



Contamination Detection Using a Deep Convolutional Neural Network with Safe Machine—Environment Interaction

 , , , ,
, , , ,  and
and 
Abstract
:1. Introduction
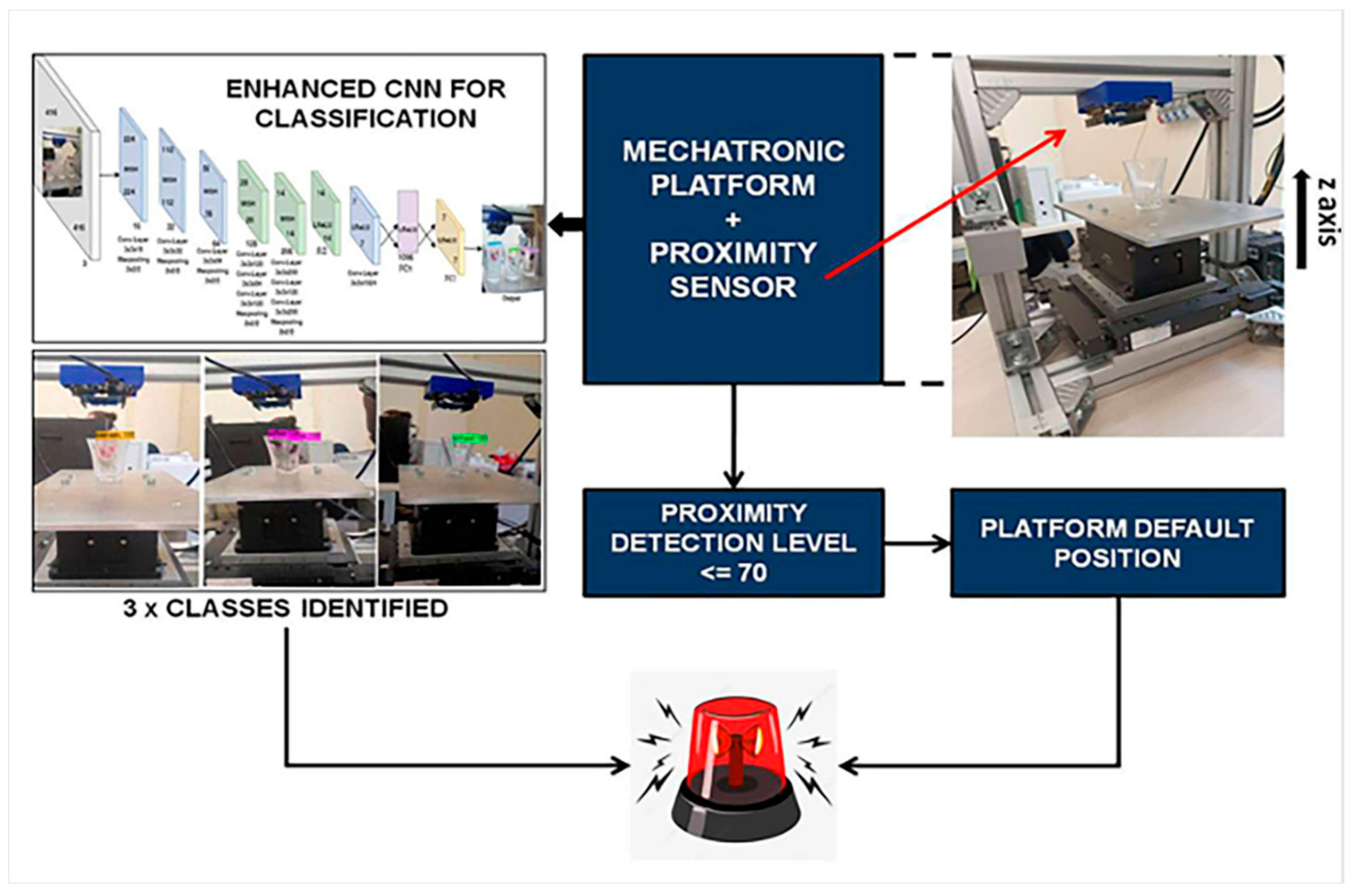
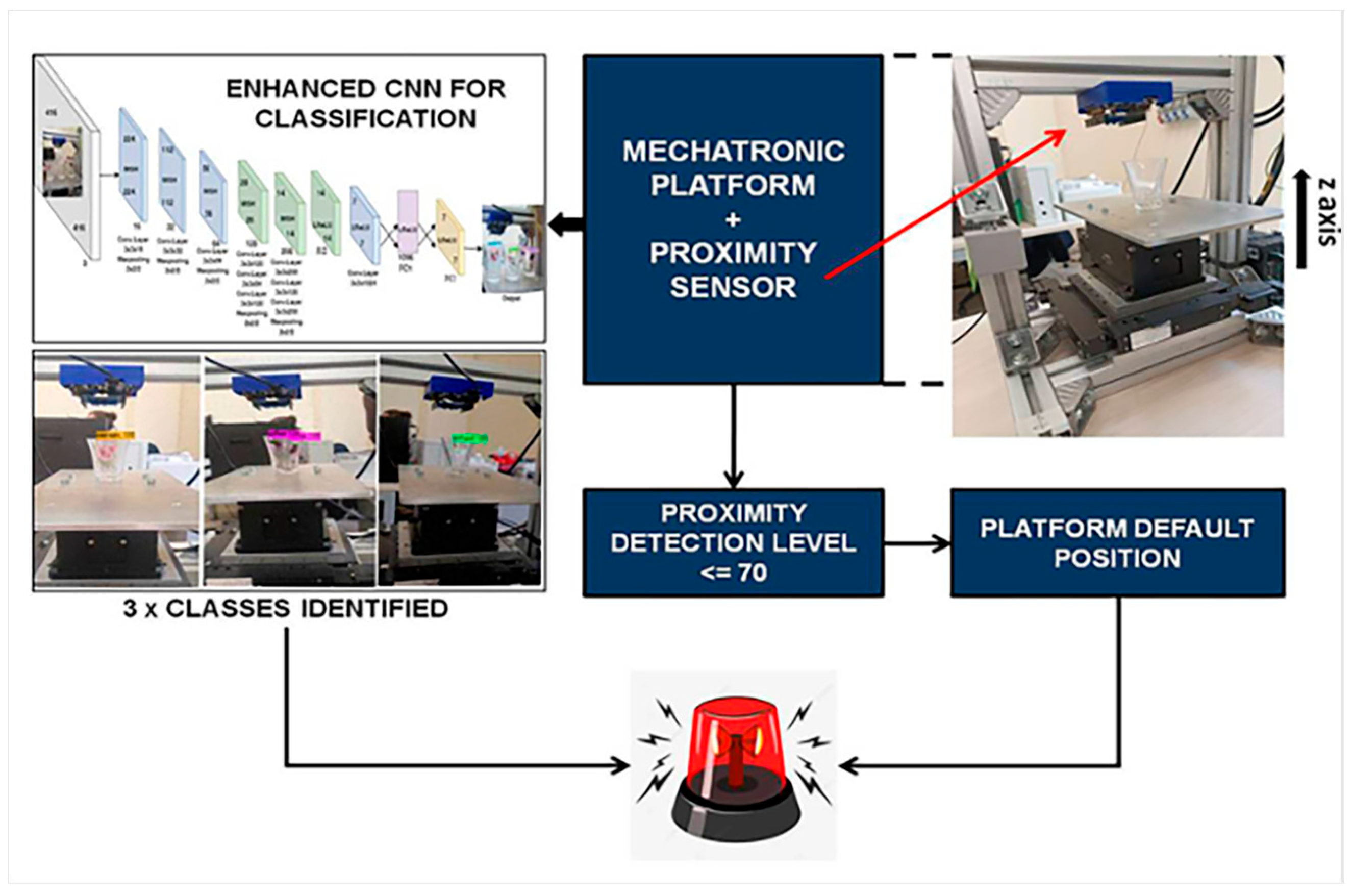
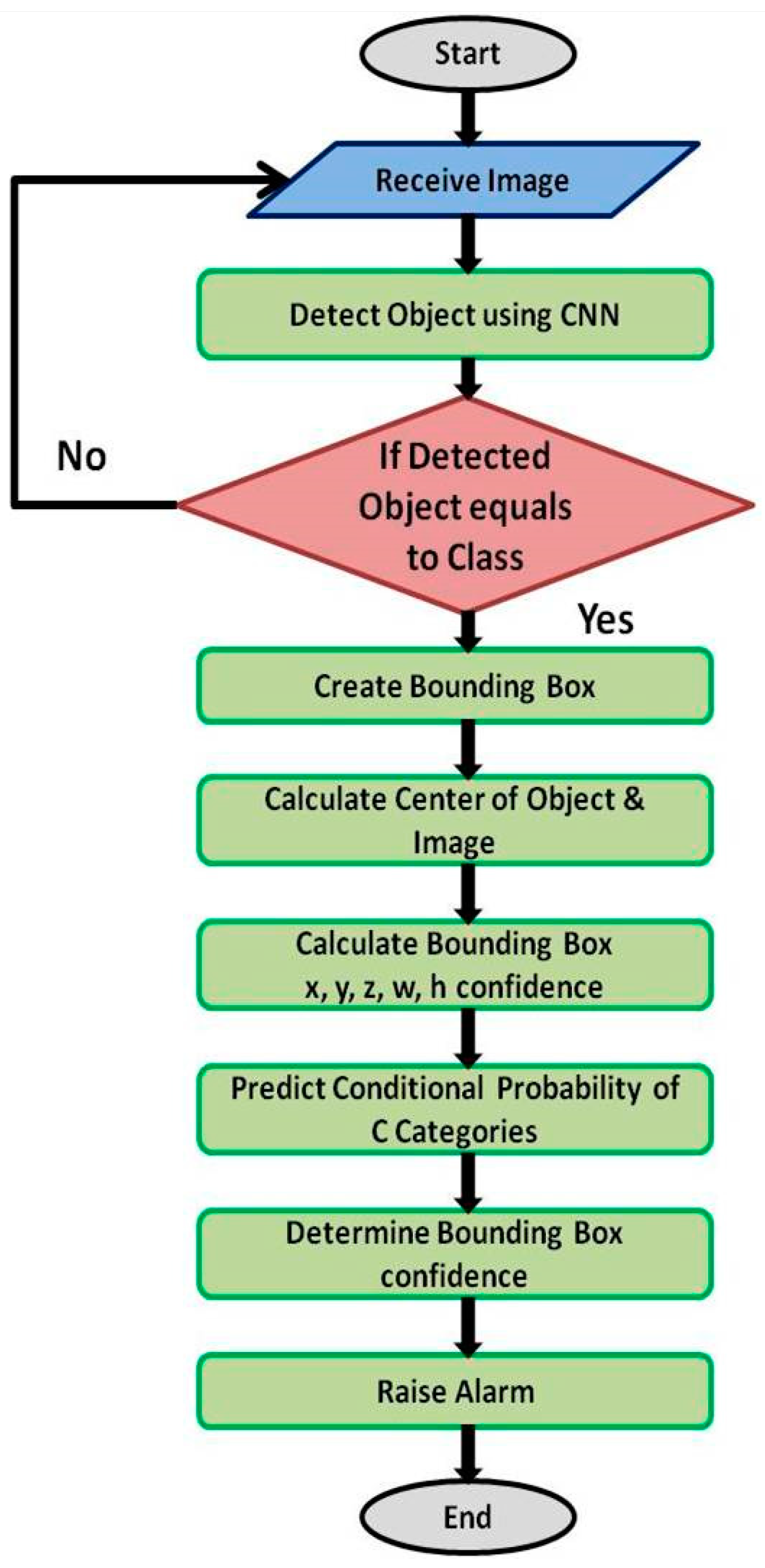
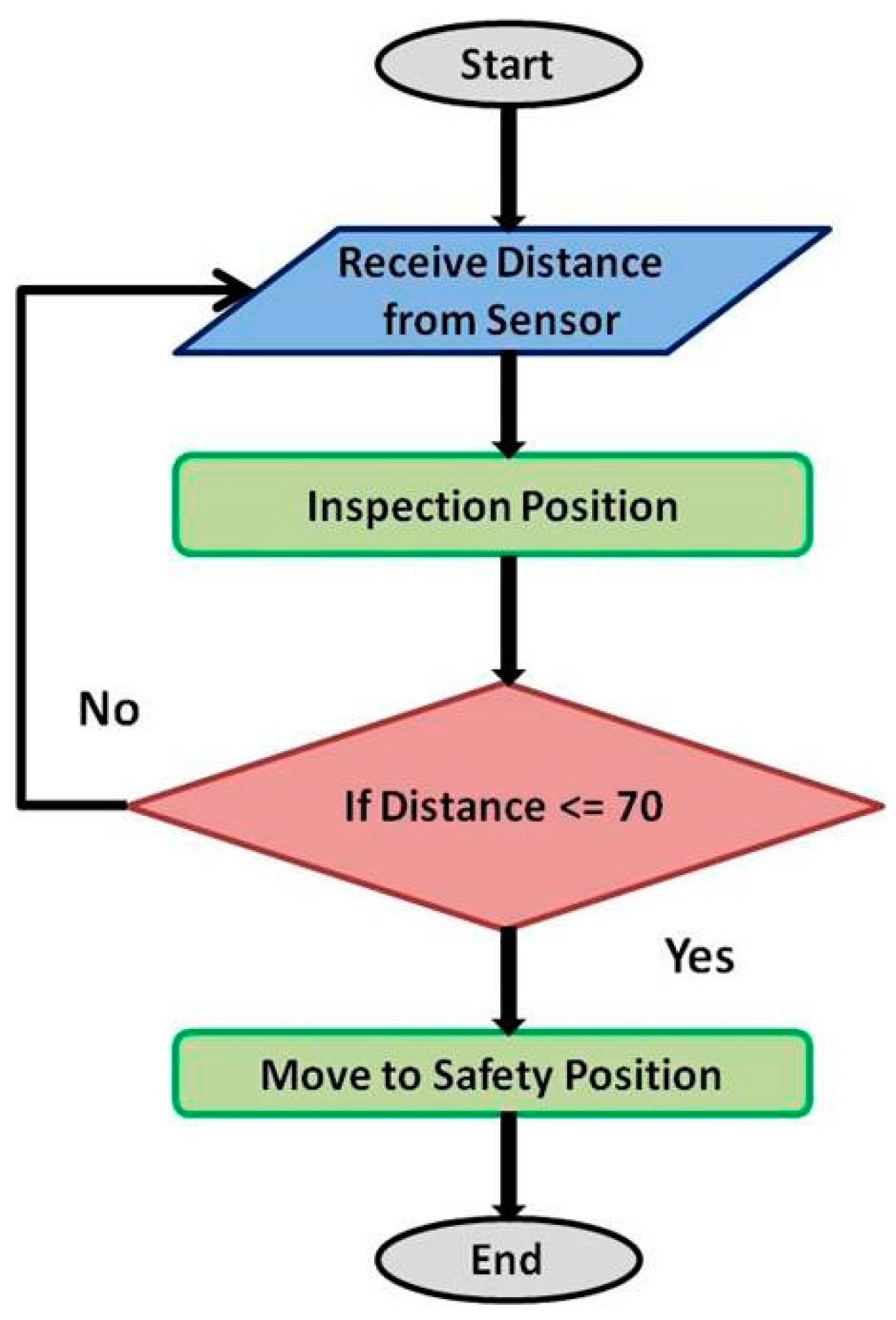
2. Use Case and Proposed Solution
2.1. Experimental Setup
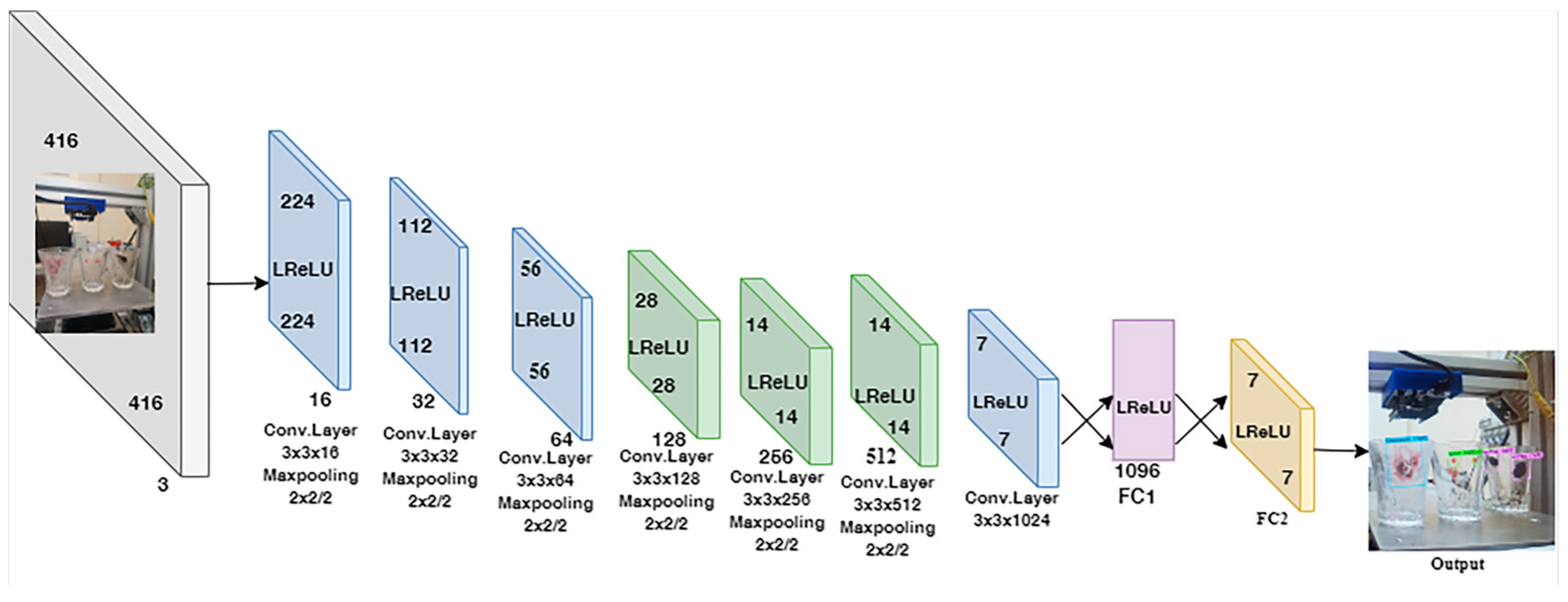
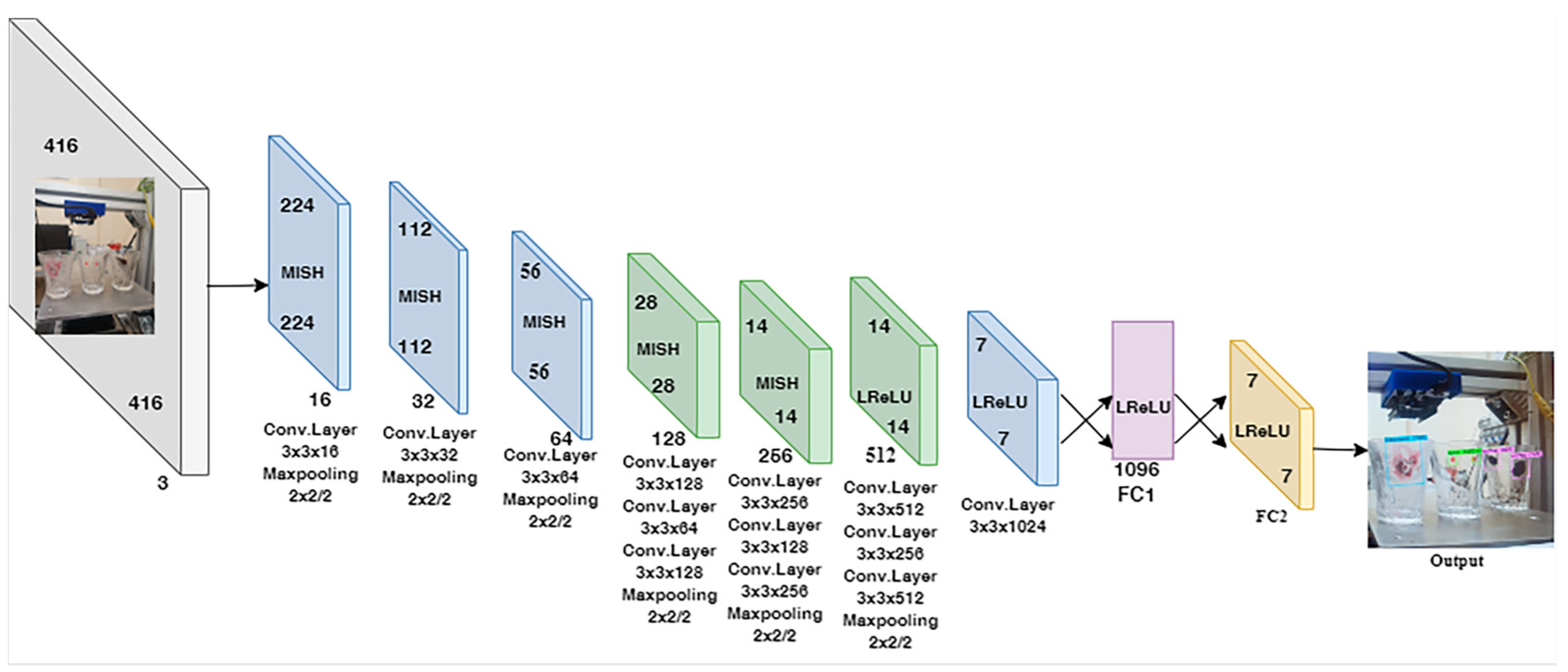
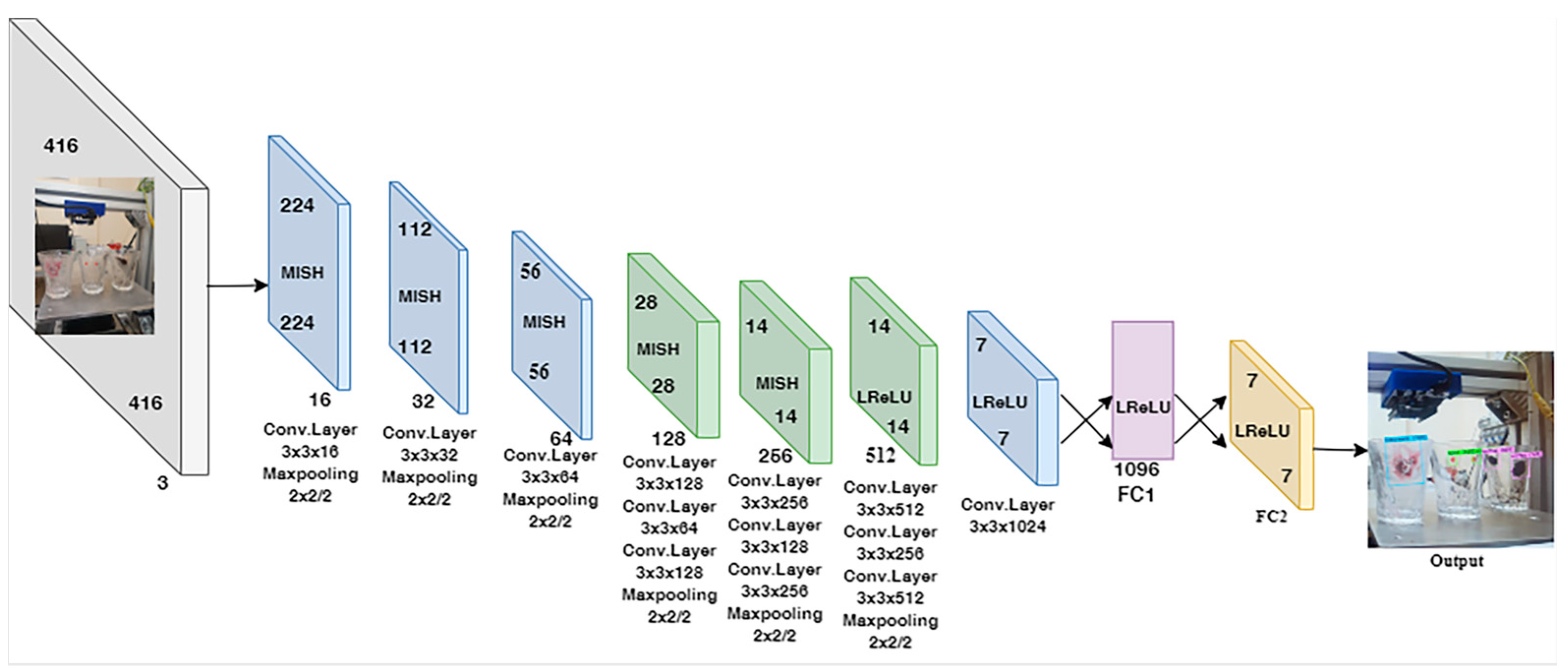
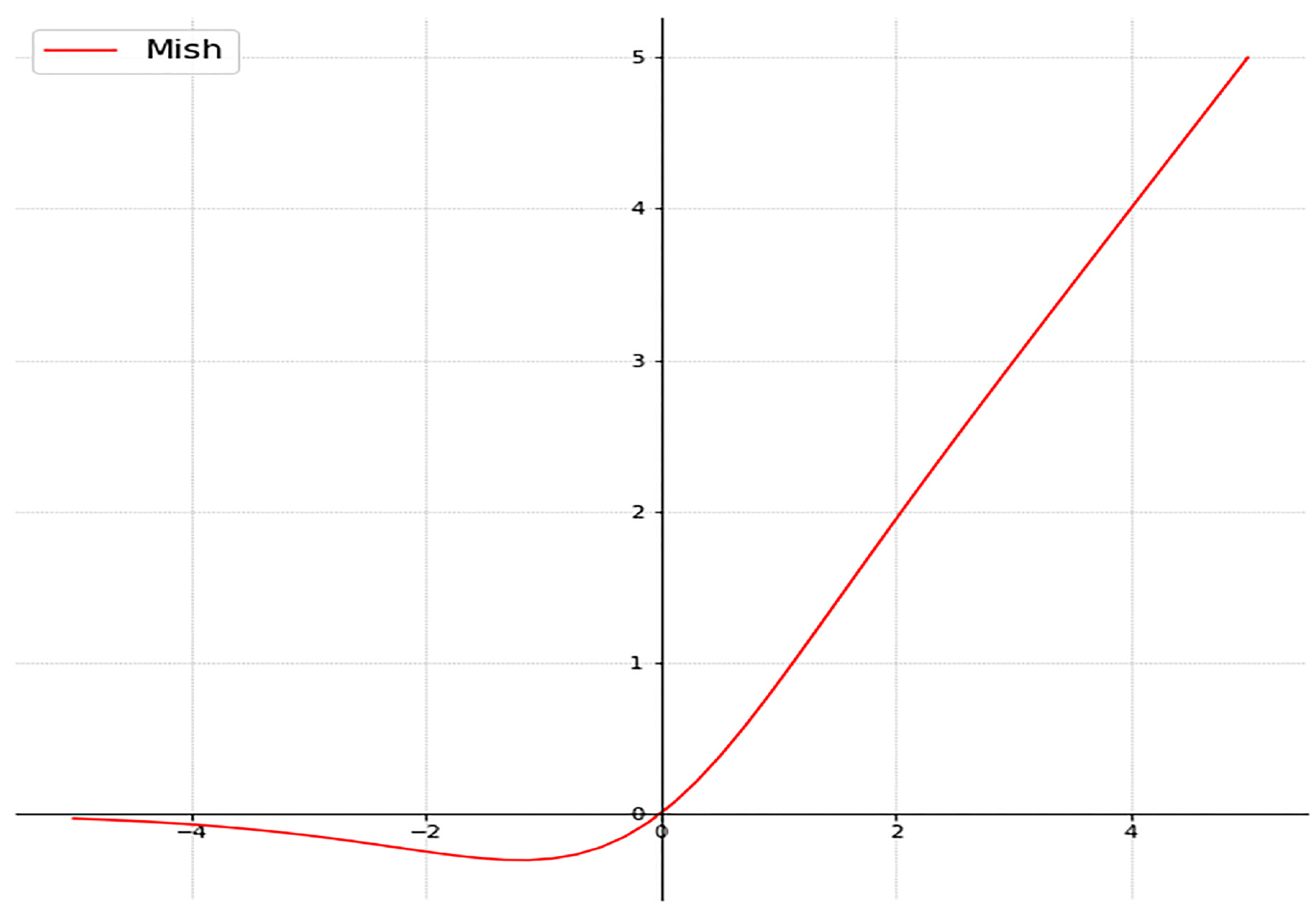
2.2. Enhancements in the CNN Model
3. Experimental Analysis
3.1. Dataset Specification and Augmentation
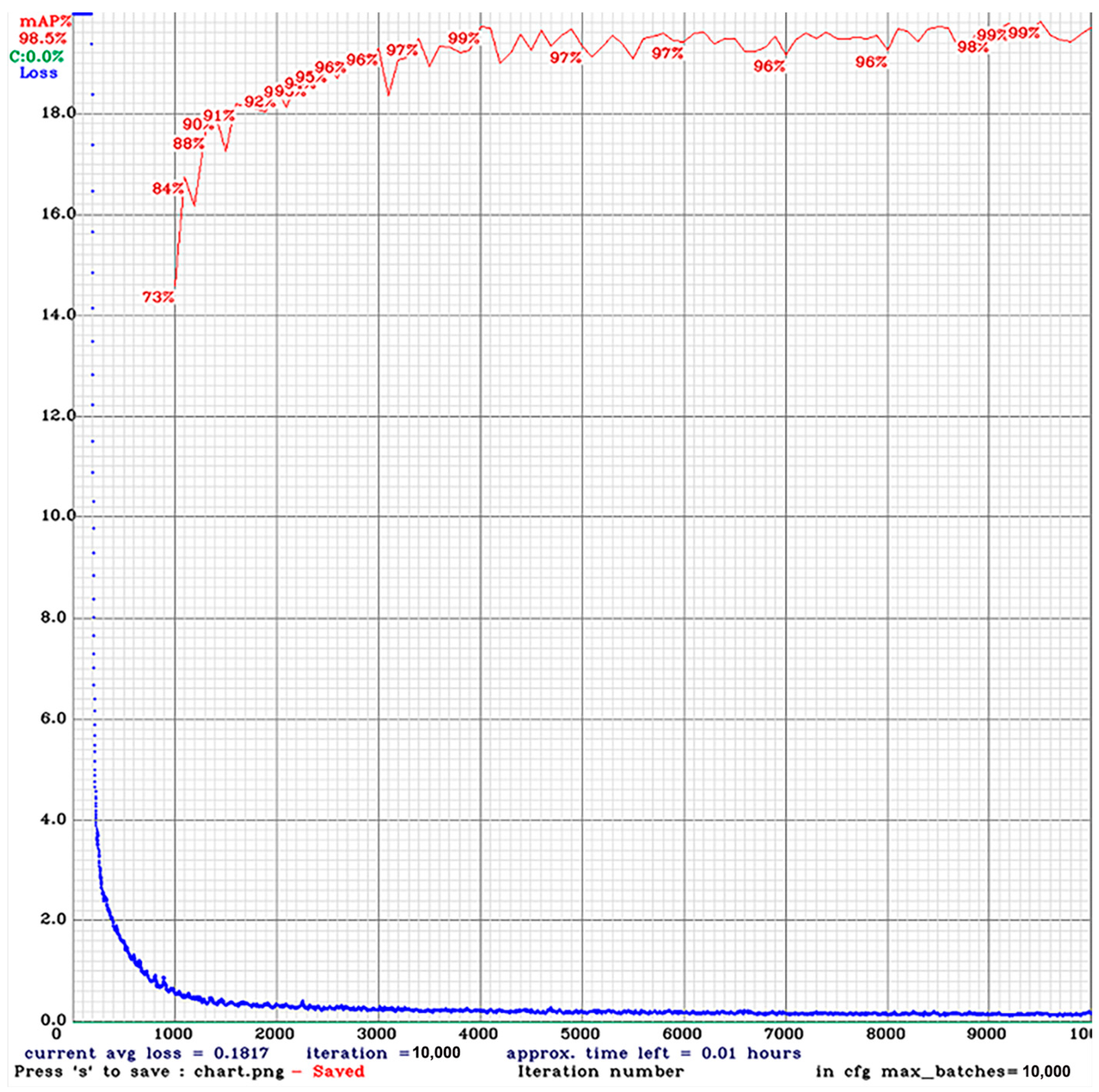
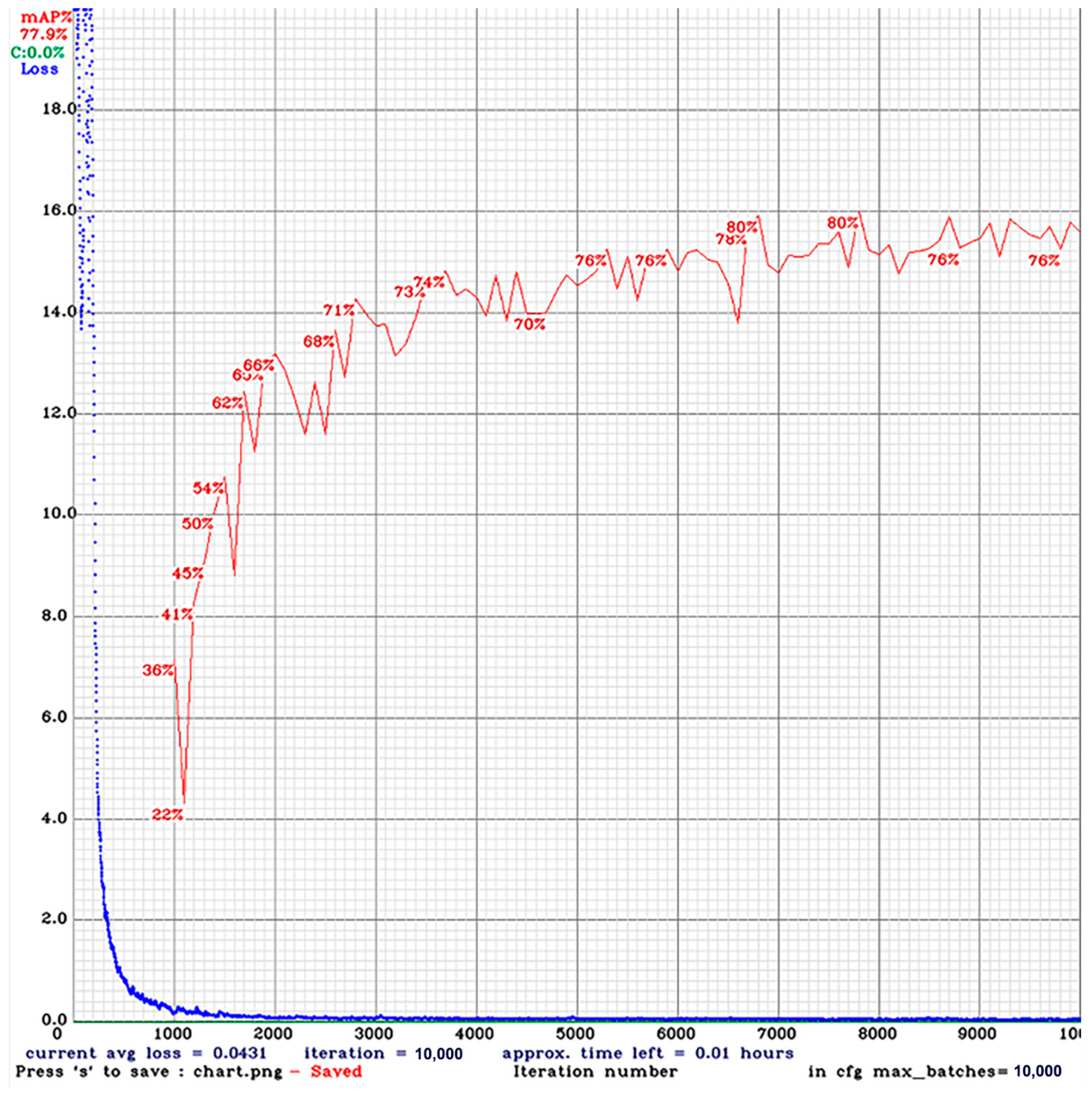
3.2. Training and Results
