1. Introduction and Related Studies
Employability requirements have changed to address the new realities and challenges faced by organizations. According to [
1] cited by [
2], in several fields, some discrepancies emerge between employee competences and the labor market. In view of this, professionals must improve and/or develop their competences and skills according to trends in the labor market in order to be competitive.
Nowadays, organizations can use different Social Networks Sites (SNSs) to research into candidates [
3], as well as to gather information on labor trends so as to adjust academic plans, analyze student profiles and extract their skills, and identify the most desired skills for the purpose of adjusting curricula [
4].
In the professional field, LinkedIn has played a very important role in terms of the dissemination of jobs, where, according to the work presented by one of its missions is to match jobs with suitable professionals [
5].
To support this process, the Recommender Systems (RSs) have emerged, which collect the information linking users to items and use it to make relevant and meaningful suggestions. By [
6] the RSs base the prediction of user interests, according to their explicit or implicit preferences. RSs are not only used to find the ideal candidate for a job position, but also to offer educational services to professionals to develop professional skills.
RSs use different filtering algorithms, in which the predominant approaches are collaborative filtering, content-based filtering and hybrid filtering. This combines the two approaches so as to overcome any problems that may arise through individual use of the different techniques, such as the problem of data sparsity, or owing to the lack of information provided by users about the recommended items, which is known as cold start [
7], and thus improve recommendation performance [
8].
On the other hand, the quality of recommendations is highly dependent on information retrieval and representation. According to [
2], RSs handle a large amount of data that, depending on their nature, can derive from different sources such as SNSs, which are characterized by their heterogeneity. In this regard, semantic RSs have emerged, which make use of the semantic web to represent reality in a specific domain, in a machine-readable way [
9].
The work presented by [
2] involves a review of articles that propose the use of ontology in order to create a model to describe the relationship between a domain area and the users that belong to it.
In this review, the importance of the representation and management of information is highlighted. Studies [
10,
11] pointed out that ontologies allow information of interest to users to be inferred, which can be used to enrich recommendations. Likewise, [
12] indicated that the amount of information handled is a key factor in the success of recommendations. Studies [
11,
13] pointed out that the use of ontology improved cold start and data sparsity problems, which limit RS performance. [
14] also suggested that the use of ontologies facilitates the analysis, reasoning, sharing and reuse of knowledge.
In recent years, artificial intelligence techniques have been introduced in RSs, where Machine Learning (ML) techniques are included [
15]. According to [
16], the use of these techniques has proved to be a promising solution when designing RSs in the era of Big Data.
According to [
17] ML algorithms have become dominant in big data analysis, visualization and modeling. For [
18] ML applies mathematical models and algorithms to gradually improve the performance of a task and can be categorized into two main groups: supervised and unsupervised learning. ML algorithms are performing tasks like classification, regression, clustering, dimensionality reduction, and ranking.
In the systematic review presented by [
19], attention should be drawn to the work shown in
Table 1 in this area.
In some cases, ML is used in RSs to make inferences about how past actions correspond to future outcomes. [
23] applies this technique to predict future performance based on students’ academic record in order to re-schedule courses for target course preparation and exam preparation. [
24] proposes an RS for different users in academia, using ML to extract information about research areas of interest to professors from publications and curricula, and then combining them with their background to assign courses and research work for supervisory purposes.
Additionally, semantic web techniques have been combined with ML techniques, allowing knowledge to be exploited from available information, updated and new relationships between data inferred [
14]. The combination of an ontology-based recommender system with ML techniques has been used as an approach to improve the accuracy of recommendations, in addition to addressing information overload, with a view to solving cold start problems [
26].
