
Integrated Algorithm Based on Bidirectional Characteristics and Feature Selection for Fire Image Classification
Abstract
:1. Introduction
- To obtain more image semantic information, we construct multiple sets of bidirectional traditional convolutions and bidirectional dilated convolutions, and the module adopts a codirectional feature fusion strategy and fuses the feature maps from different convolutions in the same direction. This module not only enables the network to obtain more semantic information but also generates shallow features to guarantee the latter deep feature screening strategy.
- We use the Inception V3 [16] module and introduce multiple sets of Euclidean distance [17] strategies and bidirectional attention mechanism strategies to calculate the correlation between feature maps and feature points produced by kernel convolution at different scales at the same level. We select features based on the importance of each feature point.
- We conducted sufficient ablation experiments on three datasets to demonstrate the feasibility of the proposed strategy in this paper.
2. Related Research
3. BCFS-Net Algorithm
3.1. BCFS-Net Algorithm
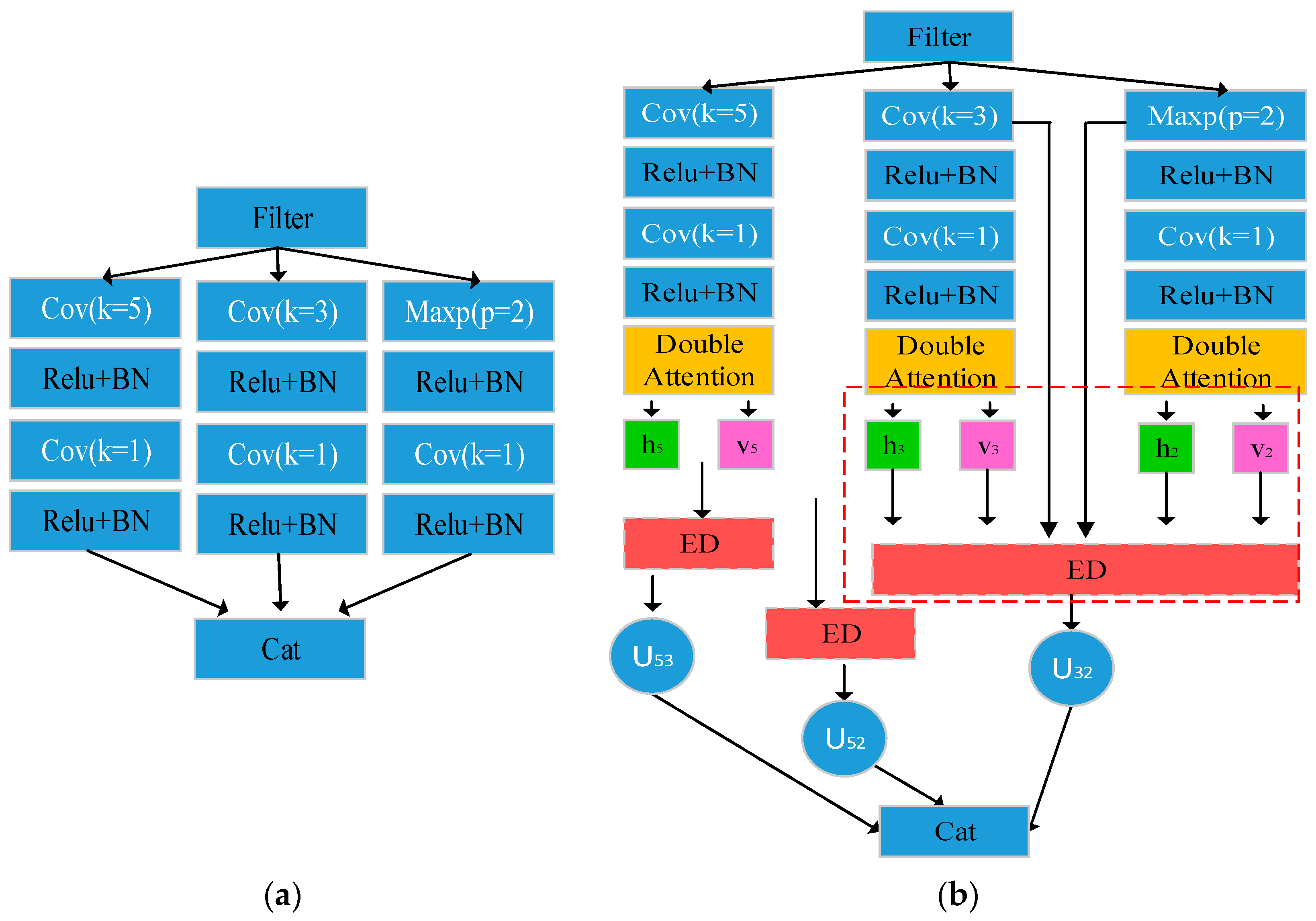
3.2. Bidirectional Feature Learning Module
3.3. Weight Selection Module
3.4. Feature Dimension Reduction and Fusion
4. Experimental Results
4.1. Datasets
4.2. Evaluation Criteria
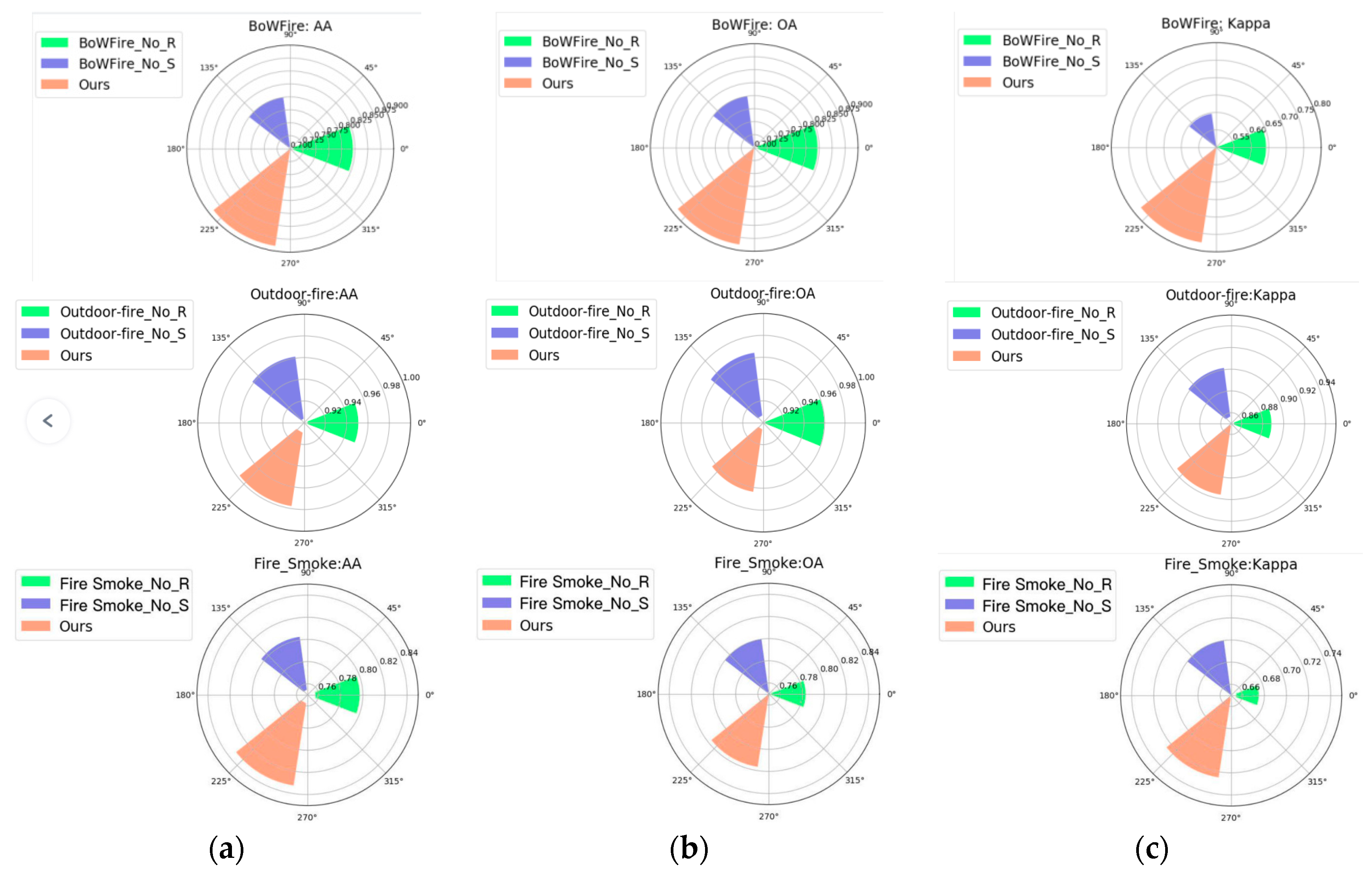
4.3. Comparison between the BCFS-Net Algorithm and Other Algorithms
4.4. The Effect of Threshold T on BCFS-Net
4.5. The Impact of Various Strategies on ResNet18 and Vgg16
4.6. Feasibility of Various Strategies in the BCFS-Net Algorithm
5. Summary and Outlook
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Khudayberdiev, O.; Zhang, J.; Elkhalil, A.; Balde, L. Fire detection approach based on vision transformer. In Proceedings of the International Conference on Adaptive and Intelligent Systems, Larnaca, Cyprus, 25–26 May 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 41–53. [Google Scholar]
- Ghali, R.; Akhloufi, M.A.; Mseddi, W.S. Deep learning and transformer approaches for UAV-based wildfire detection and segmentation. Sensors 2022, 22, 1977. [Google Scholar] [CrossRef] [PubMed]
