

Distributed Multi-Agent Approach for Achieving Energy Efficiency and Computational Offloading in MECNs Using Asynchronous Advantage Actor-Critic
 , , ,
, , ,
Abstract
:1. Introduction
1.1. Related Work
1.2. Contribution and Organization
- MECNs are currently exploring a problem related to energy optimization using DRL, which involves selecting the appropriate mode and allocating radio resources. This optimization problem considers various constraints, such as limited computing and radio resources, and quality-of-service requirements for individual user equipment (UE) in a constantly changing wireless environment;
- In order to minimize energy consumption in MECNs, a joint optimization method for mode selection, radio resource allocation, and distributed computing resource allocation is proposed. We modeled the mode selection and resource allocation problem under the Markov decision process (MDP) problem. Due to a large amount of system states and activities in our problem, we used the DRL approach, which employs a DNN as a function approximator to predict value functions. We implemented the fixed target network and experience replay technique to ensure a stable training process. In order to allocate the optimal number of computing resources, we utilized the greedy algorithm;
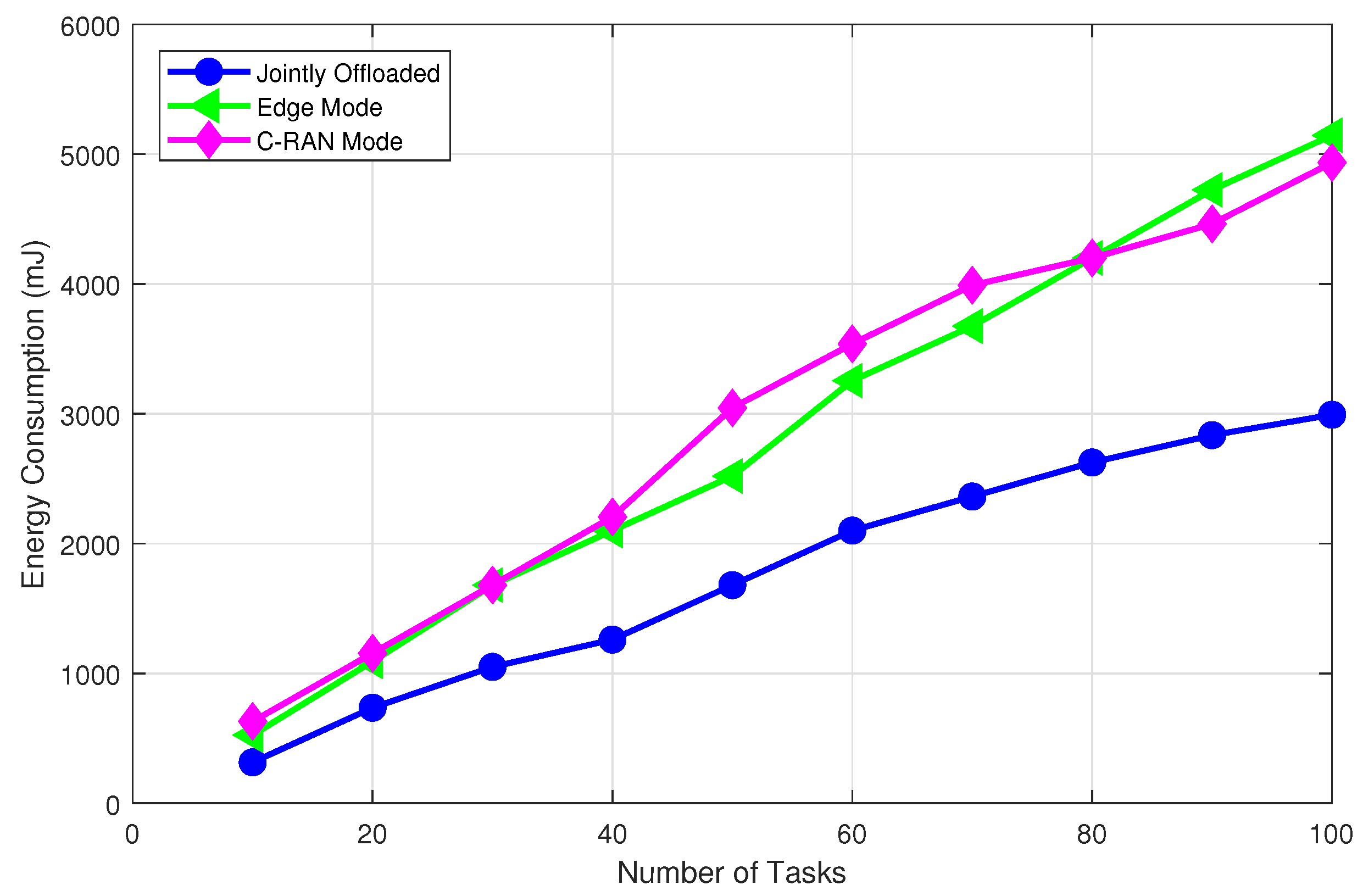
