
Deep-Learning-Based Point Cloud Semantic Segmentation: A Survey


Abstract
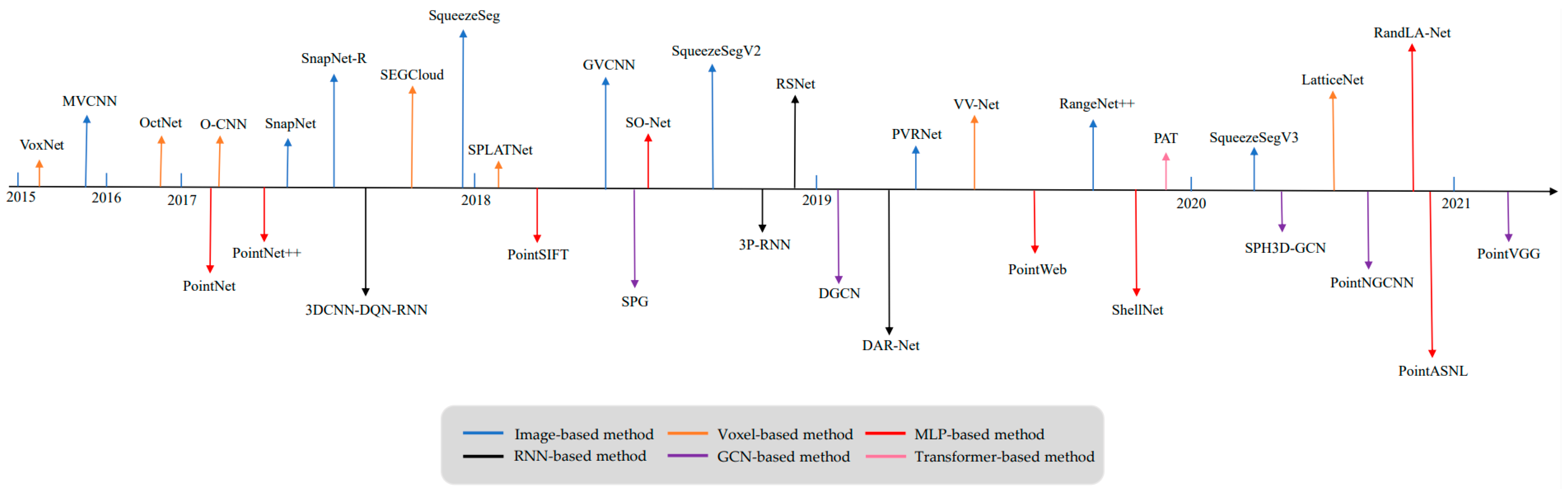
:1. Introduction
2. Point Cloud Characteristics
2.1. Diversity of Point Clouds
2.2. Information Richness of Point Clouds
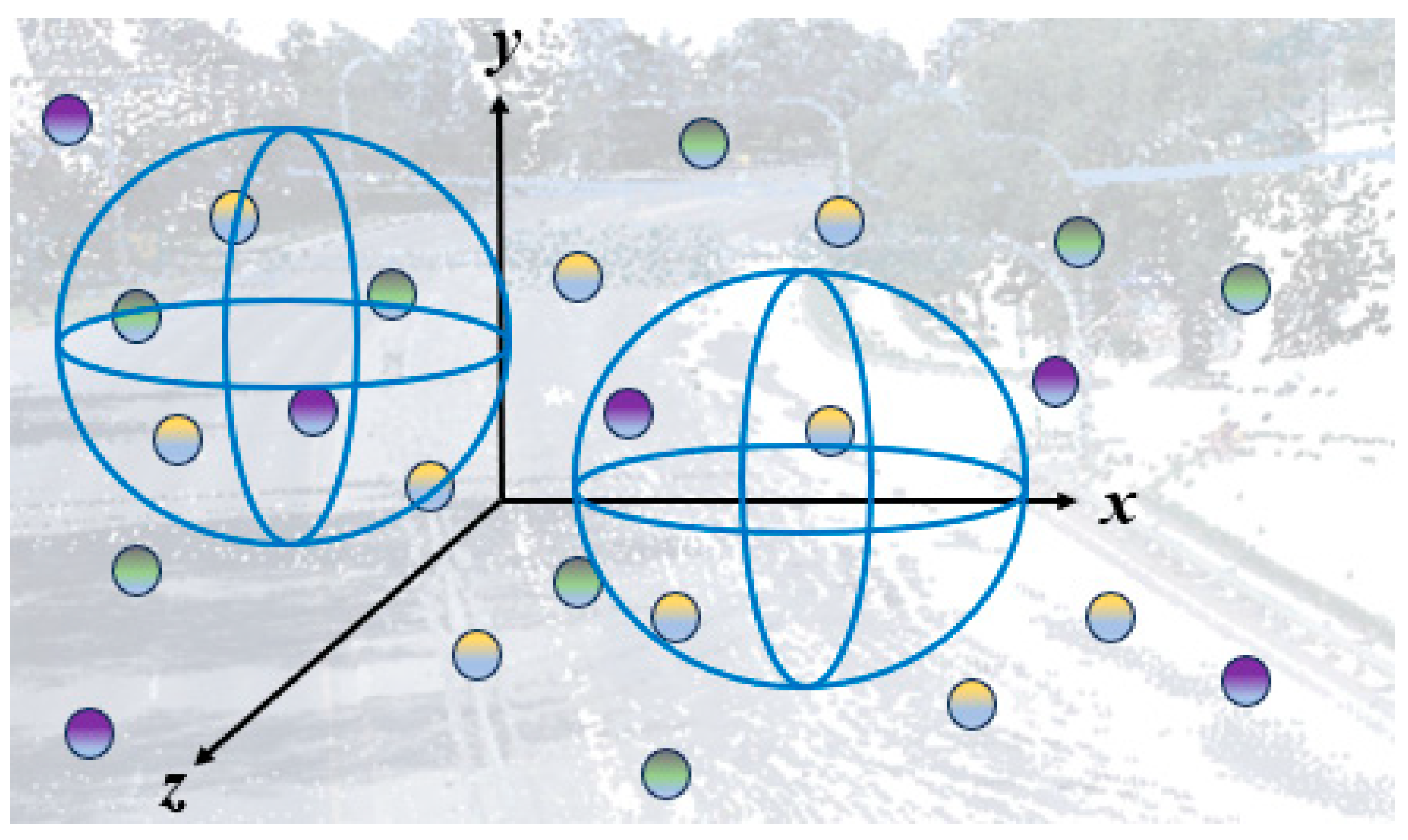
2.3. Nonuniformity of Point Clouds
2.4. Nonstructure of Point Clouds
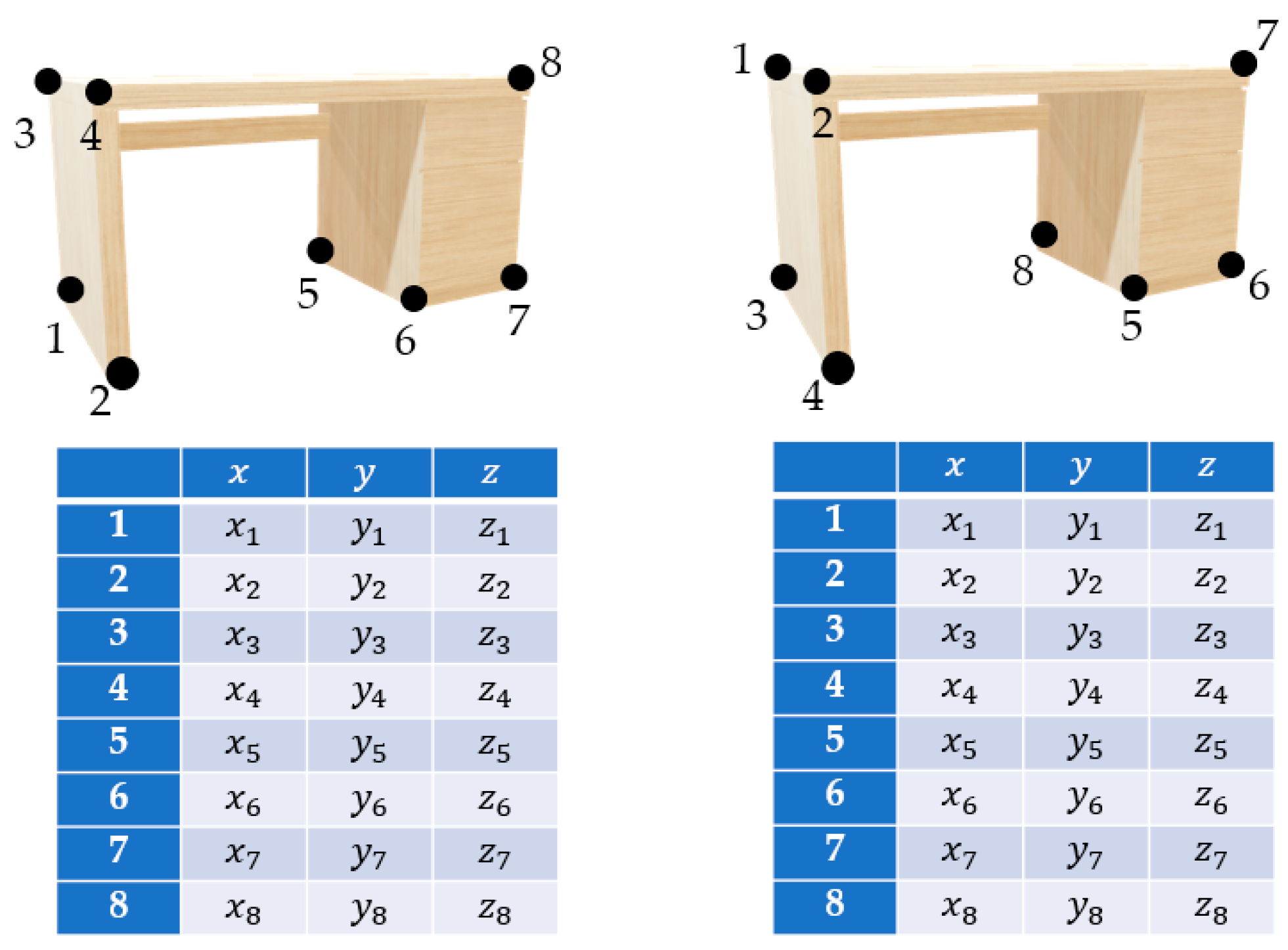
2.5. Disorder of Point Clouds
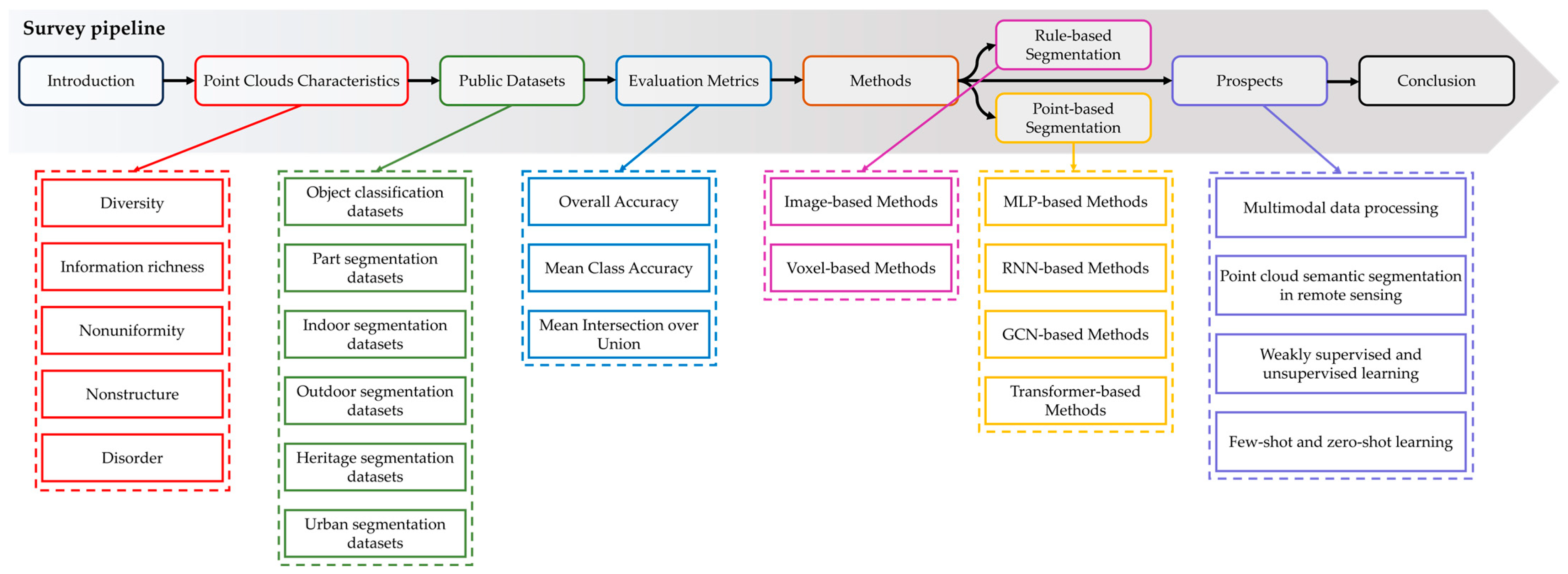
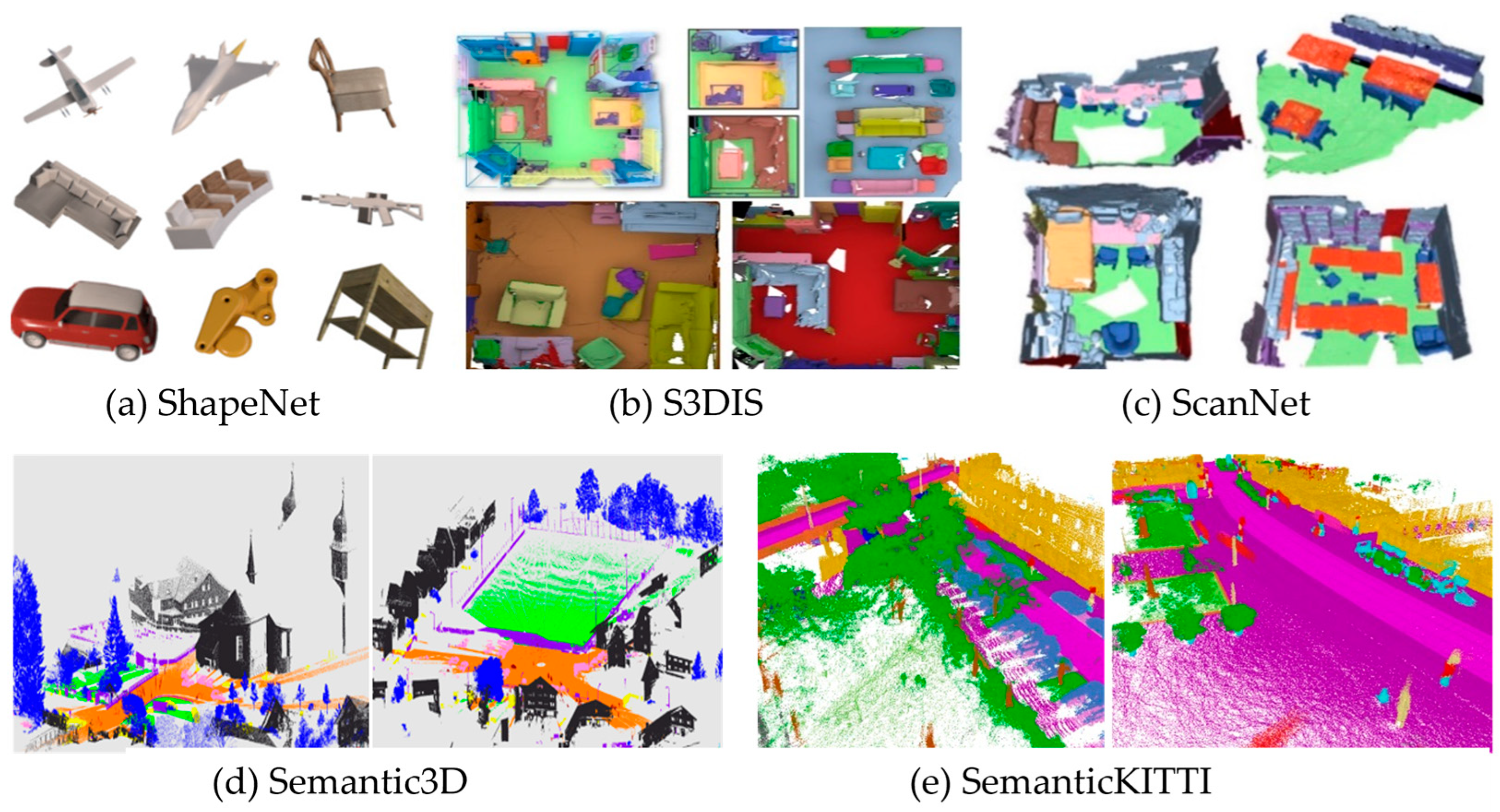
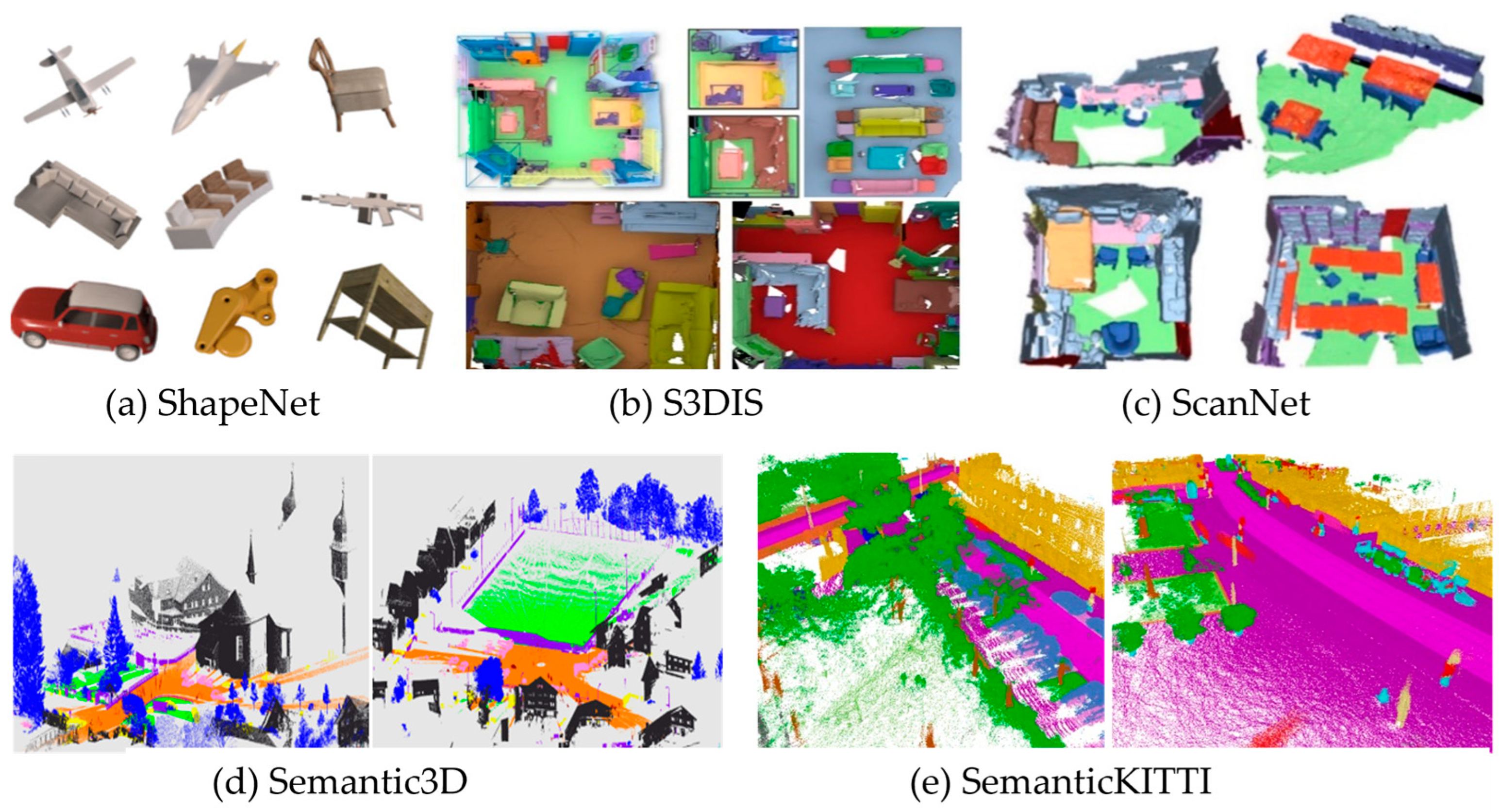
3. Public Datasets