- Ayala, A.; Fernandes, B.; Cruz, F.; Macêdo, D.; Oliveira, A.L.; Zanchettin, C. KutralNet: A portable deep learning model for fire recognition. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Majid, S.; Alenezi, F.; Masood, S.; Ahmad, M.; Gündüz, E.S.; Polat, K. Attention based CNN model for fire detection and localization in real-world images. Expert Syst. Appl. 2022, 189, 116114. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, H.; Wang, P.; Ling, X. ATT squeeze U-Net: A lightweight network for forest fire detection and recognition. IEEE Access 2021, 9, 10858–10870. [Google Scholar] [CrossRef]
- Tripathi, A.M.; Mishra, A. Environment sound classification using an attention-based residual neural network. Neurocomputing 2021, 460, 409–423. [Google Scholar] [CrossRef]
- Lin, J.; Lin, H.; Wang, F. A Semi-Supervised Method for Real-Time Forest Fire Detection Algorithm Based on Adaptively Spatial Feature Fusion. Forests 2023, 14, 361. [Google Scholar] [CrossRef]
- Xue, Z.; Lin, H.; Wang, F. A small target forest fire detection model based on YOLOv5 improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Ning, X.; Tian, W.; He, F.; Bai, X.; Sun, L.; Li, W. Hypersausage coverage function neuron model and learning algorithm for image classi cation. Pattern Recognit. 2023, 136, 109216. [Google Scholar] [CrossRef]
- Ning, X.; Tian, W.; Yu, Z.; Li, W.; Bai, X.; Wang, Y. HCFNN: High-order Coverage Function Neural Network for Image Classification. Pattern Recognit. 2022, 131, 108873. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, T.; Wu, X.; Huang, X. Predicting transient building fire based on external smoke images and deep learning. J. Build. Eng. 2022, 47, 103823. [Google Scholar] [CrossRef]
- Ning, X.; Yu, Z.; Li, L.; Li, W.; Tiwari, P. Differentiable rendering-based multiview Image-Language Fusion for zero-shot 3D shape understanding. Inf. Fusion 2023, 102, 102033. [Google Scholar] [CrossRef]
- Harkat, H.; Nascimento, J.M.; Bernardino, A.; Ahmed, H.F.T. Fire images classification based on a handcraft approach. Expert Syst. Appl. 2023, 212, 118594. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, W.; Liu, K.; Zhang, F.; Xiao, Z. A dual convolution network using dark channel prior for image smoke classification. IEEE Access 2019, 7, 60697–60706. [Google Scholar] [CrossRef]
