
A Composite Pipeline for Forwarding Low-Latency Traffic in SDN Programmable Data Planes


Abstract
1. Introduction
- We extend the POF (Protocol-Oblivious Forwarding) southbound interface protocol, based on which we provide a method to label low-latency flows.
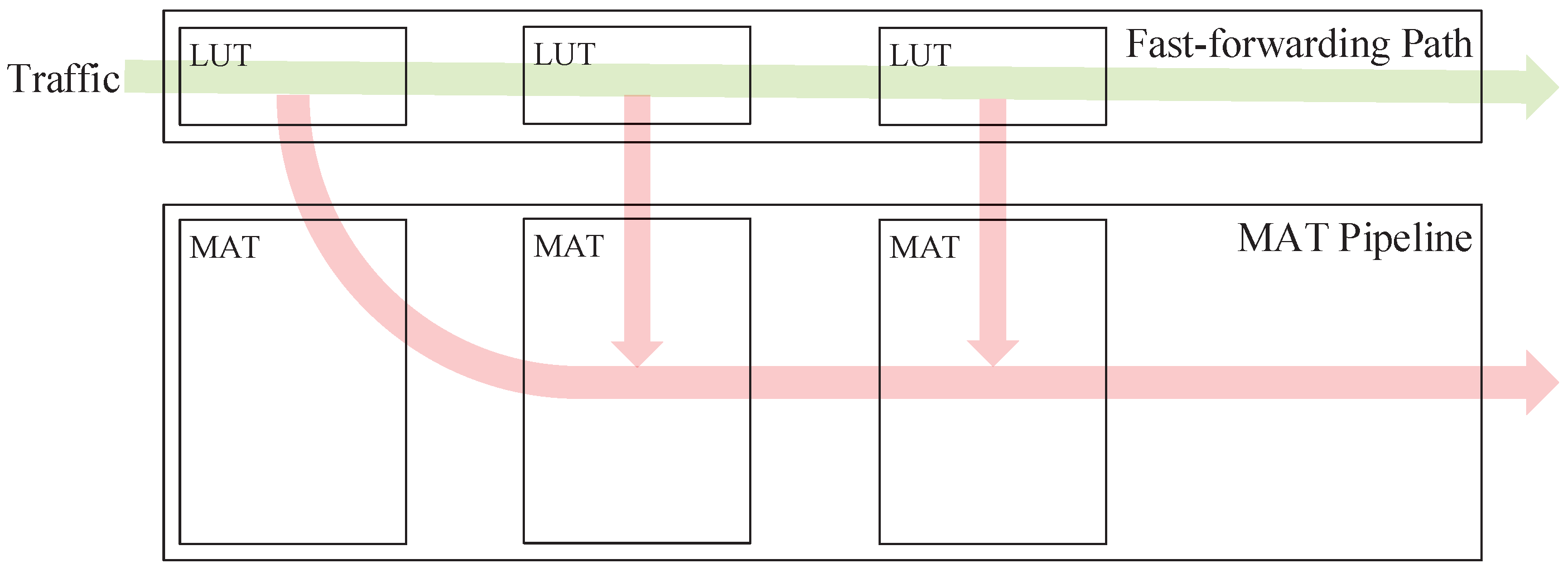
- We design a fast-forwarding path (FFP) that prioritizes low-latency flows without affecting the work of the MAT pipeline. The design includes the method to extract forwarding rules from MATs, the process of forwarding low-latency traffic, real-time FFP updating, etc.
- We implement the above scheme on a DPDK-based POF Switch and compare it with the original POF Switch. The results show that our proposed approach can effectively reduce the forwarding latency of low-latency traffic.
