
RDNet: Rate–Distortion-Based Coding Unit Partition Network for Intra-Prediction



Abstract
:1. Introduction
- We design an RDNet that integrates a prediction network and a target network, to predict the possible CU splitting modes and the RD cost.
- We propose a parameters exchanging strategy to balance the accuracy of the CU partition and the RD cost. Meanwhile, a dynamic threshold is optimized to realize the rapid optimization of the network.
- We achieve a coding time reduction of 55.83~71.72% with an efficient BD-BR of 2.876~3.347%, compared to the HEVC test model (HM16.5).
2. Related Work
2.1. Heuristic CU Partition
2.2. Learning-Based CU Partition
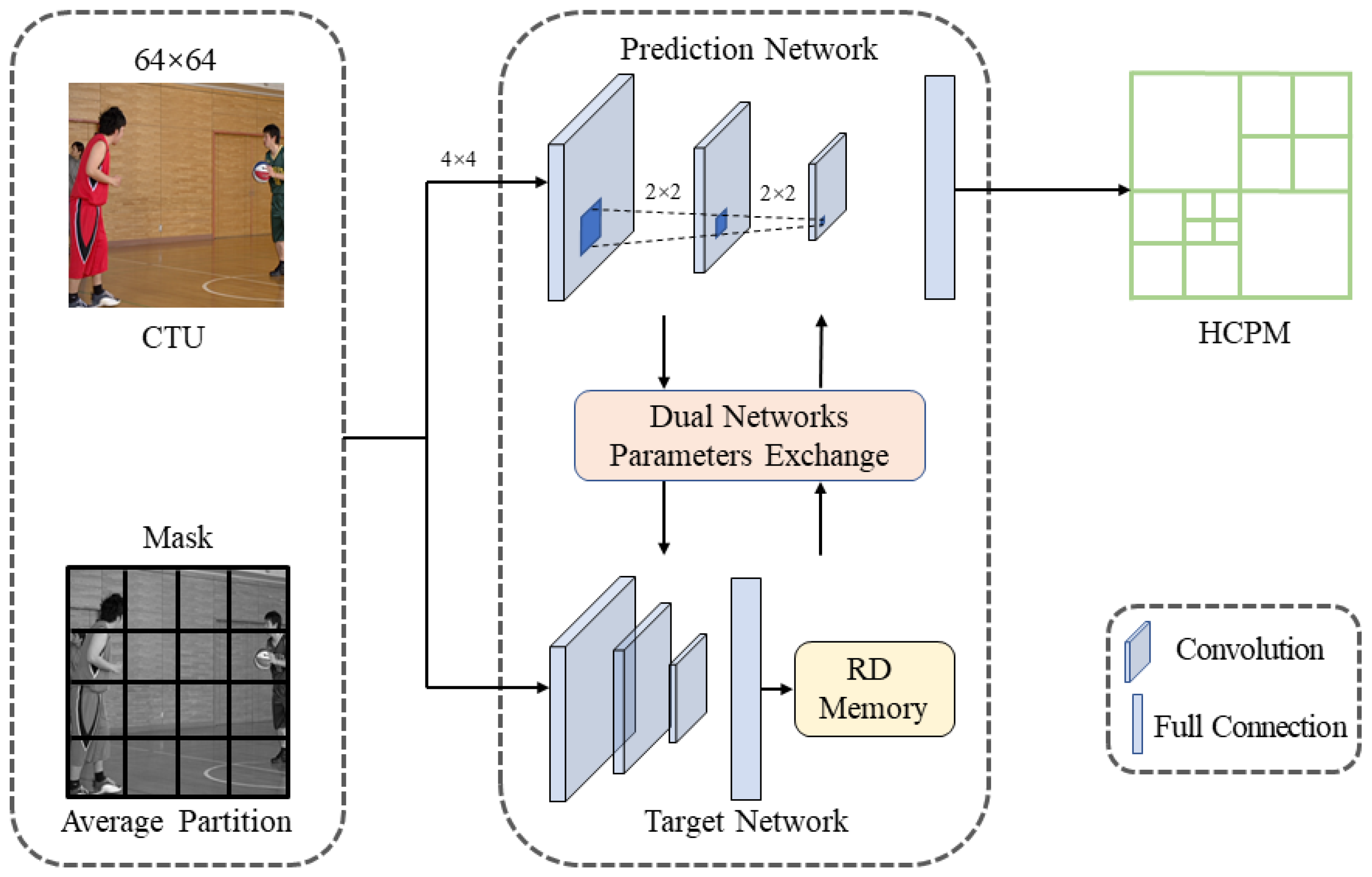
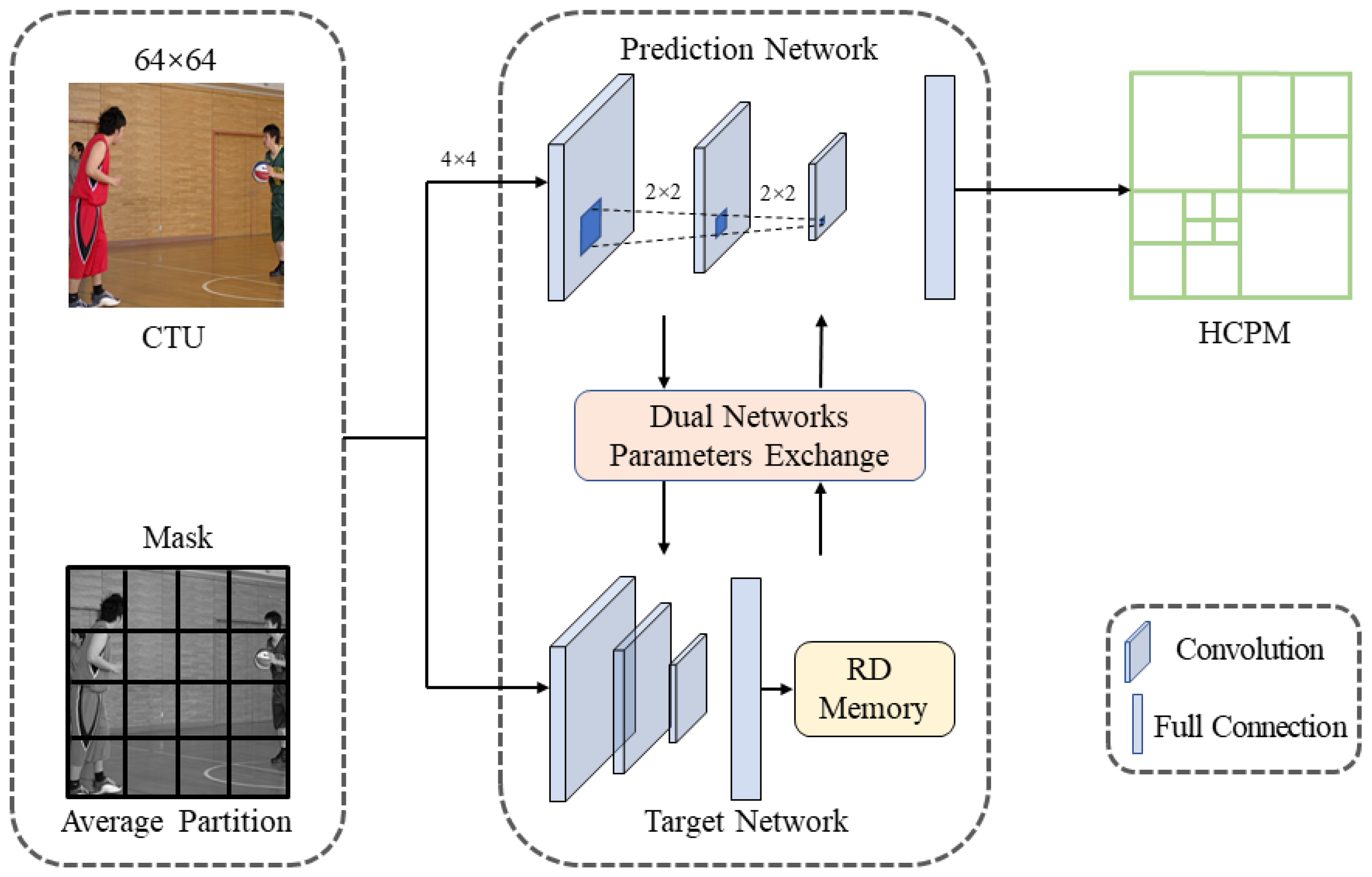
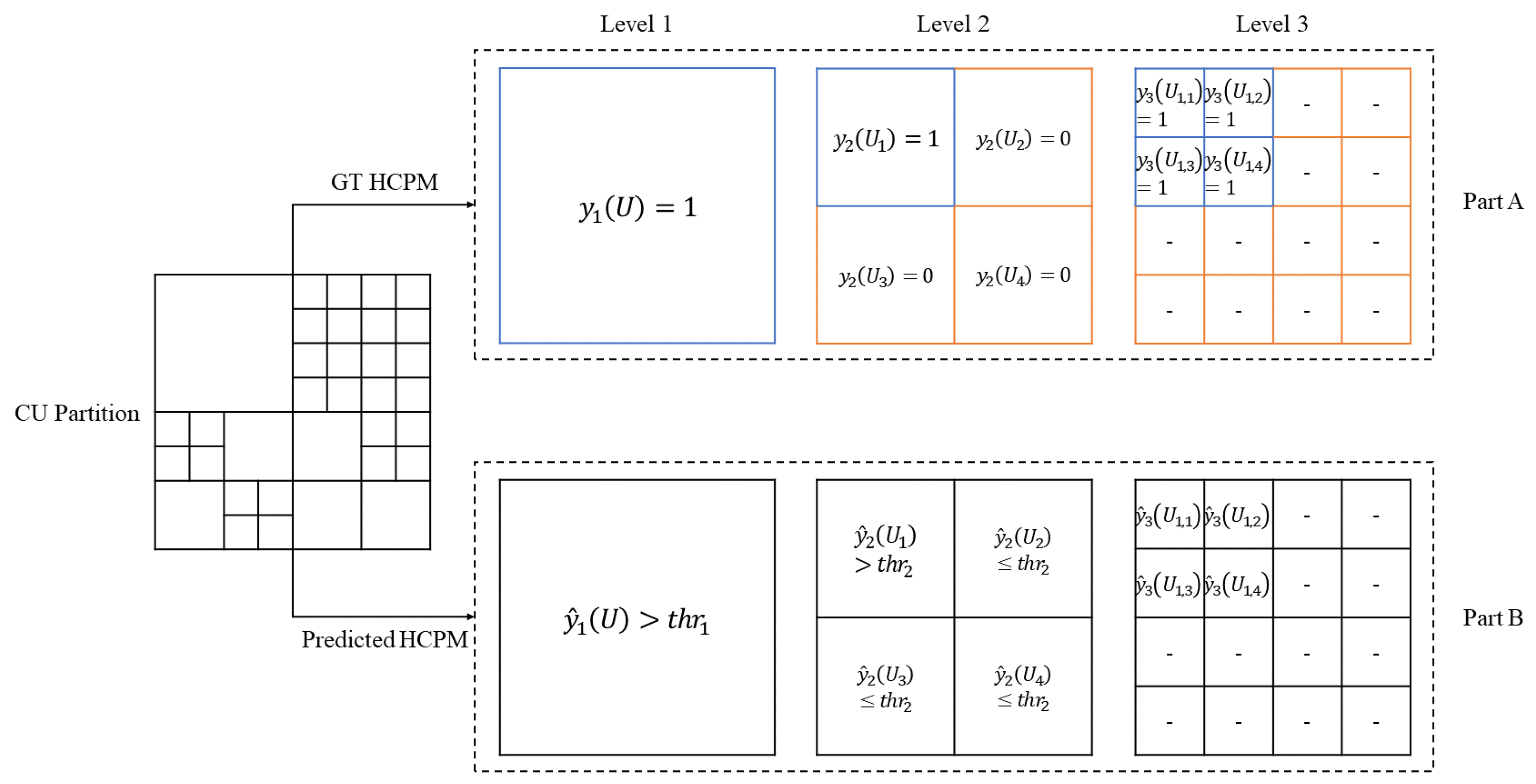
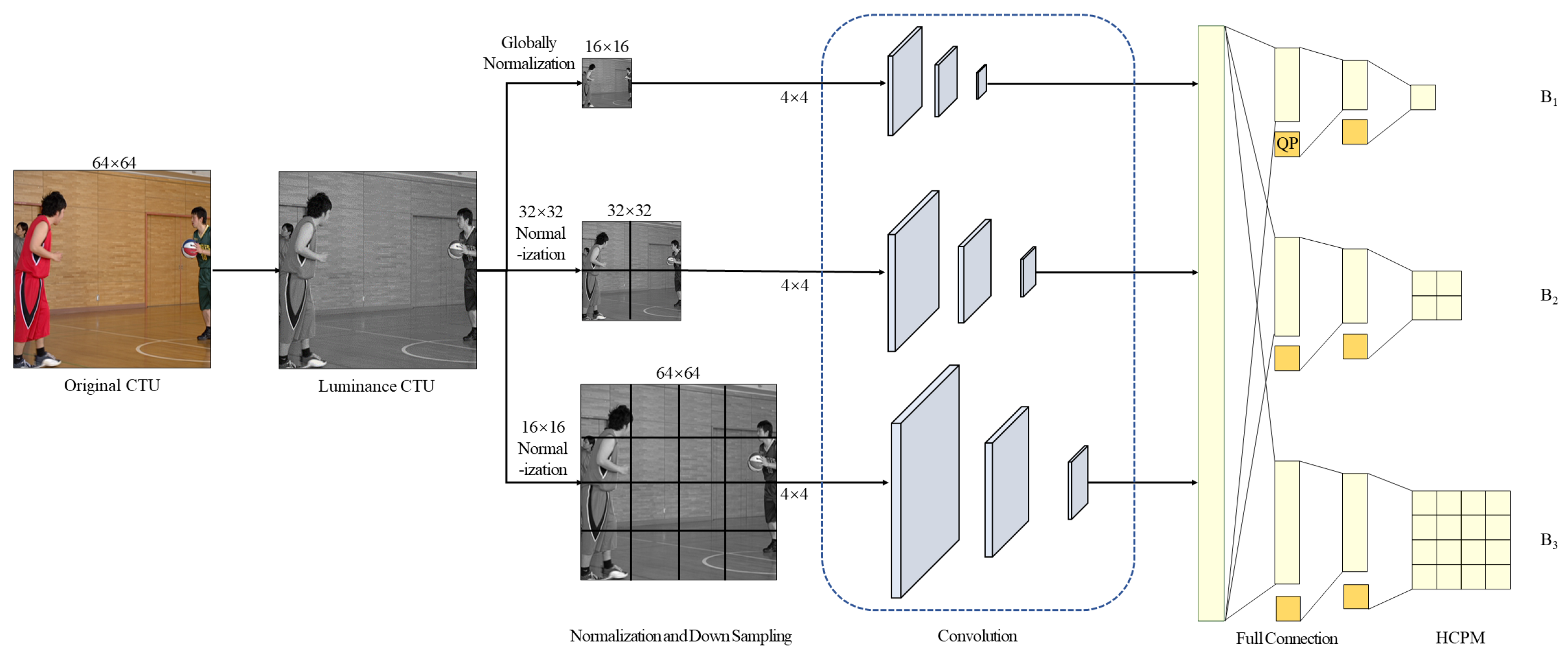
3. Methodology
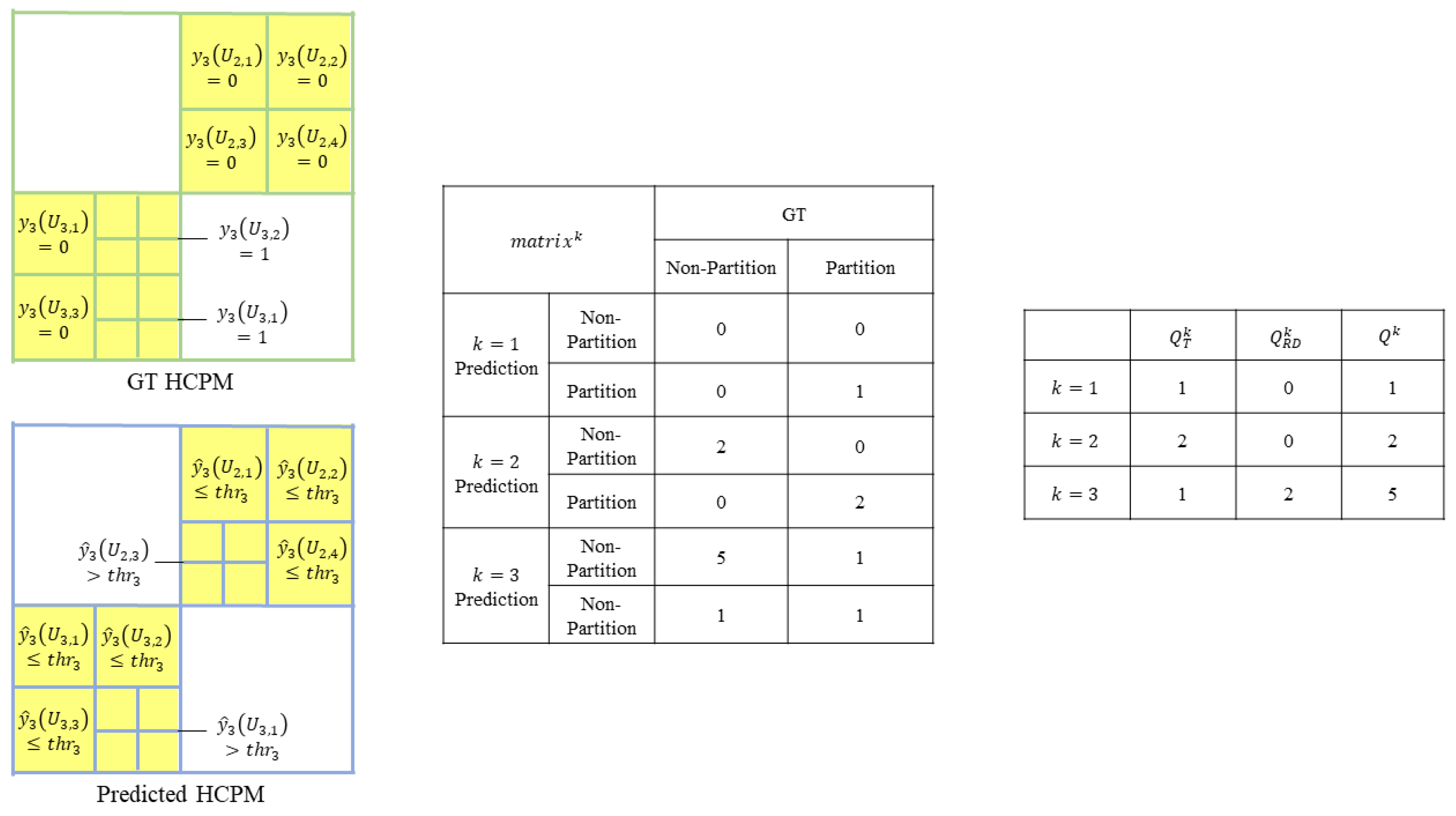
3.1. The RD Memory
3.2. Parameters Exchanging Strategy
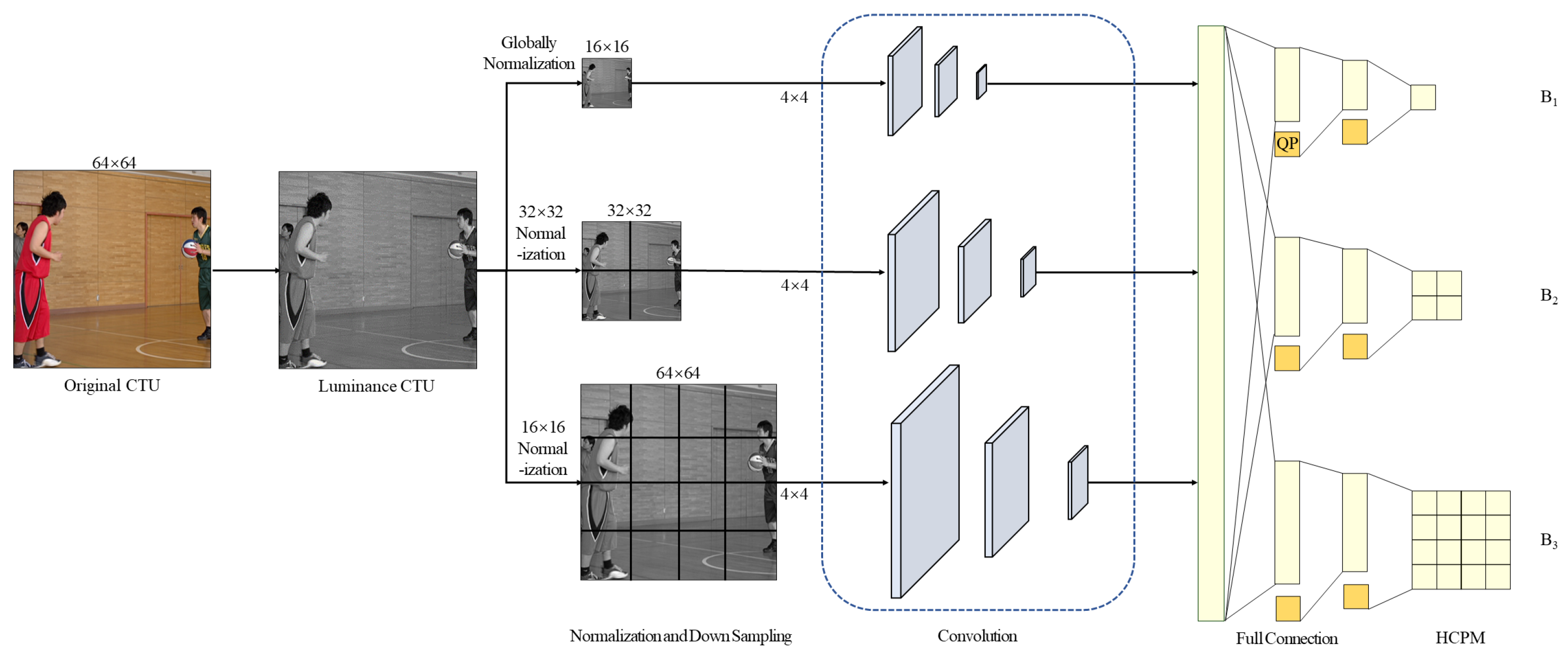
3.3. Fast Partition Neural Network
4. Experiment Results
4.1. Configuration and Settings
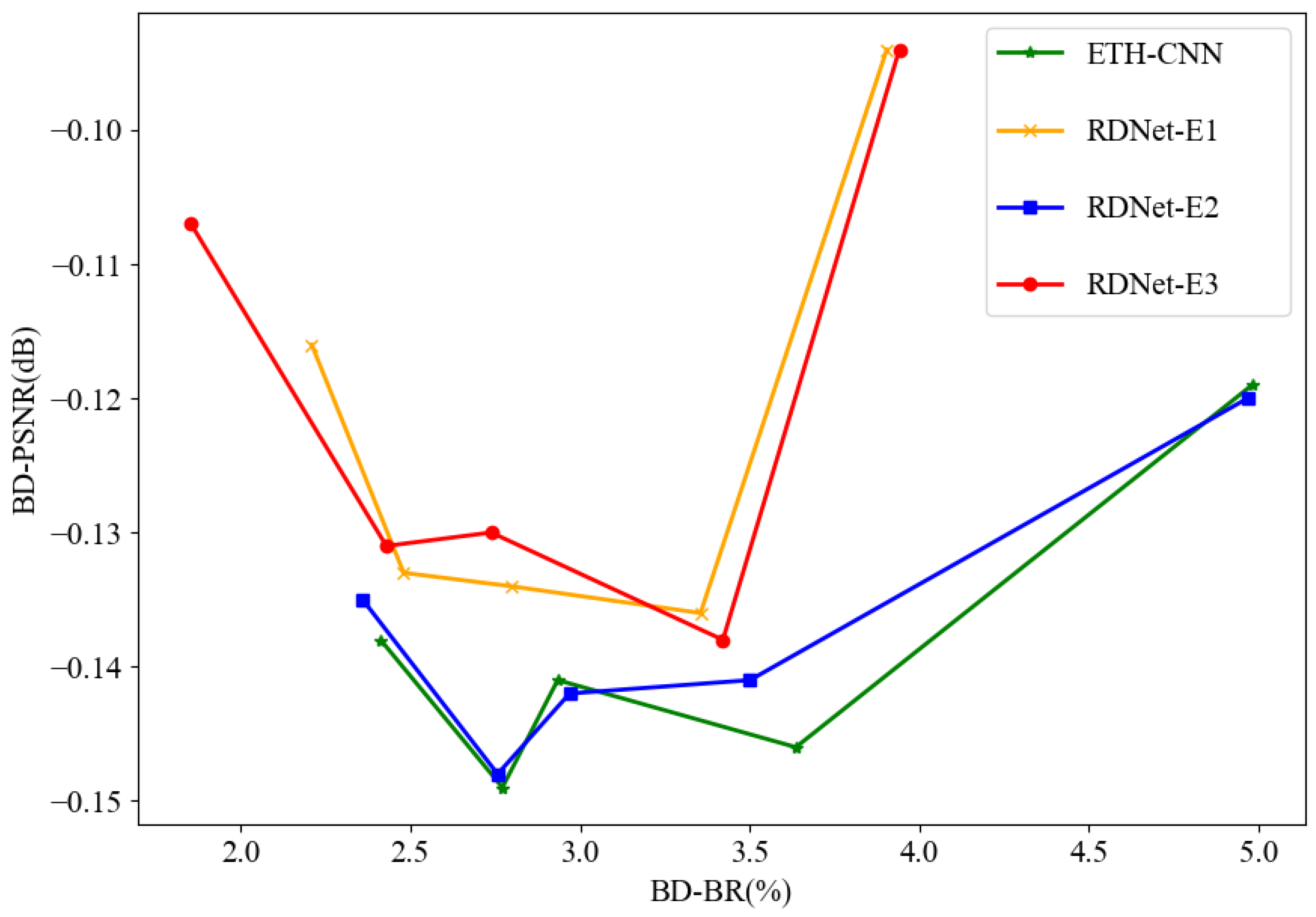
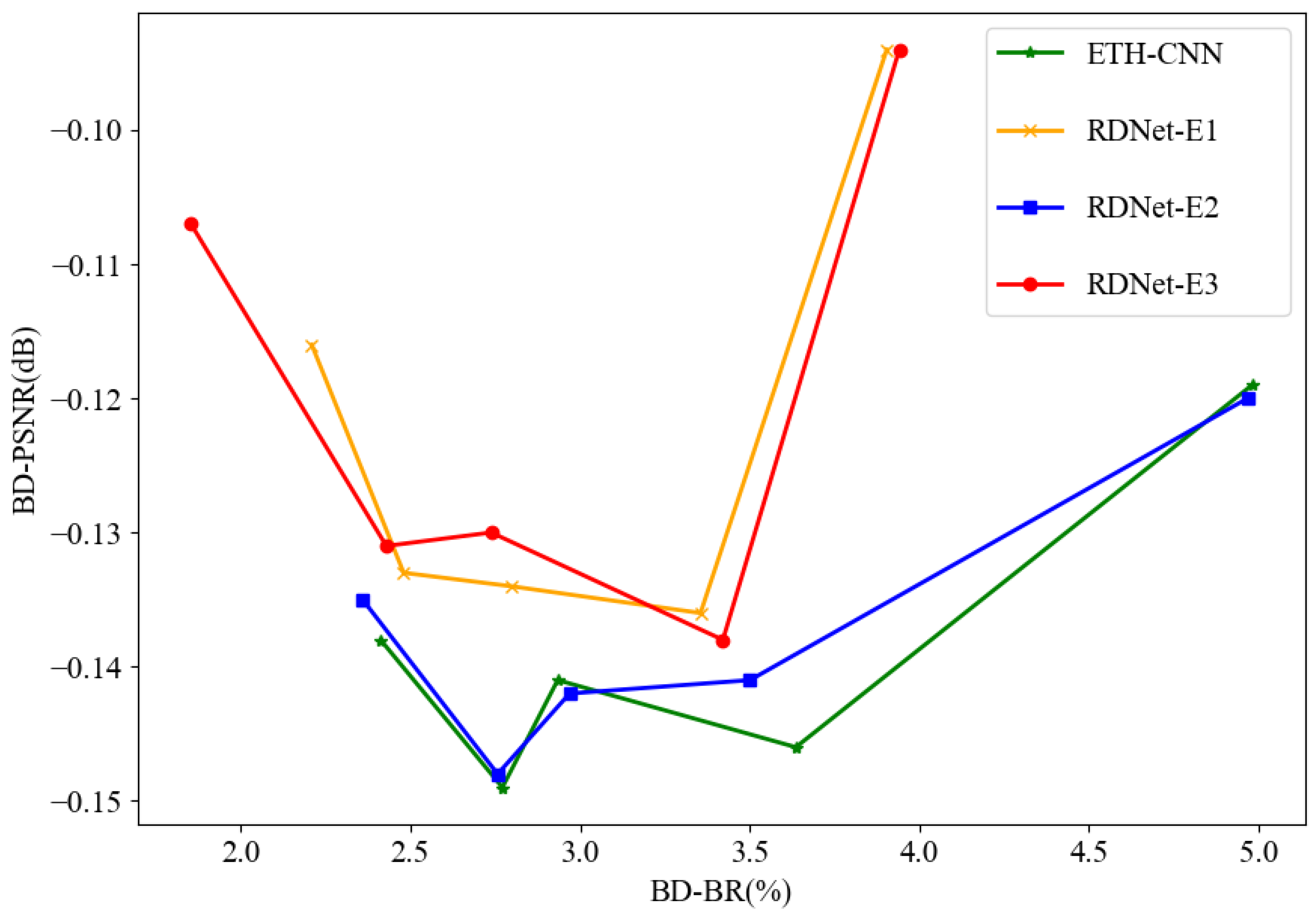
4.2. Ablation Study
