1. Introduction
Mathematical expressions play a significant role in scientific communication and calculations. Mathematical Information Retrieval (MIR) is a crucial component of Information Retrieval (IR) that deals with searching for specific mathematical expressions, concepts, or objects. Efficient indexing and retrieval of mathematical expressions have become the most challenging part of MIR due to the growing use of mathematical content in various scientific documents, educational materials, and web information in MathML or LaTeX format. Many academics have been working on mathematical information retrieval research recently and have seen some success [
1,
2,
3].
Due to the two-dimensional structure of mathematical expressions and the complexity of mathematical symbol types and semantics, traditional search engines primarily designed for plain text retrieval often struggle to fulfill the required criteria. Mathematical expression retrieval encounters numerous challenges:
Mathematical Context: Understanding the context in which a mathematical expression is used is crucial, as the same notation can have different meanings in distinct mathematical subfields or domains.
Equivalent transformations of a mathematical expression: Mathematical expressions in different forms may convey the same meaning (e.g., and , and ).
Multimodal Content: Multimodal content presents mathematical expressions in various forms, in addition to textual modes like MathML and LaTeX, these expressions can also be represented through images. Different modalities of mathematical expressions exhibit distinct characteristics, necessitating the effective handling of diverse data types.
Structure Complexity: Mathematical expressions can be symbolically complex, involving nested functions, subscripts, superscripts, and specialized symbols that require intricate parsing and interpretation.
Current research in multimodal studies is expanding rapidly, exploring the integration of various data types and modes to gain a more comprehensive understanding of complex phenomena [
4,
5]. In response to the challenges outlined above, specifically Challenge 3 and Challenge 4, this paper makes the following contributions:
Introducing the image modality in mathematical expression retrieval. Images can capture the visual aspects of mathematical expressions, providing a richer and more comprehensive representation compared to plain text. Combining image modal with text modal allows a more comprehensive understanding of mathematical content. This integration can enhance retrieval accuracy by considering multiple data types simultaneously.
Building upon extracting image features from mathematical expression images, we have devised a symbol-level feature extraction method to obtain a more comprehensive set of image feature information. This enhancement ensures that the ranking results produced by the image modality retrieval module are more rational and accurate.
We employ algorithmic analysis to extract attributes from the textual modality of mathematical expressions. Subsequently, we construct a table of attributes for textual modality expressions. By introducing hesitant fuzzy sets and leveraging their advantages in handling multi-attribute evaluation criteria, we calculate the similarity between expressions.
We opt for an appropriate fusion sorting method to combine and rank the retrieval results from both image and text modalities, resulting in the final ranking outcome. Furthermore, a subset of literature from the publicly accessible ArXiv dataset was extracted and utilized to construct a dataset encompassing 592,345 mathematical expressions.
2. Related Work
Regarding mathematical expression retrieval of the text modal, expression trees are widely used for storing and processing mathematical expressions and have been applied to mathematical expression retrieval by many scholars. Goel et al. [
6] have undertaken studies on Math Word Problems, utilizing a tree-matching algorithm for the matching of mathematical expressions; they performed pair-wise matching on expression trees through post-order traversal. Pfahler et al. [
7] incorporated unsupervised embedding learning and Graph Convolutional Neural Networks (GCNNs) for learning mathematical representations. In order to facilitate effective nearest-neighbor queries, mathematical operations represented in XML format were processed as graphical data and embedded into a low-dimensional vector space. Schellenberg et al. [
8] employed substitution trees to index and retrieve mathematical expressions in LaTeX representation, but the insertion bias limits its performance. Hu et al. [
9] proposed WikiMirs, using a method of generalization that is hierarchical to produce subtrees from the representation trees of mathematical expressions, which can support substructure and similarity matching of mathematical expressions. Zhong et al. [
10] presented a dynamic pruning algorithm for inverted index, representing mathematical expressions as OPTs (Operator Trees), which improves retrieval efficiency for substructures of mathematical expressions.
