the average autoencoder reconstruction error per measurement, denoted as
, over the entire operational life to estimate the initial faulty measurement within the deterioration curve of our test-to-failure experiments.
Figure 10 illustrates the best deterioration curve achieved by the CNN and LSTM autoencoder on bearing 1. Additionally, the plot shows how the suitability of the deterioration curves is assessed with respect to
Section 4.2.
Typically, early transient fluctuations usually do not reflect any real change in the health state of a time-worn machine under constant load. Thus, the dashed green line corresponds to an FPR of zero and marks the earliest possible correct initial fault estimate, not triggered early by random variations. In comparison, the dashed red line marks the ground truth threshold given by the human expert. The smaller the distance between both lines, the higher the AUC. Hence, a high AUC value indicates that the autoencoder model provides an initial fault estimation close to the human expert.
Figure 11 presents the AUC-based comparison for both architectural models applied to bearing 1.
Despite skipping the first 15 measurements of the experiment, the results of both models seem affected by additional run-in effects, lasting until the 3-h mark of testing. The device transitions into a normal operational condition, maintaining it until the 12-h mark when it finally starts producing faulty data. As indicated by the green line, the optimal threshold of our CNN method lags behind the independent human expert’s initial fault baseline by approximately 15 min. In contrast, the best possible threshold for the LSTM-based curve lags by over 2 h. This distinction is also reflected in their respective AUC scores. While the CNN achieves an AUC of 0.98, the LSTM only attains an AUC of 0.78 with the best hyperparameter setting described in the original work. Consequently, our proposed CNN architecture significantly outperforms the LSTM reference from the literature. Comparable results were obtained for other test-to-failure runs on bearing 5. However, these results are omitted here for brevity.
5.1.2. Influence of the Input Vector Window Size and Compression
The presented results of our CNN autoencoder are based on the choice of its hyperparameters, and for brevity, we only depicted the best performing so far. Nevertheless, we studied the impact of different input vector window sizes
fed into our autoencoder and the influence of different data compression rates
on the model performance. The results for both bearings within the dataset can be seen in
Table 1.
In our study, we achieve the best performance on both bearing test-to-failure runs using an input window size
and a compression ratio
. Note that a window size of 6144 samples corresponds to a full rotation of the bearing. All other tested window sizes are derived from the power of two. They were chosen due to their frequent usage in the machine learning literature on CNN to support model comparability. We decided to only study sizes below a complete rotation, as this would lead to overlap between the individual windows, which would enhance the memory effect during training. The compression rates are determined to study the effect of a very strong (50%), medium (25%), and low (12%) compression level. Given that the best-performing model based on Malhotra et al. [
14] using LSTM achieved inferior results compared to our best CNN model, all further evaluations are conducted exclusively with the CNN approach.
5.1.3. Visualization of the Trained Features Encoded in the Latent Vector
Related contributions on unsupervised HI estimation like [
27] or [
16] use visual evaluation methods like t-SNE [
28] or PCA [
29] to map the learned representations of the high dimensional latent vector onto a 2D plot and to compare the quality of different autoencoder models. Here, it is assumed that the most important information extracted by the trained autoencoder is present in its latent vector. By applying t-SNE and PCA, it is possible to explore emerging structures in this vector and to gain a deeper insight into results learned by a network.
