
Enhancing Dimensional Emotion Recognition from Speech through Modulation-Filtered Cochleagram and Parallel Attention Recurrent Network


Abstract
:1. Introduction
- (1)
- We propose a parallel attention recurrent network for dimensional emotion recognition to model multiple temporal dependencies from modulation-filtered cochleagrams at different resolutions.
- (2)
- The results of comprehensive experiments show that the modulation-filtered cochleagram performs better than traditional acoustic-based features and other auditory-based features for valence and arousal prediction.
- (3)
- The proposed method consistently achieves the highest value of concordance correlation coefficient for valence and arousal prediction across different signal-to-noise ratio levels, suggesting that this method is more robust to noise overall.
2. Related Work
2.1. Speech Feature Extraction
2.2. Emotion Recognition Model
3. Research Method
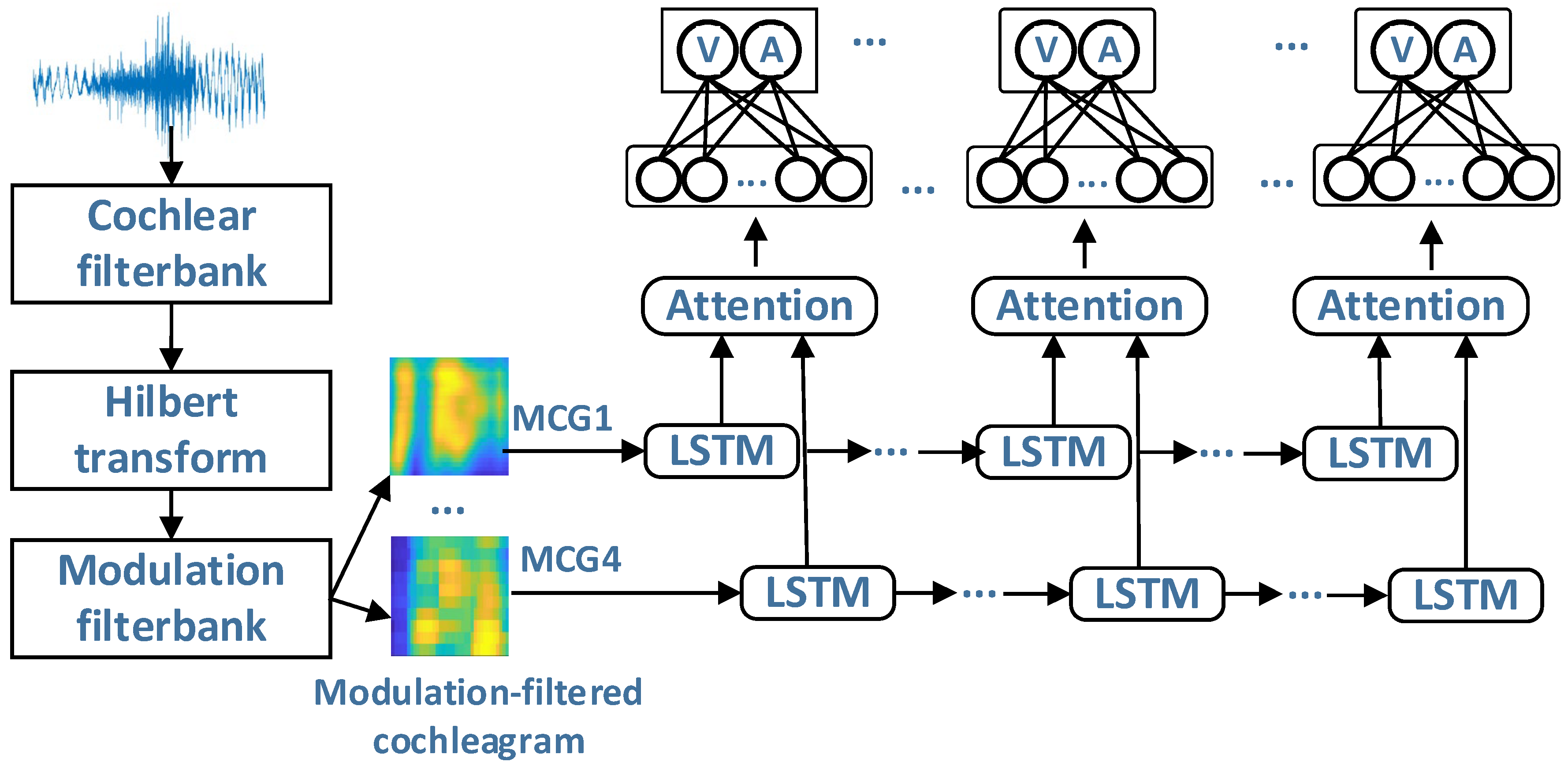
3.1. Overall Structure
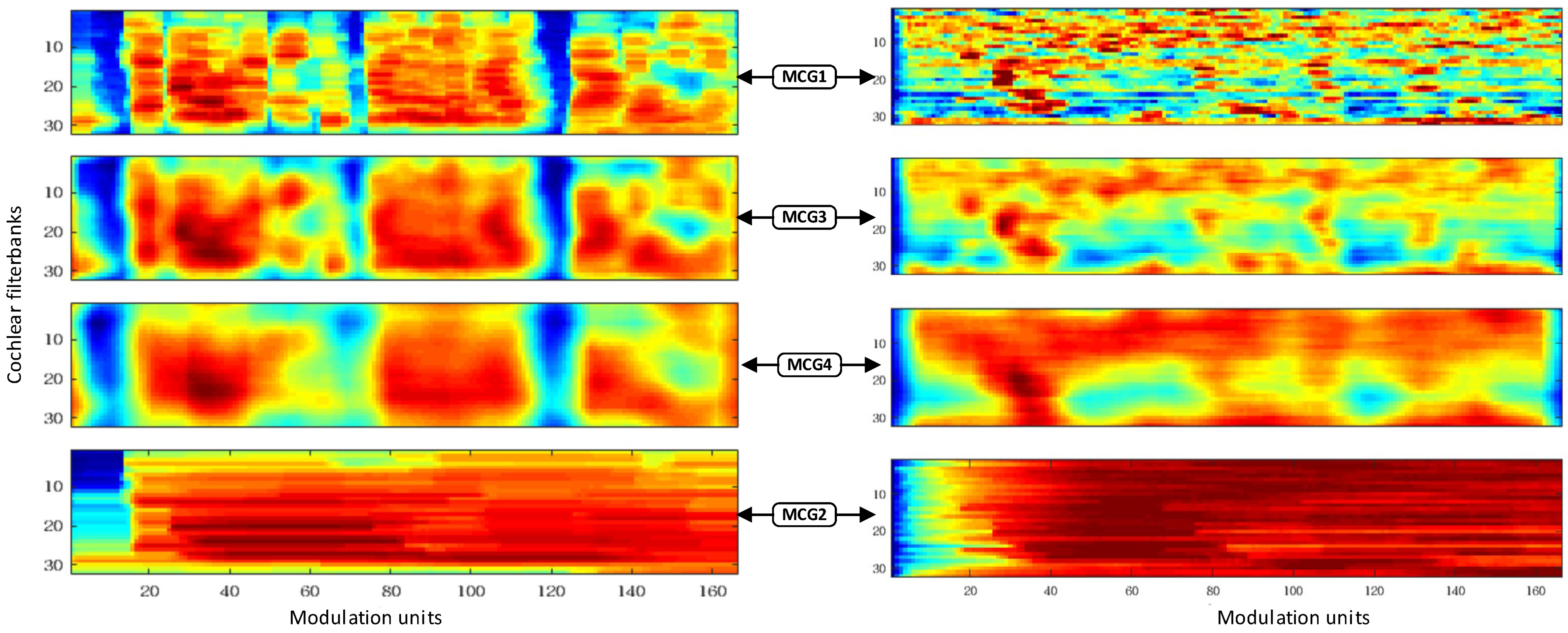
3.2. Multi-Resolution Modulation-Filtered Cochleagram
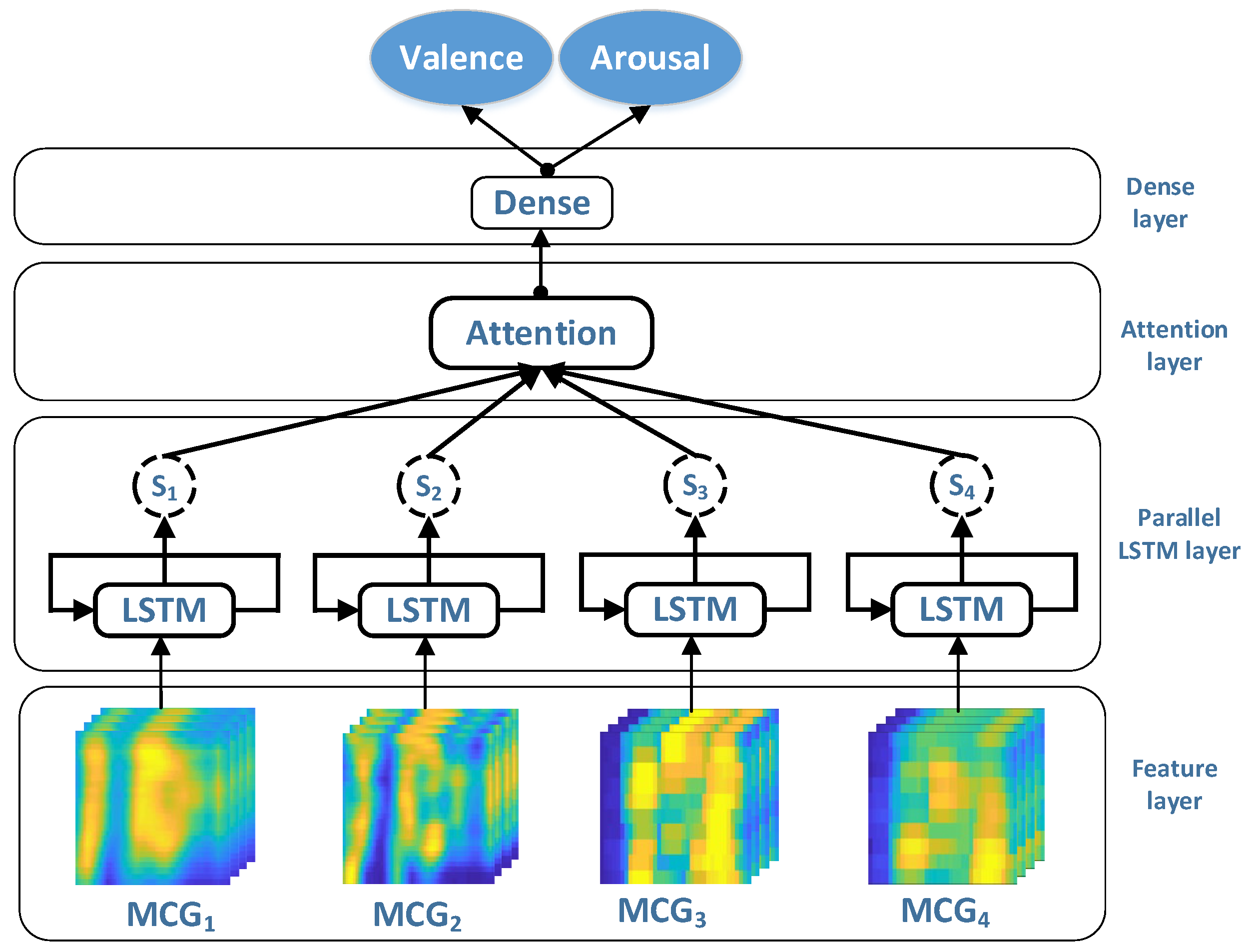
3.3. Parallel Attention Recurrent Network
4. Experimental Results and Analysis
4.1. The Emotional Speech Data
4.2. Multitask Learning and Evaluation Metrics
4.3. Experimental Results
4.3.1. Benchmark Experiments
4.3.2. Noise Environment Valence and Arousal Prediction
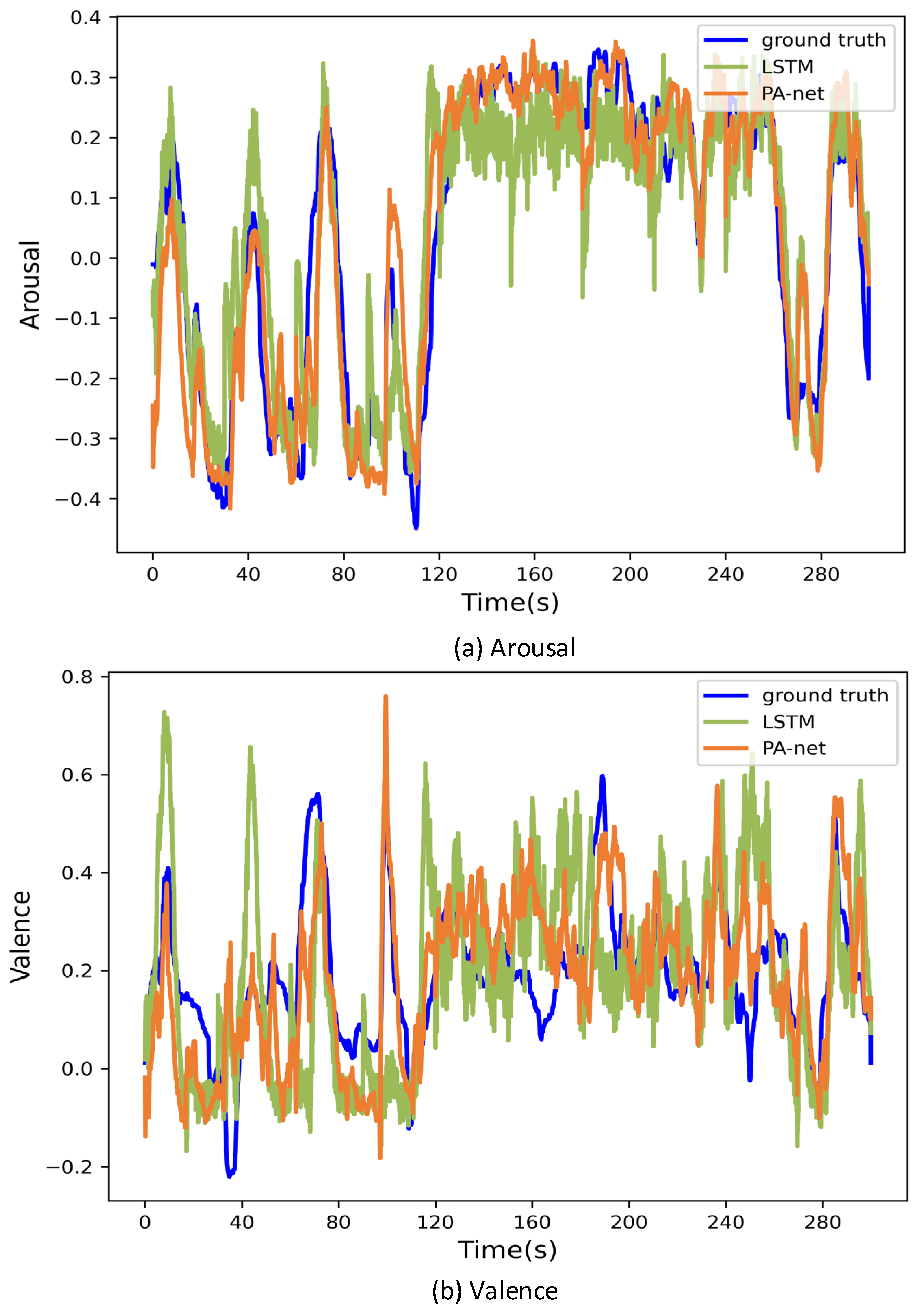
4.3.3. Valence and Arousal Prediction Based on PA-Net
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACNN | Attentive convolutional neural network |
| ARNN | Attention-based recurrent neural network |
| ASRNN | Attention-based sliding recurrent neural network |
| BLSTM | Bidirectional LSTM |
| CCC | Concordance correlation coefficient |
| CNN | Convolutional neural network |
| CRNN | Convolutional and recurrent neural network |
| eGeMAPS | Extended version of Geneva Minimalistic Acoustic Parameter Set |
| HSF | High-level statistics function |
| HRI | Human–robot interaction |
| IC | Inferior colliculus |
| IHC | Inner hair cells |