Neural network methods have achieved significant progress in natural language-related tasks, but their performance on mathematical language-related tasks remains an active research area. Gao et al. [
11] proposed a formula vector generation method based on “formula2vec” by analyzing feature differences between natural and mathematical languages. In pursuit of attaining heightened semantic information during embedding, Dadure et al. [
12] proposed a contextual formula embedding method that retrieves syntactically and semantically similar formulas, sub-formulas, and parent formulas, highlighting the importance of formula context in mathematical information retrieval. Peng et al.’s MathBERT pre-training model [
13] can capture the semantic structure information of formulas by concurrently training the formulas and the contexts that relate to them. Dai [
14] proposed NTFEM, which extends N-ary tree representations of MathML formulas to one-dimensional linear sequences, uses a word embedding model to obtain the sub-structure vector, and applies a weighting function to obtain a weighted average embedding vector.
In the realm of image-based mathematical expression retrieval, Marinai et al. [
15] proposed a mathematical symbol retrieval approach based on visual bag-of-words encoding, which employed self-organizing maps to cluster shape context into appropriate visual dictionaries, facilitating efficient retrieval of mathematical symbols. Zanibbi et al. [
16] used content-based image retrieval to match binarized and decomposed query images with expression images.
In summary, current mathematical expression retrieval mainly focuses on unimodal approaches. For text modal retrieval, methods based on representation trees and neural networks embedding expressions into vectors predominate. However, these methods may overlook structural information. Image modal retrieval, on the other hand, tends to decompose mathematical expression images into symbol images or connected components for retrieval, often emphasizing symbol similarity at the expense of semantic information. To address these limitations, our study integrates image and text retrieval outcomes, achieving a multimodal retrieval model based on mathematical expression images and text. This approach considers both modalities’ similarities, leading to more rational retrieval outcomes.
In the field of Mathematical Information Retrieval (MIR), precise assessment of expression similarity holds paramount importance. While prevalent models, such as those proposed in [
13,
14], rely on cosine distance, the intricate two-dimensional characteristics of mathematical expressions demand a more objective approach. The utilization of Hesitant Fuzzy Set (HFS) theory emerges as an apt choice for addressing uncertainty and multi-attribute evaluation, offering a versatile means of representing hesitant information [
