
Improving OSAHS Prevention Based on Multidimensional Feature Analysis of Snoring

Abstract
:1. Introduction
2. Sleep Respiratory Signal Acquisition System and Preprocessing
2.1. Data Acquisition System
2.2. Audio Signal Preprocessing and Snoring Event Monitoring
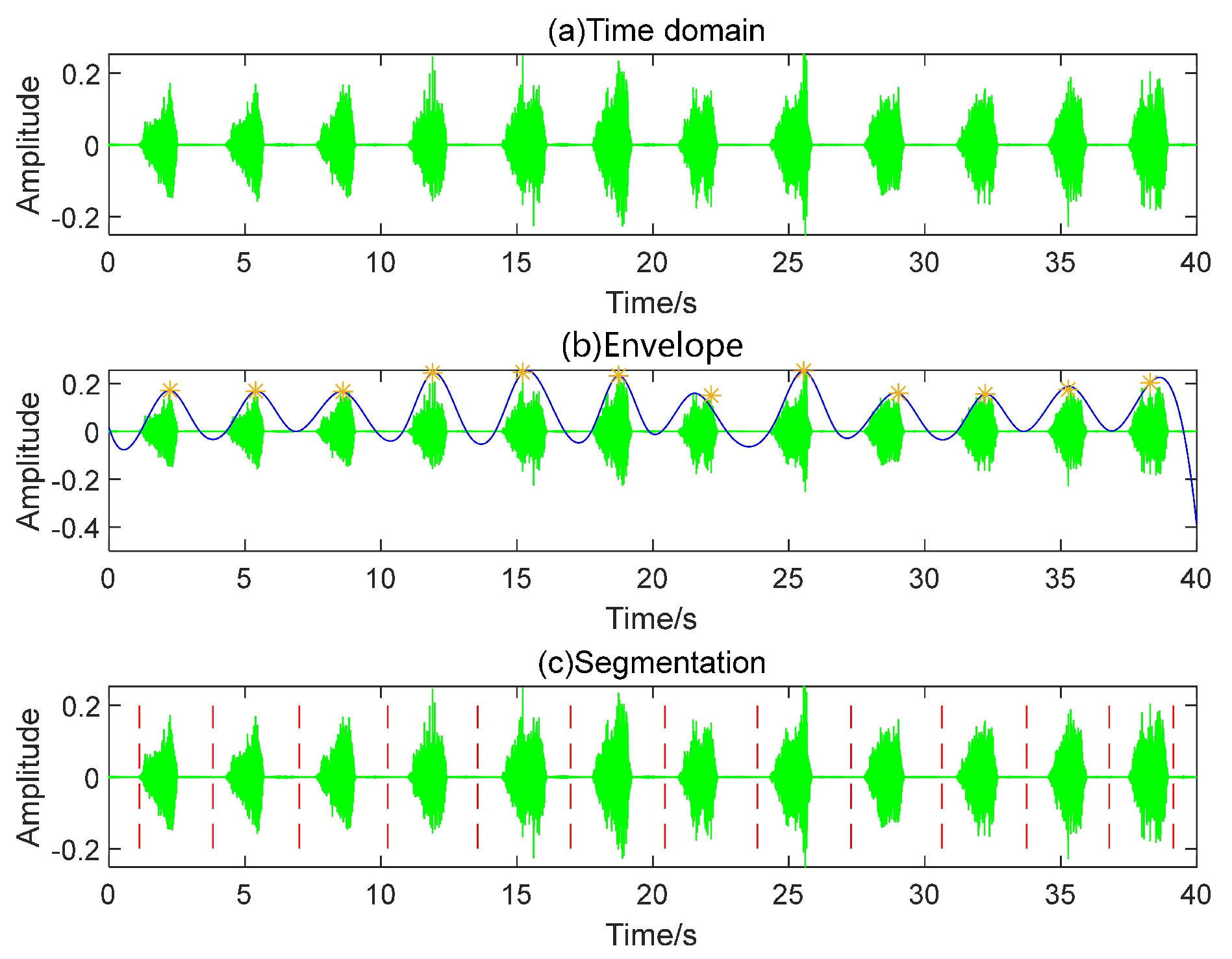
- Step 1: Read the audio file and generate a time-domain map.
- Step 2: Utilize the envelope function to extract the waveform’s envelope, selecting “peak” as the function’s argument. Subsequently, employ the “find-peaks” function to locate the envelope’s peaks. The peak interval threshold is set to 5/2*fs, where fs represents the audio sampling rate.
- Step 3: Compute the midpoints between adjacent peaks, using these points as the start and end to partition the entire audio. The effect of localized segmentation detection is illustrated in Figure 3.
