
Blind Super-Resolution Network with Dual-Channel Attention for Images Captured by Sub-Millimeter-Diameter Fiberscope

 ,
,
Abstract
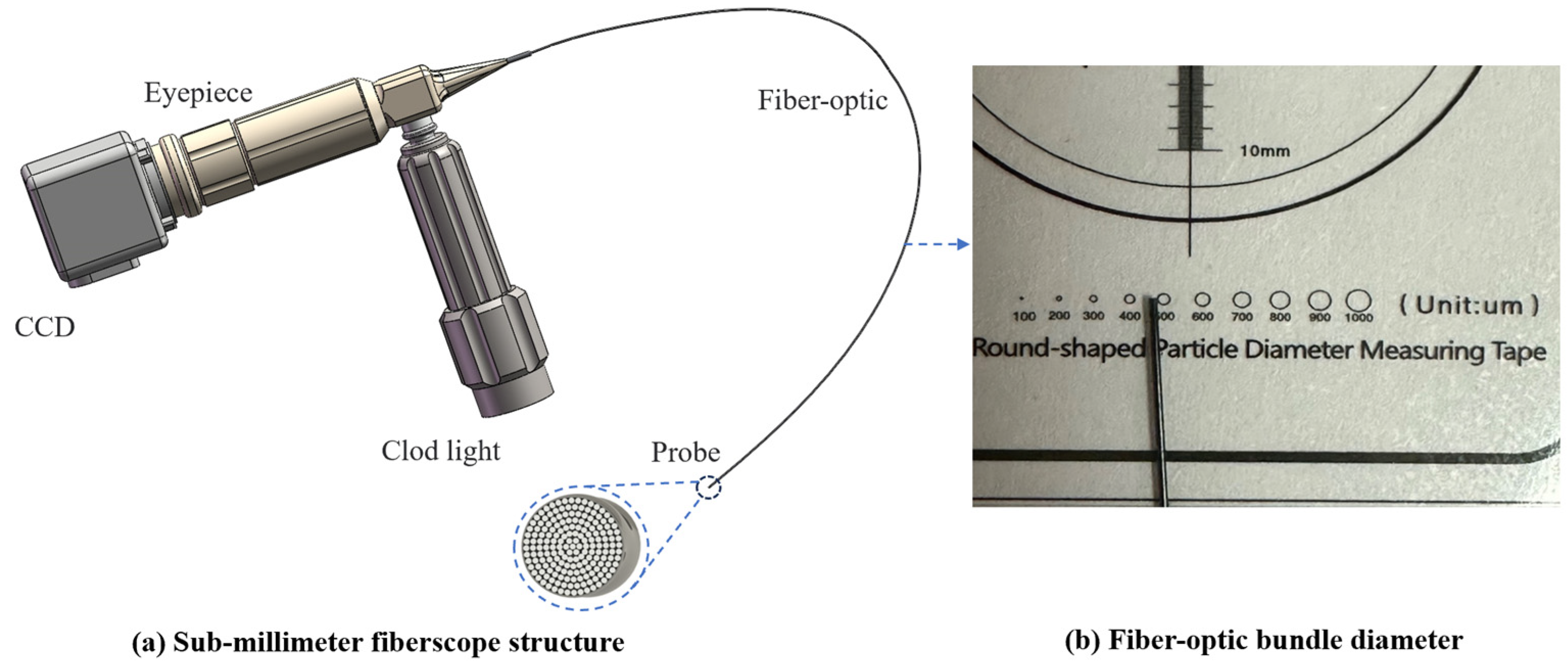
:1. Introduction
- The acquired sub-millimeter-diameter fiberscope images were Fourier transformed, and the reticulated noise was reduced from the images by employing a Butterworth band-stop filter in the frequency domain.
- To prevent the resulting image from becoming smooth and to preserve more details, the perceptual loss based on image features is employed as a loss function throughout the model training phase. In addition, the generated image gets more realistic by concentrating on the perceived quality of the image.