4. Evaluation Metrics
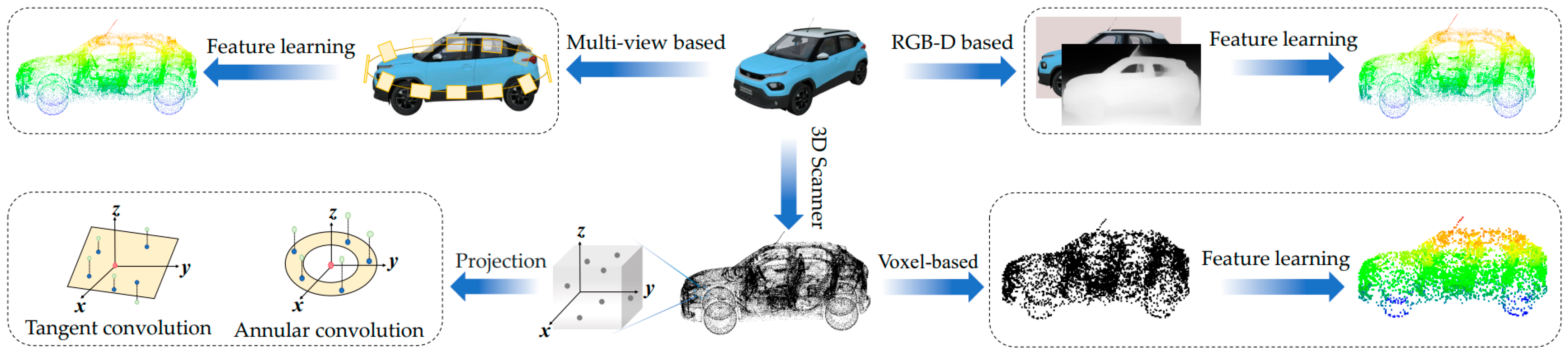
5. Point Cloud Semantic Segmentation Methods
5.1. Rule-Based Segmentation
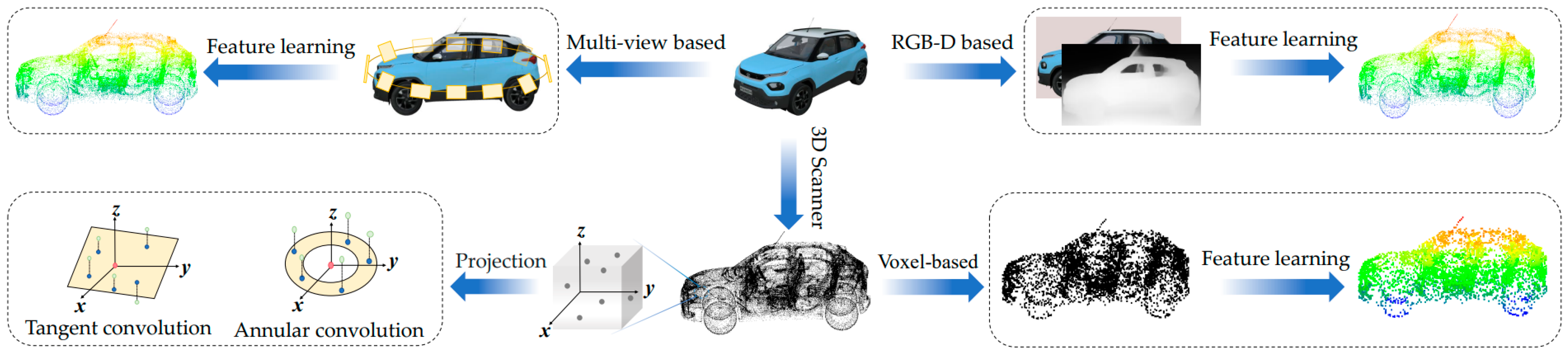
5.1.1. Image-Based Methods
- (1)
- Multiview Image-Based
- (2)
- RGB-D Image-Based
5.1.2. Voxel-Based Methods
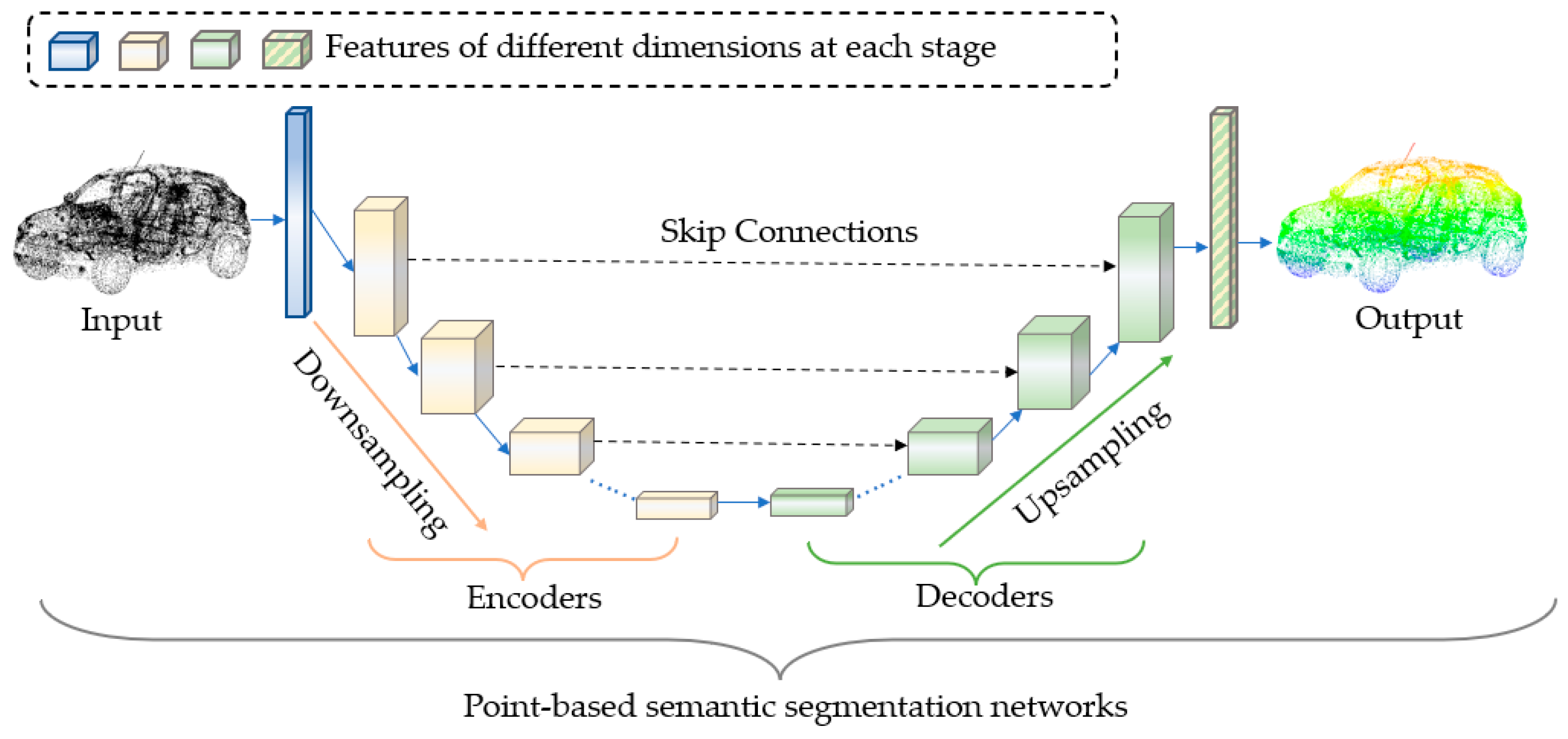
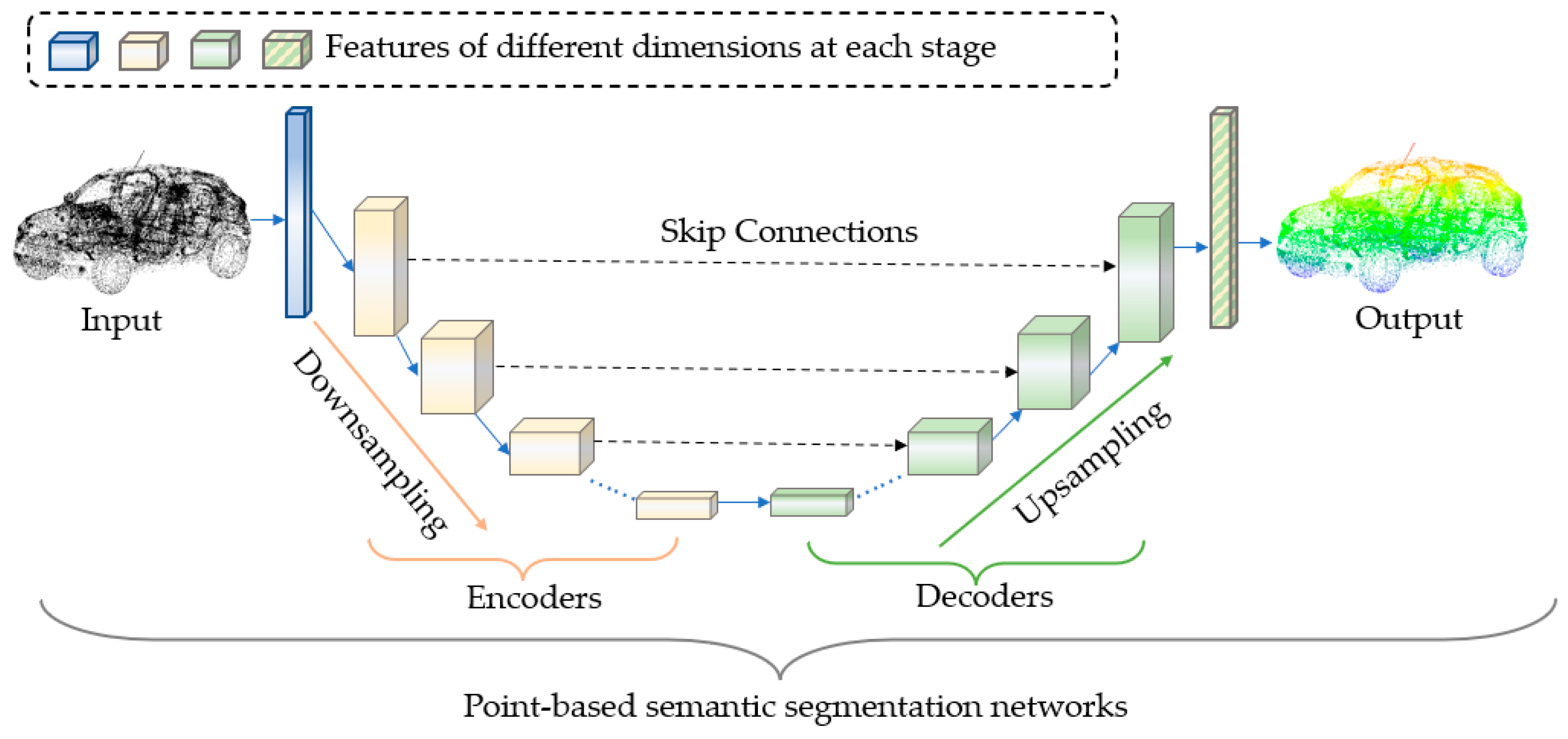
5.2. Point-Based Segmentation
5.2.1. MLP-Based Methods
5.2.2. RNN-Based Methods
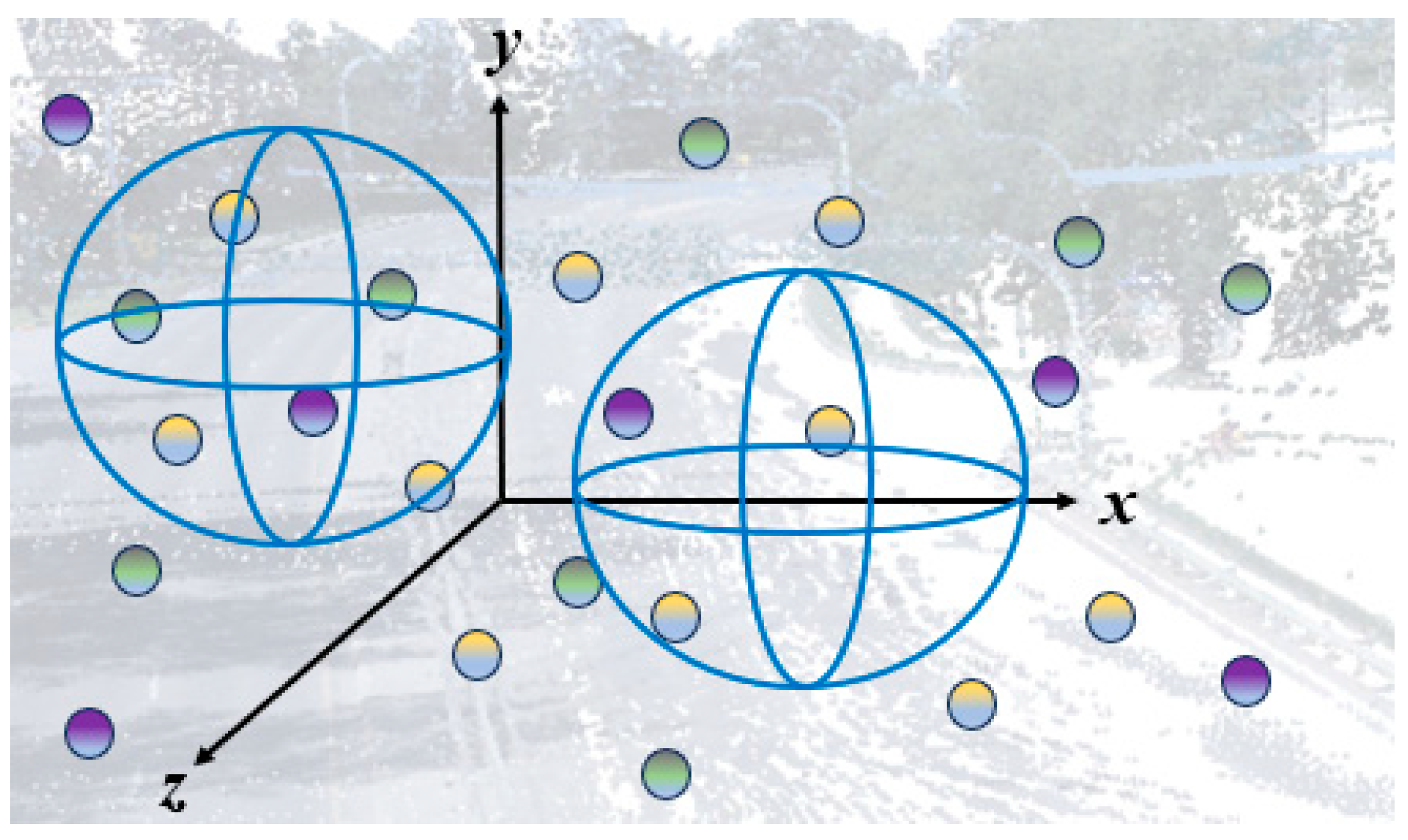
5.2.3. GCN-Based Methods
5.2.4. Transformer-Based Methods
6. Prospects
- (1)
- Multimodal data processing. Point cloud semantic segmentation methods from different research perspectives are based on different data forms (e.g., 2D images, voxels, point clouds). However, the data of a single form can hardly satisfy the all-around understanding and representation of 3D scenes. To this end, Xu et al. [99] proposed a point cloud semantic perception network based on voxels and graph-structured data. The network transforms the raw point cloud into voxels, constructs an adjacency graph for spatial contexts, and encodes the representation to realize the association of local geometric features between voxels. Liu et al. [100] proposed a dual-branch network named PVCNN for parallel processing of points and voxels, in which the voxel-based feature extraction branch aggregates coarse-grained features in the neighborhood, and the point-based branch uses MLP to achieve the extraction of fine-grained features. Therefore, designing lightweight and efficient multimodal data processing networks is an innovative idea to improve the performance of point cloud semantic segmentation methods.