- Yar, H.; Hussain, T.; Agarwal, M.; Khan, Z.A.; Gupta, S.K.; Baik, S.W. Optimized dual fire attention network and medium-scale fire classification benchmark. IEEE Trans. Image Process. 2022, 31, 6331–6343. [Google Scholar] [CrossRef] [PubMed]
- You, H.; Yu, L.; Tian, S.; Cai, W. A stereo spatial decoupling network for medical image classification. Complex Intell. Syst. 2023, 9, 5965–5974. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Su, B.-C.; Lin, T.; Huang, Y. Downlink SCMA codebook design with low error rate by maximizing minimum Euclidean distance of superimposed codewords. IEEE Trans. Veh. Technol. 2022, 71, 5231–5245. [Google Scholar] [CrossRef]
- Park, M.; Tran, D.Q.; Lee, S.; Park, S. Multilabel image classification with deep transfer learning for decision support on wildfire response. Remote Sens. 2021, 13, 3985. [Google Scholar] [CrossRef]
- Wang, J.; Yu, J.; He, Z. DECA: A novel multiscale efficient channel attention module for object detection in real-life fire images. Appl. Intell. 2022, 52, 1362–1375. [Google Scholar] [CrossRef]
- Sarıgül, M.; Ozyildirim, B.M.; Avci, M. Differential convolutional neural network. Neural Netw. 2019, 116, 279–287. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, I.; Pothuganti, K. Analysis of different convolution neural network models to diagnose Alzheimer’s disease. Mater. Today Proc. 2020. [Google Scholar] [CrossRef]
- Uyulan, C.; Ergüzel, T.T.; Unubol, H.; Cebi, M.; Sayar, G.H.; Asad, M.N.; Tarhan, N. Major depressive disorder classification based on different convolutional neural network models: Deep learning approach. Clin. EEG Neurosci. 2021, 52, 38–51. [Google Scholar] [CrossRef]
- Nanni, L.; Brahnam, S.; Paci, M.; Ghidoni, S. Comparison of Different Convolutional Neural Network Activation Functions and Methods for Building Ensembles for Small to Midsize Medical DataSets. Sensors 2022, 22, 6129. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Yan, Q.; Liu, P. An efficient fire detection method based on multiscale feature extraction, implicit deep supervision and channel attention mechanism. IEEE Trans. Image Process. 2020, 29, 8467–8475. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Zhan, J.; Zhou, G.; Chen, A.; Cai, W.; Guo, K.; Hu, Y.; Li, L. Fast forest fire smoke detection using MVMNet. Knowl.-Based Syst. 2022, 241, 108219. [Google Scholar] [CrossRef]