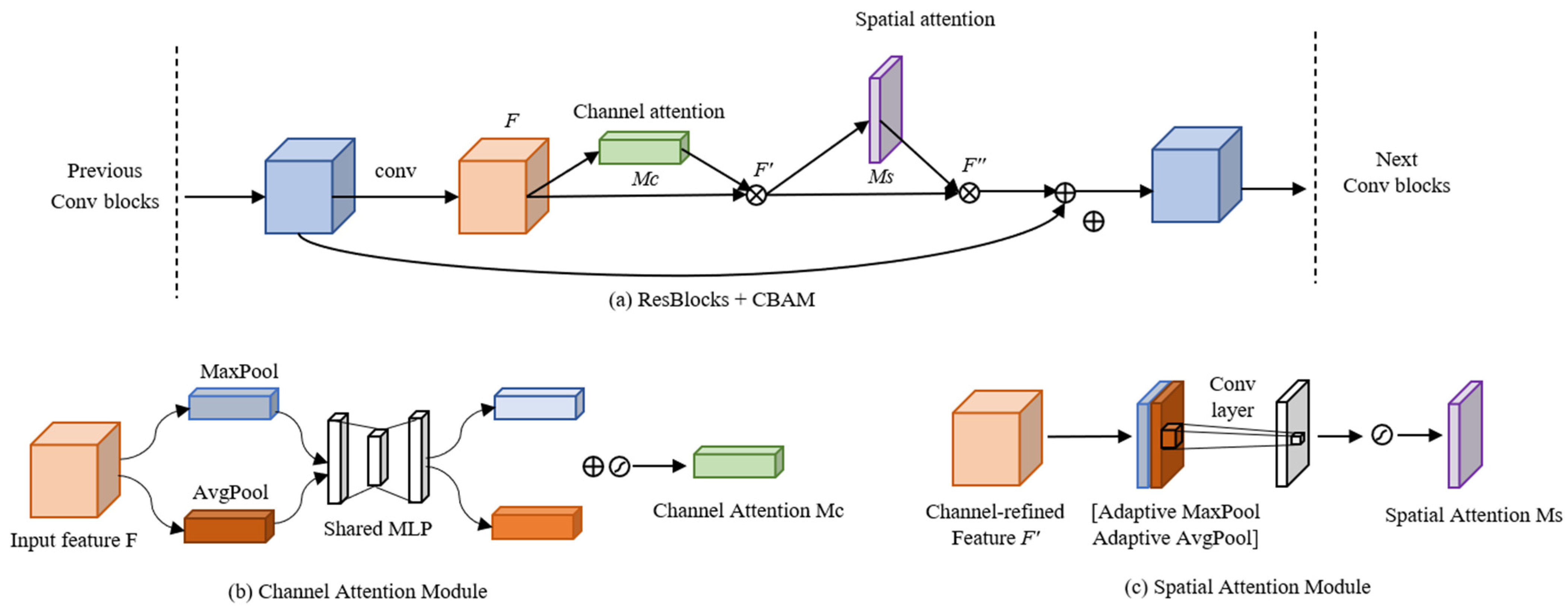
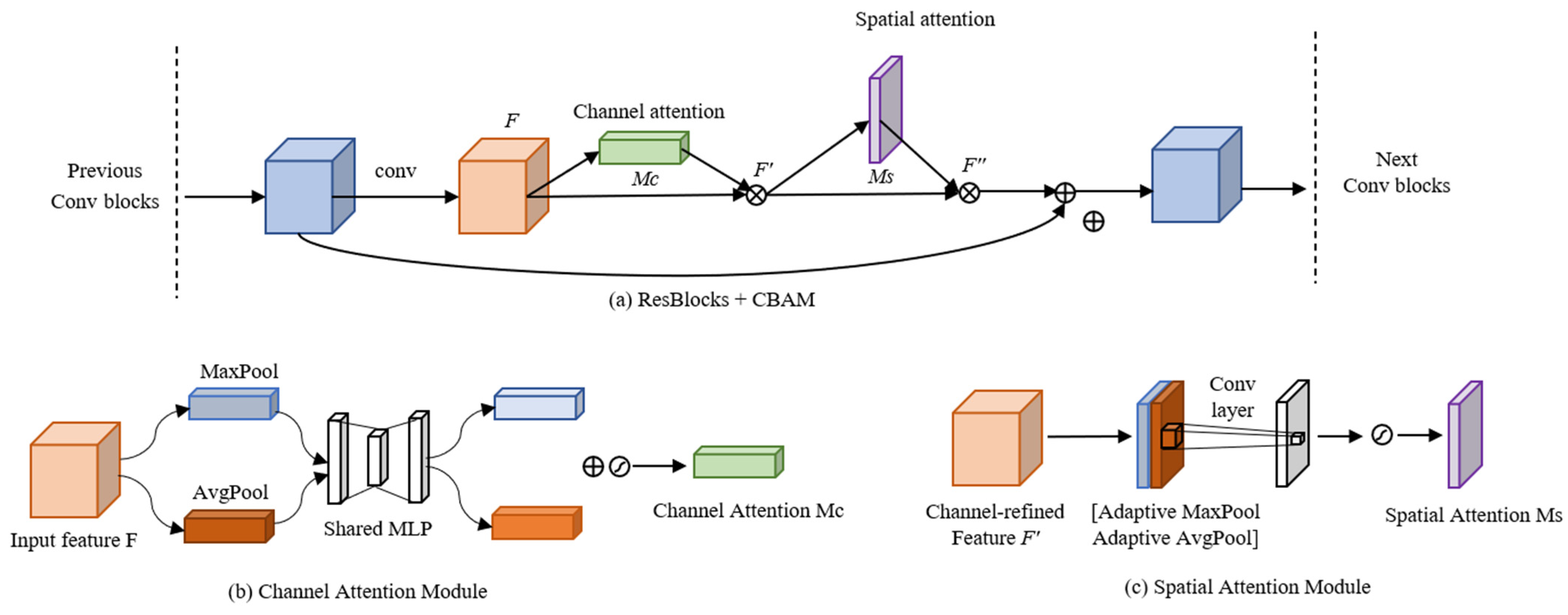
- The generalization and robustness of the model are enhanced by adding spatial and channel attention mechanisms. In this way, the model’s attention is drawn more to the image’s more crucial regions and channel characteristics when reconstructing the image.
2. Experimental Principle and Method
2.1. Butterworth Band-Stop Filter
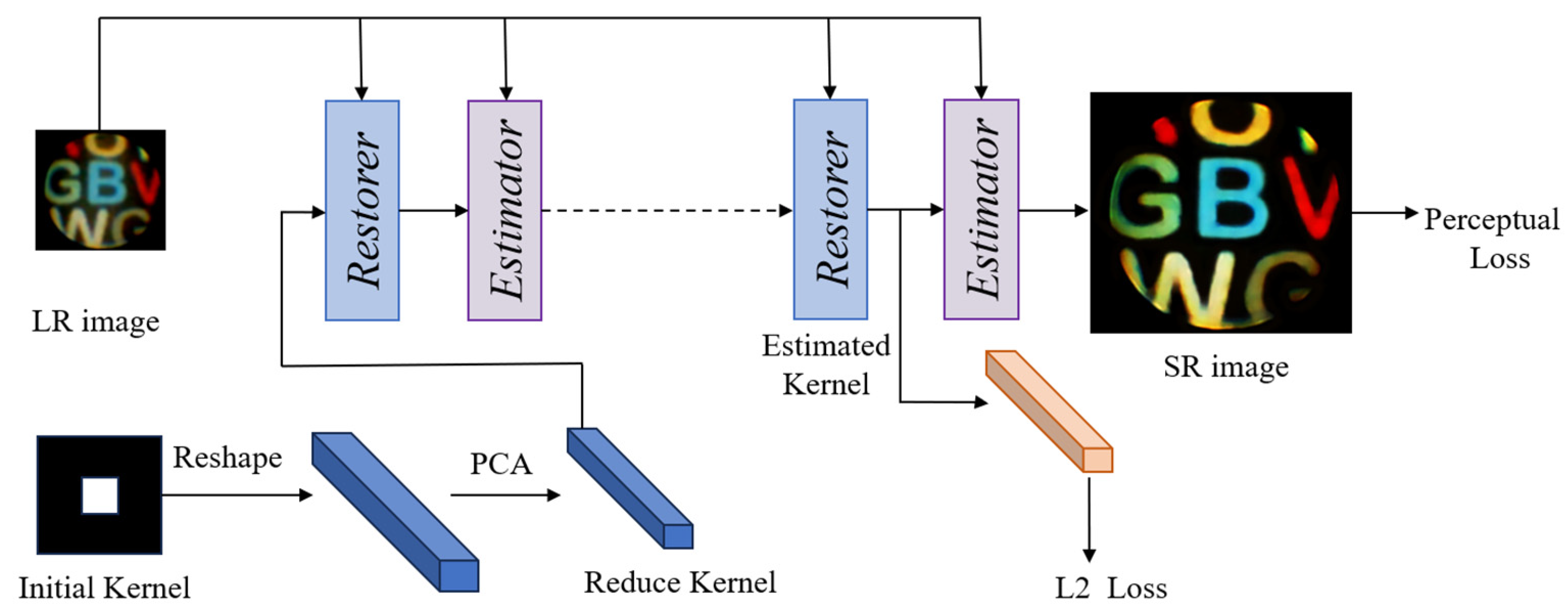
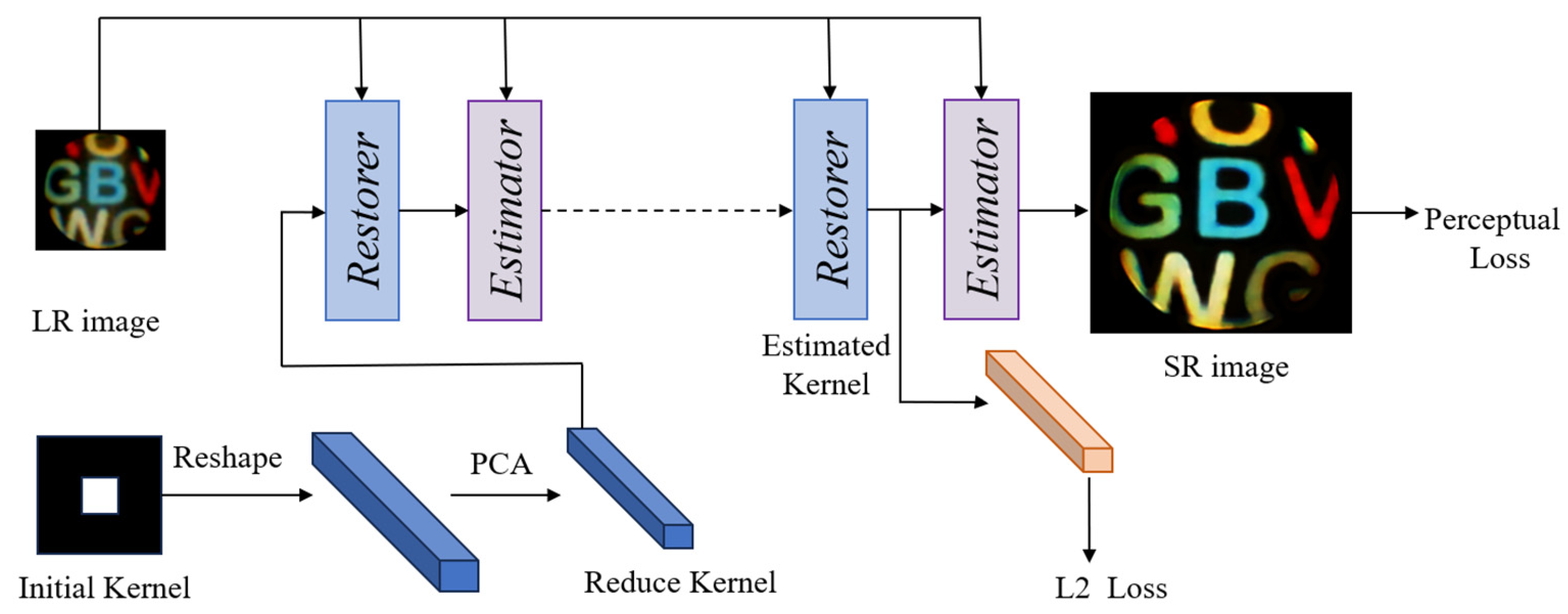
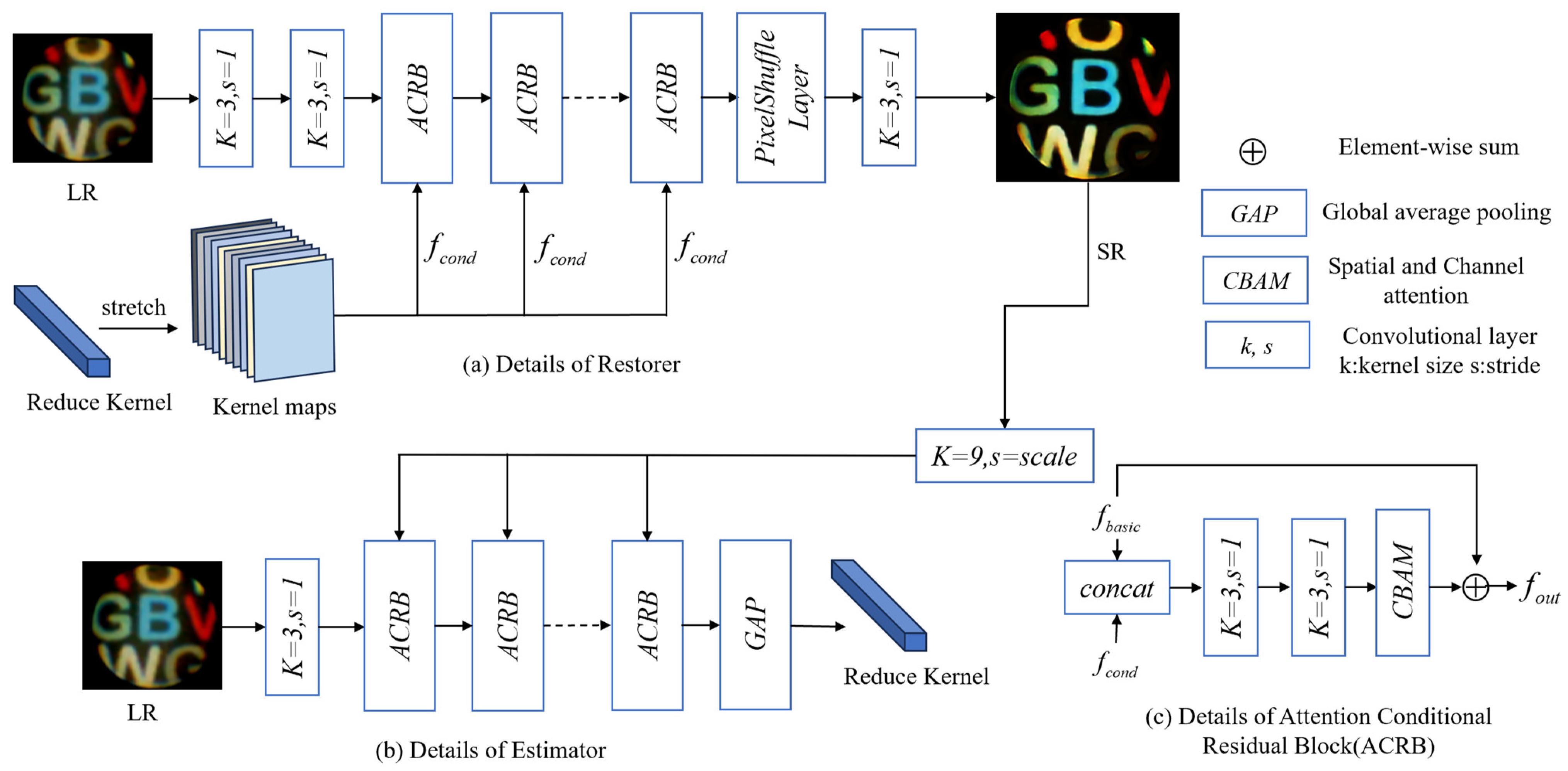
2.2. Blind Super-Resolution Network with Dual-Channel Attention
3. Experimental Results and Discussion
3.1. Dataset and Parameter Settings
3.2. Public Dataset Experimental Results
3.3. Real Image Experimental Results
3.4. Speed of Real Image Inference
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, J.; Wu, J.; Wu, S.; Goswami, R.; Girardo, S.; Cao, L.; Guck, J.; Koukourakis, N.; Czarske, J.W. Quantitative phase imaging through an ultra-thin lensless fiber endoscope. Light Sci. Appl. 2022, 11, 204. [Google Scholar] [CrossRef] [PubMed]
- Kuschmierz, R.; Scharf, E.; Ortegón-González, D.F.; Glosemeyer, T.; Czarske, J.W. Ultra-thin 3D lensless fiber endoscopy using diffractive optical elements and deep neural networks. Light Adv. Manuf. 2021, 2, 415–424. [Google Scholar] [CrossRef]
- Fröch, J.E.; Huang, L.; Tanguy, Q.A.; Colburn, S.; Zhan, A.; Ravagli, A.; Seibel, E.J.; Böhringer, K.F.; Majumdar, A. Real time full-color imaging in a meta-optical fiber endoscope. eLight 2023, 3, 13. [Google Scholar] [CrossRef]
