
Portable Skin Lesion Segmentation System with Accurate Lesion Localization Based on Weakly Supervised Learning

 ,
, 
Abstract
:1. Introduction
- A novel approach for skin lesion segmentation is proposed by integrating segmentation and classification networks to extract common features of images.
- A weakly supervised semantic segmentation method for obtaining lesion pseudo masks is presented, achieved using a dual CAM cascade of image-level and pixel-level labels, which are fed into the segmentation network to transfer localization information and improve lesion segmentation accuracy.
- A portable skin lesion segmentation system was developed and successfully applied to real human skin testing, making the results of this study clinically relevant.
2. Related Work
2.1. Skin Lesion Segmentation and Classification
2.2. SLS Based on the Less Labeled Sample Strategy
2.3. Loss Function for Semantic Segmentation
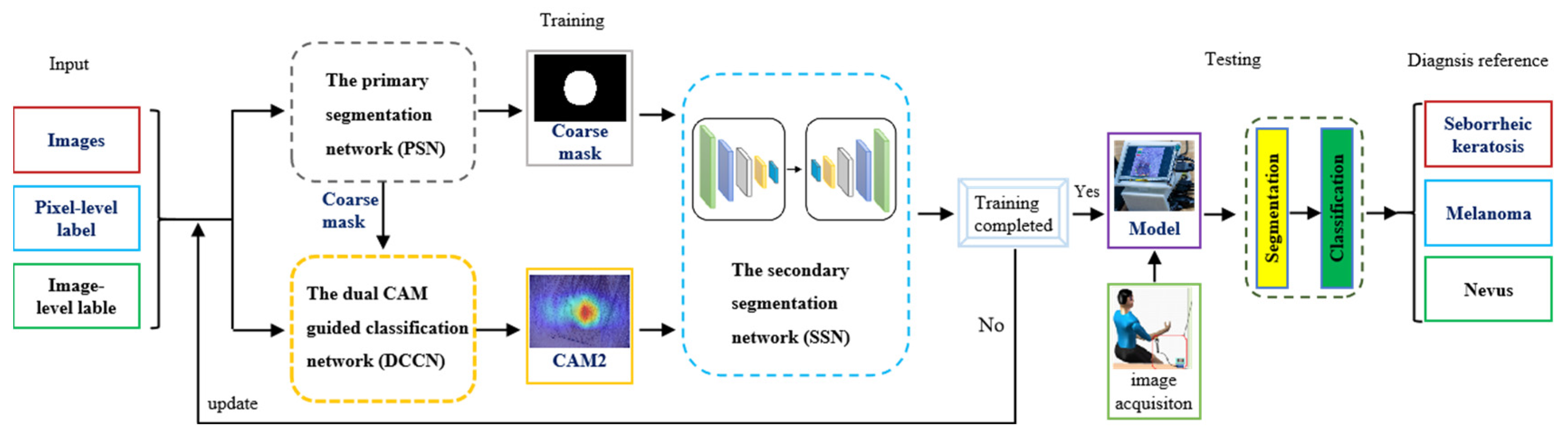
3. Method
3.1. Hardware System
3.2. Software Solution
3.2.1. PSN
3.2.2. DCCN
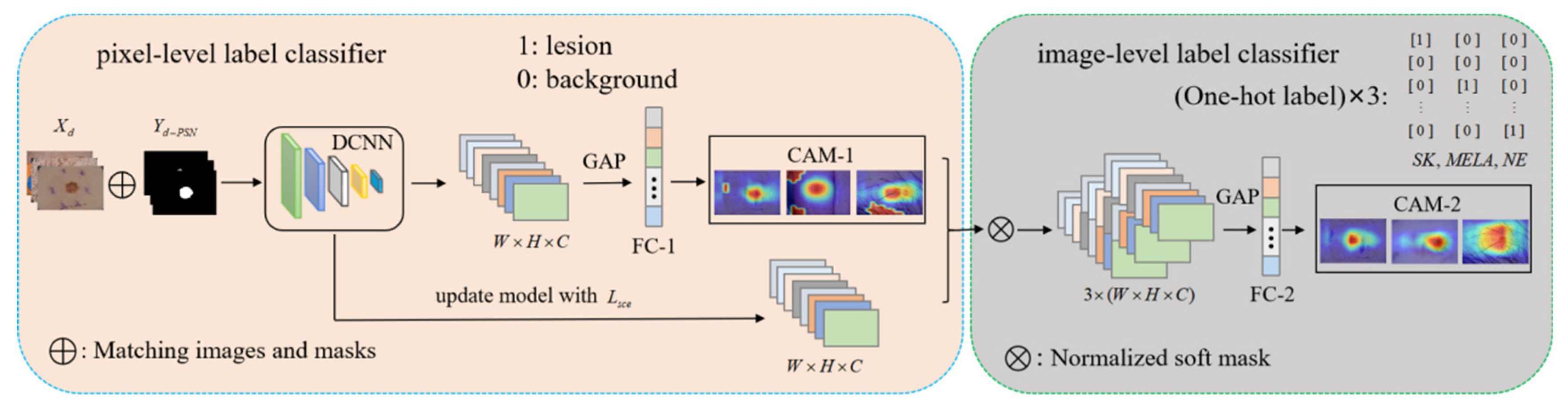
3.2.3. SSN
3.2.4. Hybrid Loss Function
4. Experiments and Results
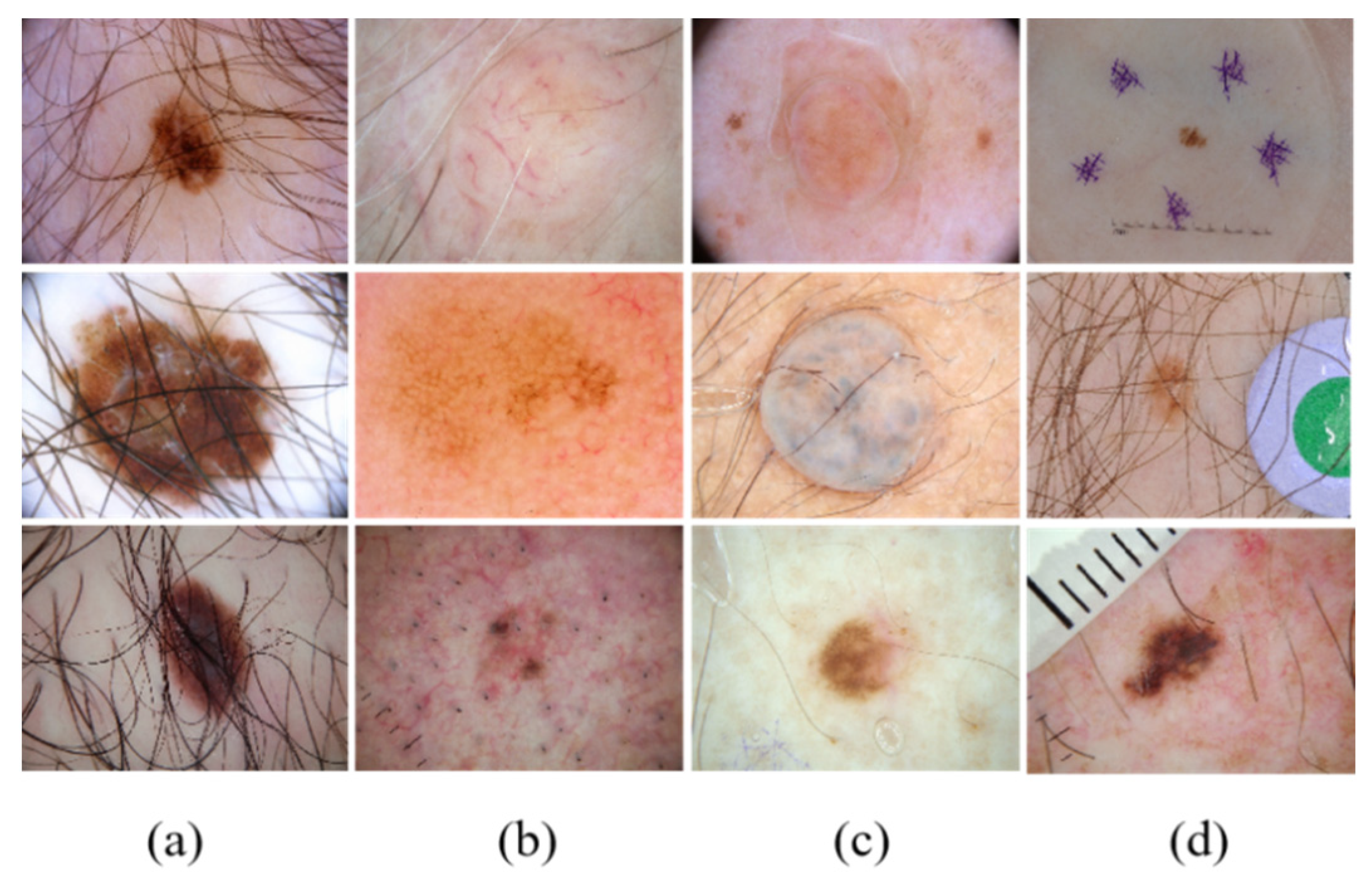
4.1. Datasets
4.2. Performance Evaluation
4.3. Implementation Details
4.4. Classification Experiments and Results
4.5. Hybrid Loss and the Effect on Experimental Results
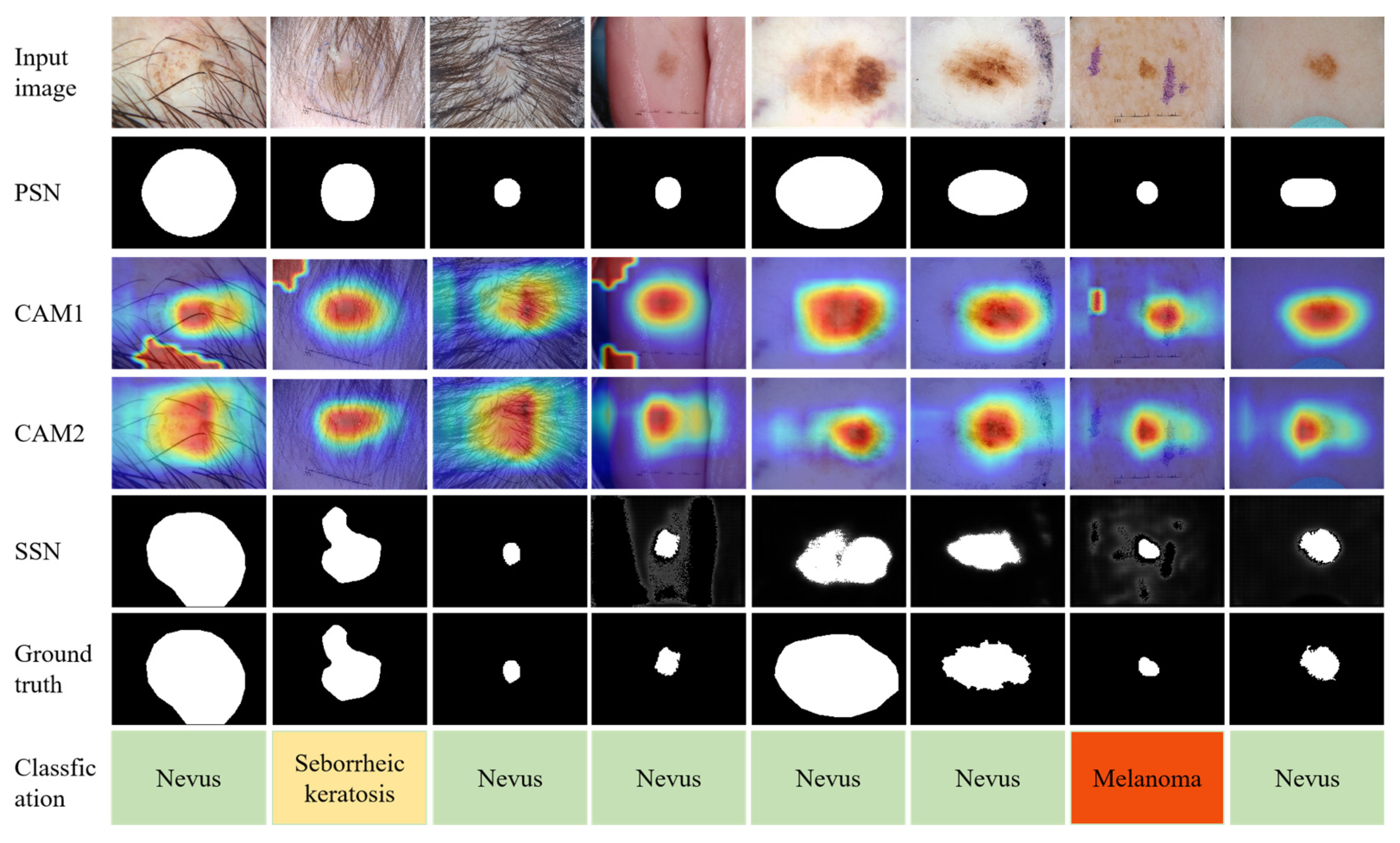
4.6. Effectiveness of the Dual CAM
4.7. System Testing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer statistics, 2022. CA Cancer J. Clin. 2022, 72, 7–33. [Google Scholar] [CrossRef] [PubMed]
- Balch, C.M.; Gershenwald, J.E.; Soong, S.-J.; Thompson, J.F.; Atkins, M.B.; Byrd, D.R.; Buzaid, A.C.; Cochran, A.J.; Coit, D.G.; Ding, S.; et al. Final version of 2009 AJCC melanoma staging and classification. J. Clin. Oncol. 2009, 27, 6199–6206. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Kaymak, R.; Kaymak, C.; Ucar, A. Skin lesion segmentation using fully convolutional networks: A comparative experimental study. Expert Syst. Appl. 2020, 161, 113742. [Google Scholar] [CrossRef]