- Step 4: Locate the segmented audio using the double-threshold method, calculate the valid segment length, filter out valid data falling within the 0.8–4.8 s range, and consolidate the filtered data.
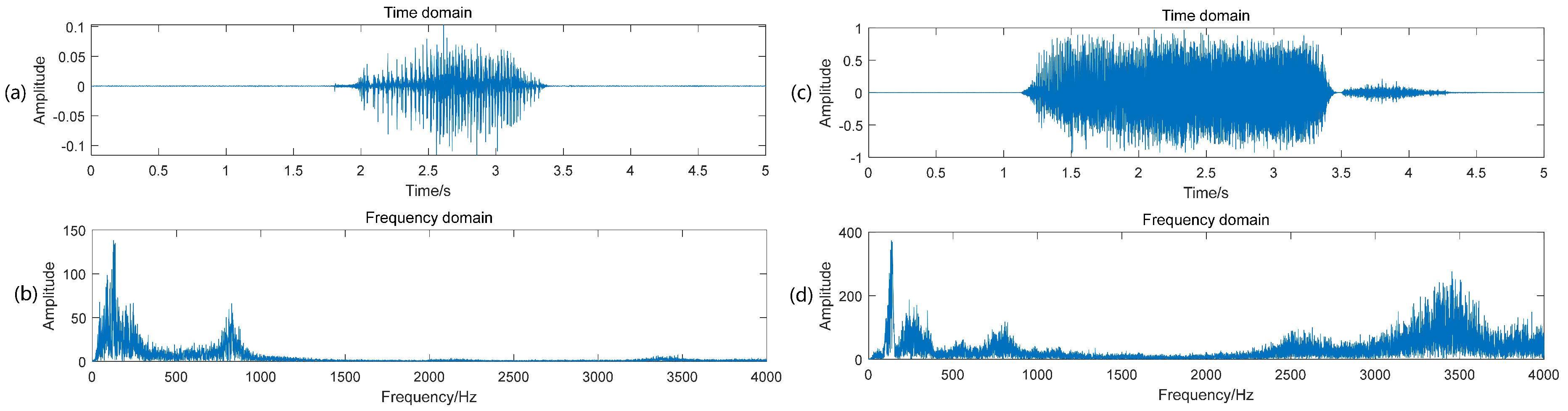
3. Classification of Breath Sound and Snoring
4. Dataset of Sleep Sound Signal
5. Multi-Features Extraction
5.1. Time-Domain Feature Extraction
5.2. Frequency-Domain Feature Extraction
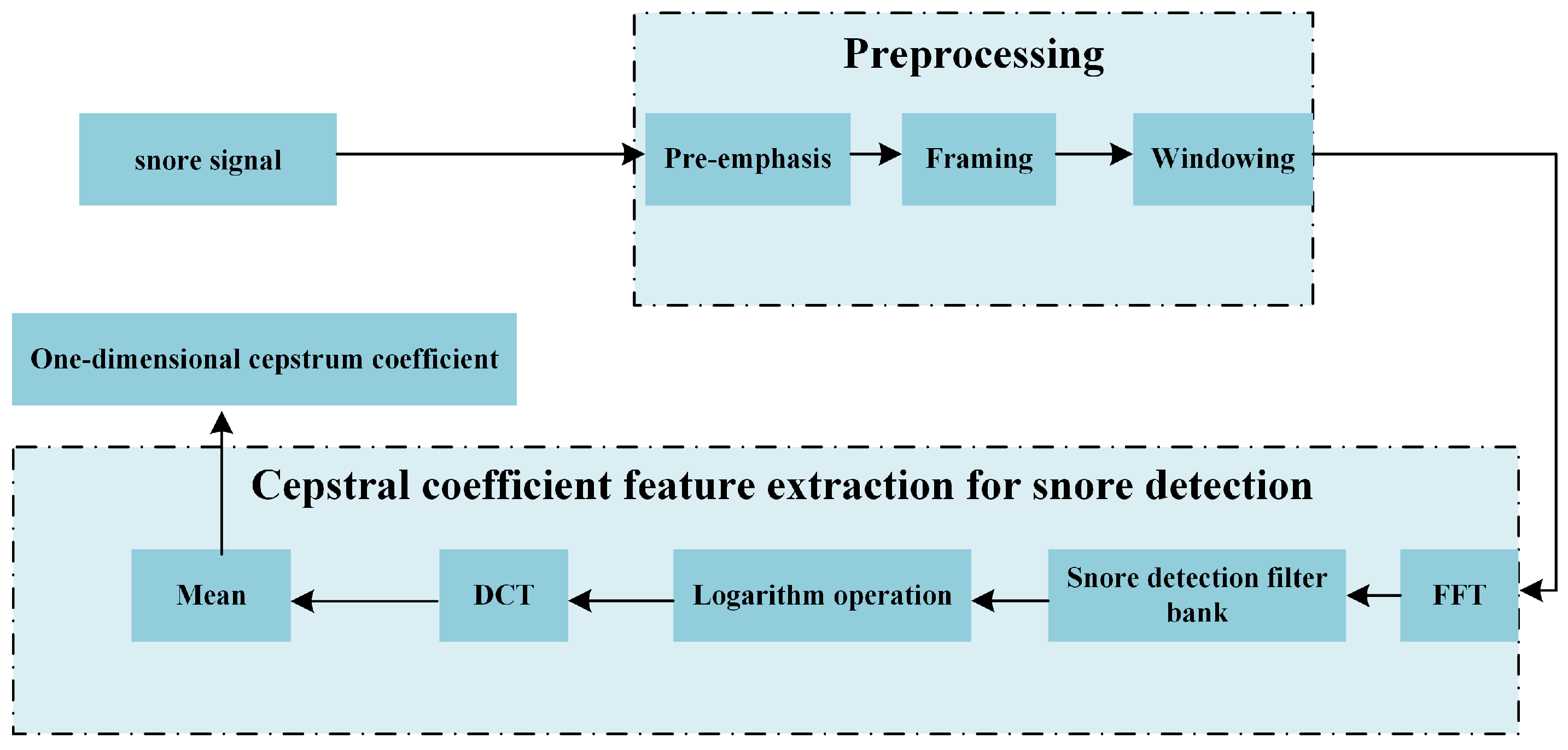
5.3. Cepstral Feature Extraction
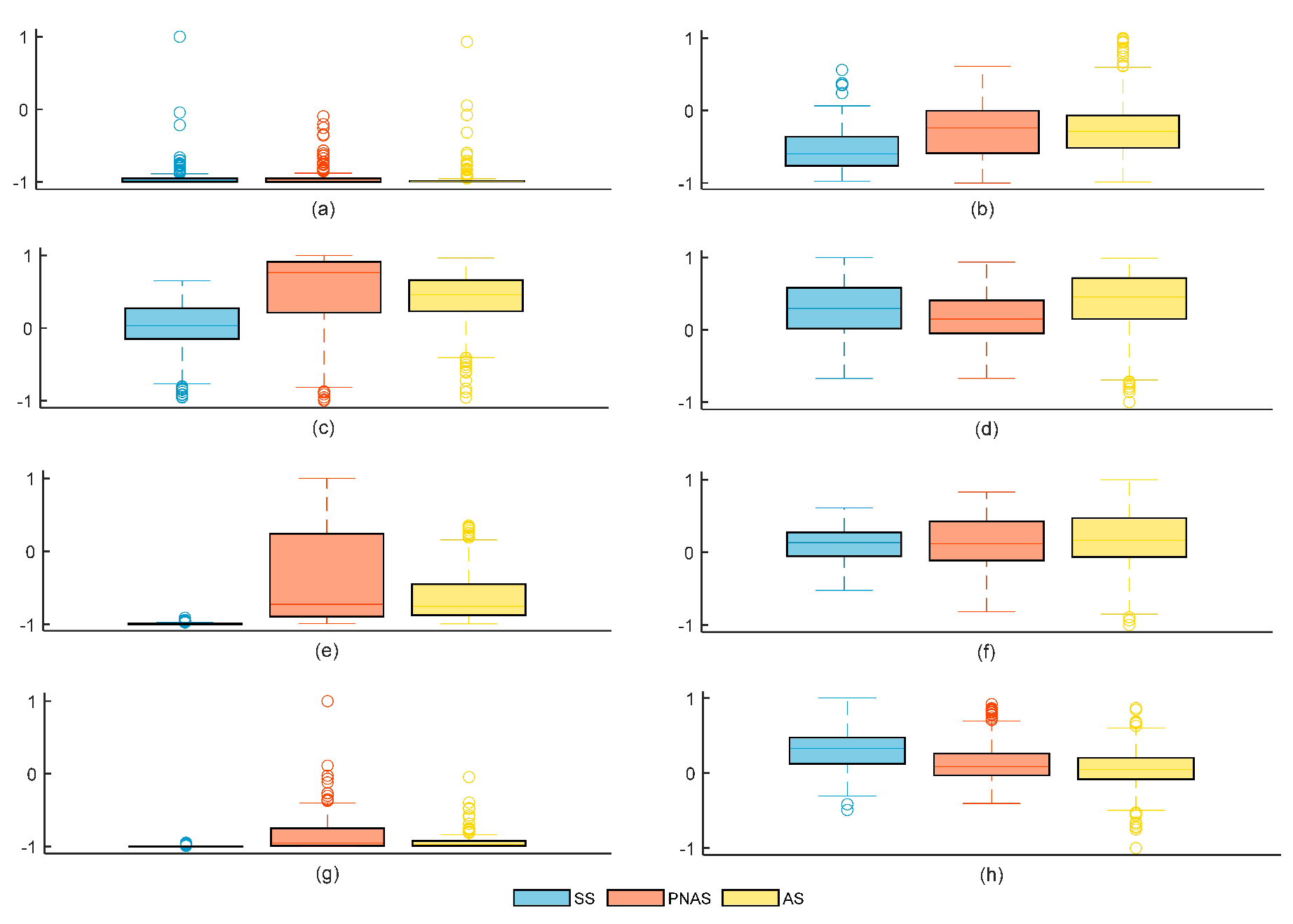
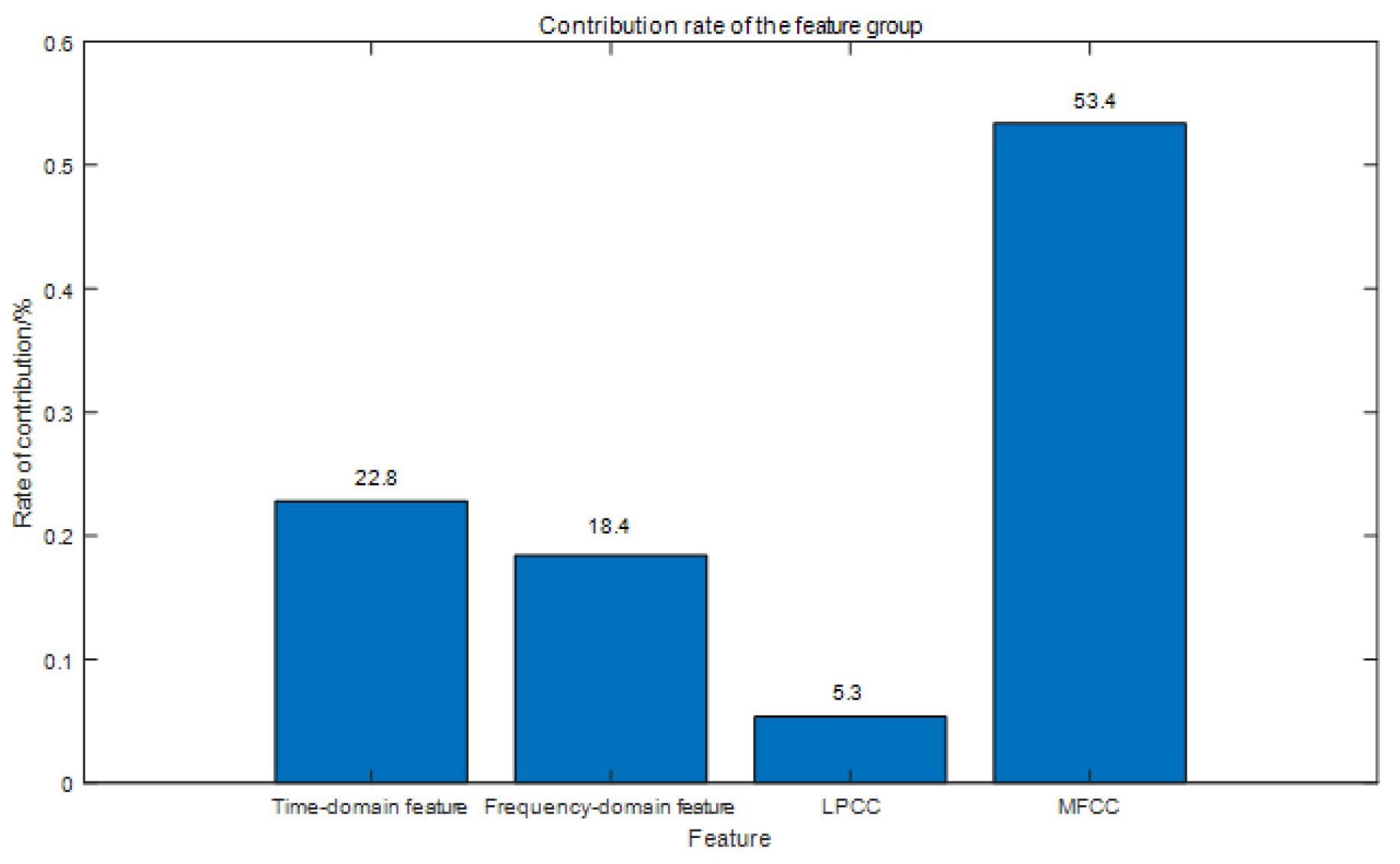
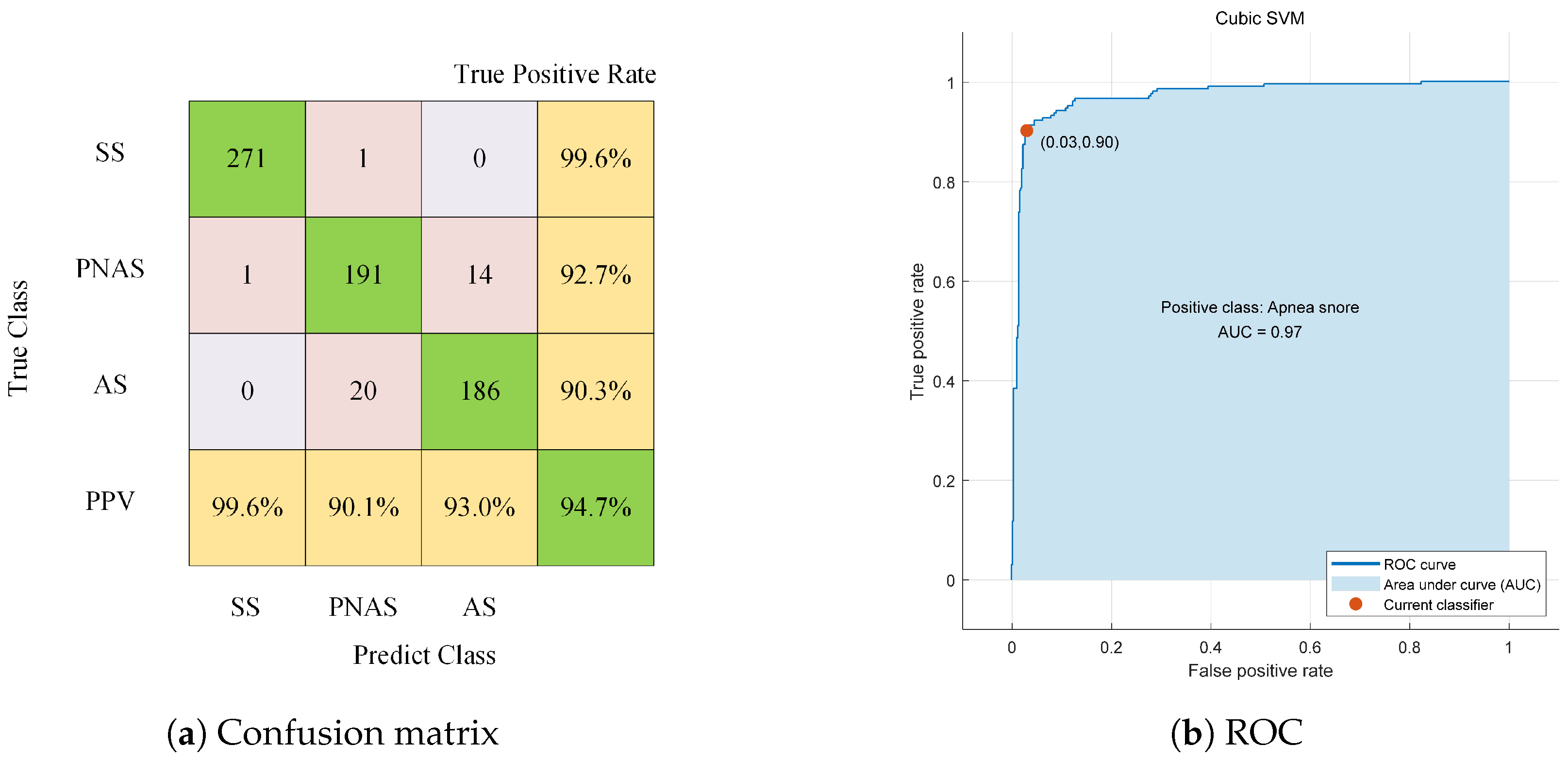
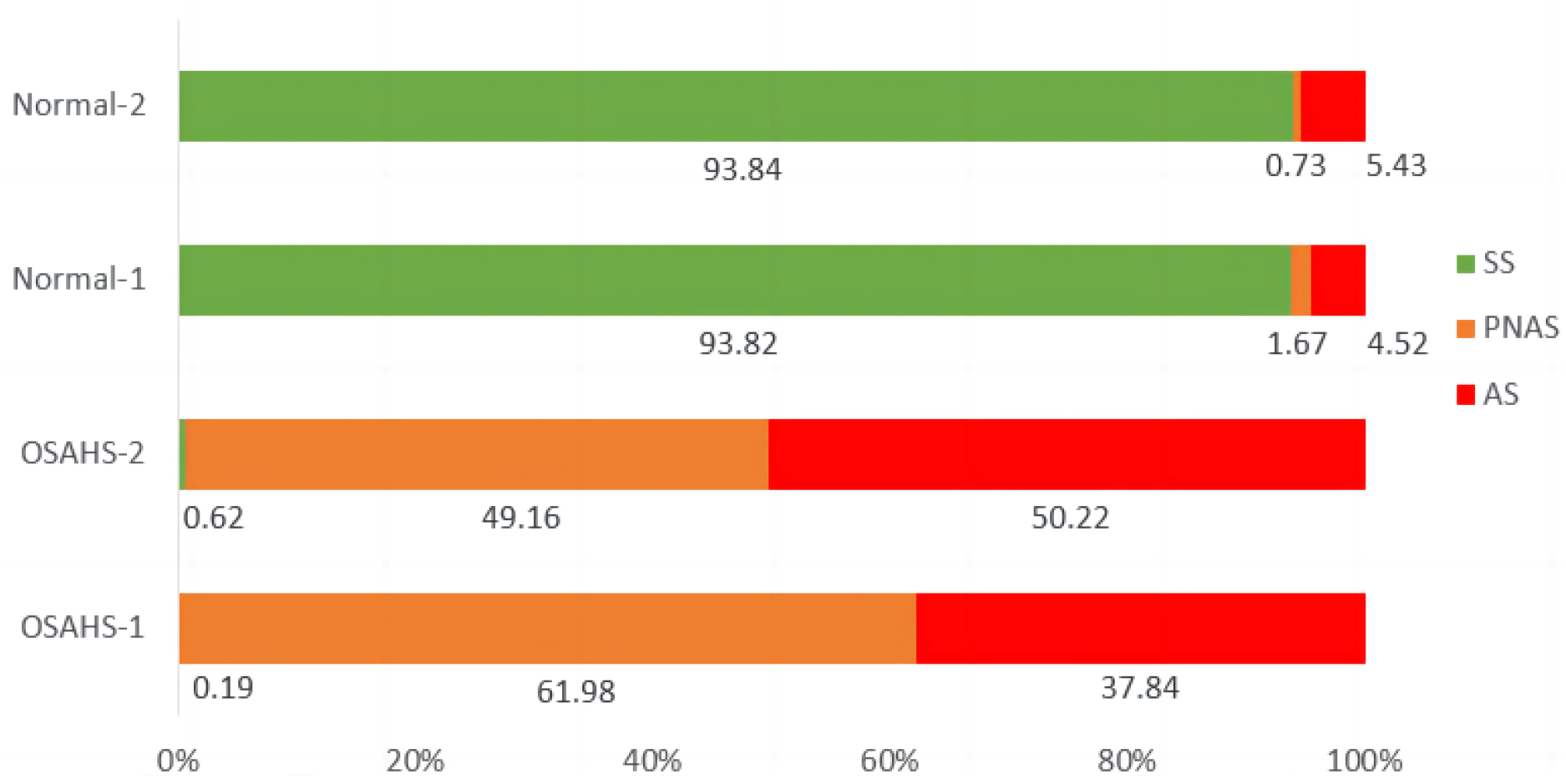
6. Experimental Results and Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Koffel, E.; Kroenke, K.; Bair, M.J.; Leverty, D.; Polusny, M.A.; Krebs, E.E. The bidirectional relationship between sleep complaints and pain: Analysis of data from a randomized trial. Health Psychol. 2016, 35, 41–49. [Google Scholar] [CrossRef] [PubMed]