17,
18,
19,
20,
21]. The integration of HFS theory into mathematical expression retrieval enhances the holistic assessment of diverse attribute features.
3. The Proposed Model Overview
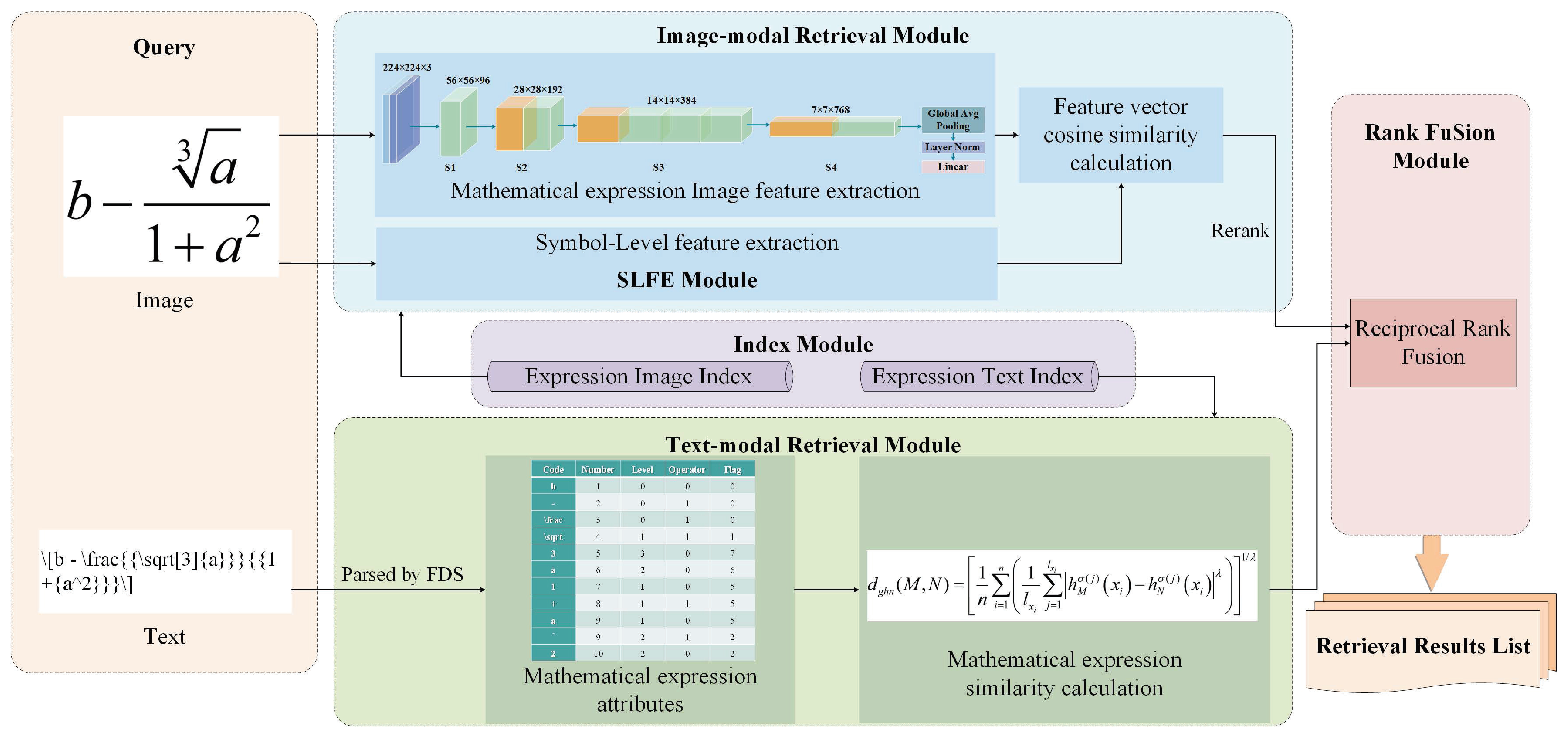
Figure 1 represents the framework diagram of the multi-modal retrieval model for mathematical expressions based on ConvNeXt and HFS. Users input images and text of query mathematical expressions and receive a ranked list after retrieval. This system retrieves mathematical expressions from both image and text modalities. In the Image-Modal Retrieval Module, ConvNeXt [
22] is used for image feature extraction and Symbol Level Features Extraction (SLFE) for symbol-level features of the mathematical expression images. Initial retrieval is conducted based on image features, followed by ranking based on symbol-level similarity, yielding descending search outcomes. In the Text-Modal Retrieval Module, the Formula Description Structure (FDS) [
23] is utilized for the analysis of textual expressions, resulting in multiple attribute features of mathematical symbols. Additionally, the Hesitant Fuzzy Set (HFS) [
24] is used to compute hesitant fuzzy similarity between mathematical query and candidate expressions, with results returned in descending similarity order. For result enhancement, the Rank Fusion Module employs Reciprocal Rank Fusion (RRF) to combine rankings generated by distinct modules.
In our research, we broaden the modal of mathematical expression retrieval to include both image and text forms, allowing retrieval from LaTeX and MathML formats. Additionally, HFS enables a flexible representation of uncertain information, facilitating a comprehensive assessment of attribute influences on decision-making. The membership degrees of mathematical expression attributes obtained through FDS analysis are computed using hesitant fuzzy sets, and the similarity between the query and candidate expressions is determined based on the HFS similarity calculation formula.
It is essential to highlight that, as of now, the method proposed in this paper faces limitations in retrieving semantically equivalent formulae to the queried ones. This is attributed to the following factors: The transformation of semantically equivalent mathematical expressions necessitates a profound understanding of domain-specific knowledge, which currently poses challenges for automated processing. The inherent semantics of mathematical expressions can be notably ambiguous, even for human comprehension, particularly when presented in isolation without adequate context. For example, the expression “” can be interpreted either as a variable “” or as a multiplication operation between “m” and “n”. This complexity further complicates machine-based semantic equivalence determination.
