
Weakly-Supervised Video Anomaly Detection with MTDA-Net

 , , ,
, , ,
Abstract
:1. Introduction
- We propose a simple and effective anomaly detection network MTDA-Net, which can explicitly leverage the relations between different video frames and learn discriminative features based on these relations.
- We construct a new plug-and-play MTDA module, which consists of three branches that complement each other in terms of features and achieves fine-grained context enhancement via feature fusion.
- We achieve competitive results on the XD-Violence dataset with our model and conduct detailed ablation experiments to explore the effects of different parts of the model.
2. Related Work
2.1. Supervised and Semi-Supervised Anomaly Detection
2.2. Weakly Supervised Anomaly Detection
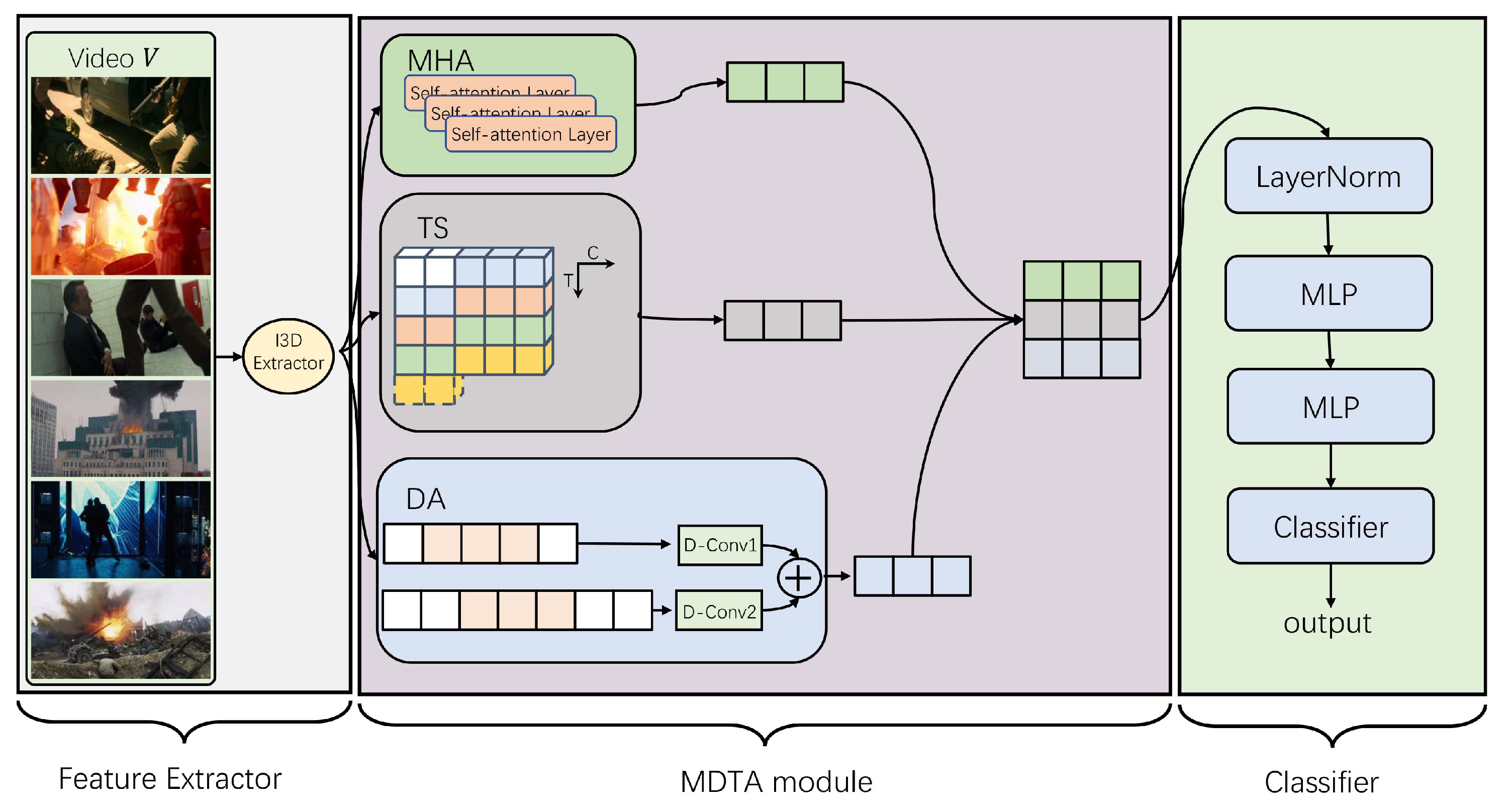
3. Methods
3.1. Notations and Preliminaries
3.2. MTDA Module
3.3. Training Based on MIL
4. Experiments
4.1. Data Sets and Evaluation Measure
4.2. Implementation Details
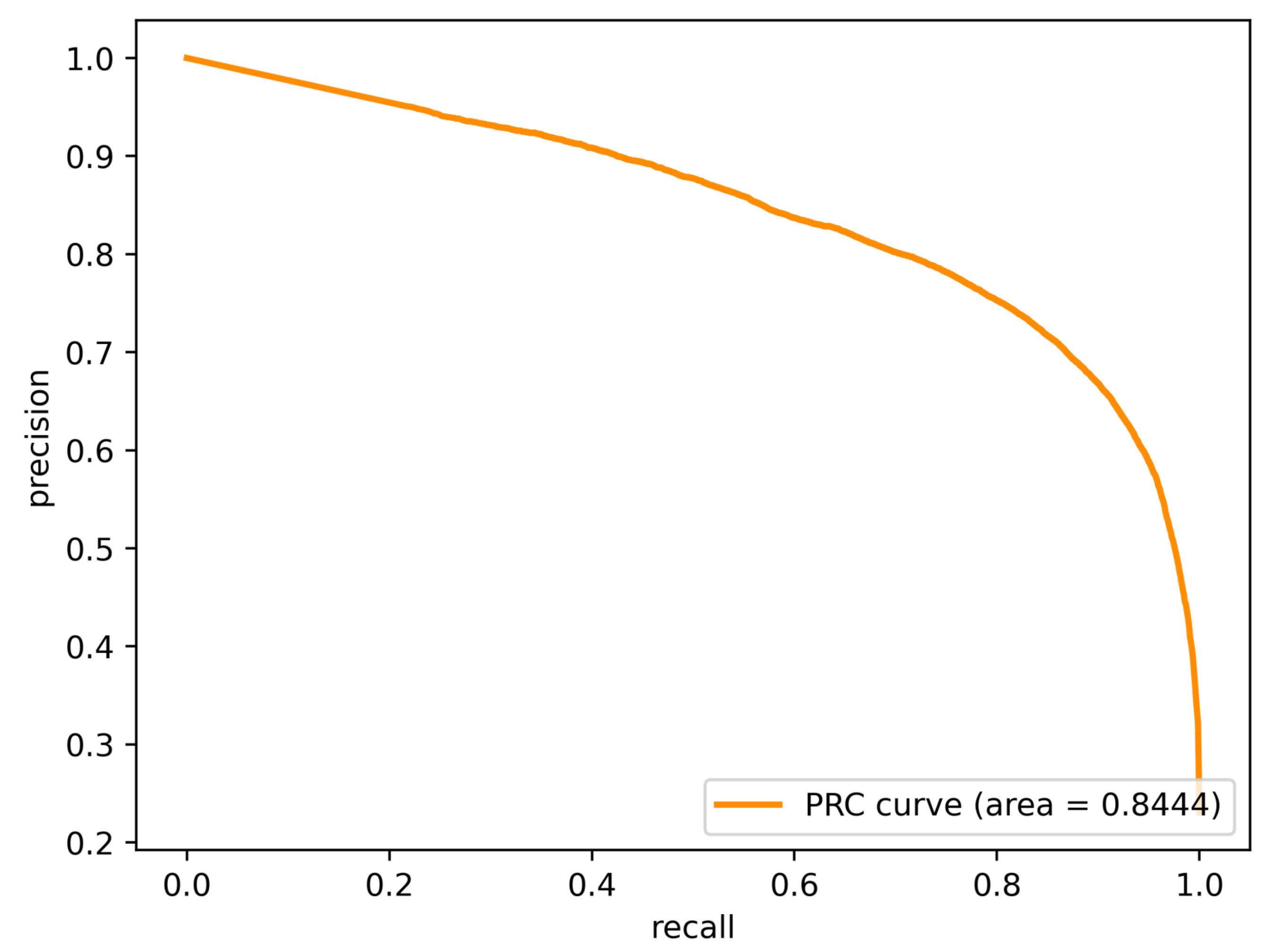
4.3. Results on XD-Violence
- Multiple instance learning ranking (MIL-Rank) [6] framework by leveraging weakly labeled training videos.
