


FPGA-Based Optimization of Industrial Numerical Machine Tool Servo Drives


Abstract
:1. Introduction
2. Specificity of Control Systems for Industrial Machine Tools
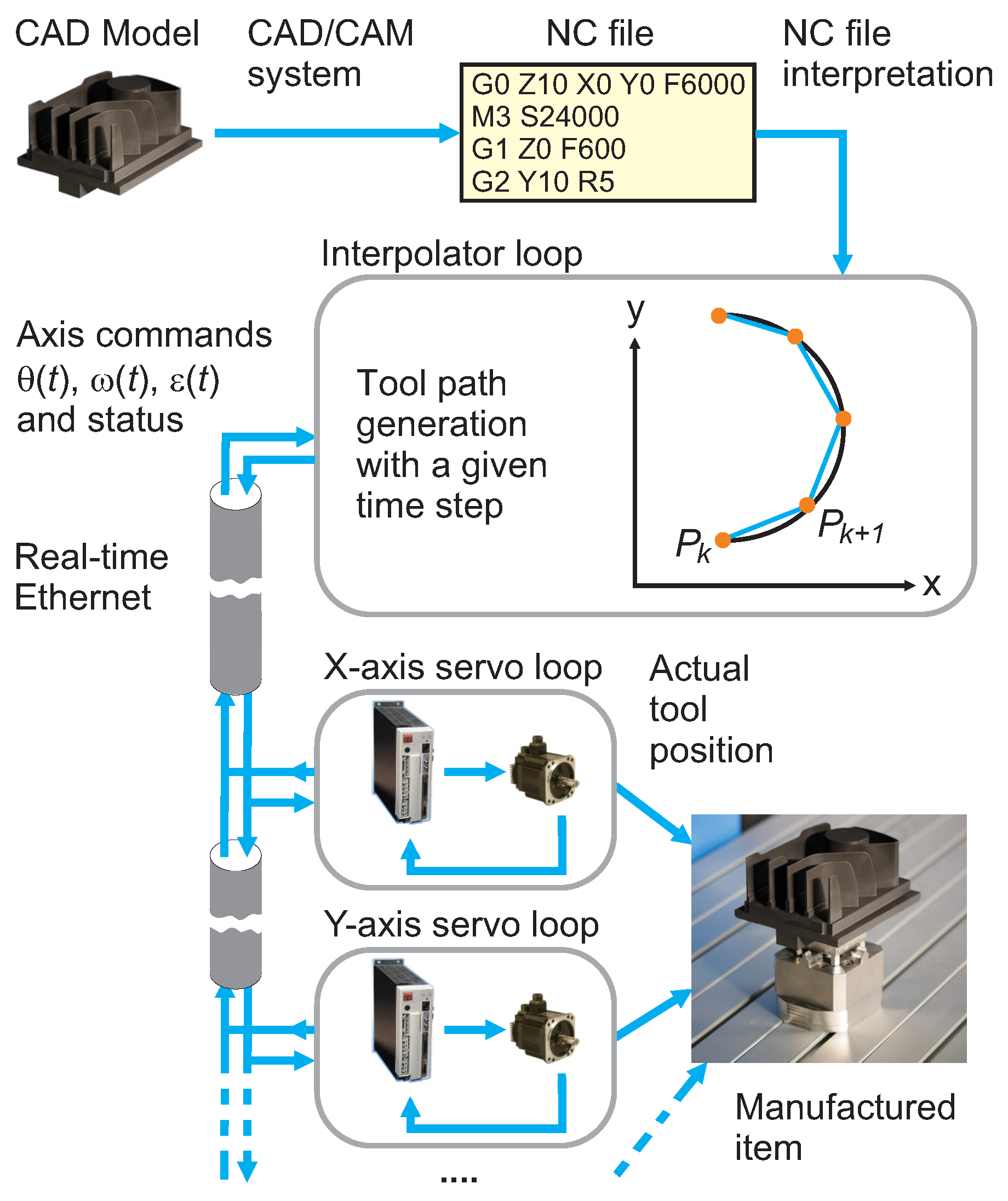
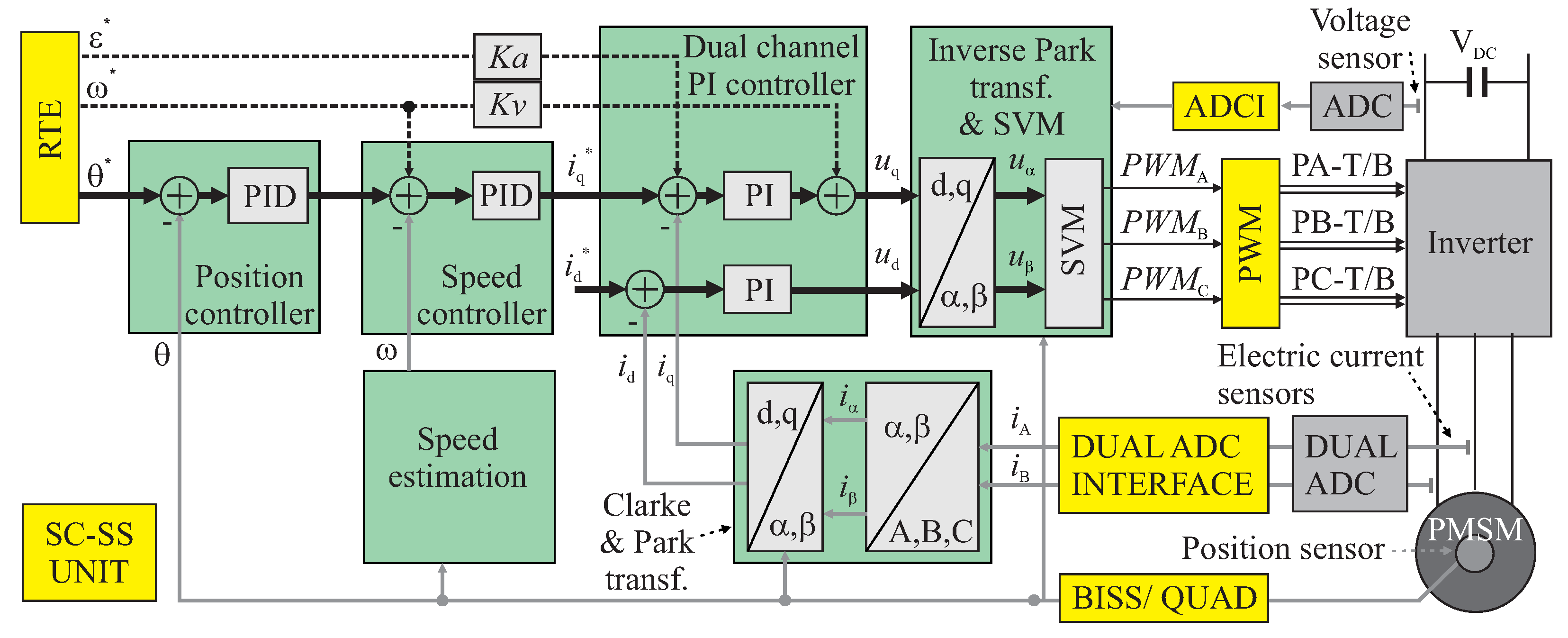
2.1. The Structure of a Distributed Control System
2.2. Real-Time Ethernet
3. Experimental Research