- (2)
- Point cloud semantic segmentation in remote sensing. The point cloud is one of the common data carriers in the field of remote sensing. At present, although there are some point cloud datasets with large data volumes, such as SemanticKITTI, Semantic3D, and DALES for outdoor scenes, the existing data are still insufficient to satisfy the demand for semantic segmentation of super-large-scale urban scenes. For this reason, it is significant to construct high-quality and reliable spatiotemporal remote sensing datasets to support scientific research on remote sensing point cloud semantic segmentation. In recent studies, Unal et al. [101] innovatively proposed a novel strategy named Scribbles that can effectively simplify data annotation and published the first LiDAR point cloud dataset based on this strategy, ScribbleKITTI. This weak annotation approach does not need to finely annotate the boundaries of the object, but simply determines the start and end points of a line annotation, thus saving human, material, and financial resources to a great extent. Therefore, using this strategy to simplify the annotation of datasets may be the research direction and development trend of remote sensing point cloud semantic segmentation in the future. In addition, due to the different focus of remote sensing and computer vision, the performance evaluation system in computer vision is not fully applicable in remote sensing. How to build a standardized and unified performance evaluation system is the focus of future research on remote sensing point cloud semantic segmentation.
- (3)
- Weakly supervised and unsupervised learning. The performance of deep-learning-based methods relies on a large amount of data, but the existing datasets are far from satisfying the development needs. By using the weakly supervised learning strategy with only a small amount of weakly labeled data or the unsupervised learning strategy to train networks, the data hunger problem due to insufficient datasets can be largely alleviated. In this regard, Yang et al. [102] proposed an unsupervised point cloud semantic segmentation network by combining co-contrastive learning and a mutual attention sampling strategy, which deeply explores the contextual interactions between point pairs and accurately identifies points with strong cross-domain correlations through the object sampler and the background sampler, showing impressive performance on ScanObjectNN and S3DIS datasets. Xie et al. [103] designed an unsupervised pretraining strategy, PointContrast, to dynamically adjust the distance between features by comparing the matching of points before and after point cloud transformation in different views of the same scene. The method demonstrates its effectiveness in point cloud semantic segmentation and 3D target detection tasks across six different benchmarks for indoor, outdoor, and synthetic datasets, while also proving the feasibility that the learned representation can generalize across domains.
- (4)
- Few-shot and zero-shot learning. Deep learning is a data-driven technique that relies heavily on labeled samples. Due to the limitations of small size, uneven quality, and unbalanced data volume of different categories, few-shot and zero-shot learning strategies have been developed to solve the problem of overdependence on sample data. Specifically, the few-shot learning [104,105] strategy extracts key information from sample data with only a small amount of labeled samples so that the pretrained model can generalize to categories that did not occur during training. The zero-shot learning strategy [106,107] uses a limited number of samples that have no intersection with the categories in test sets to train models and achieve the construction of cross-domain representations by learning cross-domain features. The few-shot and zero-shot learning strategies provide a new research concept for achieving point cloud classification and semantic segmentation in the absence of sample data, which is instructive.
7. Conclusions
- (1)
- Difference in sensor types and data acquisition platforms leads to certain obstacles in processing different datasets by the models.
- (2)
- The density of point clouds in 3D space is extremely nonuniform and the datasets are commonly long-tailed, which leads to the uneven focus of the models on different object categories in scene understanding.
- (3)
- The diversity of 3D dataset types leads to large differences in the categories and numbers of objects in each scene, which poses challenges to the cross-domain learning capability of the models.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Kang, D.; Wong, A.; Lee, B.; Kim, J. Real-time semantic segmentation of 3D point cloud for autonomous driving. Electronics 2021, 10, 1960. [Google Scholar] [CrossRef]
- Jin, Y.-H.; Hwang, I.-T.; Lee, W.-H. A mobile augmented reality system for the real-time visualization of pipes in point cloud data with a depth sensor. Electronics 2020, 9, 836. [Google Scholar] [CrossRef]
- Wang, G.; Wang, L.; Wu, S.; Zu, S.; Song, B. Semantic Segmentation of Transmission Corridor 3D Point Clouds Based on CA-PointNet++. Electronics 2023, 12, 2829. [Google Scholar] [CrossRef]
- Zhang, R.; Li, G.; Wunderlich, T.; Wang, L. A survey on deep learning-based precise boundary recovery of semantic segmentation for images and point clouds. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102411. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Diab, A.; Kashef, R.; Shaker, A. Deep Learning for LiDAR Point Cloud Classification in Remote Sensing. Sensors 2022, 22, 7868. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Hou, M.; Li, S. Three-Dimensional Point Cloud Semantic Segmentation for Cultural Heritage: A Comprehensive Review. Remote Sens. 2023, 15, 548. [Google Scholar] [CrossRef]
- Jhaldiyal, A.; Chaudhary, N. Semantic segmentation of 3D LiDAR data using deep learning: A review of projection-based methods. Appl. Intell. 2023, 53, 6844–6855. [Google Scholar] [CrossRef]
- Pan, Y.; Xia, Y.; Li, Y.; Yang, M.; Zhu, Q. Research on stability analysis of large karst cave structure based on multi-source point clouds modeling. Earth Sci. Inform. 2023, 16, 1637–1656. [Google Scholar] [CrossRef]
- Tong, X.; Zhang, X.; Liu, S.; Ye, Z.; Feng, Y.; Xie, H.; Chen, L.; Zhang, F.; Han, J.; Jin, Y. Automatic Registration of Very Low Overlapping Array InSAR Point Clouds in Urban Scenes. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–25. [Google Scholar] [CrossRef]
- Masciulli, C.; Gaeta, M.; Berardo, G.; Pantozzi, G.; Stefanini, C.A.; Mazzanti, P. ML-based characterization of PS-InSAR multi-mission point clouds for ground deformation classification. In Proceedings of the EGU General Assembly 2023, Vienna, Austria, 24–28 April 2023; p. EGU23-14546. [Google Scholar] [CrossRef]
- Hu, L.; Tomás, R.; Tang, X.; López Vinielles, J.; Herrera, G.; Li, T.; Liu, Z. Updating Active Deformation Inventory Maps in Mining Areas by Integrating InSAR and LiDAR Datasets. Remote Sens. 2023, 15, 996. [Google Scholar] [CrossRef]
- da Silva Ruiz, P.R.; Almeida CM de Schimalski, M.B.; Liesenberg, V.; Mitishita, E.A. Multi-approach integration of ALS and TLS point clouds for a 3-D building modeling at LoD3. Int. J. Archit. Comput. 2023. [Google Scholar] [CrossRef]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar]
- Geyer, J.; Kassahun, Y.; Mahmudi, M.; Ricou, X.; Durgesh, R.; Chung, A.S.; Hauswald, L.; Pham, V.H.; Mühlegg, M.; Dorn, S. A2d2: Audi autonomous driving dataset. arXiv 2020, arXiv:2004.06320. [Google Scholar]
- Roynard, X.; Deschaud, J.-E.; Goulette, F. Paris-Lille-3D: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classification. Int. J. Robot. Res. 2018, 37, 545–557. [Google Scholar] [CrossRef]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H. Shapenet: An information-rich 3d model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3d. net: A new large-scale point cloud classification benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of the Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Uy, M.A.; Pham, Q.-H.; Hua, B.-S.; Nguyen, T.; Yeung, S.-K. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of the Korea, 27 October–2 November 2019; pp. 1588–1597. [Google Scholar]