- Holistic and localized network (HL-Net) [11] that explicitly exploits relations of snippets and learns powerful representations.
- Robust Temporal Feature Magnitude learning (RTFM) [13] trains a feature magnitude learning function to effectively recognize the positive instances, substantially improving the robustness of the MIL approach to the negative instances from abnormal videos.
- Causal Temporal Relation and Feature Discrimination (CRFD) [26] consists of four modules to leverage the effect of the temporal cue and feature discrimination.
- Normality Guided Multiple Instance Learning (NG-MIL) [39] framework encodes diverse normal patterns from noise-free normal videos into prototypes for constructing a similarity-based classifier.
- Self-supervised sparse representation (S3R) [40] framework models the concept of the anomaly at the feature level by exploring the synergy between dictionary-based representation and self-supervised learning.
- Discriminative Dynamics Learning (DDL) [30] method have two objective functions, i.e., dynamics ranking loss and dynamics alignment loss.
- Uncertainty Regulated Dual Memory Units (UR-DMU) [25] model can learn both the representations of normal data and discriminative features of abnormal data.
- Modality-aware contrastive instance learning with self-distillation (MACIL-SD) [12] focuses on the modality’s heterogeneousness.
- Contrastive Attention Video Anomaly Detection (CA-VAD) [41] fully utilizes enough normal videos to train a classifier with a good discriminative ability for normal videos.
- Multi-Sequence Learning (MSL) [42] uses a sequence composed of multiple snippets as an optimization unit.
4.4. Ablation Studies
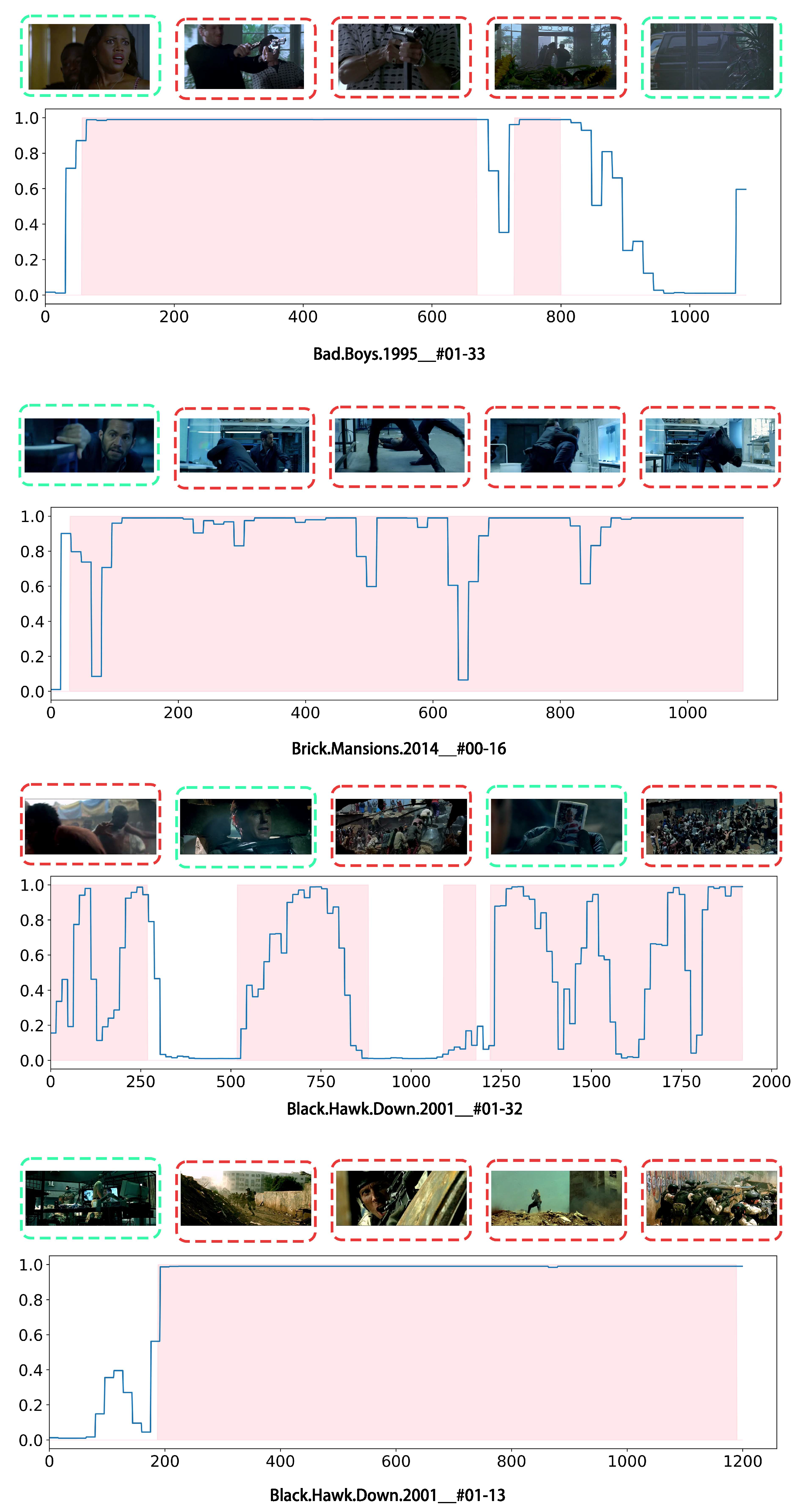
4.5. Qualitative Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republich of Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Feichtenhofer, C. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 203–213. [Google Scholar]
- Fu, W.; An, Z.; Huang, W.; Sun, H.; Gong, W.; Gonzàlez, J. A Spatio-Temporal Spotting Network with Sliding Windows for Micro-Expression Detection. Electronics 2023, 12, 3947. [Google Scholar] [CrossRef]
- Al-Dhamari, A.; Sudirman, R.; Mahmood, N.H.; Khamis, N.H.; Yahya, A. Online video-based abnormal detection using highly motion techniques and statistical measures. TELKOMNIKA (Telecommun. Comput. Electron. Control) 2019, 17, 2039–2047. [Google Scholar] [CrossRef]
- Antić, B.; Ommer, B. Video parsing for abnormality detection. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2415–2422. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Wang, L.; Zhou, F.; Li, Z.; Zuo, W.; Tan, H. Abnormal event detection in videos using hybrid spatio-temporal autoencoder. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2276–2280. [Google Scholar]
