1. Introduction
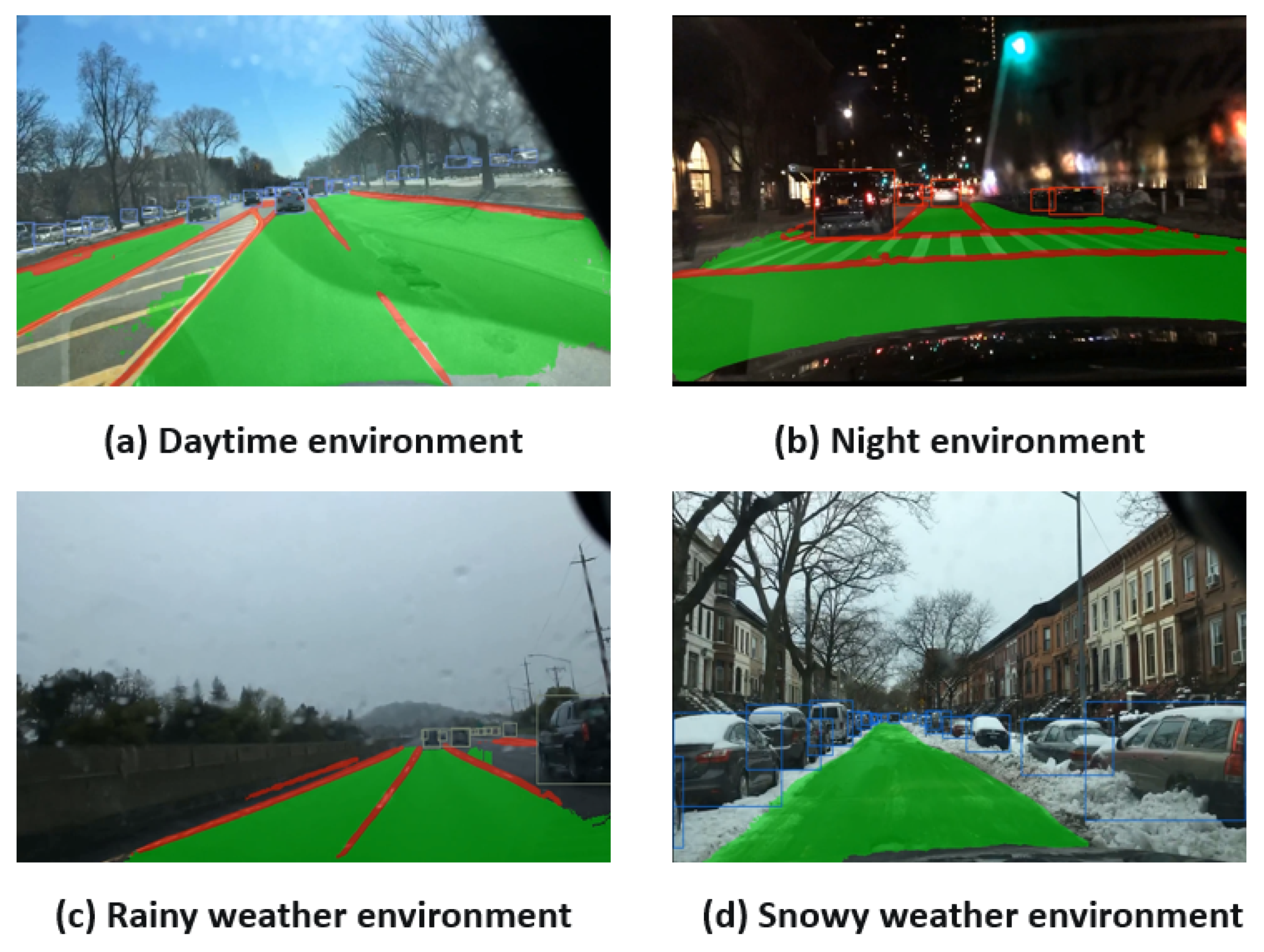
The fields of computer vision and deep learning have witnessed significant advancements in recent years, and camera-based techniques, such as object detection and semantic segmentation, are widely used in the field of autonomous driving due to their low cost. Environment perception under structured road (as shown in
Figure 1) is a key link in autonomous driving technology. The environment perception system extracts visual features from the images captured by the camera, understands the scene information, detects the position of obstacles and lanes, determines whether the road is drivable, and helps the decision-making system control the movement of the vehicle, which is crucial for planning the vehicle’s driving route. The environmental perception system makes accurate and timely decisions in the process of autonomous driving, which is the key to ensuring driving safety. Therefore, ensuring the accuracy and real-time performance of the system are the two most critical and challenging requirements.
Object detection and semantic segmentation are two topics that have been widely studied in the field of computer vision. For object detection, a series of accurate and efficient methods have been proposed, such as CenterNet [
1], RetinaNet [
2], DETR [
3], R-CNN series [
4,
5,
6], SSD [
7], YOLO series [
8,
9,
10], DINO [
11], and EVA [
12], which have achieved good detection results on public datasets. Classic semantic segmentation networks, such as UNet [
13], ENet [
14], SegNet [
15], PSPNet [
16], ERFNet [
17], PSANet [
18], EncNet [
19], CFNet [
20], and EANet [
21] are usually used to perform the segmentation task of road drivable areas. For lane line detection tasks, it is necessary to obtain more refined semantic features, combine high-level features and low-level features, and use context information to detect channels. Networks such as SCNN [
22], ENet-SAD [
23], LaneNet [
24], LaneATT [
25], and LaneAF [
26] are designed to specifically perform this task.
In order to be able to run multiple detection and segmentation tasks at the same time, considering that the information of many tasks in the traffic scene is interrelated, a multi-task learning network model [
27,
28,
29,
30,
31] was proposed, which adopted an encoder–decoder structure. Feature extraction and feature fusion are performed in the encoder structure, in which the information of multiple tasks can be shared with each other. The decoder structure can run multiple detection tasks at the same time, and the detection results are output without mutual interference between multiple tasks. Although these methods have achieved excellent performance, there are still many problems in these traditional multi-task network models in the process of environment perception of autonomous driving. First, for traffic objects with small size, the detection accuracy of the object detection part of the model is low and is prone to missed detection and false detection. Second, the segmentation accuracy of drivable area and lane line is low when the image is blurred by extreme weather, such as rain, snow, and fog, or the road is occluded. Third, the segmentation of lane lines is prone to discontinuity in the case of large changes in lane slope and sharp lane turns. Fourth, the structure of the existing multi-task network model is complex, the number of parameters and calculation of the model are generally large, and the performance is poor on embedded devices with limited computing resources, which does not meet the real-time requirements in the process of autonomous driving.
