
DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor
Abstract
1. Introduction
- (a)
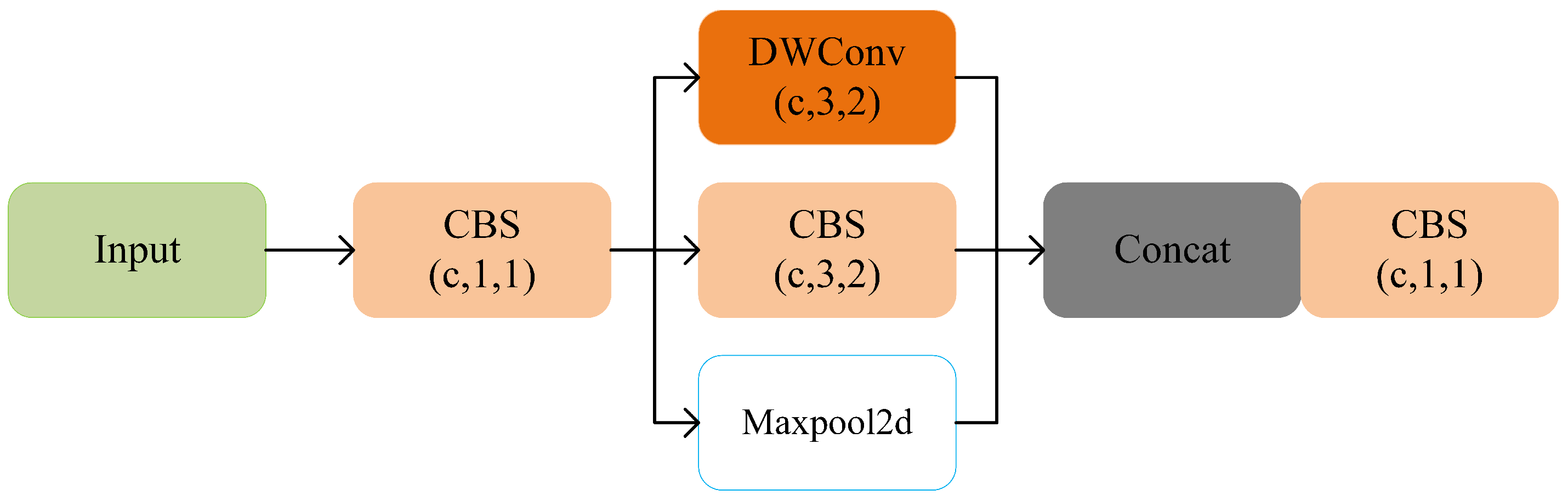
- The MDC module is proposed to perform downsampling operations (the method of concatenating depth-wise separable convolutions, maxpool, and convolutions of dimension size 3 × 3 with stride = 2 is presented). It can supplement the information lost by each module in the downsampling process, making the contextual information saved in the feature extraction process more complete.
- (b)
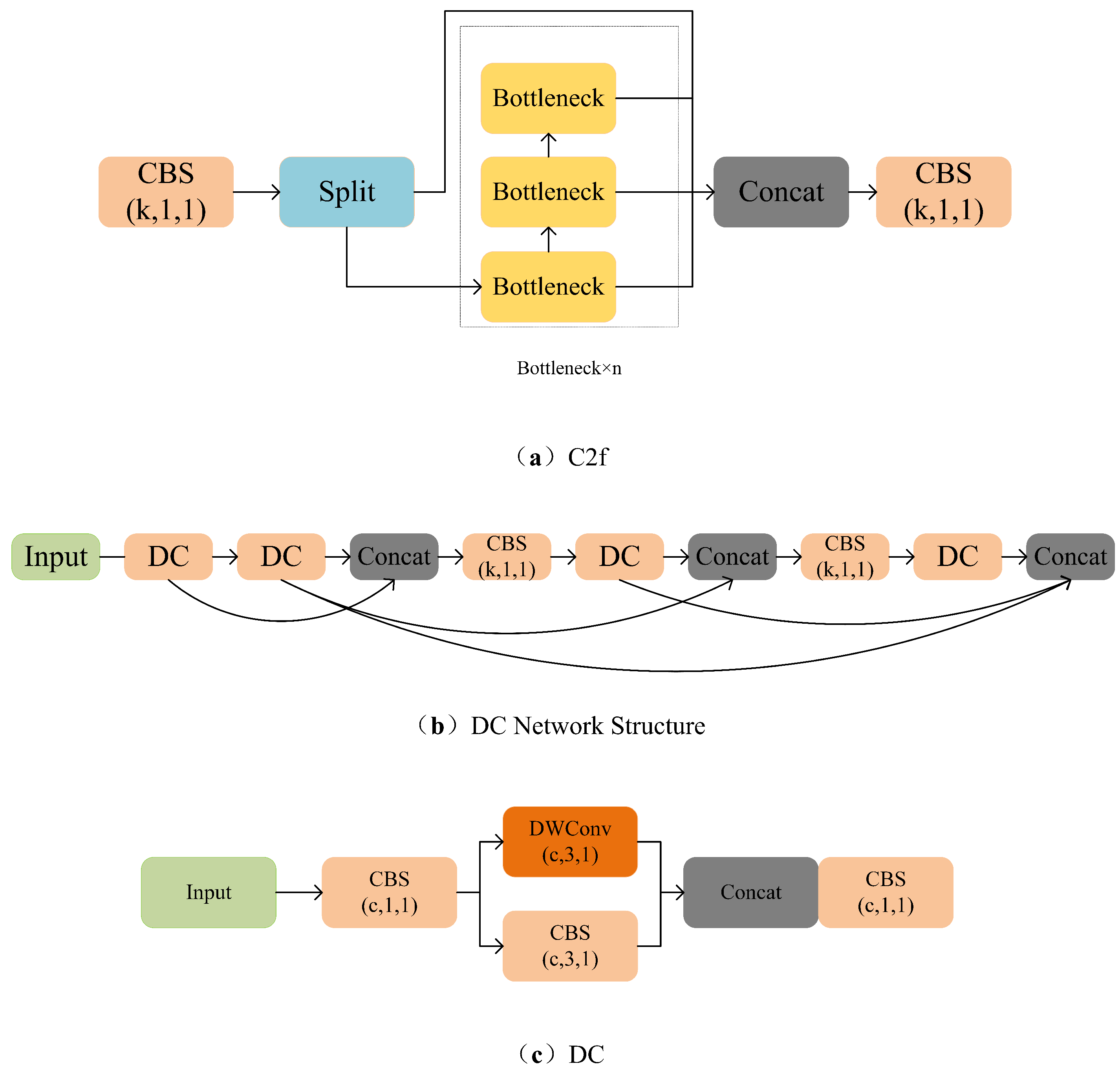
- The C2f module in front of the detector in YOLOv8 is replaced by the DC module proposed in this paper (the network structure formed by stacking depth-wise separable convolution and ordinary convolution). A new network structure is formed by stacking DC modules and fusing each small module continuously. It increases the depth of the whole structure, achieves higher resolution without significant computational cost, and is able to capture more contextual information.