- Smeureanu, S.; Ionescu, R.T.; Popescu, M.; Alexe, B. Deep appearance features for abnormal behavior detection in video. In Proceedings of the Image Analysis and Processing-ICIAP 2017: 19th International Conference, Catania, Italy, 11–15 September 2017; Part II 19. Springer: Berlin/Heidelberg, Germany, 2017; pp. 779–789. [Google Scholar]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Ganomaly: Semi-supervised anomaly detection via adversarial training. In Proceedings of the Computer Vision—ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part III 14. Springer: Berlin/Heidelberg, Germany, 2018; pp. 622–637. [Google Scholar]
- Demarty, C.H.; Penet, C.; Soleymani, M.; Gravier, G. VSD, a public dataset for the detection of violent scenes in movies: Design, annotation, analysis and evaluation. Multimed. Tools Appl. 2015, 74, 7379–7404. [Google Scholar] [CrossRef]
- Wu, P.; Liu, J.; Shi, Y.; Sun, Y.; Shao, F.; Wu, Z.; Yang, Z. Not only look, but also listen: Learning multimodal violence detection under weak supervision. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XXX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 322–339. [Google Scholar]
- Yu, J.; Liu, J.; Cheng, Y.; Feng, R.; Zhang, Y. Modality-aware contrastive instance learning with self-distillation for weakly-supervised audio-visual violence detection. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 6278–6287. [Google Scholar]
- Tian, Y.; Pang, G.; Chen, Y.; Singh, R.; Verjans, J.W.; Carneiro, G. Weakly-supervised video anomaly detection with robust temporal feature magnitude learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4975–4986. [Google Scholar]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks for action segmentation and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 156–165. [Google Scholar]
- Farha, Y.A.; Gall, J. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3575–3584. [Google Scholar]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S.W. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6836–6846. [Google Scholar]
- Lee, S.; Kim, H.G.; Ro, Y.M. BMAN: Bidirectional multi-scale aggregation networks for abnormal event detection. IEEE Trans. Image Process. 2019, 29, 2395–2408. [Google Scholar] [CrossRef] [PubMed]
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 935–942. [Google Scholar]
- Zhao, B.; Fei-Fei, L.; Xing, E.P. Online detection of unusual events in videos via dynamic sparse coding. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3313–3320. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 fps in matlab. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Li, W.; Mahadevan, V.; Vasconcelos, N. Anomaly detection and localization in crowded scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 18–32. [Google Scholar]