- Anderson, E.B.; Mitchell, J.F.; Reynol DRSFJ, H. Attentional modulation of firing rate varies with burstiness across putative pyramidal neurons in macaque visual area V4. J. Neurosci. 2011, 31, 10983–10992. [Google Scholar] [CrossRef] [PubMed]
- Cannon, J.B.; Peterson, C.J.; O’Brien, J.J.; Brewer, J.S. A review and classification of interactions between forest disturbance from wind and fire. For. Ecol. Manag. 2017, 406, 381–390. [Google Scholar] [CrossRef]
- Yu, Y.; Fu, L.; Cheng, Y.; Ye, Q. Multiview distance metric learning via independent and shared feature subspace with applications to face and forest fire recognition, and remote sensing classification. Knowl.-Based Syst. 2022, 243, 108350. [Google Scholar] [CrossRef]
- Chino, D.Y.; Avalhais, L.P.; Rodrigues, J.F.; Traina, A.J. Bowfire: Detection of fire in still images by integrating pixel color and texture analysis. In Proceedings of the 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images, Washington, DC, USA, 26–29 August 2015; pp. 95–102. [Google Scholar]
- Mlích, J.; Koplík, K.; Hradiš, M.; Zemčík, P. Fire segmentation in still images. In Proceedings of the Advanced Concepts for Intelligent Vision Systems: 20th International Conference, ACIVS 2020, Auckland, New Zealand, 10–14 February 2020; Proceedings 20. Springer International Publishing: Cham, Switzerland, 2020; pp. 27–37. [Google Scholar]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Real-time video fire/smoke detection based on CNN in antifire surveillance systems. J. Real-Time Image Process. 2021, 18, 889–900. [Google Scholar] [CrossRef]
- Shi, L.; Long, F.; Lin, C.; Zhao, Y. Video-based fire detection with saliency detection and convolutional neural networks. In Advances in Neural Networks-ISNN 2017: 14th International Symposium, ISNN 2017, Sapporo, Hakodate, and Muroran, Hokkaido, Japan, 21–26 June 2017, Proceedings, Part II 14; Springer International Publishing: Cham, Switzerland, 2017; pp. 299–309. [Google Scholar]