2. Literature Review and Background Work
2.1. Background Work
2.2. Related Work
2.2.1. Global Routing Adjustment
2.2.2. Flow Caching
2.2.3. Hardware-Based Acceleration
3. Problem Description
- How to identify and extract low-latency traffic? The POF Switch does not have a packet parser module to obtain the packet header protocol fields by parsing the packets in advance, which makes the design of the front-end traffic identification module very difficult. Therefore, we will use a runtime identification scheme to jointly participate in the identification and extraction of low-latency traffic by adding tags to the packets and forwarding rules in combination with control-plane decisions.
- After extracting the low-latency traffic, how to design a dedicated processing path with a better forwarding performance than the original MAT pipeline? Due to the nature of the POF, methods such as full-domain hashing that are used in other switch solutions for flow caching implementation would introduce an excessive time and space complexity, so we consider following the structure of a hierarchical processing pipeline. This requires us to improve the execution efficiency of individual processing stages. Further, we also need to optimize the lookup algorithm for certain tables for different match field types.
4. The Proposed Mechanisms
4.1. Definition and Recognition of Low-Latency Flows
4.2. Composite Pipeline Architecture
4.2.1. Architecture Design
4.2.2. Preliminary Benefit Analysis
4.2.3. Runtime Updating of the FFP
5. Experimental Results
5.1. Simulation Setup
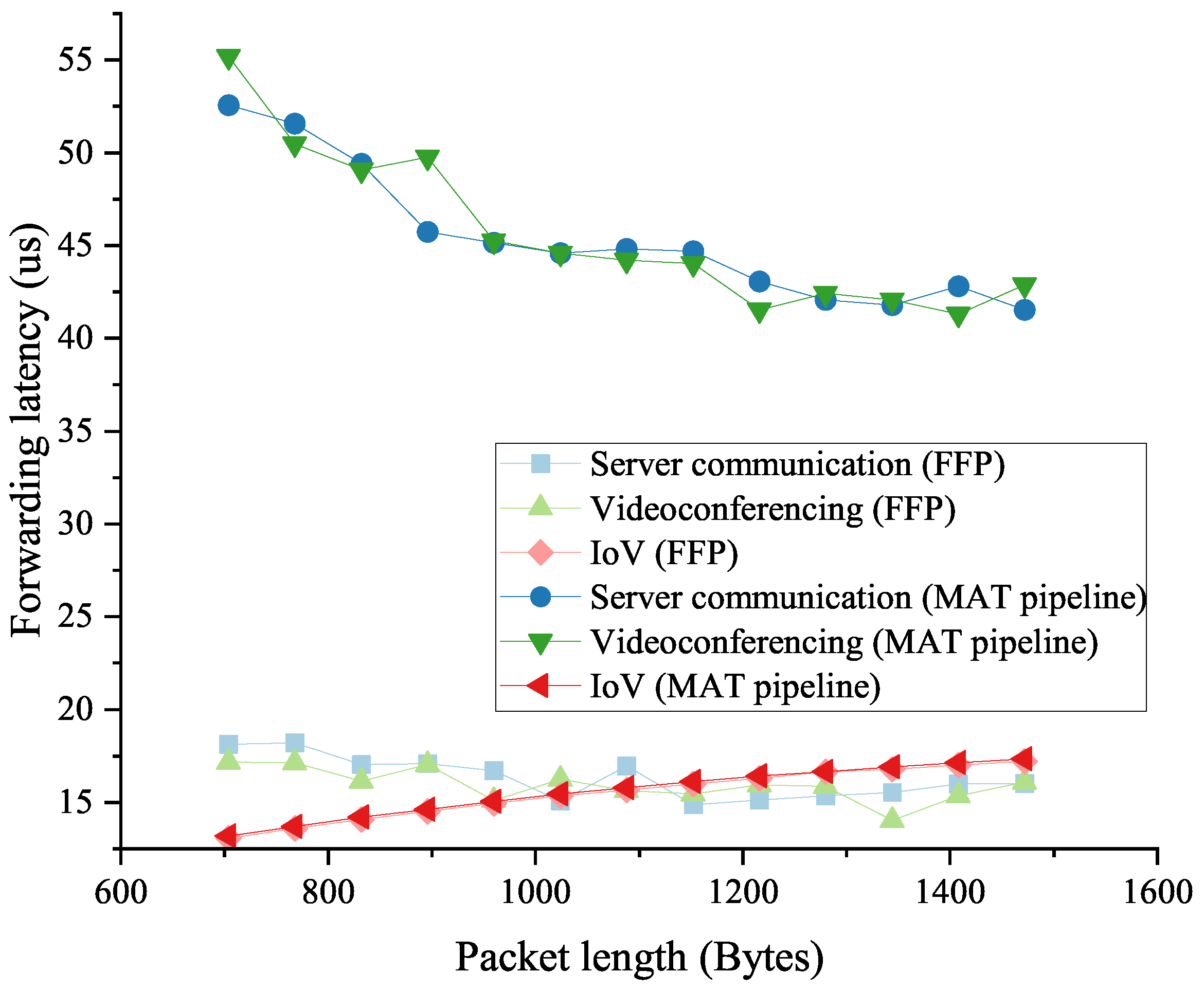
- Communication in the big data processing. Communication between servers in DCNs requires basic routing and techniques such as an ACL to secure the network and servers. We use an ACL as a traffic processing step in our experiments to test the forwarding performance of the traffic.
- Videoconferencing. Videoconferencing is a typical use case of the publish–subscribe pattern in the present and future networks, with high requirements for video transmission quality and latency. We choose the SEADP (on-Site, Elastic, Autonomous Datagram Protocol) as the transport-layer protocol to encapsulate the traffic in our tests because it can provide ID-IP resolution-based routing and multiple QoS supports.
- IoV (Internet of Vehicles). As one of the core applications of 5G communication, the IoV demands an extremely low response latency. We use WSM (Wave Short Message) in our experiments to carry the simulated traffic of the IoV.
5.1.1. Forwarding Performance for Low-Latency Traffic
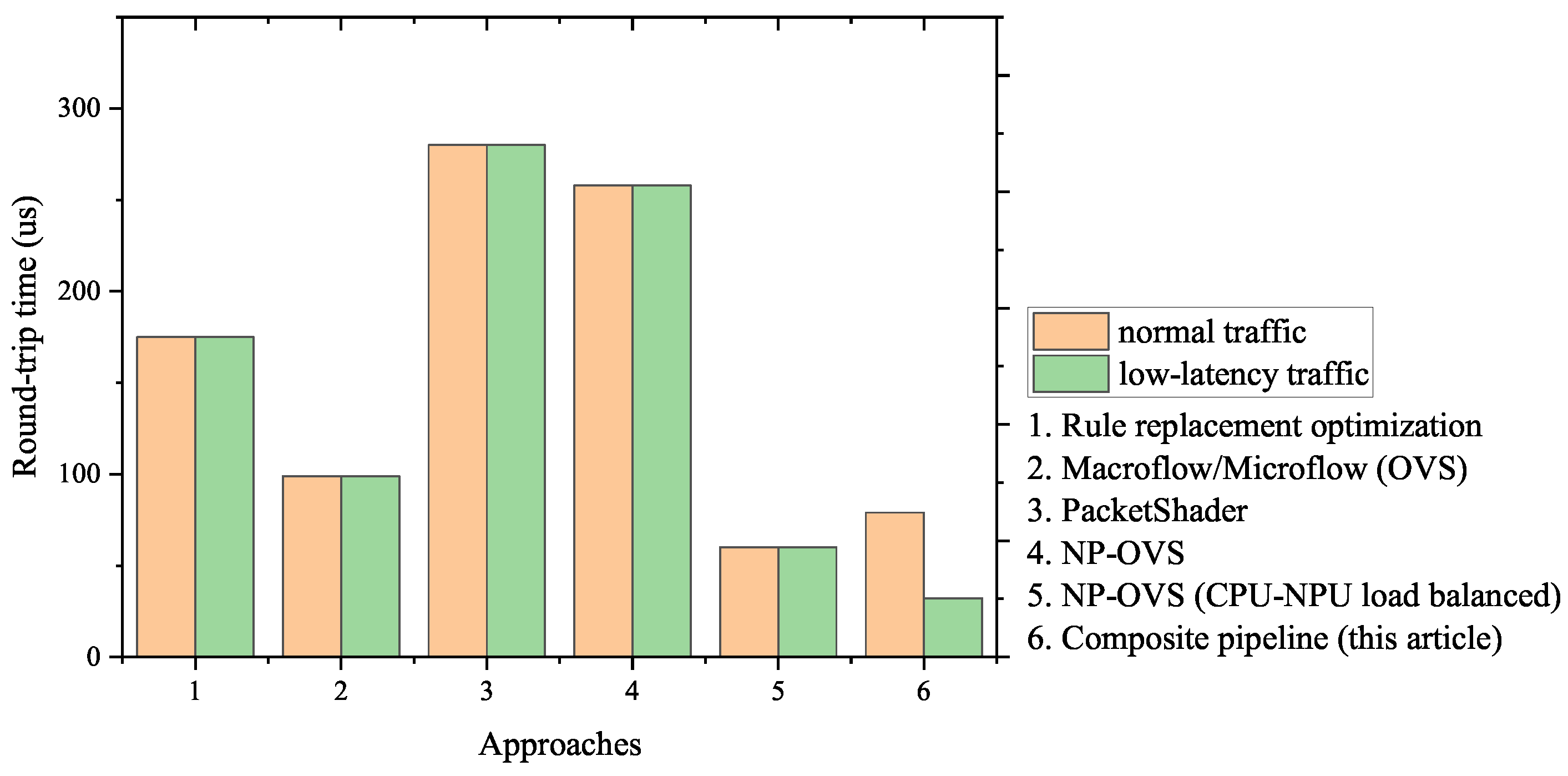
5.1.2. Forwarding Performance in Mixed Traffic Scenarios
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ICN | Information-Centric Networking |
| DCN | Data Center Networking |
| SDN | Software-Defined Networking |
| QoS | Quality of Service |
| MAT | Match-Action Table |