To this end, we propose a lightweight and efficient multi-task network model, MultiNet-GS, to solve the multi-task problem in autonomous driving environment perception, that is, traffic object detection, drivable area detection, and lane line detection in structured road scenes, and improve the shortcomings of traditional multi-task network models. Our contributions are as follows:
We introduce a new dynamic sparse attention mechanism, BiFormer [
32], in the feature extraction part of the model to achieve more flexible computing resource allocation, which can significantly improve the computational efficiency and occupy a small computational overhead. The introduction of the attention mechanism makes the model pay more attention to the region of interest and improves the accuracy of object detection, drivable area segmentation, and lane line segmentation.
We introduce a lightweight convolution, GSConv [
33], in the feature fusion part of the network, which is used to build the neck part into a new slim-neck structure, so as to reduce the computational complexity and inference time of the detector. The introduction of slim-neck structure greatly reduces the number of parameters and calculation of the model so that the model can adapt to embedded devices with limited computing power and meet the real-time requirements in autonomous driving.
We add an additional detector for tiny objects to the conventional three-head detector structure. This four-head detector structure can effectively alleviate the negative impact of drastic changes in the size of traffic objects and greatly improve the detection performance of tiny objects.
In the lane detection part, we introduce a lane detection method based on guide lines, which can aggregate the lane feature information into multiple key points and then obtain the lane heat map response through conditional convolution. Finally, the lane line is described by the adaptive decoder, which effectively makes up for the shortcomings of the traditional lane detection method so that the model can accurately and continuously segment the lane line in the case of drastic changes in lane slope and sharp lane turns.
The rest of this paper is organized as follows: In
Section 2, we introduce the current popular single-task network models and multi-task network models, as well as the current popular attention mechanism modules, and introduce their advantages and disadvantages in detail to lead to our work. In
Section 3, we elaborate the structure of our proposed model and the adopted method. In
Section 4, we design detailed ablation experiments and contrast experiments for our proposed improvements to observe the effect of our proposed improvements. Finally, we show the superiority of our proposed network model over the current mainstream network models and the content of future work.
2. Related Work
In this section, we will introduce the current popular research methods and their shortcomings as well as the current popular multi-task learning models in detail for the three tasks in the structured road environment perception task based on deep learning.
2.1. Traffic Object Detection
A variety of object detectors with excellent performance have been proposed in the field of deep learning, which can be roughly divided into two types: one-stage methods and two-stage methods.
The two-stage method represented by R-CNN series [
4,
5,
6] first generates the region (a pre-selected box that may contain the object to be detected), and then classifies the samples by convolutional neural network. This method has high detection accuracy, but it will have a large time overhead and cannot meet the real-time requirements in the process of automatic driving. The one-stage method represented by YOLO series [
8,
9,
10] will directly extract network features for the purpose of predicting object classification and location, effectively balancing detection accuracy and detection time. YOLOv3 [
8] introduces the residual model Darknet-53 for the first time and adopts the FPN architecture to realize multi-scale detection. Based on the original YOLO object detection architecture, YOLOv4 [
9] adopts many optimization strategies to further improve the network performance. YOLOv5 introduces functions such as adaptive anchor and adaptive image scaling to make the training of the network more efficient. YOLOv7 [
10] incorporates several trainable bags-of-freebies to significantly enhance detection accuracy of the real-time detector without increasing inference cost, among other improvements.
These traditional object detection methods perform well on public datasets because objects on public datasets, such as COCO and VOC, are generally more evenly distributed and have more obvious features. However, these methods have many shortcomings in the detection of traffic targets in traffic scenes. Firstly, the traffic images captured by the camera are limited by the shooting angle and shooting distance, and some traffic targets in them are small in scale, which is prone to missed detection or false detection. Secondly, the background of some road scenes is complex, and it is difficult to accurately detect the traffic targets we need. Finally, limited by the influence of light intensity, such as night or heavy rain, snow, fog, and other extreme weather, the traffic images captured by the camera are blurred and have low resolution and are also prone to missed detection or false detection.
2.2. Drivable Area Detection
Drivable area detection is often used as a regional constraint for lane detection. Currently, road detection is commonly considered a subset of road scene comprehension and remains one of the most formidable challenges for intelligent autonomous driving systems in related fields. Object detection in the environment perception system of autonomous driving provides the accurate location of various objects, such as pedestrians, vehicles, and obstacles in the road scene, which is of great significance for autonomous driving vehicles to find the driving area.
Many CNN-based methods have demonstrated impressive performance in the field of semantic segmentation and are widely used in drivable region detection, providing pixel-wise results. ENet [
14] proposes a novel deep neural network architecture specifically for low-latency manipulation tasks, effectively balancing the accuracy and processing time of the network. PSPNet [
16] provides an effective solution for pixel-level prediction, which effectively aggregates global context information and achieves good results on scene parsing tasks. ERFNet [
17] proposes an end-to-end trainable deep neural network, incorporating residual connections and decomposed convolutions, thereby significantly enhancing computational efficiency compared to alternative architectures.
However, with the increase of network depth, the problem brought by the network structure model also becomes larger and more complex. In the semantic segmentation of road environments, since the application scenario is the vehicle computing platform, in addition to the segmentation accuracy, people pay more attention to whether the network processing speed can achieve real-time performance. Conventional semantic segmentation networks typically entail a substantial computational burden, rendering them unsuitable for meeting the real-time demands of autonomous driving systems.
2.3. Lane Detection
Lane detection plays a crucial role in advanced automated driver assistance systems. Traditional feature-based lane detection methods need to manually find specific lane features, such as geometry, color, gradient, and so on. This method is less robust, susceptible to noise interference, and has low detection efficiency.