Based on the above [
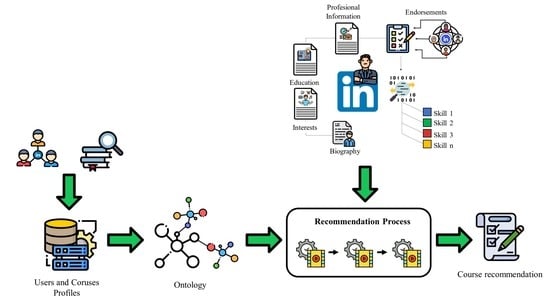
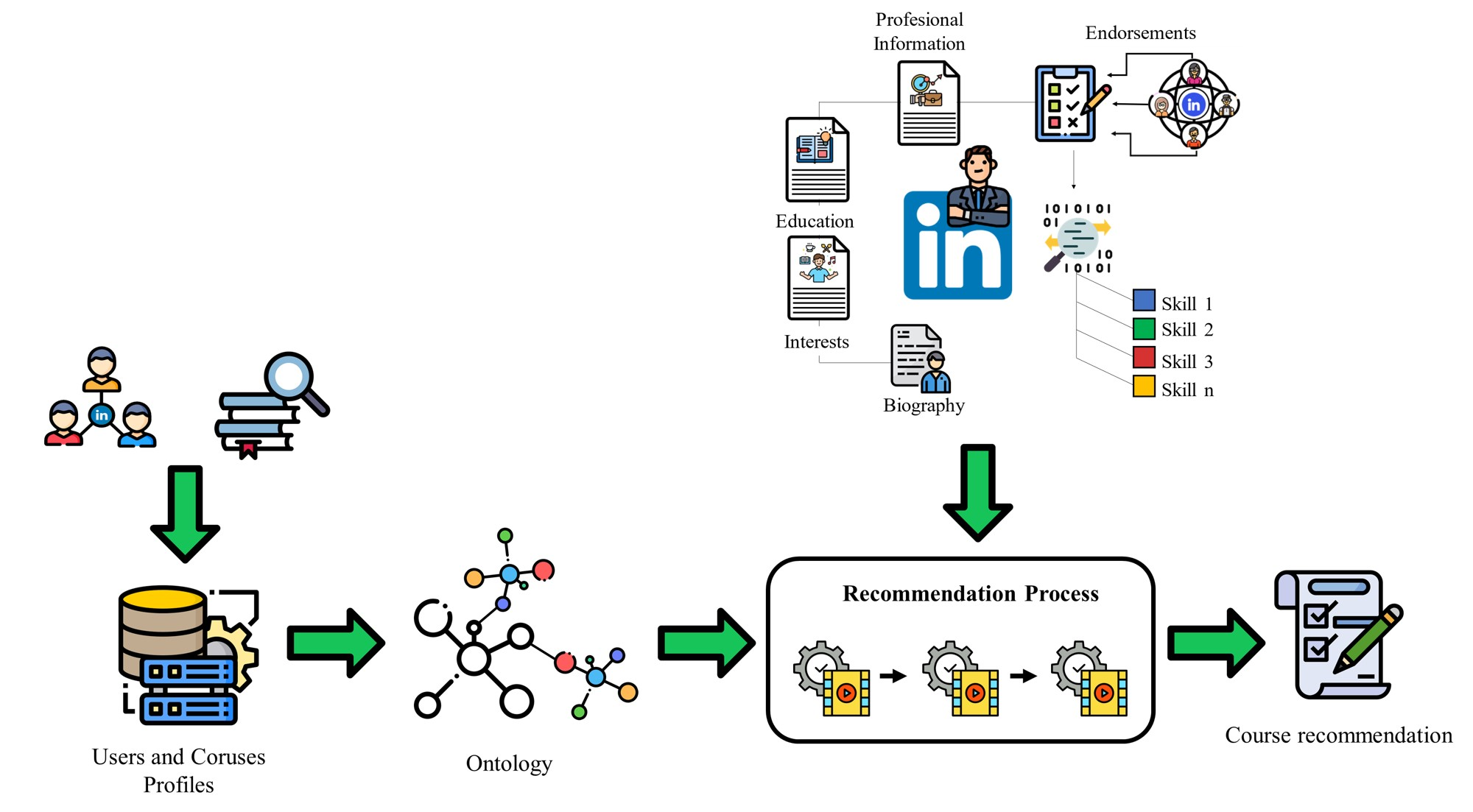
2], they propose a hybrid RS to suggest lifelong learning (LLL) courses to improve professional competences for users whose profile is built from their LinkedIn profile data. The RS core involves semantic filtering that uses ontology to model employment sectors and areas of knowledge to represent professional competences. The ontology is updated using events based on professional record profile data extracted from LinkedIn, using ML to cluster entities in order to make predictions about the new data. As a line of future work, they recommend considering the use of LinkedIn endorsements to enrich the user profile and thus improve recommendations.
Recently, there have been several research work oriented analyses of data provided by LinkedIn, which in addition to data related to academic and professional training, also highlights endorsements, which is one of the key features of LinkedIn, asking the viewer to endorse a skill for the candidate as proof of their skill level [
27].