- Ali, M.; Yaeger, K.; Ascanio, L.; Troiani, Z.; Mocco, J.; Kellner, C.P. Early minimally invasive endoscopic intracerebral hemorrhage evacuation. World Neurosurg. 2021, 148, 115. [Google Scholar] [CrossRef] [PubMed]
- McGoran, J.J.; McAlindon, M.E.; Iyer, P.G.; Seibel, E.J.; Haidry, R.; Lovat, L.B.; Sami, S.S. Miniature gastrointestinal endoscopy: Now and the future. World J. Gastroenterol. 2019, 25, 4051. [Google Scholar] [CrossRef] [PubMed]
- Sekuboyina, A.K.; Devarakonda, S.T.; Seelamantula, C.S. A convolutional neural network approach for abnormality detection in wireless capsule endoscopy. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, VIC, Australia, 18–21 April 2017; pp. 1057–1060. [Google Scholar]
- Chen, J.; Kang, X.; Liu, Y.; Wang, Z.J. Median filtering forensics based on convolutional neural networks. IEEE Signal Process. Lett. 2015, 22, 1849–1853. [Google Scholar] [CrossRef]
- Thanh, D.N.; Engínoğlu, S. An iterative mean filter for image denoising. IEEE Access 2019, 7, 167847–167859. [Google Scholar]
- Zhang, P.; Li, F. A new adaptive weighted mean filter for removing salt-and-pepper noise. IEEE Signal Process. Lett. 2014, 21, 1280–1283. [Google Scholar] [CrossRef]
- Kumar, A.; Sodhi, S.S. Comparative analysis of gaussian filter, median filter and denoise autoenocoder. In Proceedings of the 2020 7th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 12–14 March 2020; pp. 45–51. [Google Scholar]
