
Infrared and Visible Image Fusion Based on Mask and Cross-Dynamic Fusion

Abstract
:1. Introduction
1.1. Technology Application
1.2. Related Work
1.3. Contribution
2. Materials and Methods
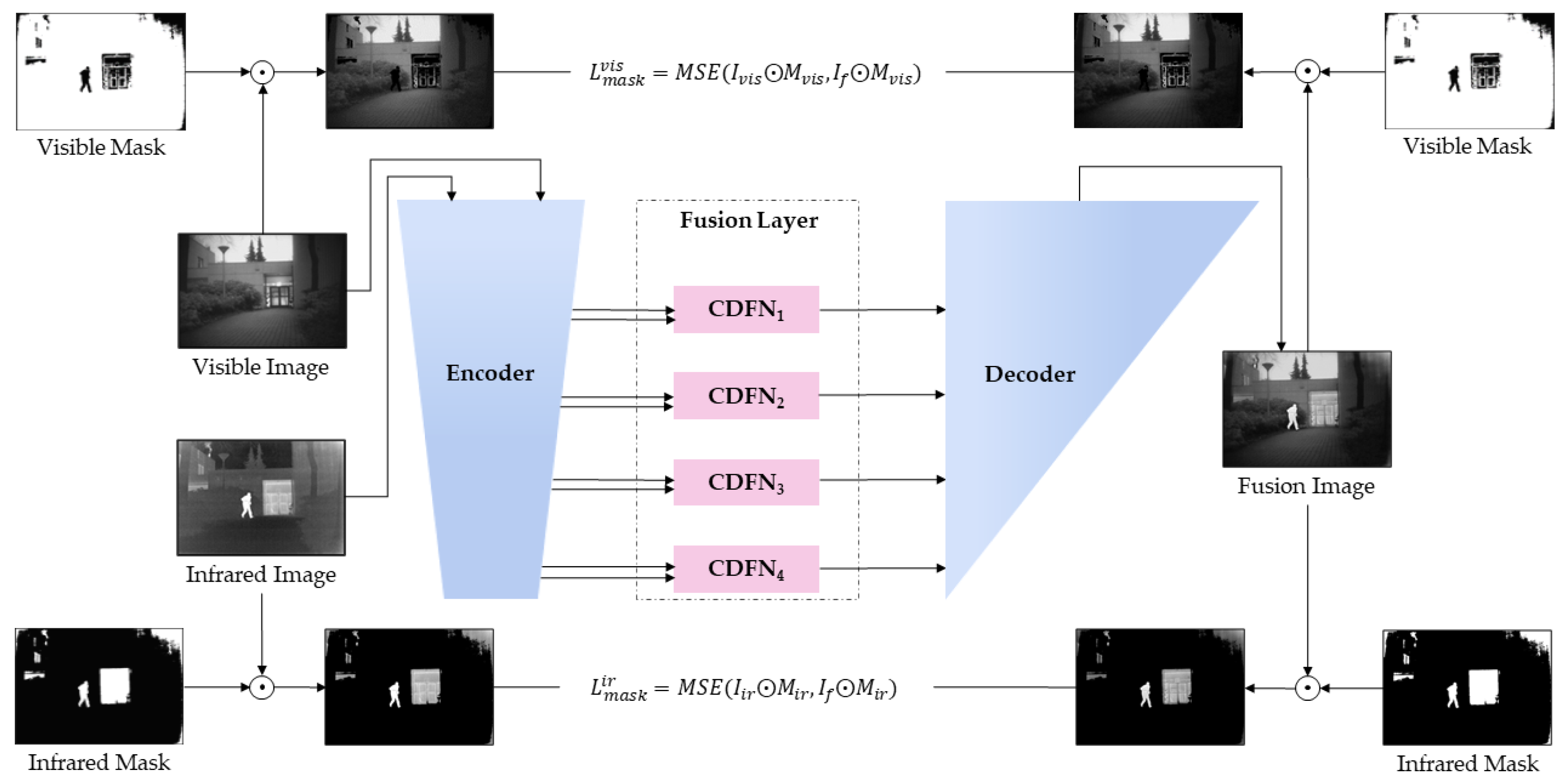
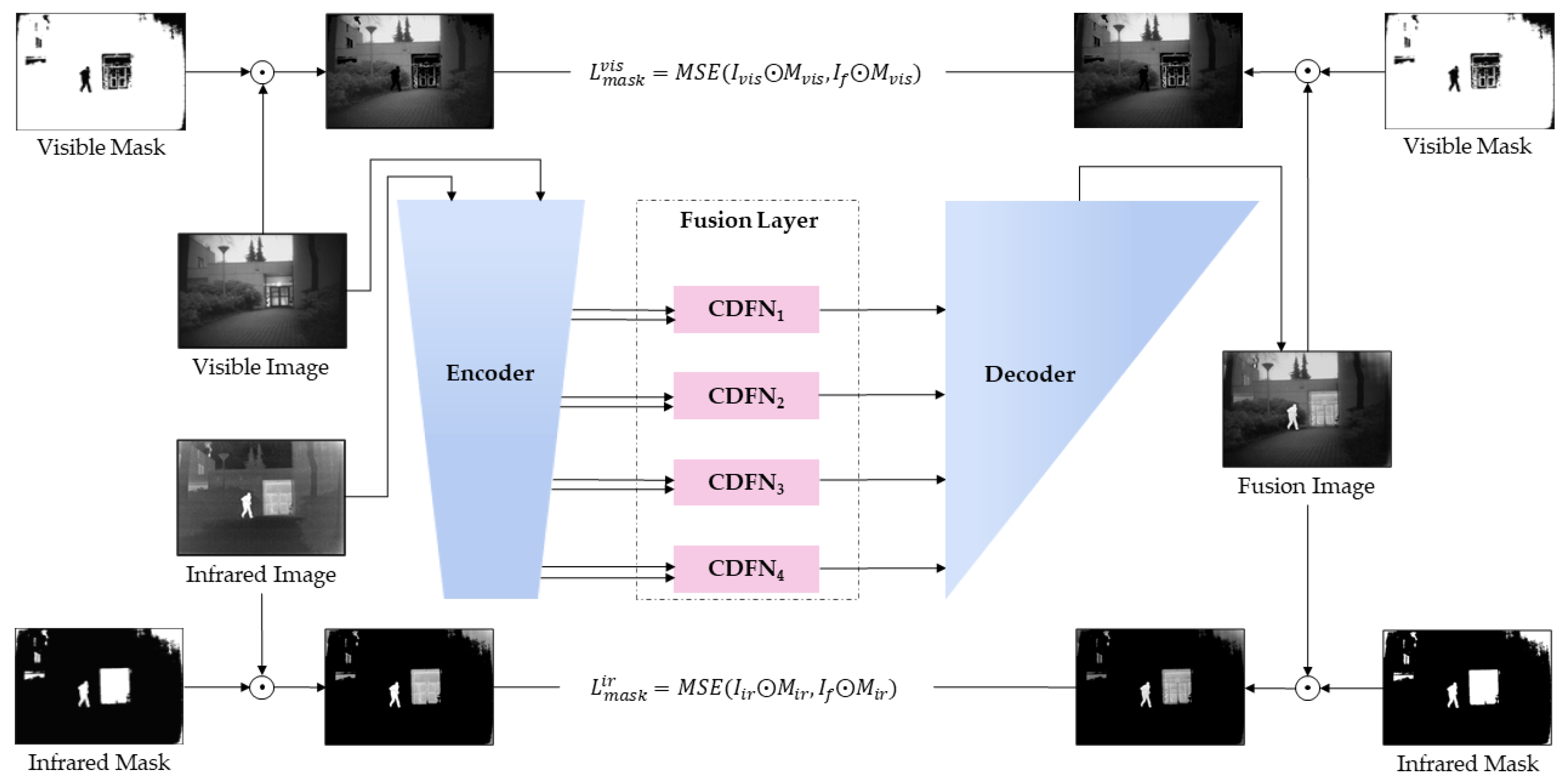
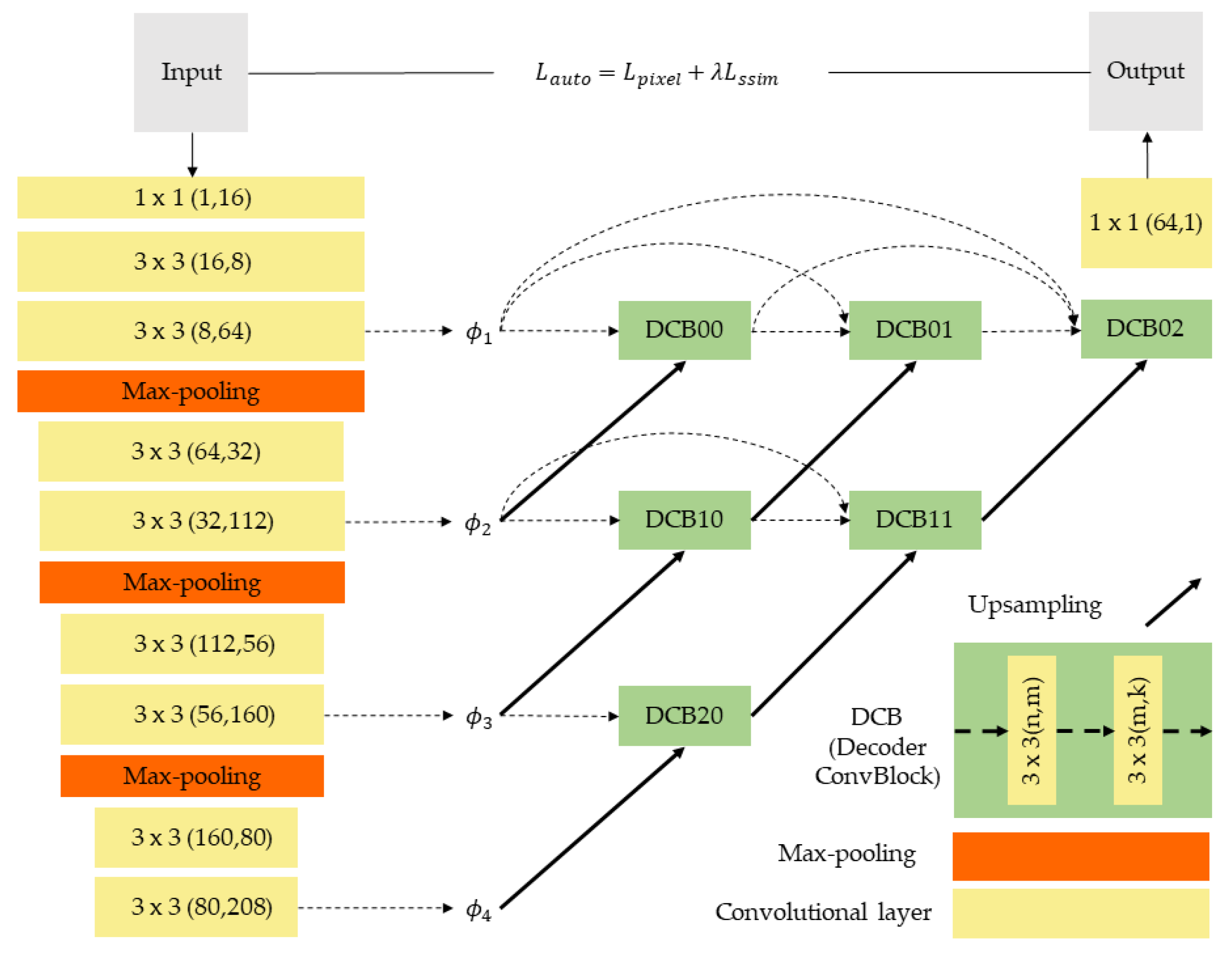
2.1. Framework Overview
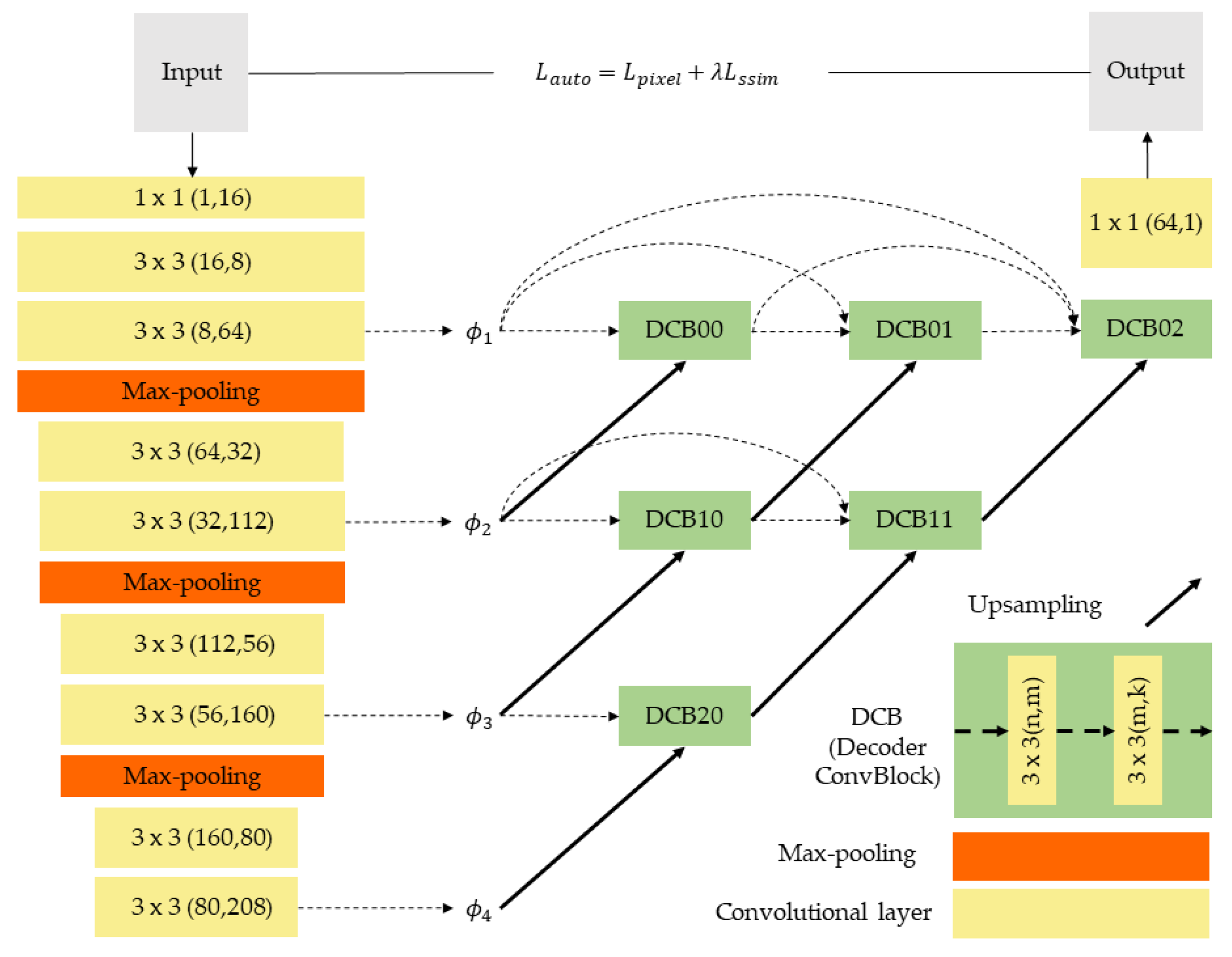
2.2. One-Stage Network Training
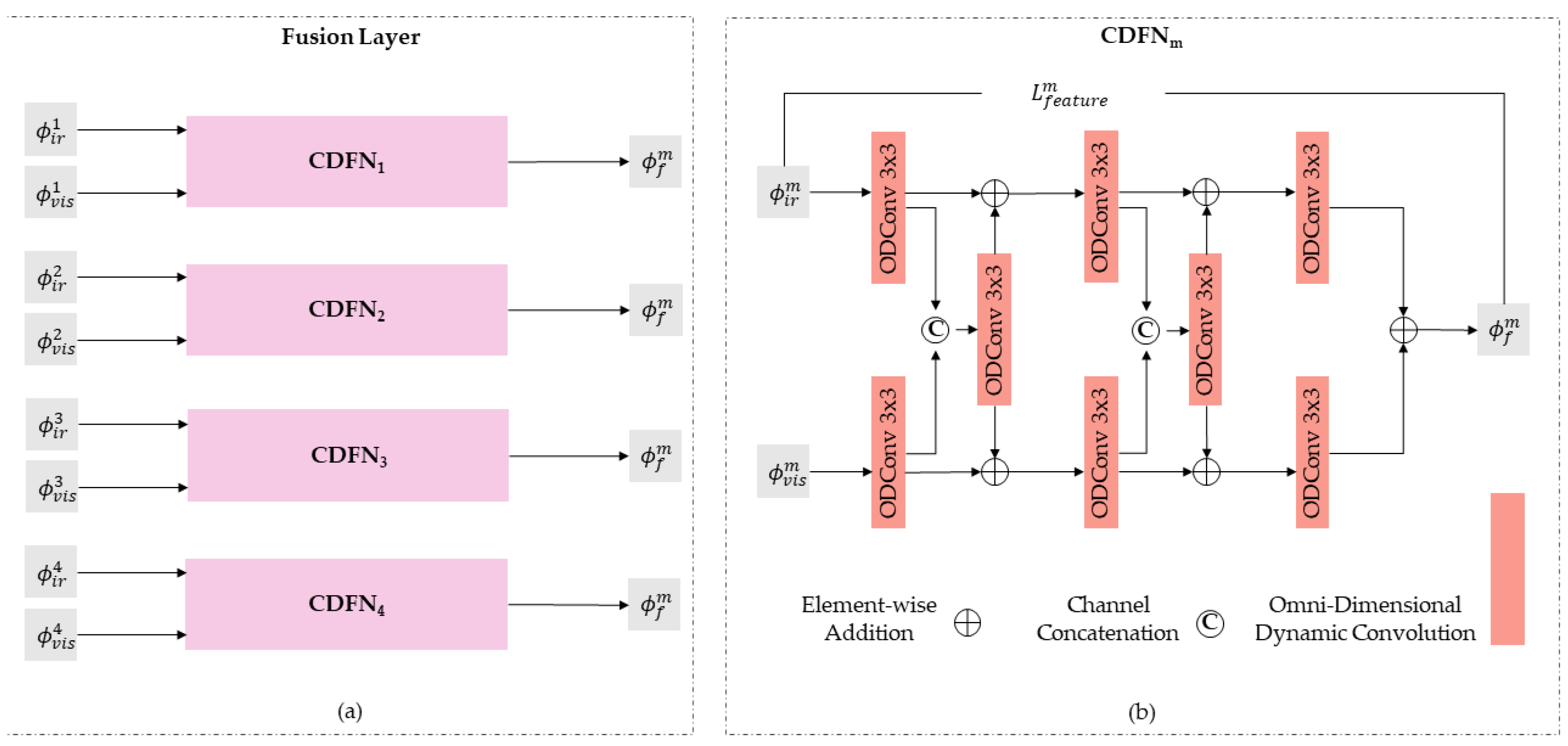
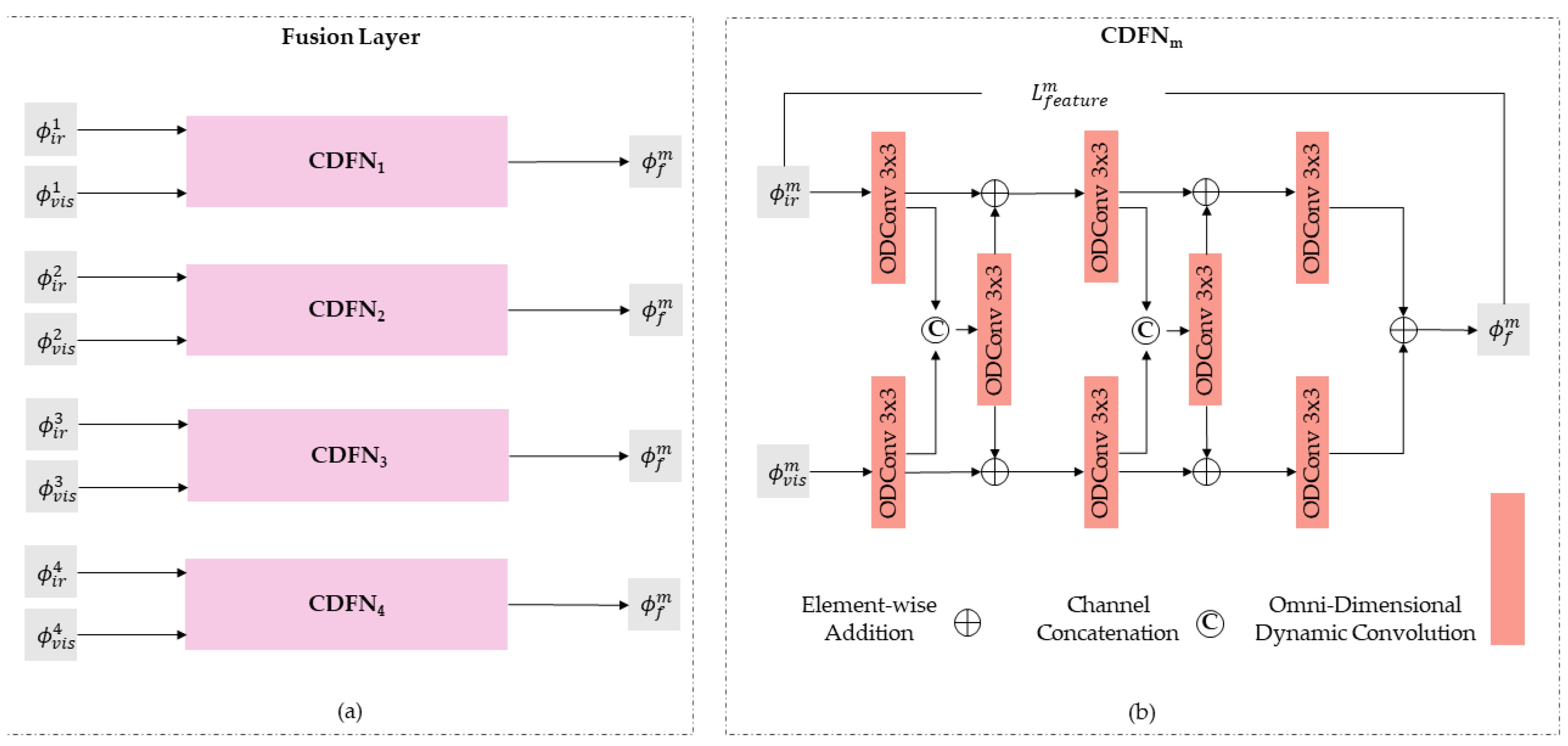
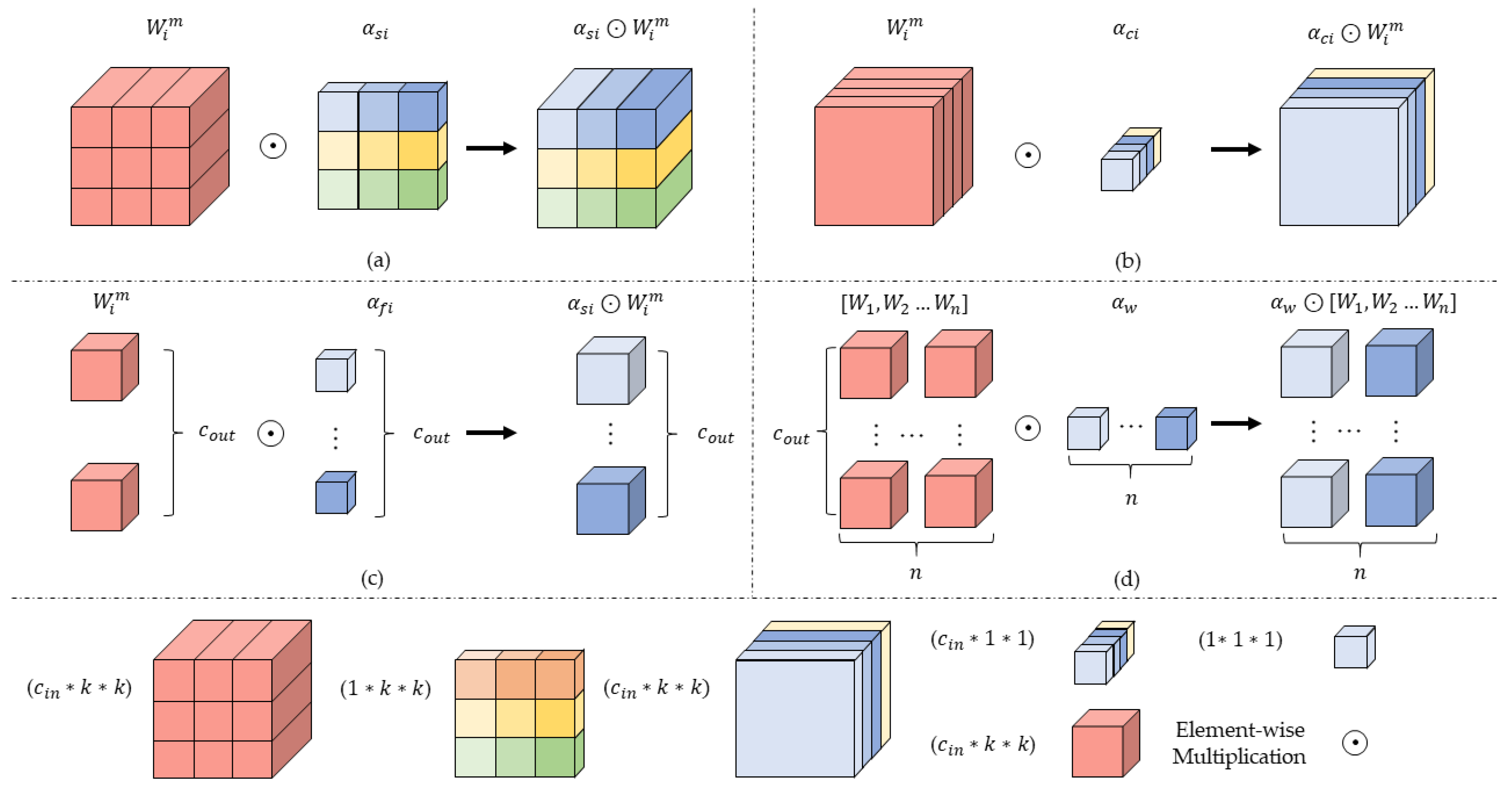
2.3. Fusion Layer Design
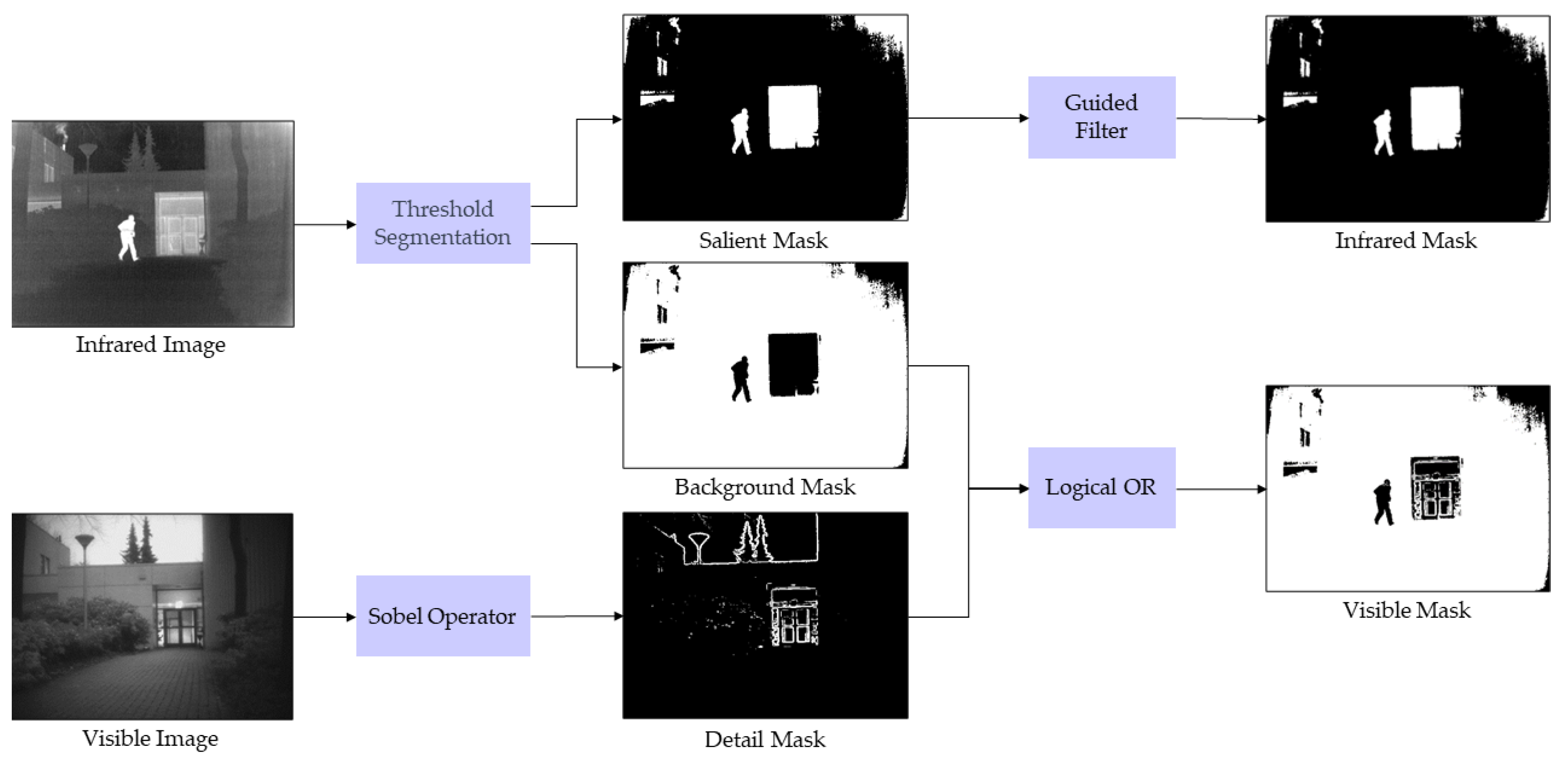
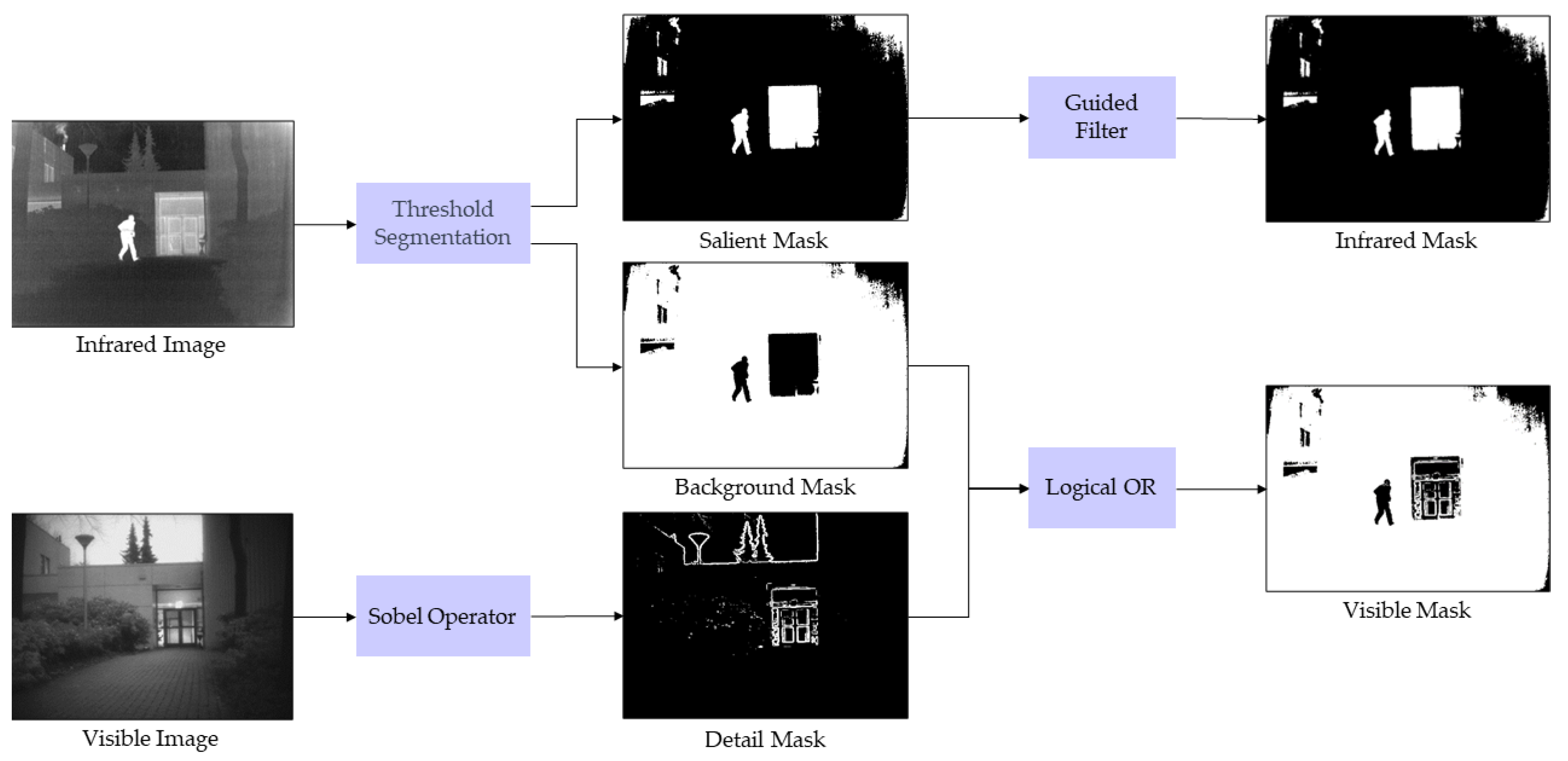
2.4. Mask Generation Strategy
2.5. Two-Stage Network Training
3. Experiments and Results Analysis
3.1. Experimental Setup and Implementation
3.1.1. Network Training Settings
3.1.2. Test Experiment Setup
3.1.3. Evaluation Metrics
3.2. Ablation Experiments
3.2.1. The Effect of the Loss Function Weights
3.2.2. Effect of Masks and ODConv Modules
3.3. Qualitative and Quantitative Evaluation on TNO Dataset
3.4. Qualitative and Quantitative Evaluation on RoadScene Dataset
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MCDFN | Mask and Cross-Dynamic Fusion Network |
| ODConv | Omni-Dimensional Dynamic Convolution |
| CNN | Convolution Neural Network |