- Bradley, T.D.; Floras, J.S. Obstructive sleep apnoea and its cardiovascular consequences. Lancet 2009, 373, 82–93. [Google Scholar] [CrossRef] [PubMed]
- Engleman, H.M.; Douglas, N.J. Sleep. 4: Sleepiness, cognitive function, and quality of life in obstructive sleep apnoea/hypop-noea syndrome. Thorax 2004, 59, 618–622. [Google Scholar] [CrossRef] [PubMed]
- Fung, J.W.; Li, T.S.; Choy, D.K.; Yip, G.W.; Ko, F.W.; Sanderson, J.E.; Hui, D.S. Severe obstructive sleep apnea is associated with left ventricular diastolic dysfunction. Chest 2002, 121, 422–429. [Google Scholar] [CrossRef]
- Yang, H. The Research and Realization of OSAHS Detection System Based on AHI. Ph.D. Thesis, Dalian University of Technology, Dalian, China, 2015. [Google Scholar]
- Duan, X.Q.; Zheng, H.L. Obstructive sleep apnea hypopnea syndrome study on pathogenesis and prognosis. J. Clin. Otorhinolaryngol. Head Neck Surg. 2017, 31, 1376–1380. [Google Scholar]
- Pevernagie, D.; Aarts, R.M.; Meyer, M.D. The acoustics of snoring. Sleep Med. Rev. 2010, 14, 131–144. [Google Scholar] [CrossRef]
- Michael, H.; Andreas, S.; Thomas, B.; Beatrice, H.; Werner, H.; Holger, K. Analysed snoring sounds correlate to obstructive sleep disordered breathing. Eur. Arch. Oto-Rhino-Laryngol. 2008, 265, 105–113. [Google Scholar] [CrossRef]
- Perez-Padilla, J.R.; Slawinski, E.; Difrancesco, L.M.; Feige, R.R.; Remmers, J.E.; Whitelaw, W.A. Characteristics of the snoring noise in patients with and without occlusive sleep apnea. Am. Rev. Respir. Dis. 1993, 147, 635–644. [Google Scholar] [CrossRef]
- Herath, D.L.; Abeyratne, U.R.; Hukins, C. HMM-based Snorer Group Recognition for Sleep Apnea Diagnosis. In Proceedings of the 35th Annual International Conference of the IEEE EMBS, Osaka, Japan, 3–7 July 2013; pp. 3962–3964. [Google Scholar]
- Shen, K.; Li, W.; Yue, K. Support Vector Machine OSAHS Snoring Recognition by Fusing LPCC and MFCC. J. Hangzhou Dianzi Univ. Sci. 2020, 40, 1–6. [Google Scholar]