- Dewangan, A.; Pande, Y.; Braun, H.-W.; Vernon, F.; Perez, I.; Altintas, I.; Cottrell, G.W.; Nguyen, M.H. FIgLib & SmokeyNet: Dataset and deep learning model for real-time wildland fire smoke detection. Remote Sens. 2022, 14, 1007. [Google Scholar]
- Zhang, Q.-X.; Lin, G.-H.; Zhang, Y.-M.; Xu, G.; Wang, J.-J. Wildland forest fire smoke detection based on faster R-CNN using synthetic smoke images. Procedia Eng. 2018, 211, 441–446. [Google Scholar] [CrossRef]
- Sathishkumar, V.E.; Cho, J.; Subramanian, M.; Naren, O.S. Forest fire and smoke detection using deep learning-based learning without forgetting. Fire Ecol. 2023, 19, 9. [Google Scholar] [CrossRef]
- Alqahtani, M.M.; Dutta, A.K.; Almotairi, S.; Ilayaraja, M.; Albraikan, A.A.; Al-Wesabi, F.N.; Al Duhayyim, M. Sailfish Optimizer with EfficientNet Model for Apple Leaf Disease Detection. Comput. Mater. Contin. 2023, 75, 217–233. [Google Scholar]
- Ghali, R.; Akhloufi, M.A. Deep Learning Approaches for Wildland Fires Remote Sensing: Classification, Detection, and Segmentation. Remote Sens. 2023, 15, 1821. [Google Scholar] [CrossRef]
- Akyol, K. A comprehensive comparison study of traditional classifiers and deep neural networks for forest fire detection. Clust. Comput. 2023, 1–15. [Google Scholar] [CrossRef]
 represents the vertical weight coefficients for obtaining feature maps (v), and
represents the vertical weight coefficients for obtaining feature maps (v), and  represents the lateral weight coefficients for obtaining feature maps. ED represents the operational strategy of the Euclidean theorem.
represents the lateral weight coefficients for obtaining feature maps. ED represents the operational strategy of the Euclidean theorem.  representing the feature points retained after Euclidean distance filtering.
represents the vertical weight coefficients for obtaining feature maps (v), and represents the lateral weight coefficients for obtaining feature maps. ED represents the operational strategy of the Euclidean theorem. representing the feature points retained after Euclidean distance filtering.
representing the feature points retained after Euclidean distance filtering.