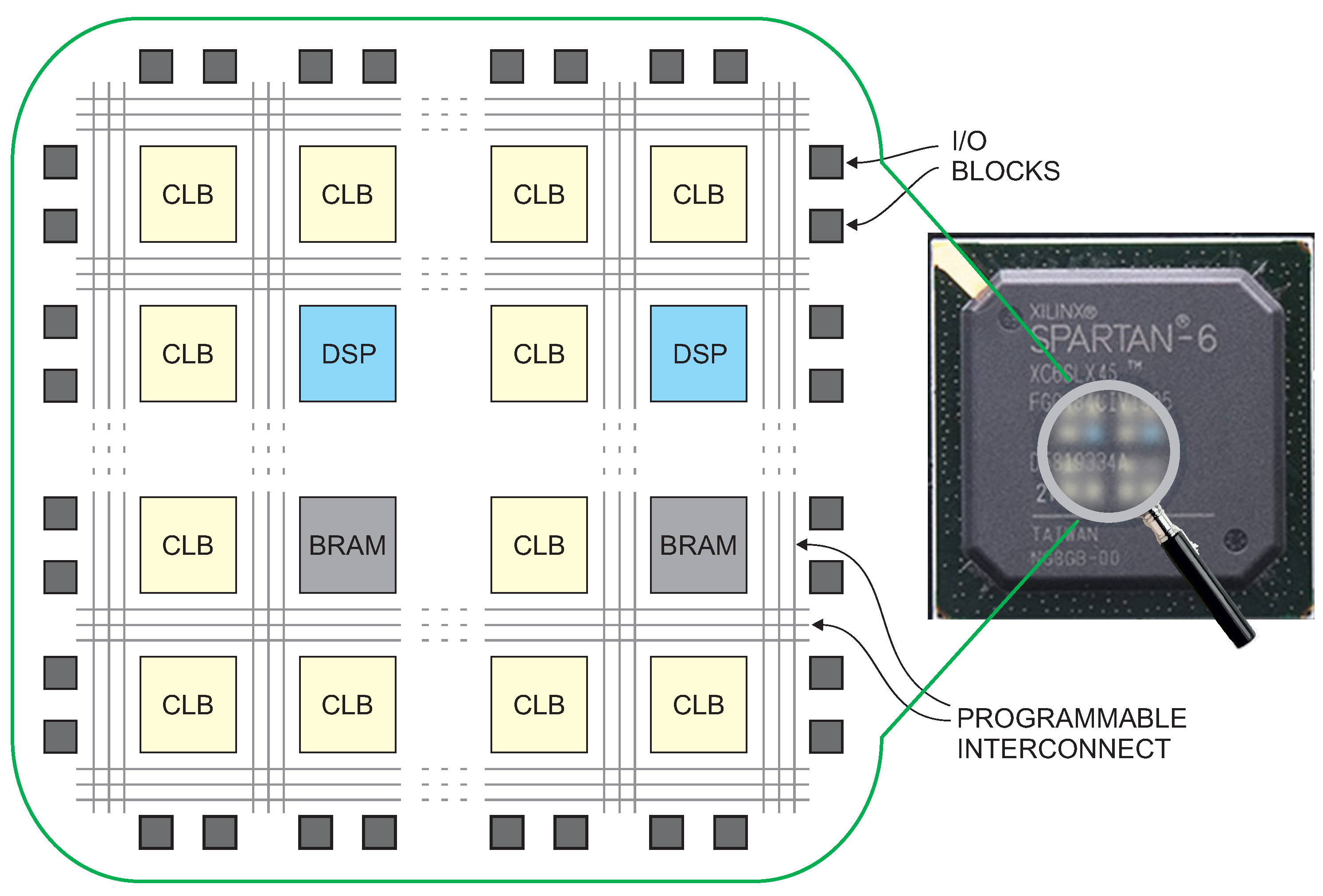
3.1. Architecture and Fundamental Properties of FPGA Devices
3.2. Properties and Architecture of an Electric Servo Drive Controller
3.3. Methods of Control Algorithm Implementation on FPGA
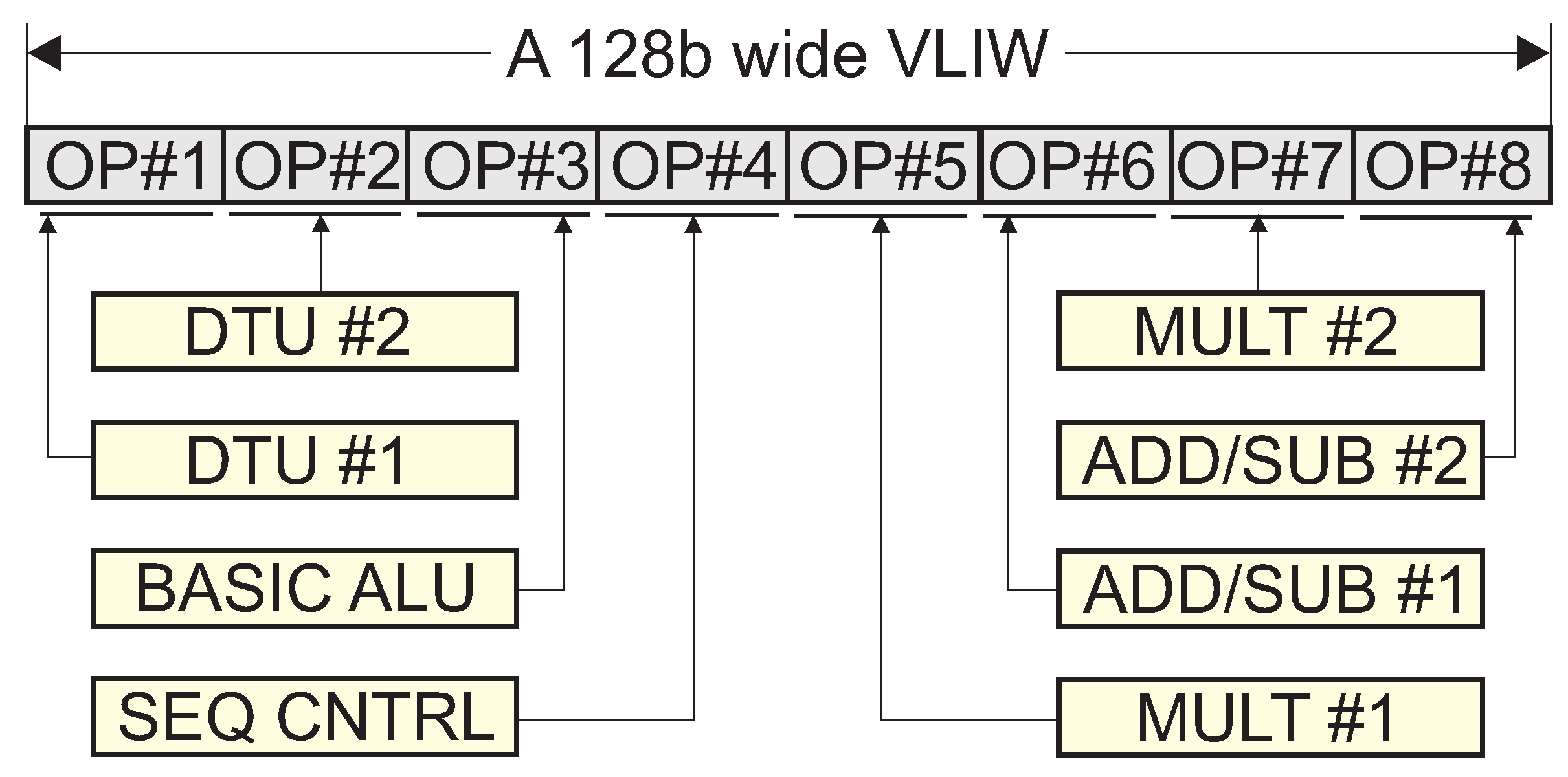
3.4. The Applied Soft-Core Superscalar Architecture
- —is a dedicated instruction for hardware acceleration of the LTSE algorithm. It implements the initialization of the n-th order LTSE with the division of the approximation domain into segments. The coefficients of the polynomials used in the approximation are listed in the two-dimensional array indicated as the last argument of the instruction.