The lane detection method based on deep learning leverages the robust feature extraction capability of convolutional neural networks to further extract lane-specific features. The current mainstream lane detection methods utilize semantic segmentation of images to comprehend the road environment semantically by isolating the lane as foreground and other areas and addressing the problem of lane detection from a semantic segmentation perspective. LaneNet [
24] proposes an end-to-end fast lane detection algorithm using a novel view transformation method to correctly fit the lane even when the road plane changes greatly. SCNN [
22] proposes a space-based convolutional neural network architecture capable of passing messages between pixels across rows and columns in layers, which is well suited for continuous shape object detection with strong spatial relationships. ENet-SAD [
23] proposes a novel self-attention distillation method called SAD based on ENet [
14], which autonomously learns and improves the model to cope with complex road situations without any additional supervision.
However, despite the fact that lane detection is commonly approached as semantic segmentation, it does not solely entail pixel-level classification. In the actual road environment, the lane often has incomplete marking lines, vehicle occlusion, and rain and snow cover, which makes the lane unvisible. In addition, the drastic change of road slope and angle in 2D images will also make it impossible to fit the lane correctly.
2.4. Multi-Task Learning Model
Now, the multi-task learning method based on CNN has been widely used. Multi-task learning can greatly improve the training efficiency by sharing information between multiple tasks, and multiple tasks can promote each other’s performance. MultiNet [
27] proposes an end-to-end training method for classification, detection, and segmentation through a unified architecture, which has achieved good results in road detection tasks. DLT-Net [
28] proposes an encoder–decoder-based network architecture that builds context tensors between decoders to share information between multiple tasks, and multiple tasks are able to promote each other’s performance during learning. YOLOP [
29] introduces the residual network structure of YOLOv4 [
9] into the network backbone for the first time, which can run multiple tasks accurately and quickly and achieves good results on embedded devices. HybridNets [
30] introduces the BiFPN [
34] structure into the feature fusion part of the network and proposes a more effective training strategy and loss function to achieve better accuracy while maintaining real-time performance.
These current popular multi-task learning networks are widely used in traffic scene detection tasks, which provide us with a good reference.
2.5. Attention Mechanism
The attention mechanism has emerged as a prominent research area in the realm of deep learning, garnering significant interest and attention from scholars worldwide. Compared with the convolution module as a local operator, the attention module can expand the global receptive field, making the model pay more attention to important weights during training. However, adding an attention mechanism has a certain cost, which has high computational complexity and takes up large memory.
In recent years, many attention mechanism modules have been proposed to improve the detection performance of existing CNN models. SENet [
35] proposes a novel architecture that focuses on channel information and adaptively calibrates channel feature responses, yielding significant improvements in model performance at a small additional computational cost. CA [
36] incorporates location information into channel attention, enabling the retention of precise spatial details and demonstrating exceptional performance across contemporary mainstream models. CBAM [
37] takes into account both channel and spatial dimensions and adaptively refines the input feature map from two directions. It can be integrated into most CNN architectures and has a wide range of applicability. NAM [
38] proposes a new attention mechanism based on normalization, which applies a weight sparsity penalty to suppress less important feature information and shows high computational efficiency. GAM [
39] proposes a global attention mechanism with multi-layer perceptrons to improve the performance of deep neural networks by amplifying the global interaction representation, which achieves promising results on several public datasets.
These traditional attention mechanism modules adopt many methods to reduce computational overhead, such as restricting attention operations to local Windows or introducing unknown sparsity. These operations are often inflexible and have limited effect.
3. Methodology
We propose an efficient and lightweight multi-task network capable of simultaneously performing traffic object detection, drivable area detection, and lane detection tasks. It consists of an encoder and three decoders; three tasks perform feature extraction and feature fusion operations in a common encoder and perform information sharing, and finally, three different decoders solve the specific task. We name this network MultiNet-GS, and it can be trained end to end, incurs minimal computational overhead while maintaining high performance, and satisfies the real-time requirements for autonomous driving.
3.1. Encoder
3.1.1. Backbone
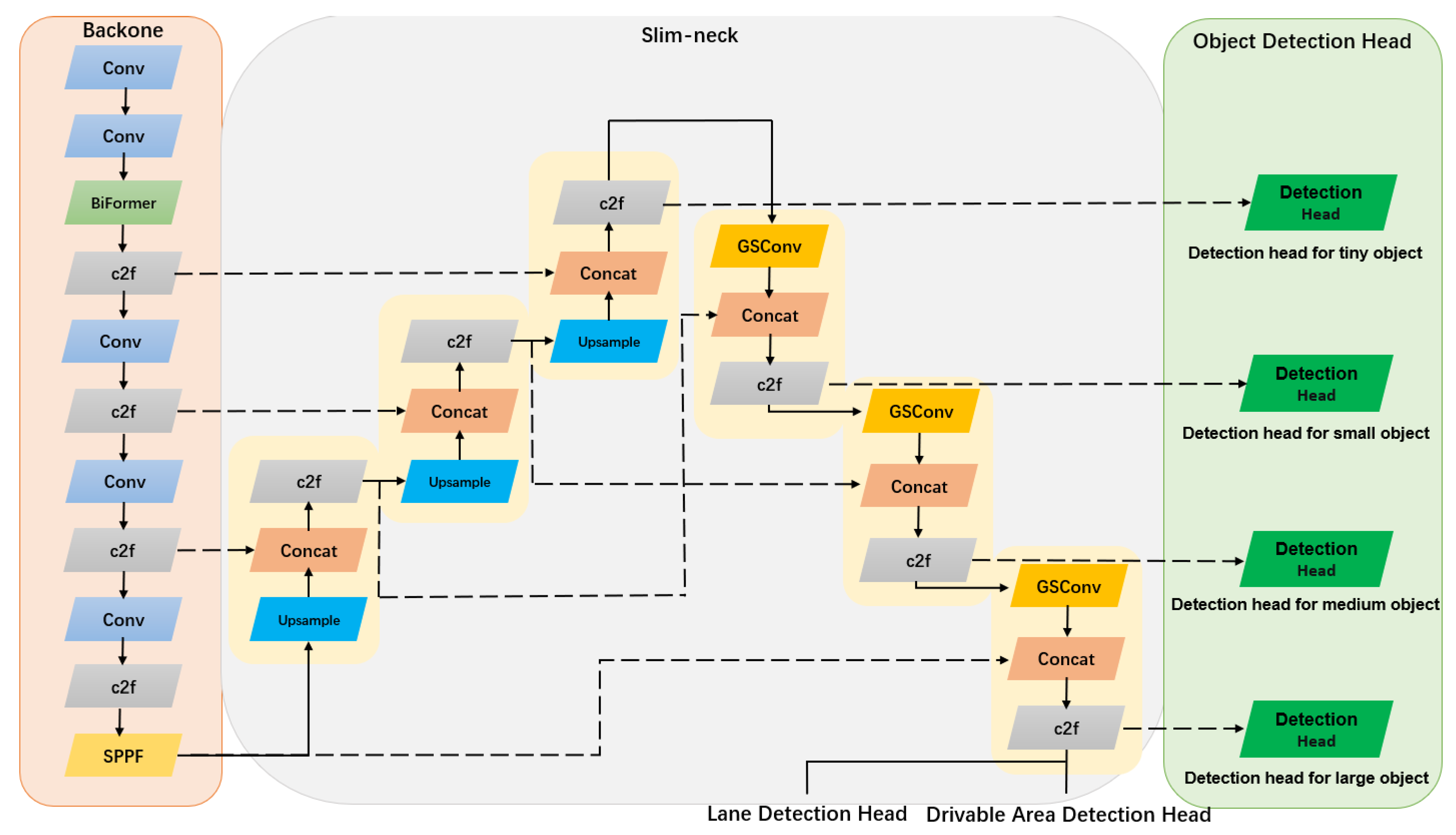
In view of the good performance of YOLOv8 network in the field of object detection, we choose CSPDarknet [
9] as our backbone structure and introduce the C2f module in YOLOv8 network to form our feature extraction part. The overall structure of the model is shown in
Figure 2. To enhance the feature extraction capability of the backbone and make the network pay more attention to important weights during feature extraction, we introduce a new dynamic sparse attention mechanism in the backbone, BiFormer, to achieve more flexible computing resource allocation. It demonstrates query-adaptive behavior by selectively focusing on relevant feature information while effectively filtering out irrelevant features. It exhibits exceptional performance and computational efficiency in dense prediction tasks.