- Lei, B.; Xia, Z.; Jiang, F.; Jiang, X.; Ge, Z.; Xu, Y.; Qin, J.; Chen, S.; Wang, T.; Wang, S. Skin lesion segmentation via generative adversarial networks with dual discriminators. Med. Image Anal. 2020, 64, 101716. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Xie, Y.; Xia, Y.; Shen, C. Attention residual learning for skin lesion classification. IEEE Trans. Med. Imaging 2019, 38, 2092–2103. [Google Scholar] [CrossRef]
- Tang, P.; Yan, X.; Nan, Y.; Xiang, S.; Krammer, S.; Lasser, T. FusionM4Net: A multi-stage multi-modal learning algorithm for multi-label skin lesion classification. Med. Image Anal. 2022, 76, 102307. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, Y.H.; Wen, P.; Shi, Y.; Qiu, Y.; Cheng, M.M. Leveraging instance-, image-and dataset-level information for weakly supervised instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1415–1428. [Google Scholar] [CrossRef]
- Wang, J.; Xia, B. Bounding box tightness prior for weakly supervised image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part II. Springer International Publishing: Cham, Switzerland, 2021; pp. 526–536. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Liang, Q.; Nan, Y.; Coppola, G.; Zou, K.; Sun, W.; Zhang, D.; Wang, Y.; Yu, G. Weakly supervised biomedical image segmentation by reiterative learning. IEEE J. Biomed. Health Inform. 2018, 23, 1205–1214. [Google Scholar] [CrossRef]
- Liu, W.; Kong, X.; Hung, T.-Y.; Lin, G. Cross-image region mining with region prototypical network for weakly supervised segmentation. IEEE Trans. Multimed. 2021, 25, 1148–1160. [Google Scholar] [CrossRef]
- Li, W.; Raj, A.N.J.; Tjahjadi, T.; Zhuang, Z. Digital hair removal by deep learning for skin lesion segmentation. Pattern Recognit. 2021, 117, 107994. [Google Scholar] [CrossRef]