| POF | Protocol-Oblivious Forwarding |
| FFP | Fast-Forwarding Path |
| PISA | Protocol-Independent Switch Architecture |
| TCAM | Ternary Content Addressable Memory |
| OVS | Open vSwitch |
| NP | Network Processor |
| FRT | Forwarding Rule Table |
| LUT | LookUp Table |
| EM | Exact Matching |
| LPM | Longest Prefix Matching |
| MM | Mask Matching |
| NDN | Named Data Networking |
| ACL | Access Control List |
| SEADP | on-Site, Elastic, Autonomous Datagram Protocol |
| IoV | Internet of Vehicles |
| WSM | Wave Short Message |
| FIB | Forwarding Information dataBase |
References
- Nasrallah, A.; Thyagaturu, A.S.; Alharbi, Z.; Wang, C.; Shao, X.; Reisslein, M.; ElBakoury, H. Ultra-low latency (ull) networks: The ieee tsn and ietf detnet standards and related 5g ull research. IEEE Commun. Surv. Tutor. 2018, 21, 88–145. [Google Scholar] [CrossRef]
- Wang, J.; Cheng, G.; You, J.; Sun, P. Seanet: Architecture and technologies of an on-site, elastic, autonomous network. J. Netw. New Media 2020, 6, 1–8. [Google Scholar]
- Han, F.; Wang, M.; Cui, Y.; Li, Q.; Liang, R.; Liu, Y.; Jiang, Y. Future data center networking: From low latency to deterministic latency. IEEE Netw. 2022, 36, 52–58. [Google Scholar] [CrossRef]
- Hammadi, A.; Mhamdi, L. A survey on architectures and energy efficiency in data center networks. Comput. Commun. 2014, 40, 1–21. [Google Scholar] [CrossRef]
- Cisco Annual Internet Report (2018–2023) White Paper; Cisco: San Jose, CA, USA, 2020.