3.1.2. Neck
We adopt the feature pyramid network FPN [
40] + PAN structure in the neck part for fusing the features generated in the backbone part. FPN is a feature pyramid from top to bottom, which passes down the strong semantic features from high levels and enhances the whole pyramid. PAN is introduced as a supplementary component to FPN, incorporating a bottom-up pyramid structure for enhanced feature transmission and integration of low-level localization information. The pyramid formed in this way combines both semantic information and localization information. To fulfill the real-time requirements, we propose the integration of a lightweight convolution, GSConv, in the neck component to establish a novel slim-neck architecture that effectively balances model accuracy and speed.
In the conventional CNN network architecture, each spatial compression and channel expansion during the process of feature extraction and fusion result in the loss of inter-channel connections, leading to a degradation in semantic information. As the number of layers of the model goes deeper, the inference time will also grow significantly. GSConv can preserve these connections as much as possible while occupying a small computational overhead. We preserve the original backbone structure of the network and incorporate the GSConv module in the neck part to construct a slim-neck architecture without compromising the model’s feature extraction capability, thereby reducing computational complexity and inference time for object detection.
3.2. Decoders
3.2.1. Traffic Object Detection Head
In the traffic scene, the size of the traffic object in the image sometimes changes dramatically, and the size of some traffic objects is tiny, so the detector will miss and misdetect. In view of this situation, we add an extra detector for the tiny object on the traditional three-head detector structure. The four-head detector structure effectively mitigates the adverse effects caused by significant variations in traffic object size, thereby enhancing the detection performance of tiny objects with minimal computational overhead.
3.2.2. Drivable Area and Lane Detection Head
We put the semantic segmentation head at the end of the neck layer so that it can make full use of the fused feature information. Our slim-neck structure is able to effectively reduce the computational overhead that increases with the number of network layers. We utilize two different heads to perform the drivable area segmentation and lane segmentation tasks, respectively. The curve fitting method and semantic segmentation method are usually used in traditional lane detection. The curve fitting method uses mathematical methods to model the lane lines and fits the lane lines to a mathematical curve. This method is not ideal in some traffic scenes where the lane lines are occluded. Semantic segmentation methods regard lane detection as a traditional semantic segmentation problem. Because lane pixels and adjacent pixels usually have similar features, it is difficult to segment lane lines, and the effect is not ideal.
We introduce a new detection method in lane detection to distinguish it from the semantic segmentation method in drivable area detection. In the instance extraction branch, we use guide lines to identify lane keypoints, obtain instance features through RIM (recurrent instance module), and then calculate Gaussian masks and offset heatmaps through conditional convolution. Finally, we infer lane coordinates with an adaptive decoder.
3.3. Method Details
3.3.1. Biformer Attention Mechanism
In order to alleviate the scalability problem in the attention mechanism, the sparse attention mechanism is widely adopted in the attention mechanism module. The sparse attention mechanism is proposed to address the scalability problem in the attention mechanism by focusing only on a limited number of key-value pairs instead of all of them in the query. However, existing approaches either utilize hand-crafted static schemas or share a sampled subset of key-value pairs across all queries. In contrast, Biformer proposed a dynamic and query-aware sparse attention mechanism that includes an additional step for identifying regions to focus on, constructing and pruning region-level graphs and gathering key-value pairs from the routed regions.