- Broughton, S.A.; Bryan, K. Discrete Fourier Analysis and Wavelets: Applications to Signal and Image Processing; John Wiley & Sons: New York, NY, USA, 2018. [Google Scholar]
- Liu, M.; Wei, Y. Image denoising using graph-based frequency domain low-pass filtering. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019; pp. 118–122. [Google Scholar]
- Sa, Y. Improved bilinear interpolation method for image fast processing. In Proceedings of the 2014 7th International Conference on Intelligent Computation Technology and Automation, Changsha, China, 25–26 October 2014; pp. 308–311. [Google Scholar]
- Fadnavis, S. Image interpolation techniques in digital image processing: An overview. Int. J. Eng. Res. Appl. 2014, 4, 70–73. [Google Scholar]
- Glasner, D.; Bagon, S.; Irani, M. Super-resolution from a single image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 349–356. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 391–407. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejan, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3262–3271. [Google Scholar]
- Gu, J.; Lu, H.; Zuo, W.; Dong, C. Blind super-resolution with iterative kernel correction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1604–1613. [Google Scholar]
- Zhang, K.; Liang, J.; Van Gool, L.; Timofte, R. Designing a practical degradation model for deep blind image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4791–4800. [Google Scholar]
- Huang, Y.; Li, S.; Wang, L.; Tan, T. Unfolding the alternating optimization for blind super resolution. Adv. Neural Inf. Process. Syst. 2020, 33, 5632–5643. [Google Scholar]
- Roonizi, A.K.; Jutten, C. Band-stop smoothing filter design. IEEE Trans. Signal Process. 2021, 69, 1797–1810. [Google Scholar] [CrossRef]
- Yamawaki, K.; Sun, Y.; Han, X.H. Blind image super resolution using deep unsupervised learning. Electronics 2021, 10, 2591. [Google Scholar] [CrossRef]
- Fan, L.; Zhang, F.; Fan, H.; Zhang, C. Brief review of image denoising techniques. Vis. Comput. Ind. Biomed. Art 2019, 2, 1–12. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lu, E.; Hu, X. Image super-resolution via channel attention and spatial attention. Appl. Intell. 2022, 52, 2260–2268. [Google Scholar] [CrossRef]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; Gil, D.; Rodríguez, C.; Vilariño, F. WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Comput. Med. Imaging Graph. 2015, 43, 99–111. [Google Scholar] [CrossRef] [PubMed]
- Pogorelov, K.; Randel, K.R.; Griwodz, C.; Eskeland, S.L.; de Lange, T.; Johansen, D.; Spampinato, C.; Dang-Nguyen, D.-T.; Lux, M.; Schmidt, P.T.; et al. Kvasir: A multi-class image dataset for computer aided gastrointestinal disease detection. In Proceedings of the 8th ACM on Multimedia Systems Conference, New York, NY, USA, 20–30 June 2017; pp. 164–169. [Google Scholar]