- Tang, P.; Liang, Q.; Yan, X.; Xiang, S.; Sun, W.; Zhang, D.; Coppola, G. Efficient skin lesion segmentation using separable-Unet with stochastic weight averaging. Comput. Methods Programs Biomed. 2019, 178, 289–301. [Google Scholar] [CrossRef] [PubMed]
- Azad, R.; Asadi-Aghbolaghi, M.; Fathy, M.; Escalera, S. Attention deeplabv3+: Multi-level context attention mechanism for skin lesion segmentation. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 251–266. [Google Scholar]
- Liang, Q.; Qin, H.; Zeng, H.; Long, J.; Sun, W.; Zhang, D.; Wang, Y. Active Learning Integrated Portable Skin Lesion Detection System Based on Multi-model Fusion. IEEE Sens. J. 2023, 23, 9898–9908. [Google Scholar] [CrossRef]
- Wu, H.; Pan, J.; Li, Z.; Wen, Z.; Qin, J. Automated skin lesion segmentation via an adaptive dual attention module. IEEE Trans. Med. Imaging 2020, 40, 357–370. [Google Scholar] [CrossRef] [PubMed]
- Hu, K.; Lu, J.; Lee, D.; Xiong, D.; Chen, Z. AS-Net: Attention Synergy Network for skin lesion segmentation. Expert Syst. Appl. 2022, 201, 117112. [Google Scholar] [CrossRef]
- Gu, R.; Wang, G.; Song, T.; Huang, R.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. CA-Net: Comprehensive attention convolutional neural networks for explainable medical image segmentation. IEEE Trans. Med. Imaging 2020, 40, 699–711. [Google Scholar] [CrossRef]
- Khouloud, S.; Ahlem, M.; Fadel, T.; Amel, S. W-net and inception residual network for skin lesion segmentation and classification. Appl. Intell. 2022, 52, 3976–3994. [Google Scholar] [CrossRef]
- Xie, Y.; Zhang, J.; Xia, Y.; Shen, C. A mutual bootstrapping model for automated skin lesion segmentation and classification. IEEE Trans. Med. Imaging 2020, 39, 2482–2493. [Google Scholar] [CrossRef]
- Sarker, M.K.; Rashwan, H.A.; Akram, F.; Singh, V.K.; Banu, S.F.; Chowdhury, F.U.; Choudhury, K.A.; Chambon, S.; Radeva, P.; Puig, D.; et al. SLSNet: Skin lesion segmentation using a lightweight generative adversarial network. Expert Syst. Appl. 2021, 183, 115433. [Google Scholar] [CrossRef]