- M1_A —this is the operation of addressing the first of the two memory blocks to prepare for the read operation in the next clock cycle. The symbol Addr denotes the address of the variable placed in the M1 memory block. The corresponding instruction for the second memory block is labeled M2_A.
- M1_RI —is the actual operation of reading from memory to the general register with the index and simultaneous addressing of the next memory location by address increment. The corresponding instruction for the second memory block is M2_RI.
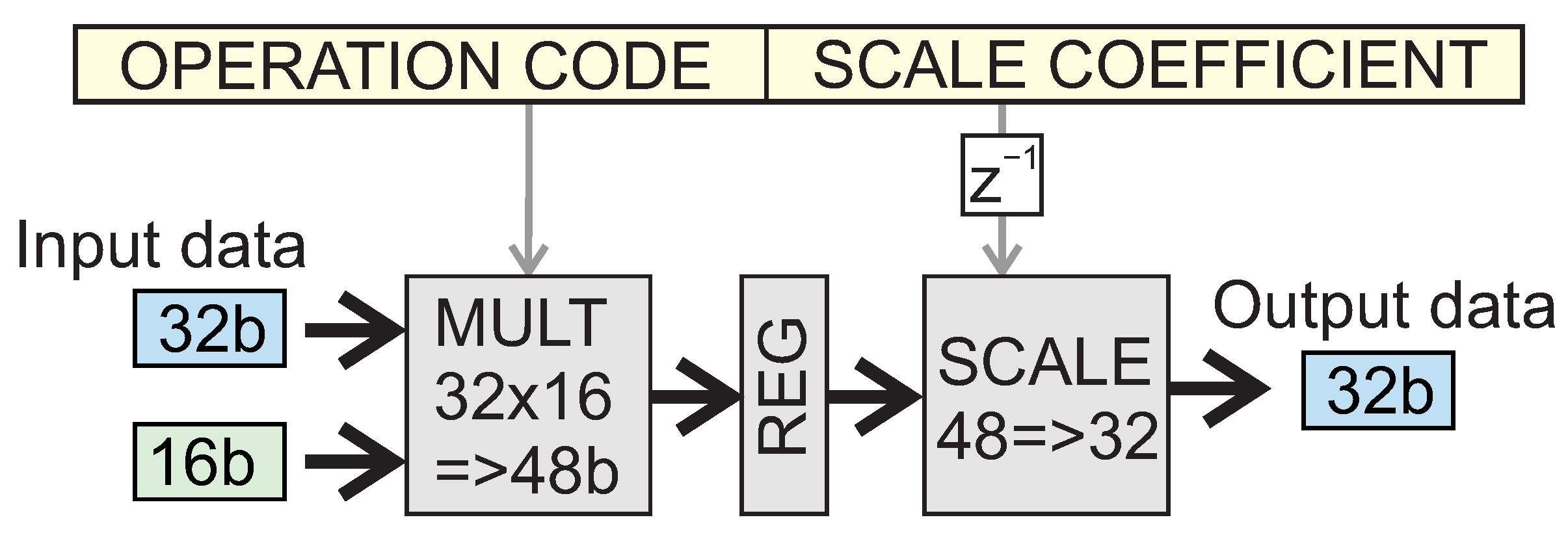
- —fixed-point multiplication with scaling, where: are the indexes of the universal registers identifying the first and second arguments and the result register, while are the i parameters defining the format of the processed fixed-point numbers, following the Fxi_n notation [3]. In this notation, the ‘i’ parameter describes the position of the binary point counting to the right, starting from the left side of the binary word. In the research described in this paper, 32-bit words were used to represent the values of processed signals. In this case, the value of n was 32. However, 16-bit words were used to represent constant parameters, so, in that case, the value of n was 16.This fixed-point multiplication is performed by the FX-MULT unit shown in Figure 8. The first part of the operation is integer multiplication, which results in a 48-bit number written to the internal register (REG) of the FX-MULT unit. To obtain the expected output format, this result will be shifted to the right by the number of positions expressed by Formula (1). This integer value is determined during the code compilation stage and placed in the SCALE COEFFICIENT field of the binary instruction intended to be executed by the FX-MULT unit.