In a review of relevant literature, we found the research shown in
Table 2, related to the use of LinkedIn endorsements.
This is highlighted in [
4], in which an RS is proposed that classifies profiles according to skills and peer endorsements, identifying the most desired skills that should be covered by curricula and areas of learning, and suggesting possible corrections in learning programs. [
32] indicates that in addition to this information, endorsements of the skills of LinkedIn users can be analyzed to complement the profile.
The system proposed by [
32] recommends relevant job opportunities for users seeking employment in the area of information technology, based on the curriculum to be entered into the system. In addition, it makes it easy for recruiters to search for the best talent based on job requirements by analyzing not only the resume, but also LinkedIn endorsements, which could improve the user profile.
Based on the above, an improvement in RS of [
2] is proposed, incorporating LinkedIn endorsements as an additional system input. These are taken into account in order to validate the skills determined in the RS profiles to improve recommendations.
In literature on the subject, we found some RSs aimed at developing professional skills through a wide range of training. In this respect, the objective of the RSs proposed by [
33,
34,
35] is to identify the professional competencies that users need to develop in their current job, so that they can be taken into account in their training plan.
For [
4], along with RSs, the analysis of SNSs data has become a common practice for collection of information about users, since [
36], SNSs such as Facebook and LinkedIn have become integrated into everyday life.
Ref. [
37] indicates that social media provide innovative pedagogical frameworks for teaching and learning that allow students to develop digital skills deemed useful for a successful professional career. He also points out that semantic social networks offer a series of advantages related to their strategic use, such as the creation of a network of contacts, which can have an impact on their professional development by connecting with professionals and following labor market trends.
As the use of SNSs has increased decade by decade, so has interest in using SNSs in recruitment and hiring processes [
3]. In this sense, for [
28], LinkedIn is the most influential web tool in terms of professional use, unlike other SNSs such as Facebook or Twitter, which focus on social relationships. In LinkedIn, users have greater visibility in professional terms, as they can share their training, skills and work experience [
