Multi-View Stereo Network Based on Attention Mechanism and Neural Volume Rendering


Abstract
:1. Introduction
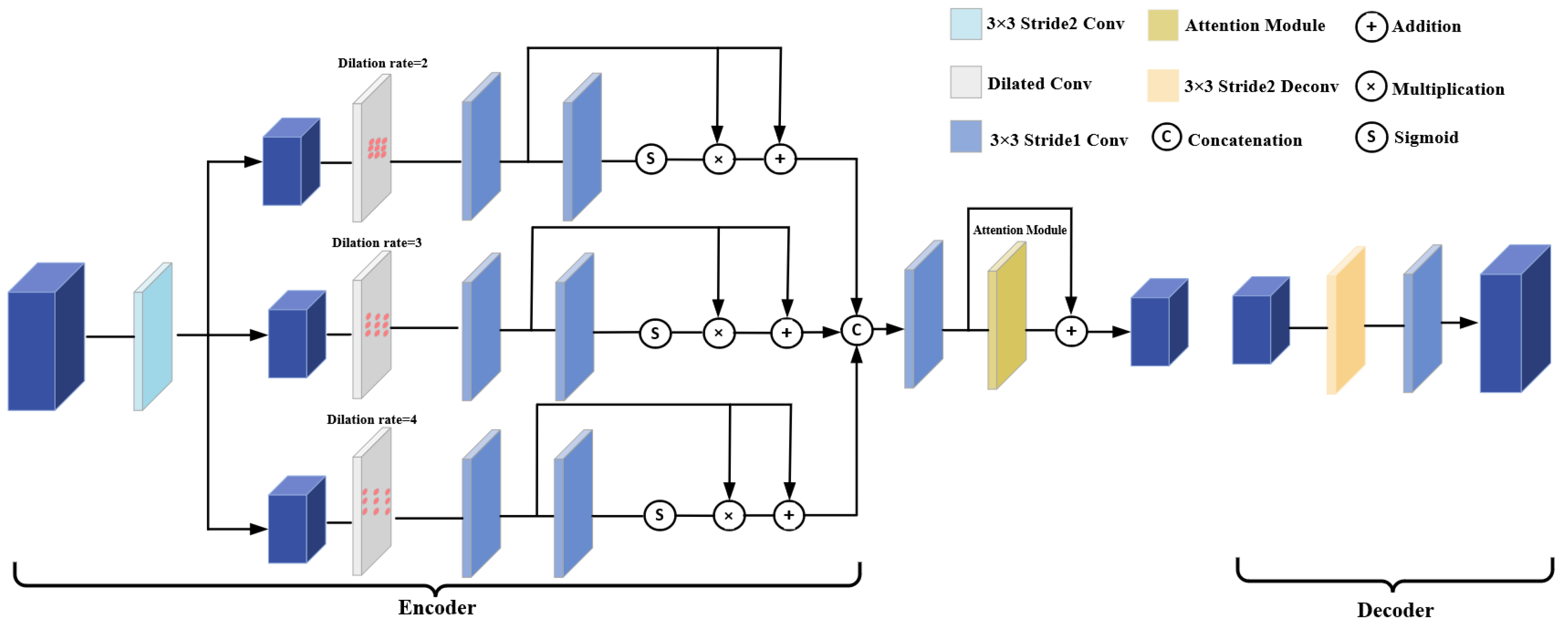
- We introduce a multi-scale feature extraction module based on triple dilated convolution and attention mechanism. This module increases the receptive field without adding model parameters, capturing dependencies between features to acquire global context information and enhance the representation of features in challenging regions;
- We establish a neural volume rendering network using multi-view semantic features and neural encoding volume. The network is iteratively optimized through the rendering reference view loss, enabling the precise decoding of the geometric appearance information represented by the radiance field. We introduce the depth consistency loss to maintain geometric consistency between the MVS network and the neural volume rendering network, mitigating the impact of the flawed cost volume;
- Our approach demonstrates state-of-the-art results on the DTU dataset and the Tanks and Temples dataset.