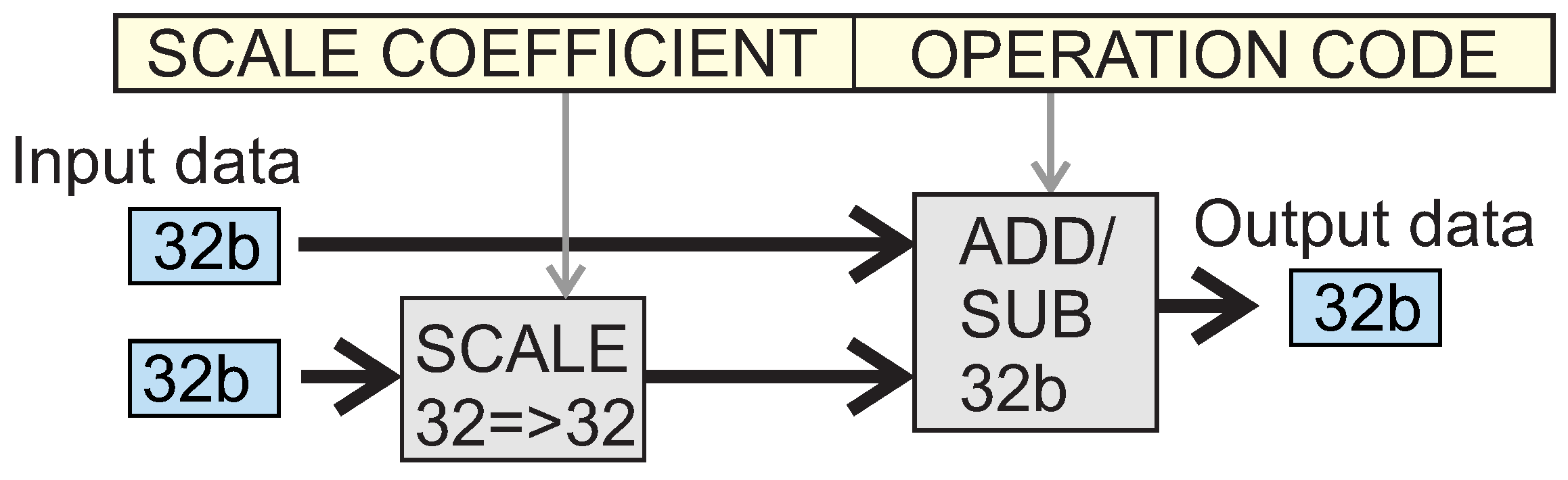
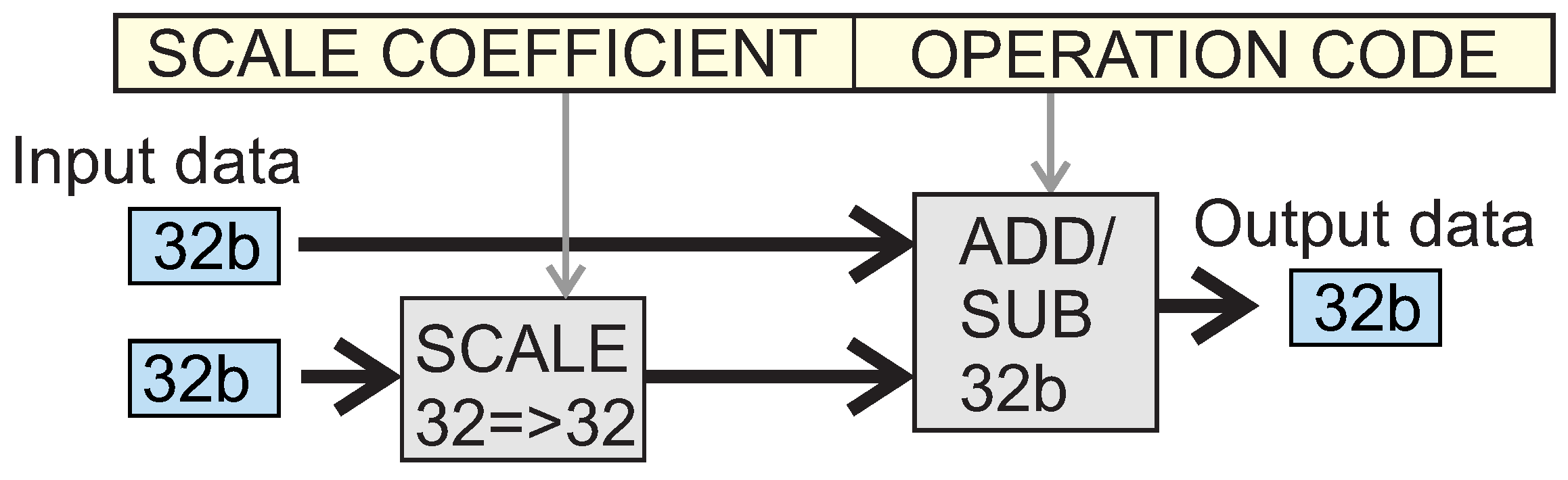
- —these are integer addition operations where the second argument is automatically scaled to the format of the first argument. The subtraction operation looks similar. This operation is shown in Figure 9 and has the predetermined requirement that . In this case, the “SCALE COEFFICIENT” field contained in the code of the instruction describes the binary left shift value. This value is determined by Formula (2) at the code compilation stage.