4.3. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, D.; Li, Y.; Lin, J.; Li, H.; Wu, F. Deep learning-based video coding: A review and a case study. ACM Comput. Surv. (CSUR) 2020, 53, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Tudor, P. MPEG-2 video compression. Electron. Commun. Eng. J. 1995, 7, 257–264. [Google Scholar] [CrossRef]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H. 264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bross, B.; Wang, Y.K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.R. Overview of the versatile video coding (VVC) standard and its applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Feng, A.; Gao, C.; Li, L.; Liu, D.; Wu, F. Cnn-Based Depth Map Prediction for Fast Block Partitioning in HEVC Intra Coding. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhang, M.; Qu, J.; Bai, H. Entropy-based fast largest coding unit partition algorithm in high-efficiency video coding. Entropy 2013, 15, 2277–2287. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.S.; Park, R.H. Fast CU partitioning algorithm for HEVC using an online-learning-based Bayesian decision rule. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 130–138. [Google Scholar] [CrossRef]
- Zhang, Y.; Kwong, S.; Wang, X.; Yuan, H.; Pan, Z.; Xu, L. Machine learning-based coding unit depth decisions for flexible complexity allocation in high efficiency video coding. IEEE Trans. Image Process. 2015, 24, 2225–2238. [Google Scholar] [CrossRef] [PubMed]
- Qing, A.; Zhou, W.; Wei, H.; Zhou, X.; Zhang, G.; Yang, J. A fast CU partitioning algorithm in HEVC inter prediction for HD/UHD video. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Korea, 13–16 December 2016; pp. 1–5. [Google Scholar]
- Yang, H.; Shen, L.; Dong, X.; Ding, Q.; An, P.; Jiang, G. Low-complexity CTU partition structure decision and fast intra mode decision for versatile video coding. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1668–1682. [Google Scholar] [CrossRef]
- Fu, T.; Zhang, H.; Mu, F.; Chen, H. Fast CU partitioning algorithm for H. 266/VVC intra-frame coding. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 55–60. [Google Scholar]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.Y.; Ying, L. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar] [PubMed]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Liu, Z.; Yu, X.; Gao, Y.; Chen, S.; Ji, X.; Wang, D. CU partition mode decision for HEVC hardwired intra encoder using convolution neural network. IEEE Trans. Image Process. 