2. Related Work
2.1. Learning-Based Multi-View Stereo
2.2. Neural Volume Rendering Based on Multi-View Stereo
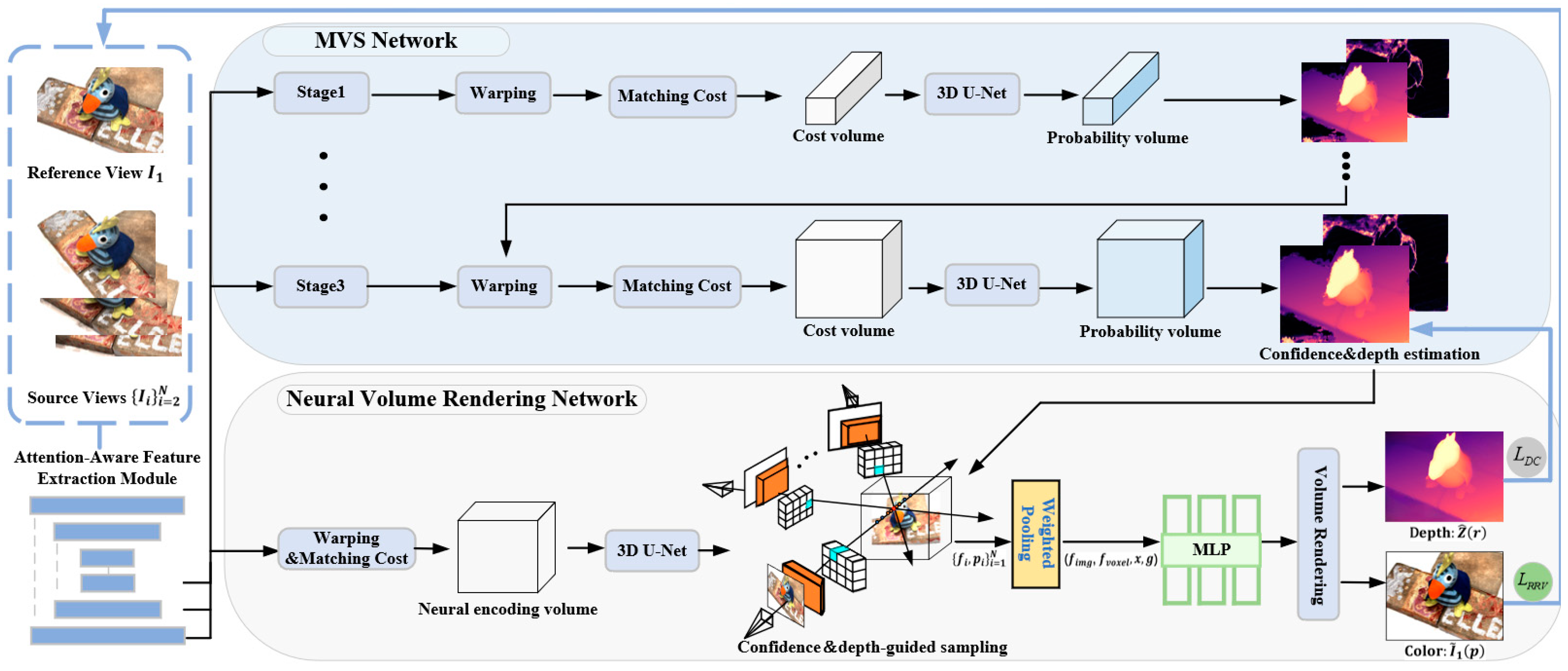
3. Methods
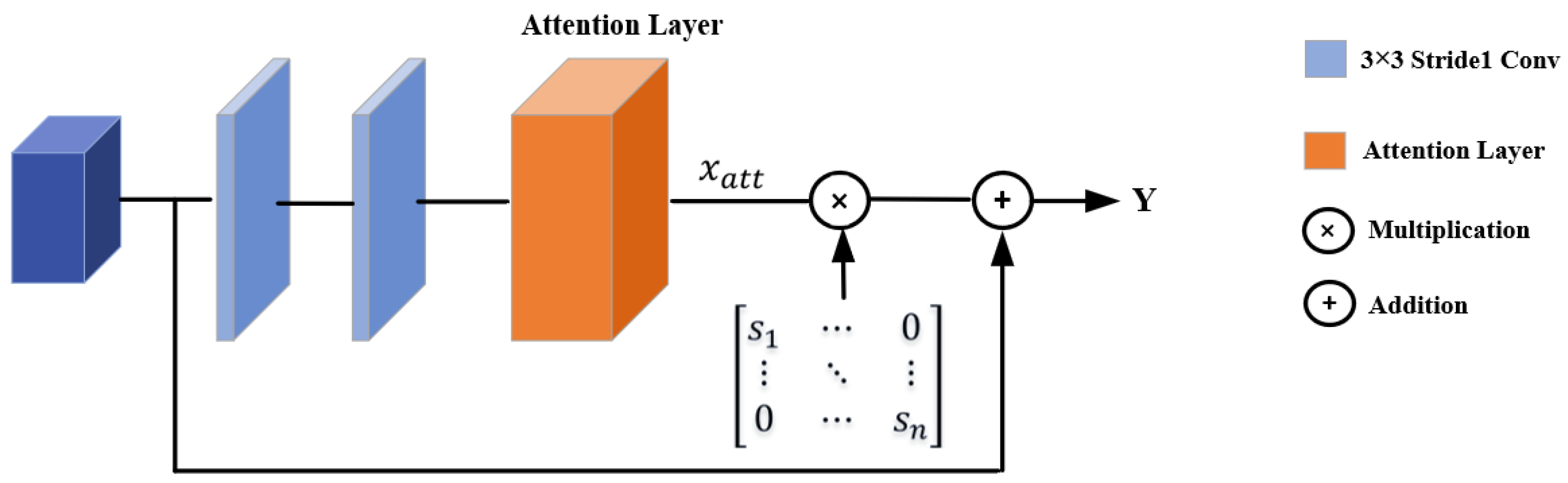
3.1. Attention-Aware Feature Extraction Module
3.2. Cost Volume Construction
3.3. Neural Volume Rendering Network
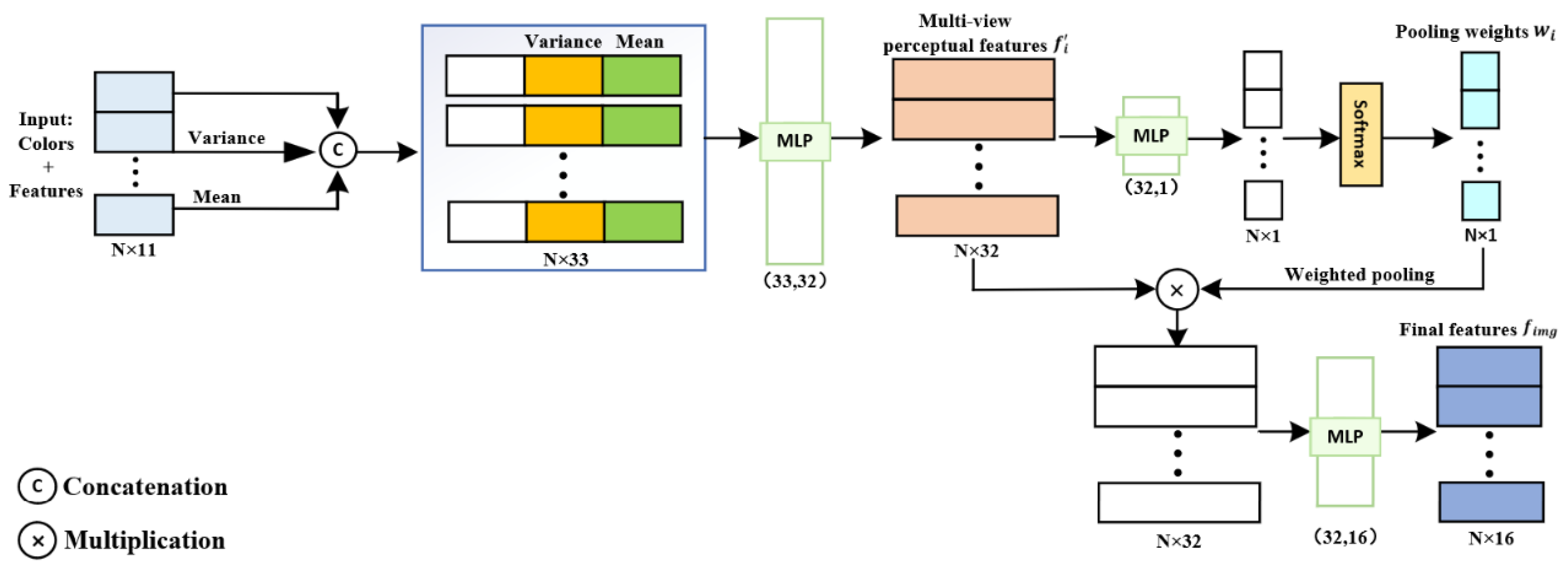
3.3.1. Scene Representation Based on Multi-View Features and Neural Encoding Volume
3.3.2. Confidence and Depth-Guided Sampling for Volume Rendering
3.4. Loss Function
4. Experiments
4.1. Datasets
4.2. End-to-End Training Details
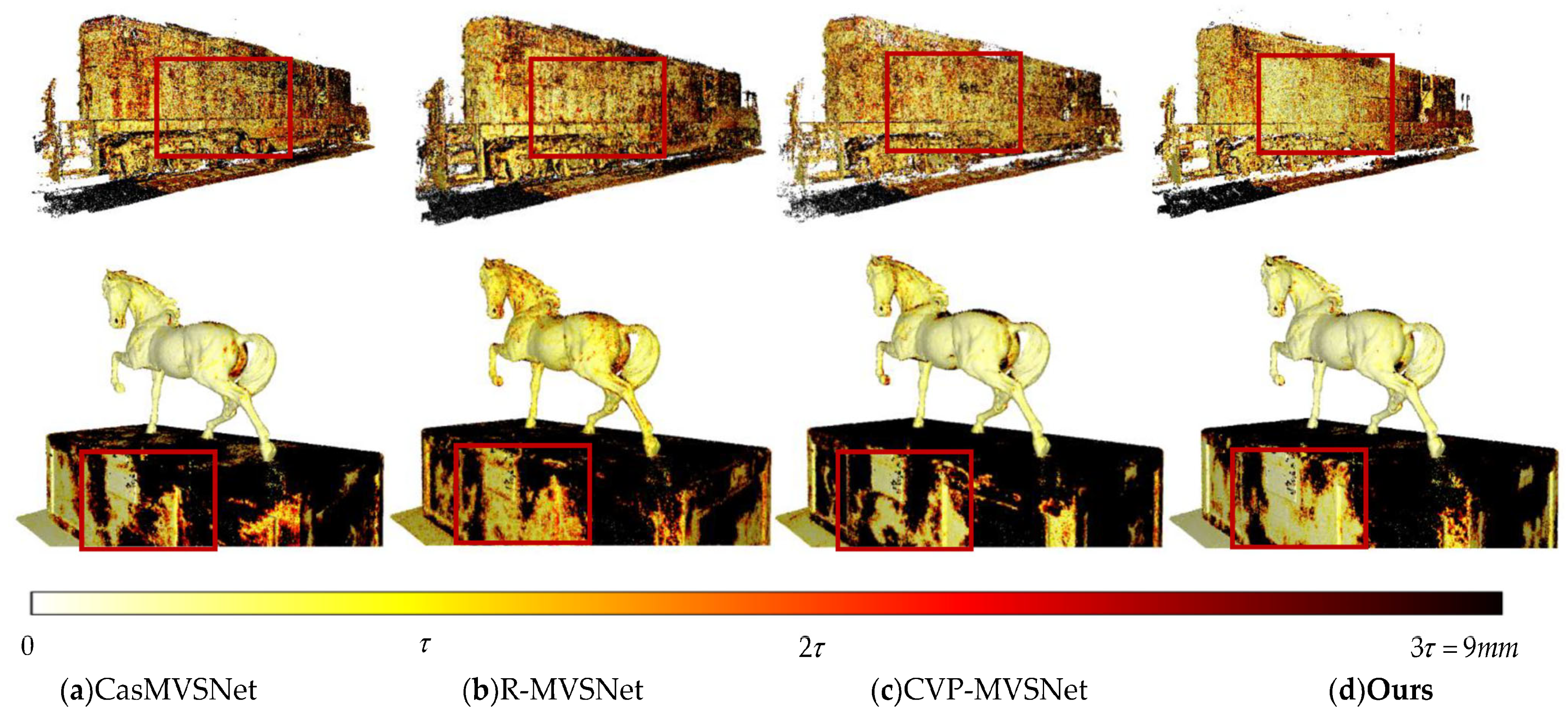
4.3. Experimental Results
4.3.1. Results on DTU Dataset
4.3.2. Results on Tanks and Temples Dataset
4.4. Ablation Study
4.4.1. Influence of Attention-Aware Feature Extraction Module and Different Loss Functions
4.4.2. Impact of Different Dilation Rates in the Attention-Aware Feature Extraction Module
4.4.3. Effect of Confidence and Depth-guided Sampling Strategy under Different Numbers of Input Views
4.4.4. Performance of Sampling with Varying Numbers of Rays
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Campbell, N.D.; Vogiatzis, G.; Hernández, C.; Cipolla, R. Using multiple hypotheses to improve depth-maps for multi-view stereo. In Proceedings of the European Conference on Computer (ECCV), Marseille, France, 12–18 October 2008; pp. 766–779. [Google Scholar]
- Ponce, J.; Furukawa, Y. Accurate, Dense, and Robust Multiview Stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1362–1376. [Google Scholar] [CrossRef]
- Galliani, S.; Lasinger, K.; Schindler, K. Massively parallel multiview stereopsis by surface normal diffusion. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 873–881. [Google Scholar]
- Schönberger, J.L.; Zheng, E.; Frahm, J.-M.; Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the European Conference on Computer (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 501–518. [Google Scholar]