3.5. Algorithm Implementation Details
| Listing 1. Fragment of C-code for LTSE algorithm implementation on a DSP unit. | |
| 1 | #define POLY_ORDER 5 |
| 2 | float LTSE_sin ( float x ) |
| 3 | { |
| 4 | unsigned int segIndex ; |
| 5 | /* Convert to integer format and use the three |
| 6 | most significant bits as the segment index . */ |
| 7 | segIndex = x * ONE_OVER_TWO_PI_FX1_16 ; |
| 8 | segIndex = ( segIndex >> 13) & 0x0007u ; |
| 9 | /* The Horner ’ s scheme . */ |
| 10 | float sum = LTSE_Coeff [ segIndex ] [ 0 ] ; // y0 |
| 11 | x −= LTSE_Coeff [ segIndex ] [ 0 ] ; |
| 12 | int i ; |
| 13 | for ( i=POLY_ORDER; i >=1; i −−) |
| 14 | { |
| 15 | sum = sum ∗ x + LTSE_Coeff [ segIndex ] [ i ] ; |
| 16 | } |
| 17 | return sum; |
| 18 | } |
| Listing 2. Fragment of FXU code for LTSE algorithm implementation on SC-SS unit. | |
| 1 | PolyIni t 5 , 3 , LTSE_Coeff ; M1_A x ; |
| 2 | M1_RI R0 ; // Load the argument and calculate the segment index . |
| 3 | M2_RI R6 ; // Load the value of x0 . |
| 4 | R0 −= R6 ; // Calculate the value of z . |
| 5 | R3 = R0∗R0 ( 2 , 2 , 2 ) ; M2_RI R7 ; // Calculate the value of z^2 and load the value of y0 . |
| 6 | R1 = R0 ; R2 = R0 ; M2_RI R8 ; // Load the value of C1 . |
| 7 | R4 = R1∗R8 ( 2 , 2 , 2 ) ; R1 = R1 ∗ R3 ( 2 , 2 , 2 ) ; M2_RI R8 ; // Use C1 , load C2 |
| 8 | R5 = R2∗R8 ( 2 , 2 , 2 ) ; R2 = R2 ∗ R3 ( 2 , 2 , 2 ) ; M2_RI R8 ; // Use C2 , load C3 |
| 9 | R7 += R4 ( 2 , 2 ) ; R4 = R1∗R8 ( 2 , 2 , 2 ) ; R1 = R1∗R0 ( 0 , 2 , 2 ) ; M2_RI R8 ; // Use C3 , load C4 |
| 10 | R7 += R5 ( 2 , 2 ) ; R5 = R2∗R8 ( 2 , 0 , 2 ) ; R2 = R2∗R0( −2 , 0 , 2 ) ; M2_RI R8 ; // Use C4 , load C5 |
| 11 | R7 += R4 ( 2 , 2 ) ; R4 = R1∗R8( 2 , −2 , 2 ) ; // Use C5 |
| 12 | R7 += R5 ( 2 , 2 ) ; |
| 13 | R7 += R4 ( 2 , 2 ) ; // Result is in register R7 . |
3.6. Analysis of the Obtained Results
4. Conclusions
- Description of the architecture, specific features, and requirements imposed on control systems of modern industrial CNC machines.
- Identifying areas where the control system can be developed to improve machining precision, introduce new functionalities, and enhance diagnostic and service operations.
- Diagnosis of the limitations of controllers typically used in servo drives based on microcontrollers or signal processors collaborating with application-specific integrated circuits (ASICs) regarding the feasibility of implementing the proposed new solutions.
- Designing and implementing a solution based on FPGA technology to eliminate the above-mentioned limitations. This solution involves proper configuration and utilization of the SC-SS unit for hardware–software processing of the servo drive control algorithm, as well as integrating the SC-SS unit and the RTE module within a common FPGA structure.
- Designing and conducting comprehensive experimental studies on three distinct digital platforms. Two of the evaluated platforms are integrated into the control systems of existing CNC machines available in the commercial market. The tests conducted on these platforms exhibit high reliability due to their execution under real operational conditions of the machine tool control system.
- Conducting a rigorous analysis of the obtained results, considering the achieved processing efficiency of the controllers, real-time communication interface delays, the amount of consumed electrical power, the complexity of the electronic printed circuit board, and the cost of digital components.
Funding
Data Availability Statement
Conflicts of Interest
References
- Przybył, A. Hard real-time communication solution for mechatronic systems. Robot. Comput.-Integr. Manuf. 2018, 49, 309–316. [Google Scholar] [CrossRef]
- Kimla, P. The Advantage of Fiber Lasers. Available online: https://kimla.pl/en/technical/the-advantage-of-fiber-lasers (accessed on 7 April 2021).
- Przybył, A. Fixed-Point Arithmetic Unit with a Scaling Mechanism for FPGA-Based Embedded Systems. Electronics 2021, 10, 1164. [Google Scholar] [CrossRef]
- Rutkowski, L.; Przybyl, A.; Cpalka, K. Novel Online Speed Profile Generation for Industrial Machine Tool Based on Flexible Neuro-Fuzzy Approximation. IEEE Trans. Ind. Electron. 2012, 59, 1238–1247. [Google Scholar] [CrossRef]
- Beckhoff. Hardware Data Sheet. EtherCAT Slave Controller. 2017. Available online: https://www.beckhoff.com/en-en/products/i-o/ethercat-development-products/elxxxx-etxxxx-fbxxxx-hardware/et1100.html (accessed on 7 April 2023).
- Schumacher, M.; Jasperneite, J.; Weber, K. A new Approach for Increasing the Performance of the Industrial Ethernet System PROFINET. In Proceedings of the 7th IEEE International Workshop on Factory Communication Systems (WFCS 2008), Dresden, Germany, 21–23 May 2008; pp. 159–167. [Google Scholar]
- Ogawa, T. Reduce BOM Costs and Development Efforts for EtherCAT and Other Industrial Ethernet-Compatible Servo Systems. 2023. Available online: https://www.renesas.com/us/en/document/whp/reduce-bom-costs-and-development-efforts-ethercat-and-other-industrial-ethernet-compatible-servo (accessed on 7 April 2023).