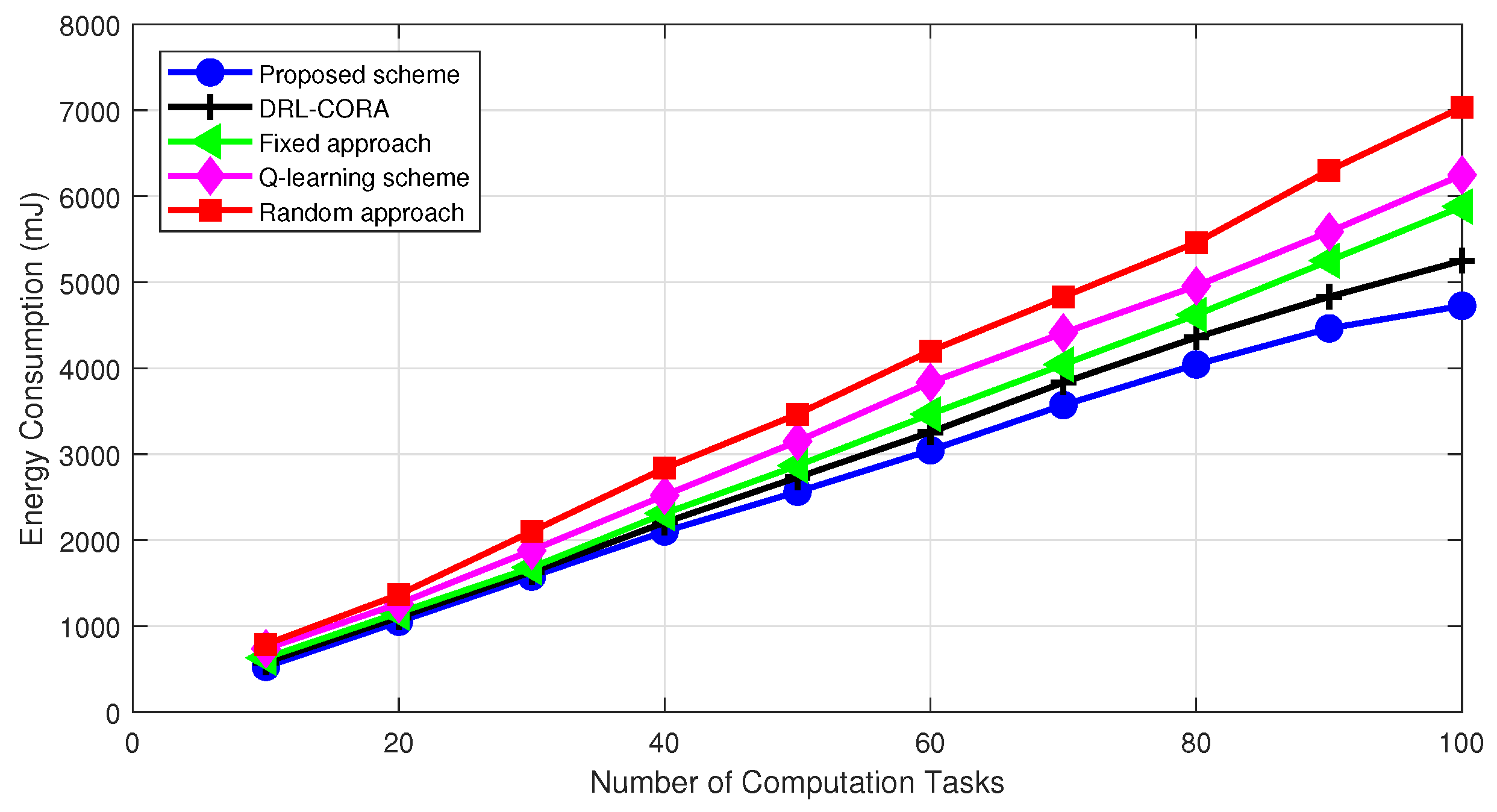
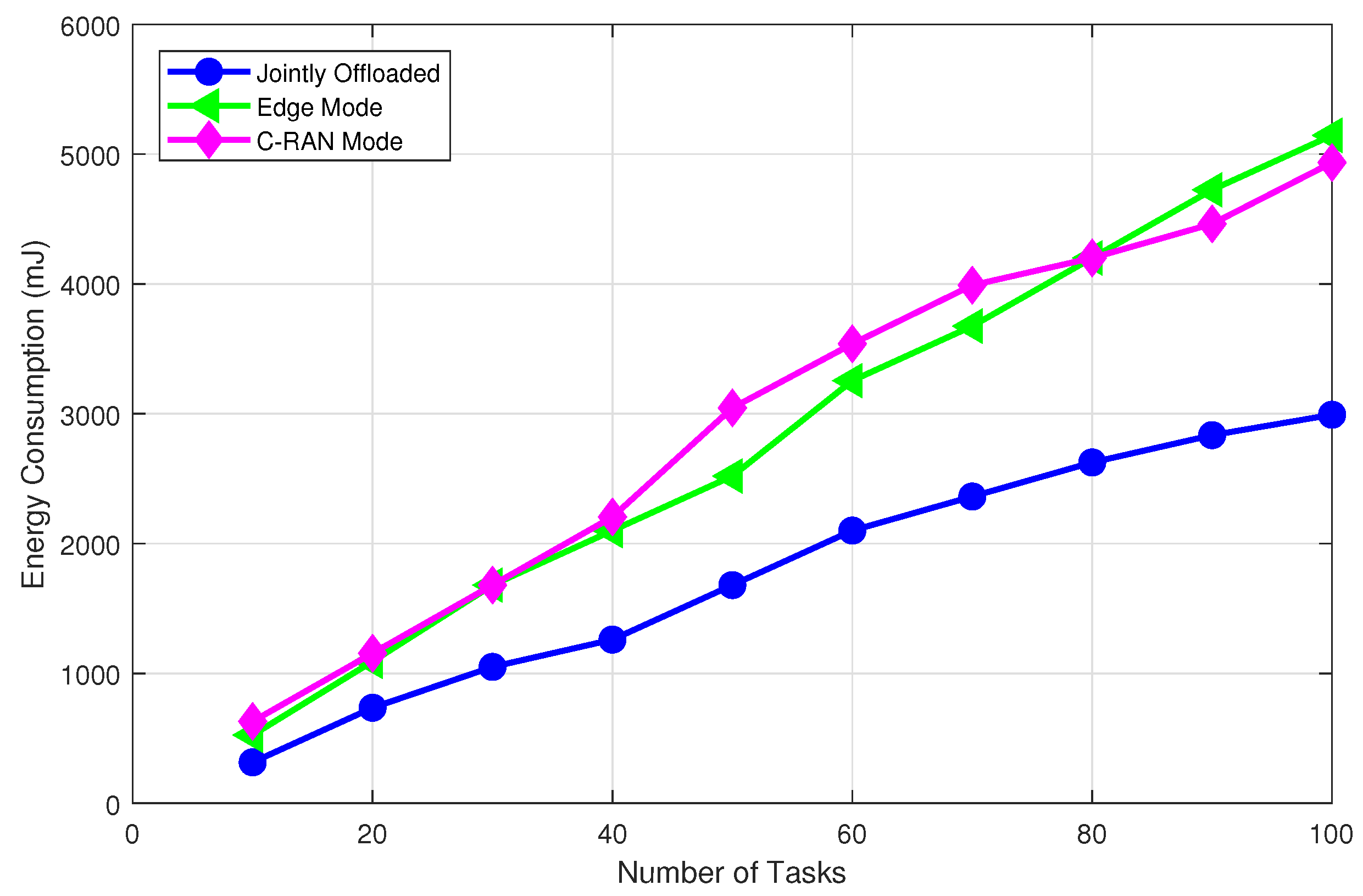
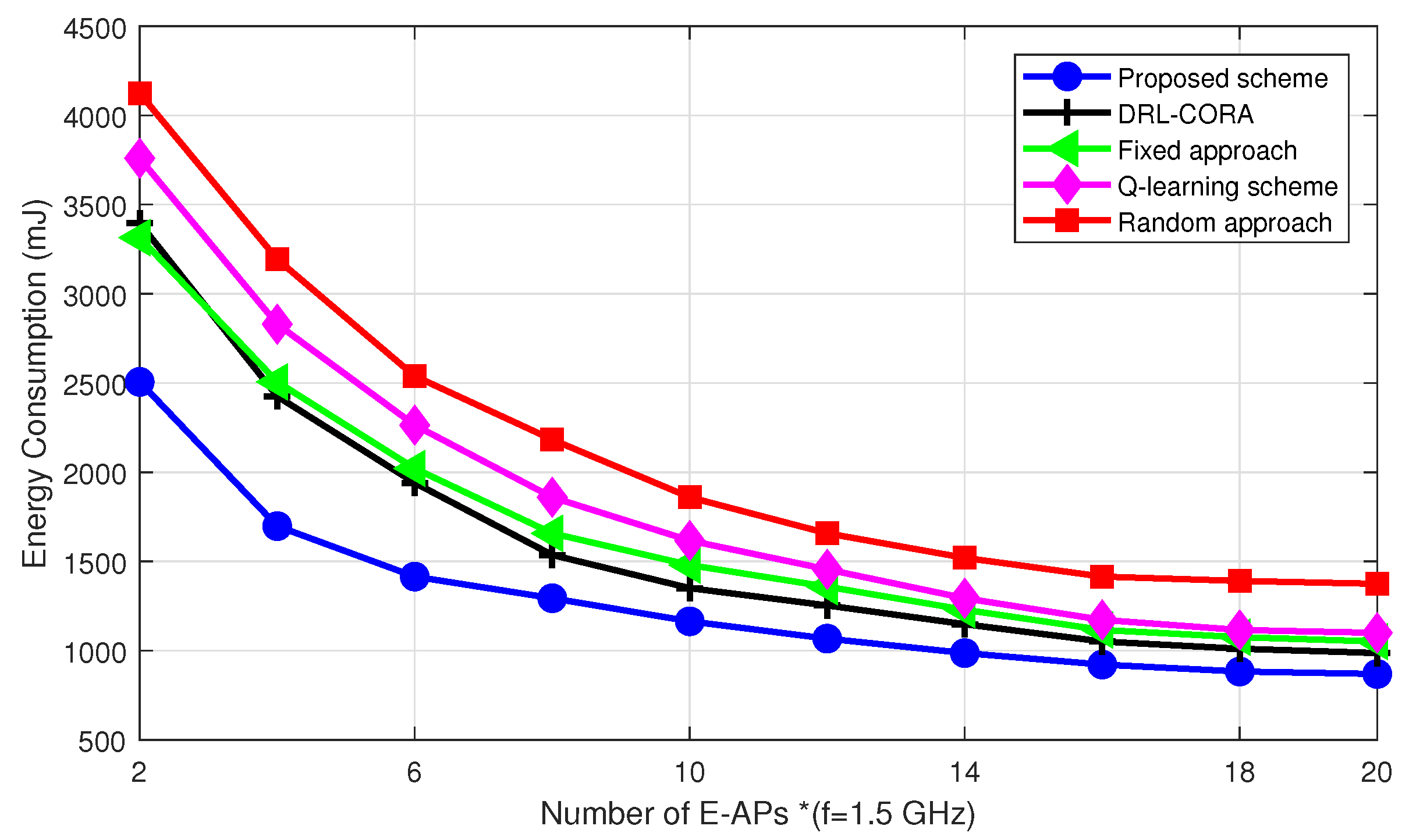
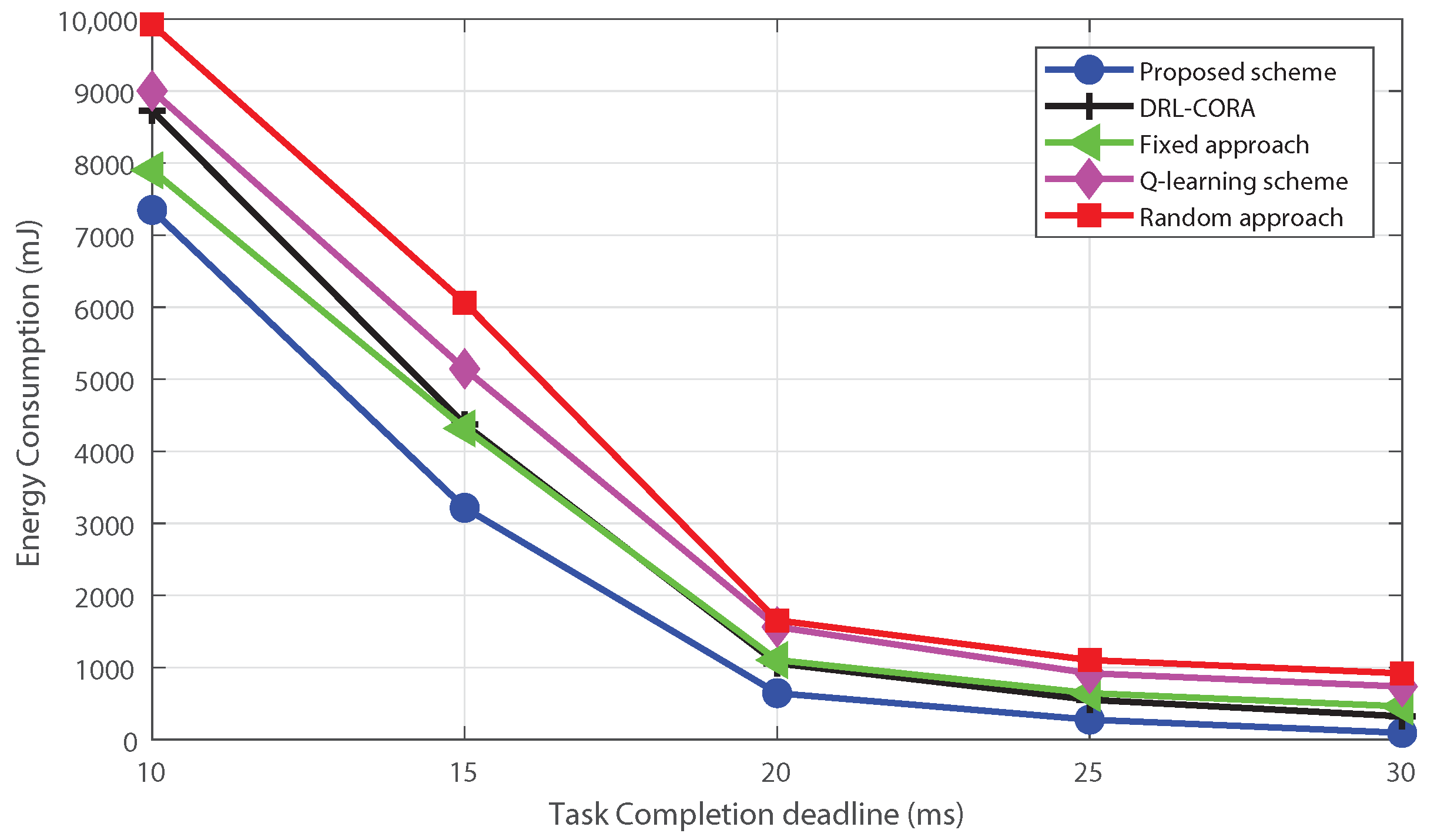
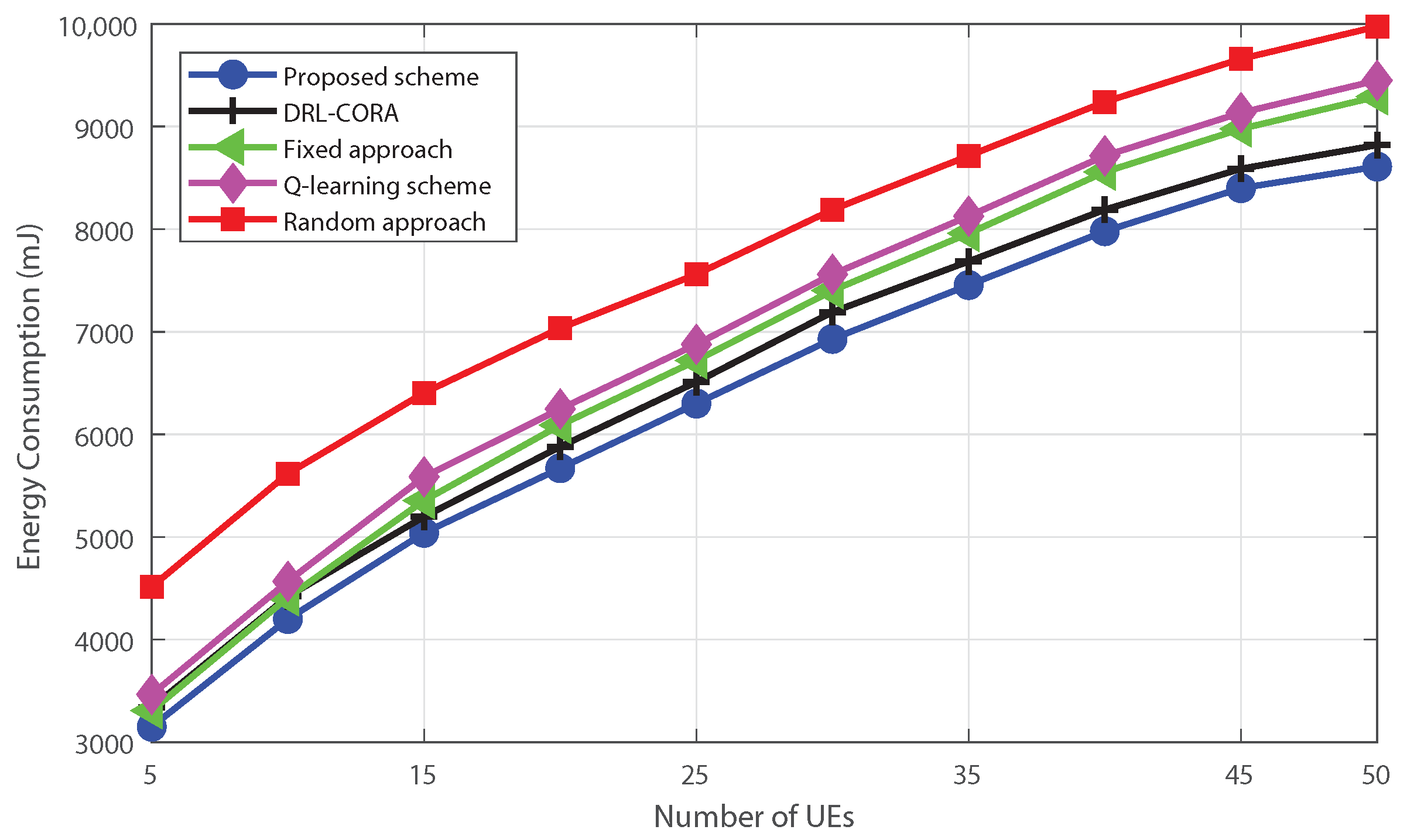
- Extensive simulation results demonstrate that the proposed DRL-based offloading and radio resource allocation mechanism can achieve a stable state very quickly and performs well in terms of energy efficiency in MECNs, while computing resource allocation is handled separately with a greedy algorithm. The proposed approach demonstrates better performance when compared to Q-learning, fixed and random approaches, and partial resource allocation schemes.