2016, 25, 5088–5103. [Google Scholar] [CrossRef] [PubMed]
- Jin, Z.; An, P.; Shen, L.; Yang, C. CNN oriented fast QTBT partition algorithm for JVET intra coding. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Xu, M.; Li, T.; Wang, Z.; Deng, X.; Yang, R.; Guan, Z. Reducing complexity of HEVC: A deep learning approach. IEEE Trans. Image Process. 2018, 27, 5044–5059. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Wang, S.; Zhang, X.; Wang, S.; Ma, S. Fast QTBT partitioning decision for interframe coding with convolution neural network. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2550–2554. [Google Scholar]
- Zhang, Y.; Wang, G.; Tian, R.; Xu, M.; Kuo, C.J. Texture-classification accelerated CNN scheme for fast intra CU partition in HEVC. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 241–249. [Google Scholar]
- Galpin, F.; Racapé, F.; Jaiswal, S.; Bordes, P.; Le Léannec, F.; François, E. CNN-based driving of block partitioning for intra slices encoding. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 162–171. [Google Scholar]
- Zhang, M.; Zhai, X.; Liu, Z.; An, C. Fast algorithm for HEVC intra prediction based on adaptive mode decision and early termination of CU partition. In Proceedings of the 2018 Data Compression Conference, Snowbird, UT, USA, 27–30 March 2018; p. 434. [Google Scholar]
- Lu, J.; Li, Y. Fast algorithm for CU partitioning and mode selection in HEVC intra prediction. In Proceedings of the 2019 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 19–21 October 2019; pp. 1–5. [Google Scholar]
- Jamali, M.; Coulombe, S. Fast HEVC intra mode decision based on RDO cost prediction. IEEE Trans. Broadcast. 2018, 65, 109–122. [Google Scholar] [CrossRef]
- Wang, M.; Li, J.; Zhang, L.; Zhang, K.; Liu, H.; Wang, S.; Kwong, S.; Ma, S. Extended quad-tree partitioning for future video coding. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 300–309. [Google Scholar]
- Kibeya, H.; Belghith, F.; Ayed, M.A.B.; Masmoudi, N. A fast CU partitionning algorithm based on early detection of zero block quantified transform coefficients for HEVC standard. In Proceedings of the International Image Processing, Applications and Systems Conference, Sfax, Tunisia, 5–7 November 2014; pp. 1–5. [Google Scholar]