4. Methods
4.1. Retrieval of Mathematical Expressions in Image Modal
4.1.1. Extraction of Mathematical Expression Image Features
While meeting the requirements, the configuration of ConvNeXt-Tiny is simpler and has fewer parameters compared to other versions. It exhibits faster feature extraction capabilities, facilitating the expedited construction of feature databases. Consequently, this study employs the ConvNeXt-Tiny neural network model [
22] for feature extraction in the image modal of mathematical expressions.
Figure 2 shows the network structure of ConvNeXt-Tiny. It consists of four stages with different numbers of ConvNeXt blocks, each producing a feature map with different dimensions. It has strong feature extraction ability, few parameters, and low hardware requirements during training.
The Visual Transformer (ViT) [
25] has emerged as an effective alternative to convolutional neural networks for various computer vision tasks, exemplified by models such as the Swin Transformer [
26]. Leveraging the layer structure, downsampling techniques, activation functions, data processing methods, anti-bottleneck architecture, and deep convolution inspired by the Swin Transformer, ConvNeXt [
22] further enhances the image feature extraction performance.
After extracting image features using the Convnext network, an image feature index is constructed. During retrieval, cosine distance is employed to calculate the similarity between feature vectors.
4.1.2. Symbol-Level Feature Extraction Module
Compared with other types of images, mathematical expression images have unique features, and the extraction of symbol-level features is helpful to the retrieval of mathematical expressions. Mathematical expressions are distinct in their two-dimensional structure, complex symbols, and specific spatial arrangements. To accurately retrieve and evaluate mathematical expressions, it is essential to capture the symbol-level details, which are crucial for understanding their meaning and structure.
The Symbol Level Features Extraction (SLFE) module extracts symbol-level features from mathematical expression images by segmenting the input image into individual symbol blocks. Given a query image of a mathematical expression
, consider
as the set of symbol blocks representing expression elements and
n as representing the total count of these symbol blocks (
). Position vectors are calculated for element symbol blocks to retain spatial information. We use the connected component labeling algorithm to obtain element symbol blocks in mathematical expression images [
27].
Figure 3a shows attached symbols “a” and “c”, which are separated using the connected component labeling algorithm (
Figure 3b). Each resulting component forms an element symbol block of
pixels. Position vectors
of the element symbol block
are computed for the symbol block set
S, where
represents the position vector for the j-th element symbol block (
Figure 4).
Here
,
,
, and
represent the distance between the top, down, left, and right edges of the j-th element symbol block and the top and left edges of the query image
. The position vector elements are standardized to range between 0 and 1 using Equation (
1), where
,
,
are the height-to-width ratio of
, for recording the size proportion of the expression.
In this study, we created a database of indexed mathematical expression images with their image features and symbol-level features. During the query process, we retrieve results based on image feature similarity, then sort by symbol-level feature similarity before outputting the final results.
4.2. Retrieval of Mathematical Expressions in Text Modal
4.2.1. Parsing and Extraction of Textual Attributes in Mathematical Expressions
The FDS [
23] is used to analyze mathematical expressions and extract their properties. Each symbol in the expression has four attribute values: Number, Level, Operator, and Flag. As shown in Equation (
2), the attributes obtained by parsing and extraction using FDS are represented as a quadruple array.
The meaning of each attribute value is as follows: (1)
denotes the sequence number of
in the expression. (2)
represents the horizontal baseline position of the symbol
in the expression, as shown in
Figure 5. (3)
is the function code of
, indicating whether the current symbol is an operator (
) or an operand (
). (4)
is the spatial flag information of
, which shows how the present symbol and the prior symbol are related.
can take values from 1 to 8, representing “above”, “superscript”, “right”, “subscript”, “below”, “contains”, “left-superscript”, and “left-subscript”. The main baseline’s symbols have
.
4.2.2. Text Similarity Calculation of Mathematical Expressions
FDS analysis on mathematical expressions yields four attribute values. A single distance calculation may introduce errors in similarity measurement. A fuzzy set [
28] is a group of items with a variety of membership grades. To deal with multi-attribute evaluation indicators, we used hesitant fuzzy sets proposed by Torra [
24] to calculate the similarity.