- Wu, H.; Chen, S.; Chen, G.; Wang, W.; Lei, B.; Wen, Z. FAT-Net: Feature adaptive transformers for automated skin lesion segmentation. Med. Image Anal. 2022, 76, 102327. [Google Scholar] [CrossRef]
- He, X.; Tan, E.-L.; Bi, H.; Zhang, X.; Zhao, S.; Lei, B. Fully transformer network for skin lesion analysis. Med. Image Anal. 2022, 77, 102357. [Google Scholar] [CrossRef]
- Li, X.; Wu, Y.; Dai, S. Semi-supervised medical imaging segmentation with soft pseudo-label fusion. Appl. Intell. 2023, 1–13. [Google Scholar] [CrossRef]
- Punn, N.S.; Agarwal, S. BT-Unet: A self-supervised learning framework for biomedical image segmentation using barlow twins with U-net models. Mach. Learn. 2022, 111, 4585–4600. [Google Scholar] [CrossRef]
- Bonechi, S. ISIC_WSM: Generating Weak Segmentation Maps for the ISIC archive. Neurocomputing 2023, 523, 69–80. [Google Scholar] [CrossRef]
- Chu, T.; Li, X.; Vo, H.V.; Summers, R.M.; Sizikova, E. Improving weakly supervised lesion segmentation using multi-task learning. In Proceedings of the Fourth Conference on Medical Imaging with Deep Learning, Lübeck, Germany, 7–9 July 2021; pp. 60–73. [Google Scholar]
- Wei, Y.; Xiao, H.; Shi, H.; Jie, Z.; Feng, J.; Huang, T.S. Revisiting dilated convolution: A simple approach for weakly- and semi- supervised semantic segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7268–7277. [Google Scholar]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; pp. 1–7. [Google Scholar]
- Yi-de, M.; Qing, L.; Zhi-Bai, Q. Automated image segmentation using improved PCNN model based on cross-entropy. In Proceedings of the 2004 International Symposium on Intelligent Multimedia, Video and Speech Processing, Hong Kong, China, 20–22 October 2004; pp. 743–746. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer International Publishing: Cham, Switzerland, 2017; pp. 240–248. [Google Scholar]