- Li, T.; Chen, J.; Fu, H. Application scenarios based on sdn: An overview. J. Phys. Conf. Ser. 2019, 1187, 052067. [Google Scholar] [CrossRef]
- Bifulco, R.; Rétvári, G. A survey on the programmable data plane: Abstractions, architectures, and open problems. In Proceedings of the 2018 IEEE 19th International Conference on High Performance Switching and Routing (HPSR), Bucharest, Romania, 18–20 June 2018; pp. 1–7. [Google Scholar]
- Czekaj, M.; Jamro, E. Flow caching effectiveness in packet forwarding applications. Comput. Sci. 2019, 20, 144. [Google Scholar] [CrossRef]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. Openflow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Openflow Switch Specification Version 1.5.1. Available online: http://www.openflow.org/ (accessed on 18 December 2022).
- Song, H. Protocol-oblivious forwarding: Unleash the power of sdn through a future-proof forwarding plane. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, Hong Kong, China, 12–16 August 2013; pp. 127–132. [Google Scholar]
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Bosshart, P.; Gibb, G.; Kim, H.-S.; Varghese, G.; McKeown, N.; Izzard, M.; Mujica, F.; Horowitz, M. Forwarding metamorphosis: Fast programmable match-action processing in hardware for sdn. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 99–110. [Google Scholar] [CrossRef]
- Li, S.; Hu, D.; Fang, W.; Ma, S.; Chen, C.; Huang, H.; Zhu, Z. Protocol oblivious forwarding (pof): Software-defined networking with enhanced programmability. IEEE Netw. 2017, 31, 58–66. [Google Scholar] [CrossRef]
- Shelly, N.; Jackson, E.J.; Koponen, T.; McKeown, N.; Rajahalme, J. Flow caching for high entropy packet fields. In Proceedings of the Third Workshop on Hot Topics in Software Defined Networking, Chicago, IL, USA, 22 August 2014; pp. 151–156. [Google Scholar]
- Wan, Y.; Song, H.; Xu, Y.; Wang, Y.; Pan, T.; Zhang, C.; Liu, B. T-cache: Dependency-free ternary rule cache for policy-based forwarding. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 536–545. [Google Scholar]
- Li, R.; Pang, Y.; Zhao, J.; Wang, X. A tale of two (flow) tables: Demystifying rule caching in openflow switches. In Proceedings of the 48th International Conference on Parallel Processing, Kyoto, Japan, 5–8 August 2019; pp. 1–10. [Google Scholar]
- Dong, M.; Li, H.; Ota, K.; Xiao, J. Rule caching in sdn-enabled mobile access networks. IEEE Netw. 2015, 29, 40–45. [Google Scholar] [CrossRef]
- Katta, N.; Alipourfard, O.; Rexford, J.; Walker, D. Infinite cacheflow in software-defined networks. In Proceedings of the Third Workshop on Hot Topics in Software Defined Networking, Chicago, IL, USA, 22 August 2014; pp. 175–180. [Google Scholar]
- Katta, N.; Alipourfard, O.; Rexford, J.; Walker, D. Cacheflow: Dependency-aware rule-caching for software-defined networks. In Proceedings of the Symposium on SDN Research, Clara, CA, USA, 14–15 March 2016; pp. 1–12. [Google Scholar]
- Daly, J.; Bruschi, V.; Linguaglossa, L.; Pontarelli, S.; Rossi, D.; Tollet, J.; Torng, E.; Yourtchenko, A. Tuplemerge: Fast software packet processing for online packet classification. IEEE/ACM Trans. Netw. 2019, 27, 1417–1431. [Google Scholar] [CrossRef]