- Ruff, L.; Vandermeulen, R.A.; Görnitz, N.; Binder, A.; Müller, E.; Müller, K.R.; Kloft, M. Deep semi-supervised anomaly detection. arXiv 2019, arXiv:1906.02694. [Google Scholar]
- Pu, Y.; Wu, X. Audio-guided attention network for weakly supervised violence detection. In Proceedings of the 2022 2nd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 14–16 January 2022; pp. 219–223. [Google Scholar]
- Zhou, H.; Yu, J.; Yang, W. Dual Memory Units with Uncertainty Regulation for Weakly Supervised Video Anomaly Detection. arXiv 2023, arXiv:2302.05160. [Google Scholar] [CrossRef]
- Wu, P.; Liu, J. Learning causal temporal relation and feature discrimination for anomaly detection. IEEE Trans. Image Process. 2021, 30, 3513–3527. [Google Scholar] [CrossRef] [PubMed]
- Pu, Y.; Wu, X.; Wang, S. Learning Prompt-Enhanced Context Features for Weakly-Supervised Video Anomaly Detection. arXiv 2023, arXiv:2306.14451. [Google Scholar]
- Zhu, Y.; Newsam, S. Motion-aware feature for improved video anomaly detection. arXiv 2019, arXiv:1907.10211. [Google Scholar]
- Zhong, J.X.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1237–1246. [Google Scholar]
- Pu, Y.; Wu, X. Locality-Aware Attention Network with Discriminative Dynamics Learning for Weakly Supervised Anomaly Detection. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? In A new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lv, H.; Zhou, C.; Cui, Z.; Xu, C.; Li, Y.; Yang, J. Localizing anomalies from weakly-labeled videos. IEEE Trans. Image Process. 2021, 30, 4505–4515. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Qing, L.; Miao, J. Temporal convolutional network with complementary inner bag loss for weakly supervised anomaly detection. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4030–4034. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Paul, S.; Roy, S.; Roy-Chowdhury, A.K. W-talc: Weakly-supervised temporal activity localization and classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 563–579. [Google Scholar]
- Perez, M.; Kot, A.C.; Rocha, A. Detection of real-world fights in surveillance videos. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2662–2666. [Google Scholar]
- Park, S.; Kim, H.; Kim, M.; Kim, D.; Sohn, K. Normality Guided Multiple Instance Learning for Weakly Supervised Video Anomaly Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 2665–2674. [Google Scholar]
- Wu, J.C.; Hsieh, H.Y.; Chen, D.J.; Fuh, C.S.; Liu, T.L. Self-supervised sparse representation for video anomaly detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 729–745. [Google Scholar]
- Chang, S.; Li, Y.; Shen, S.; Feng, J.; Zhou, Z. Contrastive attention for video anomaly detection. IEEE Trans. Multimed. 2021, 24, 4067–4076. [Google Scholar] [CrossRef]