- (c)
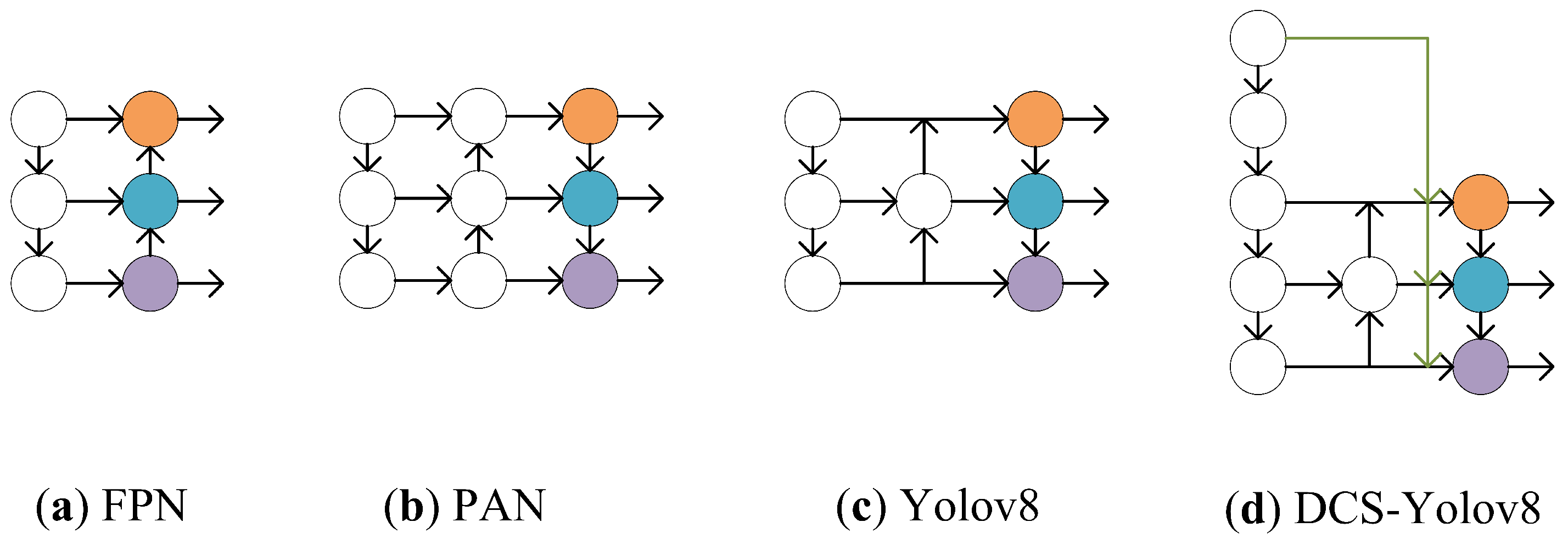
- The feature fusion method of YOLOv8 is improved, which could perfectly combine shallow information and deep information, make the information retained during network feature extraction more comprehensive, and solves the problem of missed detection due to inaccurate positioning.
2. Related Work
2.1. The Reason for Choosing YOLOv8 as the Baseline
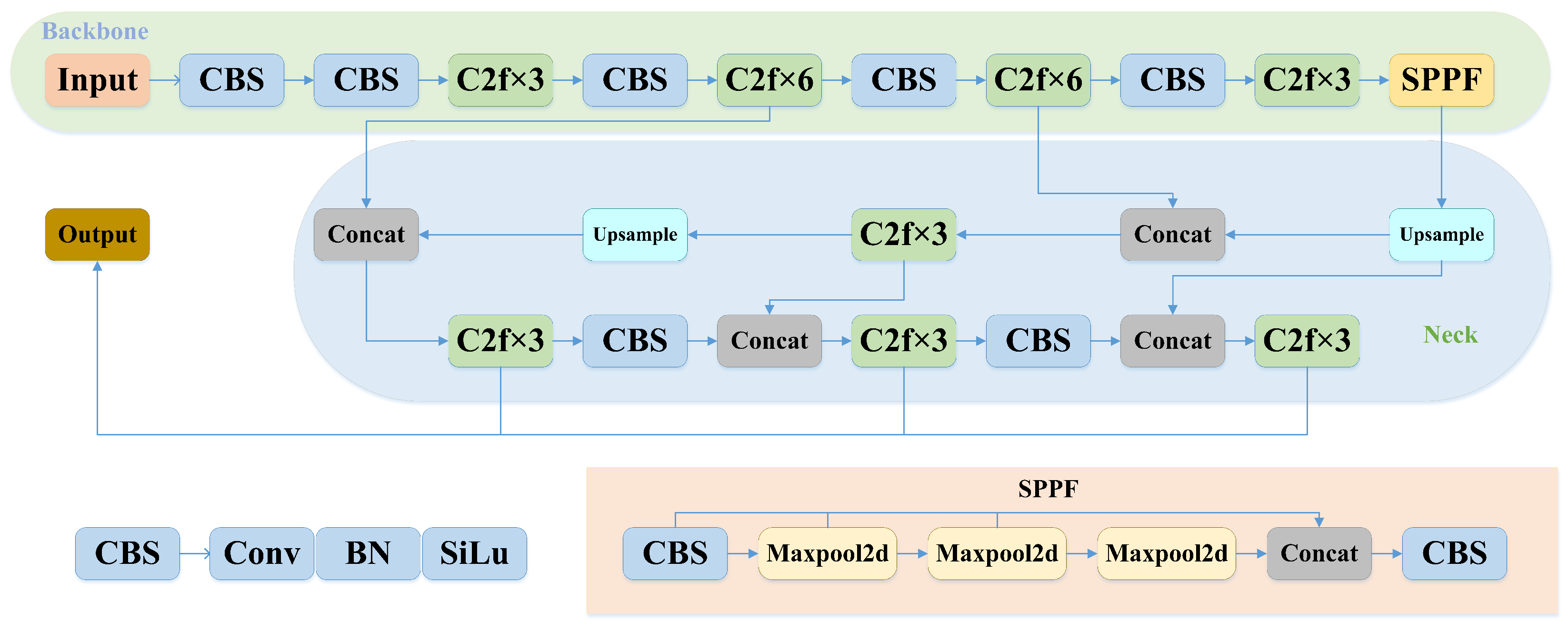
2.2. The Network Structure of YOLOv8
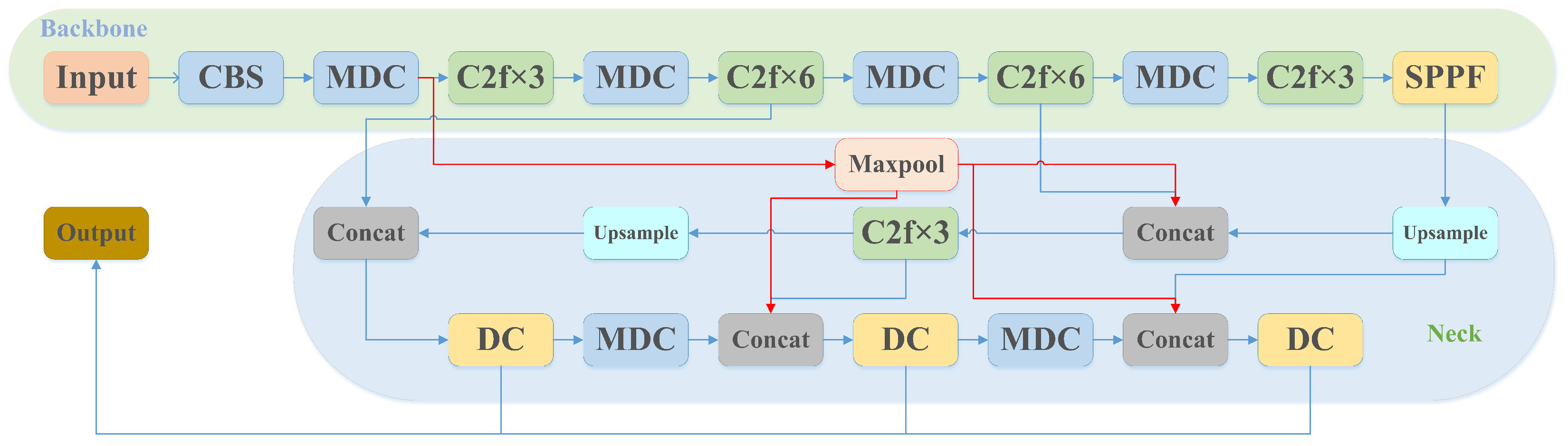
3. The Proposed DC-YOLOv8 Algorithm
3.1. A Modified Efficient Downsampling Method
3.2. Improved Feature Fusion Method
3.3. The Proposed Network Structure
4. Experiments
4.1. Experimental Platform
4.2. Valuation Index
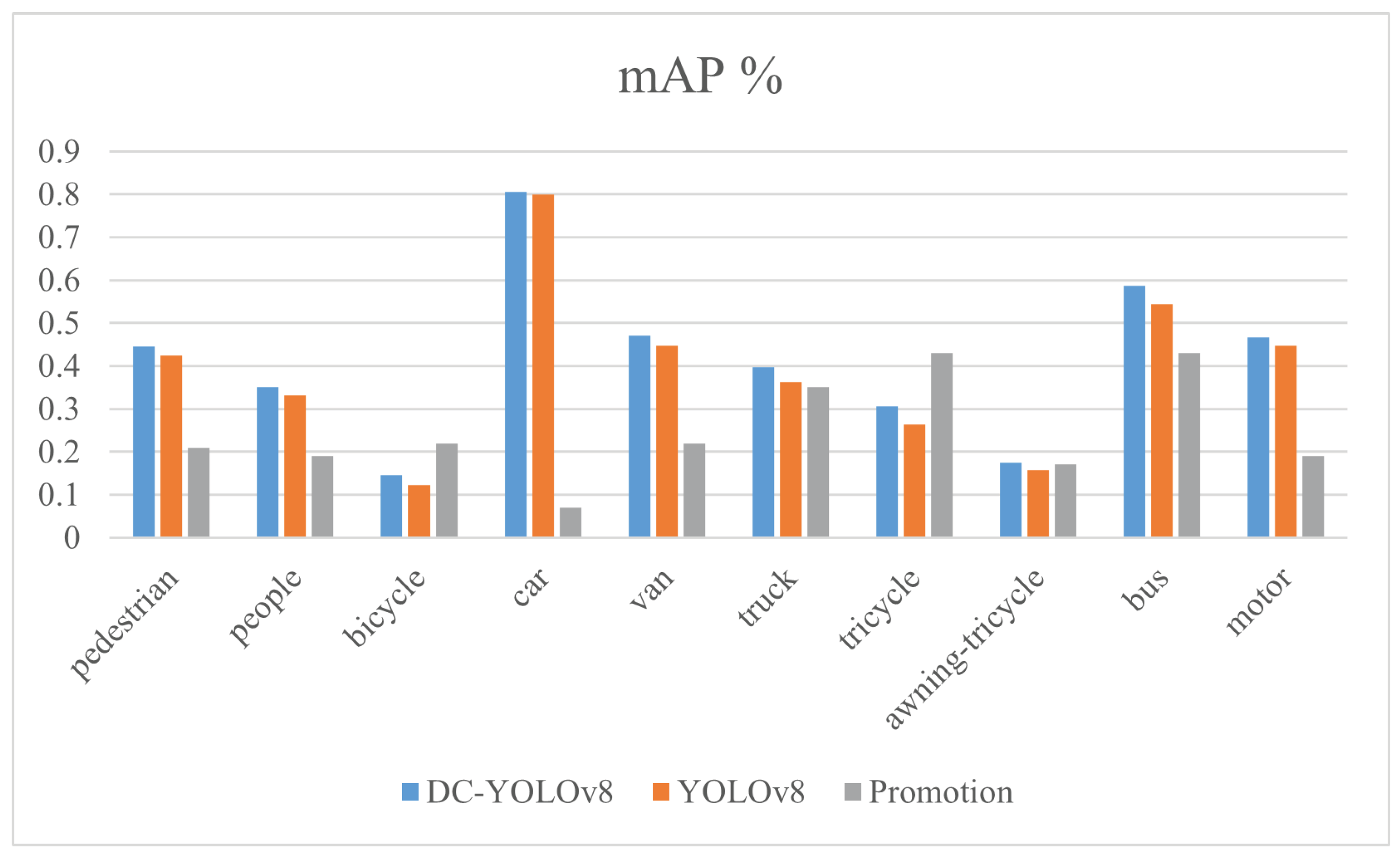
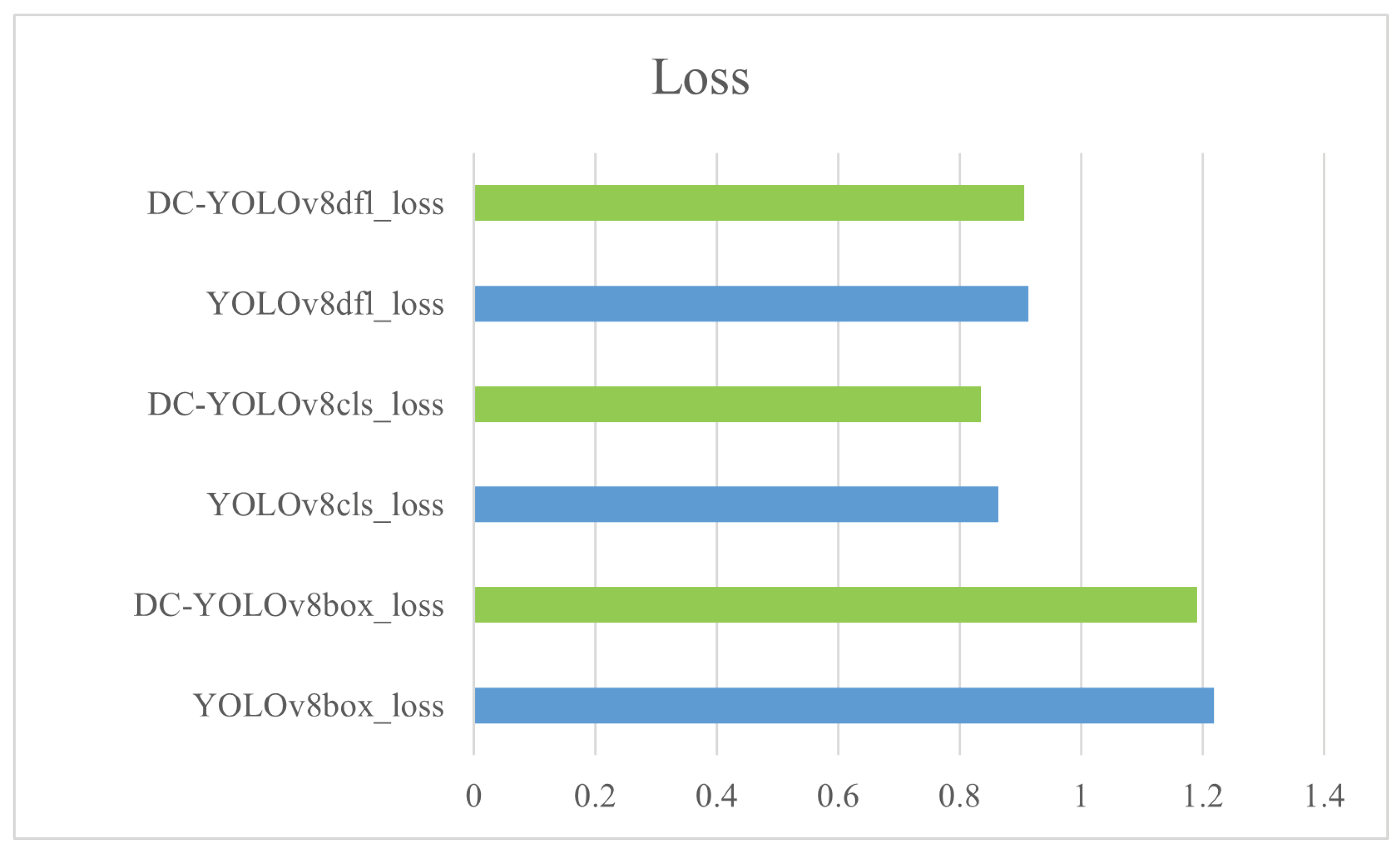
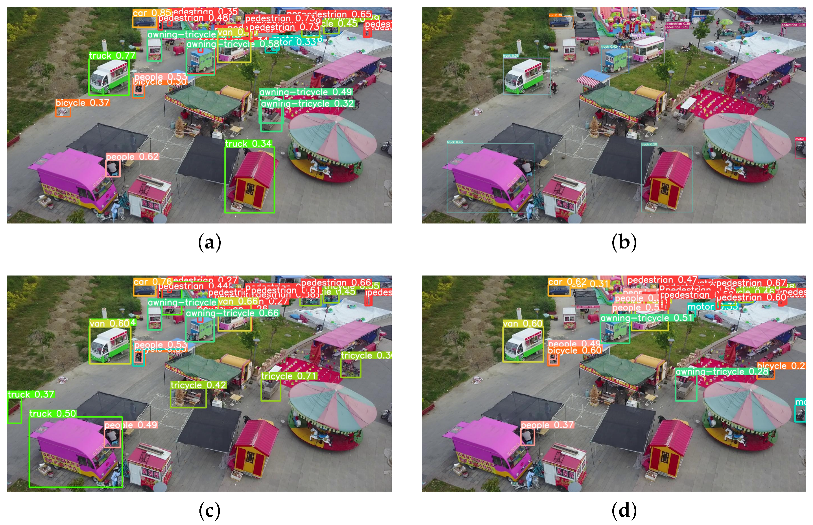