| GAN | Generative Adversarial Network |
| MSE | Mean Squared Error |
| EN | Entropy |
| MI | Mutual Information |
| FMI | Fusion Mutual Information weighted |
| SD | Standard Deviation |
| SSIM | Structural Similarity Index Measure |
| VIF | Visual Information Fidelity |
| Q | Quality Index based on Alpha Beta/Fusion |
References
- Ma, W.; Wang, K.; Li, J.; Yang, S.X.; Li, J.; Song, L.; Li, Q. Infrared and Visible Image Fusion Technology and Application: A Review. Sensors 2023, 23, 599. [Google Scholar] [CrossRef] [PubMed]
- Sun, C.; Zhang, C.; Xiong, N. Infrared and visible image fusion techniques based on deep learning: A review. Electronics 2020, 9, 2162. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.; Wang, Z.J.; Ward, R.K.; Wang, X. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J. EMFusion: An unsupervised enhanced medical image fusion network. Inf. Fusion 2021, 76, 177–186. [Google Scholar] [CrossRef]
- Zhou, T.; Li, Q.; Lu, H.; Cheng, Q.; Zhang, X. GAN review: Models and medical image fusion applications. Inf. Fusion 2023, 91, 134–148. [Google Scholar] [CrossRef]
- Fu, J.; Li, W.; Du, J.; Huang, Y. A multiscale residual pyramid attention network for medical image fusion. Biomed. Signal Process. Control 2021, 66, 102488. [Google Scholar] [CrossRef]