- Xu, Q.; Tao, W. Multi-scale geometric consistency guided multi-view stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5483–5492. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. MVSNet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Yu, A.; Guo, W.; Liu, B.; Chen, X.; Wang, X.; Cao, X.; Jiang, B.J.I.J.o.P.; Sensing, R. Attention aware cost volume pyramid based multi-view stereo network for 3d reconstruction. ISPRS J. Photogramm. Remote Sens. 2021, 175, 448–460. [Google Scholar] [CrossRef]
- Li, J.; Bai, Z.; Cheng, W.; Liu, H. Feature Pyramid Multi-View Stereo Network Based on Self-Attention Mechanism. In Proceedings of the 2022 5th International Conference on Image and Graphics Processing, Beijing, China, 7–9 January 2022; pp. 226–233. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2020, 65, 99–106. [Google Scholar] [CrossRef]
- Xu, Q.; Xu, Z.; Philip, J.; Bi, S.; Shu, Z.; Sunkavalli, K.; Neumann, U. Point-NeRF: Point-based Neural Radiance Fields. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 5428–5438. [Google Scholar]
- Yang, J.; Pavone, M.; Wang, Y. FreeNeRF: Improving Few-shot Neural Rendering with Free Frequency Regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Oxford, UK, 15–17 September 2023; pp. 8254–8263. [Google Scholar]
- Wang, Q.; Wang, Z.; Genova, K.; Srinivasan, P.; Zhou, H.; Barron, J.T.; Martin-Brualla, R.; Snavely, N.; Funkhouser, T. IBRNet: Learning Multi-View Image-Based Rendering. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 4688–4697. [Google Scholar]
- Yu, A.; Ye, V.; Tancik, M.; Kanazawa, A. pixelNeRF: Neural radiance fields from one or few images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 4578–4587. [Google Scholar]