Definition 1. Let X be a non-empty set. A hesitant fuzzy set [29] H is defined as follows: In this context,
is the hesitant fuzzy element, which is a set of several possible degrees of membership of an element x in the set
H of the elements in
[
29]. Its value range is [0,1].
Let M and N be hesitant fuzzy sets on the non-empty set
. The generalized hesitant fuzzy standard distance and similarity [
29] between M and N are respectively defined as:
In this equation,
denotes the generalized hesitant fuzzy standard distance between hesitant fuzzy sets M and N, while
represents their corresponding similarity [
29].
, when
,
is the hesitant fuzzy Hamming distance, and when
,
is the hesitant fuzzy Euclidean distance;
and
refer to the j-th largest element values in
and
, respectively. Additionally,
and
represent the number of elements in
and
, respectively.
.
The mathematical expression of the four-tuple attribute
obtained from FDS analysis is used to construct a hesitant fuzzy element set
as an evaluation attribute.
represent the hesitant fuzzy membership functions corresponding to each evaluation attribute, as shown in
Table 1.
Definition 2. Let be a query expression, be a dataset containing n mathematical expressions.
Definition 3. The formula for calculating the similarity between two mathematical expressions is as follows: Here, and represent the sets of hesitant fuzzy elements corresponding to and , respectively. The elements in and represent the membership degrees of each attribute value of expressions and , respectively. represents the number of evaluated attribute values, and represent the degree of membership values of the -th factor in and , respectively.
4.3. Ranking Fusion of Multi-Modal Retrieval Results
The Reciprocal Rank Fusion (RRF) [
30] combines the image and text modal retrieval ranking. We use Equation (
7) to calculate the fusion score
of a mathematical expression
e, based on the retrieval ranking
and a constant k to reduce the influence of highly scored documents.
To determine the optimal value for
k, we conducted experiments with various values. The experimental results are presented in
Table 2. As seen in
Table 2, with the increase in the value of
k, the MAP obtained from the fusion results initially increases and then decreases. The maximum MAP value is achieved at
k = 60. Therefore, in our experiments, we choose a value of
k equal to 60.
Illustratively, taking the query expression “
” as an example, the top 5 mathematical expression IDs, ranks, and fusion scores for multimodal retrieval results are presented in
Table 3. This culminates in a retrieval ranking of {3,4,2,1,6,5}. In this case, the top five results in the image-modal retrieval did not include the mathematical expression with ID = 5. However, the top five results in the text-modal retrieval contained the expression with ID = 5. This discrepancy might be due to the image modality retrieval method ranking this candidate expression lower (beyond the 5th position), resulting in a score of 0 in the image modality retrieval calculation. Consequently,
.
This method is not affected by similarity scores and only depends on the ranking of retrieval results. It gives higher rankings to result items that a ranking model strongly prefers and ranks result items that are weakly preferred by multiple models less highly.
5. Experimental Results and Discussion
5.1. Experimental Dataset and Environment
We obtained 592,345 mathematical expressions from 14,274 articles in the ArXiv, a free and open dataset created by Cornell University researchers, and extracted 250,045 expressions from 11,770 articles in the NTCIR-mair-Wikipedia-corpus (NTCIR). We employ the method proposed by Xu et al. [
31] to extract mathematical expressions images from scientific literature. The expressions are stored in both image and LaTeX text formats. The experimental environment is shown in
Table 4.
5.2. Evaluation Protocol and Metrics
We randomly select ten representative mathematical expressions from the dataset for our experiments, as shown in
Table 5. We employ Mean Average Precision (MAP) and Discounted Cumulative Gain (DCG) [
32] to evaluate the effectiveness of our method in this paper. Three graduate students majoring in computer science have assigned a relevance judgment to the top 20 retrieval results for query expressions. Relevance judgments range from 1 (irrelevant) to 5 (highly relevant) based on the top-k retrieval results for all queries. This approach simulates user assessment of retrieval results and allows us to calculate Average Precision (AP), MAP, and nDCG to evaluate the effectiveness of our model.
5.3. System Experiment
The average precision and MAP were calculated for ten query expressions, as shown in
Table 6.