- Ferroukhi, M.; Ouahabi, A.; Attari, M.; Habchi, Y.; Taleb-Ahmed, A. Medical Video Coding Based on 2nd-Generation Wavelets: Performance Evaluation. Electronics 2019, 8, 88. [Google Scholar] [CrossRef] [Green Version]
- Du, B.; Siu, W.C.; Yang, X. Fast CU partition strategy for HEVC intra-frame coding using learning approach via random forests. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 1085–1090. [Google Scholar]
- Zhang, D.; Duan, X.; Zang, D. Decision tree based fast CU partition for HEVC lossless compression of medical image sequences. In Proceedings of the 2017 9th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 11–13 October 2017; pp. 1–6. [Google Scholar]
- Fu, B.; Zhang, Q.; Hu, J. Fast prediction mode selection and CU partition for HEVC intra coding. IET Image Process. 2020, 14, 1892–1900. [Google Scholar] [CrossRef]
- Tissier, A.; Hamidouche, W.; Vanne, J.; Galpin, F.; Menard, D. CNN Oriented Complexity Reduction Of VVC Intra Encoder. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 3139–3143. [Google Scholar]
- JCT-VC. HM Software. 2014. Available online: https://hevc.hhi.fraunhofer.de/svn/svnHEVCSoftware/tags/HM-16.5/ (accessed on 5 November 2016).