represents the vertical weight coefficients for obtaining feature maps (v), and represents the lateral weight coefficients for obtaining feature maps. ED represents the operational strategy of the Euclidean theorem. representing the feature points retained after Euclidean distance filtering.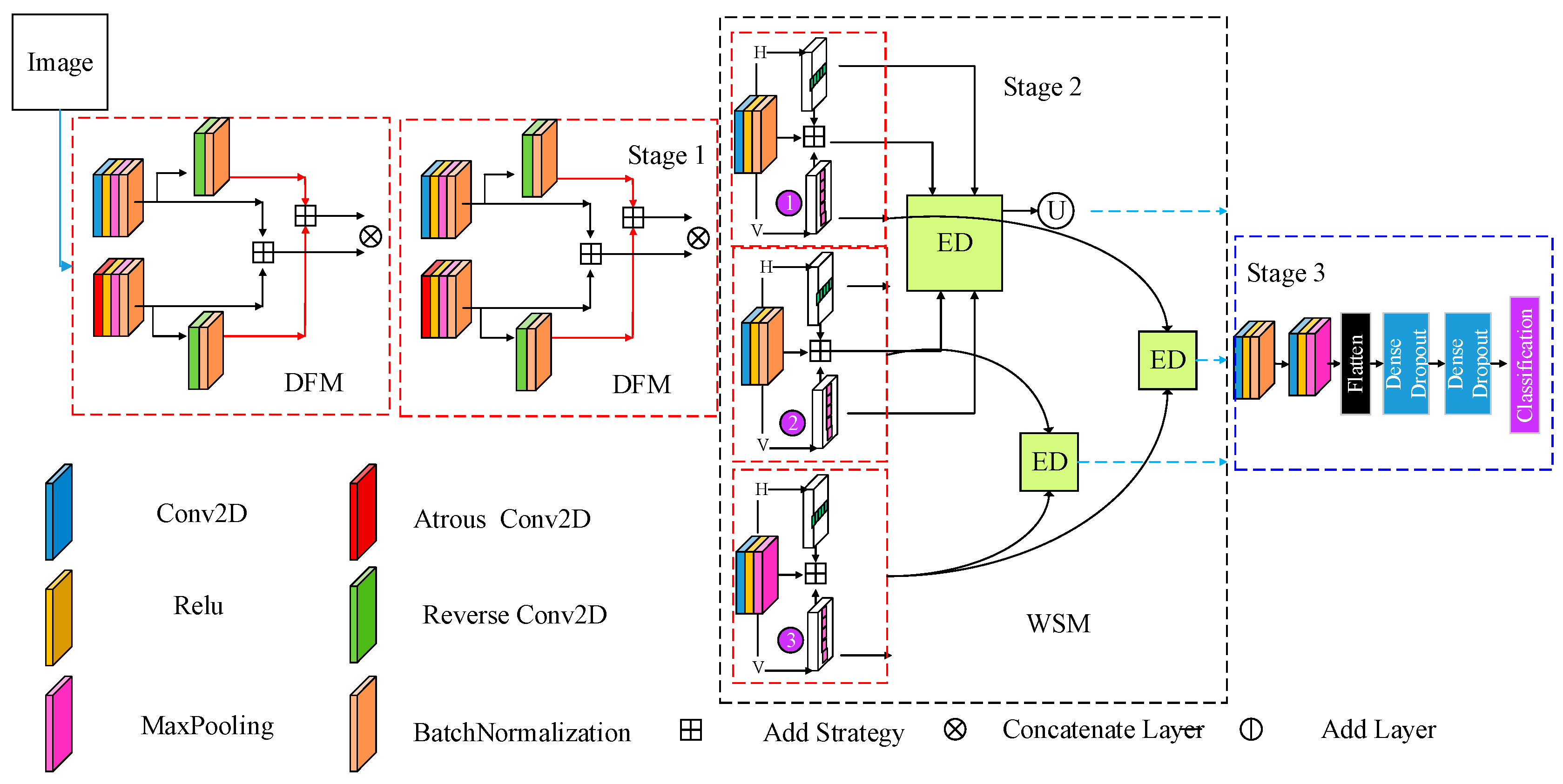







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | BoWFire Dataset | ||
|---|---|---|---|
| OA | AA | Kappa | |
| VGG16 [35] | 0.8127 | 0.8000 | 0.6041 |
| DenseNet121 [36] | 0.8231 | 0.8222 | 0.6449 |
| ResNet50 [37] | 0.7500 | 0.733 | 0.4545 |
| Xception [38] | 0.7341 | 0.7333 | 0.4674 |
| InceptionV3 | 0.8300 | 0.8220 | 0.6470 |
| EfficientNetB0 | 0.8482 | 0.8444 | 0.6902 |
| MVMNet | 0.8660 | 0.8666 | 0.7321 |
| DarkC-DCN | 0.8518 | 0.8444 | 0.6846 |
| BCFS-Net | 0.8900 | 0.8889 | 0.7761 |
| Transformer [1] | 0.8352 | 0.8244 | 0.6535 |
| TransFire [2] | 0.8437 | 0.8433 | 0.6839 |
| BCFS-Net | 0.8900 | 0.8889 | 0.7761 |
| Model | Outdoor Fire Dataset | ||
|---|---|---|---|
| OA | AA | Kappa | |
| VGG16 [35] | 0.9039 | 0.9242 | 0.7890 |
| DenseNet121 [36] | 0.9408 | 0.9545 | 0.8753 |
| ResNet50 [37] | 0.9450 | 0.9590 | 0.8900 |
| Xception [38] | 0.9355 | 0.9545 | 0.8771 |
| InceptionV3 | 0.9309 | 0.9545 | 0.8788 |
| EfficientNetB0 | 0.9548 | 0.9646 | 0.9030 |
| MVMNet | 0.9541 | 0.9545 | 0.8717 |
| DarkC-DCN | 0.9470 | 0.9545 | 0.8735 |
| BCFS-Net | 0.9777 | 0.9646 | 0.8987 |
| Transformer [1] | 0.9463 | 0.9545 | 0.8722 |
| TransFire [2] | 0.9572 | 0.9646 | 0.9041 |
| BCFS-Net | 0.9777 | 0.9646 | 0.8987 |
| Model | Fire Smoke Dataset | ||
|---|---|---|---|
| OA | AA | Kappa | |
| VGG16 [35] | 0.6870 | 0.6860 | 0.5300 |
| DenseNet121 [36] | 0.7533 | 0.7500 | 0.6250 |
| ResNet50 [37] | 0.7666 | 0.7666 | 0.6500 |