Because there were more similar expressions in the ArXiv dataset, the results were consistently better than those from the NTCIR dataset. The low P@20 values are because there are fewer than 20 expressions in the dataset which are highly similar to some complex queries.
5.4. Ablation Experiments
Through experiments, we observed that the SLFE module prioritizes results that exhibit greater structural and length similarity to the query expression. The relevance scores of the retrieved expressions were used to calculate P@k, MAP@10, and nDCG@10 values. We evaluated the impact of SLFE re-ranking on image-modal retrieval by comparing P@k, MAP@10, and nDCG@10 values. The results in
Figure 6 show that SLFE significantly improves both retrieval accuracy and ranking results by attending to symbol-level features.
The image-modal retrieval method is Method 1, the text-modal retrieval method is Method 2, and the image-text modal RRF method is Method 3. For the query
, the top 5 results from Method 1 and Method 2 are shown in
Table 7. Both methods retrieve exact matches as the first formula. Method 1 places a stronger emphasis on the structural information of mathematical expressions. For instance, because the candidate expression
closely aligns with the query expression
in terms of structure, it is ranked higher. Additionally, method 1 can retrieve formulas that share the same structure but have different symbolic representations, such as expression
. On the other hand, method 2 prioritizes the symbols within the expressions, such as candidate expressions that all contain
.
The average P@k and MAP@k of the three methods are summarized in
Figure 7. Text-modal retrieval outperformed image-modal retrieval because FDS is more concerned with the type of the symbol itself (e.g., whether the symbol is an operator, operand, constant, or variable). However, we found that within the results of image modality retrieval, expressions more structurally similar to the query image are ranked higher. This suggests that image modality retrieval methods are more adept at capturing structural information inherent in expressions. The integration of both modalities can lead to more accurate and effective retrieval results. The image-text modal RRF method was effective, as the fusion ranking of two modal retrieval results was better than the single modal retrieval ranking, demonstrating the complementary results of the two modal retrievals.
5.5. Contrast Experiments
SearchOnMath [
33] is a retrieval tool for scientific literature and Wikipedia pages based on mathematical expressions. Tangent-CFT [
34] is a mathematical expression embedding model that represents mathematical expressions using Operator trees (OPTs) and Symbol Layout Trees (SLT) and ultimately generates formula embeddings using fastText. Experimental trials were conducted utilizing the mathematical expressions from
Table 5. A comparative analysis was performed between our proposed approach and other methods. The results for MAP@k and average P@k are presented in
Table 8. The proposed image-text modal RRF method achieves an accuracy of 0.660 and an average precision of 0.774 for the top 10 results. The nDCG@10 results for each expression retrieval outcome under various methods are depicted in
Figure 8.
The method proposed in this paper, which combines the attribute features of mathematical expression text and images, is able to simultaneously consider both the holistic characteristics and symbol-level features of the image modality, as well as the symbol types characteristic of the text modality. This results in ranking outcomes that better align with user requirements. Therefore, the NDCG@10 value of the method proposed in this paper is generally higher compared to the contrastive methods. In comparison to the SearchOnMath and Tangent-CFT methods, our approach offers user convenience, avoiding the cumbersome manual input of mathematical expressions. Additionally, it effectively balances the structural information of the image modality and the symbolic attributes of the text modality, optimizing the output ranking. Consequently, it efficiently circumvents the issue of mathematical expression text losing structural features.
6. Conclusions
We have constructed a multimodal mathematical expression retrieval model by leveraging the RRF method to fuse the retrieval results from both image and text modalities. In this model, the image-modal retrieval module employs the ConvNext and SLDE modules to extract mathematical expression image features and symbol-level features, respectively. Based on the similarity of these features, the results are then outputted in descending order. Meanwhile, the text-modal retrieval module analyzes and extracts attribute values of textual expressions using FDS. To determine the hesitant fuzzy similarity between the candidate expression and the mathematical query expression, the hesitant fuzzy set theory is introduced in the meantime. The RRF amalgamates image and text modality retrieval outcomes, culminating in the ultimate combined result. Concurrently, a subset of literature from the publicly accessible ArXiv dataset was extracted and utilized to construct a dataset encompassing 592,345 mathematical expressions.