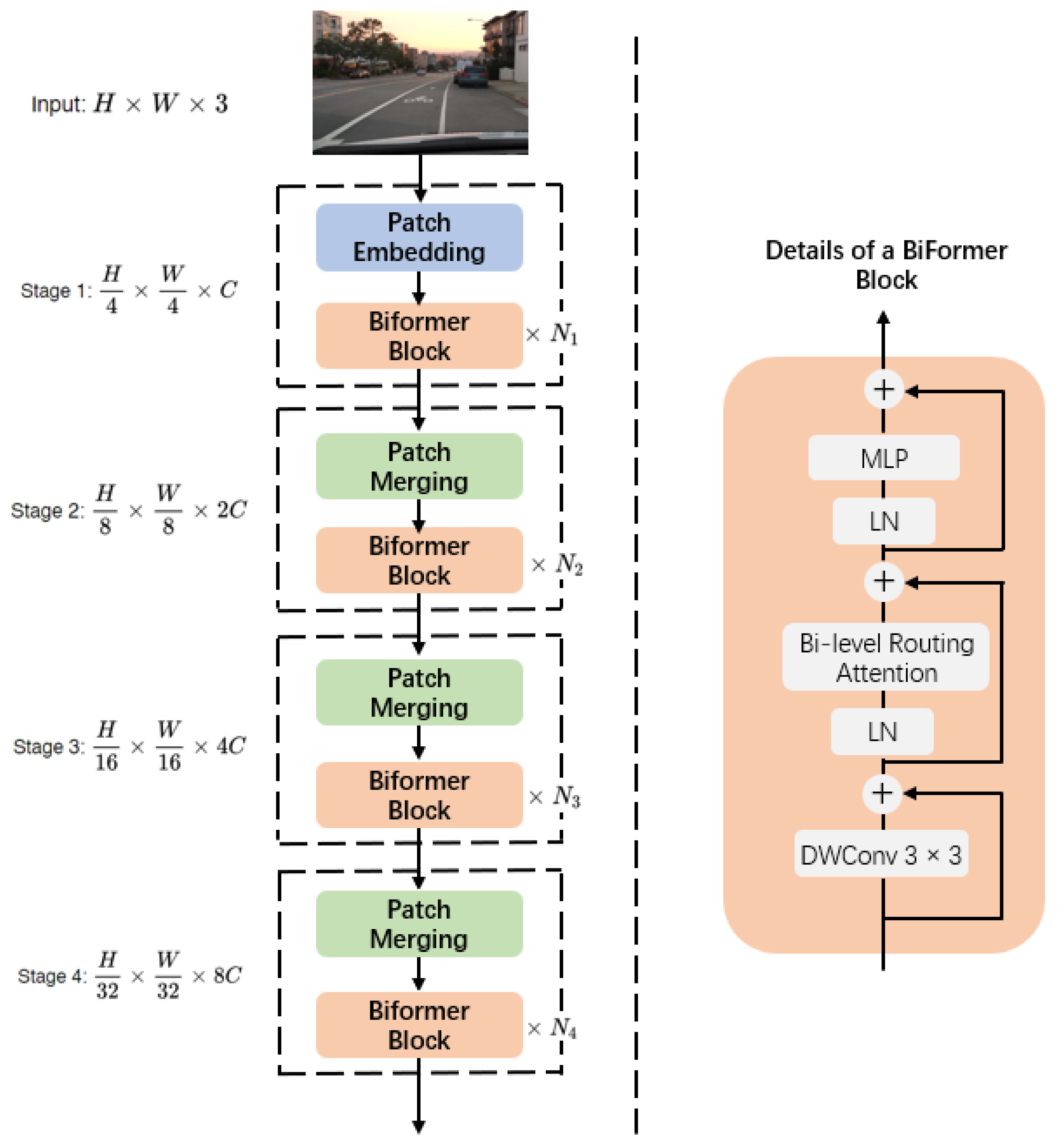
As shown in
Figure 3, the BiFomer module leverages the four-layer pyramid structure of Vision Transformer, incorporating the patch embedding module in the initial stage and integrating the patch merging module in subsequent stages two to four. With this bi-level routing attention (BRA) mechanism, it exploits sparsity to save computation and memory while only involving GPU-friendly dense matrix multiplication. The fundamental concept of BRA is to selectively extract the most pertinent key-value pairs at a macroscopic regional level. This objective is accomplished by initially constructing and refining a directed graph at the regional level, followed by employing meticulous token-to-token attention within the amalgamation of routed regions.
The BiFormer model adopts a query adaptive approach to focus on a limited set of relevant tokens, effectively disregarding irrelevant ones. This design choice not only ensures superior performance but also enhances computational efficiency, particularly in dense prediction tasks. Notably, BiFormer has demonstrated remarkable efficacy across various domains such as image classification, object detection, and semantic segmentation.
3.3.2. Gsconv Module
The requirements of real-time object detection pose a challenge for achieving a large-scale model on vehicular edge computing platforms. Conversely, lightweight models constructed with numerous depthwise separable convolutional layers often fall short in terms of accuracy. In order to address this issue, we propose the integration of GSConv, a lightweight convolution technique, into the neck part to establish a novel slim-neck structure that strikes an optimal balance between model accuracy and speed.
The input image in the CNN backbone typically undergoes a similar transformation process to enhance the computation speed of the final prediction, wherein spatial information is gradually transferred to the channel. However, each compression of spatial dimensions and expansion of channels in the feature map leads to a partial loss of semantic information. While channel-dense convolution maximally preserves hidden connections between each channel, channel-sparse convolution completely severs these connections. GSConv aims to preserve these connections as much as possible with low time complexity. The structure of the GSConv module is shown in
Figure 4.
The introduction of slim-neck structure improves the computational efficiency of the model in the feature fusion part; avoids the loss of semantic information in the feature fusion stage; significantly improves the detection accuracy of the three detection head parts of object detection, drivable area detection, and lane detection; and greatly reduces the computational overhead of the model.