- Uddin, K.; Yang, Y.; Oh, B.T. Double compression detection in HEVC-coded video with the same coding parameters using picture partitioning information. Signal Process. Image Commun. 2022, 103, 116638. [Google Scholar] [CrossRef]
- Liu, D.; Liu, X.; Li, Y. Fast CU Size Decisions for HEVC Intra Frame Coding Based on Support Vector Machines. In Proceedings of the 2016 IEEE 14th International Conference on Dependable, Autonomic and Secure Computing, 14th Intl Conf on Pervasive Intelligence and Computing, 2nd International Conference on Big Data Intelligence and Computing and Cyber Science and Technology Congress(DASC/PiCom/DataCom/CyberSciTech), Auckland, New Zealand, 8–12 August 2016; pp. 594–597. [Google Scholar]
- CPH-Intra. Available online: https://github.com/HEVC-Projects/CPH (accessed on 3 October 2018).
- Grellert, M.; Bampi, S.; Correa, G.; Zatt, B.; da Silva Cruz, L.A. Learning-based complexity reduction and scaling for HEVC encoders. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1208–1212. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Resolution Ratio | Test Sequence | Total Frames | FPs | Bit Depth |
|---|---|---|---|---|---|
| A | 2560 × 1600 | Traffic | 150 | 30 | 8 |
| B | 1920 × 1080 | Basketball Drive | 500 | 50 | 8 |
| C | 832 × 480 | Basketball Drill | 500 | 50 | 8 |
| D | 416 × 240 | Basketball Pass | 500 | 50 | 8 |
| E | 1280 × 720 | Johnny | 600 | 60 | 8 |
| Algorithm | Dynamic Threshold | RD-Based Dual Networks | Partition Threshold |
|---|---|---|---|
| ETH-CNN [18] | - | - | [0.50 0.50 0.50] |
| RDNet- | ✓ | - | [0.49 0.55 0.63] |
| RDNet- | - | ✓ | [0.50 0.50 0.50] |
| RDNet- | ✓ | ✓ | [0.48 0.55 0.63] |
| Class | Test Sequence | Algorithm | BD-PSNR (dB) | BD-BR (%) | (%) | |||
|---|---|---|---|---|---|---|---|---|
| QP = 22 | QP = 27 | QP = 32 | QP = 37 | |||||
| A | Traffic | ETH-CNN [18] | −0.149 | 2.771 | −56.62 | −65.17 | −67.79 | −63.16 |
| RDNet- | −0.133 | 2.480 | −60.44 | −66.98 | −70.71 | −69.01 | ||
| RDNet- | −0.148 | 2.757 | −59.57 | −66.41 | −70.27 | −67.80 | ||
| RDNet- | −0.131 | 2.429 | −58.13 | −63.82 | −68.29 | −63.96 | ||
| B | Basketball Drive | ETH-CNN [18] | −0.119 | 4.981 | −57.90 | −72.74 | −79.33 | −79.18 |
| RDNet- | −0.094 | 3.904 | −67.05 | −78.18 | −81.53 | −81.63 | ||
| RDNet- | −0.12 | 4.967 | −61.00 | −76.26 | −81.62 | −82.37 | ||
| RDNet- | −0.094 | 3.941 | −61.26 | −75.76 | −78.70 | −81.43 | ||
| C | Basketball Drill | ETH-CNN [18] | −0.141 | 2.934 | −23.34 | −36.87 | −52.66 | −62.19 |
| RDNet- | −0.134 | 2.796 | −35.75 | −50.64 | −57.38 | −64.14 | ||
| RDNet- | −0.142 | 2.969 | −30.80 | −47.48 | −57.37 | −64.48 | ||
| RDNet- | −0.130 | 2.738 | −20.33 | −47.09 | −57.90 | −66.16 | ||
| D | Basketball Pass | ETH-CNN [18] | −0.138 | 2.412 | −40.54 | −40.30 | −54.42 | −58.00 |
| RDNet- | −0.116 | 2.029 | −40.90 | −44.17 | −56.06 | −60.99 | ||
| RDNet- | −0.135 | 2.359 | −37.33 | −43.29 | −50.66 | −47.70 | ||
| RDNet- | −0.107 | 1.853 | −49.72 | −53.74 | −59.48 | −65.29 | ||
| E | Johnny | ETH-CNN [18] | −0.146 | 3.636 | −73.62 | −73.54 | −74.45 | −78.55 |
| RDNet- | −0.136 | 3.355 | −74.98 | −76.49 | −77.97 | −80.58 | ||
| RDNet- | −0.141 | 3.501 | −74.37 | −76.03 | −80.71 | −82.81 | ||
| RDNet- | −0.138 | 3.421 | −75.25 | −77.21 | −76.52 | −81.23 | ||
| Std. dev. | ETH-CNN [18] | 0.011 | 1.016 | 19.13 | 17.81 | 11.88 | 9.91 | |
| RDNet- | 0.018 | 0.735 | 16.88 | 15.29 | 11.64 | 9.43 | ||
| RDNet- | 0.011 | 1.013 | 18.04 | 15.66 | 13.84 | 14.54 | ||
| RDNet- | 0.018 | 0.821 | 20.42 | 13.26 | 9.51 | 8.90 | ||