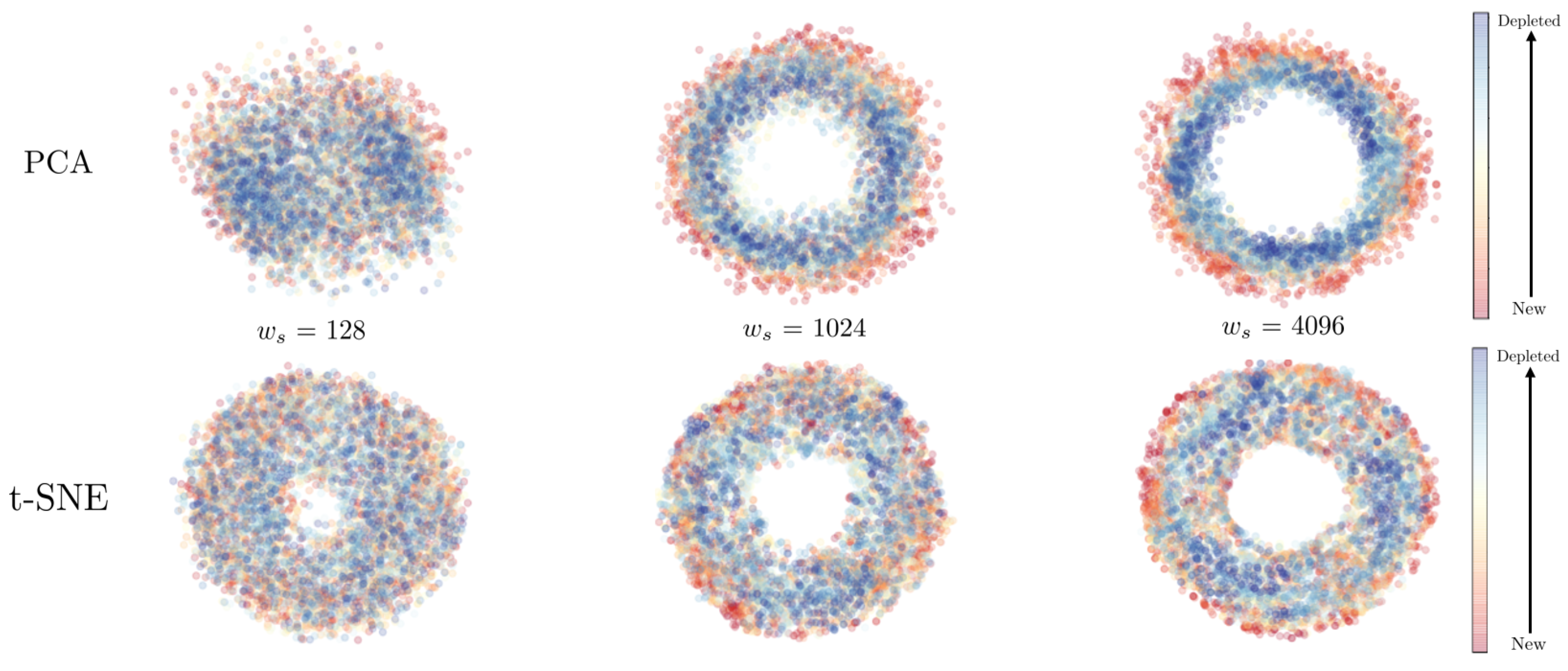
Figure 12 depicts such a t-SNE and PCA-based comparison of our CNN-autoencoder, using different window sizes and a fixed compression rate of 50%.
In the illustration, every individual point corresponds to a single measurement of the test-to-failure experiment for bearing 1. To achieve the plot, first, each measurement was fed sequentially into the trained autoencoder and the corresponding latent values were concatenated. Second, t-SNE and PCA were applied to the constructed high dimensional latent value matrix to map it to the depicted 2D plot. The recording period of each measurement is encoded by a colored gradient to visualize the chronological order of the recorded bearing life-cycle. Notably, both visualization methods yield toroidal representations that analyze the data of the rotating machinery. The results show that the t-SNE algorithm seems superior in visualizing the rotating data’s repeating character since it succeeds even for small window sizes. However, t-SNE is not suited to visualizing the deterioration process since no clear trend is observable. Here, PCA has an advantage since lifetime progression is observable from outside inwards. Unfortunately, given the best-performing configuration from
Section 5.1.2 (
,
), PCA plots succumb to a crowding issue that is only resolved for inferior models which yield lower AUC values. Likewise, PCA seems to be an insufficient evaluation approach. The similar results achieved for bearing 2 are not shown. These findings suggest that evaluating the autoencoder performance solely on PCA or t-SNE visualizations of the latent vector may not be sufficient to fully judge the performance of the trained model. Hence, different performance metrics have to be evaluated in the future.
5.2. Self-Supervised HI Generation
In this section, we evaluate the proposed self-supervised HI generation. This model estimates the device’s health over time while relying on weak labeled data to optimize the network parameters. However, as discussed in
Section 5.1.1, suitable initial fault methods are supposed to achieve a similar weak labeling capability as an expert-based evaluation. Therefore, the self-supervised HI generation is first analyzed using data labeled by human experts. Note that using expert-based labels in this context suffers from partly subjective human judgment, as the results of different experts may vary slightly. Therefore, in the second part of this section, we investigate how variations in the detection time of the initial fault affect the HI classification task.