- Garbin, S.J.; Kowalski, M.; Johnson, M.; Shotton, J.; Valentin, J. FastNeRF: High-Fidelity Neural Rendering at 200FPS. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 14326–14335. [Google Scholar]
- Chen, A.; Xu, Z.; Zhao, F.; Zhang, X.; Xiang, F.; Yu, J.; Su, H. MVSNeRF: Fast generalizable radiance field reconstruction from multi-view stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 14124–14133. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent MVSNet for High-Resolution Multi-View Stereo Depth Inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5520–5529. [Google Scholar]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade cost volume for high-resolution multi-view stereo and stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2495–2504. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Ding, Y.; Yuan, W.; Zhu, Q.; Zhang, H.; Liu, X.; Wang, Y.; Liu, X. TransMVSNet: Global Context-aware Multi-view Stereo Network with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 8575–8584. [Google Scholar]
- Zhu, J.; Peng, B.; Li, W.; Shen, H.; Zhang, Z.; Lei, J. Multi-View Stereo with Transformer. arXiv 2021, arXiv:2112.00336. [Google Scholar]
- Wang, X.; Zhu, Z.; Huang, G.; Qin, F.; Ye, Y.; He, Y.; Chi, X.; Wang, X. MVSTER: Epipolar transformer for efficient multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Tel-Aviv, Israel, 23–27 October 2022; pp. 573–591. [Google Scholar]
- Chang, D.; Božič, A.; Zhang, T.; Yan, Q.; Chen, Y.; Süsstrunk, S.; Nießner, M. RC-MVSNet: Unsupervised Multi-View Stereo with Neural Rendering. In Proceedings of the European Conference on Computer (ECCV), Tel-Aviv, Israel, 23–27 October 2022; pp. 665–680. [Google Scholar]