3.3.3. Lane Detection Method Based on Guide Line
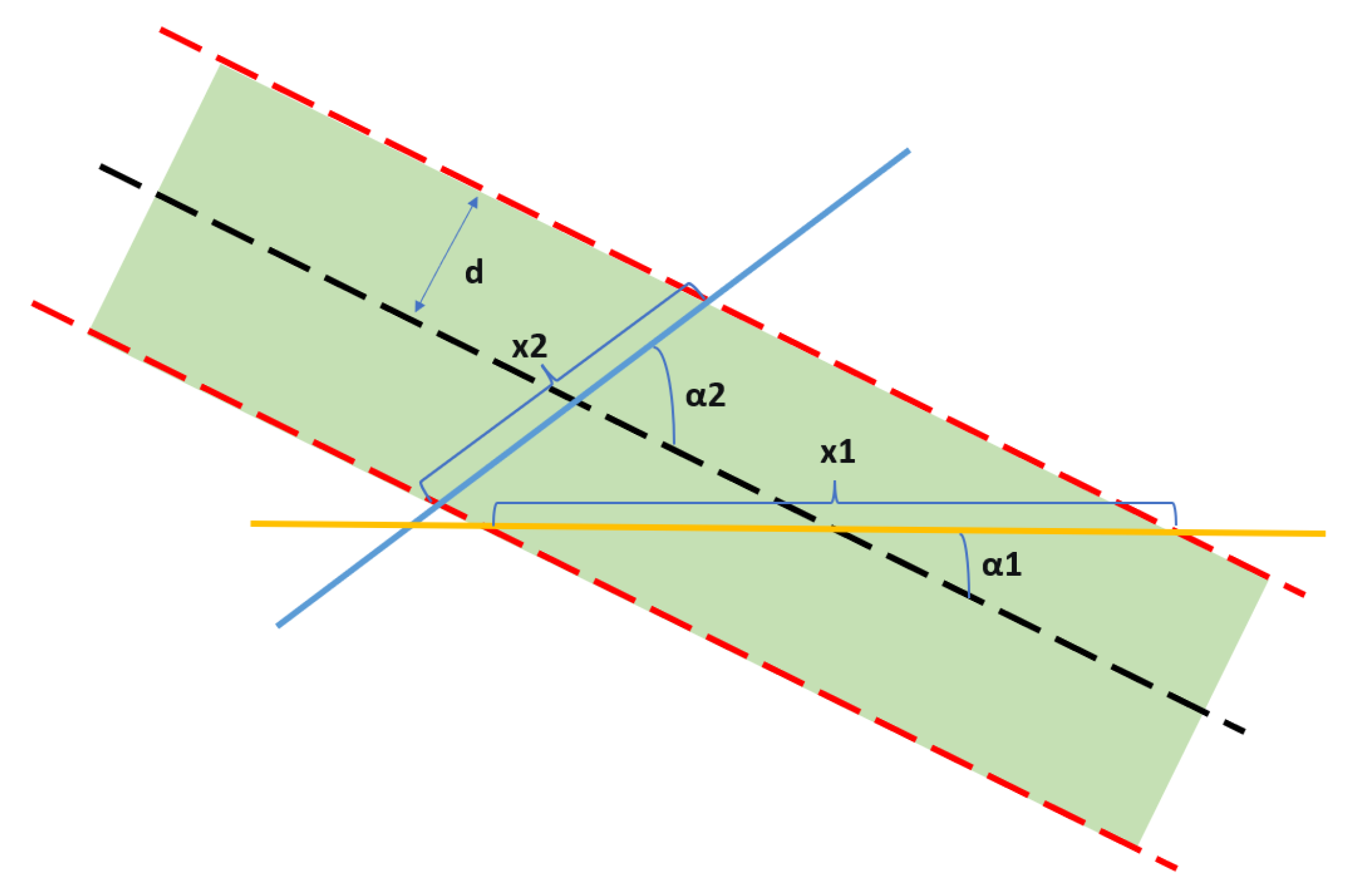
Guide lines are often used to mark the origin of lane lines, as shown in
Figure 5. The black dashed line represents the detected vectorized lane line, and the red dashed line represents the pixel range over which the response was generated on the heatmap.
d is the radius of the range, and the grazing angles of the two guide lines are
and
, respectively. As shown in Equation (
1), the smaller the grazing angle of the guide line is, the larger the response range is and, conversely, the smaller the response range is. The addition of guidance lines allows the model to focus on the dramatic changes in lane lines around corners.
According to the guiding line principle, we introduce a U-shaped curve with the lower half being a partial ellipse and the upper half being the image side boundary, and the ellipse is defined in Equation (
2), where
w and
h are the width and height of the feature map, respectively, and
and
are the hyperparameters that adjust the center of the ellipse. Due to the bending characteristics at the curve, the U-shaped guide line will lead to the increase of the sweep angle of the curve so that the model can be more sensitive to the sharp change of lane lines at the corner of the road. This special curved guide line usually performs better than the normal guide line when locating the lane line.
We use the normalized Gaussian kernel of the offset to extract the keypoints in the lane line instance as shown in Equation (
3). Where
x and
y represent the exact coordinates of each keypoint. Finally, by using Gaussian mask and adaptive decoder mechanism to decode the key point set in the supervision stage, the final fitted lane line is less affected by the surrounding pixels, and the detection performance is greatly improved compared with the traditional semantic segmentation method.
The improved lane line detection head is shown in
Figure 6.
3.4. Loss Function
Since our model is composed of three decoders, we use different loss functions for different decoders. In the object detection part, we adopt the weighted sum of bounding box loss, classification loss, and object loss to form our object detection loss function
, as shown in Equation (
4).
Among them, adopts , which is used to evaluate the distance, overlap rate, and size similarity between the predicted box and the actual traffic object. Focal loss is applied to both and , where is used to penalize classification and is used to predict the confidence of an object.
Cross-entropy loss with Logits
is used in the drivable area detection partial loss function
, while
uses
and
in the lane line detection partial loss function, as shown in Equations (
5) and (
6). Both aim to reduce the error between the output pixels of the model and the actual image regions.
Our final loss function is a weighted sum of the three partial loss functions, as shown in Equation (
7).
,
,
,
,
,
are adjusted to balance the final loss function.
4. Experiments
4.1. Setting
4.1.1. Dataset Construction
We utilized the BDD100K dataset, extensively employed in the domain of autonomous driving, for training and evaluating our network. The dataset comprises three components, with 70,000 images allocated as the training set, 20,000 images designated as the test set, and 10,000 images assigned to the validation set. There are a total of 100,000 images, covering traffic scenes under various environments, times of day, and weather, which is robust enough. In addition, we collected a large number of traffic surveillance videos of the ring highway in Xi’an, China, and produced a self-made dataset with rich scenes, about 30,000 images, including cars, trucks, motorcycles, pedestrians, roadblocks, signs, aba-performed objects, and other complex traffic targets. Compared with the BDD100K dataset with only cars as traffic targets, we collected a large number of traffic surveillance videos of the ring highway in Xi’an, China. Our dataset contains a large number of traffic targets with tiny size that are difficult to detect in order to verify the detection performance of our model for tiny objects. The dataset is shown in
Figure 7.
4.1.2. Implementation Details
We implement MultiNet-GS on Pytorch 1.8.1, CUDA 11.3. All of our models use an NVIDIA RTX3090 GPU for training and testing. In addition, in order to test the running effect of our model on embedded devices, we also adopt the NVIDIA Jetson TX2 (4 GB) embedded platform to comprehensively evaluate the detection accuracy and detection speed of our model. We jointly train the three tasks of the model to share the image features extracted in the encoder. We set the training epochs to 300, the initial learning rate to 0.01, and dynamically reset the learning rate in the first few epochs. We set an early stop mechanism during the training process so that the model stops training if the loss curve of the model cannot continue to converge. We also adopt mixup data augmentation technique in the process of dataset loading to expand the number of dataset samples and enhance the robustness of the model. We resize the images in the BDD100K dataset to 640 × 640 × 3 during the training phase.