| Xception [38] | 0.7133 | 0.7133 | 0.5700 |
| InceptionV3 | 0.7840 | 0.7560 | 0.6350 |
| EfficientNetB0 | 0.7735 | 0.7733 | 0.6600 |
| MVMNet | 0.7807 | 0.7600 | 0.6400 |
| DarkC-DCN | 0.7842 | 0.7766 | 0.6650 |
| BCFS-Net | 0.8328 | 0.8166 | 0.7250 |
| Transformer [1] | 0.7546 | 0.7497 | 0.6200 |
| TransFire [2] | 0.7632 | 0.7600 | 0.6350 |
| BCFS-Net | 0.8328 | 0.8166 | 0.7250 |
| Model | Fire Smoke Dataset | |
|---|---|---|
| Params | FLOPs | |
| VGG16 | 29.53 M | 14.82 M |
| DenseNet121 | 14.78 M | 7.16 M |
| ResNet50 | 47.41 M | 23.58 M |
| Xception | 42.54 M | 21.12 M |
| InceptionV3 | 44.10 M | 21.94 M |
| EfficientNetB0 | 31.49 M | 15.73 M |
| MVMNet | 14.78 M | 7.24 M |
| DarkC-DCN | 106.22 M | 53.06 M |
| Transformer | 199.12 M | 99.03 M |
| TransFire | 217.53 M | 103.38 M |
| BCFS-Net | 14.50 M | 7.24 M |
| Model | BoWFire Dataset | ||
|---|---|---|---|
| OA | AA | Kappa | |
| BCFS-Net (T = 0.6) | 0.8450 | 0.8444 | 0.8650 |
| BCFS-Net (T = 0.5) | 0.8900 | 0.8889 | 0.7761 |
| BCFS-Net (T = 0.4) | 0.8660 | 0.8666 | 0.7321 |
| BCFS-Net (T = 0.3) | 0.8438 | 0.8444 | 0.6880 |
| BCFS-Net (T = 0.2) | 0.8231 | 0.8222 | 0.6449 |
| Model | Outdoor Fire Dataset | ||
|---|---|---|---|
| OA | AA | Kappa | |
| BCFS-Net (T = 0.6) | 0.9450 | 0.9595 | 0.8900 |
| BCFS-Net (T = 0.5) | 0.9614 | 0.9646 | 0.9017 |
| BCFS-Net (T = 0.4) | 0.9777 | 0.9646 | 0.8987 |
| BCFS-Net (T = 0.3) | 0.9650 | 0.9696 | 0.9163 |
| BCFS-Net (T = 0.2) | 0.9532 | 0.9532 | 0.9186 |
| Model | Fire Smoke Dataset | ||
|---|---|---|---|
| OA | AA | Kappa | |
| BCFS-Net (T = 0.6) | 0.7945 | 0.7900 | 0.6850 |
| BCFS-Net (T = 0.5) | 0.8103 | 0.8067 | 0.7100 |
| BCFS-Net (T = 0.4) | 0.8328 | 0.8166 | 0.7250 |
| BCFS-Net (T = 0.3) | 0.7842 | 0.7833 | 0.6750 |
