
VMLH: Efficient Video Moment Location via Hashing


Abstract
1. Introduction
- An efficient video-moment location method with hashing is proposed, which makes full use of hash retrieval and greatly improves the efficiency of the task.
- There is no complex interaction and fusion process in the proposed method, and videos do not need to be fed into the network during the location, which leads to higher efficiency and better scalability compared with the existing methods.
2. Related Work
2.1. Activity Localization
2.2. Video Retrieval with Sentence Queries
3. Proposed Method
3.1. Video Hashing Network
3.2. Sentence-Hashing Network
3.3. Location Prediction Network
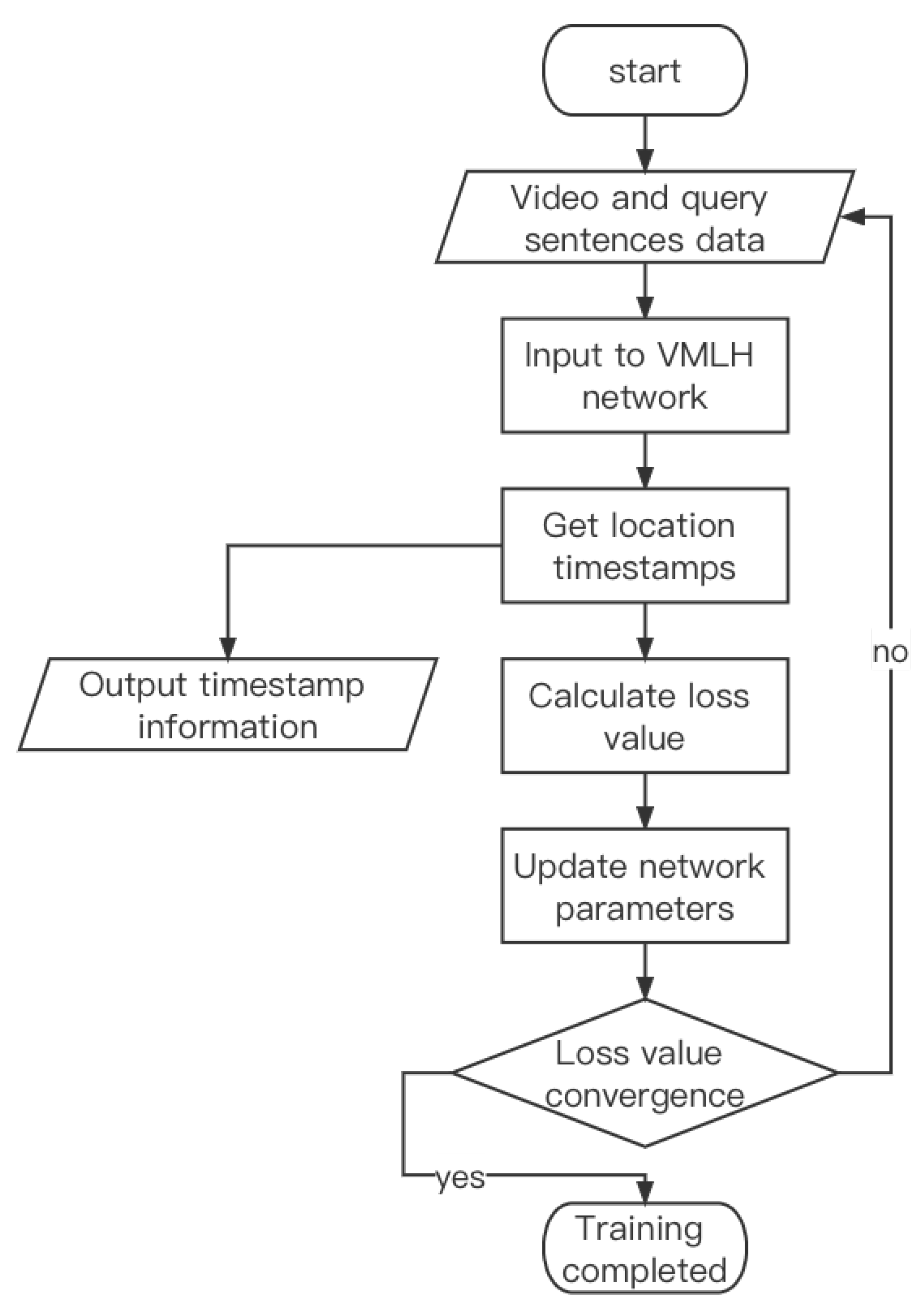
3.4. Training and Inference
| Algorithm 1: Learning algorithm for VMLH |
Input: Training video and the query sentence . The ground truth timestamps and . Output: Predicted video start and end timestamps and . Initialization: Initialize the model with the pretrained I3D and GloVe parameter file. Repeat: Randomly sample a minibatch of video from , obtain the corresponding sentence according to the video ID, and perform the following operations:
Until: a fixed number of iterations |
4. Experiments
4.1. Datasets
4.1.1. Charades-STA
4.1.2. ActivityNet Captions
4.2. Experimental Settings
4.3. Evaluation Metrics
4.4. Accuracy Performance
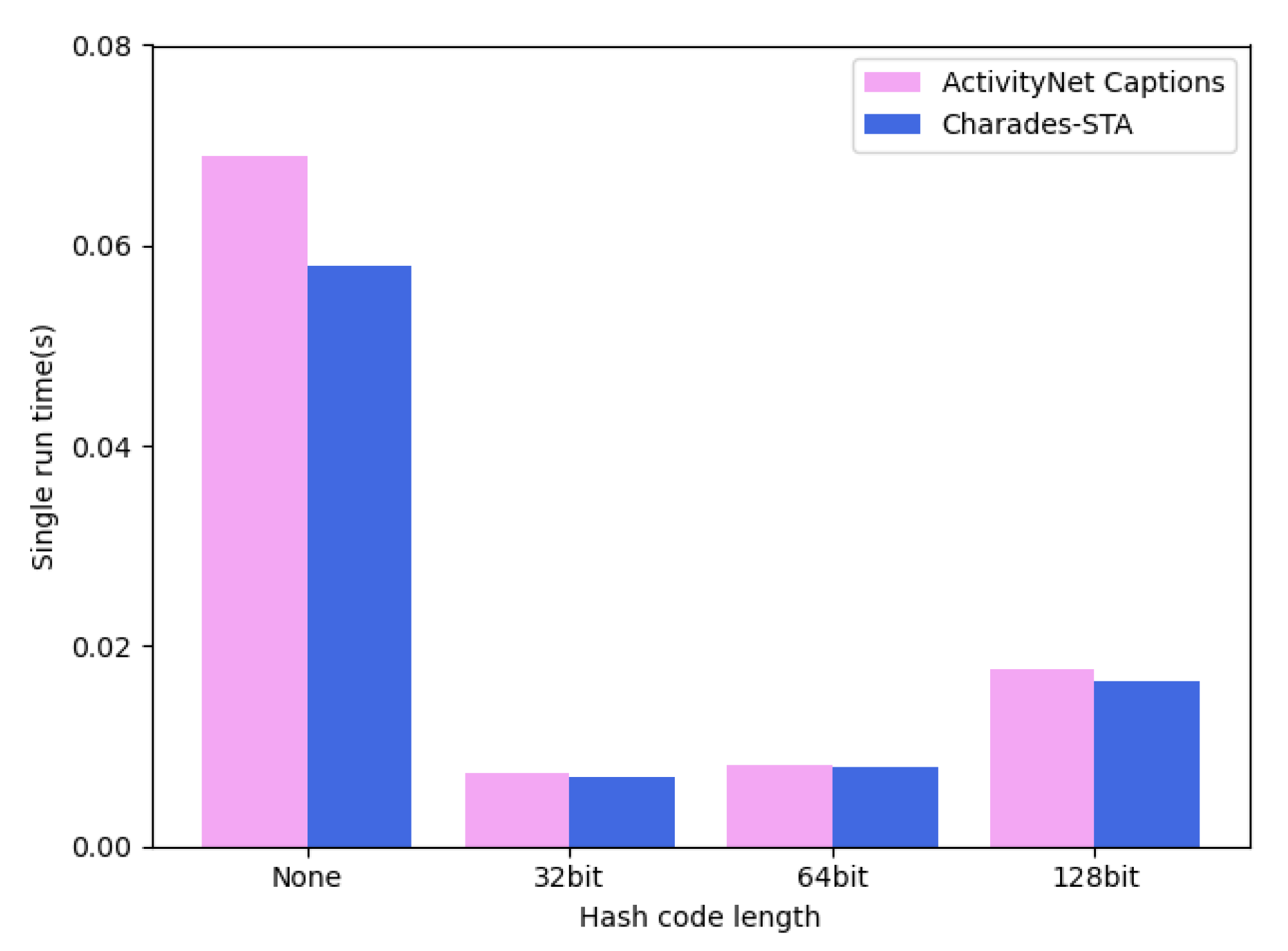
4.5. Model Efficiency
4.6. Ablation Experiment
4.7. Convergence Analysis
4.8. Qualitative Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hendricks, L.A.; Wang, O.; Shechtman, E.; Sivic, J.; Darrell, T.; Russell, B.C. Localizing Moments in Video with Natural Language. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5804–5813. [Google Scholar] [CrossRef]
- Gao, J.; Sun, C.; Yang, Z.; Nevatia, R. TALL: Temporal Activity Localization via Language Query. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5277–5285. [Google Scholar] [CrossRef]
- Chen, J.; Chen, X.; Ma, L.; Jie, Z.; Chua, T. Temporally Grounding Natural Sentence in Video. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 162–171. [Google Scholar] [CrossRef]
- Xu, H.; He, K.; Plummer, B.A.; Sigal, L.; Sclaroff, S.; Saenko, K. Multilevel Language and Vision Integration for Text-to-Clip Retrieval. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9062–9069. [Google Scholar] [CrossRef]