| Best | ETH-CNN [18] | −0.119 | 2.412 | −73.62 | −73.54 | −79.33 | −79.18 | |
| RDNet- | −0.094 | 2.029 | −74.98 | −78.18 | −81.53 | −81.63 | ||
| RDNet- | −0.120 | 2.359 | −74.37 | −76.26 | −81.62 | −82.81 | ||
| RDNet- | −0.094 | 1.853 | −75.25 | −77.21 | −78.70 | −81.43 | ||
| Average | ETH-CNN [18] | −0.138 | 3.347 | −50.40 | −57.73 | −65.73 | −68.22 | |
| RDNet- | −0.123 | 2.913 | −55.83 | −63.29 | −68.73 | −71.27 | ||
| RDNet- | −0.137 | 3.311 | −52.61 | −61.90 | −68.13 | −69.03 | ||
| RDNet- | −0.120 | 2.876 | −52.94 | −63.52 | −68.18 | −71.62 | ||
| Class | Test Sequence | FSD-SVM [34] | PPMAC [16] | RDNet- | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BD-PSNR (dB) | BD-BR (%) | (%) | BD-PSNR (dB) | BD-BR (%) | (%) | BD-PSNR (dB) | BD-BR (%) | (%) | ||
| A | PeopleOnStreet | −0.942 | 9.627 | −43.84 | −0.209 | 3.969 | −55.60 | −0.127 | 2.197 | −57.53 |
| Traffic | −0.304 | 6.411 | −28.87 | −0.240 | 4.945 | −60.84 | −0.131 | 2.429 | −63.55 | |
| B | BasketballDrive | −0.244 | 8.923 | −43.40 | −0.141 | 6.018 | −69.51 | −0.094 | 3.941 | −74.29 |
| BQTerrace | −0.295 | 6.627 | −56.62 | −0.267 | 4.815 | −57.89 | −0.078 | 1.191 | −47.96 | |
| Cactus | −0.248 | 7.533 | −43.51 | −0.208 | 6.021 | −63.23 | −0.075 | 1.945 | −52.72 | |
| Kimono | −0.170 | 5.212 | −47.80 | −0.082 | 2.382 | −72.72 | −0.051 | 1.403 | −83.53 | |
| ParkScene | −0.149 | 3.630 | −52.85 | −0.135 | 3.417 | −66.03 | −0.076 | 1.756 | −59.25 | |
| C | BasketballDrill | −0.439 | 9.818 | −53.93 | −0.538 | 12.205 | −63.58 | −0.130 | 2.738 | −47.87 |
| BQMall | −0.486 | 9.646 | −42.06 | −0.468 | 8.077 | −52.14 | −0.084 | 1.333 | −33.08 | |
| PartyScene | −0.468 | 7.383 | −43.01 | −0.672 | 9.448 | −58.75 | −0.028 | 0.363 | −33.66 | |
| RaceHorses | −0.379 | 7.220 | −44.59 | −0.264 | 4.422 | −58.20 | −0.107 | 1.656 | −36.28 | |
| D | BasketballPass | −0.546 | 10.054 | −39.72 | −0.457 | 8.401 | −63.53 | −0.107 | 1.853 | −57.06 |
| BlowingBubbles | −0.373 | 6.178 | −37.04 | −0.463 | 8.328 | −60.78 | −0.052 | 0.845 | −37.87 | |
| BQSquare | −0.876 | 12.342 | −57.43 | −0.211 | 2.563 | −46.72 | −0.022 | 0.263 | −38.67 | |
| RaceHorses | −0.487 | 8.839 | −40.23 | −0.317 | 4.593 | −57.30 | −0.068 | 0.977 | −42.99 | |
| E | FourPeople | −0.480 | 9.077 | −36.22 | −0.439 | 8.002 | −61.54 | −0.173 | 2.905 | −64.20 |
| Johnny | −0.474 | 12.182 | −63.55 | −0.307 | 7.956 | −66.55 | −0.138 | 3.421 | −77.55 | |
| KristenAndSara | −0.627 | 13.351 | −57.51 | −0.265 | 5.478 | −64.72 | −0.139 | 2.662 | −74.00 | |
| Std. dev. | 0.175 | 2.553 | 9.02 | 0.158 | 2.603 | 6.17 | 0.041 | 1.008 | 15.97 | |
| Best | −0.149 | 3.630 | −63.55 | −0.082 | 2.382 | −72.72 | −0.022 | 0.263 | −83.53 | |
| Average | −0.419 | 8.559 | −46.23 | −0.316 | 6.189 | −61.09 | −0.093 | 1.883 | −54.56 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, C.; Xu, C.; Liu, M. RDNet: Rate–Distortion-Based Coding Unit Partition Network for Intra-Prediction. Electronics 2022, 11, 916. https://doi.org/10.3390/electronics11060916
Yao C, Xu C, Liu M. RDNet: Rate–Distortion-Based Coding Unit Partition Network for Intra-Prediction. Electronics. 2022; 11(6):916. https://doi.org/10.3390/electronics11060916
Chicago/Turabian StyleYao, Chao, Chenming Xu, and Meiqin Liu. 2022. "RDNet: Rate–Distortion-Based Coding Unit Partition Network for Intra-Prediction" Electronics 11, no. 6: 916. https://doi.org/10.3390/electronics11060916
APA StyleYao, C., Xu, C., & Liu, M. (2022). RDNet: Rate–Distortion-Based Coding Unit Partition Network for Intra-Prediction. Electronics, 11(6), 916. https://doi.org/10.3390/electronics11060916