- Gutman, D.; Codella, N.C.; Celebi, E.; Helba, B.; Marchetti, M.; Mishra, N.; Halpern, A. Skin lesion analysis toward melanoma detection: A challenge at the international symposium on biomedical imaging (ISBI) 2016, hosted by the international skin imaging collaboration (ISIC). arXiv 2016, arXiv:1605.01397. [Google Scholar]
- Al-Masni, M.A.; Al-Antari, M.A.; Choi, M.-T.; Han, S.-M.; Kim, T.-S. Skin lesion segmentation in dermoscopy images via deep full resolution convolutional networks. Comput. Methods Programs Biomed. 2018, 162, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Xie, Y.; Wu, Q.; Xia, Y. Medical image classification using synergic deep learning. Med. Image Anal. 2019, 54, 10–19. [Google Scholar] [CrossRef]
- Tang, P.; Liang, Q.; Yan, X.; Xiang, S.; Zhang, D. GP-CNN-DTEL: Global-part CNN model with data-transformed ensemble learning for skin lesion classification. IEEE J. Biomed. Health Inform. 2020, 24, 2870–2882. [Google Scholar] [CrossRef] [PubMed]
- Ding, S.; Wu, Z.; Zheng, Y.; Liu, Z.; Yang, X.; Yang, X.; Yuan, G.; Xie, J. Deep attention branch networks for skin lesion classification. Comput. Methods Programs Biomed. 2021, 212, 106447. [Google Scholar] [CrossRef]
- He, X.; Wang, Y.; Zhao, S.; Yao, C. Deep metric attention learning for skin lesion classification in dermoscopy images. Complex Intell. Syst. 2022, 8, 1487–1504. [Google Scholar] [CrossRef]
- Matsunaga, K.; Hamada, A.; Minagawa, A.; Koga, H. Image classification of melanoma, nevus and seborrheic keratosis by deep neural network ensemble. arXiv 2017, arXiv:1703.03108. [Google Scholar]
- Díaz, I.G. Incorporating the knowledge of dermatologists to convolutional neural networks for the diagnosis of skin lesions. arXiv 2017, arXiv:1703.01976. [Google Scholar]
- Menegola, A.; Tavares, J.; Fornaciali, M.; Li, L.T.; Avila, S.; Valle, E. RECOD titans at ISIC challenge 2017. arXiv 2017, arXiv:1703.04819. [Google Scholar]
- Bi, L.; Kim, J.; Ahn, E.; Feng, D. Automatic skin lesion analysis using large-scale dermoscopy images and deep residual networks. arXiv 2017, arXiv:1703.04197. [Google Scholar]