| LLD | Low-level descriptors |
| LSTM | Long short-term memory |
| MFCC | Mel frequency cepstral coefficient |
| MCG | Modulation-filtered cochleagram |
| MMCG | Multi-resolution modulation-filtered cochleagram |
| MRCG | Multi-resolution cochleagram |
| MSF | Modulation spectral feature |
| RNN | Recurrent neural network |
| PA-net | Parallel attention recurrent network |
| RECOLA | Remote collaborative and affective interactions |
| SEWA | Sentiment analysis in the wild |
| SNR | Signal-to-noise ratio |
References
- Li, H.F.; Chen, J.; Ma, L.; Bo, H.J.; Xu, C.; Li, H.W. Dimensional speech emotion recognition review. Ruan Jian Xue Bao J. Softw. 2020, 31, 2465–2491. [Google Scholar] [CrossRef]
- Peng, Z.; Dang, J.; Unoki, M.; Akagi, M. Multi-resolution modulation-filtered cochleagram feature for LSTM-based dimensional emotion recognition from speech. Neural Netw. 2021, 140, 261–273. [Google Scholar] [CrossRef]
- Mencattini, A.; Martinelli, E.; Ringeval, F.; Schuller, B.; Di Natale, C. Continuous Estimation of Emotions in Speech by Dynamic Cooperative Speaker Models. IEEE Trans. Affect. Comput. 2017, 8, 314–327. [Google Scholar] [CrossRef]
- Chen, S. Multi-modal Dimensional Emotion Recognition using Recurrent Neural Networks. In Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge, Brisbane, Australia, 26–30 October 2015; pp. 49–56. [Google Scholar]
- Drullman, R. Temporal envelope and fine structure cues for speech intelligibility. J. Acoust. Soc. Am. 1995, 97, 585–592. [Google Scholar] [CrossRef]
- Atlas, L.; Shamma, S.A. Joint Acoustic and Modulation Frequency. EURASIP J. Appl. Signal Process. 2003, 668–675. [Google Scholar] [CrossRef]
- Unoki, M.; Zhu, Z. Relationship between contributions of temporal amplitude envelope of speech and modulation transfer function in room acoustics to perception of noise-vocoded speech. Acoust. Sci. Technol. 2020, 41, 233–244. [Google Scholar] [CrossRef]
- Zhu, Z.; Miyauchi, R.; Araki, Y.; Unoki, M. Contribution of modulation spectral features on the perception of vocal-emotion using noise-vocoded speech. Acoust. Sci. Technol. 2018, 39, 379–386. [Google Scholar] [CrossRef]