- Yi, L.; Kim, V.G.; Ceylan, D.; Shen, I.-C.; Yan, M.; Su, H.; Lu, C.; Huang, Q.; Sheffer, A.; Guibas, L. A scalable active framework for region annotation in 3d shape collections. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Wang, C.; Dai, Y.; Elsheimy, N.; Wen, C.; Retscher, G.; Kang, Z.; Lingua, A. ISPRS Benchmark on Multisensory Indoor Mapping and Positioning. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2020, 5, 117–123. [Google Scholar] [CrossRef]
- Matrone, F.; Lingua, A.; Pierdicca, R.; Malinverni, E.; Paolanti, M.; Grilli, E.; Remondino, F.; Murtiyoso, A.; Landes, T. A benchmark for large-scale heritage point cloud semantic segmentation. In Proceedings of the XXIV ISPRS Congress, Nice, France, 31 August–2 September 2020; pp. 1419–1426. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Serna, A.; Marcotegui, B.; Goulette, F.; Deschaud, J.-E. Paris-rue-Madame database: A 3D mobile laser scanner dataset for benchmarking urban detection, segmentation and classification methods. In Proceedings of the 4th International Conference on Pattern Recognition, Applications and Methods ICPRAM 2014, Lisbon, Portugal, 29 July 2014. [Google Scholar]
- Huang, X.; Cheng, X.; Geng, Q.; Cao, B.; Zhou, D.; Wang, P.; Lin, Y.; Yang, R. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 954–960. [Google Scholar]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A large-scale mobile lidar dataset for semantic segmentation of urban roadways. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 202–203. [Google Scholar]
- Pan, Y.; Gao, B.; Mei, J.; Geng, S.; Li, C.; Zhao, H. Semanticposs: A point cloud dataset with large quantity of dynamic instances. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 687–693. [Google Scholar]
- Dong, Z.; Liang, F.; Yang, B.; Xu, Y.; Zang, Y.; Li, J.; Wang, Y.; Dai, W.; Fan, H.; Hyyppä, J. Registration of large-scale terrestrial laser scanner point clouds: A review and benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 163, 327–342. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Xiao, P.; Shao, Z.; Hao, S.; Zhang, Z.; Chai, X.; Jiao, J.; Li, Z.; Wu, J.; Sun, K.; Jiang, K. PandaSet: Advanced Sensor Suite Dataset for Autonomous Driving. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3095–3101. [Google Scholar]
- Fong, W.K.; Mohan, R.; Hurtado, J.V.; Zhou, L.; Caesar, H.; Beijbom, O.; Valada, A. Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking. IEEE Robot. Autom. Lett. 2022, 7, 3795–3802. [Google Scholar] [CrossRef]
- Zheng, L.; Ma, Z.; Zhu, X.; Tan, B.; Li, S.; Long, K.; Sun, W.; Chen, S.; Zhang, L.; Wan, M. TJ4DRadSet: A 4D Radar Dataset for Autonomous Driving. arXiv 2022, arXiv:2204.13483. [Google Scholar]
- Varney, N.; Asari, V.K.; Graehling, Q. Dales: A large-scale aerial lidar data set for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 186–187. [Google Scholar]
- Ye, Z.; Xu, Y.; Huang, R.; Tong, X.; Li, X.; Liu, X.; Luan, K.; Hoegner, L.; Stilla, U. Lasdu: A large-scale aerial lidar dataset for semantic labeling in dense urban areas. ISPRS Int. J. Geo-Inf. 2020, 9, 450. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. SensatUrban: Learning Semantics from Urban-Scale Photogrammetric Point Clouds. Int. J. Comput. Vis. 2022, 130, 316–343. [Google Scholar] [CrossRef]
- Jiang, X.Y.; Meier, U.; Bunke, H. Fast range image segmentation using high-level segmentation primitives. In Proceedings of the Third IEEE Workshop on Applications of Computer Vision: WACV’96, Sarasota, FL, USA, 2–4 December 1996; pp. 83–88. [Google Scholar]
- Besl, P.J.; Jain, R.C. Segmentation through variable-order surface fitting. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 167–192. [Google Scholar] [CrossRef]
- Rabbani, T.; Van Den Heuvel, F.; Vosselmann, G. Segmentation of point clouds using smoothness constraint. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2006, 36, 248–253. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 945–953. [Google Scholar]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. Gvcnn: Group-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 264–272. [Google Scholar]
- You, H.; Feng, Y.; Zhao, X.; Zou, C.; Ji, R.; Gao, Y. PVRNet: Point-view relation neural network for 3D shape recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; pp. 9119–9126. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. Rangenet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Robert, D.; Vallet, B.; Landrieu, L. Learning Multi-View Aggregation in the Wild for Large-Scale 3D Semantic Segmentation. arXiv 2022, arXiv:2204.07548. [Google Scholar]
- Boulch, A.; Guerry, J.; Le Saux, B.; Audebert, N. SnapNet: 3D point cloud semantic labeling with 2D deep segmentation networks. Comput. Graph. 2018, 71, 189–198. [Google Scholar] [CrossRef]
- Guerry, J.; Boulch, A.; Le Saux, B.; Moras, J.; Plyer, A.; Filliat, D. Snapnet-r: Consistent 3d multi-view semantic labeling for robotics. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 669–678. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Xu, C.; Wu, B.; Wang, Z.; Zhan, W.; Vajda, P.; Keutzer, K.; Tomizuka, M. Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 1–19. [Google Scholar]
- Yang, Y.; Wu, X.; He, T.; Zhao, H.; Liu, X. SAM3D: Segment Anything in 3D Scenes. arXiv 2023, arXiv:2306.03908. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.-H.; Kautz, J. Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2530–2539. [Google Scholar]
- Rosu, R.A.; Schütt, P.; Quenzel, J.; Behnke, S. Latticenet: Fast point cloud segmentation using permutohedral lattices. arXiv 2019, arXiv:1912.05905. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 international conference on 3D vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Wang, P.-S.; Liu, Y.; Guo, Y.-X.; Sun, C.-Y.; Tong, X. O-cnn: Octree-based convolutional neural networks for 3d shape analysis. ACM Trans. Graph. 2017, 36, 1–11. [Google Scholar] [CrossRef]
- Meng, H.-Y.; Gao, L.; Lai, Y.-K.; Manocha, D. Vv-net: Voxel vae net with group convolutions for point cloud segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of the Korea, 27 October–2 November 2019; pp. 8500–8508. [Google Scholar]
- Park, J.; Kim, C.; Kim, S.; Jo, K. PCSCNet: Fast 3D semantic segmentation of LiDAR point cloud for autonomous car using point convolution and sparse convolution network. Expert Syst. Appl. 2023, 212, 118815. [Google Scholar] [CrossRef]
- Yu, C.; Lei, J.; Peng, B.; Shen, H.; Huang, Q. SIEV-Net: A structure-information enhanced voxel network for 3D object detection from LiDAR point clouds. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. Pointsift: A sift-like network module for 3d point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.-W.; Jia, J. Pointweb: Enhancing local neighborhood features for point cloud processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5565–5573. [Google Scholar]
- Li, J.; Chen, B.M.; Lee, G.H. So-net: Self-organizing network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9397–9406. [Google Scholar]
- Zhang, Z.; Hua, B.-S.; Yeung, S.-K. Shellnet: Efficient point cloud convolutional neural networks using concentric shells statistics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of the Korea, 27 October–2 November 2019; pp. 1607–1616. [Google Scholar]
- Yan, X.; Zheng, C.; Li, Z.; Wang, S.; Cui, S. Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5589–5598. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Ma, X.; Qin, C.; You, H.; Ran, H.; Fu, Y. Rethinking network design and local geometry in point cloud: A simple residual mlp framework. arXiv 2022, arXiv:2202.07123. [Google Scholar]
- Fan, H.; Yang, Y. PointRNN: Point recurrent neural network for moving point cloud processing. arXiv 2019, arXiv:1910.08287. [Google Scholar]