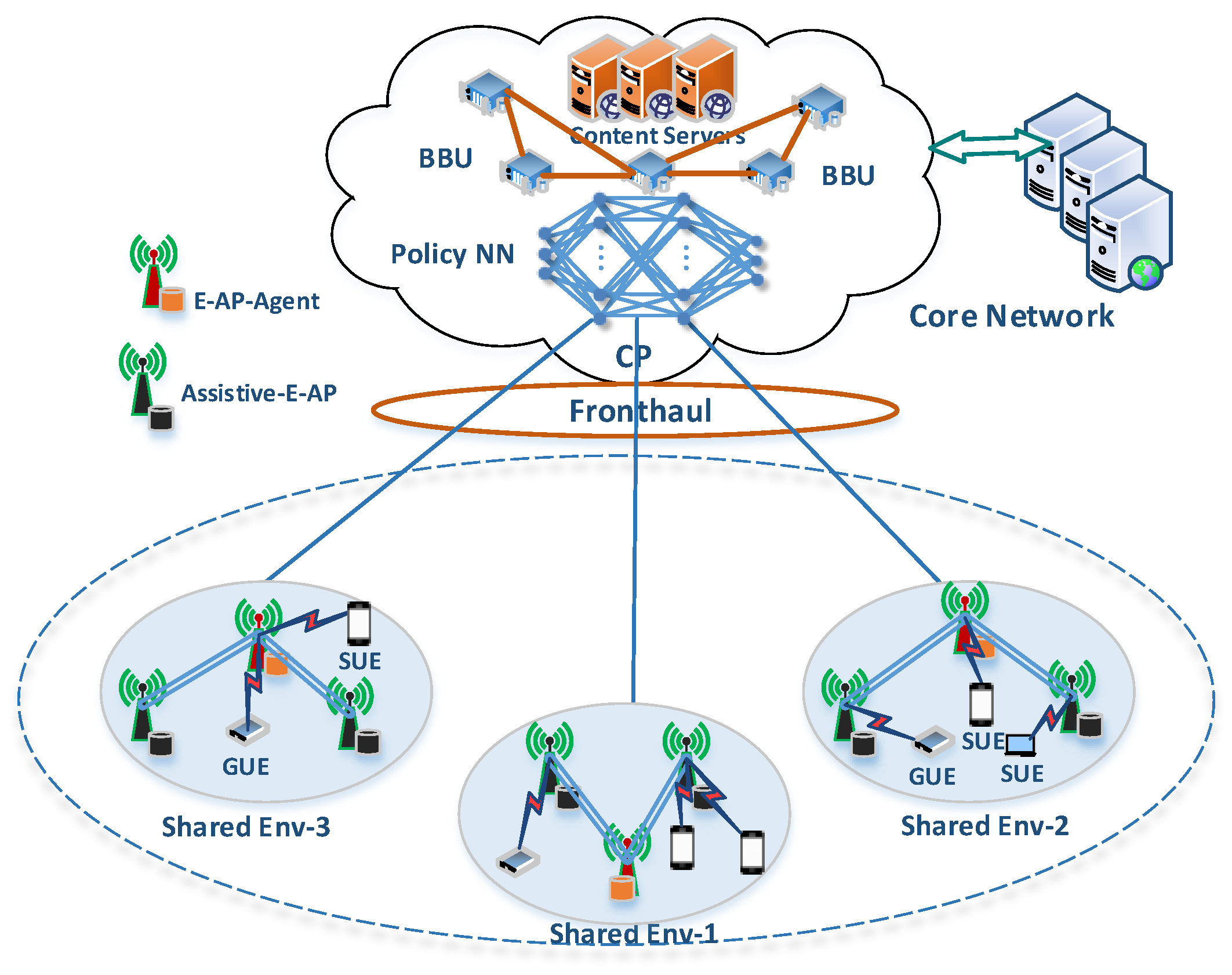
2. System Model
2.1. Task Model
2.2. Cache Model
2.3. Communication Model
2.4. Computation Model
2.4.1. Local Execution
2.4.2. Edge Execution
2.4.3. Cloud Execution
3. Problem Statement
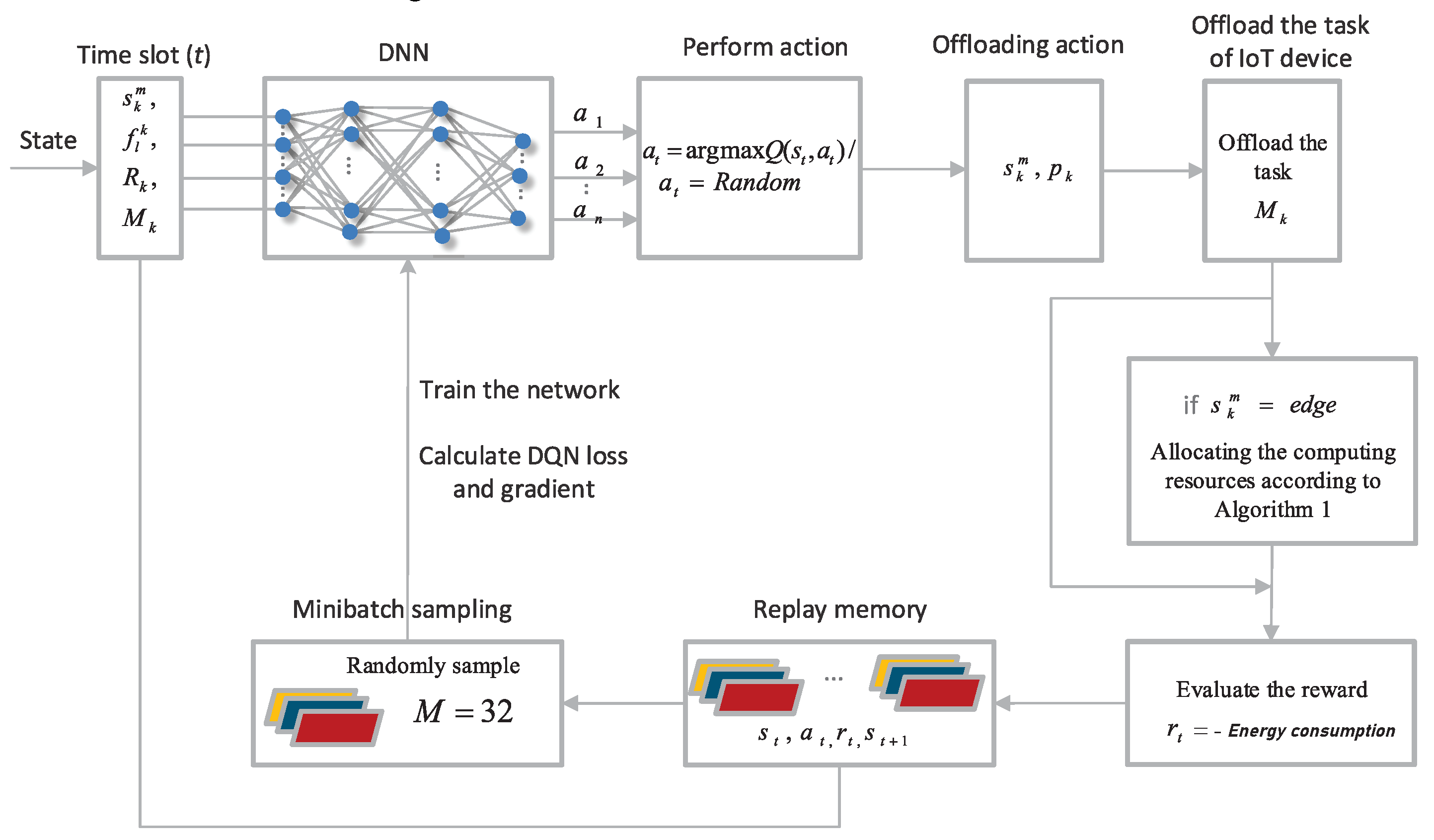
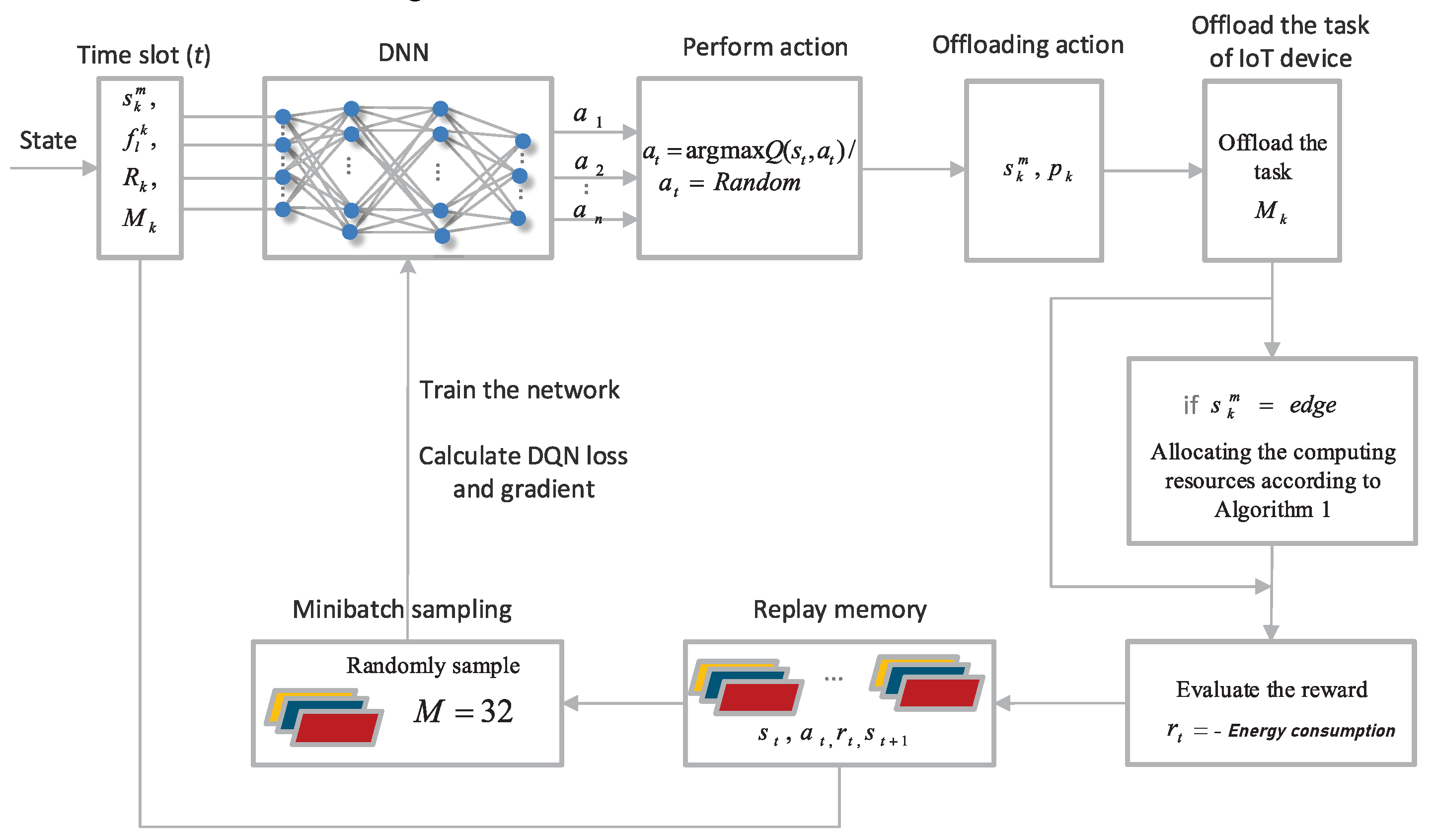
4. Distributed Computation Offloading and Resource Allocation
4.1. Computation Offloading Is Modeled as a DRL Problem
4.1.1. State Space
4.1.2. Action Space
4.1.3. Reward Function
4.2. Distributed Computing Resource Allocation
| Algorithm 1 A3C Algorithm for Distributed Computation |
|
4.3. DRL-Based Offloading
| Algorithm 2 DRL Algorithm for Computing Offloading in E-RAN |
|
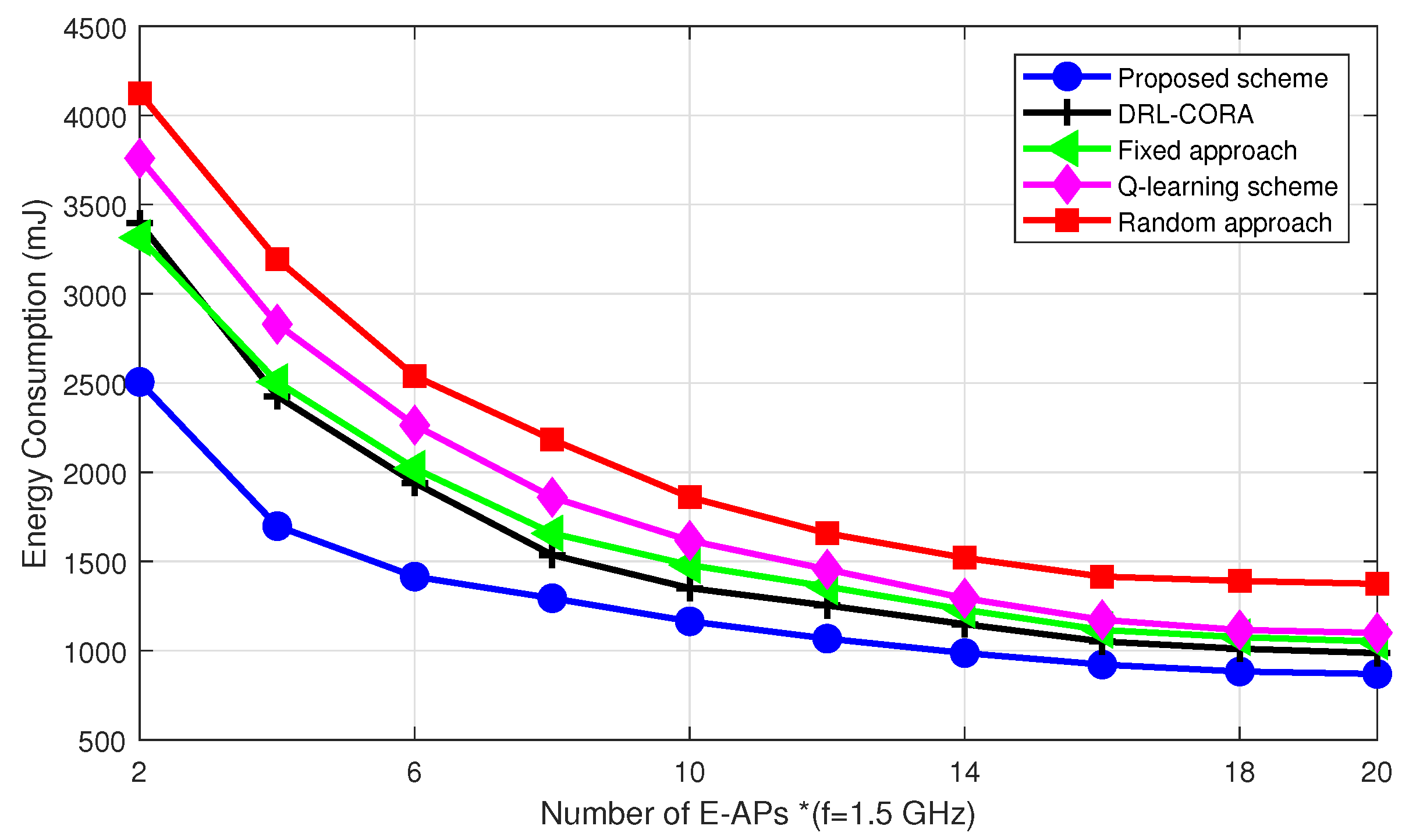
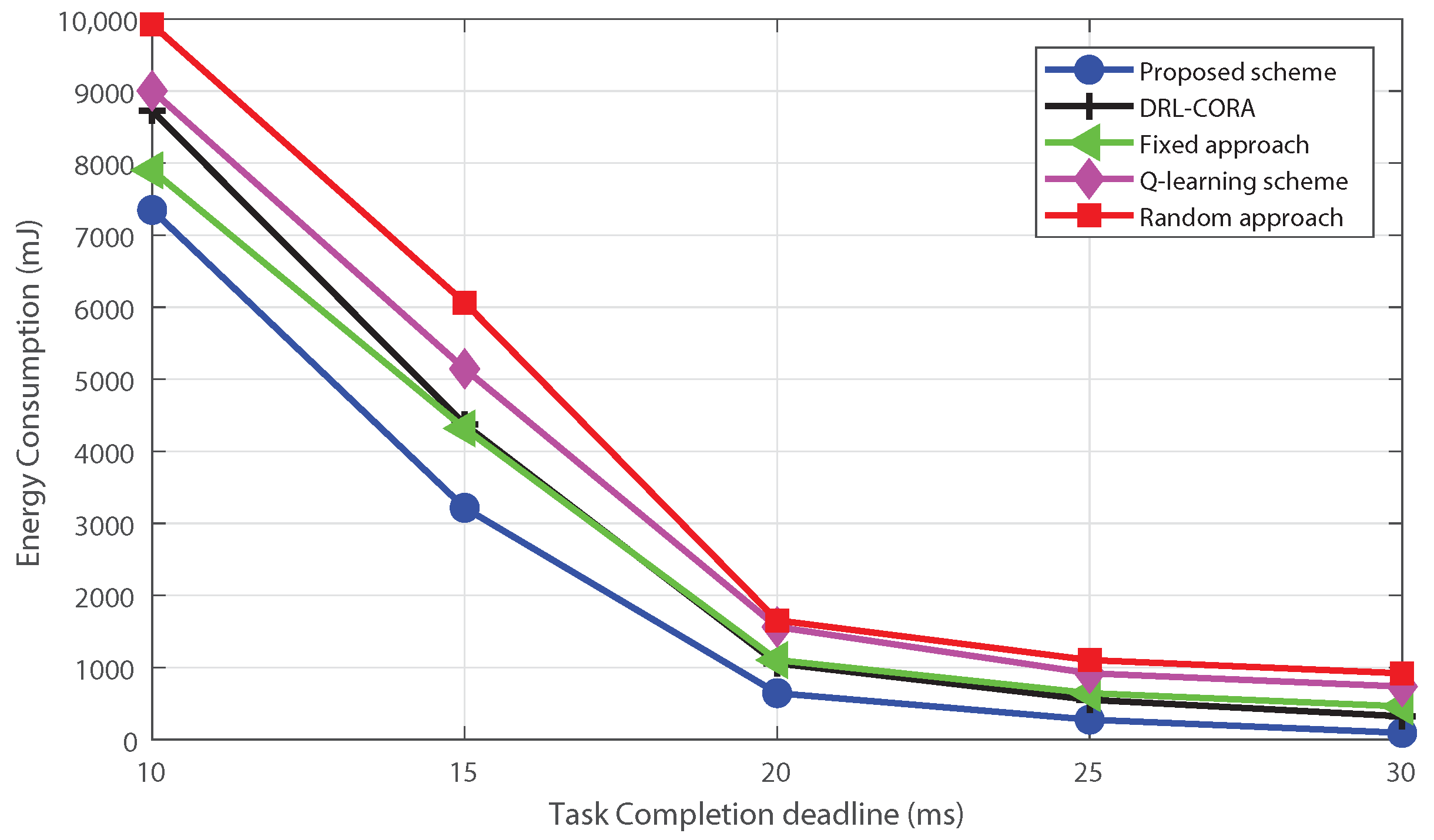
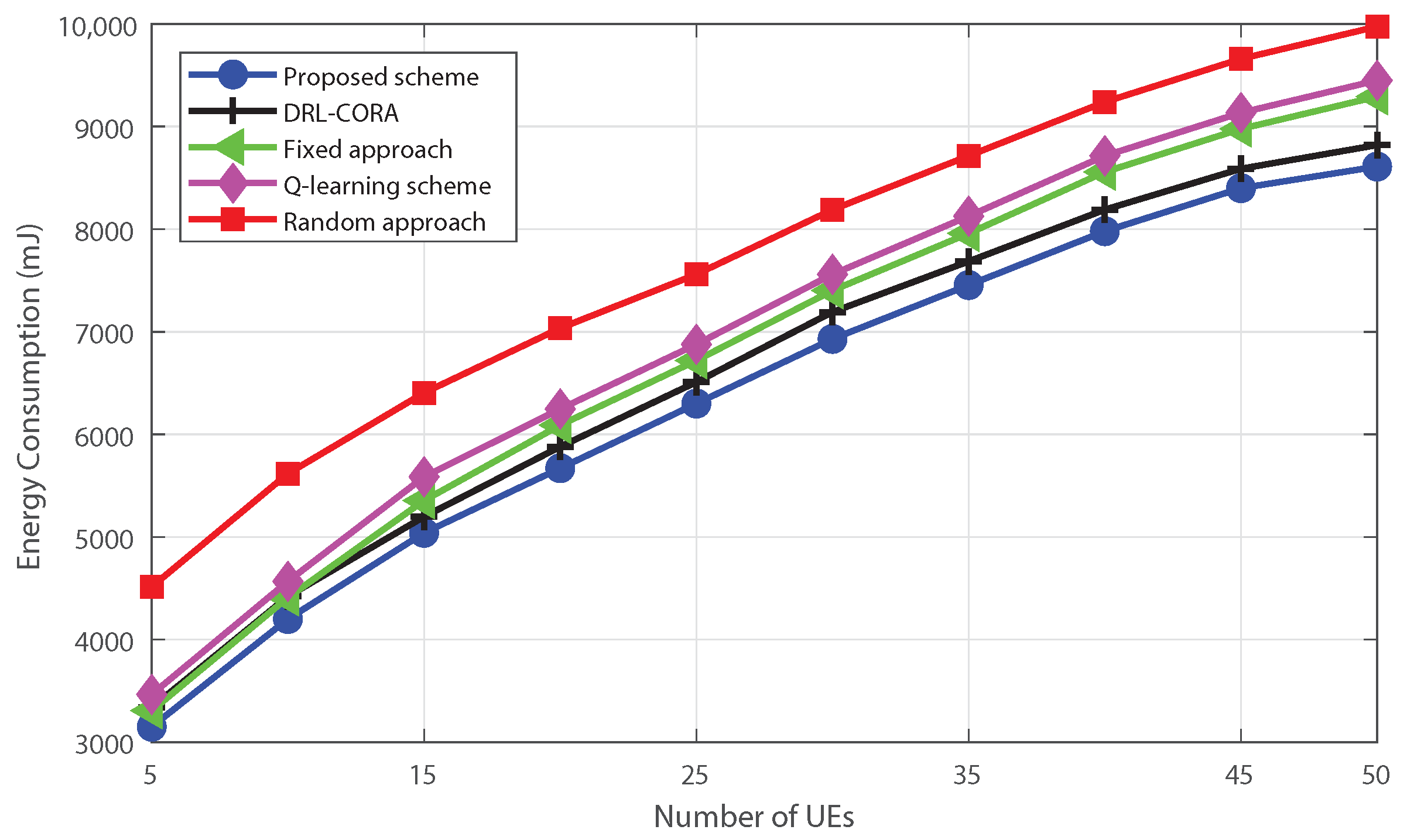
5. Simulations Results and Discussion
- Random scheme: the random algorithm involves making choices or decisions without considering any specific criteria;
- Fixed scheme: The fixed algorithm follows pre-determined rules or fixed strategies for decision-making. It was designed based on pre-defined guidelines and does not adapt to changes in the environment or task requirements;
- Q-learning scheme: The Q-learning allows dynamic cloud-edge selection. The system learns via interactions, updating the Q-table to estimate rewards for actions in different states;
- DRL-based computation offloading and resource allocation scheme (DRL-CORA) [36]: The DRL-CORA scheme employs a DQN scheme that enables the system to choose between cloud and edge computing modes dynamically. Through iterative interactions with the environment, the system refines its neural network’s Q-values to approximate anticipated rewards associated with diverse actions across varying states.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, J.; Li, Q.; Gong, Y.; Zhang, K. Computation offloading and resource allocation for cloud assisted mobile edge computing in vehicular networks. IEEE Trans. Veh. Technol. 2019, 68, 7944–7956. [Google Scholar] [CrossRef]
- Min, M.; Xiao, L.; Chen, Y.; Cheng, P.; Wu, D.; Zhuang, W. Learning-based computation offloading for IoT devices with energy harvesting. IEEE Trans. Veh. Technol. 2019, 68, 1930–1941. [Google Scholar] [CrossRef]
- Zhu, H.; Cao, Y.; Wei, X.; Wang, W.; Jiang, T.; Jin, S. Caching transient data for Internet of Things: A deep reinforcement learning approach. IEEE Internet Things J. 2018, 6, 2074–2083. [Google Scholar] [CrossRef]
- Peng, M.; Yan, S.; Zhang, K.; Wang, C. Fog-computing-based radio access networks: Issues and challenges. IEEE Netw. 2016, 30, 46–53. [Google Scholar] [CrossRef]