- Peng, Z.; Zhu, Z.; Unoki, M.; Dang, J.; Akagi, M. Dimensional Emotion Recognition from Speech Using Modulation Spectral Features and Recurrent Neural Networks. In Proceedings of the 11th Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 524–528. [Google Scholar]
- Chi, T.; Ru, P.; Shamma, S.A. Multiresolution spectrotemporal analysis of complex sounds. J. Acoust. Soc. Am. 2005, 118, 887–906. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Y.; Wang, D. A feature study for classification-based speech separation at low signal-to-noise ratios. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1993–2002. [Google Scholar] [CrossRef]
- Mao, Q.; Dong, M.; Huang, Z.; Zhan, Y. Learning Salient Features for Speech Emotion Recognition Using Convolutional Neural Networks. IEEE Trans. Multimed. 2014, 16, 2203–2213. [Google Scholar] [CrossRef]
- Keren, G.; Schuller, B. Convolutional RNN: An enhanced model for extracting features from sequential data. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3412–3419. [Google Scholar] [CrossRef]
- Satt, A.; Rozenberg, S.; Hoory, R. Efficient emotion recognition from speech using deep learning on spectrograms. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20-24 August 2017; pp. 1089–1093. [Google Scholar]
- Tzirakis, P.; Zhang, J.; Schuller, B.W. End-to-end speech emotion recognition using deep neural networks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5089–5093. [Google Scholar]
- Fan, J.; Zhang, K.; Huang, Y.; Zhu, Y.; Chen, B. Parallel spatio-temporal attention-based TCN for multivariate time series prediction. Neural Comput. Appl. 2023, 35, 13109–13118. [Google Scholar] [CrossRef]
- Chen, S.; Jin, Q.; Zhao, J.; Wang, S. Multimodal multi-task learning for dimensional and continuous emotion recognition. In Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, Mountain View, CA, USA, 23–27 October 2017; pp. 19–26. [Google Scholar]