- Yang, X.; Zeng, Z.; Yeo, S.Y.; Tan, C.; Tey, H.L.; Su, Y. A novel multi-task deep learning model for skin lesion segmentation and classification. arXiv 2017, arXiv:1703.01025. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Skin Microscope | Description | 3-in-1 1000× electronic magnifier |
| Resolution | 1920 PX × 1080 PX | |
| Magnification | 1000 times | |
| Adjustable Lighting | 8 LED | |
| Manufacturer | Shanghai Qigong Instrument Equipment Co., Ltd., Shanghai, China | |
| Display | Description | 5-inch HDMI LCD |
| Resolution | 800 PX × 480 PX | |
| Touch screen type | Capacitive | |
| Manufacturer | Shenzhen Weixue Electronic Technology Co., Ltd., Shenzhen, China | |
| Embedded Card | Description | Jetson Xavier NX |
| Size | 70 mm × 45 mm | |
| CPU | 6-core NVIDIA Carmel ARM | |
| GPU | 384-core NVIDIA VoltaTM GPU | |
| Memory | LPDDR4x, 8 GB | |
| Storage | EMMC 16 GB + SSD 1 TB | |
| Manufacturer | NVIDIA |
| Ground Truth (Lesion) | Ground Truth (No Lesion) | |
|---|---|---|
| Segmentation result (lesion) | TP | FP |
| Segmentation result (No lesion) | FN | TN |
| Methods | ACC | SEN | SPE | AUC |
|---|---|---|---|---|
| Team-CUMED | 85.5 | 50.7 | 94.1 | 80.4 |
| Team-GTDL | 81.3 | 57.3 | 87.2 | 80.2 |
| Team-BF-TB Thiemo | 83.4 | 32.0 | 96.1 | 82.6 |
| Team-ThrunLab | 78.6 | 66.7 | 81.6 | 79.6 |
| Team-Jordan Yap | 84.4 | 24.0 | 99.3 | 77.5 |
| SDL [36] (2019) | 86.3 | - | - | 82.2 |
| GP-CNN-DTEL [37] (2020) | 86.3 | 32.0 | 99.7 | 86.1 |
| DABN-ELW [38] (2021) | 86.3 | 66.8 | 89.1 | 83.6 |
| DeMAL-CNN [39] (2022) | 87.3 | 65.3 | 94.7 | 85.8 |
| Our method | 87.4 | 69.7 | 98.3 | 86.2 |
| Methods | Melanoma | Seborrheic Keratosis | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ACC | SEN | SPE | AUC | ACC | SEN | SPE | AUC | AUC | |
| #1 [40] | 82.8 | 73.5 | 85.1 | 86.8 | 80.3 | 97.8 | 77.3 | 95.3 | 91.1 |
| #2 [41] | 82.3 | 10.3 | 99.8 | 85.6 | 87.5 | 17.8 | 99.8 | 96.5 | 91.0 |