- Peng, M.; Zhang, K. Recent advances in fog radio access networks: Performance analysis and radio resource allocation. IEEE Access 2016, 4, 5003–5009. [Google Scholar] [CrossRef]
- Ceselli, A.; Premoli, M.; Secci, S. Mobile edge cloud network design optimization. IEEE/ACM Trans. Netw. 2017, 25, 1818–1831. [Google Scholar] [CrossRef]
- Zhao, Z.; Bu, S.; Zhao, T.; Yin, Z.; Peng, M.; Ding, Z.; Quek, T.Q. On the design of computation offloading in fog radio access networks. IEEE Trans. Veh. Technol. 2019, 68, 7136–7149. [Google Scholar] [CrossRef]
- Azizi, S.; Othman, M.; Khamfroush, H. DECO: A Deadline-Aware and Energy-Efficient Algorithm for Task Offloading in Mobile Edge Computing. IEEE Syst. J. 2022, 17, 952–963. [Google Scholar] [CrossRef]
- Mao, S.; Wu, J.; Liu, L.; Lan, D.; Taherkordi, A. Energy-efficient cooperative communication and computation for wireless powered mobile-edge computing. IEEE Syst. J. 2020, 16, 287–298. [Google Scholar] [CrossRef]
- Huang, J.; Wan, J.; Lv, B.; Ye, Q.; Chen, Y. Joint Computation Offloading and Resource Allocation for Edge-Cloud Collaboration in Internet of Vehicles via Deep Reinforcement Learning. IEEE Syst. J. 2023, 17, 2500–2511. [Google Scholar] [CrossRef]
- Sartoretti, G.; Paivine, W.; Shi, Y.; Wu, Y.; Choset, H. Distributed learning of decentralized control policies for articulated mobile robots. IEEE Trans. Robot. 2019, 35, 1109–1122. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tutorials 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Taya, A.; Nishio, T.; Morikura, M.; Yamamoto, K. Deep-reinforcement-learning-based distributed vehicle position controls for coverage expansion in mmWave V2X. IEICE Trans. Commun. 2019, 102, 2054–2065. [Google Scholar] [CrossRef]
- Wang, Z.; Li, M.; Zhao, L.; Zhou, H.; Wang, N. A3C-based Computation Offloading and Service Caching in Cloud-Edge Computing Networks. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), New York, NY, USA, 2–5 May 2022; pp. 1–2. [Google Scholar]
- Meng, F.; Chen, P.; Wu, L.; Cheng, J. Power allocation in multi-user cellular networks: Deep reinforcement learning approaches. IEEE Trans. Wirel. Commun. 2020, 19, 6255–6267. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Sun, Y.; Peng, M.; Mao, S. Deep reinforcement learning-based mode selection and resource management for green fog radio access networks. IEEE Internet Things J. 2018, 6, 1960–1971. [Google Scholar] [CrossRef]