- Karim, S.; Tong, G.; Li, J.; Qadir, A.; Farooq, U.; Yu, Y. Current advances and future perspectives of image fusion: A comprehensive review. Inf. Fusion 2023, 90, 185–217. [Google Scholar] [CrossRef]
- Liu, Q.; Zhou, H.; Xu, Q.; Liu, X.; Wang, Y. PSGAN: A generative adversarial network for remote sensing image pan-sharpening. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10227–10242. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Ben Hamza, A.; He, Y.; Krim, H.; Willsky, A. A multiscale approach to pixel-level image fusion. Integr. Comput.-Aided Eng. 2005, 12, 135–146. [Google Scholar] [CrossRef]
- Bin, Y.; Shutao, L. Multifocus Image Fusion and Restoration With Sparse Representation. IEEE Trans. Instrum. Meas. 2010, 59, 884–892. [Google Scholar]
- Harsanyi, J.C.; Chang, C.-I. Hyperspectral image classification and dimensionality reduction: An orthogonal subspace projection approach. IEEE Trans. Geosci. Remote Sens. 1994, 32, 779–785. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Liu, G. Multi-sensor image fusion based on fourth order partial differential equations. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–9. [Google Scholar]
- Burt, P.J.; Adelson, E.H. The Laplacian pyramid as a compact image code. In Readings in Computer Vision; Fischler, M.A., Firschein, O., Eds.; Elsevier: Amsterdam, The Netherlands, 1987; pp. 671–679. [Google Scholar]