- Zhang, D.; Dai, X.; Wang, X.; Wang, Y.; Davis, L.S. MAN: Moment Alignment Network for Natural Language Moment Retrieval via Iterative Graph Adjustment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1247–1257. [Google Scholar] [CrossRef]
- Wang, W.; Huang, Y.; Wang, L. Language-Driven Temporal Activity Localization: A Semantic Matching Reinforcement Learning Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 334–343. [Google Scholar] [CrossRef]
- Ghosh, S.; Agarwal, A.; Parekh, Z.; Hauptmann, A.G. ExCL: Extractive Clip Localization Using Natural Language Descriptions. arXiv 2019, arXiv:1904.02755. [Google Scholar] [CrossRef]
- Lu, X.; Wang, W.; Shen, J.; Crandall, D.; Luo, J. Zero-shot video object segmentation with co-attention siamese networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2228–2242. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Wang, W.; Shen, J.; Crandall, D.J.; Van Gool, L. Segmenting objects from relational visual data. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7885–7897. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Wang, W.; Ma, C.; Shen, J.; Shao, L.; Porikli, F. See more, know more: Unsupervised video object segmentation with co-attention siamese networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3623–3632. [Google Scholar]
- Shen, J.; Liu, Y.; Dong, X.; Lu, X.; Khan, F.S.; Hoi, S. Distilled Siamese networks for visual tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8896–8909. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Ma, C.; Ni, B.; Yang, X. Adaptive region proposal with channel regularization for robust object tracking. IEEE Trans. Circuits Syst. Video Technol. 2019, 31, 1268–1282. [Google Scholar] [CrossRef]
- Sodhro, A.H.; Sangaiah, A.K.; Sodhro, G.H.; Lodro, M.M.; Sekhari, A.; Ouzrout, Y.; Pirbhulal, S.; Fatima, K. Medical quality of service optimization over internet of multimedia things. In Computational Intelligence for Multimedia Big Data on the Cloud with Engineering Applications; Elsevier: Amsterdam, The Netherlands, 2018; pp. 271–295. [Google Scholar]
- Shou, Z.; Chan, J.; Zareian, A.; Miyazawa, K.; Chang, S. CDC: Convolutional-De-Convolutional Networks for Precise Temporal Action Localization in Untrimmed Videos. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1417–1426. [Google Scholar] [CrossRef]