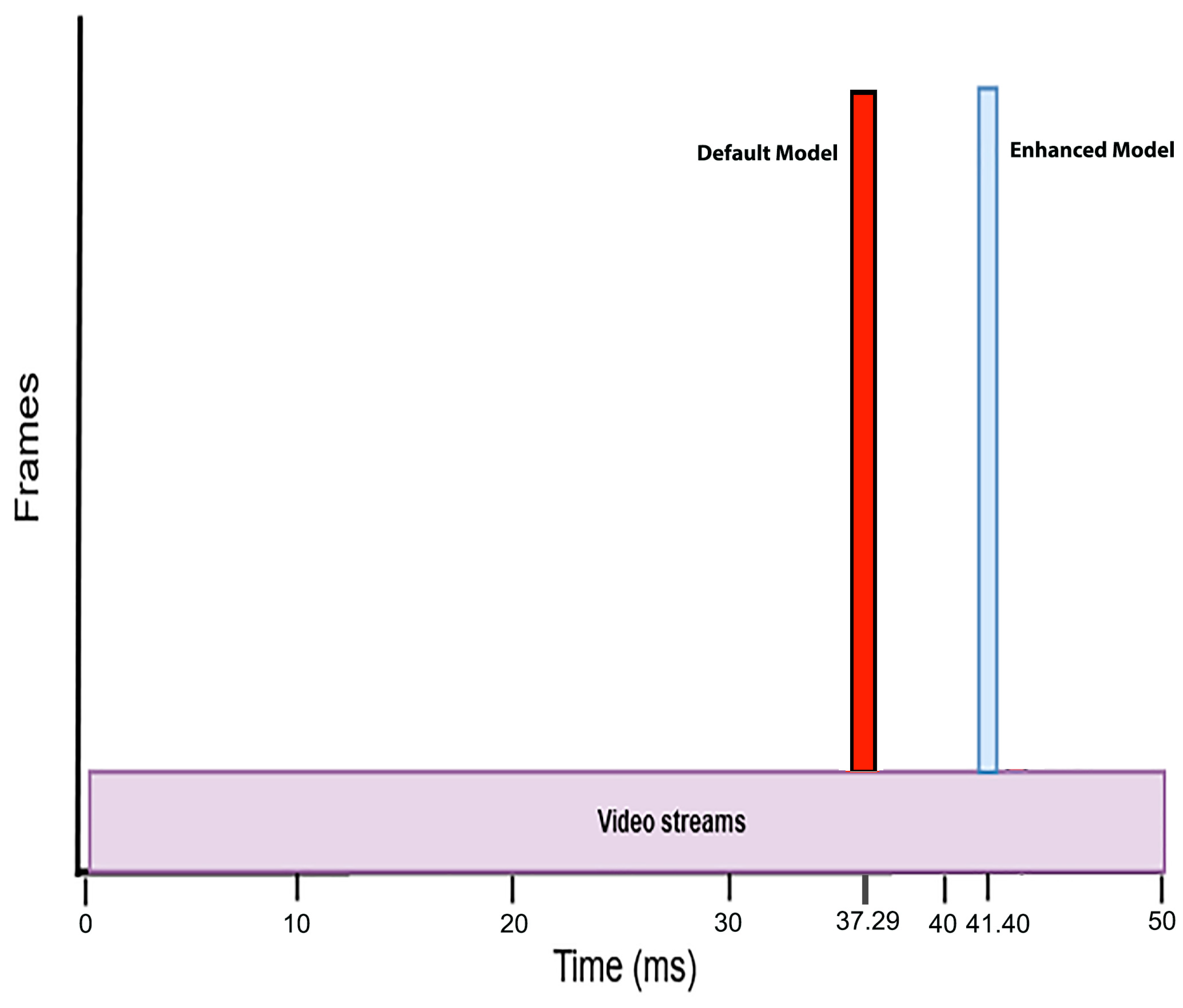
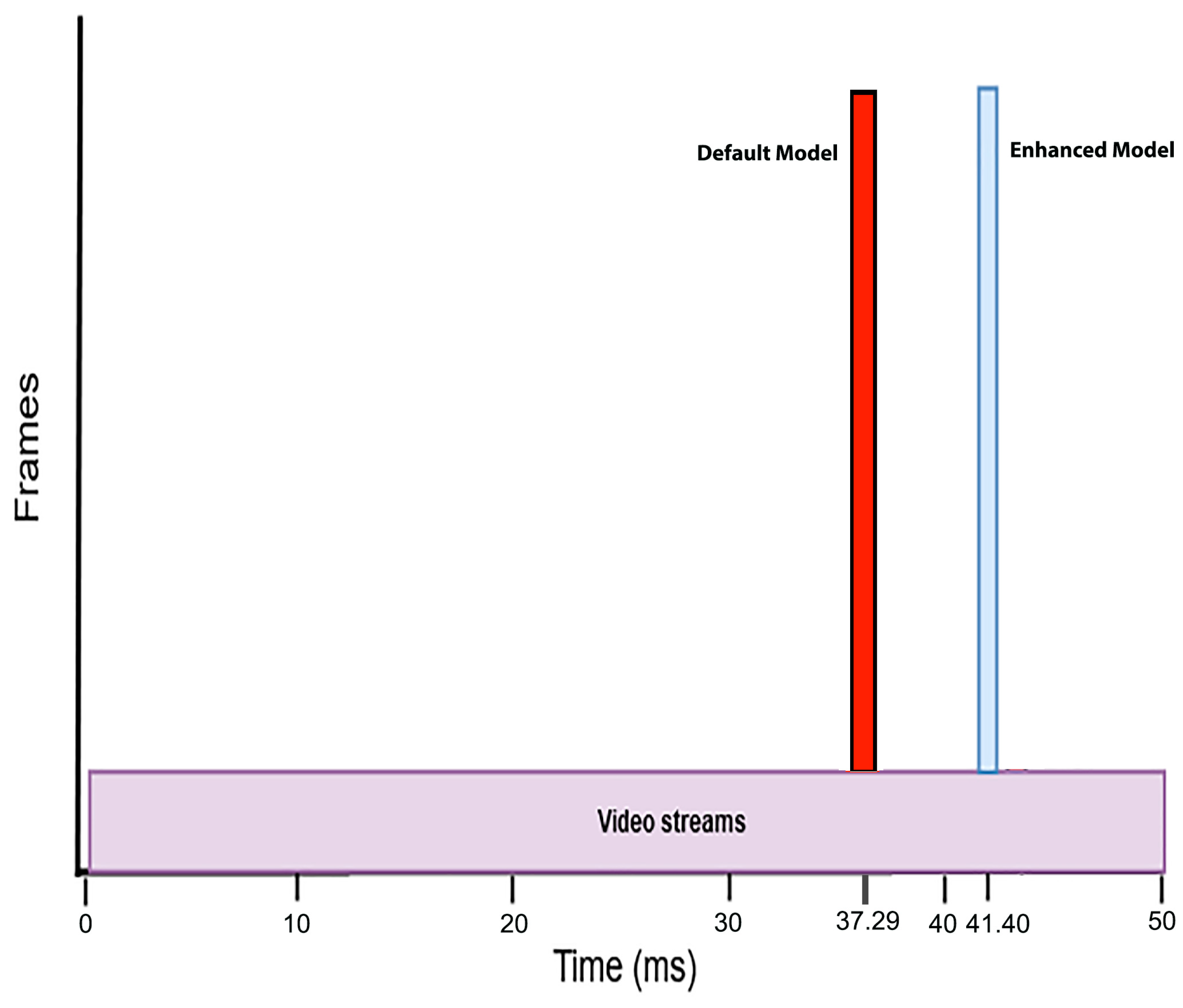
3.3. Performance Metrics for Model Evaluation
3.4. Loss Function
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Malamas, E.N.; Petrakis, E.G.M.; Zervakis, M.; Petit, L.; Legat, J.-D. A survey on industrial vision systems, applications and tools. Image Vis. Comput. 2003, 21, 171–188. [Google Scholar] [CrossRef]
- Jiang, J.; Cao, P.; Lu, Z.; Lou, W.; Yang, Y. Surface defect detection for mobile phone back glass based on symmetric convolutional neural network deep learning. Appl. Sci. 2020, 10, 3621. [Google Scholar] [CrossRef]
- Darwish, A.; Ricci, M.; Zidane, F.; Vasquez, J.A.; Casu, M.R.; Lanteri, J.; Migliaccio, C.; Vipiana, F. Physical contamination detection in food Industry using microwave and machine learning. Electronics 2022, 11, 3115. [Google Scholar] [CrossRef]