| BCFS-Net (T = 0.2) | 0.7990 | 0.7990 | 0.6950 |
| Model | BoWFire Dataset | Outdoor Fire Dataset | Fire Smoke Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| OA | AA | Kappa | OA | AA | Kappa | OA | AA | Kappa | |
| RseNet18 | 0.8214 | 0.8222 | 0.6428 | 0.945 | 0.9595 | 0.8900 | 0.7350 | 0.7266 | 0.5900 |
| RseNet18 (DFM) | 0.8482 | 0.8444 | 0.6902 | 0.9614 | 0.9646 | 0.9016 | 0.7536 | 0.7433 | 0.6150 |
| RseNet18 (WSM) | 0.8300 | 0.8222 | 0.6470 | 0.9491 | 0.9646 | 0.9044 | 0.7501 | 0.7533 | 0.6300 |
| Vgg16 | 0.8127 | 0.8000 | 0.6041 | 0.9039 | 0.9242 | 0.7890 | 0.6870 | 0.6860 | 0.5300 |
| Vgg16 (DFM) | 0.8371 | 0.8333 | 0.6583 | 0.9342 | 0.9545 | 0.8821 | 0.7344 | 0.7533 | 0.6350 |
| Vgg16 (WSM) | 0.8293 | 0.8222 | 0.6426 | 0.9211 | 0.9545 | 0.8761 | 0.7135 | 0.7226 | 0.5850 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zhao, X.; Tao, Y. Integrated Algorithm Based on Bidirectional Characteristics and Feature Selection for Fire Image Classification. Electronics 2023, 12, 4566. https://doi.org/10.3390/electronics12224566
Wang Z, Zhao X, Tao Y. Integrated Algorithm Based on Bidirectional Characteristics and Feature Selection for Fire Image Classification. Electronics. 2023; 12(22):4566. https://doi.org/10.3390/electronics12224566
Chicago/Turabian StyleWang, Zuoxin, Xiaohu Zhao, and Yuning Tao. 2023. "Integrated Algorithm Based on Bidirectional Characteristics and Feature Selection for Fire Image Classification" Electronics 12, no. 22: 4566. https://doi.org/10.3390/electronics12224566
APA StyleWang, Z., Zhao, X., & Tao, Y. (2023). Integrated Algorithm Based on Bidirectional Characteristics and Feature Selection for Fire Image Classification. Electronics, 12(22), 4566. https://doi.org/10.3390/electronics12224566