- Li, S.; Liu, F.; Jiao, L. Self-training multi-sequence learning with transformer for weakly supervised video anomaly detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 1395–1403. [Google Scholar]
- Zhang, C.; Li, G.; Qi, Y.; Wang, S.; Qing, L.; Huang, Q.; Yang, M.H. Exploiting Completeness and Uncertainty of Pseudo Labels for Weakly Supervised Video Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16271–16280. [Google Scholar]
- Schölkopf, B.; Williamson, R.C.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support vector method for novelty detection. In Proceedings of the 12th International Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Supervision | Method | Feature | AP (%) |
|---|---|---|---|
| Unsupervised | SVM baseline | - | 50.78 |
| OCSVM [44] | - | 27.25 | |
| Hasan et al. [45] | - | 30.77 | |
| Weakly Supervised | MIL-Rank [6] | C3D RGB | 73.20 |
| HL-Net [11] | I3D RGB | 75.44 | |
| CA-VAD [41] | I3D RGB | 76.90 | |
| RTFM [13] | I3D RGB | 77.81 | |
| CRFD [26] | I3D RGB | 75.90 | |
| MSL [42] | I3D RGB | 78.28 | |
| NG-MIL [39] | I3D RGB | 78.51 | |
| S3R [40] | I3D RGB | 80.26 | |
| DDL [30] | I3D RGB | 80.72 | |
| Zhang et al. [43] | I3D+VGGish | 81.43 | |
| UR-DMU [25] | I3D RGB | 81.66 | |
| MACIL-SD [12] | I3D+VGGish | 83.40 | |
| Ours | I3D+VGGish | 84.44 |
| Baseline | MHA | TS | DA | XD-Violence AP (%) |
|---|---|---|---|---|
| ✔ | ✘ | ✘ | ✘ | 74.84 |
| ✔ | ✔ | ✘ | ✘ | 79.63 |
| ✔ | ✘ | ✔ | ✘ | 78.06 |
| ✔ | ✘ | ✘ | ✔ | 80.2 |
| ✔ | ✔ | ✔ | ✘ | 82.58 |
| ✔ | ✔ | ✘ | ✔ | 83.43 |
| ✔ | ✘ | ✔ | ✔ | 80.86 |
| ✔ | ✔ | ✔ | ✔ | 84.44 |
| D-Conv1 | D-Conv2 | XD-Violence AP (%) |
|---|---|---|
| 83.66 | ||
| 0.1 | 0.9 | 82.85 |
| 0.3 | 0.7 | 82.15 |
| 0.7 | 0.3 | 83.79 |
| 0.9 | 0.1 | 83.80 |
| 0.5 | 0.5 | 84.44 |
| Right | Left | XD-Violence AP (%) |
|---|---|---|
| ✔ | ✘ | 83.30 |
| ✘ | ✔ | 83.74 |
| ✔ | ✔ | 84.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Yang, M.; Wei, F.; Shi, G.; Jiang, W.; Qiao, Y.; Dong, H. Weakly-Supervised Video Anomaly Detection with MTDA-Net. Electronics 2023, 12, 4623. https://doi.org/10.3390/electronics12224623
Wu H, Yang M, Wei F, Shi G, Jiang W, Qiao Y, Dong H. Weakly-Supervised Video Anomaly Detection with MTDA-Net. Electronics. 2023; 12(22):4623. https://doi.org/10.3390/electronics12224623
Chicago/Turabian StyleWu, Huixin, Mengfan Yang, Fupeng Wei, Ge Shi, Wei Jiang, Yaqiong Qiao, and Hangcheng Dong. 2023. "Weakly-Supervised Video Anomaly Detection with MTDA-Net" Electronics 12, no. 22: 4623. https://doi.org/10.3390/electronics12224623
APA StyleWu, H., Yang, M., Wei, F., Shi, G., Jiang, W., Qiao, Y., & Dong, H. (2023). Weakly-Supervised Video Anomaly Detection with MTDA-Net. Electronics, 12(22), 4623. https://doi.org/10.3390/electronics12224623