5.2.1. Results Using Expert-Based Initial Fault Detection
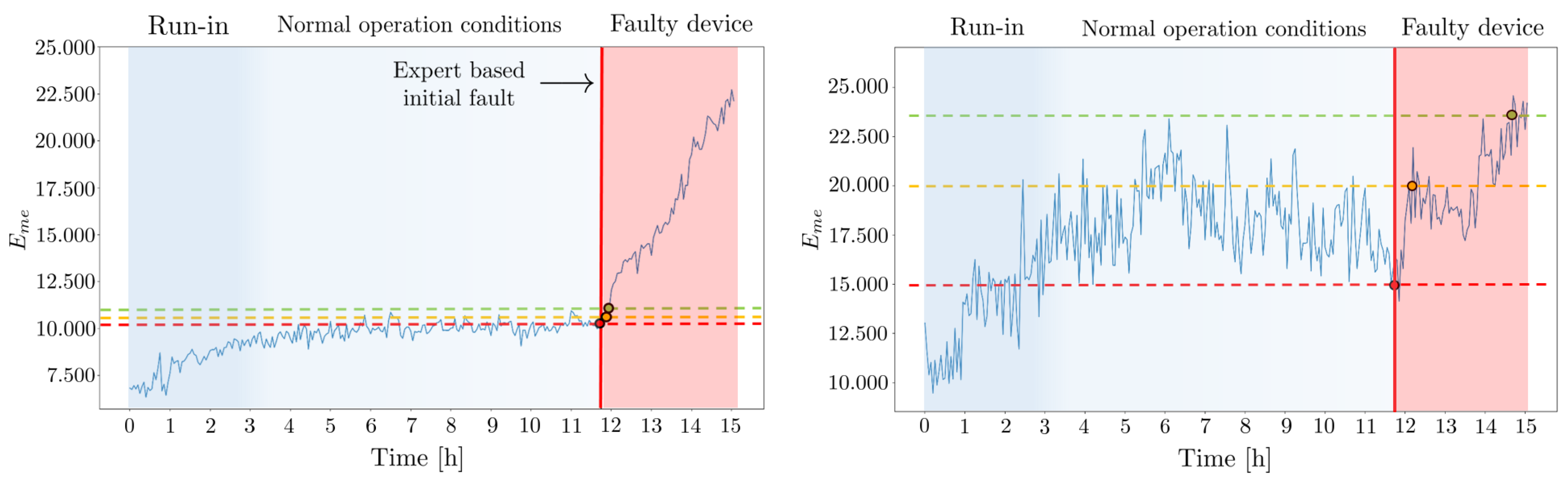
In this part of our research, we delve into the outcomes of our model, operating under the assumption that the quality of the weakly labeled data equals that of a human expert. The trained model, illustrated in
Figure 6, proceeds to classify the current health status of the bearing into two categories: ‘functional’ and ‘faulty’. Subsequently, we evaluate the classification probability of the functional class over time, yielding our proposed health index (HI) curve for our device. The results of this approach, as applied to both bearing 1 and bearing 2, are presented in
Figure 13.
The HI curves produced by our self-supervised method exhibit the desired coherent trend behavior in both of our bearing test-to-failure experiments. The model predicts both bearings to be in a healthy condition initially and faulty, mirroring the expert ground truth, after 12 h of run-time. To produce this ground truth, the expert reviewed the data by conducting an envelope spectrum analysis, a standard method for bearing evaluation. To us, this comparison to a human baseline seems conclusive since human evaluation is still one of the most common practices in the industry. In comparison to the results of the unsupervised learning methods depicted in
Figure 10, the model does not suffer from transient run-in-related effects due to our self-supervised setting. In addition, the model appears to experience increasing uncertainty over time, as reflected in the classification probability beginning to progressively fluctuate. To quantify this loss of conviction, we calculate the running standard deviation (RSD) of the network decision probabilities for the available
M test-to-failure measurements in the dataset over time:
hence for a given time instant
all classification probability outputs
of the network are considered for the calculation of the running standard deviation. The RSD steadily increases over time, indicating a continuous reduction in the model’s confidence that the provided measurements belong to the ‘functional’ class. This observation suggests that our model can successfully capture gradual wear-induced changes in the device prior to the initial fault reported by a human expert envelope spectrum analysis. This capability was not achievable with previous unsupervised methods. Nevertheless, similar to unsupervised approaches, the RSD curve yields an increased slope after approximately 12 h of run-time, which corresponds to the time the initial fault was determined by the human expert.The initial fault is indicated by the red horizontal line in
Figure 13.
Similar to the classification probability evaluation, the RSD curves of the self-supervised classifier produced coherent trends for both of our test-to-failure runs. Hence, it might be reasonable to study the use of this model uncertainty measure in terms of self-supervised HI-based RUL prediction in future work.
5.2.2. Impact of Non-Ideal Initial Fault Detection
In the preceding analysis, we operated under the assumption that the quality of the weakly labeled data equaled that of a human expert. However, in real-world scenarios, our unsupervised initial fault detection may not produce labeling results closely aligned with human evaluations. Furthermore, subjective human judgment can lead to slightly different baselines. Hence, it is important to investigate the impact of varying the initial fault times on classifier performance.