- Lin, L.; Zhang, Y.; Wang, Z.; Zhang, L.; Liu, X.; Wang, Q. A-SATMVSNet: An attention-aware multi-view stereo matching network based on satellite imagery. Front. Earth Sci. 2023, 11, 1108403. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going deeper with Image Transformers. arXiv 2021, arXiv:2103.17239. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Aanæs, H.; Jensen, R.R.; Vogiatzis, G.; Tola, E.; Dahl, A.B. Large-scale data for multiple-view stereopsis. Int. J. Comput. Vis. 2016, 120, 153–168. [Google Scholar] [CrossRef]
- Knapitsch, A.; Park, J.; Zhou, Q.-Y.; Koltun, V. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Trans. Graph. 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Yang, J.; Mao, W.; Alvarez, J.M.; Liu, M. Cost Volume Pyramid Based Depth Inference for Multi-View Stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4876–4885. [Google Scholar]
- Cheng, S.; Xu, Z.; Zhu, S.; Li, Z.; Li, L.E.; Ramamoorthi, R.; Su, H. Deep Stereo Using Adaptive Thin Volume Representation With Uncertainty Awareness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2521–2531. [Google Scholar]
- Tola, E.; Strecha, C.; Fua, P. Efficient large-scale multi-view stereo for ultra high-resolution image sets. Mach. Vis. Appl. 2012, 23, 903–920. [Google Scholar] [CrossRef]
- Xu, Q.; Tao, W. Learning inverse depth regression for multi-view stereo with correlation cost volume. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12508–12515. [Google Scholar]
- Luo, K.; Guan, T.; Ju, L.; Huang, H.; Luo, Y. P-MVSNet: Learning Patch-Wise Matching Confidence Aggregation for Multi-View Stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10451–10460. [Google Scholar]
- Chen, R.; Han, S.; Xu, J.; Su, H. Point-Based Multi-View Stereo Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1538–1547. [Google Scholar]
- Yu, Z.; Gao, S. Fast-MVSNet: Sparse-to-Dense Multi-View Stereo With Learned Propagation and Gauss-Newton Refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1946–1955. [Google Scholar]