- Ye, X.; Li, J.; Huang, H.; Du, L.; Zhang, X. 3d recurrent neural networks with context fusion for point cloud semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 403–417. [Google Scholar]
- Huang, Q.; Wang, W.; Neumann, U. Recurrent slice networks for 3d segmentation of point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2626–2635. [Google Scholar]
- Zhao, Z.; Liu, M.; Ramani, K. DAR-Net: Dynamic aggregation network for semantic scene segmentation. arXiv 2019, arXiv:1907.12022. [Google Scholar]
- Liu, F.; Li, S.; Zhang, L.; Zhou, C.; Ye, R.; Wang, Y.; Lu, J. 3DCNN-DQN-RNN: A deep reinforcement learning framework for semantic parsing of large-scale 3D point clouds. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5678–5687. [Google Scholar]
- Simonovsky, M.; Komodakis, N. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3693–3702. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. Acm Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Lei, H.; Akhtar, N.; Mian, A. Spherical kernel for efficient graph convolution on 3d point clouds. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3664–3680. [Google Scholar] [CrossRef] [PubMed]
- Lu, Q.; Chen, C.; Xie, W.; Luo, Y. PointNGCNN: Deep convolutional networks on 3D point clouds with neighborhood graph filters. Comput. Graph. 2020, 86, 42–51. [Google Scholar] [CrossRef]
- Li, R.; Zhang, Y.; Niu, D.; Yang, G.; Zafar, N.; Zhang, C.; Zhao, X. PointVGG: Graph convolutional network with progressive aggregating features on point clouds. Neurocomputing 2021, 429, 187–198. [Google Scholar] [CrossRef]
- Zhang, N.; Pan, Z.; Li, T.H.; Gao, W.; Li, G. Improving Graph Representation for Point Cloud Segmentation via Attentive Filtering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1244–1254. [Google Scholar]
- Zhang, R.; Li, G.; Wiedemann, W.; Holst, C. KdO-Net: Towards Improving the Efficiency of Deep Convolutional Neural Networks Applied in the 3D Pairwise Point Feature Matching. Remote Sens. 2022, 14, 2883. [Google Scholar] [CrossRef]
- Li, R.; Wang, S.; Zhu, F.; Huang, J. Adaptive graph convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-scale point cloud semantic segmentation with superpoint graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4558–4567. [Google Scholar]
- Geng, Y.; Wang, Z.; Jia, L.; Qin, Y.; Chai, Y.; Liu, K.; Tong, L. 3DGraphSeg: A Unified Graph Representation-Based Point Cloud Segmentation Framework for Full-Range Highspeed Railway Environments. IEEE Trans. Ind. Inform. 2023. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Guo, M.-H.; Cai, J.-X.; Liu, Z.-N.; Mu, T.-J.; Martin, R.R.; Hu, S.-M. Pct: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Engel, N.; Belagiannis, V.; Dietmayer, K. Point transformer. IEEE Access 2021, 9, 134826–134840. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, Q.; Ni, B.; Li, L.; Liu, J.; Zhou, M.; Tian, Q. Modeling point clouds with self-attention and gumbel subset sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3323–3332. [Google Scholar]
- Zhong, Q.; Han, X.-F. Point cloud learning with transformer. arXiv 2021, arXiv:2104.13636. [Google Scholar]
- Han, X.-F.; Jin, Y.-F.; Cheng, H.-X.; Xiao, G.-Q. Dual Transformer for Point Cloud Analysis. arXiv 2021, arXiv:2104.13044. [Google Scholar] [CrossRef]
- Lai, X.; Liu, J.; Jiang, L.; Wang, L.; Zhao, H.; Liu, S.; Qi, X.; Jia, J. Stratified Transformer for 3D Point Cloud Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8500–8509. [Google Scholar]
- Zhou, J.; Xiong, Y.; Chiu, C.; Liu, F.; Gong, X. SAT: Size-Aware Transformer for 3D Point Cloud Semantic Segmentation. arXiv 2023, arXiv:2301.06869. [Google Scholar]
- Xu, Y.; Hoegner, L.; Tuttas, S.; Stilla, U. Voxel-and graph-based point cloud segmentation of 3d scenes using perceptual grouping laws. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 43–50. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, H.; Lin, Y.; Han, S. Point-Voxel CNN for Efficient 3D Deep Learning. arXiv 2019, arXiv:1907.03739. [Google Scholar] [CrossRef]
- Unal, O.; Dai, D.; Van Gool, L. Scribble-Supervised LiDAR Semantic Segmentation. arXiv 2022, arXiv:2203.08537. [Google Scholar]
- Yang, C.-K.; Chuang, Y.-Y.; Lin, Y.-Y. Unsupervised Point Cloud Object Co-segmentation by Co-contrastive Learning and Mutual Attention Sampling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7335–7344. [Google Scholar]
- Xie, S.; Gu, J.; Guo, D.; Qi, C.R.; Guibas, L.; Litany, O. Pointcontrast: Unsupervised pre-training for 3d point cloud understanding. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 574–591. [Google Scholar]
- Liu, M.; Zhu, Y.; Cai, H.; Han, S.; Ling, Z.; Porikli, F.; Su, H. Partslip: Low-shot part segmentation for 3d point clouds via pretrained image-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 21736–21746. [Google Scholar]
- Sharma, C.; Kaul, M. Self-supervised few-shot learning on point clouds. Adv. Neural Inf. Process. Syst. 2020, 33, 7212–7221. [Google Scholar]
- He, S.; Jiang, X.; Jiang, W.; Ding, H. Prototype Adaption and Projection for Few- and Zero-Shot 3D Point Cloud Semantic Segmentation. IEEE Trans. Image Process. 2023, 32, 3199–3211. [Google Scholar] [CrossRef]
- Abdelreheem, A.; Skorokhodov, I.; Ovsjanikov, M.; Wonka, P. SATR: Zero-Shot Semantic Segmentation of 3D Shapes. arXiv 2023, arXiv:2304.04909. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Year | Type | Application Scenario | Category | Size | Sensor |
|---|---|---|---|---|---|---|
| ModelNet10 [15] | 2015 | S | Oc | 10 | 4.9 Tm | - |
| ModelNet40 [15] | 2015 | S | Oc | 10 | 12.3 Tm | - |
| ScanObjectNN [23] | 2019 | R | Oc | 15 | 15 To | - |
| ShapeNet [19] | 2015 | S | Ps | 55 | 51.3 Tm | - |
| ShapeNet Part [24] | 2016 | S | Ps | 16 | 16.9 Tm | - |
| SUN RGB-D [14] | 2015 | R | Is | 47 | 103.5 Tf | Kinect |
| S3DIS [16] | 2016 | R | Is | 13 | 273.0 Mp | Matterport |
| ScanNet [20] | 2017 | R | Is | 22 | 242.0 Mp | RGB-D |
| MIMAP [25] | 2020 | R | Is | - | 22.5 Mp | XBeibao |
| ArCH [26] | 2020 | R | Hs | 10 | 102.74 Mp | TLS |
| KITTI [27] | 2012 | R | Os | 3 | 179.0 Mp | MLS |
| Semantic3D [21] | 2017 | R | Os | 8 | 4000.0 Mp | MLS |
| Paris-rue-Madame [28] | 2018 | R | Os | 17 | 20.0 Mp | MLS |
| Paris-Lille-3D [18] | 2018 | R | Os | 9 | 143.0 Mp | MLS |
| ApolloScape [29] | 2018 | R | Os | 24 | 140.7 Tf | RGB-D |
| SemanticKITTI [22] | 2019 | R | Os | 25 | 4549.0 Mp | MLS |
| Toronto-3D [30] | 2020 | R | Os | 8 | 78.3 Mp | MLS |
| A2D2 [17] | 2020 | R | Os | 38 | 41.3 Tf | TLS |
| SemanticPOSS [31] | 2020 | R | Os | 14 | 216 Mp | MLS |
| WHU-TLS [32] | 2020 | R | Os | - | 1740.0 Mp | TLS |
| nuScenes [33] | 2020 | R | Os | 31 | 34.1 Tf | Velodyne HDL-32E |
| PandaSet [34] | 2021 | R | Os | 37 | 16.0 Tf | MLS |
| Panoptic nuScenes [35] | 2022 | R | Os | 32 | 1100.0 Mp | MLS |
| TJ4DRadSet [36] | 2022 | R | Os | 8 | 7.75 Tf | 4D Radar |
| DALES [37] | 2020 | R | Us | 8 | 505.0 Mp | ALS |
| LASDU [38] | 2020 | R | Us | 5 | 3.12 Mp | ALS |
| SensatUrban [39] | 2022 | R | Us | 13 | 2847.0 Mp | UAV Photogrammetry |
| Method | Year | Dataset | Performance | Contribution | ||
|---|---|---|---|---|---|---|
| OA | mAcc | mIoU | ||||
| MVCNN [43] | 2015 | ModelNet40 | 90.1% | - | - | The first multiview CNN |
| SnapNet [48] | 2017 | Sun RGB-D | - | 67.4% | - | Generate RGB and depth views by 2D image views |
| Semantic3D | 88.6% | 70.8% | 59.1% | |||
| SnapNet-R [49] | 2017 | Sun RGB-D | 78.1% | - | 38.3% | Improvements to SnapNet |
| GVCNN [44] | 2018 | ModelNet40 | 93.1% | - | - | Grouping module to learn the connections and differences between views |
| SqueezeSeg [50] | 2018 | KITTI | - | - | 29.5% | Data conversion from 3D to 2D using spherical projection |
| SqueezeSegV2 [52] | 2018 | KITTI | - | - | 39.7% | Introducing a context aggregation module to SqueezeSeg |
| PVRNet [45] | 2019 | ModelNet40 | 93.6% | - | - | Consider relationships between points and views, and fuse features |
| RangeNet++ [46] | 2019 | KITTI | - | - | 52.2% | GPU-accelerated postprocessing +RangNet++ |