4.3. Experimental Result Analysis
4.4. Comparison of Experiments with Different Sized Objects
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zou, M.Y.; Yu, J.J.; Lv, Y.; Lu, B.; Chi, W.Z.; Sun, L.N. A Novel Day-to-Night Obstacle Detection Method for Excavators based on Image Enhancement and Multi-sensor Fusion. IEEE Sens. J. 2023, 23, 10825–10835. [Google Scholar]
- Liu, H.; Member, L.L. Anomaly detection of high-frequency sensing data in transportation infrastructure monitoring system based on fine-tuned model. IEEE Sens. J. 2023, 23, 8630–8638. [Google Scholar] [CrossRef]
- Zhu, F.; Lv, Y.; Chen, Y.; Wang, X.; Xiong, G.; Wang, F.Y. Parallel Transportation Systems: Toward IoT-Enabled Smart Urban Traffic Control and Management. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4063–4071. [Google Scholar] [CrossRef]
- Thevenot, J.; López, M.B.; Hadid, A. A Survey on Computer Vision for Assistive Medical Diagnosis from Faces. IEEE J. Biomed. Health Inform. 2018, 22, 1497–1511. [Google Scholar] [CrossRef] [PubMed]
- Abadi, A.D.; Gu, Y.; Goncharenko, I.; Kamijo, S. Detection of Cyclist’s Crossing Intention based on Posture Estimation for Autonomous Driving. IEEE Sens. J. 2023, 2023, 1. [Google Scholar] [CrossRef]
- Singh, G.; Stefenon, S.F.; Yow, K.C. Yow, Interpretable Visual Transmission Lines Inspections Using Pseudo-Prototypical Part Network. Mach. Vis. Appl. 2023, 34, 41. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Wang, W.; Chu, G.; Chen, L.; Chen, B.; Tan, M. Searching for MobileNetV3 Accuracy vs MADDs vs model size. In Proceedings of the IEEE Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet V2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Volume 11218, pp. 122–138. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Seattle, WA, USA, 13–19 June 2020; Volume 42, pp. 386–397. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Liu, H.; Duan, X.; Chen, H.; Lou, H.; Deng, L. DBF-YOLO:UAV Small Targets Detection Based on Shallow Feature Fusion. IEEJ Trans. Electr. Electron. Eng. 2023, 18, 605–612. [Google Scholar] [CrossRef]
- Liu, H.; Sun, F.; Gu, J.; Deng, L. SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode. Sensors 2022, 22, 5817. [Google Scholar] [CrossRef] [PubMed]
- Sengupta, A.; Cheng, L.; Cao, S. Robust multiobject tracking using mmwave radar-camera sensor fusion. IEEE Sens. Lett. 2022, 6, 1–4. [Google Scholar] [CrossRef]
- Bharati, V. LiDAR+ Camera Sensor Data Fusion On Mobiles With AI-based Virtual Sensors to Provide Situational Awareness for the Visually Impaired. In Proceedings of the 2021 IEEE Sensors Applications Symposium (SAS), Sundsvall, Sweden, 23–25 August 2021; pp. 1–6. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 1571–1580. [Google Scholar]
- Lin, T.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee Jae, Y. Yolact: Real-time Instance Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Cao, Y.; Chen, K.; Loy, C.C.; Lin, D. Prime Sample Attention in Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11583–11591. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An energy and GPU-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 752–760. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Algorithm | Module | Result | |||||
|---|---|---|---|---|---|---|---|
| MDC | Feature Fusion | DC | mAP0.5 | mAP0.5:0.95 | P | R | |
| YOLOv8 | 39 | 23.2 | 50.8 | 38 | |||
| DC-YOLOv8 | ✓ | 39.5 | 23.5 | 51.2 | 38.8 | ||
| DC-YOLOv8 | ✓ | ✓ | 40.3 | 24.1 | 51.8 | 39.4 | |
| DC-YOLOv8 | ✓ | ✓ | ✓ | 41.5 | 24.7 | 52.7 | 40.1 |
| Datasets | Result | YOLOv3 | YOLOv5 | YOLOv7 | YOLOv8 | DC-YOLOv8 |
|---|---|---|---|---|---|---|
| Visdrone | mAP0.5 | 38.8 | 38.1 | 30.7 | 39 | 41.5 |
| mAP0.5:0.95 | 21.6 | 21.7 | 20.4 | 23.2 | 24.7 | |
| VOC | mAP0.5 | 79.5 | 78 | 69.1 | 83.1 | 83.5 |
| mAP0.5:0.95 | 53.1 | 51.6 | 42.4 | 63 | 64.3 | |
| Tinyperson | mAP0.5 | 18.5 | 18.3 | 16.9 | 18.1 | 19.1 |
| mAP0.5:0.95 | 5.79 | 5.81 | 5.00 | 6.59 | 7.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. https://doi.org/10.3390/electronics12102323
Lou H, Duan X, Guo J, Liu H, Gu J, Bi L, Chen H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics. 2023; 12(10):2323. https://doi.org/10.3390/electronics12102323
Chicago/Turabian StyleLou, Haitong, Xuehu Duan, Junmei Guo, Haiying Liu, Jason Gu, Lingyun Bi, and Haonan Chen. 2023. "DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor" Electronics 12, no. 10: 2323. https://doi.org/10.3390/electronics12102323
APA StyleLou, H., Duan, X., Guo, J., Liu, H., Gu, J., Bi, L., & Chen, H. (2023). DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics, 12(10), 2323. https://doi.org/10.3390/electronics12102323