- Huang, J.; Li, Y.; Tao, J.; Lian, Z.; Wen, Z.; Yang, M.; Yi, J. Continuous multimodal emotion prediction based on long short term memory recurrent neural network. In Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, Mountain View, CA, USA, 23–27 October 2017; pp. 11–18. [Google Scholar]
- Zang, T.; Zhu, Y.; Zhu, J.; Xu, Y.; Liu, H. MPAN: Multi-parallel attention network for session-based recommendation. Neurocomputing 2022, 471, 230–241. [Google Scholar] [CrossRef]
- Fu, B.; Yang, Y.; Ma, Y.; Hao, J.; Chen, S.; Liu, S.; Li, T.; Liao, Z.; Zhu, X. Attention-Based Recurrent Multi-Channel Neural Network for Influenza Epidemic Prediction. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 1245–1248. [Google Scholar] [CrossRef]
- Xu, M.; Zhang, F.; Cui, X.; Zhang, W. Speech Emotion Recognition with Multiscale Area Attention and Data Augmentation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6319–6323. [Google Scholar] [CrossRef]
- Zhang, T.; Li, S.; Chen, B.; Yuan, H.; Chen, C.L.P. AIA-Net: Adaptive Interactive Attention Network for Text–Audio Emotion Recognition. IEEE Trans. Cybern. 2022, 1–13. [Google Scholar] [CrossRef] [PubMed]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Atmaja, B.T.; Akagi, M. Two-stage dimensional emotion recognition by fusing predictions of acoustic and text networks using SVM. Speech Commun. 2020, 126, 9–21. [Google Scholar] [CrossRef]
- Dau, T.; Kollmeier, B.; Kohlrausch, A. Modeling auditory processing of amplitude modulation. II. Spectral and temporal integration. J. Acoust. Soc. Am. 1997, 102, 2906–2919. [Google Scholar] [CrossRef]
- McDermott, J.H.; Simoncelli, E.P. Sound Texture Perception via Statistics of the Auditory Periphery: Evidence from Sound Synthesis. Neuron 2011, 71, 926–940. [Google Scholar] [CrossRef]
- Zhu, Z.; Miyauchi, R.; Araki, Y.; Unoki, M. Contributions of temporal cue on the perception of speaker individuality and vocal emotion for noise-vocoded speech. Acoust. Sci. Technol. 2018, 39, 234–242. [Google Scholar] [CrossRef]
- Moritz, N.; Anemuller, J.; Kollmeier, B. An Auditory Inspired Amplitude Modulation Filter Bank for Robust Feature Extraction in Automatic Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 1926–1937. [Google Scholar] [CrossRef]