- Yi, H.; Wei, Z.; Ding, M.; Zhang, R.; Chen, Y.; Wang, G.; Tai, Y.-W. Pyramid multi-view stereo net with self-adaptive view aggregation. In Proceedings of the European Conference on Computer (ECCV), Glasgow, UK, 23–28 August 2020; pp. 766–782. [Google Scholar]
- Wang, F.; Galliani, S.; Vogel, C.; Speciale, P.; Pollefeys, M. Patchmatchnet: Learned multi-view patchmatch stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 14194–14203. [Google Scholar]
- Ma, X.; Gong, Y.; Wang, Q.; Huang, J.; Chen, L.; Yu, F. EPP-MVSNet: Epipolar-assembling based Depth Prediction for Multi-view Stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 5712–5720. [Google Scholar]
- Wei, Z.; Zhu, Q.; Min, C.; Chen, Y.; Wang, G. AA-RMVSNet: Adaptive Aggregation Recurrent Multi-view Stereo Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 6167–6176. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Acc. (mm) | Comp. (mm) | Overall (mm) | |
|---|---|---|---|---|
| Traditional | Tola [30] | 0.613 | 0.941 | 0.777 |
| Furu [2] | 0.342 | 1.190 | 0.766 | |
| Camp [1] | 0.835 | 0.554 | 0.695 | |
| Gipuma [3] | 0.283 | 0.873 | 0.578 | |
| Colmap [4] | 0.400 | 0.644 | 0.532 | |
| Learning-based | MVSNet [6] | 0.396 | 0.527 | 0.462 |
| CIDER [31] | 0.417 | 0.437 | 0.427 | |
| R-MVSNet [16] | 0.383 | 0.452 | 0.417 | |
| P-MVSNet [32] | 0.406 | 0.434 | 0.420 | |
| Point-MVSNet [33] | 0.342 | 0.411 | 0.376 | |
| Fast-MVSNet [34] | 0.336 | 0.403 | 0.370 | |
| PVA-MVSNet [35] | 0.379 | 0.336 | 0.357 | |
| CasMVSNet [17] | 0.325 | 0.385 | 0.355 | |
| UCS-Net [29] | 0.338 | 0.349 | 0.344 | |
| CVP-MVSNet [28] | 0.296 | 0.406 | 0.351 | |
| PatchmatchNet [36] | 0.427 | 0.277 | 0.352 | |
| EPP-MVSNet [37] | 0.413 | 0.296 | 0.355 | |
| AA-RMVSNet [38] | 0.376 | 0.339 | 0.357 | |
| Ours | 0.363 | 0.296 | 0.329 |
| Method | Mean | Fam. | Fra. | Hor. | Lig. | M60. | Pan. | Pla. | Tra. |
|---|---|---|---|---|---|---|---|---|---|