- Jiang, Y.; Peng, J.; Song, L. An OSAHS evaluation method based on multi-features acoustic analysis of snoring sounds. Sleep Med. 2021, 84, 317–323. [Google Scholar] [CrossRef]
- Luo, Y.; Jiang, Z. A simple method for monitoring sleeping conditions by all-night breath sound measurement. J. Interdiscip. Math. 2017, 20, 307–317. [Google Scholar] [CrossRef]
- Fang, Y.; Jiang, Z.W.; Wang, H.B. A novel sleep respiratory rate detection method for obstructive sleep apnea based on characteristic moment waveform. J. Healthc. Eng. 2018, 2018, 1–10. [Google Scholar] [CrossRef]
- Sun, J.; Hu, X.; Peng, S.; Ma, Y. A Review on Snore Detection. World J. Sleep Med. 2020, 7, 552–554. [Google Scholar]
- Zhao, S.; Fang, Y.; Wang, W.; Liu, D. Analysis of Sleeping Respiratory Signal Utilizing Frequency Energy Features. In Proceedings of the 2022 5th International Conference on Information Communication and Signal Processing, Shenzhen, China, 26–28 November 2022; pp. 86–90. [Google Scholar]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 25th International Workshop on Machine Learning Signal Process, Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Cui, X.; Su, Z. A new feature extraction method of respiration signal and its application. Chin. J. Med. Phys. 2018, 35, 214–218. [Google Scholar]
- Wang, C.; Peng, J.; Song, L.; Zhang, X. Automatic snoring sounds detection from sleep sounds via multi-features analysis. Australas Phys. Eng. Sci. Med. 2017, 40, 127–135. [Google Scholar] [CrossRef] [PubMed]
- Zeng, J.; Teng, Z. Spectral Centroid Applications on Power Harmonic Analysis. In Proceedings of the CSEE, New Delhi, India, 23–24 February 2013; Volume 33, pp. 73–80. [Google Scholar]
- Kim, H.G.; Moreau, N.; Sikora, T. MPEG-7 Audio and Beyond: Audio Content Indexing and Retrieval; Wiley: West Sussex, UK, 2005. [Google Scholar]
- Peeters, G. A large set of audio features for sound description (similarity and classification). Cuid. Proj. Ircam Tech. Rep. 2004, 54, 1–25. [Google Scholar]
- Mokhsin, M.B.; Rosli, N.B.; Adnan, W.A.W.; Manaf, N.A. Automatic music emotion classification using artificial neural network based on vocal and instrumental sound timbres. J. Comput. Sci. 2014, 10, 2584–2592. [Google Scholar] [CrossRef]
- Shelar, V.S.; Bhalke, D.G. Musical instrument recognition and transcription using neural network. In Proceedings of the Emerging Trends in Electronics and Telecommunication Engineering, Karimnagar, Telangana, India, 13–14 December 2014; pp. 31–36. [Google Scholar]
- Misra, H.; Bourlard, H. Spectral entropy feature in full-combination multistream for robust ASR. In Proceedings of the ISCA European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; pp. 2633–2636. [Google Scholar]
- Toh, A.M.; Togneri, R.; Nordholm, S. Spectral entropy as speech features for speech recognition. In Proceedings of PEECS. 2005, pp. 22–25. Available online: https://www.researchgate.net/publication/247612912_Spectral_entropy_as_speech_features_for_speech_recognition (accessed on 28 September 2023).