- Yin, H.; Hohmann, V.; Nadeu, C. Acoustic features for speech recognition based on Gammatone filterbank and instantaneous frequency. Speech Commun. 2011, 53, 707–715. [Google Scholar] [CrossRef]
- Sharan, R.V.; Moir, T.J. Acoustic event recognition using cochleagram image and convolutional neural networks. Appl. Acoust. 2019, 148, 62–66. [Google Scholar] [CrossRef]
- Santoro, R.; Moerel, M.; De Martino, F.; Goebel, R.; Ugurbil, K.; Yacoub, E.; Formisano, E. Encoding of Natural Sounds at Multiple Spectral and Temporal Resolutions in the Human Auditory Cortex. PLOS Comput. Biol. 2014, 10, e1003412. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Nishino, Y.; Miyauchi, R.; Unoki, M. Study on linguistic information and speaker individuality contained in temporal envelope of speech. Acoust. Sci. Technol. 2016, 37, 258–261. [Google Scholar] [CrossRef]
- Wu, S.; Falk, T.H.; Chan, W.-Y. Automatic speech emotion recognition using modulation spectral features. Speech Commun. 2011, 53, 768–785. [Google Scholar] [CrossRef]
- Kshirsagar, S.R.; Falk, T.H. Quality-Aware Bag of Modulation Spectrum Features for Robust Speech Emotion Recognition. IEEE Trans. Affect. Comput. 2022, 13, 1892–1905. [Google Scholar] [CrossRef]
- Zhang, Z.; Ringeval, F.; Han, J.; Deng, J.; Marchi, E.; Schuller, B. Facing realism in spontaneous emotion recognition from speech: Feature enhancement by autoencoder with LSTM neural networks. In Proceedings of the Annual Conference International Speech Communication Association, Interspeech, San Francisco, CA, USA, 8–12-September 2016; pp. 3593–3597. [Google Scholar] [CrossRef]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the 41st IEEE International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar] [CrossRef]
- Wöllmer, M.; Kaiser, M.; Eyben, F.; Schuller, B.; Rigoll, G. LSTM-Modeling of continuous emotions in an audiovisual affect recognition framework. Image Vis. Comput. 2013, 31, 153–163. [Google Scholar] [CrossRef]