- Coulthard, M.A. Image processing for automatic surface defect detection. In Proceedings of the Third International Conference on Image Processing and its Applications, Warwick, UK, 18–20 July 1989; pp. 192–196. [Google Scholar]
- Zhu, L.; Spachos, P.; Pensini, E.; Plataniotis, K.N. Deep learning and machine vision for food processing: A survey. Curr. Res. Food Sci. 2021, 4, 233–249. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 1–40. [Google Scholar] [CrossRef]
- Park, J.-K.; Kwon, B.-K.; Park, J.-H.; Kang, D.-J. Machine learning-based imaging system for surface defect inspection. Int. J. Precis. Eng. Manuf. Technol. 2016, 3, 303–310. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference On Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Kim, P.; Kim, P. MATLAB Deep Learning with Machine Learning Neural Networks Artificial Intelligence. In Convolutional Neural Network; Springer: Berlin/Heidelberg, Germany, 2017; pp. 121–147. [Google Scholar]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Krichen, M. Convolutional Neural Networks: A Survey. Computers 2023, 12, 151. [Google Scholar] [CrossRef]
- Alahmari, F.; Naim, A.; Alqahtani, H. E-Learning Modeling Technique and Convolution Neural Networks in Online Education. In IoT-Enabled Convolutional Neural Networks: Techniques and Applications; River Publishers: Aalborg, Denmark, 2023; pp. 261–295. [Google Scholar]