- Luo, Y.; Wu, C.; Zhang, Y.; Li, X. A further speech signal features extraction algorithm based on LPC Mel frequency scale. J. Chongqing Univ. Posts Telecommun. Sci. Ed. 2016, 28, 175–179. [Google Scholar]
- Cao, D.; Gao, X.; Gao, L. An Improved Endpoint Detection Algorithm Based on MFCC Cosine Value; Springer Science+Business Media: New York, NY, USA, 2017; pp. 3–4. [Google Scholar]
- Kononenko, I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach. Learn. J. 2008, 53, 23–69. [Google Scholar]
- Correa, N.; Li, Y.; Adali, T.; Calhoun, V.D. Canonical correlation analysis for feature-based fusion of biomedical imaging modalities and its application to detection of associative networks in schizophrenia. IEEE J. Sel. Top. Signal Process 2008, 2, 998–1007. [Google Scholar] [CrossRef]
- Xue, B.; Deng, B.; Hong, H.; Wang, Z.; Zhu, X.; Feng, D.D. Non-Contact Sleep Stage Detection Using Canonical Correlation Analysis of Respiratory Sound. IEEE J. Biomed. Health Inform. 2020, 24, 618–620. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Type | Reference Classifier Accuracy | Sensitivity | Specificity | AUC |
|---|---|---|---|---|
| Wavelet Frequency Division (16D) | 77.5% | 77.5% | 77.5% | 0.81 |
| Mel Frequency Division (16D) | 71.3% | 68.8% | 73.8% | 0.73 |
| ERB Frequency Division (16D) | 72.5% | 78.8% | 62.5% | 0.77 |
| SD Frequency Division (16D) | 80.0% | 78.8% | 81.3% | 0.87 |
| Dimension | Classifier | Three-Way Classification | SS/OPS | PNAS/AS | ||
|---|---|---|---|---|---|---|
| Acc (%) | Sen (%) | Spe (%) | Sen (%) | Spe (%) | ||
| 6 | Cubic SVM | 85.8 | 96.0 | 97.8 | 78.1 | 83.7 |
| Subspace KNN | 85.8 | 97.8 | 92.2 | 83.8 | 85.1 | |
| 26 | Cubic SVM | 95.6 | 99.6 | 99.5 | 93.2 | 93.6 |
| Subspace KNN | 97.8 | 100.0 | 99.3 | 98.1 | 96.1 | |
| 30 | Cubic SVM | 94.7 | 99.6 | 99.5 | 91.7 | 92.2 |
| Subspace KNN | 96.1 | 99.6 | 99.0 | 94.1 | 95.1 | |
| 37 | Cubic SVM | 93.7 | 98.2 | 98.8 | 91.2 | 92.6 |
| Subspace KNN | 63.7 | 79.4 | 80.0 | 70.2 | 64.9 | |
| 51 | Cubic SVM | 93.9 | 99.6 | 99.5 | 91.2 | 89.8 |
| Subspace KNN | 58.6 | 72.4 | 75.2 | 66.9 | 64.7 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Y.; Liu, D.; Zhao, S.; Deng, D. Improving OSAHS Prevention Based on Multidimensional Feature Analysis of Snoring. Electronics 2023, 12, 4148. https://doi.org/10.3390/electronics12194148
Fang Y, Liu D, Zhao S, Deng D. Improving OSAHS Prevention Based on Multidimensional Feature Analysis of Snoring. Electronics. 2023; 12(19):4148. https://doi.org/10.3390/electronics12194148
Chicago/Turabian StyleFang, Yu, Dongbo Liu, Sixian Zhao, and Daishen Deng. 2023. "Improving OSAHS Prevention Based on Multidimensional Feature Analysis of Snoring" Electronics 12, no. 19: 4148. https://doi.org/10.3390/electronics12194148
APA StyleFang, Y., Liu, D., Zhao, S., & Deng, D. (2023). Improving OSAHS Prevention Based on Multidimensional Feature Analysis of Snoring. Electronics, 12(19), 4148. https://doi.org/10.3390/electronics12194148