- Yang, Z.; Hirschberg, J. Predicting Arousal and Valence from Waveforms and Spectrograms using Deep Neural Networks. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 3092–3096. [Google Scholar]
- Neumann, M.; Vu, N.T. Attentive convolutional neural network based speech emotion recognition: A study on the impact of input features, signal length, and acted speech. In Proceedings of the Interspeech 2017 18th Conference International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 1263–1267. [Google Scholar] [CrossRef]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 40th IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Peng, Z.; Li, X.; Zhu, Z.; Unoki, M.; Dang, J.; Akagi, M. Speech Emotion Recognition Using 3D Convolutions and Attention-Based Sliding Recurrent Networks With Auditory Front-Ends. IEEE Access 2020, 8, 16560–16572. [Google Scholar] [CrossRef]
- Makhmudov, F.; Kutlimuratov, A.; Akhmedov, F.; Abdallah, M.S.; Cho, Y.-I. Modeling Speech Emotion Recognition via Attention-Oriented Parallel CNN Encoders. Electronics 2022, 11, 4047. [Google Scholar] [CrossRef]
- Karnati, M.; Seal, A.; Yazidi, A.; Krejcar, O. FLEPNet: Feature Level Ensemble Parallel Network for Facial Expression Recognition. IEEE Trans. Affect. Comput. 2022, 13, 2058–2070. [Google Scholar] [CrossRef]
- Wagner, J.; Triantafyllopoulos, A.; Wierstorf, H.; Schmitt, M.; Burkhardt, F.; Eyben, F.; Schuller, B.W. Dawn of the Transformer Era in Speech Emotion Recognition: Closing the Valence Gap. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10745–10759. [Google Scholar] [CrossRef]
- Avila, A.R.; Akhtar, Z.; Santos, J.F.; Oshaughnessy, D.; Falk, T.H. Feature Pooling of Modulation Spectrum Features for Improved Speech Emotion Recognition in the Wild. IEEE Trans. Affect. Comput. 2018, 12, 177–188. [Google Scholar] [CrossRef]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013. [Google Scholar] [CrossRef]
- Kossaifi, J.; Walecki, R.; Panagakis, Y.; Shen, J.; Schmitt, M.; Ringeval, F.; Han, J.; Pandit, V.; Toisoul, A.; Schuller, B.W.; et al. SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild. arXiv 2019, arXiv:1901.02839. [Google Scholar] [CrossRef] [PubMed]