| Point-MVSNet [33] | 48.27 | 61.79 | 41.15 | 34.20 | 50.79 | 51.97 | 50.85 | 52.38 | 43.06 |
| MVSNet [6] | 43.48 | 55.99 | 28.55 | 25.07 | 50.79 | 53.96 | 50.86 | 47.90 | 34.69 |
| Fast-MVSNet [34] | 47.39 | 65.18 | 39.59 | 34.98 | 47.81 | 49.16 | 46.20 | 53.27 | 42.91 |
| UCS-Net [29] | 54.83 | 76.09 | 53.16 | 43.03 | 54.00 | 55.60 | 51.49 | 57.38 | 47.89 |
| CIDER [31] | 46.76 | 56.79 | 32.39 | 29.89 | 54.67 | 53.46 | 53.51 | 50.48 | 42.85 |
| R-MVSNet [16] | 48.40 | 69.96 | 46.65 | 32.59 | 42.95 | 51.88 | 48.80 | 52.00 | 42.38 |
| P-MVSNet [32] | 55.62 | 70.04 | 44.64 | 40.22 | 65.20 | 55.08 | 55.17 | 60.37 | 54.29 |
| PatchmatchNet [36] | 53.15 | 66.99 | 52.64 | 43.24 | 54.87 | 52.87 | 49.54 | 54.21 | 50.81 |
| PVA-MVSNet [35] | 54.46 | 69.36 | 46.80 | 46.01 | 55.74 | 57.23 | 54.75 | 56.70 | 49.06 |
| CVP-MVSNet [28] | 54.03 | 76.50 | 47.74 | 36.34 | 55.12 | 57.28 | 54.28 | 57.43 | 47.54 |
| MVSTR [20] | 56.93 | 76.92 | 59.82 | 50.16 | 56.73 | 56.53 | 51.22 | 56.58 | 47.48 |
| CasMVSNet [17] | 56.42 | 76.36 | 58.45 | 46.20 | 55.53 | 56.11 | 54.02 | 58.17 | 46.56 |
| Ours | 58.00 | 76.65 | 56.19 | 50.20 | 55.69 | 60.69 | 57.34 | 53.86 | 53.43 |
| Method | Mean | Aud. | Bal. | Court. | Mus. | Pal. | Tem. |
|---|---|---|---|---|---|---|---|
| R-MVSNet [16] | 24.91 | 12.55 | 29.09 | 25.06 | 38.68 | 19.14 | 24.96 |
| CIDER [31] | 23.12 | 12.77 | 24.94 | 25.01 | 33.64 | 19.18 | 23.15 |
| PatchmatchNet [36] | 32.31 | 23.69 | 37.73 | 30.04 | 41.80 | 28.31 | 32.29 |
| CasMVSNet [17] | 31.12 | 19.81 | 38.46 | 29.10 | 43.87 | 27.36 | 28.11 |
| Ours | 31.66 | 22.75 | 38.77 | 28.55 | 39.46 | 30.53 | 29.91 |
| Method | Acc. (mm) | Comp. (mm) | Overall (mm) | Test Param. | Test Time (s) | Test Memory (GB) |
|---|---|---|---|---|---|---|
| Baseline | 0.325 | 0.385 | 0.355 | 934,304 | 0.49 | 5.3 |
| Baseline + AM | 0.357 | 0.324 | 0.340 | 964,943 | 0.528 | 5.4 |