| #3 [42] | 87.2 | 54.7 | 95.0 | 87.4 | 89.5 | 35.6 | 99.0 | 94.3 | 90.8 |
| #4 [43] | 85.8 | 42.7 | 96.3 | 87.0 | 91.8 | 58.9 | 97.6 | 92.1 | 89.6 |
| #5 [44] | 83.0 | 43.6 | 92.5 | 83.0 | 91.7 | 70.0 | 99.5 | 94.2 | 88.6 |
| SDL [36] (2019) | 88.8 | - | - | 86.8 | 92.5 | - | - | 95.8 | 91.3 |
| GP-CNN-DTEL [37] (2020) | 85.0 | 37.6 | 96.5 | 89.1 | 93.5 | 72.2 | 97.3 | 96.0 | 92.6 |
| DABN-ELW [38] (2021) | 86.2 | 37.6 | 91.7 | 88.3 | 92.8 | 83.3 | 94.5 | 96.1 | 92.2 |
| DeMAL-CNN [39] (2022) | 85.5 | 61.5 | 90.6 | 87.5 | 92.7 | 88.1 | 91.1 | 96.7 | 92.1 |
| Our method | 87.1 | 55.6 | 94.6 | 89.2 | 92.7 | 75.6 | 95.7 | 96.6 | 92.9 |
| Methods | ACC | SEN | SPE | DIC | JAI |
|---|---|---|---|---|---|
| Unet | 52.64 | 41.45 | 87.96 | 51.15 | 39.23 |
| ResNet_Unet | 66.23 | 70.59 | 75.04 | 56.35 | 44.33 |
| ours | 83.84 | 90.18 | 81.16 | 58.68 | 45.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, H.; Deng, Z.; Shu, L.; Yin, Y.; Li, J.; Zhou, L.; Zeng, H.; Liang, Q. Portable Skin Lesion Segmentation System with Accurate Lesion Localization Based on Weakly Supervised Learning. Electronics 2023, 12, 3732. https://doi.org/10.3390/electronics12173732
Qin H, Deng Z, Shu L, Yin Y, Li J, Zhou L, Zeng H, Liang Q. Portable Skin Lesion Segmentation System with Accurate Lesion Localization Based on Weakly Supervised Learning. Electronics. 2023; 12(17):3732. https://doi.org/10.3390/electronics12173732
Chicago/Turabian StyleQin, Hai, Zhanjin Deng, Liye Shu, Yi Yin, Jintao Li, Li Zhou, Hui Zeng, and Qiaokang Liang. 2023. "Portable Skin Lesion Segmentation System with Accurate Lesion Localization Based on Weakly Supervised Learning" Electronics 12, no. 17: 3732. https://doi.org/10.3390/electronics12173732
APA StyleQin, H., Deng, Z., Shu, L., Yin, Y., Li, J., Zhou, L., Zeng, H., & Liang, Q. (2023). Portable Skin Lesion Segmentation System with Accurate Lesion Localization Based on Weakly Supervised Learning. Electronics, 12(17), 3732. https://doi.org/10.3390/electronics12173732