- Liu, Y.; Jin, J.; Wang, Q.; Shen, Y.; Dong, X. Region level based multi-focus image fusion using quaternion wavelet and normalized cut. Signal Process. 2014, 97, 9–30. [Google Scholar] [CrossRef]
- Pajares, G.; De La Cruz, J.M. A wavelet-based image fusion tutorial. Pattern Recognit. 2004, 37, 1855–1872. [Google Scholar] [CrossRef]
- Choi, M.; Kim, R.Y.; Nam, M.-R.; Kim, H.O. Fusion of multispectral and panchromatic satellite images using the curvelet transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 136–140. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Durrani, T. NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12797–12804. [Google Scholar]
- Wang, K.; Zheng, M.; Wei, H.; Qi, G.; Li, Y. Multi-modality medical image fusion using convolutional neural network and contrast pyramid. Sensors 2020, 20, 2169. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H. A medical image fusion method based on convolutional neural networks. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–7. [Google Scholar]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.-P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. CondConv: Conditionally parameterized convolutions for efficient inference. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–12 December 2019; pp. 1307–1318. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Guo, C.; Fan, D.; Jiang, Z.; Zhang, D. MDFN: Mask deep fusion network for visible and infrared image fusion without reference ground-truth. Expert Syst. Appl. 2023, 211, 118631. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An infrared and visible image fusion network based on salient target detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Fast end-to-end trainable guided filter. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1838–1847. [Google Scholar]
- Toet, A. The TNO multiband image data collection. Data Brief 2017, 15, 249–251. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Le, Z.; Jiang, J.; Guo, X. Fusiondn: A unified densely connected network for image fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12484–12491. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Roberts, J.W.; Van Aardt, J.A.; Ahmed, F.B. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 1. [Google Scholar] [CrossRef]
- Haghighat, M.; Razian, M.A. Fast-FMI: Non-reference image fusion metric. In Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT), Astana, Kazakhstan, 14–17 October 2014; pp. 1–3. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Shreyamsha Kumar, B. Image fusion based on pixel significance using cross bilateral filter. Signal Image Video Process. 