The multimodal retrieval model eliminates constraints on the user’s input modalities for mathematical query expressions, thereby ensuring a comprehensive evaluation of both modality similarities. This approach enhances the rationality of retrieval outcomes.
In the future, our research will further explore multimodal mathematical expression retrieval in the following areas:
Enhancing image modality feature extraction by incorporating contextual parsing of mathematical expressions, thereby preserving a richer semantic understanding.
Extending the application of the proposed method to scientific literature retrieval. This involves integrating mathematical expressions with intrinsic attributes of scientific literature, including keywords, to enhance retrieval accuracy during scientific literature searches.
Author Contributions
Data curation, R.L. and J.W.; Formal analysis, R.L., J.W. and X.T.; Funding acquisition, X.T.; Investigation, R.L.; Methodology, R.L., J.W. and X.T.; Software, R.L.; Supervision, X.T.; Validation, R.L. and X.T.; Visualization, R.L. and X.T.; Writing—original draft, R.L.; Writing—review & editing, R.L., J.W. and X.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the Natural Science Foundation of Hebei Province of China (Grant No. F2019201329).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available upon request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, X.; Zhu, Y.; Liu, S.; Ju, J.; Qu, Y.; Cheng, G. Dyrren: A dynamic retriever-reranker-generator model for numerical reasoning over tabular and textual data. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 13139–13147. [Google Scholar]
- Satpute, A.; Greiner-Petter, A.; Schubotz, M.; Meuschke, N.; Aizawa, A.; Gipp, B. TEIMMA: The First Content Reuse Annotator for Text, Images, and Math. arXiv 2023, arXiv:2305.13193. [Google Scholar]
- Gipp, B.; Greiner-Petter, A.; Schubotz, M.; Meuschke, N. Methods and Tools to Advance the Retrieval of Mathematical Knowledge from Digital Libraries for Search-, Recommendation-, and Assistance-Systems. arXiv 2023, arXiv:2305.07335. [Google Scholar]
- Xu, P.; Zhu, X.; Clifton, D.A. Multimodal learning with transformers: A survey. arXiv 2023, arXiv:2206.06488. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, M.; Matsuo, Y. A survey of multimodal deep generative models. Adv. Robot. 2022, 36, 261–278. [Google Scholar] [CrossRef]
- Goel, M.; Goyal, V.; Venktesh, V. MWPRanker: An Expression Similarity Based Math Word Problem Retriever. arXiv 2023, arXiv:2307.01240. [Google Scholar]
- Pfahler, L.; Morik, K. Self-Supervised Pretraining of Graph Neural Network for the Retrieval of Related Mathematical Expressions in Scientific Articles. arXiv 2022, arXiv:2209.00446. [Google Scholar]
- Schellenberg, T.; Yuan, B.; Zanibbi, R. Layout-based substitution tree indexing and retrieval for mathematical expressions. In Proceedings of the Document Recognition and Retrieval XIX, SPIE, Burlingame, CA, USA, 25–26 January 2012; Volume 8297, pp. 126–133. [Google Scholar]
- Hu, X.; Gao, L.; Lin, X.; Tang, Z.; Lin, X.; Baker, J.B. Wikimirs: A mathematical information retrieval system for wikipedia. In Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries, Indianapolis, IN, USA, 22–26 July 2013; pp. 11–20. [Google Scholar]
- Zhong, W.; Rohatgi, S.; Wu, J.; Giles, C.L.; Zanibbi, R. Accelerating substructure similarity search for formula retrieval. In Proceedings of the Advances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–7 April 2020; pp. 714–727. [Google Scholar]
- Gao, L.; Jiang, Z.; Yin, Y.; Yuan, K.; Yan, Z.; Tang, Z. Preliminary Exploration of Formula Embedding for Mathematical Information Retrieval: Can mathematical formulae be embedded like a natural language? arXiv 2017, arXiv:1707.05154. [Google Scholar]