| SqueezeSegV3 [53] | 2020 | SemanticKITTI | - | - | 55.9% | Proposing the spatially adaptive and context-aware convolution |
| Robert et al. [47] | 2022 | S3DIS | - | - | 74.4% | Introducing an attention scheme for multiview image-based methods |
| ScanNet | - | - | 71.0% | |||
| Method | Year | Dataset | Performance | Contribution | ||
|---|---|---|---|---|---|---|
| OA | mAcc | mIoU | ||||
| VoxNet [55] | 2015 | ModelNet10 | - | 92.0% | - | The first method to process raw point clouds using voxelization |
| ModelNet40 | 85.9% | 83.0% | - | |||
| SEGCloud [58] | 2015 | ShapeNet Part | - | - | 79.4% | Combining 3DFCNN with fine representation using trilinear interpolation and conditional random field |
| ScanNet | 73.0% | - | - | |||
| S3DIS | - | 57.4% | 48.9% | |||
| Semantic3D | 88.1% | 73.1% | 61.3% | |||
| KITTI | - | 49.5% | 36.8% | |||
| OctNet [59] | 2017 | ModelNet10 | 90.0% | - | - | Divide the space into nonuniform voxels using unbalanced octrees |
| ModelNet40 | 83.8% | - | - | |||
| O-CNN [60] | 2017 | ModelNet40 | 90.2% | - | - | Making 3D-CNN feasible for high-resolution voxels |
| ShapeNet Part | - | - | 85.9% | |||
| SPLATNet [56] | 2018 | ShapeNet Part | - | 83.7% | - | Hierarchical and spatially aware feature learning |
| VV-Net [61] | 2019 | ShapeNet Part | - | - | 87.4% | Using the radial basis function to compute the localized continuous representation within each voxel |
| S3DIS | 87.8% | - | 78.2% | |||
| LatticeNet [57] | 2020 | ShapeNet Part | - | 83.9% | - | Proposing a novel slicing operator for computational efficiency |
| ScanNet | - | - | 64.0% | |||
| SemanticKITTI | - | - | 52.9% | |||
| PCSCNet [62] | 2022 | nuScenes | - | - | 72.0% | Reducing the voxel discretization error |
| SemanticKITTI | - | - | 62.7% | |||
| SIEV-Net [63] | 2022 | KITTI | - | - | 62.6% | Effectively reduces loss of height information |
| Method | Year | Dataset | Performance | Contribution | ||
|---|---|---|---|---|---|---|
| OA | mAcc | mIoU | ||||
| PointNet [64] | 2017 | ModelNet40 | 89.2% | 86.2% | - | The first method for processing raw point clouds |
| ShapeNet Part | - | - | 83.7% | |||
| ScanNet | 73.9% | - | 14.7% | |||
| S3DIS | 78.6% | - | 47.7% | |||
| PointNet++ [65] | 2017 | ModelNet40 | 90.7% | - | - | Improvements to PointNet and design of hierarchical network architecture |
| ShapeNet Part | - | - | 85.1% | |||
| ScanNet | 84.5% | - | 34.3% | |||
| S3DIS | 81.0% | - | 54.5% | |||
| SO-Net [68] | 2018 | ModelNet10 | 94.1% | - | - | SOM for modeling the spatial distribution of points |
| ModelNet40 | 90.8% | - | - | |||
| ShapeNet | - | - | 84.6% | |||
| PointSIFT [66] | 2018 | ScanNet | 86.2% | - | - | Integration of multidirectional features using orientation-encoding convolution |
| S3DIS | 88.7% | - | 70.2% | |||
| PointWeb [67] | 2019 | ModelNet40 | 92.3% | 89.4% | - | Proposing an adaptive feature adjustment module for interactive feature exploitation |
| S3DIS | 86.9% | 66.6% | 60.3% | |||
| ShellNet [69] | 2019 | ScanNet | 85.2% | - | - | Proposing an efficient point cloud processing network using statistics from concentric spherical shells |
| S3DIS | 87.1% | 66.8% | ||||
| Semantic3D | 93.2% | - | 69.4% | |||
| RandLA-Net [71] | 2020 | Semantic3D | 94.8% | - | 77.4% | Proposing a lightweight network that exploits large receptive fields and keeps geometric details through LFAM |
| SemanticKITTI | - | - | 53.9% | |||
| PointASNL [70] | 2020 | ModelNet10 | 95.9% | - | - | Proposing a local–nonlocal module with strong noise robustness |
| ModelNet40 | 93.2% | - | - | |||
| ScanNet | - | - | 63.0% | |||
| S3DIS | - | - | 68.7% | |||
| PointMLP [72] | 2022 | ModelNet40 | 94.1% | 91.5% | - | A pure residual MLP network |
| ScanObjectNN | 86.1% | 84.4% | - | |||
| Method | Year | Dataset | Performance | Contribution | ||
|---|---|---|---|---|---|---|
| OA | mAcc | mIoU | ||||
| 3DCNN-DQN-RNN [77] | 2017 | S3DIS | 70.8% | - | - | Combining 3DCNN, DQN, and RNN in a single framework |
| 3P-RNN [74] | 2018 | S3DIS | 86.9% | - | 56.3% | Designing a novel pointwise pyramid pooling module |
| RSNet [75] | 2018 | ShapeNet Part | - | - | 84.9% | Processing point clouds using bidirectional RNN |
| ScanNet | - | 48.4% | 39.4% | |||
| S3DIS | - | 59.4% | 51.9% | |||
| DAR-Net [76] | 2019 | ScanNet | - | 61.6% | 55.8% | The network supports dynamic feature aggregation |
| Method | Year | Dataset | Performance | Contribution | ||
|---|---|---|---|---|---|---|
| OA | mAcc | mIoU | ||||
| SPG [86] | 2018 | S3DIS | 85.5% | 73.0% | 62.1% | Introducing superpoint graph with rich edge features |
| SensatUrban | 85.3% | 44.4% | 37.3% | |||
| Semantic3D (reduced-8) | 94.0% | - | 73.2% | |||
| Semantic3D | 92.9% | - | 76.2% | |||
| DGCN [79] | 2019 | ModelNet40 | 92.2% | 90.2% | - | Proposing the EdgeConv operator |
| ShapeNet Part | - | - | 85.2% | |||
| S3DIS | 84.1% | - | 56.1% | |||
| SPH3D-GCN [80] | 2020 | ModelNet40 | 85.5% | 73.0% | 62.1% | Proposing the SPH3D operator |
| S3DIS | 86.4% | 66.5% | 58.0% | |||
| PointNGCNN [81] | 2020 | ModelNet40 | 92.8% | - | - | Using Chebyshev polynomials as the neighborhood graph filter to extract neighborhood geometric features |
| ShapeNet Part | - | - | 85.6% | |||
| ScanNet | 84.9% | - | - | |||
| S3DIS | 87.3% | - | - | |||
| PointVGG [82] | 2021 | ModelNet40 | 93.6% | 91.0% | - | Proposing point convolution and point pooling operations |
| ShapeNet Part | - | - | 86.1% | |||
| AF-GCN [83] | 2023 | ShapeNet Part | - | - | 85.3% | Combining graph convolution and self-attention mechanisms |
| ScanNet | - | - | 71.8% | |||
| S3DIS | - | - | 78.4% | |||
| 3DGraphSeg [87] | 2023 | Semantic3D | 94.7% | - | 76.8% | Proposing a local embedding super-point graph to alleviate gradient vanishing or exploding |
| Method | Year | Dataset | Performance | Contribution | ||
|---|---|---|---|---|---|---|
| OA | mAcc | mIoU | ||||
| PAT [94] | 2019 | ModelNet40 | 91.7% | - | - | Pioneering Transformer-based processing of point clouds |
| S3DIS | - | - | 64.28% | |||
| PCT [91] | 2021 | ModelNet40 | 93.2% | - | - | Proposing a coordinate-based embedding module and an offset attention module |
| S3DIS | - | 67.7% | 61.33% | |||
| Point Transformer [92] (Zhao et al.) | 2021 | ModelNet40 | 93.7% | 90.6% | - | Facilitating interactions between local feature vectors through residual transformer blocks |
| S3DIS | 90.2% | 81.9% | 73.5% | |||
| ShapeNet Part | - | - | 86.6% | |||
| Point Transformer [93] (Engel et al.) | 2021 | ModelNet40 | 92.8% | - | - | Proposing a multihead attention network |
| ShapeNet | - | - | 85.9% | |||
| MLMST [95] | 2021 | ModelNet10 | 95.5% | - | - | Proposing a multilevel multiscale Transformer |
| ModelNet40 | 92.9% | - | - | |||
| ShapeNet Part | - | - | 86.4% | |||
| S3DIS | - | - | 62.9% | |||
| DTNet [96] | 2021 | ModelNet40 | 92.9% | 90.4% | - | Proposing a novel dual-point cloud Transformer architecture |
| ShapeNet Part | - | - | 85.6% | |||
| Stratified Transformer [97] | 2022 | ShapeNet Part | - | - | 86.6% | Adaptive contextual relative position encoding and point embedding effective learning of long-range contexts |
| ScanNet | - | - | 73.7% | |||
| SAT [98] | 2023 | ScanNet | - | - | 74.2% | Proposing a multigranular attention scheme and a reattention module |
| S3DIS | - | 78.8% | 72.6% | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Wu, Y.; Jin, W.; Meng, X. Deep-Learning-Based Point Cloud Semantic Segmentation: A Survey. Electronics 2023, 12, 3642. https://doi.org/10.3390/electronics12173642
Zhang R, Wu Y, Jin W, Meng X. Deep-Learning-Based Point Cloud Semantic Segmentation: A Survey. Electronics. 2023; 12(17):3642. https://doi.org/10.3390/electronics12173642
Chicago/Turabian StyleZhang, Rui, Yichao Wu, Wei Jin, and Xiaoman Meng. 2023. "Deep-Learning-Based Point Cloud Semantic Segmentation: A Survey" Electronics 12, no. 17: 3642. https://doi.org/10.3390/electronics12173642
APA StyleZhang, R., Wu, Y., Jin, W., & Meng, X. (2023). Deep-Learning-Based Point Cloud Semantic Segmentation: A Survey. Electronics, 12(17), 3642. https://doi.org/10.3390/electronics12173642