2015, 9, 1193–1204. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image fusion with convolutional sparse representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Kittler, J. Infrared and visible image fusion using a deep learning framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- Li, H.; Wu, X.-J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EN | SD | MI | FMI | SSIM | VIF | Q | |
|---|---|---|---|---|---|---|---|
| 0.3 | 7.022 | 100.319 | 14.044 | 0.425 | 0.664 | 0.940 | 0.484 |
| 0.4 | 7.055 | 102.314 | 14.110 | 0.422 | 0.679 | 0.927 | 0.471 |
| 0.5 | 7.043 | 101.701 | 14.087 | 0.412 | 0.687 | 0.870 | 0.452 |
| 0.6 | 7.012 | 101.434 | 14.065 | 0.393 | 0.695 | 0.794 | 0.416 |
| 0.7 | 7.026 | 98.127 | 14.052 | 0.391 | 0.697 | 0.716 | 0.367 |
| EN | SD | MI | FMI | SSIM | VIF | Q | ||
|---|---|---|---|---|---|---|---|---|
| 0.1 | 1 | 6.874 | 90.236 | 13.749 | 0.425 | 0.697 | 0.826 | 0.429 |
| 0.1 | 7.055 | 102.314 | 14.110 | 0.422 | 0.679 | 0.927 | 0.471 | |
| 0.01 | 7.039 | 100.761 | 14.079 | 0.382 | 0.655 | 0.896 | 0.457 | |
| 1 | 0.1 | 7.015 | 100.747 | 14.051 | 0.411 | 0.659 | 0.962 | 0.470 |
| 0.01 | 0.1 | 6.992 | 99.106 | 13.985 | 0.429 | 0.649 | 0.925 | 0.469 |
| EN | SD | MI | FMIw | SSIM | VIF | Q | |
|---|---|---|---|---|---|---|---|