- Zhou, L.; Zhang, C.; Liu, F.; Qiu, Z.; He, Y. Application of deep learning in food: A review. Compr. Rev. Food Sci. Food Saf. 2019, 18, 1793–1811. [Google Scholar] [CrossRef]
- Vaddi, R.; Manoharan, P. Hyperspectral image classification using CNN with spectral and spatial features integration. Infrared Phys. Technol. 2020, 107, 103296. [Google Scholar] [CrossRef]
- Ng, W.; Minasny, B.; McBratney, A. Convolutional neural network for soil microplastic contamination screening using infrared spectroscopy. Sci. Total Environ. 2020, 702, 134723. [Google Scholar] [CrossRef] [PubMed]
- Andri, R.; Cavigelli, L.; Rossi, D.; Benini, L. YodaNN: An ultra-low power convolutional neural network accelerator based on binary weights. In Proceedings of the 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, PA, USA, 11–13 July 2016; pp. 236–241. [Google Scholar]
- Yepeng, Z.; Yuezhen, T.; Zhiyong, F. Application of digital image process technology to the mouth of beer bottle defect inspection. In Proceedings of the 2007 8th International Conference on Electronic Measurement and Instruments, Xi’an, China, 16–18 August 2007; pp. 2–905. [Google Scholar]
- Shah, S.S.A.; Khalil, M.A.; Shah, S.I.; Khan, U.S. Ball Detection and Tracking Through Image Processing Using Embedded Systems. In Proceedings of the 2018 IEEE 21st International Multi-Topic Conference (INMIC), Karachi, Pakistan, 1–2 November 2018; pp. 1–5. [Google Scholar]
- Hassan, S.-A.; Rahim, T.; Shin, S.-Y. An Improved Deep Convolutional Neural Network-Based Autonomous Road Inspection Scheme Using Unmanned Aerial Vehicles. Electronics 2021, 10, 2764. [Google Scholar] [CrossRef]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Raza, K.; Song, H. Fast and accurate fish detection design with improved YOLO-v3 model and transfer learning. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 2. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, X.; Gao, Y.; Qu, T.; Shi, Y. Improved CNN method for crop pest identification based on transfer learning. Comput. Intell. Neurosci. 2022, 2022. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Sharma, A.K.; Foroosh, H. Slim-cnn: A light-weight cnn for face attribute prediction. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 329–335. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. 2019. Available online: https//www.bmvc2020-conference.com/assets/papers/0928.pdf (accessed on 30 July 2023).