- Maneesh, S. EtherCAT® on Sitara™ Processors. 2020. Available online: https://www.ti.com/lit/pdf/spry187 (accessed on 7 April 2023).
- Unpatchable Cyber-Flaws Found on over 120 Siemens PLCs. Available online: https://drivesncontrols.com/news/fullstory.php/aid/7224/Unpatchable_cyber-flaws_found_on_over_120_Siemens_PLCs.html (accessed on 7 April 2023).
- Heinz, A. Obsolescence Risks Persist! Available online: https://www.elektroniknet.de/international/obsolescence-risks-persist.204469.html (accessed on 7 April 2023).
- Chiang, J.; Zammattio, S. Five Ways to Build Flexibility into Industrial Applications with FPGAs, White Paper WP-01154-2.2. 2014. Available online: https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/wp/wp-01154-flexible-industrial.pdf (accessed on 7 April 2023).
- Tao, F.; Tang, Y.; Zou, X.; Qi, Q. A field programmable gate array implemented fibre channel switch for big data communication towards smart manufacturing. Robot. Comput.-Integr. Manuf. 2019, 57, 166–181. [Google Scholar] [CrossRef]
- What Is Software Defined Everything—Part 1: Definition of SDx. 2016. Available online: https://www.sdxcentral.com/cloud/definitions/software-defined-everything-sdx-part-1-definition/ (accessed on 7 April 2023).
- Haddad, S. Why a Software-Defined Approach Is the Future for Embedded and IoT. 2023. Available online: https://www.embedded.com/why-a-software-defined-approach-is-the-future-for-embedded-and-iot/ (accessed on 7 April 2023).
- High-Speed, Low-Cost Telemetry Access from Space (MFS-TOPS-62). Programmable, Lightweight, and Adaptable Software-Defined Radio. Available online: https://technology.nasa.gov/patent/MFS-TOPS-62 (accessed on 7 April 2023).
- Diverse Architectures for Unmatched Innovation. Available online: https://www.intel.com/content/www/us/en/silicon-innovations/6-pillars/architecture.html (accessed on 7 April 2023).
- Xilinx. Xilinx Spartan-6 Family Overview, DS160. 2011. Available online: https://docs.xilinx.com/v/u/en-US/ds160 (accessed on 7 April 2023).
- AMD Adaptive SoCs. Available online: https://www.xilinx.com/products/silicon-devices/soc.html (accessed on 7 April 2023).
- Sankar, D.; Syamala, L.; Chembathu Ayyappan, B.; Kallarackal, M. FPGA-Based Cost-Effective and Resource Optimized Solution of Predictive Direct Current Control for Power Converters. Energies 2021, 14, 7669. [Google Scholar] [CrossRef]
- Scrugli, M.A.; Meloni, P.; Sau, C.; Raffo, L. Runtime Adaptive IoMT Node on Multi-Core Processor Platform. Electronics 2021, 10, 2572. [Google Scholar] [CrossRef]
- Przybył, A.; Szczypta, J. Method of Evolutionary Designing of FPGA-based Controllers. Przegląd Elektrotechniczny 2016, 92, 174–179. [Google Scholar] [CrossRef]
- Nowak, M.; Popenda, A. Influence of neural network configuration on PMSM motor angular velocity estimation. Przegląd Elektrotechniczny 2023, 99, 238–241. (In Polish) [Google Scholar] [CrossRef]
- Dziwiński, P.; Avedyan, E.D. A New Method of the Intelligent Modeling of the Nonlinear Dynamic Objects with Fuzzy Detection of the Operating Points. In Artificial Intelligence and Soft Computing; Rutkowski, L., Korytkowski, M., Scherer, R., Tadeusiewicz, R., Zadeh, L.A., Zurada, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 293–305. [Google Scholar] [CrossRef]
- Dziwinski, P.; Przybyl, A.; Trippner, P.; Paszkowski, J.; Hayashi, Y. Hardware Implementation of a Takagi-Sugeno Neuro-Fuzzy System Optimized by a Population Algorithm. J. Artif. Intell. Soft Comput. Res. 2021, 11, 243–266. [Google Scholar] [CrossRef]
- BiSS Interface Concept. 2021. Available online: https://biss-interface.com/download/biss-c-interface-flyer/ (accessed on 7 April 2023).