| Conv | 6.707 | 66.450 | 13.414 | 0.419 | 0.709 | 0.746 | 0.427 |
| ODConv | 6.741 | 67.529 | 13.482 | 0.423 | 0.713 | 0.761 | 0.426 |
| Conv + Mask | 6.827 | 92.065 | 13.655 | 0.424 | 0.685 | 0.886 | 0.449 |
| ODConv + Mask | 7.055 | 102.314 | 14.110 | 0.422 | 0.679 | 0.927 | 0.471 |
| EN | SD | MI | FMI | SSIM | VIF | Q | |
|---|---|---|---|---|---|---|---|
| CBF | 6.857 | 76.824 | 13.714 | 0.323 | 0.599 | 0.718 | 0.453 |
| ConvSR | 6.258 | 50.743 | 12.517 | 0.383 | 0.753 | 0.633 | 0.534 |
| VggML | 6.182 | 48.157 | 12.365 | 0.416 | 0.778 | 0.295 | 0.451 |
| DeepFuse | 6.699 | 68.793 | 13.398 | 0.424 | 0.728 | 0.779 | 0.437 |
| DenseFuse | 6.173 | 47.819 | 12.347 | 0.417 | 0.779 | 0.608 | 0.343 |
| FusionGAN | 6.362 | 54.357 | 12.725 | 0.370 | 0.653 | 0.453 | 0.218 |
| U2Fusion | 6.757 | 64.911 | 13.514 | 0.362 | 0.694 | 0.751 | 0.424 |
| NestFuse | 6.894 | 80.372 | 13.789 | 0.432 | 0.714 | 0.752 | 0.483 |
| RFN-Nest | 6.841 | 71.899 | 13.682 | 0.302 | 0.699 | 0.657 | 0.359 |
| Ours | 7.055 | 102.314 | 14.110 | 0.422 | 0.679 | 0.927 | 0.471 |
| EN | SD | MI | FMI | SSIM | VIF | Q | |
|---|---|---|---|---|---|---|---|
| CBF | 7.397 | 74.974 | 14.415 | 0.370 | 0.624 | 0.649 | 0.514 |
| ConvSR | 7.035 | 57.831 | 14.070 | 0.388 | 0.722 | 0.735 | 0.589 |