4].
For [
37], LinkedIn focuses on professional networking and career development, designed to help people make connections, share experiences and resumes, and find jobs. It is also a tool that can be used to find relevant, quality content. According to [
3], allowing users to provide written recommendations and endorsements of skills that appear on a user’s profile, LinkedIn has also introduced endorsements, in which users are asked to endorse the skills of other users [
27].
The data contained in SNSs are very diverse [
3], and RSs also obtain information from multiple sources; to handle heterogeneity, they have adopted semantic knowledge representation as one of the theories to help deal with this [
26].
Based on this review and lending continuity to the RS presented by [
2], it is proposed that LinkedIn skills endorsements be incorporated in order to validate the skills obtained in the user profiling stage to optimize performance and prediction of the continuing education course recommendation system. The system uses LinkedIn user records in the area of software development.
This article is structured as follows:
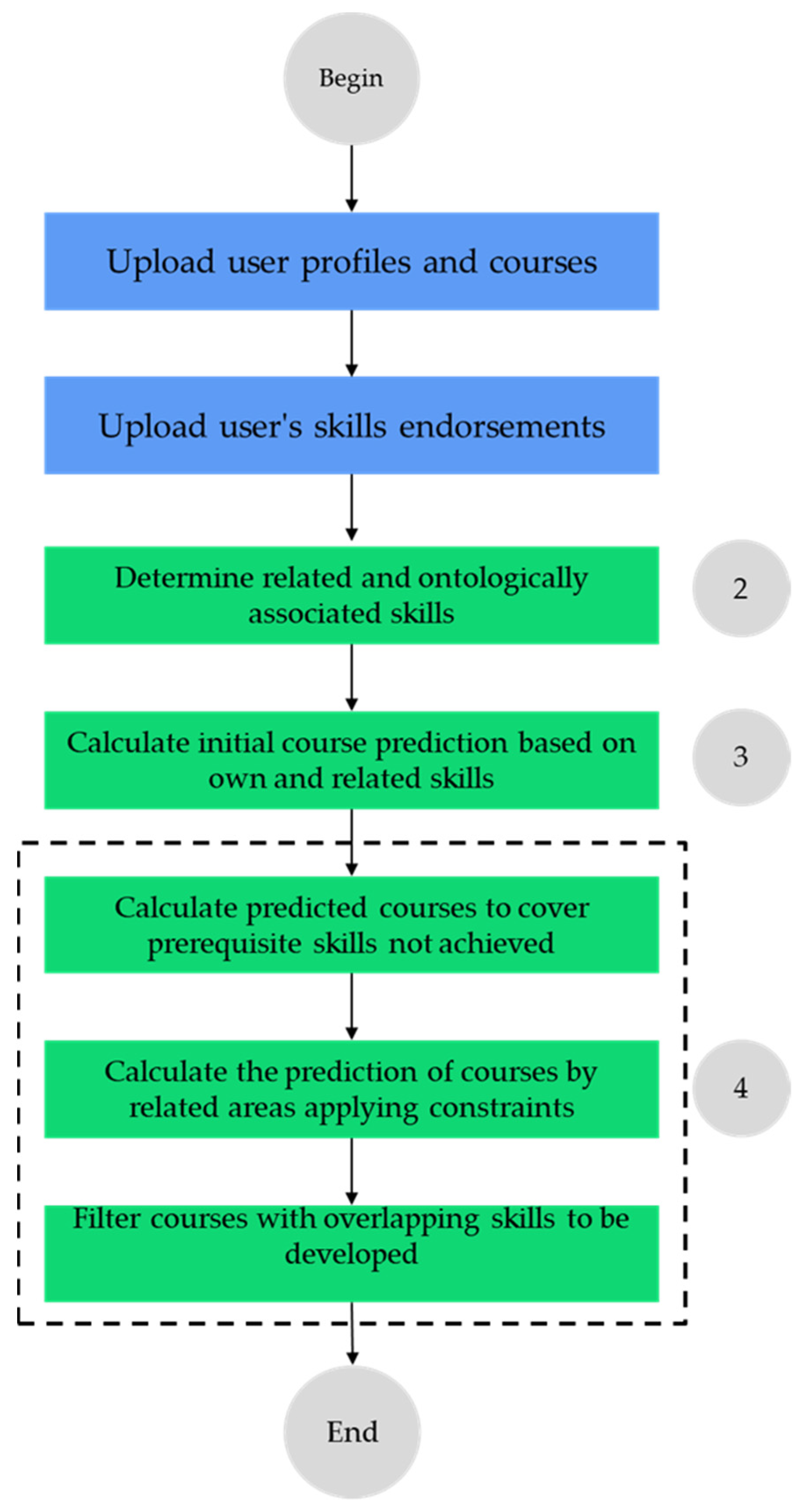
Section 2 details the RS proposal;
Section 3 describes the evaluation of the proposal; and
Section 4 provides conclusions and recommendations for future research.
3. Evaluation and Results
According to [
7], RS evaluation can be conducted through on-line and off-line experimentation. The work presented by [
2] performed off-line RS evaluation. This type of evaluation allows different algorithms and approaches to be assessed, which is used in experimental environments, since the utmost consistency is desired in order to compare the performance of different proposals under the same conditions. Likewise, the off-line evaluation involves metrics to reflect the effectiveness of the system from the user perspective and provide a widely accepted evaluation, due to the robustness of the metrics used.
To evaluate our proposal, and to compare the results with our previous work [
2], we performed an off-line evaluation and calculated the metrics used in it (
Table 5).
RSs are evaluated in batches, with a set of data containing the profiles of both users and courses, as well as user preferences. These were taken from a survey conducted using a Google form, where it was requested that a list of courses be classified in the categories of desirable, preferred, novel and serendipitous, in order to ascertain the preferences of users regarding choice of LLL courses.