- Valstar, M.; Schuller, B.; Smith, K.; Almaev, T.; Eyben, F.; Krajewski, J.; Cowie, R.; Pantic, M. Avec 2016: Depression, mood, and emotion recognition workshop and challenge. In Proceedings of the AVEC 2016—Depression, Mood, and Emotion Recognition Workshop and Challenge, Amsterdam, Netherlands, 15–19 October 2016; pp. 3–10. [Google Scholar] [CrossRef]
- Ringeval, F.; Schuller, B.; Valstar, M.; Gratch, J.; Cowie, R.; Scherer, S.; Mozgai, S.; Cummins, N.; Schmitt, M.; Pantic, P. Avec 2017: Real-life depression, and affect recognition workshop and challenge. In Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, Mountain View, CA, USA, 23–27 October 2017; pp. 3–9. [Google Scholar]
- Ouyang, A.; Dang, T.; Sethu, V.; Ambikairajah, E. Speech based emotion prediction: Can a linear model work? In Proceedings of the Annual Conference of the International Speech Communication Association, Interspeech, Graz, Austria, 15–19 September 2019; pp. 2813–2817. [Google Scholar] [CrossRef]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; Andre, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The Geneva Minimalistic Acoustic Parameter Set (GeMAPS) for Voice Research and Affective Computing. IEEE Trans. Affect. Comput. 2015, 7, 190–202. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, J.; Coutinho, E.; Schuller, B.W. Dynamic Difficulty Awareness Training for Continuous Emotion Prediction. IEEE Trans. Multimed. 2019, 21, 1289–1301. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | SVR | LSTM | ||
|---|---|---|---|---|
| Arousal | Valence | Arousal | Valence | |
| MFCC_LLD | 0.595 | 0.269 | 0.679 | 0.320 |
| MFCC_HSF | 0.606 | 0.305 | 0.651 | 0.331 |
| eGeMAPS_LLD | 0.610 | 0.293 | 0.662 | 0.312 |
| eGeMAPS_HSF | 0.602 | 0.314 | 0.701 | 0.329 |
| MSF | 0.641 | 0.304 | 0.709 | 0.368 |
| MRCG | 0.685 | 0.353 | 0.734 | 0.351 |
| MMCG | 0.694 | 0.371 | 0.742 | 0.362 |
| Feature | 0 dB | 5 dB | 10 dB | 20 dB | ||||
|---|---|---|---|---|---|---|---|---|
| Arousal | Valence | Arousal | Valence | Arousal | Valence | Arousal | Valence | |