- Guo, L.; Jia, J.; Chen, J.; Du, A.; Wang, X. Deep reinforcement learning empowered joint mode selection and resource allocation for RIS-aided D2D communications. Neural Comput. Appl. 2023, 35, 18231–18249. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, K.; Huang, H.; Miyazaki, T.; Guo, S. Traffic and computation co-offloading with reinforcement learning in fog computing for industrial applications. IEEE Trans. Ind. Inform. 2018, 15, 976–986. [Google Scholar] [CrossRef]
- Chandra, K.R.; Borugadda, S. Multi Agent Deep Reinforcement learning with Deep Q-Network based energy efficiency and resource allocation in NOMA wireless Systems. In Proceedings of the 2023 Second International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Trichirappalli, India, 5–7 April 2023; pp. 1–8. [Google Scholar]
- Babaeizadeh, M.; Frosio, I.; Tyree, S.; Clemons, J.; Kautz, J. Reinforcement learning through asynchronous advantage actor-critic on a gpu. arXiv 2016, arXiv:1611.06256. [Google Scholar]
- Zhang, J.; Hu, X.; Ning, Z.; Ngai, E.C.H.; Zhou, L.; Wei, J.; Cheng, J.; Hu, B. Energy-latency tradeoff for energy-aware offloading in mobile edge computing networks. IEEE Internet Things J. 2017, 5, 2633–2645. [Google Scholar] [CrossRef]
- Huynh, L.N.; Pham, Q.V.; Nguyen, T.D.; Hossain, M.D.; Park, J.H.; Huh, E.N. A study on computation offloading in mec systems using whale optimization algorithm. In Proceedings of the 2020 14th International Conference on Ubiquitous Information Management and Communication (IMCOM), Taichung, Taiwan, 3–5 January 2020; pp. 1–4. [Google Scholar]
- Waqar, N.; Hassan, S.A.; Mahmood, A.; Dev, K.; Do, D.T.; Gidlund, M. Computation offloading and resource allocation in MEC-enabled integrated aerial-terrestrial vehicular networks: A reinforcement learning approach. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21478–21491. [Google Scholar] [CrossRef]
- Zaman, S.K.u.; Jehangiri, A.I.; Maqsood, T.; Ahmad, Z.; Umar, A.I.; Shuja, J.; Alanazi, E.; Alasmary, W. Mobility-aware computational offloading in mobile edge networks: A survey. Clust. Comput. 2021, 24, 2735–2756. [Google Scholar] [CrossRef]
- He, W.; Wu, S.; Sun, J. An Effective Metaheuristic for Partial Offloading and Resource Allocation in Multi-Device Mobile Edge Computing. In Proceedings of the 2021 IEEE 23rd Int Conf on High Performance Computing & Communications; 7th Int Conf on Data Science & Systems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Haikou, China, 20–22 December 2021; pp. 1419–1426. [Google Scholar]