| VggML | 6.988 | 55.660 | 13.976 | 0.426 | 0.717 | 0.724 | 0.487 |
| DeepFuse | 7.156 | 63.983 | 14.312 | 0.433 | 0.705 | 0.753 | 0.495 |
| DenseFuse | 7.224 | 64.155 | 14.448 | 0.390 | 0.695 | 0.751 | 0.484 |
| FusionGAN | 7.040 | 58.950 | 14.080 | 0.277 | 0.598 | 0.590 | 0.251 |
| U2Fusion | 7.162 | 60.603 | 14.324 | 0.391 | 0.695 | 0.713 | 0.513 |
| NestFuse | 7.370 | 76.136 | 14.541 | 0.390 | 0.668 | 0.867 | 0.495 |
| RFN-Nest | 7.317 | 69.510 | 14.604 | 0.271 | 0.657 | 0.743 | 0.304 |
| Ours | 7.405 | 78.301 | 14.610 | 0.399 | 0.655 | 0.786 | 0.427 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Q.; Fu, H.; Wu, Y. Infrared and Visible Image Fusion Based on Mask and Cross-Dynamic Fusion. Electronics 2023, 12, 4342. https://doi.org/10.3390/electronics12204342
Fu Q, Fu H, Wu Y. Infrared and Visible Image Fusion Based on Mask and Cross-Dynamic Fusion. Electronics. 2023; 12(20):4342. https://doi.org/10.3390/electronics12204342
Chicago/Turabian StyleFu, Qiang, Hanxiang Fu, and Yuezhou Wu. 2023. "Infrared and Visible Image Fusion Based on Mask and Cross-Dynamic Fusion" Electronics 12, no. 20: 4342. https://doi.org/10.3390/electronics12204342
APA StyleFu, Q., Fu, H., & Wu, Y. (2023). Infrared and Visible Image Fusion Based on Mask and Cross-Dynamic Fusion. Electronics, 12(20), 4342. https://doi.org/10.3390/electronics12204342