- Shou, Z.; Wang, D.; Chang, S. Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1049–1058. [Google Scholar] [CrossRef]
- Lin, T.; Zhao, X.; Shou, Z. Single Shot Temporal Action Detection. In Proceedings of the 2017 ACM on Multimedia Conference, Mountain View, CA, USA, 23–27 October 2017; pp. 988–996. [Google Scholar] [CrossRef]
- Mithun, N.C.; Li, J.; Metze, F.; Roy-Chowdhury, A.K. Learning Joint Embedding with Multimodal Cues for Cross-Modal Video-Text Retrieval. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 19–27. [Google Scholar] [CrossRef]
- Yu, Y.; Kim, J.; Kim, G. A Joint Sequence Fusion Model for Video Question Answering and Retrieval. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11211, pp. 487–503. [Google Scholar] [CrossRef]
- Chen, S.; Zhao, Y.; Jin, Q.; Wu, Q. Fine-Grained Video-Text Retrieval with Hierarchical Graph Reasoning. In Proceedings of the 2020 IEEE/CVF Conference on CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 10635–10644. [Google Scholar] [CrossRef]
- Chung, J.; Gülçehre, Ç.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Krishna, R.; Hata, K.; Ren, F.; Fei-Fei, L.; Niebles, J.C. Dense-Captioning Events in Videos. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 706–715. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.D.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef]
- Liu, L.; Shao, L. Sequential Compact Code Learning for Unsupervised Image Hashing. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 2526–2536. [Google Scholar] [CrossRef] [PubMed]
- Hahn, M.; Kadav, A.; Rehg, J.M.; Graf, H.P. Tripping through time: Efficient Localization of Activities in Videos. In Proceedings of the 31st British Machine Vision Conference 2020, Virtual, 7–10 September 2020. [Google Scholar]
- Liu, M.; Wang, X.; Nie, L.; He, X.; Chen, B.; Chua, T. Attentive Moment Retrieval in Videos. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 15–24. [Google Scholar] [CrossRef]
- Ge, R.; Gao, J.; Chen, K.; Nevatia, R. MAC: Mining Activity Concepts for Language-Based Temporal Localization. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 245–253. [Google Scholar] [CrossRef]