- Yuan, X.; Zhu, Y.; Zhao, Z.; Zheng, Y.; Pan, J.; Liu, D. An A3C-based joint optimization offloading and migration algorithm for SD-WBANs. In Proceedings of the 2020 IEEE Globecom Workshops (GC Wkshps), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Rahman, G.S.; Peng, M.; Yan, S.; Dang, T. Learning based joint cache and power allocation in fog radio access networks. IEEE Trans. Veh. Technol. 2020, 69, 4401–4411. [Google Scholar] [CrossRef]
- Wen, Y.; Zhang, W.; Luo, H. Energy-optimal mobile application execution: Taming resource-poor mobile devices with cloud clones. In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2716–2720. [Google Scholar]
- Tuli, S.; Ilager, S.; Ramamohanarao, K.; Buyya, R. Dynamic scheduling for stochastic edge-cloud computing environments using a3c learning and residual recurrent neural networks. IEEE Trans. Mobile Comput. 2020, 21, 940–954. [Google Scholar] [CrossRef]
- Li, Y.; Qi, F.; Wang, Z.; Yu, X.; Shao, S. Distributed edge computing offloading algorithm based on deep reinforcement learning. IEEE Access 2020, 8, 85204–85215. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Thar, K.; Oo, T.Z.; Tun, Y.K.; Kim, K.T.; Hong, C.S. A deep learning model generation framework for virtualized multi-access edge cache management. IEEE Access 2019, 7, 62734–62749. [Google Scholar] [CrossRef]
- Li, C.; Zhang, Y.; Gao, X.; Luo, Y. Energy-latency tradeoffs for edge caching and dynamic service migration based on DQN in mobile edge computing. J. Parallel Distrib. Comput. 2022, 166, 15–31. [Google Scholar] [CrossRef]
- Rahman, G.S.; Dang, T.; Ahmed, M. Deep reinforcement learning based computation offloading and resource allocation for low-latency fog radio access networks. Intell. Converg. Netw. 2020, 1, 243–257. [Google Scholar] [CrossRef]
- Fan, Z.; Xu, Y.; Kang, Y.; Luo, D. Air Combat Maneuver Decision Method Based on A3C Deep Reinforcement Learning. Machines 2022, 10, 1033. [Google Scholar] [CrossRef]
- Raza, S.; Wang, S.; Ahmed, M.; Anwar, M.R.; Mirza, M.A.; Khan, W.U. Task offloading and resource allocation for IoV using 5G NR-V2X communication. IEEE Internet Things J. 2021, 9, 10397–10410. [Google Scholar] [CrossRef]
- Khan, I.; Tao, X.; Rahman, G.S.; Rehman, W.U.; Salam, T. Advanced energy-efficient computation offloading using deep reinforcement learning in MTC edge computing. IEEE Access 2020, 8, 82867–82875. [Google Scholar] [CrossRef]
- Chen, Z.; Su, X. Computation offloading and resource allocation based on cell-free radio access network. In Proceedings of the 2022 IEEE 6th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 4–6 March 2022; Volume 6, pp. 1498–1502. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| A3C | Advanced Asynchronous Advantage Actor-Critic |