- Erfurt, J.; Helmrich, C.R.; Bosse, S.; Schwarz, H.; Marpe, D.; Wiegand, T. A study of the perceptually weighted peak signal-to-noise ratio (WPSNR) for image compression. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2339–2343. [Google Scholar]
- Mudeng, V.; Kim, M.; Choe, S. Prospects of structural similarity index for medical image analysis. Appl. Sci. 2022, 12, 3754. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Xue, W.; Mou, X.; Zhang, L.; Bovik, A.C.; Feng, X. Blind image quality assessment using joint statistics of gradient magnitude and Laplacian features. IEEE Trans. Image Process. 2014, 23, 4850–4862. [Google Scholar] [CrossRef]
- Tsai, D.Y.; Lee, Y.; Matsuyama, E. Information entropy measure for evaluation of image quality. J. Digit. Imaging 2008, 21, 338–347. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method/Datasets | Set5 | Set14 | BSD100 | Kvasir-Sessile |
|---|---|---|---|---|
| Bicubic | 26.75/0.85 | 24.76/0.78 | 24.69/0.77 | 23.78/0.74 |
| SRCNN | 27.95/0.89 | 26.13/0.62 | 25.38/0.61 | 24.61/0.59 |
| ESPCN | 28.67/0.77 | 27.92/0.74 | 26.87/0.74 | 26.13/0.65 |
| SRGAN | 30.15/0.81 | 28.14/0.72 | 26.98/0.76 | 26.34/0.72 |
| This paper | 31.92/0.93 | 28.47/0.77 | 27.53/0.81 | 27.36/0.79 |
| Method/Datasets | Set5 | Set14 | BSD100 | Kvasir-Sessile |
|---|---|---|---|---|
| Bicubic | 0.27 | 0.30 | 0.32 | 0.35 |
| SRCNN | 0.25 | 0.31 | 0.29 | 0.31 |
| ESPCN | 0.24 | 0.26 | 0.30 | 0.32 |
| SRGAN | 0.23 | 0.25 | 0.28 | 0.30 |
| This paper | 0.19 | 0.22 | 0.23 | 0.25 |