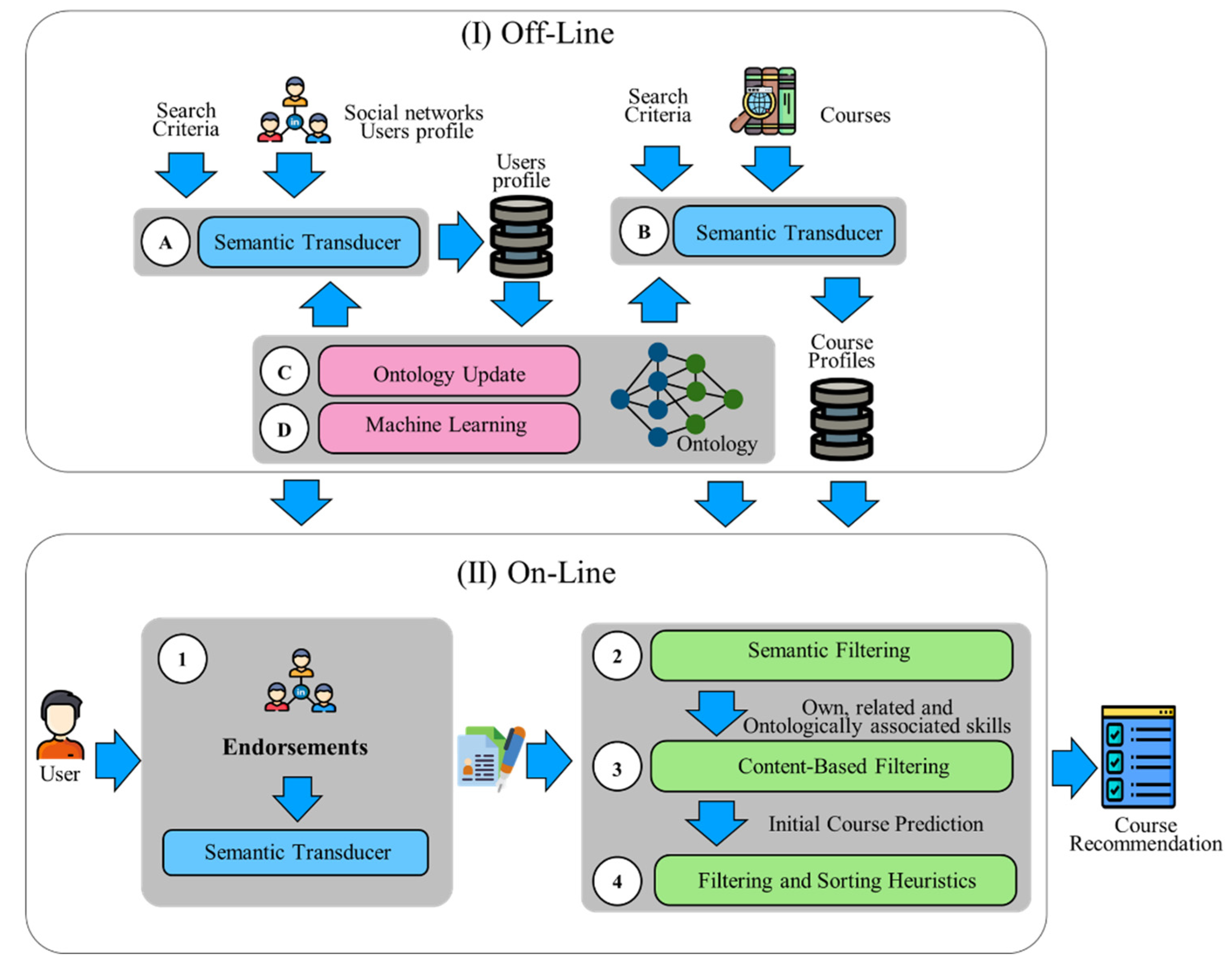
The off-line phase of the system was implemented, whereby data were loaded into the Neo4j database that had previously been populated by the ontology substrate definitions. This was updated via events using the training dataset, and clusters of job performance sectors were determined using ML, k-Means and DBSCAN algorithms.
In order to evaluate RS performance and compare it to our previous work, metrics were calculated for each of the following configurations [
2]:
1: Content filtering using only the user’s own skills; no related skills are determined, although skills of interest are considered;
2: Collaborative filtering using only the user’s own work performance sectors; semantically related skills are determined;
3: Semantic filtering using rules to determine related job performance sectors and related skills;
4: Semantic filtering using 75% coverage of user skills to determine related job performance sectors. In other words, those positions that cover 75% of the user’s skills were selected as related job performance sectors;
5: Semantic filtering using 50% coverage of skills from the job performance sector to determine related job performance sectors. In other words, those job performance sectors in which the user’s skills cover 50% of the skills associated with the position;
6: Semantic filtering using DBSCAN clustering with ε = 0.3, to determine related job performance sectors and semantic rules to determine related skills;
7: Semantic filtering using k-Means clustering to determine related job performance sectors and semantic rules to determine related skills;
8: Semantic filtering using DBSCAN and k-Means clustering to determine related job performance sectors and semantic rules to determine related skills.
Each of the configurations described above were run through the different data sets, training, testing and total, obtaining the following results.
The test results are next shown along with the results obtained in the previous work [
2], to compare the results and evaluate improvement in the RS.