- Przybył, A.; Smoląg, J.; Kimla, P. Distributed Control System Based on Real Time Ethernet for Computer Numerical Controlled Machine Tool. Przegląd Elektrotechniczny 2010, 86, 342–346. (In Polish) [Google Scholar]
- Herasymenko, P. Software implementation of pulse-density modulation control for H-bridge series-resonant converters. Przegląd Elektrotechniczny 2023, 99, 116–119. [Google Scholar] [CrossRef]
- Hajduk, Z.; Trybus, B.; Sadolewski, J. Architecture of FPGA Embedded Multiprocessor Programmable Controller. IEEE Trans. Ind. Electron. 2015, 62, 2952–2961. [Google Scholar] [CrossRef]
- Fisher, J.A. Very Long Instruction Word Architectures and the ELI-512. In Proceedings of the 10th Annual International Symposium on Computer Architecture, ISCA ’83, Stockholm, Sweden, 13–17 June 1983; Association for Computing Machinery: New York, NY, USA, 1983; pp. 140–150. [Google Scholar] [CrossRef]
- Nurmi, J. Processor Design. System-on-Chip Computing for ASICs and FPGAs; Springer: Berlin/Heidelberg, Germany, 2007; Book Chapters 3 and 7. [Google Scholar] [CrossRef]
- Jenner, A. Reenigne Blog, Stuff I Think about, “Very Low-Level Programming”. Available online: https://www.reenigne.org/blog/very-low-level-programming/ (accessed on 12 April 2021).
- STMicroelectronics. RM0090 Reference Manual, Rev. 19. 2021. Available online: https://www.st.com/resource/en/reference_manual/rm0090-stm32f405415-stm32f407417-stm32f427437-and-stm32f429439-advanced-armbased-32bit-mcus-stmicroelectronics.pdf (accessed on 7 April 2023).
- Analog Devices, Inc. One Technology Way. In SHARC Processor Programming Reference, Rev. 2.4; Analog Devices, Inc.: Wilmington, MA, USA, 2013. [Google Scholar]
- Micrel. KSZ8842-16/32 2-Port Ethernet Switch with Non-PCI Interface. Data Sheet. 2007. Available online: https://www.microchip.com/content/dam/mchp/documents/OTH/ProductDocuments/DataSheets/KS8842M.pdf (accessed on 7 April 2023).
- Hennessy, J.; Jouppi, N.; Przybylski, S.; Rowen, C.; Gross, T.; Baskett, F.; Gill, J. MIPS: A Microprocessor Architecture. SIGMICRO Newsl. 1982, 13, 17–22. [Google Scholar] [CrossRef]
- Istoan, M.; Pasca, B. Fixed-Point Implementations of the Reciprocal, Square Root, and Reciprocal Square Root Functions. 2015. Available online: https://hal.archives-ouvertes.fr/hal-01229538/document (accessed on 12 April 2021).
- Sandoval-Hernandez, M.; Velez-Lopez, G.; Vazquez-Leal, H.; Filobello-Nino, U.; Morales-Alarcon, G.; De-Leo-Baquero, E.; Bielma-Perez, A.; Sampieri-Gonzalez, C.; Perez-Jacome Friscione, J.; Contreras-Hernandez, A.; et al. Basic Implementation of Fixed-Point Arithmetic in Numerical Analysis. Int. J. Eng. Res. Technol. 2023, 12, 313–318. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FPGA Part Number | DSP Slices | CLB Slices | BRAMs | Approx. Price [USD] |
|---|---|---|---|---|
| XC6SLX9 | 16 | 1430 | 32 | 30 |
| XC6SLX45 | 58 | 6822 | 116 | 110 |
| XC6SLX150 | 180 | 23,038 | 268 | 400 |
| XC6VLX240T | 768 | 37,680 | 832 | 4k |
| XC6VSX475T | 2016 | 74,400 | 2128 | 20k |
| Selected Parameters | MCU | DSP | FPGA |
|---|---|---|---|
| The amount of consumed electrical power [W] | |||
| Approximate cost of the key digital components [USD] | 60 | 91 | 120 |
| Servo Code Functional Block | MCU | DSP | FPGA (SC-SS) |
|---|---|---|---|
| Sine and cosine | 1.18 μs | 0.23 μs | 0.31 μs |
| Clarke and Park | 0.33 μs | 0.09 μs | 0.18 μs |
| Inv. Park and SVM | 0.84 μs | 0.21 μs | 0.61 μs |
| Dual-channel PI | 0.98 μs | 0.30 μs | 0.48 μs |
| Data transfer delay 28 B/256 B | 1.40 μs/12.80 μs | 0.77 μs/7.04 μs | 0.10 μs/0.81 μs |
| The sum of the above 28 B/256 B | 4.73 μs/16.13 μs | 1.60 μs/7.87 μs | 1.68 μs/2.39 μs |
| Features | MCU/DSP + ASICs | FPGA |
|---|---|---|
| Processing performance (total) | medium to high | high (SC-SS) to very high (FHD) |
| Design comfort | high | limited (SC-SS) low (FHD) |
| Compactness of the device | no | yes |
| Development potential | limited | large |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Przybył, A. FPGA-Based Optimization of Industrial Numerical Machine Tool Servo Drives. Electronics 2023, 12, 3585. https://doi.org/10.3390/electronics12173585
Przybył A. FPGA-Based Optimization of Industrial Numerical Machine Tool Servo Drives. Electronics. 2023; 12(17):3585. https://doi.org/10.3390/electronics12173585
Chicago/Turabian StylePrzybył, Andrzej. 2023. "FPGA-Based Optimization of Industrial Numerical Machine Tool Servo Drives" Electronics 12, no. 17: 3585. https://doi.org/10.3390/electronics12173585
APA StylePrzybył, A. (2023). FPGA-Based Optimization of Industrial Numerical Machine Tool Servo Drives. Electronics, 12(17), 3585. https://doi.org/10.3390/electronics12173585