| Method/Image | Image1 | Image2 | Image3 |
|---|---|---|---|
| Bicubic | 2.75/4.19 | 2.32/3.83 | 7.32/3.58 |
| SRCNN | 2.68/4.17 | 2.46/3.84 | 7.36/3.95 |
| SRGAN | 2.69/4.20 | 3.22/3.90 | 7.39/3.95 |
| This paper | 3.06/4.23 | 3.96/3.90 | 13.34/4.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Liu, Y.; Zhang, J.; Duan, Z.; Zhang, L.; Hou, X.; He, W.; You, Y.; He, J.; Chou, X. Blind Super-Resolution Network with Dual-Channel Attention for Images Captured by Sub-Millimeter-Diameter Fiberscope. Electronics 2023, 12, 4352. https://doi.org/10.3390/electronics12204352
Chen W, Liu Y, Zhang J, Duan Z, Zhang L, Hou X, He W, You Y, He J, Chou X. Blind Super-Resolution Network with Dual-Channel Attention for Images Captured by Sub-Millimeter-Diameter Fiberscope. Electronics. 2023; 12(20):4352. https://doi.org/10.3390/electronics12204352
Chicago/Turabian StyleChen, Wei, Yi Liu, Jie Zhang, Zhigang Duan, Le Zhang, Xiaojuan Hou, Wenjun He, Yajun You, Jian He, and Xiujian Chou. 2023. "Blind Super-Resolution Network with Dual-Channel Attention for Images Captured by Sub-Millimeter-Diameter Fiberscope" Electronics 12, no. 20: 4352. https://doi.org/10.3390/electronics12204352
APA StyleChen, W., Liu, Y., Zhang, J., Duan, Z., Zhang, L., Hou, X., He, W., You, Y., He, J., & Chou, X. (2023). Blind Super-Resolution Network with Dual-Channel Attention for Images Captured by Sub-Millimeter-Diameter Fiberscope. Electronics, 12(20), 4352. https://doi.org/10.3390/electronics12204352