- Wittenberg, C. Human-CPS Interaction-requirements and human-machine interaction methods for the Industry 4.0. IFAC-PapersOnLine 2016, 19, 420–425. [Google Scholar] [CrossRef]
- Gambao, E.; Hernando, M.; Surdilovic, D. A new generation of collaborative robots for material handling. In Proceedings of the ISARC, International Symposium on Automation and Robotics in Construction; IAARC Publications: Eindhoven, Netherlands, 2012; p. 1. [Google Scholar]
- Krüger, J.; Lien, T.K.; Verl, A. Cooperation of human and machines in assembly lines. CIRP Ann. 2009, 58, 628–646. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Swish: A self-gated activation function. arXiv 2017, arXiv:1710.059415. [Google Scholar]
- Kabir, S.; Sakib, S.; Hossain, M.A.; Islam, S.; Hossain, M.I. A convolutional neural network based model with improved activation function and optimizer for effective intrusion detection and classification. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 373–378. [Google Scholar]
- Pattanaik, A.; Balabantaray, R.C. Enhancement of license plate recognition performance using Xception with Mish activation function. Multimed. Tools Appl. 2023, 82, 16793–16815. [Google Scholar] [CrossRef]
- Rasamoelina, A.D.; Adjailia, F.; Sinčák, P. A review of activation function for artificial neural network. In Proceedings of the 2020 IEEE 18th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herlany, Slovakia, 23–25 January 2020; pp. 281–286. [Google Scholar]
- Kumar, R. APTx: Better activation function than MISH, SWISH, and ReLU’s variants used in deep learning. arXiv 2023, arXiv:2209.06119. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Montalbo, F.J.P. A computer-aided diagnosis of brain tumors using a fine-tuned YOLO-based model with transfer learning. KSII Trans. Internet Inf. Syst. 2020, 14, 4816–4834. [Google Scholar]
- Wei, Y.; Liu, X. Dangerous goods detection based on transfer learning in X-ray images. Neural Comput. Appl. 2020, 32, 8711–8724. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, Y.; Men, C.; Li, X. Tiny YOLO optimization oriented bus passenger object detection. Chinese J. Electron. 2020, 29, 132–138. [Google Scholar] [CrossRef]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 687–694. [Google Scholar]
- Rahim, T.; Hassan, S.A.; Shin, S.Y. A deep convolutional neural network for the detection of polyps in colonoscopy images. Biomed. Signal Process. Control 2021, 68, 102654. [Google Scholar] [CrossRef]
- Ranjbar, M.; Lan, T.; Wang, Y.; Robinovitch, S.N.; Li, Z.-N.; Mori, G. Optimizing nondecomposable loss functions in structured prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 911–924. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A comprehensive survey of loss functions in machine learning. Ann. Data Sci. 2020, 1–26. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Learning rate | 0.001 |
| Optimizer | SGD |
| Batch size | 32 |
| Subdivisions | 4 |
| Input dimension | 416 × 416 |
| Exposure | 1.5 |
| Saturation | 1.5 |
| Channels | 3 |
| Hue | 0.1 |
| Momentum | 0.9 |
| Decay | 0.0005 |
| Performance Metrics | ||||
|---|---|---|---|---|
| Default Model (%) | Enhanced Model (%) | |||
| Pre | 100 | Pre | 56.34 | |
| Shaving Foam | Sen | 95.77 | Sen | 79.06 |
| Pre | 63.7 | Pre | 97.45 | |
| Spot. | Sen | 58.95 | Sen | 86.46 |
| Pre | 100 | Pre | 96.77 | |
| Tomato Paste | Sen | 62.83 | Sen | 83.33 |
| Pre | 100 | Pre | 100 | |
| Chocolate | Sen. | 56.6 | Sen | 80 |
| Pre | 92.1 | Pre | 100 | |
| Coffee | Sen | 70.1 | Sen | 88.53 |
| Pre | 100 | Pre | 97.1 | |
| Conditioner | Sen | 55.6 | Sen | 78.82 |
| Pre | 98.83 | Pre | 96.51 | |
| Cream | Sen | 60.71 | Sen | 82.17 |
| Pre | 95.29 | Pre | 98.79 | |
| Jam | Sen | 59.55 | Sen | 82 |
| Pre | 97.53 | Pre | 100 | |
| Toothpaste | Sen | 58.95 | Sen | 81.81 |
| Model | mAP% | F1-Score%s | Average Recall% |
|---|---|---|---|
| Default Model | 93.21 | 93.00 | 94.00 |
| Enhanced Model | 99.74 | 98.00 | 98.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, S.A.; Khalil, M.A.; Auletta, F.; Filosa, M.; Camboni, D.; Menciassi, A.; Oddo, C.M. Contamination Detection Using a Deep Convolutional Neural Network with Safe Machine—Environment Interaction. Electronics 2023, 12, 4260. https://doi.org/10.3390/electronics12204260
Hassan SA, Khalil MA, Auletta F, Filosa M, Camboni D, Menciassi A, Oddo CM. Contamination Detection Using a Deep Convolutional Neural Network with Safe Machine—Environment Interaction. Electronics. 2023; 12(20):4260. https://doi.org/10.3390/electronics12204260
Chicago/Turabian StyleHassan, Syed Ali, Muhammad Adnan Khalil, Fabrizia Auletta, Mariangela Filosa, Domenico Camboni, Arianna Menciassi, and Calogero Maria Oddo. 2023. "Contamination Detection Using a Deep Convolutional Neural Network with Safe Machine—Environment Interaction" Electronics 12, no. 20: 4260. https://doi.org/10.3390/electronics12204260
APA StyleHassan, S. A., Khalil, M. A., Auletta, F., Filosa, M., Camboni, D., Menciassi, A., & Oddo, C. M. (2023). Contamination Detection Using a Deep Convolutional Neural Network with Safe Machine—Environment Interaction. Electronics, 12(20), 4260. https://doi.org/10.3390/electronics12204260