The results, using the training data (70% of the data set) to validate the model performance, are shown in
Table 6.
The results obtained from use of the different configurations with the total number of samples from the dataset are shown in
Table 7.
Finally, the system was run under the different configurations, using the test portion (30%) of data, with the results shown in
Table 8.
From the results obtained, it can be observed that both this proposal and the system proposed in [
2] evidence similar behavior. As such, the configurations showing the best performance in the case of all data sets were semantic filtering using rules to determine related job performance sectors and related skills (3) and semantic filtering using DBSCAN clustering with ε = 0.3 to determine related job performance sectors, and semantic rules to determine related skills (6). However, there was an improvement in MAE and RMSE scores, and a slight increase in precision.
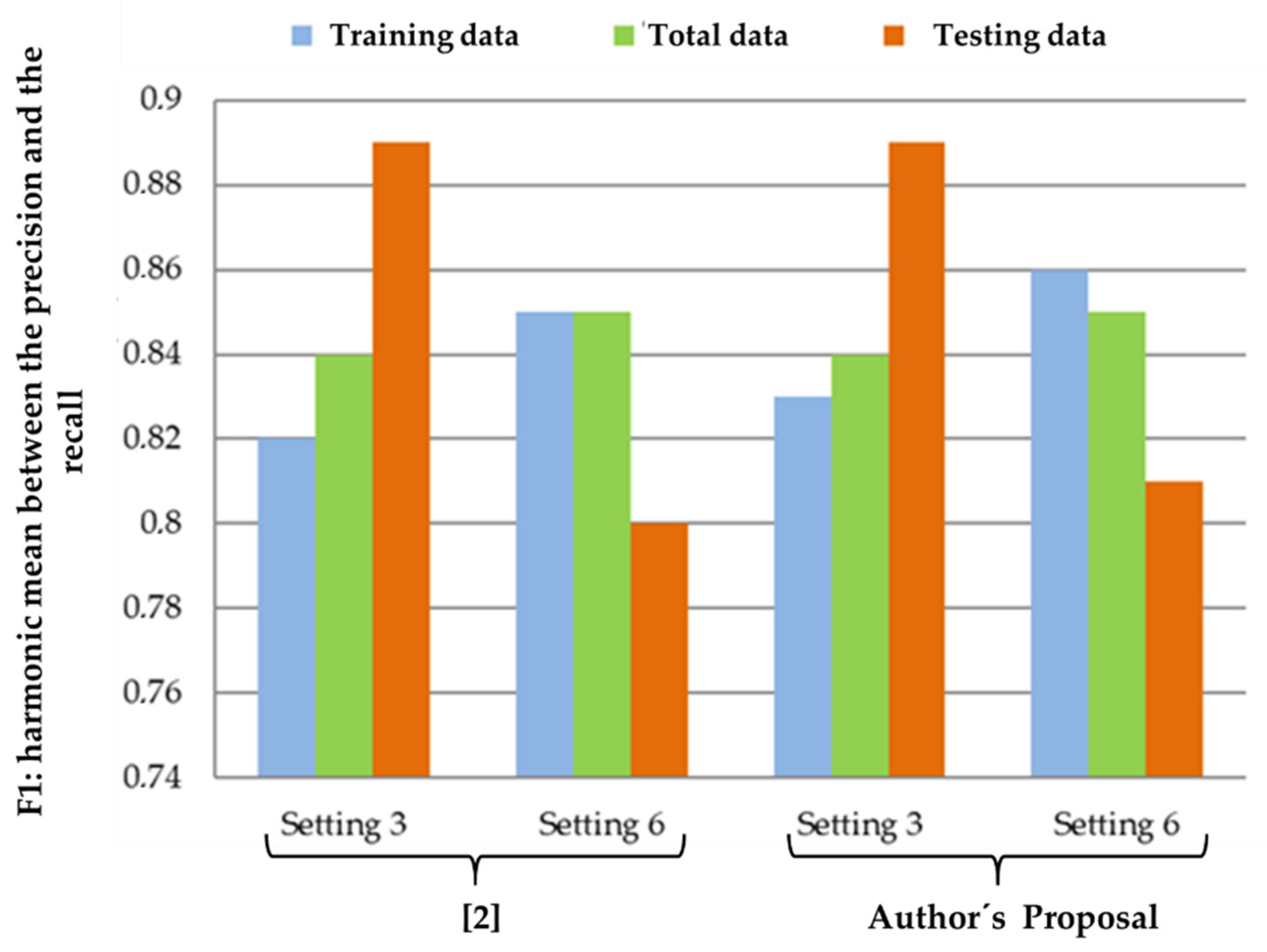
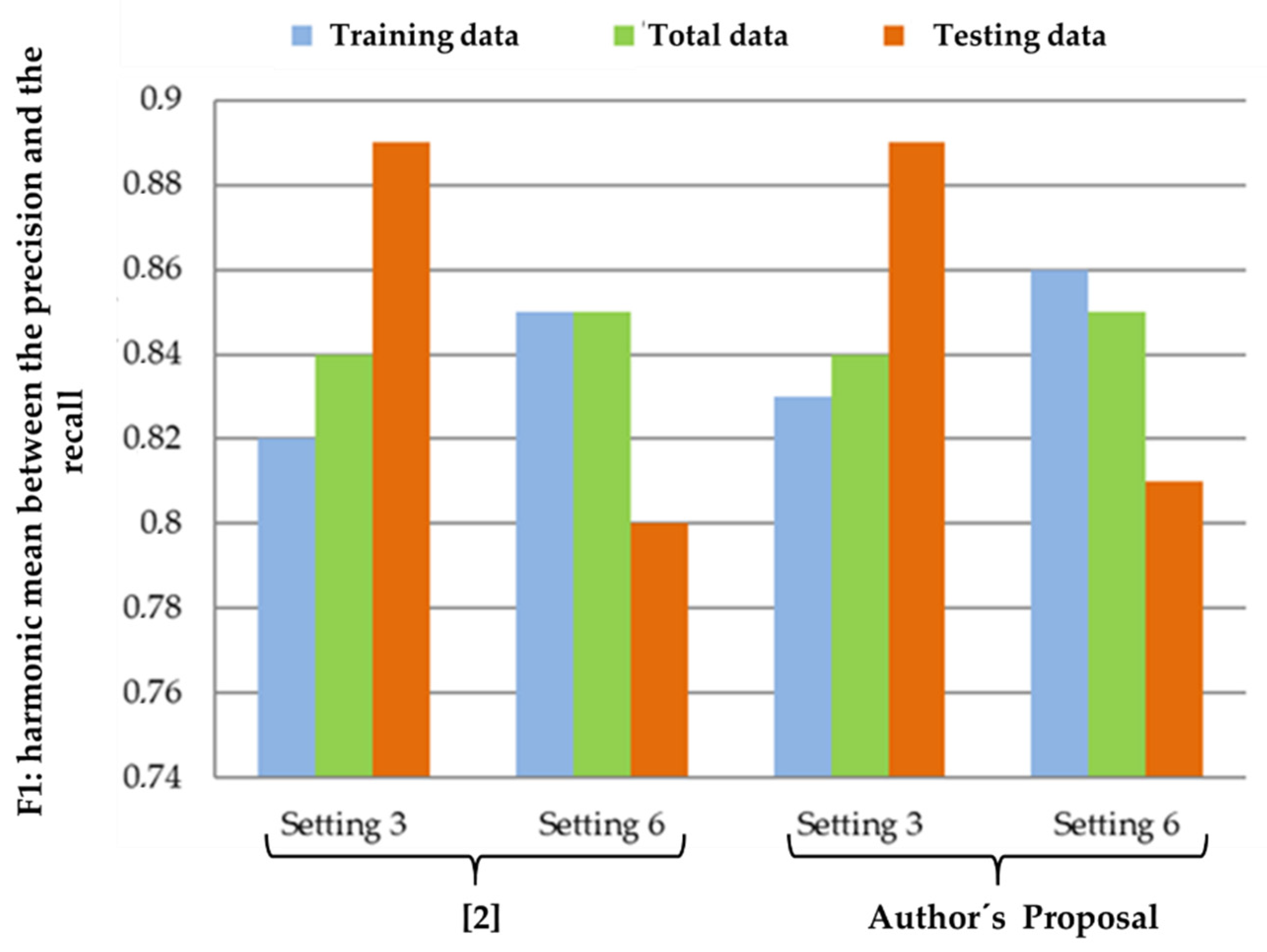
A measure that summarizes both precision and recall is the harmonic mean between them (F1).
Table 9 shows the harmonic means for the best performing configurations.