4.1.3. Evaluation Index
In the object detection part of the model, mean average precision (
), precision (
P), recall (
R), are used to evaluate the performance of the algorithm. Where mean average precision (
), precision (
P), and recall (
R) are expressed as
where average precision (
) indicates the average precision of an object class, while true positives (
) represents the number of correctly detected objects. False positives (
) denotes the number of incorrectly detected objects, and false negatives (
) signifies the number of undetected objects
In the drivable area detection part and lane detection part of the model,
,
,
, are used to evaluate the performance of the algorithm. Where
,
, and
are expressed as
where
represents the part where the prediction is correct, that is, the part where the two regions coincide.
corresponds to the total number of pixels of class
i, and
represents the total number of all pixels predicted as class
i.
In addition, in order to evaluate the real-time performance of our proposed algorithm, we introduce two metrics, Params and FLOPs, to evaluate the number of parameters and the amount of computation of the algorithm model, respectively. We introduce FPS to evaluate the detection speed when the model is running.
4.2. Result
4.2.1. Comparison Experiments of Model with Improved Four-Head Structure
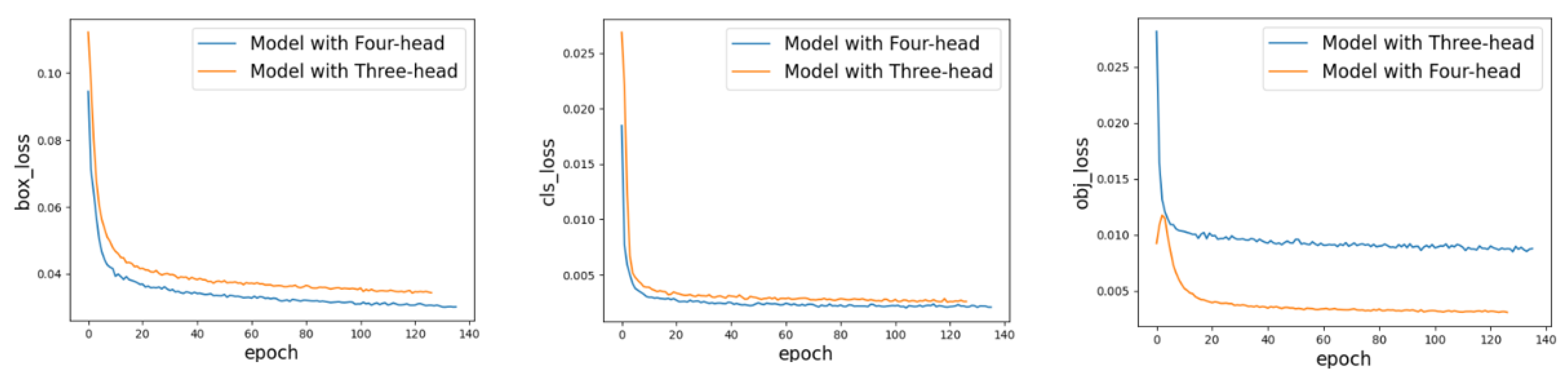
We add an additional object detection head to the object detection part of the baseline model to detect tiny size objects and verify our improved results on our self-made traffic scene dataset. The experimental results are shown in
Table 1, and the loss function curve of the model is shown in
Figure 8.
The experimental results show that the additional detection head we added has a significant improvement on the detection effect of the model. The detection effect of the model on tiny size objects, such as pedestrians, roadblocks, reflective clothing, boxes, and motorcycles, in the dataset is significantly improved, and the detection accuracy is increased by 5.4%, 5.6%, 3.2%, 2.6%, 2.0% respectively, which proves the effectiveness of our improvement.
4.2.2. Ablation Experiments after Introducing Different Improved Methods
In order to compare the influence of different improvements on model performance, we will call the model with BiFormer structure as Model-B, the model with GSConv structure as Model-G, the model with four-head structure as Model-F, and the model with improved lane detection structure as Model-L. We design ablation experiments from the following two directions: (1) Based on the baseline model, each improvement method was individually incorporated to assess its impact on the baseline model’s performance. (2) Based on the final model, each improvement method was systematically eliminated to evaluate its influence on the final model’s outcome.
As shown in
Table 2, experimental results show that in the object detection part of the model, the introduction of BiFormer has the largest improvement on the model detection effect, with the mAP@0.5 increased by 5.8%, but Params and FLOPs are increased by 1.8 M and 6.8 respectively, the detection speed of the model is reduced by 7 FPS. The introduction of GSConv has the largest improvement on the model detection speed, with an increase of 13 FPS, and Params and FLOPs are reduced by 4 M and 11.4, respectively. Compared with the baseline model, the final improved model has the mAP@0.5 increased by 8.1%, Params and FLOPs are increased by 3.4 M and 5.8, respectively, and the detection speed decreased by 2 FPS. The final improved model maintains a good detection speed while greatly improving the detection accuracy, which proves the effectiveness of our improvement in the object detection part.
As shown in
Table 3, experimental results show that in the drivable area detection part of the model, the introduction of BiFormer has the largest improvement on the model detection effect, with the accuracy increased by 5.8%, IOU increased by 2.4, and mIOU increased by 2.1, but Params and FLOPs are increased by 1.8 M and 6.8, respectively, and the detection speed of the model is reduced by 4 FPS. The introduction of GSConv has the largest improvement on the model detection speed, with an increase of 13 FPS, and Params and FLOPs are reduced by 4 M and 11.4, respectively. Compared with the baseline model, the final improved model has the accuracy increased by 6.4%, the IOU increased by 1.7, and the mIOU increased by 1.9, Params and FLOPs are reduced by 1.8 M and 6.7, respectively. The final improved model maintains a good detection speed while greatly improving the detection accuracy, which proves the effectiveness of our improvement in the object detection part.
As shown in
Table 4, experimental results show that in the line detection part of the model, the improvement of the lane detection part has the largest improvement on the model detection effect, with the accuracy increased by 5.7%, IOU increased by 4.5, and mIOU increased by 1.9, but Params and FLOPs are increased by 1.4M and 1.4, respectively, and the model detection speed reduced by 3 FPS. The introduction of GSConv has the largest improvement on the model detection speed, with an increase of 11 FPS, and Params and FLOPs are reduced by 4 M and 11.4, respectively. Compared with the baseline model, the final improved model has the accuracy increased by 11.3%, the IOU increased by 10.2, the mIOU increased by 14, Params and FLOPs are increased by 3.1M and 3.7, respectively, and the detection speed increased by 2 FPS. The final improved model maintains a good detection speed while greatly improving the detection accuracy, which proves the effectiveness of our improvement in the object detection part.