- Yuan, Y.; Mei, T.; Zhu, W. To Find Where You Talk: Temporal Sentence Localization in Video with Attention Based Location Regression. In Proceedings of the The Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9159–9166. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, M.; Su, X.; Gao, Z.; Nie, L. Video Moment Localization via Deep Cross-Modal Hashing. IEEE Trans. Image Process. 2021, 30, 4667–4677. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison | Cross–Merge Ratio | ||
|---|---|---|---|
| Method | IoU = 0.3 | IoU = 0.5 | IoU = 0.7 |
| MCN [1] | 39.35 | 21.36 | 6.43 |
| CTRL [26] | 47.43 | 29.01 | 10.34 |
| TGN [3] | 45.51 | 28.47 | - |
| TripNet [27] | 48.42 | 32.19 | 13.93 |
| ACRN [28] | 49.70 | 31.67 | 11.25 |
| VMLH | 52.15 | 34.50 | 17.16 |
| Comparison | Cross–Merge Ratio | |
|---|---|---|
| Method | IoU = 0.5 | IoU = 0.7 |
| CTRL [2] | 23.63 | 8.89 |
| MLVI [4] | 35.60 | 15.80 |
| ACL-K [29] | 30.48 | 12.20 |
| ACRN [28] | 20.26 | 7.64 |
| SM-RL [6] | 24.36 | 11.17 |
| QSPN [4] | 35.60 | 15.80 |
| TripNet [27] | 36.61 | 14.50 |
| VMLH | 43.80 | 20.32 |
| Method | Single Run Time (s) |
|---|---|
| CTRL [2] | 3.41 |
| ACRN [28] | 4.42 |
| ABLR [30] | 0.06 |
| CMHN [31] | 0.0076 |
| VMLH-full | 0.0093 |
| VMLH-vh | 0.0036 |
| VMLH-h | 0.0007 |
| Hash Code | Charades-STA | ActivityNet Captions | |||
|---|---|---|---|---|---|
| Length | IoU = 0.5 | IoU= 0.7 | IoU = 0.3 | IoU = 0.5 | IoU = 0.7 |
| 32 bit | 42.29 | 20.16 | 51.00 | 33.74 | 16.63 |
| 64 bit | 43.80 | 20.32 | 52.15 | 34.50 | 17.16 |
| 128 bit | 43.99 | 20.76 | 52.87 | 34.36 | 17.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, Z.; Dong, F.; Liu, X.; Li, C.; Nie, X. VMLH: Efficient Video Moment Location via Hashing. Electronics 2023, 12, 420. https://doi.org/10.3390/electronics12020420
Tan Z, Dong F, Liu X, Li C, Nie X. VMLH: Efficient Video Moment Location via Hashing. Electronics. 2023; 12(2):420. https://doi.org/10.3390/electronics12020420
Chicago/Turabian StyleTan, Zhifang, Fei Dong, Xinfang Liu, Chenglong Li, and Xiushan Nie. 2023. "VMLH: Efficient Video Moment Location via Hashing" Electronics 12, no. 2: 420. https://doi.org/10.3390/electronics12020420
APA StyleTan, Z., Dong, F., Liu, X., Li, C., & Nie, X. (2023). VMLH: Efficient Video Moment Location via Hashing. Electronics, 12(2), 420. https://doi.org/10.3390/electronics12020420