- Mimidis-Kentis, A.; Pilimon, A.; Soler, J.; Berger, M.; Ruepp, S. A novel algorithm for flow-rule placement in sdn switches. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft), Montreal, QC, Canada, 25–29 June 2018; pp. 1–9. [Google Scholar]
- Narayanan, R.; Kotha, S.; Lin, G.; Khan, A.; Rizvi, S.; Javed, W.; Khan, H.; Khayam, S.A. Macroflows and microflows: Enabling rapid network innovation through a split sdn data plane. In Proceedings of the 2012 European Workshop on Software Defined Networking, Darmstadt, Germany, 25–26 October 2012; pp. 79–84. [Google Scholar]
- Han, S.; Jang, K.; Park, K.; Moon, S. Packetshader: A gpu-accelerated software router. ACM SIGCOMM Comput. Commun. Rev. 2010, 40, 195–206. [Google Scholar] [CrossRef]
- Luo, Y.; Cascon, P.; Murray, E.; Ortega, J. Accelerating openflow switching with network processors. In Proceedings of the 5th ACM/IEEE Symposium on Architectures for Networking and Communications Systems, Princeton, NJ, USA, 19–20 October 2009; pp. 70–71. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Reference | Contributions | Shortcoming |
|---|---|---|---|
| Global routing adjustment | Rule replacement optimization [22] | Improved forwarding performance | High time complexity |
| Flow caching | Open vSwitch [23] | High performance and scalability | Low cache hit ratio for single-connection traffic |
| Hardware-based acceleration | PacketShader [24], OpenFlow switch with NP acceleration card [25] | Higher forwarding performance than software solutions | Less programmability |
| Hierarchical-hash rule caching | This article | Extract and fast-forward low-latency traffic | Little latency increasement for normal traffic in some scenarios |
| Table Types | Linear | EM | MM | LPM |
| Searching time | C |
| Traffic Type | Average Round-Trip Time (μs) | Reliability |
|---|---|---|
| Server communication | 14 ± 0.5 | 99.99999% |
| Videoconferencing | 15 ± 0.2 | 99.99999% |
| IoV | 15 ± 0.2 | 99.999% |
| Approaches | Average Round-Trip Time before Optimization (μs) | Average Round-Trip Time after Optimization (μs) | Reduction for Normal Traffic | Reduction for Low-Latency Traffic |
|---|---|---|---|---|
| Rule replacement optimization | 184 | 175 | 4.89% | - |
| Macroflow/ Microflow (OVS) | 172 | 99 | 42.44% | - |
| PacketShader | >1000 | 280 | >72.00% | - |
| NP-OVS | 313 | 258 | 17.57% | - |
| NP-OVS (CPU-NPU load balanced) | 234 | 60 | 74.36% | - |
| Composite pipeline (this article) | 90 | 32 | <10% | 64.44% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ling, Z.; Chen, X.; Song, L. A Composite Pipeline for Forwarding Low-Latency Traffic in SDN Programmable Data Planes. Electronics 2023, 12, 461. https://doi.org/10.3390/electronics12020461
Ling Z, Chen X, Song L. A Composite Pipeline for Forwarding Low-Latency Traffic in SDN Programmable Data Planes. Electronics. 2023; 12(2):461. https://doi.org/10.3390/electronics12020461
Chicago/Turabian StyleLing, Zhiyuan, Xiao Chen, and Lei Song. 2023. "A Composite Pipeline for Forwarding Low-Latency Traffic in SDN Programmable Data Planes" Electronics 12, no. 2: 461. https://doi.org/10.3390/electronics12020461
APA StyleLing, Z., Chen, X., & Song, L. (2023). A Composite Pipeline for Forwarding Low-Latency Traffic in SDN Programmable Data Planes. Electronics, 12(2), 461. https://doi.org/10.3390/electronics12020461