- Dadure, P.; Pakray, P.; Bandyopadhyay, S. Embedding and generalization of formula with context in the retrieval of mathematical information. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 6624–6634. [Google Scholar] [CrossRef]
- Peng, S.; Yuan, K.; Gao, L.; Tang, Z. Mathbert: A pre-trained model for mathematical formula understanding. arXiv 2021, arXiv:2105.00377. [Google Scholar]
- Dai, Y.; Chen, L.; Zhang, Z. An N-ary tree-based model for similarity evaluation on mathematical formulae. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 2578–2584. [Google Scholar]
- Marinai, S.; Miotti, B.; Soda, G. Mathematical symbol indexing using topologically ordered clusters of shape contexts. In Proceedings of the 2009 10th International Conference on Document Analysis and Recognition, Barcelona, Spain, 26–29 July 2009; pp. 1041–1045. [Google Scholar]
- Zanibbi, R.; Yuan, B. Keyword and image-based retrieval of mathematical expressions. In Proceedings of the Document Recognition and Retrieval XVIII, SPIE, San Francisco, CA, USA, 26–27 January 2011; Volume 7874, pp. 141–149. [Google Scholar]
- Torra, V.; Narukawa, Y. On hesitant fuzzy sets and decision. In Proceedings of the 2009 IEEE International Conference on Fuzzy Systems, Jeju Island, Republic of Korea, 20–24 August 2009; pp. 1378–1382. [Google Scholar]
- Farhadinia, B.; Aickelin, U.; Khorshidi, H.A. Uncertainty measures for probabilistic hesitant fuzzy sets in multiple criteria decision making. Int. J. Intell. Syst. 2020, 35, 1646–1679. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, X. A new hesitant fuzzy linguistic approach for multiple attribute decision making based on Dempster–Shafer evidence theory. Appl. Soft Comput. 2020, 86, 105897. [Google Scholar] [CrossRef]
- Farhadinia, B.; Aickelin, U.; Khorshidi, H.A. Higher order hesitant fuzzy Choquet integral operator and its application to multiple criteria decision making. arXiv 2020, arXiv:2011.08183. [Google Scholar]
- Cai, L. Interval-Valued Hesitant Fuzzy Sets and Its Application to Decision Making. Ph.D. Thesis, Zhengzhou University, Zhengzhou, China, 2013. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Tian, X. A mathematical indexing method based on the hierarchical features of operators in formulae. In Proceedings of the 2nd International Conference on Automatic Control and Information Engineering (ICACIE 2017), Hong Kong, China, 26–28 August 2017; pp. 49–52. [Google Scholar]
- Torra, V. Hesitant fuzzy sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Samet, H.; Tamminen, M. Efficient component labeling of images of arbitrary dimension represented by linear bintrees. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 579–586. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Xu, Z.; Xia, M. Distance and similarity measures for hesitant fuzzy sets. Inf. Sci. 2011, 181, 2128–2138. [Google Scholar] [CrossRef]
- Cormack, G.V.; Clarke, C.L.; Buettcher, S. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 758–759. [Google Scholar]
- Xu, X.; Tian, X.; Yang, F. A retrieval and ranking method of mathematical documents based on CA-YOLOv5 and HFS. Math. Biosci. Eng. 2022, 19, 4976–4990. [Google Scholar] [CrossRef] [PubMed]
- Jarvelin, K.; Kekalainen, J. IR evaluation methods for retrieving highly relevant documents. In Proceedings of the ACM SIGIR Forum; ACM: New York, NY, USA, 2017; Volume 51, pp. 243–250. [Google Scholar]
- Oliveira, R.M.; Gonzaga, F.B.; Barbosa, V.C.; Xexéo, G.B. A distributed system for SearchOnMath based on the Microsoft BizSpark program. arXiv 2017, arXiv:1711.04189. [Google Scholar]
- Mansouri, B.; Rohatgi, S.; Oard, D.W.; Wu, J.; Giles, C.L.; Zanibbi, R. Tangent-CFT: An embedding model for mathematical formulas. In Proceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval, Santa Clara, CA, USA, 2–5 October 2019; pp. 11–18. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}