From the harmonic mean comparison table, it can be seen in
Figure 3, that there is a slight improvement in configuration 6, which makes use of the DBSCAN algorithm, while configuration 3, which corresponds to semantic filtering, remains unchanged.
From the different tests, the clustering performed by k-Means evidences an inferior performance, which could be explained by the nature of the domain and distribution of the positions in space. In general, in the graph analysis we observe better clustering (related positions) performed by DBSCAN than that performed by k-Means. Improvements in the recall and serendipity metrics can be associated with use in the ontology and the estimation of associated skills or skills of interest and filtering of positions prior to the current one in an orderly relationship imposed by a ladder.
In our review of different works, we found some similar RS proposals, and so to evaluate the performance of ours it is advisable to compare results. The work by [
41] is geared to university students and company coordinators, recommends jobs according to user skills, while that by [
21] is designed to recommend courses to students, using multiple data sources. On the other hand, the work by [
42] recommends career paths and skills required for different jobs to users, based on their skills and interests. Finally, [
35] recommends online courses to professionals according to their professional competences and professional development preferences.
Table 10 provides a summary of the results obtained from each of these papers, which use the precision and recall metrics for the evaluation of their RSs, and the best performing configuration from our proposal.
When comparing these works with the best results obtained from our proposal, an improvement in metrics of all similar RS proposals can be seen, as can an increase in accuracy, recall and harmonic mean; the latter measures being the combined performance between accuracy and recall.
4. Discussion and Conclusions
In this paper we have presented a new version of the RS proposed by [
2], taking the incorporation of endorsements of user LinkedIn skills to evaluate RS performance into consideration. In the review of literature on LinkedIn endorsements, we noted that very few papers analyze this element. These are more oriented to analyze the validity of endorsements, as an element to be taken into account in the data extracted from SNSs.
The strategy proposed for recommendation of LLL courses was based on establishing a relationship between users according to work performance sectors and professional skills in order to identify those skills that should be improved or developed for their current job, or to access another, higher level job and, based on these identified skills, to determine an initial prediction of courses that may develop them. This strategy made it possible to establish a mechanism for relating the data, which generally speaking, did not initially have relationships on which to base recommendations.
By incorporating the endorsements, it was possible to obtain more information on the user profile, which in turn made it possible to incorporate skills that were not evident in the data related to current employment, and which were useful when refining course recommendation. When evaluating the incorporation of endorsements in creating user profiles, an improvement in RS performance was observed. The configuration that makes use of the DBSCAN algorithm improves the precision value by 3%, and results in a decrease in the root mean square error (RMSE) and mean absolute error (MAE).
When we wanted to compare our proposal with similar works, we did not find RSs that made use of endorsements, therefore, we selected some similar proposals in terms of RSs objectives. One of the main differences focuses on the nature of the data as it was observed that most work was with structured data. The work by [
42] obtained data directly from a university database, while [
41] obtained them from a data repository used for ML experimentation, and [
35] extracted them from employee profiles and the training plan directly from a company. The work by [
21], on the other hand, proposed using information from LinkedIn to complement the data entered directly from users through the application or obtained from the university database. From these data a taxonomy was proposed to represent course, job and student information.
The metrics used by most works were found to be recall and accuracy when they were analyzed to compare results with this proposal. In terms of the scores obtained, we can conclude that if we compare them to the results obtained from the tests performed on the total set of data, this proposal improves on the metrics obtained by these previous works by two percentage points in terms of accuracy and 10 percentage points in recall.
Research on LinkedIn endorsements is oriented towards assessing the veracity of endorsements on LinkedIn profiles. [
30] propose a framework for assessing the trustworthiness of endorsements. The work of [
31] proposes to measure the trustworthiness of job candidates based on their skills and endorsements. Based on this research, one line of future work is to incorporate the validation of endorsements into the RS to determine their veracity when taking them into account for recommendations.
In order to evaluate system behavior for multiple domains, the ontology could be updated with new instances associated with new domains. In order to evaluate system behavior for multiple domains, the ontology could be acted on with new instances associated with new domains, and the use of ontologies already built could also be evaluated, together with new ways to represent areas of knowledge and job performance sectors.
With regard to information sources and given the continuous changes, the use of other SNSs should be evaluated, as well as different platforms such as, RocketReach and DataLead, from where professional profiles can be obtained.
Online applications could also be offered for course recommendations, not only for online evaluation of the system, but also to determine opportunities for improvement based on user suggestions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}