| MFCC_HSF | 0.361 | 0.173 | 0.367 | 0.182 | 0.403 | 0.195 | 0.426 | 0.193 |
| eGeMAPS_HSF | 0.403 | 0.202 | 0.421 | 0.196 | 0.446 | 0.201 | 0.451 | 0.203 |
| MSF | 0.594 | 0.252 | 0.548 | 0.266 | 0.478 | 0.318 | 0.574 | 0.226 |
| MRCG | 0.658 | 0.304 | 0.674 | 0.318 | 0.696 | 0.316 | 0.718 | 0.364 |
| MMCG | 0.700 | 0.344 | 0.744 | 0.400 | 0.750 | 0.446 | 0.772 | 0.418 |
| Dataset | Single-Channel LSTM | Multi-Channel LSTM | PA-Net | |||
|---|---|---|---|---|---|---|
| Arousal | Valence | Arousal | Valence | Arousal | Valence | |
| RECOLA | 0.742 | 0.362 | 0.824 | 0.474 | 0.859 | 0.529 |
| SEWA | 0.472 | 0.342 | 0.523 | 0.519 | 0.557 | 0.531 |
| Model | 0 dB | 5 dB | 10 dB | 20 dB | ||||
|---|---|---|---|---|---|---|---|---|
| Arousal | Valence | Arousal | Valence | Arousal | Valence | Arousal | Valence | |
| LSTM | 0.700 | 0.344 | 0.744 | 0.400 | 0.750 | 0.446 | 0.772 | 0.418 |
| PA-net | 0.743 | 0.372 | 0.779 | 0.427 | 0.795 | 0.463 | 0.817 | 0.476 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Z.; Zeng, H.; Li, Y.; Du, Y.; Dang, J. Enhancing Dimensional Emotion Recognition from Speech through Modulation-Filtered Cochleagram and Parallel Attention Recurrent Network. Electronics 2023, 12, 4620. https://doi.org/10.3390/electronics12224620
Peng Z, Zeng H, Li Y, Du Y, Dang J. Enhancing Dimensional Emotion Recognition from Speech through Modulation-Filtered Cochleagram and Parallel Attention Recurrent Network. Electronics. 2023; 12(22):4620. https://doi.org/10.3390/electronics12224620
Chicago/Turabian StylePeng, Zhichao, Hua Zeng, Yongwei Li, Yegang Du, and Jianwu Dang. 2023. "Enhancing Dimensional Emotion Recognition from Speech through Modulation-Filtered Cochleagram and Parallel Attention Recurrent Network" Electronics 12, no. 22: 4620. https://doi.org/10.3390/electronics12224620
APA StylePeng, Z., Zeng, H., Li, Y., Du, Y., & Dang, J. (2023). Enhancing Dimensional Emotion Recognition from Speech through Modulation-Filtered Cochleagram and Parallel Attention Recurrent Network. Electronics, 12(22), 4620. https://doi.org/10.3390/electronics12224620