| AI | Artificial Intelligence |
| DRL | Deep Reinforcement Learning |
| MECNs | Mobile Edge Computing Networks |
| CP | Cloud Processor |
| CRRM | Collaborative Radio Resource Management |
| CRSP | Collaborative Radio Signal Processing |
| E-AP | Edge Access Point |
| SUE | Smart User Equipment |
| CSI | Channel State Information |
| GUE | General User Equipment |
| transmitted signal vector | |
| the transmitting power from user k to E-AP l | |
| the channel gain between user k to E-AP l | |
| available mode for user k | |
| the lower bound of QoS for user k | |
| maximum achievable transmission rate | |
| tolerable maximum latency for the task completion | |
| task of user k | |
| transmission rate between user k to E-AP l | |
| transmission rate between user k to RRH j | |
| the allocated computing resources of E-AP l to user k | |
| energy consumption for per CPU cycle at E-AP l | |
| s | state in the environment |
| a | the agent action |
| the discount factor | |
| r | reward obtained from appropriate action |
| action-state pair for every time t cycle | |
| optimal Q-function at time t | |
| the reward obtained from the current action state pair | |
| the learning rate of Q-learning | |
| The loss function in which represents the parameter of the neural network | |
| E | Expected outcome |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, I.; Raza, S.; Khan, R.; Rehman, W.u.; Rahman, G.M.S.; Tao, X. Distributed Multi-Agent Approach for Achieving Energy Efficiency and Computational Offloading in MECNs Using Asynchronous Advantage Actor-Critic. Electronics 2023, 12, 4605. https://doi.org/10.3390/electronics12224605
Khan I, Raza S, Khan R, Rehman Wu, Rahman GMS, Tao X. Distributed Multi-Agent Approach for Achieving Energy Efficiency and Computational Offloading in MECNs Using Asynchronous Advantage Actor-Critic. Electronics. 2023; 12(22):4605. https://doi.org/10.3390/electronics12224605
Chicago/Turabian StyleKhan, Israr, Salman Raza, Razaullah Khan, Waheed ur Rehman, G. M. Shafiqur Rahman, and Xiaofeng Tao. 2023. "Distributed Multi-Agent Approach for Achieving Energy Efficiency and Computational Offloading in MECNs Using Asynchronous Advantage Actor-Critic" Electronics 12, no. 22: 4605. https://doi.org/10.3390/electronics12224605
APA StyleKhan, I., Raza, S., Khan, R., Rehman, W. u., Rahman, G. M. S., & Tao, X. (2023). Distributed Multi-Agent Approach for Achieving Energy Efficiency and Computational Offloading in MECNs Using Asynchronous Advantage Actor-Critic. Electronics, 12(22), 4605. https://doi.org/10.3390/electronics12224605