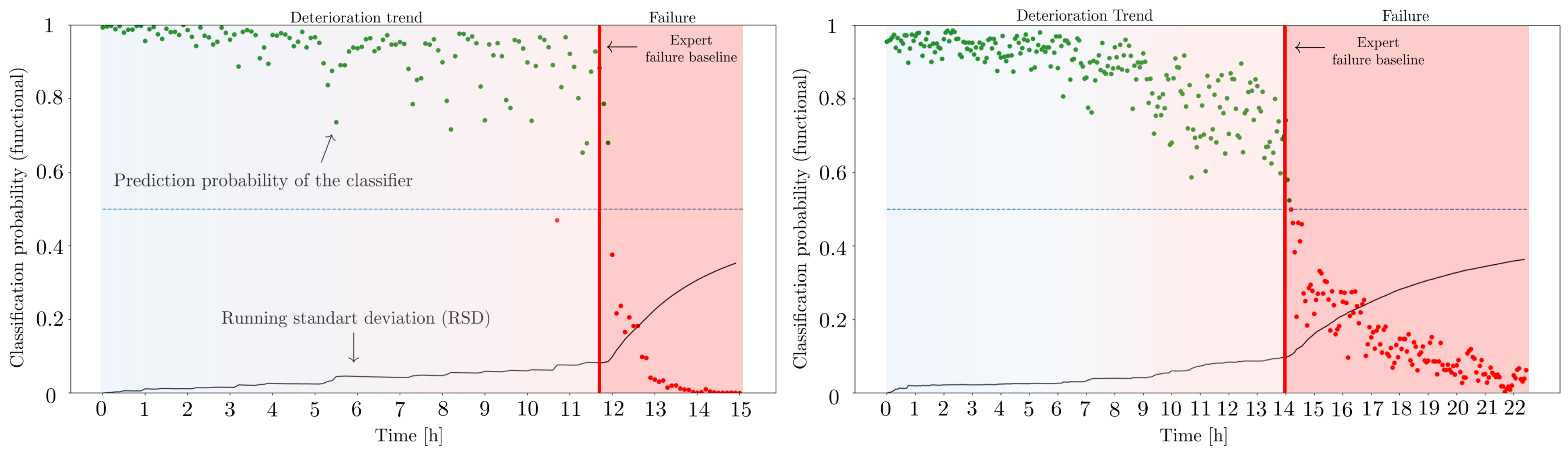
To examine this effect, we manually adjusted the labeling threshold for the data, shifting it by up to 15 measurements in either direction around the expert-based decision at shift 0. Subsequently, we employed each newly labeled dataset to train the classifier, following a procedure similar to the previous experiment. Additionally, for each shift, we repeated the training 20 times with different initialization seeds. Considering that our data are recorded at intervals of 10 min (for bearing 1) or 5 min (for bearing 2), the results encompass a time range of 150 to 300 min around the initial fault point determined by the expert, respectively. The results presented in
Figure 14 suggest that the classifier’s performance reaches its peak for positive shifts in comparison to the human expert baseline (shift 0). This indicates the positive effect of a later initial fault choice in improving the quality of weak labels. Consequently, the labels provided by the human expert can be considered as a rather conservative estimation of failure.
However, it is noteworthy that all examined shift values yield average classification results exceeding 97% (bearing 1) and 93% (bearing 2). Hence, a slightly earlier or delayed initial fault timing appears to have minimal impact on the self-supervised classifier’s performance.
5.3. Implications, Limitations, and Outlook
In our previous investigations above, we demonstrated several important findings: Firstly, self-supervised learning is capable of generating coherent health index (HI) trends. Secondly, CNN-autoencoders surpass LSTM-autoencoders in creating the weakly labeled data necessary for this process. Finally, we showed that the self-supervised HI can detect wear in the device earlier than human expert analysis and examined how imperfect labeling affects the performance of the self-supervised HI in a bearing test-to-failure scenario. In our study, a shift of up to 300 min had only a minimal effect on the model performance.
Our method, as currently understood, has the potential for application in a variety of scenarios where devices undergo gradual wear, not just in mechanical transmissions. This opens up possibilities for more precise wear monitoring and Remaining Useful Life (RUL) prediction in numerous predictive maintenance situations. However, our testing to date has been limited to a bearing test-to-failure scenario within a controlled environment. The effects of sudden environmental changes on the algorithm’s performance, such as noise interference from nearby machines in sound-based sensor systems, are yet to be explored. Furthermore, the influence of different operational conditions, like varying rotational speeds, on the method’s effectiveness remains to be determined. Consequently, there is a need for further research to extend our findings to different types of bearings, sizes, and devices, enabling the practical application of our method.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}