| Baseline + RRV | 0.359 | 0.313 | 0.336 | 934,304 | 0.49 | 5.3 |
| Baseline + RRV + DC | 0.364 | 0.305 | 0.334 | 934,304 | 0.49 | 5.3 |
| Baseline + RRV + DC + AM | 0.363 | 0.296 | 0.329 | 964,943 | 0.528 | 5.4 |
| Dilation Rate | Acc. (mm) | Comp. (mm) | Overall (mm) |
|---|---|---|---|
| (1, 2, 3) | 0.358 | 0.306 | 0.332 |
| (2, 3, 4) | 0.363 | 0.296 | 0.329 |
| (2, 3, 5) | 0.365 | 0.313 | 0.339 |
| (1, 3, 5) | 0.370 | 0.312 | 0.341 |
| (3, 4, 5) | 0.379 | 0.329 | 0.354 |
| Nviews | CDG | Acc. (mm) | Comp. (mm) | Overall (mm) |
|---|---|---|---|---|
| 3 | 0.377 | 0.325 | 0.351 | |
| 3 | ✓ | 0.367 | 0.315 | 0.341 |
| 4 | 0.374 | 0.299 | 0.336 | |
| 4 | ✓ | 0.363 | 0.296 | 0.329 |
| 5 | 0.379 | 0.305 | 0.342 | |
| 5 | ✓ | 0.370 | 0.302 | 0.336 |
| Num_Rays | Acc. (mm) | Comp. (mm) | Overall (mm) |
|---|---|---|---|
| 256 | 0.371 | 0.304 | 0.337 |
| 1024 | 0.363 | 0.296 | 0.329 |
| 4096 | 0.369 | 0.300 | 0.334 |
| 8192 | 0.363 | 0.297 | 0.330 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, D.; Kong, H.; Qiu, Q.; Ruan, X.; Liu, S. Multi-View Stereo Network Based on Attention Mechanism and Neural Volume Rendering. Electronics 2023, 12, 4603. https://doi.org/10.3390/electronics12224603
Zhu D, Kong H, Qiu Q, Ruan X, Liu S. Multi-View Stereo Network Based on Attention Mechanism and Neural Volume Rendering. Electronics. 2023; 12(22):4603. https://doi.org/10.3390/electronics12224603
Chicago/Turabian StyleZhu, Daixian, Haoran Kong, Qiang Qiu, Xiaoman Ruan, and Shulin Liu. 2023. "Multi-View Stereo Network Based on Attention Mechanism and Neural Volume Rendering" Electronics 12, no. 22: 4603. https://doi.org/10.3390/electronics12224603
APA StyleZhu, D., Kong, H., Qiu, Q., Ruan, X., & Liu, S. (2023). Multi-View Stereo Network Based on Attention Mechanism and Neural Volume Rendering. Electronics, 12(22), 4603. https://doi.org/10.3390/electronics12224603