4.2.3. Comparison Experiment with the Current Mainstream Network Models
As shown in
Table 5, experimental results show that, in the object detection part of the model, our MultiNet-GS model has an increase of 2.3% compared with SOTA (YOLOPv2) on mAP@0.5, Params and FLOPs are reduced by 6.6 M and 8.3, respectively, and the detection speed is reduced by 3 FPS. It has the highest detection accuracy among the current mainstream object detection models, while maintaining a high detection speed.
As shown in
Table 6, experimental results show that in the drivable area detection part of the model, compared with SOTA (YOLOPv2), our MultiNet-GS model improves the accuracy by 1.5%, improves the IOU by 2.0, and improves the mIOU by 2.3; Params and FLOPs are reduced by 6.6 M and 8.3, respectively, and the detection speed is reduced by 3 FPS. It has the highest detection accuracy among the current mainstream object detection models, while maintaining a high detection speed.
As shown in
Table 7, experimental results show that in the line detection part of the model, compared with SOTA (YOLOPv2), our MultiNet-GS model improves the accuracy by 3.2%, improves the IOU by 4.0, and improves the mIOU by 2.3; Params and FLOPs are reduced by 6.6 M and 8.3, respectively, and the detection speed is reduced by 3 FPS. It has the highest detection accuracy among the current mainstream object detection models, while maintaining a high detection speed.
4.2.4. Comparison Experiment of the Improved Model on Embedded Platform
In order to test the running effect of our proposed model on the embedded platform, we deploy the model on the NVIDIA Jetson TX2 embedded AI platform and compare the experiment with the current mainstream multi-task network model, where mAP@0.5 represents the detection accuracy of the traffic object detection part of the model, accuracy1 represents the accuracy of the drivable area segmentation part of the model, and accuracy2 represents the accuracy of the lane line segmentation part of the model.
As shown in
Table 8, experimental results show that although the detection performance of our proposed model slightly decreases on the embedded platform, it still maintains good detection accuracy and detection speed as a whole. Compared with SOTA(YOLOPv2), the mAP@0.5 of the model in traffic object detection reaches 82.1%, which is increased by 2.7%. The accuracy of the model in drivable area detection reaches 93.2%, which is increased by 0.5%. The accuracy of the model in lane detection reaches 85.7%, which is increased by 4.3%. The Params and FLOPs of the model reach 47.5 M and 117.5 M, which are reduced by 6.6 M and 8.3, respectively. The model achieves 72 FPS, which is increased by 5. The detection effect of the model on the BDD100K dataset is shown in
Figure 9 and
Figure 10.
5. Conclusions
In order to solve the problem of environment perception under structured roads in the process of autonomous driving, a multi-task network model is proposed to simultaneously process three tasks: traffic object detection, drivable area detection, and lane detection. However, the current mainstream multi-task network model has some shortcomings in complex traffic scenarios. First, for traffic objects with small size, the detection accuracy of the object detection part of the model is low, which is prone to missed detection and false detection. Second, the segmentation accuracy of drivable area and lane line is low when the image is blurred by extreme weather, such as rain, snow, and fog, or the road is occluded. Third, the segmentation of lane lines is prone to discontinuity in the case of large changes in lane slope and sharp lane turns. Fourth, most of the multi-task network models have complex structures, occupy large computational overhead, and perform poorly on embedded devices with limited computing power, and their performance cannot meet the real-time requirements in autonomous driving.
To this end, we propose a multi-task convolutional neural network model MultiNet-GS based on encoder–decoder structure. We use the main structure of the latest object detection model, YOLOv8 model, as the encoder structure of our model. We introduce a new dynamic sparse attention mechanism, BiFormer, in the feature extraction part of the model to achieve more flexible computing resource allocation, which can significantly improve the computational efficiency and occupy a small computational overhead. The introduction of the attention mechanism makes the model pay more attention to the region of interest and improves the accuracy of object detection, drivable area segmentation, and lane line segmentation. We introduce a lightweight convolution, GSConv, in the feature fusion part of the network, which is used to build the neck part into a new slim-neck structure so as to reduce the computational complexity and inference time of the detector. The introduction of slim-neck structure greatly reduces the number of parameters and calculation of the model so that the model can adapt to embedded devices with limited computing power and meet the real-time requirements in autonomous driving. We also add an additional detector for tiny objects to the traditional three-head detector structure, and the introduction of the four-head structure leads to a substantial increase in the accuracy of the model for detecting tiny objects in traffic images. Finally, we introduce a lane detection method based on guide line in the lane detection part, which can aggregate the lane feature information into multiple key points, and then obtain the lane heat map response through conditional convolution. Finally, the lane line is described by the adaptive decoder, which effectively makes up for the shortcomings of the traditional lane detection method. So that the model can accurately and continuously segment the lane line in the case of drastic changes in lane slope and sharp lane turns.
Our comparative experiments on the BDD100K dataset on the embedded platform NVIDIA Jetson TX2 show that compared with SOTA(YOLOPv2), the mAP@0.5 of the model in traffic object detection reaches 82.1%, which is increased by 2.7%. The accuracy of the model in drivable area detection reaches 93.2%, which is increased by 0.5%. The accuracy of the model in lane detection reaches 85.7%, which is increased by 4.3%. The Params and FLOPs of the model reach 47.5 M and 117.5, which are reduced by 6.6 M and 8.3, respectively. The model achieves 72 FPS, which is increased by 5. Our MultiNet-GS model has the highest detection accuracy among the current mainstream models, while maintaining a good detection speed. Our proposed model makes up for the shortcomings of the traditional multi-task network model and can maintain good real-time performance on the embedded devices in the process of autonomous driving. At the same time, it can maintain the detection accuracy of traffic objects, drivable areas, and lane lines in complex traffic scenes so that the vehicle can make timely and accurate decisions and control in the process of environment perception. It effectively ensures the safety of automatic driving.
In the future work, we will continue to optimize the number of parameters and calculation of the network model, reduce the time cost of the model operation, and optimize and improve the network model for specific traffic scenarios to enhance the robustness of the model so that it can adapt to more diverse traffic scenarios.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}